
Last Updated May 11, 2026
ETL and data transformation systems are the architectural layer through which heterogeneous source data is converted into governed, analyzable, and reusable downstream state. Extract, transform, and load processes emerged as the operational machinery for populating data warehouses from fragmented operational sources, but the underlying problem is broader than warehousing alone. Institutions continually need to move data across boundaries, reconcile differences in structure and meaning, standardize representation, enforce quality rules, compute derived fields, and load the results into environments suited for analysis, reporting, modeling, operational monitoring, or institutional memory.
This topic matters because source systems are rarely designed around shared analytical meaning. Transactional databases optimize for operational state changes; APIs expose application-specific representations; logs and event streams preserve system behavior rather than analytical coherence; files and third-party feeds often arrive with inconsistent identifiers, units, timestamps, and coding conventions. Data transformation systems exist to mediate among these incompatible forms. They do not merely move bytes. They reshape semantics. They define how source records become standardized entities, how business rules are enforced, how quality defects are isolated or corrected, and how downstream tables, marts, models, dashboards, and data products inherit coherent meaning rather than fragmented operational residue.
Main Library
Publications
Article Map
Data Systems & Analytics
Related Topic
Data Pipelines
Related Topic
Data Quality & Observability
Related Topic
Cloud Data Platforms
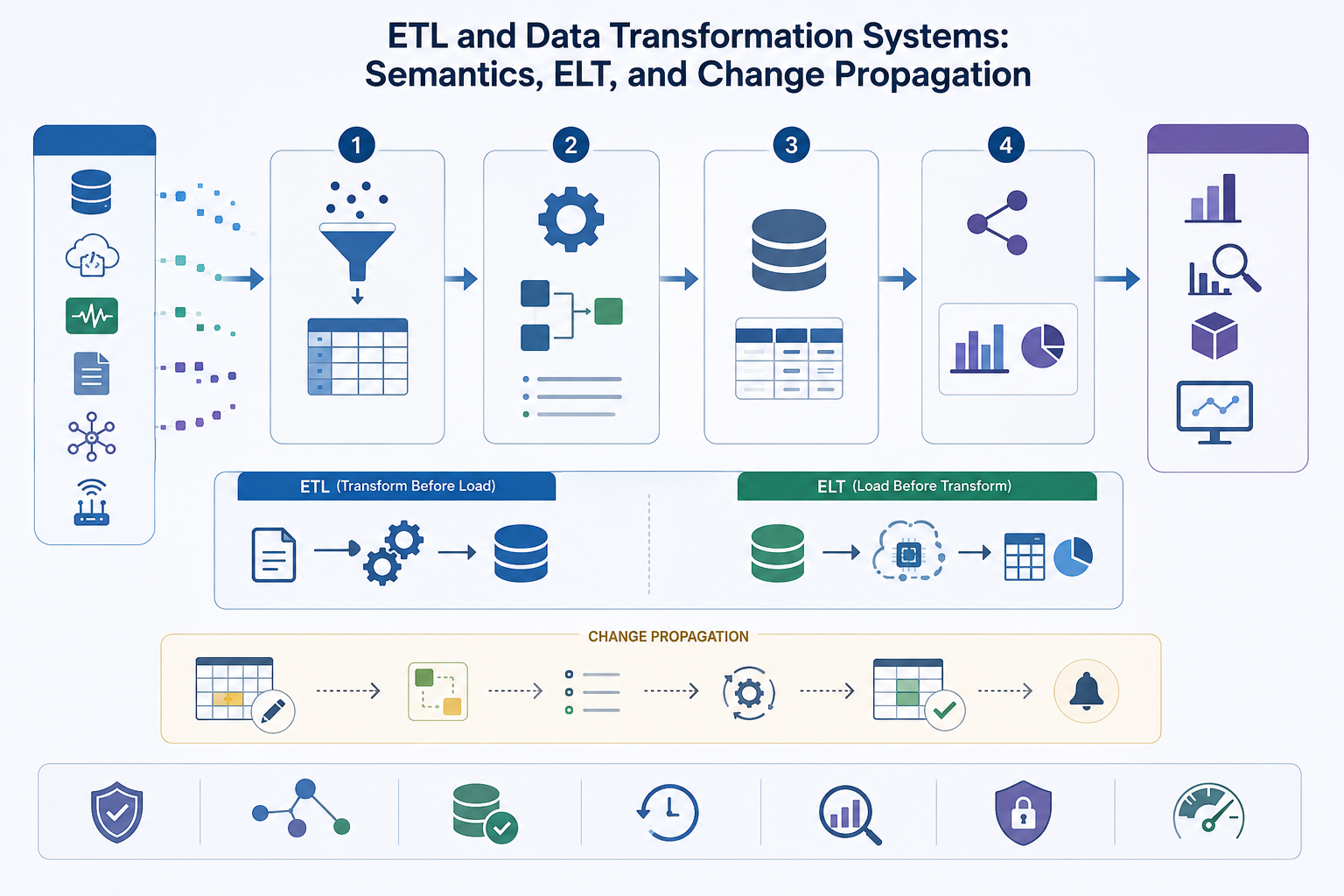
Modern practice has expanded the traditional ETL model. Cloud warehouses, lakehouses, and warehouse-native transformation frameworks have made ELT—extract, load, transform—a major variation, shifting transformation work into the target analytical platform rather than into a separate external engine. Microsoft’s architecture guidance defines the distinction directly: ETL performs transformation before loading into the target store, while ELT loads data first and then uses the computational capabilities of the target data store for transformation. dbt similarly frames ELT as loading raw data into the warehouse and then transforming it there. These shifts matter because they change where computation happens, how staging is managed, how lineage is documented, and how teams organize transformation logic.
This article should therefore be read alongside Data Pipelines and Data Processing Systems, Data Cleaning and Data Quality Management, Data Quality Metrics and Observability, Data Warehouses and Data Lakes, Cloud Data Platforms and Modern Data Stack Architecture, Metadata, Data Catalogs, and Lineage, Streaming Data and Real-Time Analytics, and Reproducible Analytics and Versioned Data Workflows. ETL and ELT sit at the point where movement, meaning, quality, lineage, orchestration, and reuse become one architectural problem.
ETL as semantic infrastructure
The strongest way to understand ETL is not as plumbing but as semantic infrastructure. Extraction retrieves source records. Loading moves data into target environments. But transformation decides what those records mean once they cross architectural boundaries. It decides whether two identifiers refer to the same entity, whether a status code is active or inactive, whether an event belongs to a customer session, whether a correction overwrites history or creates a new historical version, and whether rejected records are discarded, quarantined, or repaired.
This is why ETL and transformation systems are so consequential. They often sit beneath dashboards, machine-learning features, reporting marts, data products, metrics layers, compliance extracts, and institutional decision systems. Downstream users may see only clean tables and certified metrics, but those outputs are the result of many prior decisions: mapping, filtering, cleansing, deduplication, enrichment, conformance, validation, and controlled loading.
Seen this way, transformation logic is not a neutral technical layer. It is institutional interpretation formalized in executable form. High-integrity ETL therefore requires not only performance and scheduling discipline, but also documentation, testing, lineage, review, and governance over the meaning being constructed.
What ETL and data transformation systems mean
ETL refers to the extraction of data from source systems, its transformation into forms suitable for a target use, and its loading into a destination such as a warehouse, mart, lakehouse, analytical store, or operational serving layer. In the classic warehouse literature, ETL processes are the workflows responsible for original loading and periodic refresh, including extraction, transport, transformation, cleansing, and loading into target structures. A data transformation system is the broader computational and organizational environment that defines how source representations are standardized, combined, validated, enriched, documented, and governed over time.
This broader phrasing matters because transformation is not reducible to one batch step inside a warehouse project. Transformation logic exists wherever institutions reconcile mismatched schemas, convert units, standardize codes, compute derived measures, conform identifiers, or reshape source data into canonical downstream models. ETL is therefore one historically dominant pattern for operationalizing transformation, but the architectural problem it addresses is wider and more durable than the acronym alone suggests.
Modern systems may implement transformation in dedicated ETL tools, cloud warehouses, lakehouses, orchestration frameworks, SQL transformation layers, stream processors, notebooks, data build tools, or custom code. The implementation varies, but the problem remains the same: source data must be made trustworthy, interoperable, and meaningful before it can serve as institutional evidence.
Why ETL emerged historically
ETL emerged because the early warehouse problem was not simply storage but integration. As organizations accumulated multiple operational systems, each optimized for local transaction processing, reporting teams needed a separate environment in which information could be reconciled across business functions and historical periods. Operational systems were good at recording state changes for one application. They were not designed to produce shared analytical truth across customer, product, finance, logistics, risk, or regulatory domains.
Historically, this was also a problem of control. Shared analytical stores required repeatable refresh logic, dependable reconciliation routines, and stable methods for cleansing and reshaping operational records into warehouse-ready structures. ETL became the disciplined answer to that challenge. It created a place in the architecture where extraction, staging, validation, semantic mapping, and controlled loading could occur under explicit rules rather than through ad hoc manual exports and spreadsheet repair.
That historical origin still matters. Even though cloud platforms and ELT patterns have changed where transformations often run, the core problem is unchanged: organizations still need a governed mechanism for turning heterogeneous operational traces into stable analytical representations. The platforms evolved. The architectural need did not.
Why ETL exists
ETL exists because operational data is usually not analytically ready. Source systems are optimized around local process needs, not shared enterprise interpretation. A customer table in one application may use different identifiers, status codes, timestamp rules, or address structures than another. Sensor data may use different sampling intervals or units than reporting systems expect. Logs may be timestamped in UTC while operational summaries are maintained in local time. Third-party feeds may contain null-heavy fields, duplicate records, changing schemas, or undocumented coding conventions.
The need is therefore semantic as much as technical. Extraction retrieves data. Transformation makes different sources commensurable. Loading places the results into structures that can support reporting, modeling, auditing, or reuse. Without this layer, organizations often accumulate more data while increasing interpretive fragmentation. ETL is the architecture through which compatibility is engineered rather than assumed.
This is also why transformation systems become institutional bottlenecks when they are underbuilt. If business rules are buried in scripts, if mappings are undocumented, if rejected records are invisible, or if downstream users cannot trace how values were produced, the organization may have integrated storage but not integrated meaning.
The classical ETL architecture
The classical ETL pattern typically includes several stages: extraction from source systems, movement into a staging area, transformation and cleansing against business rules and target schemas, and loading into the destination environment. This description remains useful because it makes clear that ETL is not just copying data from one place to another. It is a multi-stage control system for reshaping data under operational discipline.
A classical pipeline usually begins with source extraction. Source data may arrive through database queries, flat files, APIs, change logs, message streams, or partner feeds. It is then moved into staging, where teams can profile records, validate formats, inspect completeness, isolate malformed tuples, and prepare transformation logic. Transformation then applies mapping rules, standardization, enrichment, deduplication, type conversion, aggregation, and conformance. Loading writes the results into a governed target, often with indexing, partitioning, merge rules, or historical versioning.
The architecture is valuable because each stage creates a control boundary. Source systems remain protected from analytical workloads. Staging preserves intermediate state. Transformation logic becomes testable. Rejected records can be quarantined. Target tables can receive data only after checks pass. The discipline lies not only in the steps themselves, but in the fact that those steps are explicit, rerunnable, and inspectable.
Transformation as semantic reconciliation
Transformation is the intellectual center of ETL. It is where data ceases to be a mere extract from a source system and becomes part of a governed analytical representation. Transformations commonly include type conversion, unit harmonization, timestamp normalization, lookup and enrichment from reference data, reshaping from one grain to another, aggregation, deduplication, derivation of measures, filtering, and rule enforcement.
But the deeper issue is semantic reconciliation. Source systems often encode the same domain differently because they were built for different purposes. One system’s “active customer” may mean recent purchase activity; another may mean contractual status; a third may mean CRM engagement. Transformation logic decides whether those categories should be collapsed, preserved separately, or mapped into a new canonical concept. In this sense, transformation is not merely technical cleanup. It is institutional interpretation formalized in executable form.
This is also why transformation systems tend to become some of the most consequential but least visible assets in the data estate. They embody the organization’s decisions about equivalence, granularity, authoritative sources, and valid analytical state. When those decisions are weakly specified, downstream analytics inherits ambiguity. When they are explicit, tested, and documented, transformation systems become the place where institutional meaning is stabilized.
Canonical models, target schemas, and conformance
Most mature transformation systems implicitly or explicitly rely on a canonical model: a target representation whose purpose is to stabilize meaning across heterogeneous sources. The canonical model may be a warehouse dimensional schema, a conformed customer table, a harmonized event model, a curated analytical layer, or a domain data product with standardized dimensions and measures. Its function is to reduce semantic drift by giving downstream consumers one governed representation instead of many incompatible source-specific ones.
This is why target schemas matter so much. They are not just storage layouts; they are assertions about grain, entity identity, field meaning, valid relationships, historical behavior, and allowed states. Conformance work inside ETL is the process of forcing diverse operational data to respect those assertions. Where this work is weak, downstream systems inherit ambiguity. Where it is strong, the transformation layer becomes a stabilizing mechanism for institutional memory.
Canonical modeling also explains why transformation systems often feel more consequential than their infrastructure footprint suggests. The database may store the tables, but the transformation logic determines what those tables mean. In that sense, ETL is one of the primary places where an institution translates local operational language into shared analytical language.
Staging areas, intermediate state, and controlled loading
Classical ETL design often relies on a staging area: an intermediate environment where extracted data can be profiled, validated, standardized, and prepared before it is loaded into the target. The purpose of staging is not just convenience. It creates a controlled boundary between heterogeneous source systems and governed target structures. In that boundary, teams can isolate malformed records, preserve raw extracts for audit or replay, perform batch reconciliation, and apply transformations without destabilizing either the source or the final destination.
Staging also supports recoverability and controlled failure. If a load breaks, institutions often need to inspect intermediate state, identify the defect, rerun only the relevant segment, or backfill corrected logic. A mature transformation system is therefore not just a chain of direct writes. It often preserves intermediate states precisely because operational trust depends on inspectability and repeatability.
In ELT-oriented systems, staging may move into the target analytical platform itself. Raw landing tables, bronze/silver/gold layers, source snapshots, or warehouse staging schemas can provide the same logical function even when the physical architecture changes. The architectural question is not whether staging is inside or outside the warehouse. The question is whether intermediate state is controlled, inspectable, and governed.
Data quality, cleansing, and constraint enforcement
ETL has long been one of the main places where data quality is enforced in practice. Source systems often permit or produce data that is unsuitable for shared analytics: duplicate entities, invalid codes, incompatible formats, referential mismatches, missing values, unstable identifiers, impossible dates, or records that violate target constraints. ETL therefore functions as one of the institutional checkpoints at which data defects are surfaced and either repaired, quarantined, or disclosed.
A high-integrity transformation system should distinguish several responses to defects. Some records can be standardized automatically. Some should be enriched from reference data. Some should be rejected with clear reason codes. Some should pass with warnings. Some should trigger upstream remediation. Treating all defects as silent cleanup is dangerous because it masks the source-system behavior that produced the problem.
This also reveals a risk. If ETL becomes the sole place where quality is managed, organizations can end up masking deeper upstream design problems through endless downstream cleanup. Transformation systems are vital for remediation, but they should also produce feedback about recurring defects so that source systems, definitions, and workflows can be improved structurally rather than cosmetically.
ETL, ELT, and the shift in processing location
The ETL/ELT distinction is fundamentally about where transformation happens. In traditional ETL, transformation occurs before the target store receives curated data. In ELT, raw or lightly processed data is loaded first, and transformation occurs inside the target data platform, often a cloud warehouse, lakehouse, or analytical SQL engine.
This shift matters because it changes architecture. In traditional ETL, a separate transformation engine or staging layer bears much of the computational burden before the target receives curated data. In ELT, the target platform becomes both storage layer and transformation engine. Warehouse-native transformation frameworks make modular SQL models, tests, documentation, dependency graphs, and lineage easier to organize close to the analytical store.
Neither pattern is universally superior. ETL can be advantageous where transformation must occur before target loading because of quality, compliance, privacy, target-structure, or bandwidth constraints. ELT can be advantageous where scalable analytical compute is already present in the destination and teams want simpler ingestion plus modular, testable transformation logic close to the warehouse. The right choice depends on latency, cost, governance, privacy, and where institutional control over semantics is best maintained.
| Pattern | Transformation location | Strength | Risk if poorly governed |
|---|---|---|---|
| ETL | Before loading into the target store | Curated data reaches the target after pre-load validation and transformation | Opaque external logic, duplicated transformation engines, or hard-to-audit staging |
| ELT | After loading into the target analytical platform | Raw data is preserved and transformations can use scalable warehouse or lakehouse compute | Raw landing sprawl, uncontrolled transformation logic, or weak semantic promotion rules |
| Hybrid | Partly before and partly after loading | Pre-load privacy/quality controls can coexist with warehouse-native modeling | Unclear ownership of which layer is authoritative for meaning |
Mapping logic, surrogate keys, slowly changing state, and business rules
One of the hardest parts of ETL is mapping: deciding how source attributes, entities, and codes correspond to target models. Mapping is not just column-to-column assignment. It often requires grain conversion, surrogate-key generation, status normalization, vocabulary conformance, survivorship rules for conflicting records, and derivation of canonical representations from inconsistent source states. This is where transformation becomes deeply entwined with business semantics.
Surrogate keys are especially important in warehouse-oriented transformation because they decouple target identity from unstable or source-specific operational identifiers. That move is not only technical. It allows the target system to preserve slowly changing and historically stable analytical identity even when upstream systems change their own identifiers, split entities, merge entities, or revise operational classifications.
Slowly changing state is one of the clearest examples of why transformation systems need architectural depth. A source correction does not always mean “overwrite the old value.” Sometimes the downstream model must preserve history, distinguish current from historical truth, or maintain effective-date logic. Transformation systems therefore mediate not just between sources, but between different philosophies of time, identity, and change.
For that reason, ETL systems should be treated as repositories of institutional logic. A transformation that maps operational statuses into reporting categories or converts raw events into standardized measures is not just a technical convenience. It defines what the organization believes those categories and measures mean. Mature teams therefore document mappings, test them, version them, and treat them as governed assets rather than ad hoc code fragments.
Incremental loads, CDC, and change propagation
ETL systems are rarely concerned only with initial loading. They also govern ongoing refresh: daily warehouse updates, near-real-time landing, late-arriving records, corrected source data, source deletes, and change propagation into downstream tables. Full reloads may be simple conceptually, but they are often too slow or too expensive for large systems. Incremental patterns therefore become central to operational design.
One major modern pattern is change data capture, or CDC. CDC captures inserts, updates, and deletes from source systems and represents them as change events that downstream systems can consume. Debezium, for example, is designed to monitor databases and produce row-level change events in commit order, avoiding frequent polling and supporting event-driven propagation of database changes.
This is where transformation systems intersect with scheduling, streaming, and orchestration. Institutions need to know when a downstream table is current, which upstream changes have been incorporated, and how late or corrected data should affect existing derived state. Transformation architecture therefore includes temporal policy as well as structural logic.
Idempotent loads, merge logic, replay, and late corrections
Incremental transformation creates a harder question than simple loading: how should new change records interact with existing target state? Mature ETL systems therefore depend on idempotent load design, meaning that retries, replays, or partial reruns should not silently corrupt downstream tables. In practice this often requires deterministic merge logic, stable business keys, deduplication rules, ordered change application, and careful handling of updates versus inserts.
Late-arriving corrections make this even more important. A source system may revise historical records after the downstream target has already been populated. A CDC stream may surface updates long after an earlier snapshot was loaded. A backfill may rerun older transformation logic with improved mappings. The target must therefore be capable of reconciling new information with existing state rather than merely appending records blindly. This is one reason merge semantics, load windows, and replay safety deserve to be treated as first-class architectural concerns.
Replay capability also changes the philosophical status of ETL. A robust transformation system does not merely produce one current output. It preserves enough lineage, raw state, and deterministic logic to reconstruct that output if assumptions change or defects are discovered. In that sense, replay is not just an operational convenience. It is part of analytical defensibility.
Execution, orchestration, and operational dependability
ETL logic only matters if it runs reliably. A transformation engine is not the same thing as an orchestration layer. The engine performs mapping, filtering, cleansing, joining, validation, enrichment, and computation. Orchestration determines when jobs run, in what order, with which dependencies, retries, logs, credentials, configurations, and failure-handling behavior.
Operational dependability depends on both. A technically correct transformation can still produce unreliable institutional data if it runs out of order, fails silently, lacks restart safety, or cannot be audited after partial failure. Mature ETL systems therefore require scheduling discipline, logging, configuration management, dependency control, restart logic, and controlled rerun behavior in addition to correct transformation logic.
This is especially important when transformation systems become part of recurring reporting, regulatory submission, operational dashboards, ML feature generation, or data product delivery. In those contexts, a transformation failure is not just a technical incident. It is a failure of institutional evidence production.
Lineage, documentation, and transformation governance
Because ETL systems alter data meaningfully, they are a crucial site of lineage and governance. Transformations change codes, derive values, enforce rules, discard records, consolidate entities, normalize timestamps, and reshape grain. Unless these changes are documented, tested, and reviewable, downstream users may see clean tables without understanding how those tables came to be.
Transformation governance means that institutions can answer questions such as: Which sources fed this field? Which rules determined inclusion or exclusion? Which version of the mapping logic produced this table? What happened to rejected records? Which CDC events or load windows contributed to the current state? Which code version ran? Which tests passed or failed? Without those answers, ETL becomes a black box. With them, transformation systems become part of auditable analytical infrastructure.
This is also why ETL should be understood as a mechanism of institutional memory. It preserves not only data movement, but the executable logic through which the institution has chosen to interpret and standardize its data. When transformation logic is versioned, documented, and reproducible, the organization retains a defensible record of how analytical truth was constructed. When it is hidden in opaque scripts or improvised warehouse patches, institutional meaning becomes fragile.
A mathematical lens for ETL and transformation systems
A source extract can be represented as a collection of records from heterogeneous systems:
S = \{r_i : i = 1,\ldots,n\}
\]
Interpretation: The source extract \(S\) contains records \(r_i\) that may differ in schema, grain, identifiers, codes, timestamps, and data quality.
A transformation maps source records into canonical target records:
T(r_i) = c_i
\]
Interpretation: The transformation function \(T\) converts a source record \(r_i\) into a canonical record \(c_i\). This includes semantic mapping, validation, normalization, and target-shape construction.
A mapping table can be represented as a function from source values to canonical values:
M(s, f, v) = v_c
\]
Interpretation: Mapping function \(M\) takes a source system \(s\), field \(f\), and source value \(v\), then returns a canonical value \(v_c\). This is where source-specific language becomes shared analytical language.
A rejected-record rate makes transformation quality visible:
R = \frac{N_{\mathrm{rejected}}}{N_{\mathrm{input}}}
\]
Interpretation: The reject rate \(R\) measures how much input data failed validation or mapping rules. High rejection can indicate source defects, mapping gaps, schema drift, or overly restrictive rules.
Idempotent merge logic requires repeated application to produce the same target state:
L(L(D)) = L(D)
\]
Interpretation: A load function \(L\) is idempotent when applying it more than once to the same data \(D\) does not create duplicate or contradictory target state.
A CDC stream can be represented as ordered changes:
C = \{(k_i, o_i, t_i, q_i)\}_{i=1}^{m}
\]
Interpretation: Each CDC event contains a business key \(k_i\), operation \(o_i\), event time \(t_i\), and sequence number \(q_i\). Correct transformation depends on applying changes in the proper order.
A slowly changing record can carry an effective-time interval:
c_j = (k_j, a_j, t_{\mathrm{start}}, t_{\mathrm{end}})
\]
Interpretation: Slowly changing state can preserve a key \(k_j\), attributes \(a_j\), and the interval during which that version was valid.
A transformation-readiness score can combine mapping coverage, test status, reject-rate control, lineage, orchestration health, and replay capability:
Q_p = w_M M_p + w_T T_p + w_R(1-R_p) + w_L L_p + w_O O_p + w_B B_p
\]
Interpretation: Pipeline quality \(Q_p\) for transformation pipeline \(p\) can combine mapping coverage \(M_p\), transformation test score \(T_p\), controlled reject rate \(R_p\), lineage coverage \(L_p\), orchestration health \(O_p\), and backfill or replay capability \(B_p\).
The point of this mathematical lens is not to reduce transformation to formulas. It is to make the architecture visible: source records become canonical records through governed mappings, validation rules, merge logic, lineage, and controlled promotion into downstream state.
Python Workflow: ETL Transformation and Lineage Scorecard
The following Python workflow demonstrates how an ETL review can transform raw customer and order extracts into canonical outputs, apply status mappings, quarantine rejected records, summarize CDC operations, preserve lineage, and compute a transformation-readiness score.
#!/usr/bin/env python3
"""
Python Workflow: ETL Transformation and Lineage Scorecard
This compact example treats ETL as evidence infrastructure:
raw extracts, semantic mappings, canonical targets, rejects,
lineage, CDC events, transformation tests, and readiness scoring.
"""
from __future__ import annotations
import hashlib
import re
from collections import Counter
from dataclasses import dataclass
@dataclass
class CustomerRecord:
source_system: str
source_customer_id: str
customer_name: str
status_code: str
email: str
@dataclass
class OrderRecord:
source_system: str
source_order_id: str
source_customer_id: str
amount: float
status_code: str
def stable_surrogate_key(*parts: str) -> str:
text = "|".join(parts).lower().strip()
return hashlib.sha256(text.encode("utf-8")).hexdigest()[:16]
def valid_email(value: str) -> bool:
return bool(value and re.match(r"^[^@\s]+@[^@\s]+\.[^@\s]+$", value))
def etl_readiness_score(
mapping_coverage: float,
transformation_tests: float,
controlled_reject_rate: float,
lineage_coverage: float,
orchestration_health: float,
replay_capability: float,
) -> float:
return round(
0.20 * mapping_coverage
+ 0.20 * transformation_tests
+ 0.18 * controlled_reject_rate
+ 0.16 * lineage_coverage
+ 0.14 * orchestration_health
+ 0.12 * replay_capability,
3,
)
def main() -> None:
status_mapping = {
("crm", "A"): "active",
("crm", "I"): "inactive",
("erp", "ACTIVE"): "active",
("erp", "INACTIVE"): "inactive",
("commerce", "paid"): "completed",
("commerce", "refund"): "refunded",
("pos", "COMPLETE"): "completed",
("pos", "RETURN"): "refunded",
}
customers = [
CustomerRecord("crm", "CRM-001", "Ada Lovelace", "A", "ada@example.com"),
CustomerRecord("crm", "CRM-002", "Grace Hopper", "A", "grace@example.com"),
CustomerRecord("erp", "1001", "Ada L.", "ACTIVE", "ada@example.com"),
CustomerRecord("crm", "CRM-004", "Invalid Missing Email", "A", ""),
]
canonical_customers = []
rejects = []
key_map = {}
for record in customers:
canonical_status = status_mapping.get((record.source_system, record.status_code))
reasons = []
if not valid_email(record.email):
reasons.append("invalid_or_missing_email")
if not canonical_status:
reasons.append("unmapped_customer_status")
canonical_customer_id = stable_surrogate_key(record.email or record.source_customer_id)
key_map[record.source_customer_id] = canonical_customer_id
if reasons:
rejects.append({
"entity": "customer",
"source_id": record.source_customer_id,
"reject_reason": ";".join(reasons),
})
continue
canonical_customers.append({
"canonical_customer_id": canonical_customer_id,
"source_system": record.source_system,
"source_customer_id": record.source_customer_id,
"customer_status": canonical_status,
"email": record.email.lower(),
})
orders = [
OrderRecord("commerce", "O-1001", "CRM-001", 120.50, "paid"),
OrderRecord("commerce", "O-1003", "CRM-003", 45.00, "refund"),
OrderRecord("pos", "P-4401", "1001", 63.25, "COMPLETE"),
OrderRecord("commerce", "O-1004", "CRM-404", 98.00, "paid"),
]
canonical_orders = []
for record in orders:
canonical_status = status_mapping.get((record.source_system, record.status_code))
canonical_customer_id = key_map.get(record.source_customer_id)
reasons = []
if not canonical_status:
reasons.append("unmapped_order_status")
if not canonical_customer_id:
reasons.append("missing_customer_mapping")
if reasons:
rejects.append({
"entity": "order",
"source_id": record.source_order_id,
"reject_reason": ";".join(reasons),
})
continue
canonical_orders.append({
"canonical_order_id": stable_surrogate_key(record.source_system, record.source_order_id),
"canonical_customer_id": canonical_customer_id,
"amount_usd": record.amount,
"order_status": canonical_status,
})
cdc_events = [
{"entity": "customer", "operation": "insert"},
{"entity": "order", "operation": "insert"},
{"entity": "order", "operation": "update"},
{"entity": "customer", "operation": "update"},
]
cdc_summary = Counter((event["entity"], event["operation"]) for event in cdc_events)
total_input = len(customers) + len(orders)
reject_rate = len(rejects) / total_input
print({"canonical_customers": canonical_customers})
print({"canonical_orders": canonical_orders})
print({"rejected_records": rejects})
print({"cdc_summary": dict(cdc_summary)})
print({
"etl_readiness_score": etl_readiness_score(
mapping_coverage=0.95,
transformation_tests=0.82,
controlled_reject_rate=1.0 - reject_rate,
lineage_coverage=0.90,
orchestration_health=0.78,
replay_capability=0.85,
)
})
if __name__ == "__main__":
main()
This workflow treats transformation as a governed evidence process. It does not only produce canonical outputs. It preserves rejected records, mapping logic, CDC operation summaries, surrogate keys, and readiness indicators that help explain whether the transformation can be trusted.
R Workflow: ETL Staging, Mapping, Quality Gates, and Transformation Summary
The following R workflow summarizes source extracts, applies canonical status mappings, identifies quality issues, summarizes transformed customer and order states, reviews transformation tests, and records orchestration run health.
#!/usr/bin/env Rscript
# R Workflow: ETL Staging, Mapping, Quality Gates,
# and Transformation Summary
customers <- data.frame(
source_system = c("crm", "crm", "erp", "erp", "billing", "crm"),
source_customer_id = c("CRM-001", "CRM-002", "1001", "1002", "B-884", "CRM-004"),
customer_name = c(
"Ada Lovelace",
"Grace Hopper",
"Ada L.",
"Grace M. Hopper",
"Ada Lovelace",
"Invalid Missing Email"
),
status_code = c("A", "A", "ACTIVE", "ACTIVE", "current", "A"),
email = c(
"ada@example.com",
"grace@example.com",
"ada@example.com",
"grace@example.com",
"ada@example.com",
NA
),
stringsAsFactors = FALSE
)
orders <- data.frame(
source_system = c("commerce", "commerce", "pos", "pos", "billing", "commerce"),
source_order_id = c("O-1001", "O-1002", "P-4401", "P-4402", "INV-778", "O-1004"),
source_customer_id = c("CRM-001", "CRM-002", "1001", "1002", "B-884", "CRM-404"),
amount = c(120.50, 84.00, 63.25, 71.90, 200.00, 98.00),
status_code = c("paid", "paid", "COMPLETE", "COMPLETE", "posted", "paid"),
stringsAsFactors = FALSE
)
mappings <- data.frame(
source_system = c("crm", "crm", "erp", "billing", "commerce", "pos", "billing"),
source_value = c("A", "I", "ACTIVE", "current", "paid", "COMPLETE", "posted"),
canonical_domain = c(
"customer_status",
"customer_status",
"customer_status",
"customer_status",
"order_status",
"order_status",
"order_status"
),
canonical_value = c("active", "inactive", "active", "active", "completed", "completed", "completed"),
stringsAsFactors = FALSE
)
customer_mapping <- subset(mappings, canonical_domain == "customer_status")
order_mapping <- subset(mappings, canonical_domain == "order_status")
customers_mapped <- merge(
customers,
customer_mapping[, c("source_system", "source_value", "canonical_value")],
by.x = c("source_system", "status_code"),
by.y = c("source_system", "source_value"),
all.x = TRUE
)
customers_mapped$customer_status <- customers_mapped$canonical_value
customers_mapped$email_missing <- ifelse(is.na(customers_mapped$email) | customers_mapped$email == "", 1, 0)
orders_mapped <- merge(
orders,
order_mapping[, c("source_system", "source_value", "canonical_value")],
by.x = c("source_system", "status_code"),
by.y = c("source_system", "source_value"),
all.x = TRUE
)
orders_mapped$order_status <- orders_mapped$canonical_value
customer_summary <- aggregate(
source_customer_id ~ source_system + customer_status,
data = customers_mapped,
FUN = length
)
names(customer_summary) <- c(
"source_system",
"customer_status",
"customer_count"
)
order_summary <- aggregate(
amount ~ source_system + order_status,
data = orders_mapped,
FUN = function(x) c(
order_count = length(x),
amount_sum = sum(x),
amount_mean = mean(x)
)
)
order_summary <- do.call(data.frame, order_summary)
names(order_summary) <- c(
"source_system",
"order_status",
"order_count",
"amount_sum",
"amount_mean"
)
quality_summary <- data.frame(
metric = c(
"customer_rows",
"order_rows",
"missing_customer_email",
"unmapped_customer_status",
"unmapped_order_status",
"missing_customer_mapping"
),
value = c(
nrow(customers),
nrow(orders),
sum(customers_mapped$email_missing),
sum(is.na(customers_mapped$customer_status)),
sum(is.na(orders_mapped$order_status)),
sum(!(orders_mapped$source_customer_id %in% customers_mapped$source_customer_id))
)
)
tests <- data.frame(
test_name = c(
"customer_email_required",
"canonical_status_required",
"order_customer_key_required",
"status_mapping_coverage",
"idempotent_merge_key",
"lineage_run_id_present"
),
scope = c("customer", "customer", "order", "mapping", "load", "governance"),
status = c("warn", "pass", "warn", "pass", "pass", "pass"),
severity = c("high", "critical", "critical", "critical", "critical", "high"),
stringsAsFactors = FALSE
)
test_summary <- aggregate(
test_name ~ scope + status + severity,
data = tests,
FUN = length
)
names(test_summary) <- c(
"scope",
"status",
"severity",
"test_count"
)
runs <- data.frame(
pipeline_name = c("customer_transform", "order_transform", "cdc_merge"),
input_rows = c(10, 10, 7),
loaded_rows = c(9, 9, 6),
rejected_rows = c(1, 1, 1),
status = c("completed_with_warning", "completed_with_warning", "completed_with_warning"),
stringsAsFactors = FALSE
)
run_summary <- aggregate(
cbind(input_rows, loaded_rows, rejected_rows) ~ pipeline_name + status,
data = runs,
FUN = sum
)
dir.create("outputs", showWarnings = FALSE, recursive = TRUE)
write.csv(customer_summary, "outputs/customer_status_summary_r.csv", row.names = FALSE)
write.csv(order_summary, "outputs/order_status_summary_r.csv", row.names = FALSE)
write.csv(quality_summary, "outputs/quality_summary_r.csv", row.names = FALSE)
write.csv(test_summary, "outputs/transformation_test_summary_r.csv", row.names = FALSE)
write.csv(run_summary, "outputs/orchestration_run_summary_r.csv", row.names = FALSE)
cat("Wrote ETL customer, order, quality, test, and run summaries.\n")
This workflow treats ETL as an auditable transformation record. It shows how source-specific statuses become canonical states, how quality gates identify missing or unmapped records, and how orchestration metadata reveals whether transformation runs completed cleanly or with warnings.
Applications across domains
ETL and data transformation systems appear wherever heterogeneous source data must become coherent downstream state. Enterprises use them to populate warehouses and reporting marts from transactional systems. Platforms use them to standardize logs, events, and customer data for analytics. Public-sector organizations use them to integrate administrative records across programs. Healthcare systems use them to reconcile clinical, operational, and billing data. Scientific and environmental systems use them to standardize measurements, metadata, and observational records across instruments and time.
In machine-learning environments, transformation systems produce training datasets, feature tables, label definitions, and evaluation slices. In compliance settings, they produce auditable extracts and governed reporting structures. In streaming architectures, they standardize event schemas and change records. In self-service analytics, they provide curated models and certified tables that protect users from source-system inconsistency.
Across these domains, the core problem is the same: raw source data is not yet institutional knowledge. Transformation systems make it comparable, governed, and usable.
Implementation principles for high-integrity transformation systems
Preserve raw source state. Raw extracts, snapshots, or CDC logs should be retained long enough to support audit, replay, and backfill.
Define target grain and identity. Canonical tables should state what one row represents and how entities are identified.
Treat mappings as governed assets. Status codes, unit conversions, vocabulary mappings, and source-to-target logic should be versioned, reviewed, and tested.
Separate staging from promotion. Intermediate data should be inspectable before it becomes authoritative downstream state.
Test transformation logic. Null constraints, referential integrity, accepted values, row counts, mapping coverage, duplicate checks, and business rules should run before promotion.
Quarantine rejected records. Rejections should include reason codes, source identifiers, run IDs, and remediation paths.
Design incremental loads for idempotence. Retries and replays should not create duplicate or contradictory target state.
Document CDC and late-correction policy. Inserts, updates, deletes, corrections, and late-arriving records should have explicit merge semantics.
Record lineage for every output. Downstream tables should link to source batches, input fingerprints, transformation versions, run IDs, and test results.
Make orchestration observable. Job status, dependencies, retries, duration, row counts, failures, and warnings should be monitored as part of analytical trust.
| Control | Purpose | Failure it prevents |
|---|---|---|
| Raw extract preservation | Maintains original source state for audit and replay | Irreversible transformation with no way to reconstruct inputs |
| Staging layer | Creates an inspectable boundary before canonical promotion | Direct loading of malformed or unvalidated source records |
| Semantic mapping registry | Documents source-to-canonical values and business rules | Hidden institutional meaning buried in ad hoc code |
| Transformation tests | Checks validity, completeness, referential integrity, and mapping coverage | Clean-looking outputs built on failed assumptions |
| Rejected-record quarantine | Captures records that fail quality or mapping rules | Silent data loss and untraceable exclusions |
| Idempotent merge logic | Ensures retries and replays produce stable target state | Duplicate inserts, corrupted updates, and inconsistent reruns |
| CDC operation ordering | Applies inserts, updates, and deletes in correct sequence | Incorrect target state from unordered changes |
| Lineage and run metadata | Links outputs to inputs, code versions, tests, and orchestration runs | Black-box transformation and weak auditability |
GitHub Repository
This article can be paired with a companion code workflow that models ETL and ELT as transformation evidence infrastructure. The example includes raw extracts, semantic mappings, CDC events, transformation tests, orchestration runs, canonical customers and orders, rejected-record quarantine, lineage records, SQL schemas, Python and R workflows, Julia scoring, typed contracts, Quarto report templates, and multi-language examples across Python, R, Julia, SQL, Go, Rust, C, C++, TypeScript, and Terraform placeholders.
Conclusion
ETL and data transformation systems are central to trustworthy data architecture because they convert heterogeneous operational traces into governed analytical state. Their purpose is not merely to extract, move, and load records. Their deeper purpose is to reconcile meaning across systems: identifiers, statuses, timestamps, units, grains, histories, business rules, quality constraints, and target representations.
The deeper point is that transformation systems are institutional memory in executable form. They define how source records become canonical entities, how defects are handled, how changes propagate, how history is preserved, and how downstream users can trust what they see. In mature data systems, ETL and ELT are not background plumbing. They are the governed machinery through which data becomes evidence.
Related articles
- Data Systems & Analytics
- Data Pipelines and Data Processing Systems
- Data Cleaning and Data Quality Management
- Data Quality Metrics and Observability
- Data Warehouses and Data Lakes
- Cloud Data Platforms and Modern Data Stack Architecture
- Metadata, Data Catalogs, and Lineage
- Reproducible Analytics and Versioned Data Workflows
Further reading
- Batini, C. and Scannapieco, M. (2016) Data and Information Quality: Dimensions, Principles and Techniques. Cham: Springer.
- Kimball, R. and Caserta, J. (2004) The Data Warehouse ETL Toolkit: Practical Techniques for Extracting, Cleaning, Conforming, and Delivering Data. Indianapolis: Wiley.
- Kleppmann, M. (2017) Designing Data-Intensive Applications. Sebastopol, CA: O’Reilly Media.
- Reis, J. and Housley, M. (2022) Fundamentals of Data Engineering. Sebastopol, CA: O’Reilly Media.
- Vassiliadis, P., Simitsis, A. and Skiadopoulos, S. (2009) ‘A survey of extract-transform-load technology’, International Journal of Data Warehousing and Mining, 5(3), pp. 1–27.
References
- Amazon Web Services (n.d.) What is ETL? Available at: https://aws.amazon.com/what-is/etl/
- Amazon Web Services (n.d.) ETL vs ELT: Difference Between Data-Processing Approaches. Available at: https://aws.amazon.com/compare/the-difference-between-etl-and-elt/
- Azure Architecture Center (n.d.) Extract, transform, load (ETL). Microsoft Learn. Available at: https://learn.microsoft.com/en-us/azure/architecture/data-guide/relational-data/etl
- Debezium (n.d.) Features. Available at: https://debezium.io/documentation/reference/stable/features.html
- Debezium (n.d.) Frequently Asked Questions. Available at: https://debezium.io/documentation/faq/
- dbt Labs (2025) Understanding ELT: extract, load, transform. Available at: https://www.getdbt.com/blog/extract-load-transform
- dbt Labs (2026) ETL vs ELT: Key differences explained. Available at: https://www.getdbt.com/blog/etl-vs-elt
- Microsoft (2024) Instead of ETL, design ELT. Azure Synapse Analytics. Available at: https://learn.microsoft.com/en-us/azure/synapse-analytics/sql-data-warehouse/design-elt-data-loading
- Microsoft (2025) Introduction to Azure Data Factory. Available at: https://learn.microsoft.com/en-us/azure/data-factory/introduction
- The Kimball Group (n.d.) The Data Warehouse ETL Toolkit. Available at: https://www.kimballgroup.com/data-warehouse-business-intelligence-resources/books/data-warehouse-dw-etl-toolkit/
- Vassiliadis, P., Simitsis, A. and Skiadopoulos, S. (2009) ‘A survey of extract-transform-load technology’, International Journal of Data Warehousing and Mining, 5(3), pp. 1–27. Available at: https://www.cse.uoi.gr/~pvassil/downloads/ETL/SHORT_DESCR/09IJDWM_proof.pdf