
Last Updated May 11, 2026
Experimental design and causal inference are the disciplines through which analysts move from observing associations to making disciplined claims about what causes what. Descriptive analytics can summarize patterns, exploratory work can reveal structure, and statistical models can estimate relationships under uncertainty, but causal questions demand something stronger: an account of what would happen under intervention rather than merely what tends to vary together in the observed record. Experimental design is the classical answer because it structures comparison so that treated and untreated conditions are made comparable by design. Causal inference is the broader analytical field that asks how such comparisons can be justified, estimated, and interpreted, both in randomized experiments and in observational settings where random assignment is absent.
This topic matters because many of the highest-stakes analytical questions are causal rather than merely predictive. Did a policy reduce emissions? Did a treatment improve outcomes? Did a training intervention change behavior? Did a platform change increase retention, or did retention simply move with broader demand conditions? Answering such questions requires more than fitting a model to historical data. It requires a design logic capable of supporting the comparison between what happened and what would plausibly have happened otherwise. That is why design, identification, assumptions, validity, and bias control sit at the center of serious causal reasoning.
Main Library
Publications
Article Map
Data Systems & Analytics
Related Topic
Institutions & Governance
Related Topic
Risk & Resilience
Related Topic
Stewardship & Ethics
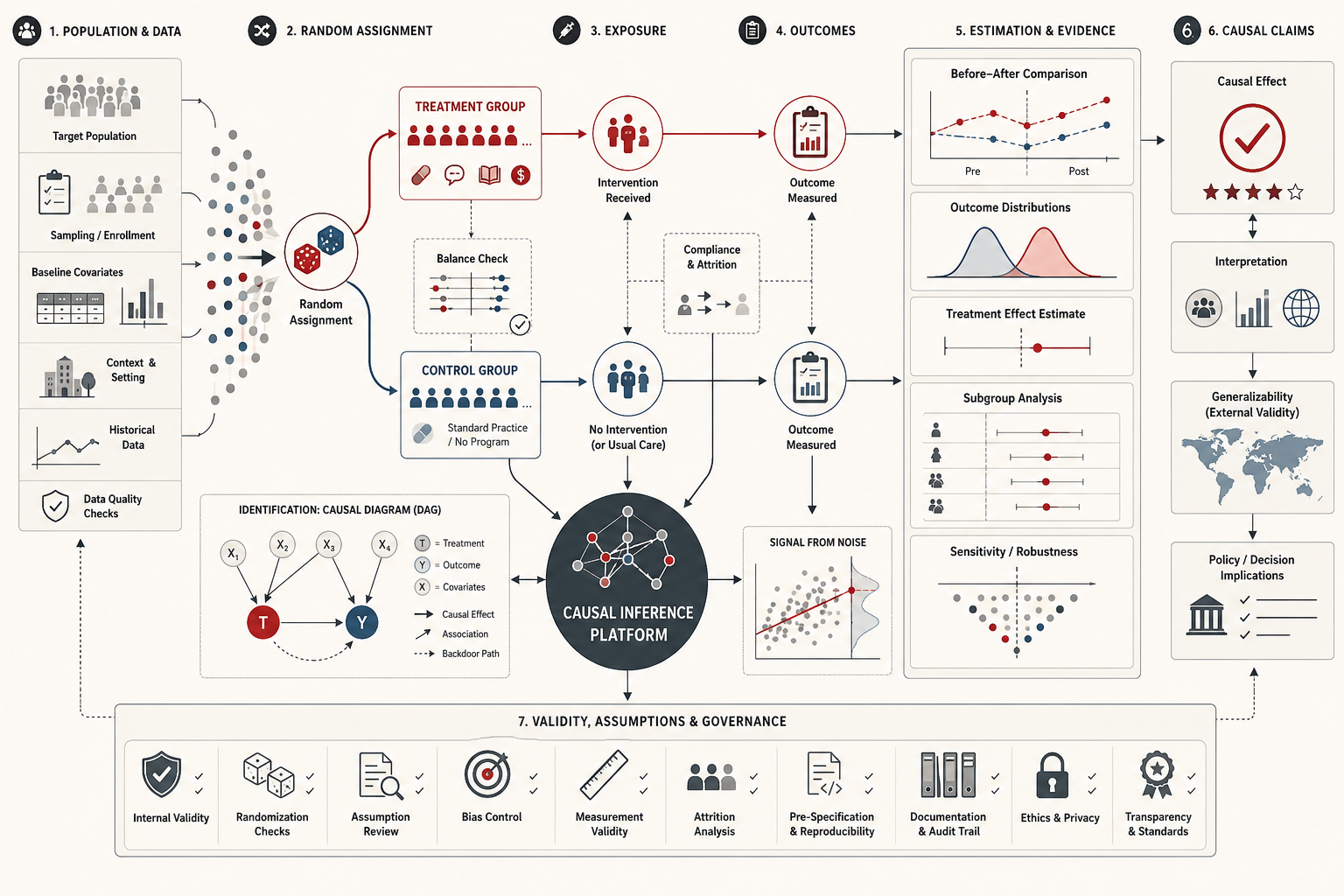
The modern statistical framework for causal inference is often organized around potential outcomes. In Holland’s classic formulation, causal effects are defined through contrasts between the outcomes that would be observed for the same unit under different treatment states, even though only one of those outcomes can actually be observed. That is the fundamental problem of causal inference: the counterfactual outcome is missing. Imbens and Rubin develop this framework more systematically, while Hernán and Robins extend it into a broader program for reasoning about causal questions in both experimental and observational data. This article should therefore be read alongside Descriptive Analytics and Data Exploration, Statistical Modeling and Inference, Time Series Analysis and Forecasting, Predictive Analytics and Machine Learning Models, Model Training and Validation, and Model Evaluation and Performance Metrics.
Causal claims as design-governed evidence
The strongest way to understand experimental design and causal inference is as design-governed evidence. Causal inference is not merely a more sophisticated form of regression. It is a discipline for asking whether an observed comparison can credibly stand in for an unobserved counterfactual comparison. Experimental design helps answer that question by structuring assignment, treatment, comparison, and measurement before estimation begins.
This distinction matters because causal language is easy to overuse. Analysts often say that one variable “drives,” “impacts,” “leads to,” “improves,” or “causes” another when the evidence supports only association. The problem is not vocabulary alone. Causal claims often support intervention, policy, investment, treatment, product change, operational reform, or public accountability. If the comparison is weak, the resulting action may be misguided even when the statistical model is technically competent.
A mature causal workflow therefore asks: what is the intervention, what is the comparison condition, what outcome is being measured, what unit is being analyzed, what time horizon matters, what estimand is being claimed, what design supports identification, what assumptions are required, and what validity threats remain? Causal inference begins with that structure, not with the estimator.
What experimental design and causal inference mean
Experimental design is the deliberate structuring of interventions, comparisons, assignments, and measurements so that causal effects can be estimated with minimal ambiguity. Causal inference is the broader discipline of reasoning from data to claims about the effects of interventions or exposures. Experimental design asks how evidence should be produced. Causal inference asks how causal claims can be justified from that evidence.
The connection between them is that design solves part of the inferential problem before analysis begins. If treatment assignment is randomized, many alternative explanations for differences in outcomes are weakened by construction. If assignment is not randomized, analysts must recover comparability through assumptions, adjustment strategies, or design emulation, and those strategies are usually more fragile than randomization itself. Hernán and Robins’ framework is especially useful because it insists on specifying the causal question first and then asking what design, actual or hypothetical, would identify it.
This is one reason causal inference should not be confused with “advanced regression.” Regression may be part of a causal analysis, but causal inference is fundamentally about the logic of comparison. The central question is not merely whether variables are associated after adjustment. It is whether the comparison being made can stand in for the missing counterfactual contrast that defines a causal effect.
The counterfactual logic of causation
The potential-outcomes framework formalizes causation through counterfactual comparison. For a given unit, one can define the outcome that would occur under treatment and the outcome that would occur under control. The causal effect for that unit is the difference between those two potential outcomes. Holland’s classic formulation explains the core problem immediately: for any unit, only one potential outcome is observed, because the same unit cannot simultaneously receive both treatment states.
This missing-data perspective is fundamental. Causal inference is difficult not because analysts are poor at summarizing observed data, but because the most important comparison is partly unobservable. The goal of design and identification is therefore to recover or approximate the missing counterfactual comparison in a justified way.
This is why causal claims are categorically different from predictive ones. Prediction asks what is likely to happen given observed covariates. Causation asks what would change under a different intervention. Those are related questions, but they are not interchangeable. A system can predict treatment uptake well without telling us what the treatment causes. It can predict default, disease, or dropout without telling us what would happen if the relevant exposure were altered.
Why experimental design matters
Experimental design matters because the quality of a causal claim depends heavily on the structure of comparison. Design choice depends on the objective of the study, the factors being studied, the source of variation, and the measurements needed to answer the question. That may sound operational, but it is epistemically central: the design determines which effects can be separated, which nuisance factors can be controlled, and how much ambiguity remains in the comparison.
A good design reduces the need for heroic analytic rescue later. If important nuisance variation is blocked, if assignment is randomized, if timing is structured carefully, and if outcomes are measured consistently, the causal question becomes easier to answer. If those protections are absent, analysis must carry much more of the burden, and the final claim is typically less secure.
Design is therefore not a procedural preamble to analysis. It is part of the evidence itself. The design determines whether a later estimate should be read as a credible causal contrast, a provisional observational comparison, or only an association that still lacks counterfactual justification.
Randomization, exchangeability, and bias reduction
Randomization is central because it breaks systematic links between treatment assignment and many other factors that could distort comparison. In the potential-outcomes framework, randomized assignment supports the idea that treated and untreated groups are comparable, on average, in both observed and unobserved respects before treatment is applied. That comparability is what makes differences in outcomes interpretable as causal effects rather than as mixtures of treatment and preexisting differences.
The key idea often described in causal inference is exchangeability: conditional on the design or assumptions, the outcomes observed under one treatment regime can stand in for the missing counterfactual outcomes under the other. Randomization is powerful because it supports this condition by design rather than merely hoping for it analytically.
Randomization does not solve every problem. Noncompliance, attrition, interference between units, and poor outcome measurement can still weaken interpretation. But it does address one of the hardest problems in causal reasoning: the possibility that treated and untreated units differed in systematic ways before the intervention ever occurred.
Blocking, factorial design, and nuisance control
Not all experimental rigor comes from simple randomization alone. Blocking is a way to isolate nuisance factors so that they do not obscure the effects of primary interest. Randomized block designs and blocked factorial designs help remove systematic variation due to machines, operators, batches, environments, regions, cohorts, or other known sources of noise by structuring assignment within more homogeneous groups.
This matters because causal design is rarely about one undifferentiated treatment applied to one undifferentiated population. Real settings often contain heterogeneity that would otherwise swamp the signal. Blocking, factorial structuring, and related design-of-experiments principles are therefore part of causal inference in practice, even when engineering, biomedical, social-science, and platform-experimentation literatures use slightly different vocabularies.
Factorial design is especially important because it allows analysts to estimate more than one intervention effect at once and to study interactions among factors. This is a powerful reminder that causal questions are often plural rather than singular. In many real systems, what matters is not just whether a treatment works in isolation, but whether its effect changes depending on context, dosage, environment, timing, population, or the presence of other interventions.
Treatment effects, estimands, and units of analysis
One of the most important questions in causal inference is: what effect, exactly, is being estimated for which units? The potential-outcomes framework makes this precise by treating causal estimands as summaries of unit-level treatment effects, such as an average treatment effect or an average treatment effect on the treated. Imbens and Rubin’s framework is especially influential here because it treats causal inference not merely as “did treatment work?” but as a problem of defining estimands carefully before choosing methods.
This precision matters because causal language becomes misleading when the unit of intervention, the population of interest, and the estimand are left vague. A platform-level intervention, a patient-level treatment, and a policy-level reform do not necessarily share the same unit structure or effect definition, even if they are all described loosely as “causal effects.”
It also matters because the same study can support different estimands with different policy meanings. The effect of offering a program is not necessarily the same as the effect of actually receiving it. The effect in a trial sample is not necessarily the same as the effect in a broader population. The effect for treated units is not necessarily the same as the effect for all eligible units. Serious causal work therefore begins by clarifying which contrast matters and for whom.
Identification and the conditions for causal claims
Identification refers to the conditions under which a causal effect can be learned from the observed data and assumptions. In randomized experiments, identification is often cleaner because treatment assignment is designed to be independent of potential outcomes. In observational studies, identification usually requires stronger assumptions about comparability, measurement, timing, and lack of unmeasured confounding.
This is where causal inference becomes conceptually demanding. A statistical association may be easy to estimate, but whether that association identifies a causal effect depends on assumptions that are not reducible to computation alone. Design and identification are therefore inseparable: one structures the comparison, the other explains why that structure supports a causal interpretation.
Identification also clarifies why causal disagreement persists even when analysts use similar datasets. The disagreement may not be about arithmetic. It may be about whether the underlying assumptions are credible enough for the observed contrast to represent the missing counterfactual one. A causal estimate without identification assumptions is not a causal claim; it is an association wearing causal language.
DAGs, backdoor, frontdoor, and structural causal logic
Causal diagrams and structural causal models help analysts express assumptions before estimating effects. A directed acyclic graph, or DAG, represents hypothesized causal relationships among variables. It can show common causes, mediators, colliders, treatment assignment pathways, outcome pathways, and variables that should or should not be adjusted for.
The backdoor criterion formalizes when adjustment for observed covariates can block noncausal paths between treatment and outcome. The practical lesson is that adjustment is not simply “control for everything.” Some variables clarify comparison; others distort it. Conditioning on a mediator can block part of the causal effect. Conditioning on a collider can open a spurious path. Conditioning on post-treatment variables can make the estimate uninterpretable.
The frontdoor criterion is less common in practice but conceptually important because it shows that effects may sometimes be identified through mediating pathways even when direct confounding between treatment and outcome exists, provided specific structural conditions are satisfied. These criteria remind analysts that causal inference depends on the structure of the data-generating process, not only on statistical adjustment.
Quasi-experiments and design-based causal strategies
Between fully randomized experiments and purely uncontrolled observational comparisons lies a broad family of quasi-experimental and design-based strategies. These include natural experiments, instrumental variables, regression discontinuity, difference-in-differences, interrupted time series, matching-based designs, and synthetic controls. Their common ambition is to recover some of the comparability of an experiment from institutional rules, thresholds, timing shocks, or carefully structured observational contrasts.
The important point is not that these methods magically turn observational data into randomized evidence. It is that they import design logic into observational settings. They ask whether some source of variation approximates random assignment, whether a discontinuity can isolate an intervention effect, whether pre/post comparisons can be made credible through suitable controls, or whether a counterfactual comparison unit can be constructed from untreated cases.
This is one of the strongest lessons of modern causal inference: causal credibility often comes less from the sophistication of the estimator than from the plausibility of the design logic. A simple estimator attached to a strong design is often more convincing than a complex estimator attached to a weak comparison.
Observational data and the challenge of confounding
When treatment is not randomized, groups may differ for reasons that also affect the outcome. This is the classic problem of confounding. Observational data can produce biased treatment-effect estimates when treatment choice is entangled with prognostic factors, especially when those factors vary over time.
Observational causal inference therefore often requires analysts to emulate the logic of a target trial: define eligibility, treatment strategies, follow-up, outcomes, and comparison structure as if an experiment had been run. That design mentality is one of the strongest lessons in modern causal inference. It moves the work away from naïve model fitting and toward explicit design emulation.
This does not eliminate fragility. Observational analyses remain vulnerable to unmeasured confounding, selection mechanisms, and misspecified adjustment strategies. But target-trial thinking raises the standard by forcing the analyst to say what intervention is being imagined, when treatment begins, which outcomes matter, and what kind of comparison would count as credible.
Validity, transportability, and intervention context
Even a well-identified causal effect within one study does not automatically generalize elsewhere. Internal validity concerns whether the study credibly estimates the causal effect for the units and setting under analysis. External validity concerns whether that effect transports to other populations, places, institutions, or times. The methodological literature treats this as a separate question, not a free bonus that comes with randomization.
This distinction matters because organizations often jump too quickly from “we estimated an effect here” to “the same intervention will work everywhere.” Serious causal work resists that leap unless the transport conditions are argued explicitly: are the populations comparable, are the implementation conditions similar, are the mechanisms stable, and are the relevant moderators of treatment effect understood?
In applied settings, this is often where the boundary between causal inference and decision science becomes visible. A study may identify an effect internally but still leave significant uncertainty about scale-up, replication, policy adaptation, or implementation elsewhere. Causal evidence should therefore travel with its assumptions, not as an orphaned effect size.
Selection bias, post-treatment bias, and other failure modes
Causal inference fails in recognizable ways. Selection bias arises when who enters treatment or the sample is related to outcomes in ways that distort comparison. Post-treatment bias arises when analysts control for variables that are themselves affected by treatment, thereby blocking part of the causal effect or opening misleading paths. Time-varying confounding can make matters even worse when covariates both influence future treatment and are influenced by past treatment.
Other familiar threats include measurement error in treatment timing, attrition that depends on both treatment and outcome, interference between units, poor adherence, and inappropriate conditioning on colliders. The practical lesson is that causal analysis is not rescued merely by adding more covariates to a model. Some controls clarify the comparison; others distort it. Design logic must come first.
This is also why causal work requires restraint. There are many situations in which the honest conclusion is not “the effect is zero” or “the effect is positive,” but rather “the comparison is still too compromised to support a confident causal claim.” Causal integrity includes the discipline to withhold causal language when the comparison cannot bear it.
A mathematical lens for causal inference
The potential-outcomes framework begins by defining the outcomes a unit would have under different treatment states:
Y_i(1), \quad Y_i(0)
\]
Interpretation: \(Y_i(1)\) is the potential outcome for unit \(i\) under treatment, and \(Y_i(0)\) is the potential outcome for the same unit under control. Only one of these is observed for any unit.
A unit-level causal effect is the difference between potential outcomes:
\tau_i = Y_i(1) – Y_i(0)
\]
Interpretation: The causal effect for unit \(i\) is defined by comparing what would happen under treatment with what would happen under control. The difficulty is that the counterfactual outcome is missing.
The average treatment effect summarizes those unit-level effects:
ATE = E[Y(1) – Y(0)]
\]
Interpretation: The average treatment effect asks what the average effect would be if all relevant units could be observed under both treatment and control.
The average treatment effect on the treated asks a different question:
ATT = E[Y(1) – Y(0) \mid T = 1]
\]
Interpretation: The ATT estimates the causal effect for units that actually received treatment. This can differ from the population-wide ATE when treatment effects are heterogeneous.
Randomized assignment supports causal identification by making treatment independent of potential outcomes:
T \perp \{Y(1), Y(0)\}
\]
Interpretation: Under randomized assignment, treatment status \(T\) is independent of potential outcomes, allowing treated and untreated groups to serve as credible counterfactual comparisons on average.
Difference-in-differences estimates a causal contrast by subtracting the change in a comparison group from the change in a treated group:
DiD = (\bar{Y}_{T,post} – \bar{Y}_{T,pre}) – (\bar{Y}_{C,post} – \bar{Y}_{C,pre})
\]
Interpretation: Difference-in-differences attributes the difference between treated and control changes to the intervention, under a parallel-trends assumption.
Inverse probability weighting uses estimated treatment probabilities to rebalance observed data:
\widehat{ATE}_{IPW} =
\frac{1}{n}\sum_{i=1}^{n}\left(\frac{T_iY_i}{e(X_i)} – \frac{(1-T_i)Y_i}{1-e(X_i)}\right)
\]
Interpretation: IPW reweights treated and control observations by their estimated propensity scores \(e(X_i)\). This requires measured confounders, positivity, and a credible treatment model.
A causal-readiness score can combine design strength, assumption status, estimation evidence, validity review, and governance posture:
C_s = w_DD_s + w_AA_s + w_EE_s + w_VV_s + w_GG_s
\]
Interpretation: Causal readiness \(C_s\) for study \(s\) can combine design strength \(D_s\), assumption credibility \(A_s\), estimation evidence \(E_s\), validity review \(V_s\), and governance review \(G_s\).
The purpose of these equations is not to pretend that causal inference is mechanical. It is to make causal claims explicit: what counterfactual is being estimated, what assumptions are required, and why the comparison is credible enough to support an intervention claim.
Python Workflow: Causal Design and Inference Scorecard
The following Python workflow demonstrates how a causal-evidence workflow can estimate simple treatment contrasts, inverse-probability weighting, difference-in-differences, regression-discontinuity local contrasts, and causal-readiness review scores.
#!/usr/bin/env python3
"""
Python Workflow: Causal Design and Inference Scorecard
This compact example treats causal analysis as evidence infrastructure:
intervention, comparison, estimand, design, assumptions, estimation, and review.
"""
from __future__ import annotations
from dataclasses import dataclass
@dataclass
class Unit:
treatment: int
outcome: float
propensity_score: float
def mean(values: list[float]) -> float:
return sum(values) / len(values) if values else 0.0
def difference_in_means(units: list[Unit]) -> dict[str, float]:
treated = [unit.outcome for unit in units if unit.treatment == 1]
control = [unit.outcome for unit in units if unit.treatment == 0]
return {
"treated_mean": mean(treated),
"control_mean": mean(control),
"difference_in_means": mean(treated) - mean(control),
}
def inverse_probability_weighted_ate(units: list[Unit]) -> float:
treated_weighted = []
control_weighted = []
for unit in units:
p = min(max(unit.propensity_score, 0.01), 0.99)
if unit.treatment == 1:
treated_weighted.append(unit.outcome / p)
else:
control_weighted.append(unit.outcome / (1 - p))
return mean(treated_weighted) - mean(control_weighted)
def difference_in_differences(
treated_pre: float,
treated_post: float,
control_pre: float,
control_post: float,
) -> float:
return (treated_post - treated_pre) - (control_post - control_pre)
def causal_readiness_score(
design_strength: float,
assumption_score: float,
estimation_score: float,
validity_review: float,
governance_review: float,
) -> float:
return round(
0.28 * design_strength
+ 0.26 * assumption_score
+ 0.20 * estimation_score
+ 0.14 * validity_review
+ 0.12 * governance_review,
3,
)
def main() -> None:
units = [
Unit(treatment=1, outcome=0, propensity_score=0.50),
Unit(treatment=0, outcome=1, propensity_score=0.50),
Unit(treatment=1, outcome=0, propensity_score=0.50),
Unit(treatment=0, outcome=1, propensity_score=0.50),
Unit(treatment=1, outcome=0, propensity_score=0.50),
Unit(treatment=0, outcome=1, propensity_score=0.50),
]
print(difference_in_means(units))
print({"ipw_ate": round(inverse_probability_weighted_ate(units), 3)})
print({
"difference_in_differences": difference_in_differences(
treated_pre=100,
treated_post=90,
control_pre=99,
control_post=98,
)
})
print({
"causal_readiness_score": causal_readiness_score(
design_strength=1.00,
assumption_score=0.80,
estimation_score=0.75,
validity_review=0.70,
governance_review=0.85,
)
})
if __name__ == "__main__":
main()
This workflow shows why causal inference should not be reduced to one fitted regression. The causal question, estimand, design, assumptions, and validity checks are part of the evidence. The estimate is meaningful only in relation to that structure.
R Workflow: Causal Study Registry, Design, Estimand, and Assumption Summary
The following R workflow summarizes causal study designs, estimands, simple treatment contrasts, difference-in-differences structure, regression-discontinuity local windows, and assumption-review status.
#!/usr/bin/env Rscript
# R Workflow: Causal Study Registry, Design, Estimand,
# and Assumption Summary
registry <- data.frame(
study_id = c("study001", "study002", "study003", "study004", "study005"),
design_type = c(
"randomized_experiment",
"regression_discontinuity",
"difference_in_differences",
"target_trial_emulation",
"observational_regression"
),
estimand = c("ATE", "LATE", "ATT", "ATE", "ATE"),
status = c("approved", "in_review", "in_review", "planned", "needs_revision"),
risk_level = c("medium", "medium", "high", "high", "medium"),
stringsAsFactors = FALSE
)
units <- data.frame(
study_id = c(rep("study001", 6), rep("study005", 6)),
treatment = c(1, 0, 1, 0, 1, 0, 1, 0, 1, 0, 1, 0),
outcome = c(0, 1, 0, 1, 0, 1, 1, 0, 1, 0, 0, 0),
propensity_score = c(0.50, 0.50, 0.50, 0.50, 0.50, 0.50, 0.72, 0.48, 0.68, 0.46, 0.61, 0.42)
)
did <- data.frame(
group = c("treated", "treated", "treated", "treated", "control", "control", "control", "control"),
post = c(0, 1, 0, 1, 0, 1, 0, 1),
outcome = c(102, 91, 98, 89, 101, 99, 97, 96)
)
rdd <- data.frame(
running_variable = c(47, 48, 49, 50, 51, 52, 53, 46),
cutoff = rep(50, 8),
treatment = c(0, 0, 0, 1, 1, 1, 1, 0),
outcome = c(0, 0, 1, 1, 1, 1, 1, 0)
)
checks <- data.frame(
assumption = c(
"random_assignment",
"sutva_no_interference",
"continuity_at_cutoff",
"parallel_trends",
"exchangeability",
"no_unmeasured_confounding",
"post_treatment_bias"
),
status = c("pass", "warn", "warn", "warn", "planned", "fail", "fail"),
severity = c("critical", "high", "critical", "critical", "critical", "critical", "high"),
stringsAsFactors = FALSE
)
design_summary <- aggregate(
study_id ~ design_type + estimand + status + risk_level,
data = registry,
FUN = length
)
names(design_summary) <- c(
"design_type",
"estimand",
"status",
"risk_level",
"study_count"
)
ate_summary <- aggregate(
outcome ~ study_id + treatment,
data = units,
FUN = mean
)
names(ate_summary) <- c("study_id", "treatment", "mean_outcome")
did_summary <- aggregate(
outcome ~ group + post,
data = did,
FUN = mean
)
treated_change <- with(
did_summary,
outcome[group == "treated" & post == 1] -
outcome[group == "treated" & post == 0]
)
control_change <- with(
did_summary,
outcome[group == "control" & post == 1] -
outcome[group == "control" & post == 0]
)
did_estimate <- data.frame(
treated_change = treated_change,
control_change = control_change,
difference_in_differences = treated_change - control_change
)
rdd_near <- rdd[abs(rdd$running_variable - rdd$cutoff) <= 2, ]
rdd_summary <- aggregate(
outcome ~ treatment,
data = rdd_near,
FUN = mean
)
assumption_summary <- aggregate(
assumption ~ status + severity,
data = checks,
FUN = length
)
names(assumption_summary) <- c("status", "severity", "check_count")
dir.create("outputs", showWarnings = FALSE, recursive = TRUE)
write.csv(design_summary, "outputs/design_summary_r.csv", row.names = FALSE)
write.csv(ate_summary, "outputs/ate_summary_r.csv", row.names = FALSE)
write.csv(did_estimate, "outputs/did_estimate_r.csv", row.names = FALSE)
write.csv(rdd_summary, "outputs/rdd_summary_r.csv", row.names = FALSE)
write.csv(assumption_summary, "outputs/assumption_summary_r.csv", row.names = FALSE)
cat("Wrote causal study, treatment contrast, DiD, RDD, and assumption summaries.\n")
This workflow treats causal analysis as an auditable design record. It does not only ask whether the treatment coefficient is positive or negative. It asks whether the study has a defined estimand, a credible design, documented assumptions, and enough validity review to justify causal language.
Causal reasoning in analytical workflow
In a mature analytical workflow, causal inference comes after descriptive understanding and exploratory scrutiny, but before strong policy or intervention claims are made. Analysts first need to understand data structure, subgroup patterns, timing, and quality. They then need to define the causal question clearly, specify the intervention and estimand, and determine what design or design emulation would make the comparison credible. Only then does formal estimation become meaningful.
This sequencing matters because causal reasoning is not just another modeling stage. It is a discipline of comparison design, counterfactual definition, and evidentiary restraint. The design question comes before the estimation question, and the interpretation question remains after both.
For a broader analytical architecture, this links causal inference directly to evidentiary discipline. Causal reasoning is where an institution decides whether it is merely describing patterns in observed data or whether it is prepared to make stronger claims about intervention and change.
Governance and institutional accountability
Causal claims should be governed because they often support action. A predictive score might prioritize attention, but a causal claim can justify changing policy, treatment, design, funding, platform behavior, or institutional practice. The difference is important. Claiming that an intervention caused an outcome gives decision-makers a reason to replicate, scale, stop, expand, or regulate that intervention.
Governance should therefore require causal claims to be linked to study design, estimand, identification strategy, assumption checks, robustness tests, sensitivity analyses, external-validity limits, and responsible interpretation. A report should not say merely “the model controls for covariates.” It should state why the comparison is credible, which assumptions are necessary, what threats remain, and what claims are not supported.
This is especially important in high-impact domains such as health, labor, education, public policy, environmental regulation, platform governance, and institutional accountability. In those settings, weak causal claims can legitimize harmful or ineffective interventions. Strong causal inference does not remove uncertainty, but it disciplines the way uncertainty is carried into decision-making.
Applications across domains
Experimental design and causal inference appear across many domains where intervention effects matter: clinical trials, policy evaluation, platform experimentation, program assessment, education, epidemiology, industrial process improvement, labor analysis, environmental regulation, social programs, and product analytics.
Across all these domains, the core question is the same: what would change under intervention, for whom, under what conditions, and how defensible is the answer to that counterfactual question? A clinical trial may ask whether treatment improves recovery. A policy study may ask whether a regulation reduced emissions. A platform experiment may ask whether a design change improved retention. A workforce program may ask whether training improved completion or advancement. In each case, the causal claim depends on comparison structure, not simply on observed association.
This is what makes causal inference one of the most important and demanding branches of modern data analysis. It sits at the boundary between evidence and action.
Implementation principles for high-integrity causal analysis
Start with a causal question. Name the intervention, comparison, outcome, unit, and time horizon before selecting a model.
Define the estimand before the estimator. Clarify whether the analysis targets ATE, ATT, LATE, CATE, ITT, TOT, or another causal quantity.
Prefer design strength over model complexity. A strong comparison with a simple estimator is often more credible than a weak comparison with a sophisticated model.
Protect temporal order. Treatment must precede outcome, and post-treatment variables should not be treated as ordinary controls.
State identification assumptions explicitly. Randomization, exchangeability, positivity, consistency, noninterference, continuity, exclusion restrictions, and parallel trends are assumptions, not implementation details.
Use diagrams where they clarify adjustment logic. DAGs can help distinguish confounders, mediators, colliders, and inappropriate controls.
Use quasi-experimental designs carefully. Difference-in-differences, regression discontinuity, instrumental variables, interrupted time series, and synthetic control designs depend on specific assumptions that require evidence.
Run robustness and sensitivity checks. Causal estimates should be examined under plausible alternative specifications, bandwidths, control groups, placebo tests, or sensitivity assumptions.
Separate prediction from causation. A model that predicts an outcome well does not necessarily identify the effect of changing an input.
Govern causal claims. High-impact causal claims should be attached to a study registry, assumptions, limitations, evidence review, and accountable interpretation.
| Control | Purpose | Failure it prevents |
|---|---|---|
| Causal question registry | Documents intervention, comparison, outcome, unit, and time horizon | Vague causal language without a defined contrast |
| Estimand definition | Names the causal quantity being estimated | Confusing ATE, ATT, ITT, LATE, or policy-relevant effects |
| Randomization or design logic | Explains why comparison groups are credible | Associations being mistaken for causal effects |
| Assumption review | States exchangeability, positivity, consistency, noninterference, or design-specific assumptions | Hidden assumptions disguised as model output |
| DAG or structural review | Clarifies confounders, mediators, colliders, and adjustment logic | Bad controls, post-treatment bias, and collider bias |
| Robustness and sensitivity checks | Tests whether conclusions depend on fragile modeling choices | Overconfident causal claims from one specification |
| External-validity review | Examines whether effects may transport to other populations or contexts | Assuming a local effect generalizes everywhere |
| Governance review | Connects causal claims to accountable institutional interpretation | Weak evidence being used to justify strong intervention claims |
GitHub Repository
This article can be paired with a companion code workflow that models causal inference as evidence infrastructure. The example includes causal study registries, experimental-unit data, difference-in-differences panels, regression-discontinuity examples, assumption checks, factorial design records, SQL schemas, Python and R workflows, Julia scoring, typed contracts, governance checklists, Quarto report templates, and multi-language examples across Python, R, Julia, SQL, Go, Rust, C, C++, TypeScript, and Terraform placeholders.
Conclusion
Experimental design and causal inference are central to trustworthy analytics because they discipline the movement from observed association to claims about intervention. They ask not merely whether variables move together, but whether a comparison can credibly answer what would have happened under an alternative treatment, policy, exposure, or institutional choice.
The deeper point is that causal inference is a design-governed form of evidence. Randomization, blocking, factorial design, estimand definition, identification assumptions, DAGs, quasi-experimental strategies, target-trial emulation, robustness checks, and validity review all exist to protect the counterfactual comparison from wishful interpretation. In data-intensive organizations, this is not only a statistical skill. It is a condition of responsible evidence, governance, and institutional decision-making.
Related articles
- Data Systems and Analytics knowledge series
- Descriptive Analytics and Data Exploration
- Statistical Modeling and Inference
- Time Series Analysis and Forecasting
- Predictive Analytics and Machine Learning Models
- Model Training and Validation
- Model Evaluation and Performance Metrics
- Reproducible Analytics and Versioned Data Workflows
Further reading
- Angrist, J.D. and Pischke, J.-S. (2009) Mostly Harmless Econometrics: An Empiricist’s Companion. Princeton, NJ: Princeton University Press.
- Hernán, M.A. and Robins, J.M. (2020) Causal Inference: What If. Boca Raton: Chapman & Hall/CRC.
- Imbens, G.W. and Rubin, D.B. (2015) Causal Inference for Statistics, Social, and Biomedical Sciences. Cambridge: Cambridge University Press.
- Morgan, S.L. and Winship, C. (2015) Counterfactuals and Causal Inference: Methods and Principles for Social Research. 2nd edn. Cambridge: Cambridge University Press.
- Montgomery, D.C. (2017) Design and Analysis of Experiments. 9th edn. Hoboken, NJ: Wiley.
- Pearl, J., Glymour, M. and Jewell, N.P. (2016) Causal Inference in Statistics: A Primer. Chichester: Wiley.
- Rosenbaum, P.R. (2017) Observation and Experiment: An Introduction to Causal Inference. Cambridge, MA: Harvard University Press.
- Shadish, W.R., Cook, T.D. and Campbell, D.T. (2002) Experimental and Quasi-Experimental Designs for Generalized Causal Inference. Boston: Houghton Mifflin.
References
- Angrist, J.D. and Pischke, J.-S. (2009) Mostly Harmless Econometrics: An Empiricist’s Companion. Princeton, NJ: Princeton University Press. Available at: https://press.princeton.edu/books/paperback/9780691120355/mostly-harmless-econometrics
- Hernán, M.A. and Robins, J.M. (2020) Causal Inference: What If. Boca Raton: Chapman & Hall/CRC. Available at: https://www.hsph.harvard.edu/miguel-hernan/causal-inference-book/
- Hernán, M.A., Brumback, B. and Robins, J.M. (2000) ‘Marginal structural models to estimate the causal effect of zidovudine on the survival of HIV-positive men’, Epidemiology, 11(5), pp. 561–570. Available at: https://cdn1.sph.harvard.edu/wp-content/uploads/sites/1268/2012/10/hernan_epid00.pdf
- Hitchcock, C. (2018) ‘Causal Models’, The Stanford Encyclopedia of Philosophy. Available at: https://plato.stanford.edu/entries/causal-models/
- Holland, P.W. (1986) ‘Statistics and causal inference’, Journal of the American Statistical Association, 81(396), pp. 945–960. Available at: https://www.jstor.org/stable/2289064
- Imbens, G.W. and Rubin, D.B. (2015) Causal Inference for Statistics, Social, and Biomedical Sciences. Cambridge: Cambridge University Press. Available at: https://www.cambridge.org/core/books/causal-inference-for-statistics-social-and-biomedical-sciences/71126BE90C58F1A431FE9B2DD07938AB
- National Institute of Standards and Technology and SEMATECH (n.d.) Choosing an Experimental Design. Available at: https://www.itl.nist.gov/div898/handbook/pri/section3/pri3.htm
- National Institute of Standards and Technology and SEMATECH (n.d.) Randomized Block Designs. Available at: https://www.itl.nist.gov/div898/handbook/pri/section3/pri332.htm
- National Institute of Standards and Technology and SEMATECH (n.d.) Blocking of Full Factorial Designs. Available at: https://www.itl.nist.gov/div898/handbook/pri/section3/pri3333.htm
- Pearl, J. (2009) Causality: Models, Reasoning, and Inference. 2nd edn. Cambridge: Cambridge University Press. Available at: https://www.cambridge.org/core/books/causality/4E6B0B5C8B1D1B51A4E6B0B8FBB74B47
- Rosenbaum, P.R. and Rubin, D.B. (1983) ‘The central role of the propensity score in observational studies for causal effects’, Biometrika, 70(1), pp. 41–55. Available at: https://doi.org/10.1093/biomet/70.1.41
- Woodward, J. (2001) ‘Causation and Manipulability’, The Stanford Encyclopedia of Philosophy. Available at: https://plato.stanford.edu/entries/causation-mani/