Distributed Data Systems: Replication, Partitioning, and Consistency
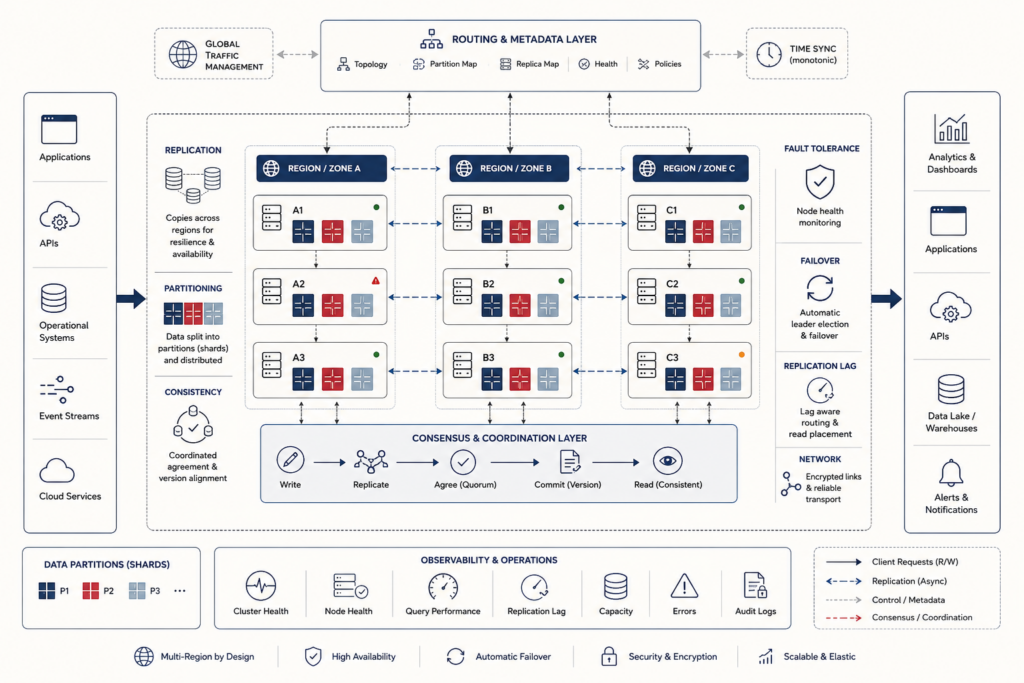
Distributed data systems preserve useful data behavior when storage, computation, and users no longer live in one place. This article frames distribution not as “bigger databases,” but as coordination under failure: the discipline of partitioning data, replicating state, routing requests, managing quorum reads and writes, handling replica lag, coordinating leaders, resolving conflicts, and recovering after partial failure. It explains why scale, availability, geographic locality, and resilience force systems beyond centralized architecture, while also creating tradeoffs among consistency, latency, durability, and availability. The article also examines CAP, quorum policies, distributed transactions, consensus, conflict resolution, CP/AP/mixed architectures, failover, observability, and auditability. Mathematical examples and Python/R workflows show how teams can evaluate shard routing, replication health, quorum intersection, replica lag, operation health, conflict resolution, consensus events, failover drills, and distributed-system readiness scores.