
Last Updated May 11, 2026
Statistical modeling and inference are the disciplines through which data moves from description toward explanation, estimation, and disciplined uncertainty. Descriptive analytics can summarize what has been observed, and exploratory analysis can reveal distributions, anomalies, and latent structure, but statistical modeling asks a more demanding question: what systematic pattern or process plausibly generated these observations? Inference then asks what can be learned from limited data about a wider population, process, or parameter, and how strongly that learning should be qualified by uncertainty.
This topic matters because modern data work is rarely satisfied with summary alone. Organizations want to estimate effects, compare groups, quantify uncertainty, project likely ranges, test whether observed differences are consistent with noise, and determine whether relationships are stable enough to inform action. But statistical modeling is not a mechanical truth machine. A model is a structured simplification. It highlights some relationships and suppresses others. Inference is therefore only as credible as the assumptions, design, measurement quality, diagnostics, and uncertainty accounting behind it.
Main Library
Publications
Article Map
Data Systems & Analytics
Related Topic
Artificial Intelligence Systems
Related Topic
Risk & Resilience
Related Topic
Institutions & Governance
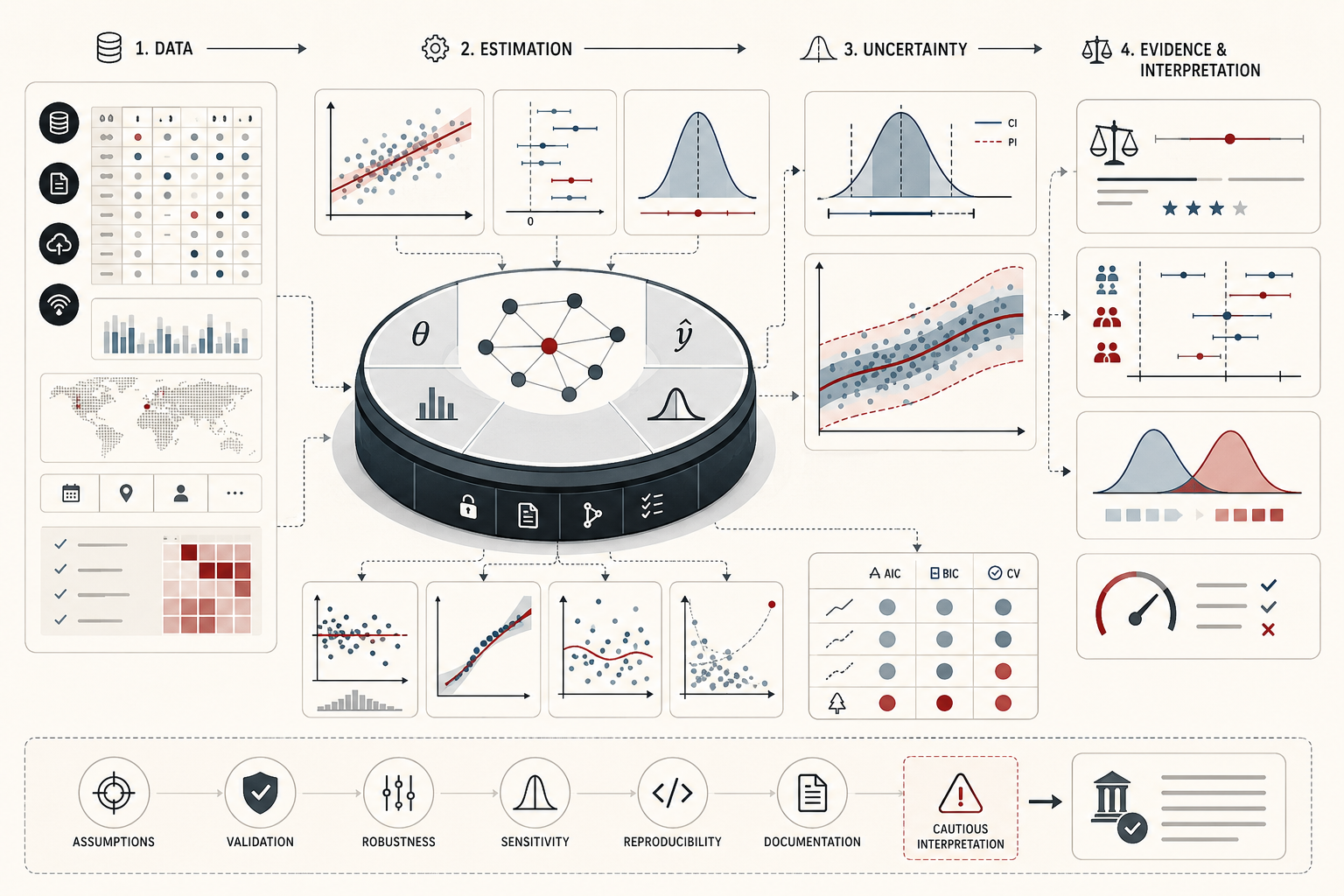
This article builds on the themes developed in Descriptive Analytics and Data Exploration, Data Cleaning and Data Quality Management, Experimental Design and Causal Inference, Time Series Analysis and Forecasting, Predictive Analytics and Machine Learning Models, Model Training and Validation, Model Evaluation and Performance Metrics, and Reproducible Analytics and Versioned Data Workflows. If descriptive analytics clarifies observed patterns, statistical modeling and inference ask what can be estimated, how uncertain those estimates are, and what claims the evidence can responsibly support.
Inference as qualified evidence
The strongest way to understand statistical modeling and inference is as qualified evidence. Statistical inference does not remove uncertainty from empirical work. It makes uncertainty explicit enough that claims can be stated with proportion. A model estimate is not a fact by itself. It is a structured claim produced from data, assumptions, measurement processes, and a modeling framework.
This distinction matters because data analysis often moves too quickly from numerical output to substantive conclusion. A coefficient is interpreted as if it were a mechanism. A p-value is treated as if it were a truth detector. A narrow confidence interval is treated as if it were more trustworthy than the design that produced it. Statistical modeling and inference discipline this movement by asking what is being estimated, what assumptions make the estimate meaningful, how much uncertainty remains, and what the estimate does or does not justify.
Inference therefore sits between description and decision. It helps analysts move beyond raw summaries while resisting overclaim. The goal is not to make every conclusion timid. The goal is to make each conclusion properly supported by the evidence available.
What statistical modeling and inference mean
Statistical modeling is the construction of mathematical or probabilistic representations that describe how observed data may have been generated, how variables may be related, and how uncertainty enters those relationships. Statistical inference is the process of using observed data to estimate unknown quantities, compare groups, evaluate claims, and quantify uncertainty about a broader population, process, or parameter.
The two ideas are closely linked but not identical. A model specifies a structure: for example, that an outcome depends on predictors plus random error, or that repeated measurements arise from a probability distribution with certain parameters. Inference uses observed data within that structure to say something about unknown quantities or competing explanations. In practice, inference is rarely model-free; even apparently simple confidence intervals and tests depend on assumptions about randomness, sampling, measurement, and variation.
This is why statistical inference should not be reduced to software output. The software returns estimates, intervals, test statistics, residuals, diagnostics, and fitted values. The inferential work is deciding what those outputs mean under the model, whether the assumptions are plausible, and how cautiously the result should be interpreted.
Why inference matters
Inference matters because most empirical work is conducted under partial information. Analysts seldom observe every case, every future outcome, or every counterfactual scenario. Instead, they work with samples, measurements, operational records, sensors, surveys, experiments, transactions, administrative data, and imperfect proxies. Statistical inference provides a disciplined way to move from those limited observations toward broader claims while keeping uncertainty visible.
Without inference, observed differences may be mistaken for stable effects, noise may be mistaken for structure, and sample idiosyncrasies may be treated as general truths. A sample mean may look persuasive, but another sample might have produced a different mean. A regression coefficient may look large, but the uncertainty around it may be substantial. A group difference may appear meaningful, but the sample may be too small, biased, or noisy to support a strong conclusion.
Inference also matters because decisions often require judgment under uncertainty. A responsible analytical system does not pretend uncertainty is absent. It records, estimates, communicates, and governs uncertainty so decisions can be made with better knowledge of what is known, what is plausible, and what remains unresolved.
What a statistical model is
A statistical model is a simplified representation of a data-generating process. It may take the form of a distributional assumption, a regression equation, a likelihood function, a hierarchical structure, a Bayesian model, a generalized linear model, or another probabilistic specification. The key point is that a model is selective. It captures some structure while ignoring other complexity.
This selective nature is not a defect. Models are useful because they simplify. But simplification becomes dangerous when forgotten. Every model includes judgment: which variables are relevant, which distribution seems plausible, which error structure is acceptable, whether observations can be treated as independent, whether relationships are linear, whether variance is constant, whether interactions matter, and whether the sample supports the claim being made.
A statistical model is therefore neither pure reality nor arbitrary fiction. It is a disciplined approximation. Its value depends on whether the approximation is good enough for the inferential purpose at hand.
Populations, samples, and sampling variability
Much of statistical inference begins with the distinction between a population and a sample. The population is the broader set of cases, units, events, or process states of interest. The sample is the subset actually observed. Because different samples would generally produce different numerical summaries, inference must account for sampling variability: the fact that estimates fluctuate across repeated sampling even when the underlying process is unchanged.
This is one of the most important reasons descriptive patterns alone are not enough. A sample mean, difference, proportion, slope, or rate may look striking, but inference asks whether that observed pattern is large relative to the variation one would reasonably expect from the sampling process.
Sampling variability also complicates organizational analytics. Operational data may appear exhaustive but still be only a partial view of the process that matters. A dashboard may include all recorded transactions, yet omit unrecorded behavior, future cases, missing populations, measurement changes, or alternative conditions. Inference therefore requires clarity about what the observed data represents and what population or process the analyst is generalizing toward.
Estimands, estimators, and estimates
High-quality inference begins by distinguishing estimands, estimators, and estimates. The estimand is the quantity of interest: a population mean, treatment effect, regression slope, risk difference, odds ratio, variance component, correlation, or prediction error. The estimator is the procedure used to estimate that quantity. The estimate is the numerical result produced by applying the estimator to data.
This distinction prevents confusion. Analysts often start with a model or software function before defining what they want to learn. But the estimand should come first. If the target is a population mean, the workflow differs from one targeting a group difference, a causal effect, a predictive error rate, or an adjusted association. If the estimand is unclear, the estimate may be technically valid but substantively ambiguous.
Defining the estimand also improves communication. It forces the analyst to say what the claim is about. Is the article estimating a mean level, a difference between groups, a slope, a probability, a rate, a causal effect, or the expected value of a future outcome? Good inference begins with that clarity.
Point estimation and interval estimation
Point estimation provides a single best estimate of an unknown quantity, such as a mean, proportion, slope, difference, or rate. Interval estimation provides a range of plausible values for that quantity given the data, method, and assumptions used. The point estimate is useful, but the interval often carries the more honest evidentiary message.
Intervals matter because they resist false precision. A single number can create the impression of certainty even when uncertainty is large. An interval reminds readers that the estimate is conditional on finite data and a modeling procedure. The width of the interval communicates how much precision the data can support.
This does not mean intervals should be treated mechanically. A confidence interval has a specific frequentist interpretation tied to repeated sampling. A credible interval has a Bayesian interpretation tied to posterior probability under a model and prior. Both are useful, but neither eliminates the need for design quality, assumption review, measurement validity, and substantive interpretation.
Hypothesis testing and evidentiary claims
Hypothesis testing evaluates whether observed data would be surprising under a specified null model. In classical form, analysts specify a null hypothesis, calculate a test statistic, and assess how extreme the observed result is relative to a reference distribution. This can be useful when the analytical question is framed as whether the data provide evidence against a particular baseline claim.
But hypothesis testing is often overinterpreted. A test can help evaluate compatibility with a null model, but it does not automatically establish practical importance, causal truth, or theoretical explanation. The result depends on sample size, measurement quality, model assumptions, test choice, and the interpretation of the null.
Hypothesis testing is therefore strongest when used as one part of a broader evidentiary frame. A responsible analysis usually reports effect size, uncertainty interval, design context, model diagnostics, robustness checks, and practical meaning. The test result should sharpen interpretation, not replace it.
P-values, statistical significance, and interpretive limits
Few statistical tools are more widely used, and more widely misused, than the p-value. A p-value is often treated as a bright line between discovery and non-discovery, but that interpretation is too crude. A p-value does not measure the probability that the studied hypothesis is true. It does not measure the size of an effect. It does not measure the practical importance of a result. It is not a substitute for design, measurement, uncertainty, or substantive judgment.
Thresholded significance language is especially dangerous when it encourages analysts to ignore effect size. A tiny effect can become statistically detectable in a large sample. A practically important effect can remain uncertain in a small or noisy sample. A result just below a threshold and a result just above it may be substantively similar, even if one is called “significant” and the other is not.
Good inference therefore treats p-values as evidence within context, not as verdicts. The question is not only whether the p-value crossed a conventional threshold. The question is what was estimated, how large it is, how uncertain it is, how plausible the assumptions are, and whether the result matters in the domain being studied.
Regression as modeling framework
Regression is one of the most widely used modeling frameworks because it provides a structured way to relate an outcome variable to one or more predictors while explicitly modeling residual variation. In practice, regression is not merely one technique among many. It is a general modeling language for estimation, comparison, adjustment, association analysis, and prediction.
The conceptual strength of regression lies in its dual role. It can summarize relationships descriptively, and it can also support inference about parameters under assumptions. A regression coefficient can estimate how an outcome changes with a predictor, conditional on the model structure. But that phrase—conditional on the model structure—is essential. Coefficients are not self-interpreting.
Regression is easy to misuse because it looks authoritative. Coefficients can be overread causally. Model fit can be confused with truth. Omitted structure can bias interpretation. Heteroskedasticity can distort uncertainty. Influential observations can shape estimates. Collinearity can make coefficients unstable. This is why regression belongs inside a broader inference discipline rather than standing alone as a recipe.
Assumptions, diagnostics, and model adequacy
No inference is stronger than the assumptions that support it. Statistical procedures typically rely on conditions involving sampling, independence, distributional form, functional structure, variance behavior, measurement quality, or model specification. When those assumptions fail, inferential output changes meaning.
Diagnostics are therefore essential. Residual patterns, influential observations, heteroskedasticity, nonlinearity, subgroup instability, multicollinearity, distributional mismatch, and measurement anomalies can all signal that a model is misrepresenting the process. Diagnostics are not optional cleanup steps after estimation. They are part of inference itself.
A mature workflow treats diagnostics as evidence. If residuals show structure, the model has missed something. If influential points drive the conclusion, the result may be fragile. If variance changes across the range of prediction, standard errors may be misleading. If subgroups behave differently, one aggregate model may obscure important heterogeneity. Model adequacy is not a checkbox. It is a continuing question.
Uncertainty, effect size, and practical meaning
One of the most important disciplines of statistical reasoning is the separation of statistical evidence from practical importance. A result may be statistically detectable and yet substantively trivial. Conversely, a practically important effect may remain uncertain in a small or noisy sample. Inference should not end with a test statistic or p-value. It should also consider effect size, uncertainty intervals, practical thresholds, domain context, and consequence.
Effect size asks how large the estimated relationship or difference is. Uncertainty asks how precisely it is estimated. Practical meaning asks whether the estimate matters for the decision, system, or population under discussion. These are different questions.
In public systems, sustainability, health, engineering, education, finance, and organizational analytics, practical meaning often matters more than thresholded significance. A statistically detectable result may not justify a policy change. An uncertain but potentially large effect may justify further study. Responsible inference keeps those distinctions visible.
Misuse, overinterpretation, and statistical humility
Statistical modeling is vulnerable to recurring failures: overfitting, uncritical thresholding, model misspecification, unexamined multiple comparisons, causal interpretation of associative structure, underreported uncertainty, and selective reporting of favorable results. These failures are not merely technical. They are interpretive failures.
Statistical humility matters because every model is limited. A fitted model is not the world. A significant result is not a discovery by itself. A narrow interval may still rest on fragile assumptions. A predictive relationship is not automatically causal. A large dataset can still be biased. A sophisticated model can still estimate the wrong quantity.
Good inference is therefore not only technically competent. It is proportionate in its claims. It says what the evidence supports, what remains uncertain, what assumptions matter, and what should not be concluded.
A mathematical lens for statistical modeling and inference
A common starting point is a sample drawn from a broader population or process:
X_1, X_2, \ldots, X_n
\]
Interpretation: The observed sample provides finite evidence about a broader population or data-generating process. Inference depends on how those observations were produced.
A point estimate summarizes a sample quantity:
\bar{X} = \frac{1}{n}\sum_{i=1}^{n}X_i
\]
Interpretation: The sample mean \(\bar{X}\) estimates a population mean, but different samples would generally produce different means.
A standard error summarizes the sampling variability of an estimator:
SE(\bar{X}) = \frac{s}{\sqrt{n}}
\]
Interpretation: The standard error measures how much the sample mean would tend to vary across repeated samples, assuming the sampling model is appropriate.
A confidence interval combines a point estimate with uncertainty:
\hat{\theta} \pm z_{\alpha/2}SE(\hat{\theta})
\]
Interpretation: A confidence interval expresses a range of plausible values for an unknown parameter \(\theta\), conditional on the method and assumptions used.
A linear regression model represents an outcome as a function of predictors plus error:
Y_i = \beta_0 + \beta_1X_i + \varepsilon_i
\]
Interpretation: The coefficient \(\beta_1\) represents the modeled association between \(X\) and \(Y\), while \(\varepsilon_i\) represents residual variation not explained by the model.
A hypothesis test statistic often compares an estimate to a null value relative to its uncertainty:
t = \frac{\hat{\theta} – \theta_0}{SE(\hat{\theta})}
\]
Interpretation: The test statistic measures how far the estimate is from the null value \(\theta_0\) in standard-error units. It does not measure practical importance by itself.
An inference-readiness score can combine estimate quality, uncertainty, diagnostics, robustness, and interpretive review:
I_m = w_EE_m + w_UU_m + w_DD_m + w_RR_m + w_GG_m
\]
Interpretation: Inference readiness \(I_m\) for model \(m\) can combine effect clarity \(E_m\), uncertainty reporting \(U_m\), diagnostics \(D_m\), robustness \(R_m\), and governance review \(G_m\).
The purpose of these equations is not to make inference mechanical. It is to make the logic explicit: what is being estimated, how uncertainty is quantified, what model structure is assumed, and what kind of claim the evidence can support.
Python Workflow: Statistical Modeling and Inference Scorecard
The following Python workflow demonstrates how an inference review can estimate group means, confidence intervals, mean differences, a simple regression coefficient, diagnostic scores, and inference-readiness records.
#!/usr/bin/env python3
"""
Python Workflow: Statistical Modeling and Inference Scorecard
This compact example treats inference as evidence infrastructure:
estimates, uncertainty, diagnostics, robustness, and interpretation.
"""
from __future__ import annotations
import math
import statistics
from dataclasses import dataclass
@dataclass
class Observation:
group: str
outcome: float
predictor_x: float
def mean(values: list[float]) -> float:
return sum(values) / len(values) if values else 0.0
def sample_sd(values: list[float]) -> float:
return statistics.stdev(values) if len(values) > 1 else 0.0
def confidence_interval_for_mean(values: list[float], z: float = 1.96) -> dict[str, float]:
estimate = mean(values)
standard_error = sample_sd(values) / math.sqrt(len(values))
return {
"mean": estimate,
"standard_error": standard_error,
"ci_low": estimate - z * standard_error,
"ci_high": estimate + z * standard_error,
"n": len(values),
}
def mean_difference(group_a: list[float], group_b: list[float]) -> dict[str, float]:
difference = mean(group_b) - mean(group_a)
standard_error = math.sqrt(
sample_sd(group_a) ** 2 / len(group_a) +
sample_sd(group_b) ** 2 / len(group_b)
)
return {
"contrast": "B_minus_A",
"mean_difference": difference,
"standard_error": standard_error,
"ci_low": difference - 1.96 * standard_error,
"ci_high": difference + 1.96 * standard_error,
}
def simple_linear_regression(x: list[float], y: list[float]) -> dict[str, float]:
x_bar = mean(x)
y_bar = mean(y)
sxx = sum((xi - x_bar) ** 2 for xi in x)
sxy = sum((xi - x_bar) * (yi - y_bar) for xi, yi in zip(x, y))
slope = sxy / sxx
intercept = y_bar - slope * x_bar
fitted = [intercept + slope * xi for xi in x]
residuals = [yi - fi for yi, fi in zip(y, fitted)]
rss = sum(residual ** 2 for residual in residuals)
sigma_squared = rss / max(len(x) - 2, 1)
slope_standard_error = math.sqrt(sigma_squared / sxx)
return {
"intercept": intercept,
"slope": slope,
"slope_standard_error": slope_standard_error,
"slope_ci_low": slope - 1.96 * slope_standard_error,
"slope_ci_high": slope + 1.96 * slope_standard_error,
"rmse": math.sqrt(rss / len(x)),
}
def inference_readiness_score(
effect_clarity: float,
uncertainty_reporting: float,
diagnostic_review: float,
robustness_review: float,
governance_review: float,
) -> float:
return round(
0.22 * effect_clarity
+ 0.22 * uncertainty_reporting
+ 0.22 * diagnostic_review
+ 0.18 * robustness_review
+ 0.16 * governance_review,
3,
)
def main() -> None:
observations = [
Observation("A", 12.4, 2.1),
Observation("A", 13.2, 2.5),
Observation("A", 11.8, 1.9),
Observation("A", 14.1, 2.8),
Observation("A", 12.9, 2.3),
Observation("B", 15.2, 3.2),
Observation("B", 16.1, 3.5),
Observation("B", 14.9, 3.1),
Observation("B", 15.7, 3.4),
Observation("B", 16.4, 3.8),
]
group_a = [obs.outcome for obs in observations if obs.group == "A"]
group_b = [obs.outcome for obs in observations if obs.group == "B"]
print({
"group_a": {
key: round(value, 3)
for key, value in confidence_interval_for_mean(group_a).items()
},
"group_b": {
key: round(value, 3)
for key, value in confidence_interval_for_mean(group_b).items()
},
})
print({
key: round(value, 3) if isinstance(value, float) else value
for key, value in mean_difference(group_a, group_b).items()
})
x = [obs.predictor_x for obs in observations]
y = [obs.outcome for obs in observations]
print({
key: round(value, 3)
for key, value in simple_linear_regression(x, y).items()
})
print({
"inference_readiness_score": inference_readiness_score(
effect_clarity=0.85,
uncertainty_reporting=0.90,
diagnostic_review=0.70,
robustness_review=0.65,
governance_review=0.80,
)
})
if __name__ == "__main__":
main()
This workflow separates statistical detection from inferential readiness. It does not only compute estimates. It asks whether uncertainty is visible, diagnostics are reviewed, robustness is considered, and the claim is proportionate to the evidence.
R Workflow: Estimation, Regression, Diagnostics, and Readiness Summary
The following R workflow summarizes group-level intervals, regression coefficients, diagnostic checks, inference claims, robustness records, and model status.
#!/usr/bin/env Rscript
# R Workflow: Estimation, Regression, Diagnostics,
# and Inference Readiness Summary
observations <- data.frame(
group_id = c(
"A", "A", "A", "A", "A",
"B", "B", "B", "B", "B",
"C", "C", "C", "C", "C"
),
outcome = c(
12.4, 13.2, 11.8, 14.1, 12.9,
15.2, 16.1, 14.9, 15.7, 16.4,
10.5, 10.9, 11.2, 10.1, 11.0
),
predictor_x = c(
2.1, 2.5, 1.9, 2.8, 2.3,
3.2, 3.5, 3.1, 3.4, 3.8,
1.4, 1.6, 1.7, 1.2, 1.5
),
predictor_z = c(
0, 1, 0, 1, 0,
1, 1, 0, 1, 0,
0, 0, 1, 0, 1
)
)
registry <- data.frame(
model_id = c("mod001", "mod002", "mod003", "mod004"),
model_family = c(
"two_sample_estimator",
"linear_regression",
"multiple_regression",
"null_hypothesis_test"
),
estimand = c("mean_difference", "slope", "adjusted_slope", "p_value_threshold"),
status = c("approved", "in_review", "in_review", "needs_revision"),
risk_level = c("medium", "medium", "medium", "medium"),
stringsAsFactors = FALSE
)
claims <- data.frame(
model_id = c("mod001", "mod002", "mod003", "mod004"),
claim_type = c(
"mean_difference",
"slope_estimate",
"adjusted_slope",
"p_value_threshold"
),
effect_size = c(2.78, 1.82, 1.46, 0.22),
standard_error = c(0.62, 0.31, 0.44, 0.11),
p_value = c(0.012, 0.004, 0.031, 0.049),
confidence_low = c(1.34, 1.14, 0.52, 0.01),
confidence_high = c(4.22, 2.50, 2.40, 0.43),
practical_threshold = c(1.00, 0.50, 0.50, 0.50),
claim_status = c("approved", "in_review", "in_review", "needs_revision"),
stringsAsFactors = FALSE
)
diagnostics <- data.frame(
model_id = c("mod001", "mod001", "mod002", "mod002", "mod003", "mod003", "mod004", "mod004"),
check_type = c(
"sample_size",
"independence",
"linearity",
"influential_observations",
"multicollinearity",
"heteroskedasticity",
"p_value_overreliance",
"assumption_documentation"
),
status = c("pass", "warn", "pass", "warn", "warn", "warn", "fail", "fail"),
severity = c("medium", "high", "high", "medium", "medium", "high", "critical", "critical"),
stringsAsFactors = FALSE
)
robustness <- data.frame(
model_id = c("mod001", "mod002", "mod003", "mod004"),
check_name = c(
"batch_adjusted_difference",
"leave_one_high_leverage_out",
"robust_standard_errors",
"practical_threshold_review"
),
status = c("pass", "watch", "watch", "fail"),
stringsAsFactors = FALSE
)
group_summary <- aggregate(
outcome ~ group_id,
data = observations,
FUN = function(x) c(
n = length(x),
mean = mean(x),
sd = sd(x),
se = sd(x) / sqrt(length(x))
)
)
group_summary <- do.call(data.frame, group_summary)
names(group_summary) <- c("group_id", "n", "mean", "sd", "standard_error")
group_summary$ci_low <- group_summary$mean - 1.96 * group_summary$standard_error
group_summary$ci_high <- group_summary$mean + 1.96 * group_summary$standard_error
fit <- lm(outcome ~ predictor_x + predictor_z, data = observations)
regression_summary <- data.frame(
term = rownames(summary(fit)$coefficients),
estimate = summary(fit)$coefficients[, 1],
standard_error = summary(fit)$coefficients[, 2],
t_value = summary(fit)$coefficients[, 3],
p_value = summary(fit)$coefficients[, 4],
row.names = NULL
)
diagnostic_summary <- aggregate(
model_id ~ check_type + status + severity,
data = diagnostics,
FUN = length
)
names(diagnostic_summary) <- c(
"check_type",
"status",
"severity",
"check_count"
)
claim_summary <- aggregate(
model_id ~ claim_type + claim_status,
data = claims,
FUN = length
)
names(claim_summary) <- c(
"claim_type",
"claim_status",
"claim_count"
)
robustness_summary <- aggregate(
model_id ~ check_name + status,
data = robustness,
FUN = length
)
names(robustness_summary) <- c(
"check_name",
"status",
"robustness_check_count"
)
model_summary <- aggregate(
model_id ~ model_family + estimand + status + risk_level,
data = registry,
FUN = length
)
names(model_summary) <- c(
"model_family",
"estimand",
"status",
"risk_level",
"model_count"
)
dir.create("outputs", showWarnings = FALSE, recursive = TRUE)
write.csv(group_summary, "outputs/group_summary_r.csv", row.names = FALSE)
write.csv(regression_summary, "outputs/regression_summary_r.csv", row.names = FALSE)
write.csv(diagnostic_summary, "outputs/diagnostic_summary_r.csv", row.names = FALSE)
write.csv(claim_summary, "outputs/claim_summary_r.csv", row.names = FALSE)
write.csv(robustness_summary, "outputs/robustness_summary_r.csv", row.names = FALSE)
write.csv(model_summary, "outputs/model_summary_r.csv", row.names = FALSE)
cat("Wrote group intervals, regression coefficients, diagnostics, claims, robustness, and model summaries.\n")
This workflow treats inference as an auditable evidence record. It does not only ask whether a p-value is below a threshold. It asks whether the estimate is meaningful, uncertainty is reported, assumptions are documented, diagnostics are reviewed, and robustness checks are preserved.
Inference in the analytical workflow
In a mature analytical workflow, statistical modeling and inference sit between exploration and decision. Exploration helps determine whether variables are interpretable, distributions stable enough, and subgroup patterns visible enough to justify formal modeling. Modeling then organizes relationships into an estimable structure. Inference quantifies uncertainty around what the model suggests. Diagnostics send the analyst back to exploration if assumptions fail.
This cyclical movement is a sign of rigor, not inefficiency. Good analysis often moves from description to modeling, from modeling to diagnostics, from diagnostics back to exploration, and from revised models toward more careful claims. Inference is not a single button pressed at the end of analysis. It is part of an iterative evidence-building process.
Inference also extends beyond one-off studies. In production analytics, organizations revisit assumptions, recalibrate estimates, compare historical and current distributions, and assess whether earlier inferential conclusions still hold under drift, redesign, or new data. Statistical inference is therefore part of ongoing evidentiary maintenance.
Governance and institutional accountability
Statistical claims should be governed because they often support institutional action. A model estimate may influence policy, staffing, budgeting, risk assessment, service delivery, product design, public communication, or scientific interpretation. If the model assumptions are weak, diagnostics ignored, p-values overinterpreted, or uncertainty underreported, the resulting decision can appear evidence-based while resting on fragile inference.
Governance does not mean bureaucracy for its own sake. It means preserving the evidentiary chain: data source, sampling logic, estimand, estimator, model assumptions, diagnostics, robustness checks, effect size, uncertainty interval, claim status, reviewer, and limitations. Later readers should be able to understand what was estimated, why the model was used, what uncertainty remains, and what the claim does not support.
This matters especially in high-impact domains. Statistical inference is not only a technical procedure. It is part of the moral and institutional responsibility to distinguish evidence from overclaim.
Applications across domains
Statistical modeling and inference appear across nearly every empirical domain. In science, they support estimation, uncertainty quantification, and hypothesis evaluation. In public policy, they support comparisons, trend interpretation, program assessment, and claims about population outcomes. In healthcare, they inform treatment-effect estimation, risk modeling, measurement validation, and evidence appraisal. In business, they support experimentation, demand estimation, customer analysis, and performance measurement.
Engineering uses statistical modeling for process control, reliability analysis, calibration, and design evaluation. Environmental systems use inference to estimate trends, compare regions, evaluate monitoring data, and quantify uncertainty in ecological and climate-related observations. Social research uses inference to interpret survey data, compare groups, and test theoretical expectations.
Across these domains, the underlying role is the same: to convert limited observations into disciplined claims while keeping uncertainty visible.
Implementation principles for high-integrity inference
Define the estimand before the estimator. Know what quantity is being estimated before choosing the model.
Separate description from inference. A descriptive pattern is not automatically a population claim.
Report effect size with uncertainty. Estimates should be accompanied by intervals or other uncertainty measures where appropriate.
Avoid p-value reductionism. Statistical significance is not practical importance, causal truth, or scientific meaning by itself.
Document assumptions. Sampling, independence, distributional, functional-form, and measurement assumptions should be visible.
Use diagnostics as evidence. Residuals, leverage, nonlinearity, heteroskedasticity, and subgroup instability affect interpretation.
Run robustness checks. Important claims should be checked under reasonable alternative specifications.
Distinguish association, prediction, and causation. Regression coefficients do not automatically identify causal effects.
Preserve inference records. Model versions, estimates, intervals, diagnostics, and reviewer decisions should remain traceable.
Interpret in context. Practical meaning depends on domain thresholds, consequences, and institutional judgment.
| Control | Purpose | Failure it prevents |
|---|---|---|
| Estimand definition | Names the quantity being estimated | Ambiguous model output with unclear meaning |
| Sampling and measurement review | Clarifies what the observed data represent | Unsupported generalization beyond the data |
| Effect size reporting | Shows the magnitude of the estimate | Overreliance on thresholded significance |
| Uncertainty interval | Communicates precision and sampling variability | False certainty from single-number reporting |
| Assumption documentation | Makes model conditions explicit | Hidden assumptions disguised as neutral computation |
| Diagnostic review | Checks model adequacy and residual structure | Inference from poorly specified models |
| Robustness checks | Tests sensitivity to reasonable alternatives | Overconfident claims from one fragile specification |
| Interpretation review | Separates statistical detection from practical meaning | Numerical results overstated as substantive conclusions |
GitHub Repository
This article can be paired with a companion code workflow that models statistical inference as evidence infrastructure. The example includes sample observations, statistical model registries, inference claims, diagnostic checks, robustness records, SQL schemas, Python and R workflows, Julia scoring, typed contracts, governance checklists, Quarto report templates, and multi-language examples across Python, R, Julia, SQL, Go, Rust, C, C++, TypeScript, and Terraform placeholders.
The companion repository provides a vendor-neutral statistical modeling and inference scaffold with sample summaries, confidence intervals, mean-difference estimation, regression estimates, diagnostic review, robustness checks, inference-readiness scoring, SQL governance queries, reproducible reporting templates, typed contracts, documentation, and CI smoke-test patterns.
Conclusion
Statistical modeling and inference are central to trustworthy analytics because they convert limited observations into qualified claims. They help analysts estimate quantities, compare groups, model relationships, test claims, quantify uncertainty, and decide how strongly evidence supports a conclusion. But their value depends on discipline. A model is a simplification. A p-value is not a verdict. An interval is not stronger than the assumptions behind it. A regression coefficient is not automatically causal.
The deeper point is that inference is a form of evidentiary responsibility. It asks analysts to state what is being estimated, how uncertainty is measured, which assumptions matter, which diagnostics were reviewed, and what should not be concluded. In data-intensive organizations, this is not only a statistical skill. It is part of the infrastructure of responsible evidence, institutional judgment, and honest analytical communication.
Related articles
- Data Systems and Analytics knowledge series
- Descriptive Analytics and Data Exploration
- Data Cleaning and Data Quality Management
- Experimental Design and Causal Inference
- Time Series Analysis and Forecasting
- Predictive Analytics and Machine Learning Models
- Model Training and Validation
- Model Evaluation and Performance Metrics
Further reading
- Freedman, D.A. (2009) Statistical Models: Theory and Practice. Revised edn. Cambridge: Cambridge University Press.
- Gelman, A., Hill, J. and Vehtari, A. (2020) Regression and Other Stories. Cambridge: Cambridge University Press.
- McElreath, R. (2020) Statistical Rethinking: A Bayesian Course with Examples in R and Stan. 2nd edn. Boca Raton: CRC Press.
- Wasserman, L. (2004) All of Statistics: A Concise Course in Statistical Inference. New York: Springer.
- OpenIntro (2024) OpenIntro Statistics. Available at: https://www.openintro.org/book/os/
- National Institute of Standards and Technology and SEMATECH (2012) e-Handbook of Statistical Methods. Available at: https://www.itl.nist.gov/div898/handbook/
References
- American Statistical Association (2016) ASA Statement on Statistical Significance and P-Values. Available at: https://www.amstat.org/asa/files/pdfs/p-valuestatement.pdf
- Gelman, A., Hill, J. and Vehtari, A. (2020) Regression and Other Stories. Cambridge: Cambridge University Press. Available at: https://avehtari.github.io/ROS-Examples/
- National Institute of Standards and Technology and SEMATECH (2012) e-Handbook of Statistical Methods. Available at: https://www.itl.nist.gov/div898/handbook/
- National Institute of Standards and Technology and SEMATECH (2012) Introduction to Process Modeling. Available at: https://www.itl.nist.gov/div898/handbook/pmd/section1/pmd1.htm
- National Institute of Standards and Technology and SEMATECH (2012) Graphical Techniques: Alphabetic. Available at: https://www.itl.nist.gov/div898/handbook/eda/section3/eda33.htm
- OpenIntro (2024) OpenIntro Statistics. Available at: https://www.openintro.org/book/os/
- OpenIntro (n.d.) Inference Guide. Available at: https://www.openintro.org/go/?id=ahss_inference_guide&referrer=%2Fstat%2Ftextbook.php
- Romeijn, J.-W. (2014) ‘Philosophy of Statistics’, The Stanford Encyclopedia of Philosophy. Available at: https://plato.stanford.edu/entries/statistics/
- Wasserstein, R.L. and Lazar, N.A. (2016) ‘The ASA Statement on p-Values: Context, Process, and Purpose’, The American Statistician, 70(2), pp. 129–133. Available at: https://www.tandfonline.com/doi/full/10.1080/00031305.2016.1154108
- Wasserman, L. (2004) All of Statistics: A Concise Course in Statistical Inference. New York: Springer. Available at: https://link.springer.com/book/10.1007/978-0-387-21736-9