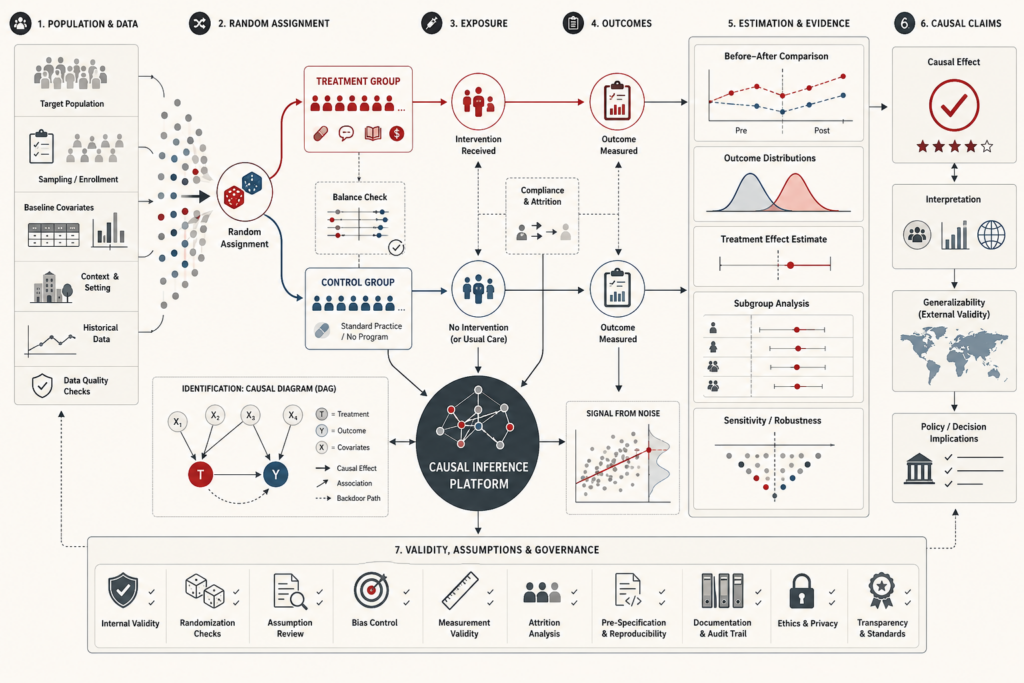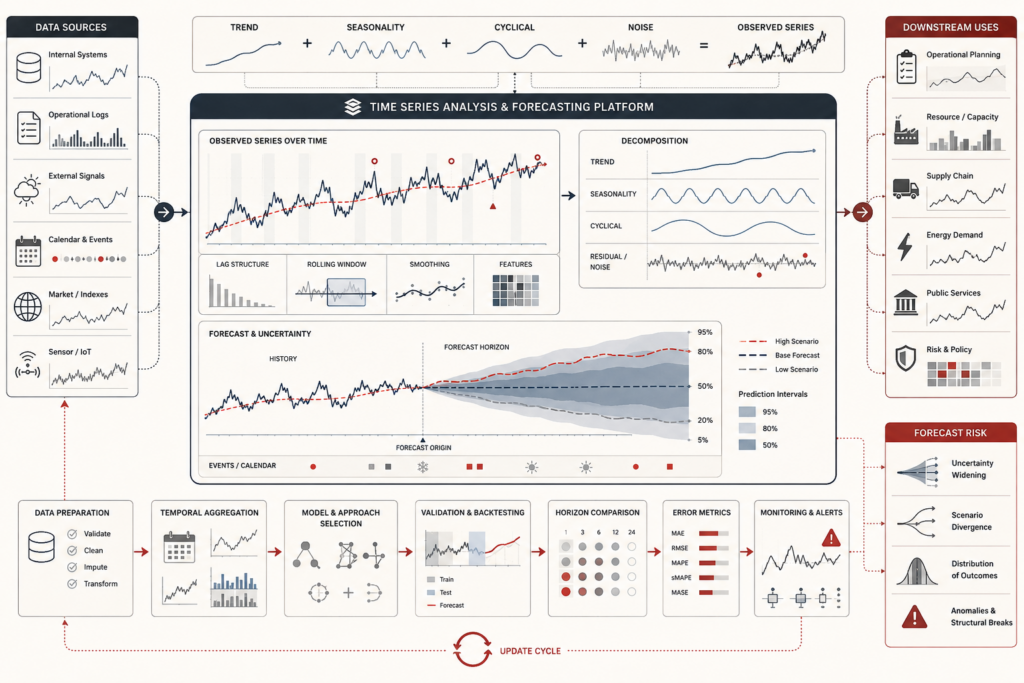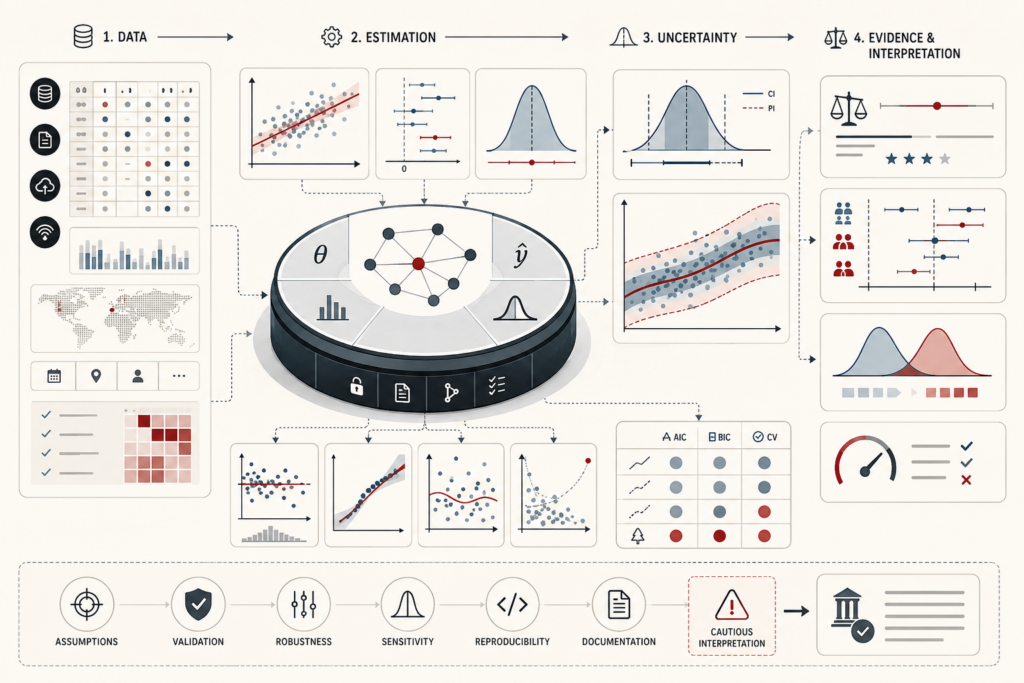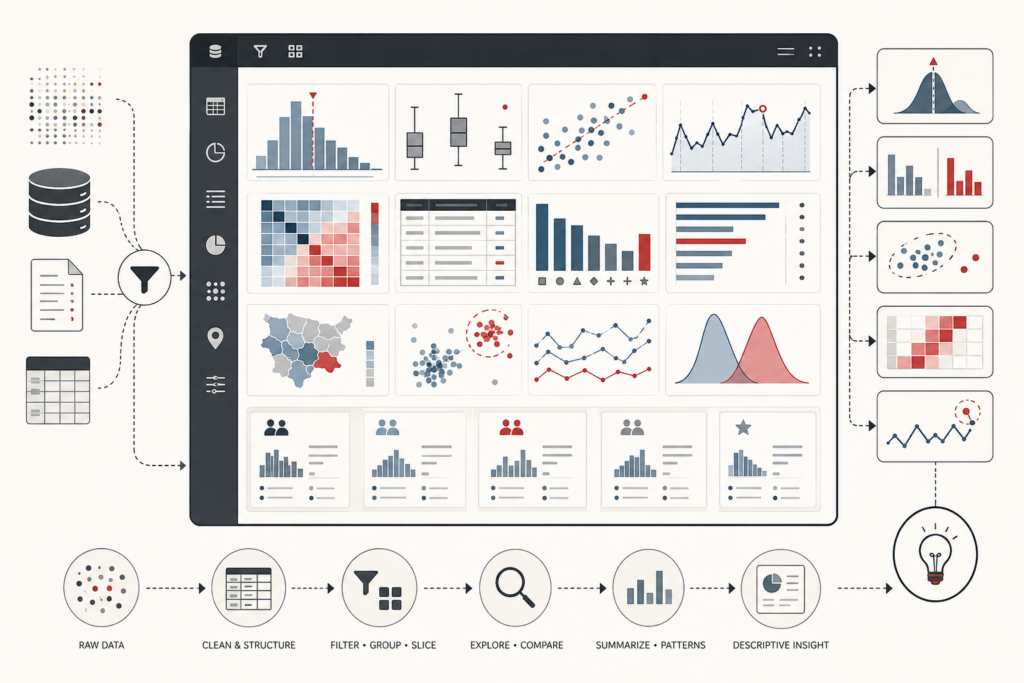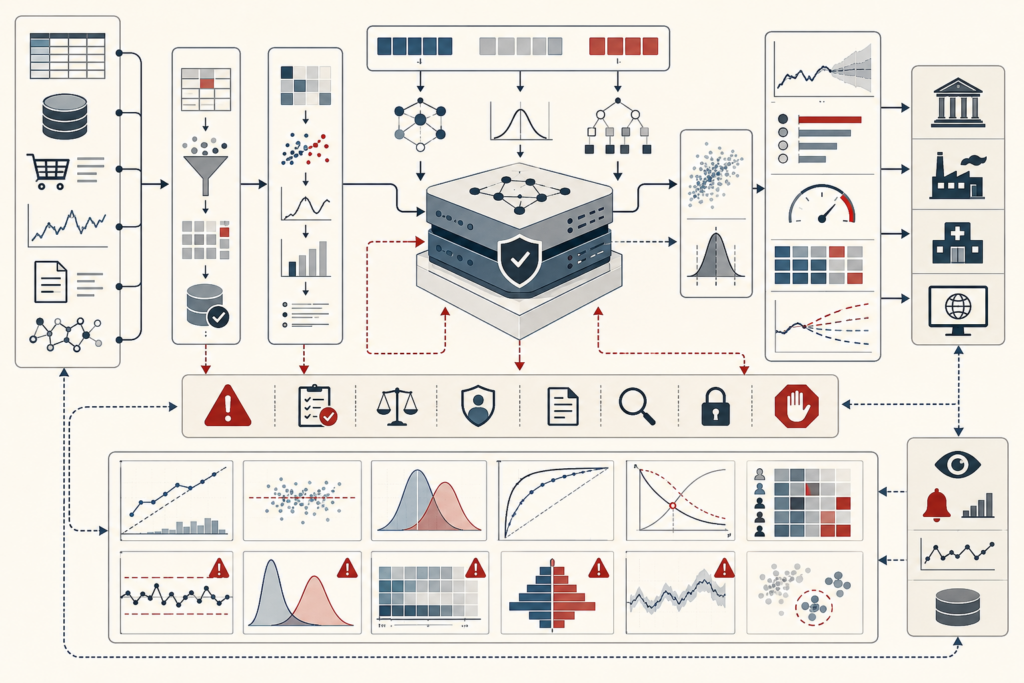
Predictive Analytics and Machine Learning Models: Generalization, Evaluation, and Model Risk
Predictive analytics and machine learning models use historical data to estimate outcomes for unseen cases. This article frames prediction as generalization under uncertainty: the disciplined process of defining targets, engineering features, training models, validating performance, selecting metrics, calibrating probabilities, setting thresholds, monitoring drift, and governing model risk. It explains why predictive modeling is distinct from descriptive analytics, statistical inference, and causal explanation, while still depending on data quality, representation, validation, and evaluation discipline. The article also examines supervised learning, regression, classification, ranking, loss functions, bias–variance tradeoffs, cross-validation, rare-event prediction, calibration, leakage, distribution shift, interpretation, and lifecycle monitoring. A mathematical lens and Python/R workflows show how teams can evaluate predictive readiness, threshold policy, calibration quality, regression error, monitoring windows, leakage controls, and governance gaps.