
Last Updated May 11, 2026
Streaming data and real-time analytics transform data systems from periodic reporting infrastructures into continuously updating environments of observation, interpretation, and response. In batch-oriented architectures, data is collected over an interval, transformed on a schedule, and analyzed after the fact. In streaming architectures, data is processed as events arrive, often with the expectation that the system can detect patterns, update metrics, trigger actions, or surface anomalies with minimal delay. This does not mean that every streaming system operates at millisecond latency or that all real-time analytics is equally immediate. It means that the architecture is organized around continual data arrival, incremental computation, and the temporal significance of events.
This topic matters because many contemporary systems no longer operate comfortably on yesterday’s state. Financial fraud detection, industrial telemetry, network operations, customer behavior monitoring, logistics visibility, application observability, and digital platform analytics all depend on the ability to interpret ongoing streams of events rather than waiting for nightly refresh cycles. The shift is not simply toward faster reporting. It is toward data architectures built around persistent event motion, event-time reasoning, stateful computation, replayable histories, and decision windows in which latency changes the value of information.
Main Library
Publications
Article Map
Data Systems & Analytics
Related Topic
Data Pipelines
Related Topic
Distributed Data Systems
Related Topic
Intelligent Infrastructure Systems
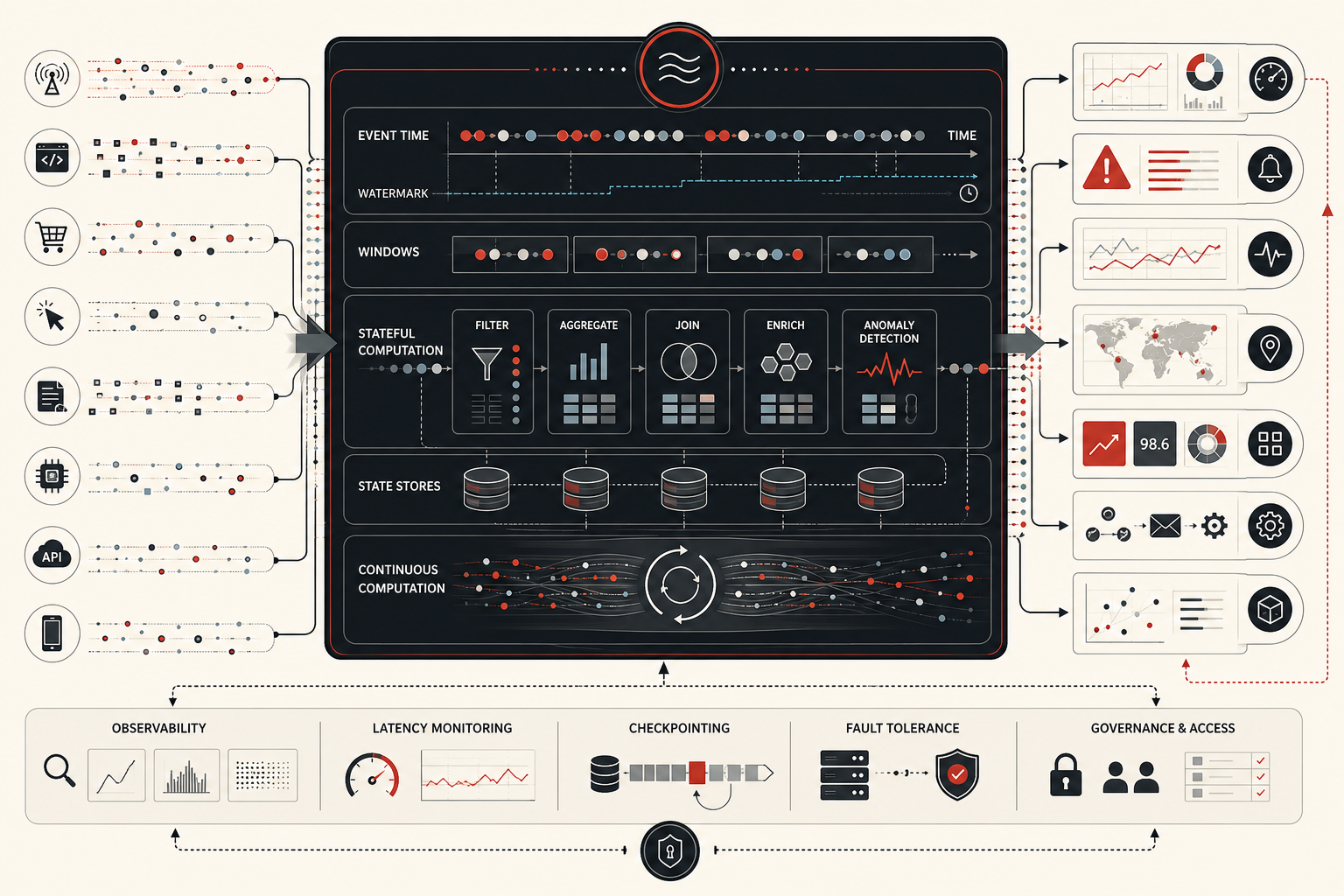
Streaming analytics also changes how time itself is handled in data systems. In batch environments, time is often implicit in schedules, partitions, and report refresh cycles. In stream processing, time becomes a first-class modeling problem. Systems must distinguish when an event happened from when it was observed by the processor, handle out-of-order arrival, decide how long to wait for late data, and determine when a partial result is sufficiently complete to publish. The Google Dataflow model is especially important because it frames unbounded data processing as a problem of balancing correctness, latency, and cost rather than pretending that all relevant data arrives neatly, completely, and in order.
This article should therefore be read alongside Data Pipelines and Data Processing Systems, Distributed Data Systems, ETL and Data Transformation Systems, Cloud Data Platforms and Modern Data Stack Architecture, Data Quality Metrics and Observability, Metadata, Data Catalogs, and Lineage, and Reproducible Analytics and Versioned Data Workflows. Streaming analytics is where data pipelines, distributed processing, temporal modeling, observability, and governance converge under live operational pressure.
Streaming as temporal evidence in motion
The strongest way to understand streaming data and real-time analytics is as temporal evidence in motion. A batch dataset is bounded. It has a start, an end, and a moment at which analysis can be performed on a relatively settled collection of records. A stream is different. It is a continuing sequence of events, often unbounded, often out of order, and often meaningful precisely because the state of the world is still changing.
This changes the analytical posture. A streaming system does not merely ask what happened last week, yesterday, or at the end of a reporting period. It asks what is happening now, what has changed since the last event, whether a pattern is emerging, whether state should be updated, and whether action is still possible. The unit of analysis becomes temporal, incremental, and operational.
That also means streaming analytics produces a different kind of evidence. A stream output may be early, provisional, late-adjusted, revised, replayed, or final. Trustworthy streaming systems therefore require more than low latency. They require explicit timestamp semantics, windowing logic, lateness policy, state recovery, replayability, delivery guarantees, and governance over what a continuously updated result actually means.
What streaming data and real-time analytics mean
Streaming data refers to data that arrives as a continuing sequence of events rather than as one fixed, bounded dataset. These events may come from applications, sensors, databases, logs, mobile devices, financial transactions, user interactions, industrial equipment, or operational systems. A real-time analytics system is one that computes, updates, or delivers analytical results with low enough latency to matter during the interval in which conditions are still changing and action is still possible.
The key architectural point is continuous ingestion and incremental interpretation. A stream-processing system does not wait for the complete dataset before beginning computation. Instead, it updates state as events arrive, maintaining rolling aggregates, keyed counters, session states, anomaly detectors, pattern rules, or continuously refreshed serving views. This makes streaming analytics different from ordinary dashboarding. The question is not whether a chart refreshes quickly. The question is whether the system is built to interpret events continuously enough that timing affects meaning.
Real-time analytics is therefore a socio-technical capability, not only a speed target. It requires technical systems for event transport, state management, processing, storage, and monitoring, but it also requires institutional decisions about when a result is timely enough, how much lateness is tolerated, which alerts are actionable, and who is responsible when a continuously updated metric changes.
Why streaming architectures matter
Streaming architectures matter because some domains lose value when interpretation is delayed. Fraud detection requires rapid recognition of suspicious patterns. Infrastructure monitoring depends on identifying anomalies before failure cascades. Customer alerting systems must often react while the customer can still respond. Operational telemetry, digital advertising, algorithmic risk controls, and application observability all depend on the ability to process event sequences as they evolve rather than after they settle into historical batches.
Streaming also matters because it changes the relationship between data and action. Batch systems often support retrospective understanding. Streaming systems often support ongoing intervention. This is not only a difference of speed. It is a difference of institutional posture. A system designed for real-time analytics is one in which data participates in live coordination, not simply post hoc explanation.
This shift creates responsibility. A slow report may mislead after the fact; a live stream can trigger action while uncertainty remains. That means the architecture must make clear whether outputs are provisional or final, whether late events can revise results, whether alerts are based on event time or processing time, and whether the system can be reconstructed after a failure or dispute.
Event streams as a data model
One of the most important conceptual shifts in modern streaming systems is the treatment of data as an event stream. Instead of thinking primarily in terms of tables that periodically change, the stream model treats data as a sequence of immutable events recording that something happened at a particular time. An event may represent a payment, click, device reading, order update, login attempt, shipment movement, sensor threshold crossing, or application error.
This matters because an event stream is not just a transport format. It is a way of organizing knowledge about change. Event streams preserve temporal sequence, permit replay, and allow multiple downstream consumers to derive different interpretations from the same underlying event history. A fraud detector, operational dashboard, customer-facing notification system, warehouse sink, and machine-learning feature pipeline may all consume the same event stream for different purposes.
Seen this way, streams are not merely fast-moving versions of tables. They are often the historical substrate from which tables, dashboards, alerts, models, and materialized views can be continuously derived. That makes streaming architecture directly relevant to auditable, reconstructable analytics. If the event log is durable, well-typed, and replayable, the organization can act in real time while preserving the possibility of later explanation.
What “real time” actually means
Real-time analytics is often used imprecisely. In practice, it refers to a family of latency expectations rather than one universal threshold. Some systems require sub-second reaction. Others are effectively real time if they update within seconds or minutes. The decisive question is whether the latency is small enough relative to the use case that the result remains actionable while the relevant state of the world is still unfolding.
This means “real time” is contextual rather than absolute. A compliance dashboard refreshed every five minutes may be operationally real time in one setting and uselessly delayed in another. A sensor alerting pipeline may need second-level responsiveness, while a logistics visibility system may remain effective with longer windows. A fraud intervention may need immediate scoring, while a public-health monitoring stream may tolerate slower review if the signal is more stable and action is less instantaneous.
The architectural challenge is therefore not to minimize latency at all costs. It is to design for the latency envelope required by the consequence structure of the domain. Real time is not simply fast. It is timely enough for the decision being supported.
Batch, micro-batch, and continuous streaming
Streaming systems are best understood against the background of batch processing. Batch systems operate over bounded datasets and often favor reproducibility, high throughput, periodic recomputation, and cost-efficient processing. Streaming systems operate over unbounded or continually growing event sequences and favor incremental updates, stateful computation, and low-latency outputs.
Between these poles sits micro-batch processing, in which events are accumulated over short intervals and processed as small recurring batches. Micro-batch systems can be effective for many analytical problems because they provide near-real-time results while retaining some of the operational simplicity of batch processing. Continuous stream processing usually gives finer-grained latency and richer event-time semantics, but it can also introduce more state-management and correctness complexity.
The real distinction is not simply “old batch versus new streaming.” The deeper distinction is whether the system can process unbounded data with the temporal primitives needed for correctness and with latency, cost, and operational guarantees appropriate to the use case. In many mature architectures, batch and streaming coexist: batch recomputes historical truth, while streaming updates current state and alerts.
Event time, processing time, and temporal correctness
Streaming analytics becomes difficult because events do not necessarily arrive in the order in which they happened. Event time refers to the time an event actually occurred. Processing time refers to the system time at which the processor observes the event. This distinction matters because a fast but temporally naive system may produce analytically incorrect results if it treats arrival order as truth when records are delayed, reordered, retried, or replayed.
A payment may happen before a risk signal but arrive after it. A sensor reading may be delayed because of network congestion. A mobile device may upload stored events after reconnecting. A database change event may be replayed after recovery. If processing time is mistaken for event time, windowed aggregates, alerts, and session states may be wrong even though the system is technically fast.
Serious stream-processing architectures therefore reason about temporal correctness, not just rapid display. They define which timestamp is authoritative, how late data is handled, whether late events revise prior results, and whether users can distinguish early output from final output. This is one of the defining differences between casual live dashboards and high-integrity streaming analytics.
Windows, watermarks, triggers, and refinements
Because unbounded streams do not naturally end, stream processors often rely on windows to create manageable intervals of interpretation. A window may represent one minute of events, one session of user activity, one hour of telemetry, or another domain-specific interval. Tumbling windows are fixed, non-overlapping intervals. Sliding windows overlap. Session windows are driven by periods of activity and inactivity.
Watermarks help the system estimate how far event time has advanced despite out-of-order arrival. They allow the system to reason about whether most events for a time interval have probably arrived. Triggers determine when results are emitted: once, repeatedly, early, at watermark time, or after later refinement. These concepts are not implementation decoration. They determine what a result means.
The trio of windows, watermarks, and triggers embodies one of the deepest truths of streaming analytics: real-time results are often provisional, and correctness is a managed relationship between latency and completeness. Early output may be valuable precisely because it is early. Later output may be more correct because it incorporates late events. A mature system makes this refinement process explicit rather than hiding it behind a single changing number.
Stateful stream processing and derived views
Modern stream processors are powerful because they are not limited to stateless per-event transformations. Stateful stream processing retains information across events: rolling counts, partial aggregates, keyed totals, session state, fraud patterns, device baselines, recent history, join buffers, or alert thresholds. Without state, many real-time analytics tasks collapse into simple forwarding or filtering rather than sustained interpretation.
Statefulness is what makes streaming analytics genuinely analytical. A real-time fraud detector must remember recent behavior for an account. A telemetry platform must maintain baselines and rolling windows. A customer analytics system may need session state or continuously updated entity views. An operations platform may need to compare current readings against recent history and expected patterns.
Stateful processing also connects directly to continuously maintained materialized views. Instead of recomputing a result from scratch, the stream processor updates derived state as new events arrive. In this sense, streaming systems begin to resemble continuously updating databases. They maintain current representations of a changing world by applying event histories to stateful logic.
Logs, replay, and reconstructable state
One of the most powerful implications of stream architecture is that a persistent event log can function as a replayable history of change. A durable log is not only a transport medium. It is a source from which downstream state can be derived and re-derived. If business logic changes, a stream can be replayed to regenerate derived views. If a consumer fails, it can rebuild state from earlier offsets or checkpoints. If a new analytical view is needed, it may be derived from the same underlying event history.
Replay changes the meaning of real-time analytics. A streaming system is not merely a fast calculator. It can also be a reconstructable historical processor. That matters for auditability, debugging, lineage, incident response, and reproducibility. It means real-time action and later reconstruction can exist in the same architecture when event logs, schemas, retention policies, offsets, checkpoints, and transformation versions are governed carefully.
This is where streaming analytics connects deeply to reproducible analytics. Batch systems often rerun from stored datasets. Streaming systems can rerun from durable event logs. The architectural question becomes whether the stream is retained long enough, documented well enough, and processed deterministically enough to reconstruct meaningful state.
Delivery semantics and exactly-once claims
Streaming systems often describe delivery guarantees using terms such as at-most-once, at-least-once, and exactly-once. At-most-once systems may lose events but avoid duplicates. At-least-once systems avoid loss but may produce duplicates. Exactly-once systems aim to produce results as though each event affected state once, even in the presence of retries, failures, and recovery.
Architecturally, the important point is that “exactly once” is rarely a simple binary property of the entire pipeline. It depends on how event transport, offsets, checkpointing, state recovery, idempotent writes, transactions, and output sinks interact. A stream processor may maintain internal state correctly while a downstream database, notification system, or external API still produces duplicates. Conversely, idempotent sink design can make at-least-once delivery practically acceptable for some use cases.
Real-time analytical trust therefore depends less on slogans and more on explicit end-to-end semantics. What happens if an event is retried? Can a downstream write be repeated safely? Are alerts deduplicated? Are late corrections retracted or appended? Are users told whether a result is provisional? These questions determine whether a streaming output is merely fast or actually trustworthy.
Stream joins, materialization, and serving layers
Streaming analytics becomes significantly more powerful when systems can join streams to streams, streams to tables, or streams to reference state. These joins allow enriched event interpretation: a telemetry event may be joined with device metadata, a transaction with risk attributes, a user event with session state, or an operational signal with current inventory. In practice, this often requires maintaining keyed state and careful time semantics so relationships remain meaningful even when data arrives asynchronously.
The result of streaming computation is often not just an alert or transient calculation. It is a materialized serving layer: continuously updated aggregates, dashboards, operational tables, search indexes, feature stores, or other views that downstream systems treat as current state. In this architecture, stream processors incrementally maintain derived representations from a change log.
This matters because real-time analytics is not only about immediate outputs. It is also about continuously updated institutional representations. A serving table may become the source of operational decisions, customer-facing experiences, risk controls, or automated workflows. That gives stream-materialized views the same governance importance as more traditional warehouse tables, but under greater temporal pressure.
Latency, cost, and correctness tradeoffs
Streaming systems are often justified by speed, but speed alone is not the right optimization target. The more mature framing is a tradeoff among latency, cost, and correctness. A system can emit results early, but early results may need later revision. It can wait longer for completeness, but that increases latency. It can maintain large amounts of state and perform sophisticated temporal reasoning, but that raises resource cost and operational complexity.
This means real-time analytics is always a design tradeoff. The right architecture depends on how much lateness can be tolerated, what kinds of revisions are acceptable, how expensive missed events are, how costly false alerts are, and whether the use case values immediate response over complete accuracy or vice versa. A security alert, energy-grid signal, financial transaction risk score, and public dashboard may each require a different latency/correctness balance.
The most mature systems make these tradeoffs explicit. They do not hide behind the rhetoric of “instant insight.” They state what is early, what is final, how late data changes results, how cost grows with state and latency requirements, and what level of temporal incompleteness the domain can tolerate.
Streaming platforms and architectural patterns
Streaming ecosystems typically combine event transport with stream processing. Event streaming platforms provide durable topics, producers, consumers, partitioning, replication, retention, and APIs for publishing and subscribing to event histories. Stream-processing engines add event-time logic, stateful computation, windows, watermarks, fault tolerance, recovery, and output materialization.
In a typical architecture, producers publish events to topics. Stream processors consume events, apply transformations, maintain state, emit alerts, and update serving views. Warehouses, lakehouses, monitoring systems, feature stores, dashboards, and operational applications may consume either raw events or derived outputs. Some systems also feed historical storage for batch recomputation, compliance retention, or long-term analysis.
Modern data estates often combine streaming with batch recomputation, warehouse publication, and replay-based reconstruction. Streaming should therefore not be imagined as a total replacement for other processing modes. It is better understood as one temporal layer within a broader architecture: the layer that helps the data system respond while the world is still changing.
Observability, governance, and analytical trust
Streaming systems are operationally demanding because outputs are continuously changing and correctness may depend on subtle temporal assumptions. Teams need visibility into throughput, lag, watermark progress, late-event rates, state size, checkpoint success, backpressure, error rates, duplicate events, output revisions, and downstream sink behavior. Without observability, streaming systems can fail silently while still appearing live.
Governance matters here for the same reason it matters in batch analytics, but with greater temporal pressure. Institutions need to know what an event means, which timestamp is authoritative, how windows are defined, what lateness is tolerated, how state is recovered after failure, whether results are refinable or final, and whether replay can reconstruct the output. Real-time analytics is not trustworthy just because it is fast. It becomes trustworthy when timing, state, revision, replay, and delivery semantics are explicit enough to be audited and defended.
This is the deeper institutional implication of streaming architecture: it creates continuously updated truth claims. Those claims are valuable only when the system preserves enough semantic and temporal discipline for people to understand what the claims actually mean.
A mathematical lens for streaming analytics
An event stream can be represented as an ordered or partially ordered sequence of events:
S = \{e_1, e_2, \ldots, e_t, \ldots\}
\]
Interpretation: A stream \(S\) is a continuing sequence of events. Unlike a bounded dataset, the stream may not have a natural endpoint.
Each event may carry both event time and processing time:
e_i = (k_i, v_i, \tau_i, p_i)
\]
Interpretation: Event \(e_i\) has a key \(k_i\), value \(v_i\), event time \(\tau_i\), and processing time \(p_i\). The distinction between \(\tau_i\) and \(p_i\) is central to temporal correctness.
Event lateness can be measured as processing time minus event time:
L_i = p_i – \tau_i
\]
Interpretation: Lateness \(L_i\) measures how long after occurrence the processor observes the event. Large lateness affects windows, watermarks, alerts, and completeness.
A tumbling event-time window aggregate can be written as:
A_w = \sum_{i:\tau_i \in [w, w+\Delta)} v_i
\]
Interpretation: Window aggregate \(A_w\) sums event values whose event times fall inside a window beginning at \(w\) with width \(\Delta\).
A watermark can be treated as an estimate of event-time progress:
W(p) = \max(\tau_i \mid p_i \le p) – \lambda
\]
Interpretation: A simple watermark at processing time \(p\) can be represented as the largest observed event time minus an allowed-lateness margin \(\lambda\). Real systems use more sophisticated policies, but the principle is progress estimation under out-of-order arrival.
Stateful stream processing updates keyed state incrementally:
\sigma_k^{(t)} = f(\sigma_k^{(t-1)}, e_t)
\]
Interpretation: The state \(\sigma_k\) for key \(k\) evolves as events arrive. Fraud scores, counters, sessions, rolling aggregates, and serving views all depend on state update logic.
A streaming-readiness score can combine event-time discipline, lateness policy, state recovery, replayability, delivery semantics, and observability:
R_s = w_TT_s + w_LL_s + w_SS_s + w_PP_s + w_DD_s + w_OO_s
\]
Interpretation: Streaming readiness \(R_s\) for system \(s\) can combine timestamp discipline \(T_s\), lateness policy \(L_s\), state recovery \(S_s\), replayability \(P_s\), delivery semantics \(D_s\), and observability \(O_s\).
The purpose of this mathematical lens is not to make streaming analytics mechanical. It is to make the temporal logic visible: events happen at one time, arrive at another, enter windows under lateness policy, update state, and produce outputs whose meaning depends on the system’s treatment of time.
Python Workflow: Streaming Analytics and Event-Time Scorecard
The following Python workflow demonstrates how a streaming analytics review can evaluate event-time lateness, one-minute event-time windows, keyed state, watermark lag, alert records, governance checks, and streaming-readiness scoring.
#!/usr/bin/env python3
"""
Python Workflow: Streaming Analytics and Event-Time Scorecard
This compact example treats streaming analytics as temporal evidence:
event time, processing time, lateness, windows, state, alerts, and governance.
"""
from __future__ import annotations
from collections import defaultdict
from dataclasses import dataclass
from datetime import datetime, timezone
@dataclass
class Event:
event_id: str
event_key: str
event_type: str
event_time: str
processing_time: str
value: float
quality_score: float
def parse_ts(value: str) -> datetime:
return datetime.fromisoformat(value.replace("Z", "+00:00"))
def lateness_seconds(event: Event) -> float:
return max(
0.0,
(parse_ts(event.processing_time) - parse_ts(event.event_time)).total_seconds()
)
def window_start(event_time: datetime, size_seconds: int) -> datetime:
epoch = int(event_time.timestamp())
start = epoch - (epoch % size_seconds)
return datetime.fromtimestamp(start, tz=timezone.utc)
def mean(values: list[float]) -> float:
return sum(values) / len(values) if values else 0.0
def streaming_readiness_score(
timestamp_discipline: float,
lateness_policy: float,
state_recovery: float,
replayability: float,
delivery_semantics: float,
observability: float,
) -> float:
return round(
0.18 * timestamp_discipline
+ 0.18 * lateness_policy
+ 0.18 * state_recovery
+ 0.16 * replayability
+ 0.15 * delivery_semantics
+ 0.15 * observability,
3,
)
def main() -> None:
events = [
Event("evt001", "user-001", "click", "2026-05-01T10:00:02Z", "2026-05-01T10:00:05Z", 1.0, 0.98),
Event("evt002", "user-002", "purchase", "2026-05-01T10:00:21Z", "2026-05-01T10:00:25Z", 42.5, 0.96),
Event("evt003", "device-001", "sensor_reading", "2026-05-01T10:01:24Z", "2026-05-01T10:02:01Z", 190.0, 0.52),
Event("evt004", "user-004", "purchase", "2026-05-01T10:02:41Z", "2026-05-01T10:03:20Z", 12.0, 0.90),
Event("evt005", "device-001", "sensor_reading", "2026-05-01T10:03:45Z", "2026-05-01T10:04:55Z", 210.0, 0.48),
]
lateness = [lateness_seconds(event) for event in events]
print({
"event_count": len(events),
"mean_lateness_seconds": round(mean(lateness), 3),
"max_lateness_seconds": round(max(lateness), 3),
"late_event_rate_over_30s": round(sum(1 for x in lateness if x > 30) / len(lateness), 3),
})
windows: dict[str, list[Event]] = defaultdict(list)
for event in events:
start = window_start(parse_ts(event.event_time), 60)
windows[start.isoformat().replace("+00:00", "Z")].append(event)
window_summary = {}
for start, rows in windows.items():
window_summary[start] = {
"event_count": len(rows),
"value_sum": round(sum(event.value for event in rows), 3),
"purchase_value_sum": round(sum(event.value for event in rows if event.event_type == "purchase"), 3),
"sensor_mean": round(mean([event.value for event in rows if event.event_type == "sensor_reading"]), 3),
}
print({"event_time_windows": window_summary})
keyed_state = defaultdict(lambda: {"events": 0, "purchase_value": 0.0})
for event in sorted(events, key=lambda item: item.processing_time):
keyed_state[event.event_key]["events"] += 1
if event.event_type == "purchase":
keyed_state[event.event_key]["purchase_value"] += event.value
print({"keyed_state": dict(keyed_state)})
alerts = []
for event in events:
if event.event_type == "sensor_reading" and event.value > 150:
alerts.append({
"event_id": event.event_id,
"event_key": event.event_key,
"rule": "high_sensor_reading",
"severity": "high",
"value": event.value,
})
if event.quality_score < 0.70:
alerts.append({
"event_id": event.event_id,
"event_key": event.event_key,
"rule": "low_quality_event",
"severity": "high",
"quality_score": event.quality_score,
})
print({"alerts": alerts})
print({
"streaming_readiness_score": streaming_readiness_score(
timestamp_discipline=1.00,
lateness_policy=0.75,
state_recovery=0.70,
replayability=0.85,
delivery_semantics=0.70,
observability=0.80,
)
})
if __name__ == "__main__":
main()
This workflow treats streaming analytics as an evidence record, not merely a live counter. It evaluates how events move through time, how late they arrive, how they enter windows, how keyed state changes, when alerts fire, and how governance affects trust in continuously updated outputs.
R Workflow: Event-Time Lateness, Window Summaries, Watermark Lag, and Governance
The following R workflow summarizes event-time lateness, event-time window metrics, watermark lag, topic readiness, window policies, and governance checks.
#!/usr/bin/env Rscript
# R Workflow: Event-Time Lateness, Window Summaries,
# Watermark Lag, and Streaming Governance
events <- data.frame(
event_id = c("evt001", "evt002", "evt003", "evt004", "evt005"),
event_key = c("user-001", "user-002", "device-001", "user-004", "device-001"),
event_type = c("click", "purchase", "sensor_reading", "purchase", "sensor_reading"),
event_time = c(
"2026-05-01T10:00:02Z",
"2026-05-01T10:00:21Z",
"2026-05-01T10:01:24Z",
"2026-05-01T10:02:41Z",
"2026-05-01T10:03:45Z"
),
processing_time = c(
"2026-05-01T10:00:05Z",
"2026-05-01T10:00:25Z",
"2026-05-01T10:02:01Z",
"2026-05-01T10:03:20Z",
"2026-05-01T10:04:55Z"
),
value = c(1.0, 42.5, 190.0, 12.0, 210.0),
quality_score = c(0.98, 0.96, 0.52, 0.90, 0.48),
stringsAsFactors = FALSE
)
watermarks <- data.frame(
processing_time = c(
"2026-05-01T10:01:00Z",
"2026-05-01T10:02:00Z",
"2026-05-01T10:03:00Z",
"2026-05-01T10:04:00Z",
"2026-05-01T10:05:00Z"
),
watermark_time = c(
"2026-05-01T10:00:15Z",
"2026-05-01T10:01:14Z",
"2026-05-01T10:02:11Z",
"2026-05-01T10:03:03Z",
"2026-05-01T10:04:15Z"
),
late_event_count = c(0, 1, 1, 0, 2),
state_size_mb = c(12.5, 14.8, 18.2, 21.7, 29.4),
backpressure_ms = c(8, 15, 25, 30, 75),
status = c("pass", "watch", "watch", "pass", "warn"),
stringsAsFactors = FALSE
)
governance <- data.frame(
check_type = c(
"event_timestamp_authority",
"processing_time_recorded",
"late_event_policy",
"replayability",
"state_recovery",
"exactly_once_claims",
"provisional_output_labeling",
"backpressure_monitoring"
),
status = c("pass", "pass", "warn", "pass", "in_review", "warn", "warn", "warn"),
severity = c("critical", "high", "high", "high", "critical", "critical", "medium", "medium"),
stringsAsFactors = FALSE
)
events$event_time_posix <- as.POSIXct(
events$event_time,
format = "%Y-%m-%dT%H:%M:%SZ",
tz = "UTC"
)
events$processing_time_posix <- as.POSIXct(
events$processing_time,
format = "%Y-%m-%dT%H:%M:%SZ",
tz = "UTC"
)
events$lateness_seconds <- as.numeric(
difftime(events$processing_time_posix, events$event_time_posix, units = "secs")
)
events$window_start <- as.POSIXct(
floor(as.numeric(events$event_time_posix) / 60) * 60,
origin = "1970-01-01",
tz = "UTC"
)
window_summary <- aggregate(
value ~ window_start + event_type,
data = events,
FUN = function(x) c(n = length(x), mean = mean(x), sum = sum(x))
)
window_summary <- do.call(data.frame, window_summary)
lateness_summary <- aggregate(
lateness_seconds ~ event_type,
data = events,
FUN = function(x) c(n = length(x), mean = mean(x), max = max(x))
)
lateness_summary <- do.call(data.frame, lateness_summary)
watermarks$processing_time_posix <- as.POSIXct(
watermarks$processing_time,
format = "%Y-%m-%dT%H:%M:%SZ",
tz = "UTC"
)
watermarks$watermark_time_posix <- as.POSIXct(
watermarks$watermark_time,
format = "%Y-%m-%dT%H:%M:%SZ",
tz = "UTC"
)
watermarks$watermark_lag_seconds <- as.numeric(
difftime(watermarks$processing_time_posix, watermarks$watermark_time_posix, units = "secs")
)
watermark_summary <- aggregate(
cbind(late_event_count, state_size_mb, backpressure_ms, watermark_lag_seconds) ~ status,
data = watermarks,
FUN = mean
)
alert_summary <- subset(
events,
(event_type == "sensor_reading" & value > 150) | quality_score < 0.70
)
governance_summary <- aggregate(
check_type ~ status + severity,
data = governance,
FUN = length
)
names(governance_summary) <- c(
"status",
"severity",
"check_count"
)
dir.create("outputs", showWarnings = FALSE, recursive = TRUE)
write.csv(window_summary, "outputs/window_summary_r.csv", row.names = FALSE)
write.csv(lateness_summary, "outputs/lateness_summary_r.csv", row.names = FALSE)
write.csv(watermark_summary, "outputs/watermark_summary_r.csv", row.names = FALSE)
write.csv(alert_summary, "outputs/alert_summary_r.csv", row.names = FALSE)
write.csv(governance_summary, "outputs/governance_summary_r.csv", row.names = FALSE)
cat("Wrote streaming window, lateness, watermark, alert, and governance summaries.\n")
This workflow treats real-time analytics as a temporal-governance problem. It does not only count events. It asks how late events arrived, how event-time windows behave, whether watermark lag is growing, whether alert rules are triggered, and where governance review is still needed.
Applications across domains
Streaming data and real-time analytics appear across many domains, but the reason for their use is consistent: the value of information depends on speed of interpretation relative to changing conditions. Financial services use streaming for transaction monitoring, fraud scoring, risk controls, and market signals. Industrial and infrastructure systems use streaming for telemetry, anomaly detection, predictive maintenance, and failure prevention. Digital platforms use streaming for user behavior monitoring, personalization, ranking signals, experiment monitoring, and operational observability.
Logistics and mobility systems use streaming for location updates, shipment visibility, vehicle telemetry, route conditions, and event-triggered coordination. Environmental monitoring systems can use streaming architectures for sensor feeds, hazard alerts, water levels, air-quality signals, or infrastructure stress. Public systems may use event streams for emergency response, service demand, cyber monitoring, or operational dashboards.
Across all these settings, the central architectural question is the same: how to maintain an analytically meaningful view of a world that is still unfolding. Streaming systems are one modern answer to that problem, provided that temporal semantics, state, replay, observability, and governance are strong enough to make the outputs trustworthy.
Implementation principles for high-integrity streaming analytics
Define event semantics clearly. Each event should have a documented meaning, key, schema, timestamp, and source.
Distinguish event time from processing time. Arrival order should not be treated as occurrence order unless the system explicitly justifies that choice.
Document window logic. Window type, size, slide, session gap, allowed lateness, trigger policy, and output mode should be visible.
Label provisional and final outputs. Early results, late refinements, and finalized results should not be indistinguishable to downstream users.
Preserve durable event logs. Retention and replay policies should support reconstruction, debugging, and audit needs.
Make state recoverable. Checkpointing, restoration, state size, and failure behavior should be operationally tested.
State delivery semantics end to end. At-most-once, at-least-once, and exactly-once claims should be evaluated across the whole pipeline, including sinks.
Monitor streaming health. Throughput, lag, watermark progress, late events, state size, backpressure, failures, and duplicate behavior should be observable.
Connect latency to decision value. The target latency should reflect the action window and consequence structure of the domain.
Govern alerts and serving views. Real-time outputs should have owners, thresholds, review processes, and escalation policies.
| Control | Purpose | Failure it prevents |
|---|---|---|
| Event schema registry | Defines event fields, keys, types, timestamps, and source meaning | Ambiguous event interpretation across consumers |
| Event-time policy | Identifies authoritative occurrence time | Processing-time artifacts being mistaken for real-world timing |
| Window and lateness policy | Controls how unbounded streams are sliced and revised | Incomplete or inconsistent aggregates from late events |
| Watermark monitoring | Tracks event-time progress and late-data behavior | Silent temporal drift in supposedly live metrics |
| State recovery controls | Ensures stateful processors can recover after failure | Lost or corrupted rolling aggregates, sessions, and counters |
| Replayable event log | Supports reconstruction and reprocessing | Inability to audit, debug, or rebuild derived views |
| Delivery semantics review | Clarifies duplicate, loss, retry, and sink behavior | Misleading exactly-once claims or duplicate-triggered actions |
| Streaming observability | Monitors lag, throughput, backpressure, errors, state, and alerts | Live systems failing silently while appearing current |
GitHub Repository
This article can be paired with a companion code workflow that models streaming analytics as temporal evidence infrastructure. The example includes event streams, topic registries, window definitions, watermark observations, alert rules, governance checks, event-time lateness summaries, windowed aggregates, keyed state, SQL schemas, Python and R workflows, Julia scoring, typed contracts, Quarto report templates, and multi-language examples across Python, R, Julia, SQL, Go, Rust, C, C++, TypeScript, and Terraform placeholders.
The companion repository provides a vendor-neutral streaming data and real-time analytics scaffold with event logs, event-time and processing-time examples, lateness profiles, event-time windows, watermark-lag summaries, stateful keyed aggregates, alert records, stream-topic readiness scoring, SQL governance queries, reproducible reporting templates, typed contracts, documentation, and CI smoke-test patterns.
Conclusion
Streaming data and real-time analytics transform data systems by making ongoing events available for continuous interpretation. They support fast response, live monitoring, operational coordination, anomaly detection, and continuously updated views of changing conditions. But their value does not come from speed alone. It comes from the disciplined handling of time, state, replay, refinement, delivery semantics, and governance.
The deeper point is that streaming systems create temporal truth claims while the world is still unfolding. Those claims may be early, provisional, refined, late-adjusted, or final. High-integrity streaming architecture therefore asks not only how quickly data moves, but what each event means, which time matters, how late data is handled, whether state can be reconstructed, and whether real-time outputs are trustworthy enough to support action. In mature data systems, streaming analytics is not a replacement for batch analytics. It is the temporal layer that allows institutions to observe, interpret, and respond while events are still in motion.
Related articles
- Data Systems and Analytics knowledge series
- Data Pipelines and Data Processing Systems
- Distributed Data Systems
- ETL and Data Transformation Systems
- Cloud Data Platforms and Modern Data Stack Architecture
- Data Quality Metrics and Observability
- Metadata, Data Catalogs, and Lineage
- Reproducible Analytics and Versioned Data Workflows
Further reading
- Akidau, T., Chernyak, S. and Lax, R. (2018) Streaming Systems. Sebastopol, CA: O’Reilly Media.
- Carbone, P., Katsifodimos, A., Ewen, S., Markl, V., Haridi, S. and Tzoumas, K. (2015) ‘Apache Flink: Stream and Batch Processing in a Single Engine’, IEEE Data Engineering Bulletin, 36(4), pp. 28–38.
- Kleppmann, M. (2017) Designing Data-Intensive Applications. Sebastopol, CA: O’Reilly Media.
- Kreps, J. and Kleppmann, M. (2015) ‘Kafka, Samza and the Unix Philosophy of Distributed Data’, IEEE Data Engineering Bulletin, 38(4), pp. 4–14.
- Reis, J. and Housley, M. (2022) Fundamentals of Data Engineering. Sebastopol, CA: O’Reilly Media.
- Stonebraker, M., Çetintemel, U. and Zdonik, S. (2005) ‘The 8 Requirements of Real-Time Stream Processing’, SIGMOD Record, 34(4), pp. 42–47.
References
- Akidau, T. et al. (2013) MillWheel: Fault-Tolerant Stream Processing at Internet Scale. Available at: https://research.google.com/pubs/archive/41378.pdf
- Akidau, T. et al. (2015) The Dataflow Model: A Practical Approach to Balancing Correctness, Latency, and Cost in Massive-Scale, Unbounded, Out-of-Order Data Processing. Available at: https://research.google.com/pubs/archive/43864.pdf
- Apache Flink (n.d.) Stateful Stream Processing. Available at: https://nightlies.apache.org/flink/flink-docs-stable/docs/concepts/stateful-stream-processing/
- Apache Flink (n.d.) Timely Stream Processing. Available at: https://nightlies.apache.org/flink/flink-docs-stable/docs/concepts/time/
- Apache Flink (n.d.) Windows. Available at: https://nightlies.apache.org/flink/flink-docs-stable/docs/dev/datastream/operators/windows/
- Apache Kafka (2026) Introduction. Available at: https://kafka.apache.org/intro/
- Apache Kafka (2026) Documentation. Available at: https://kafka.apache.org/documentation/
- Apache Kafka (2026) Kafka Streams. Available at: https://kafka.apache.org/documentation/streams/
- Kleppmann, M. (2016) Making Sense of Stream Processing. Available at: https://martin.kleppmann.com/2016/05/24/making-sense-of-stream-processing.html
- Kleppmann, M. (2016) Making Sense of Stream Processing. PDF. Available at: https://martin.kleppmann.com/papers/stream-processing.pdf