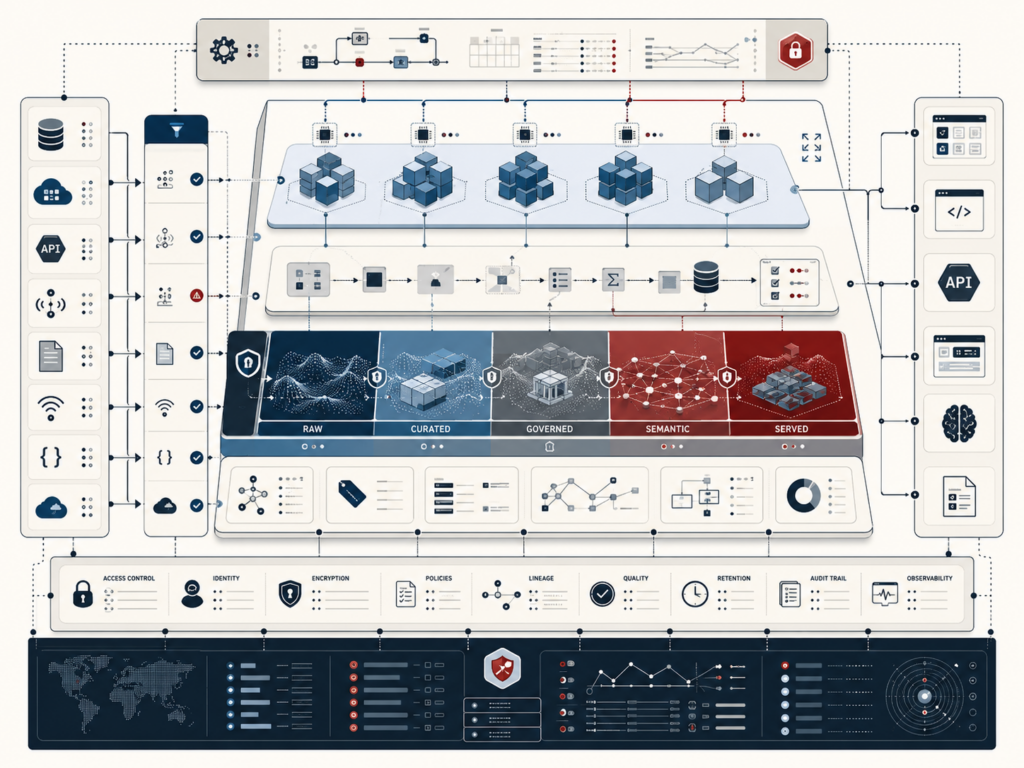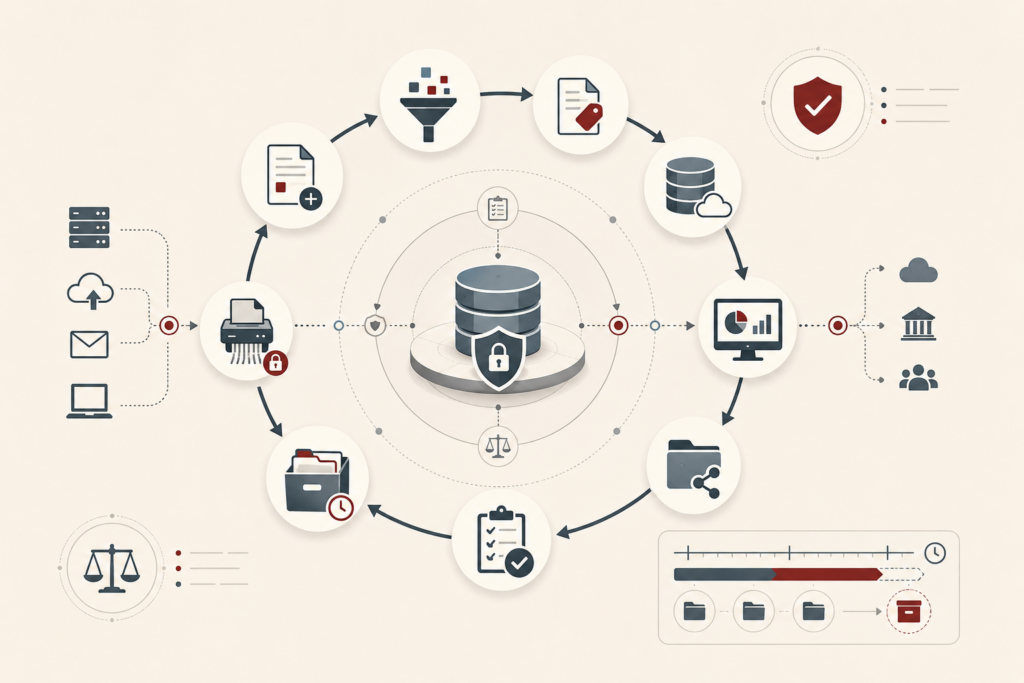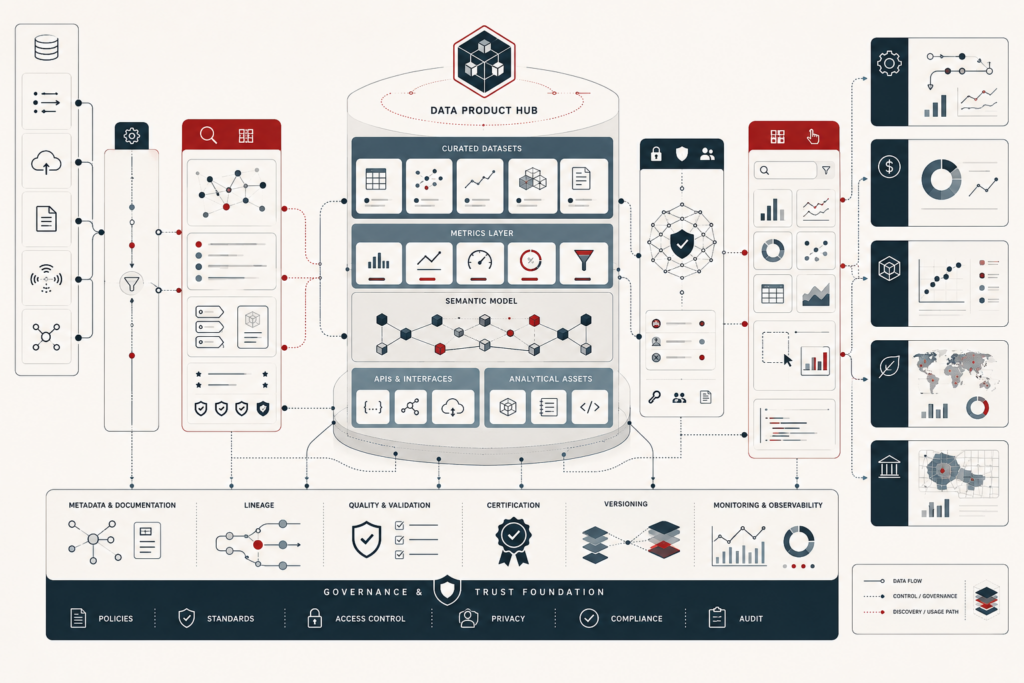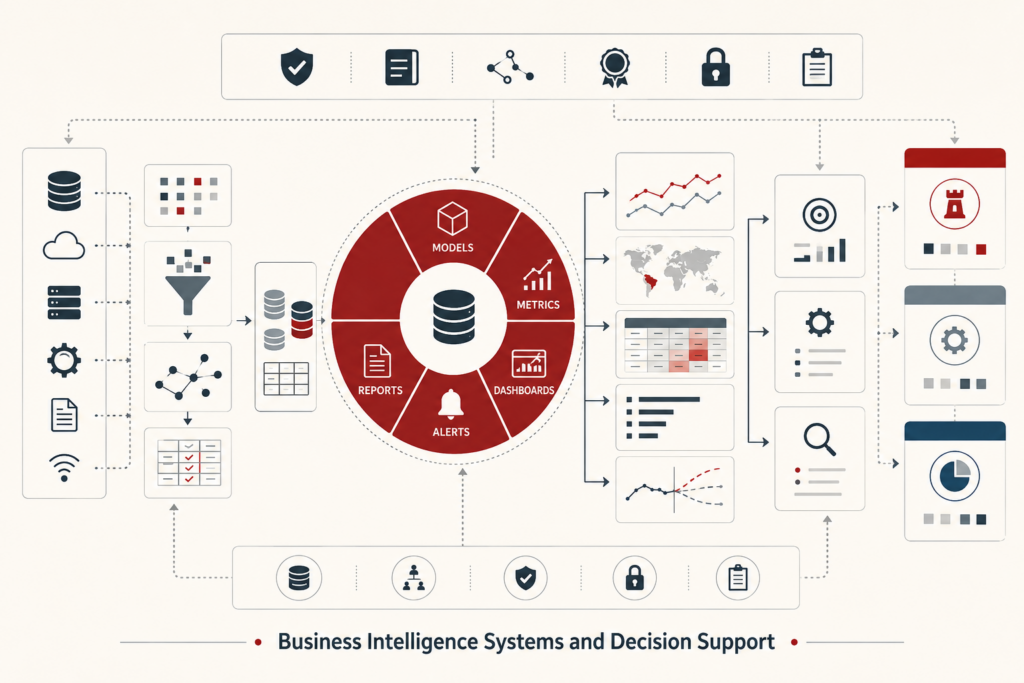
Reproducible Analytics and Versioned Data Workflows
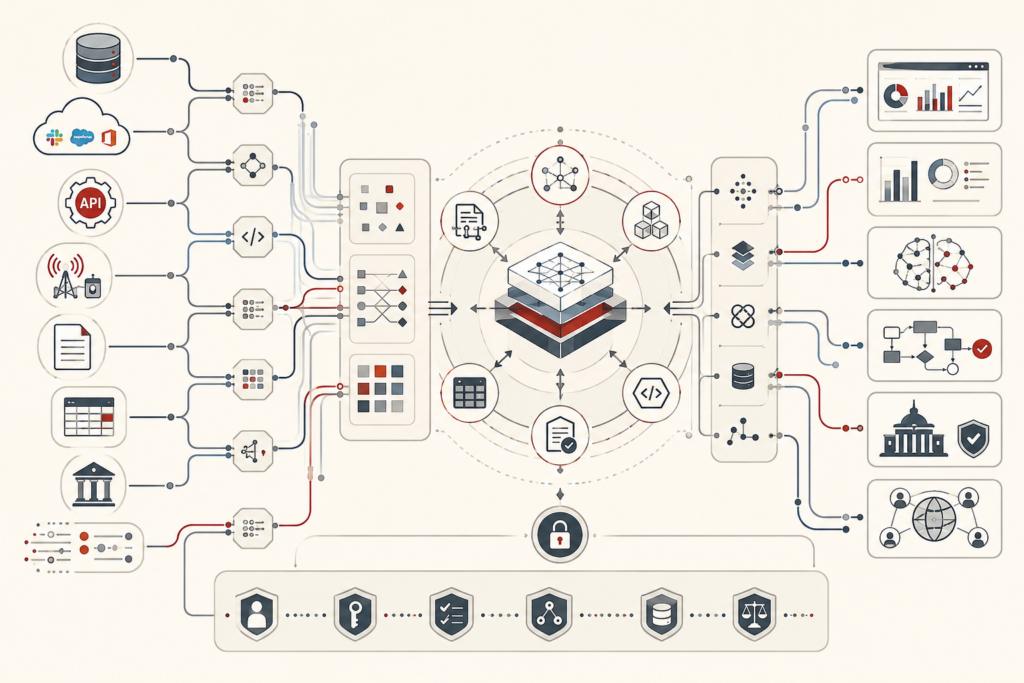
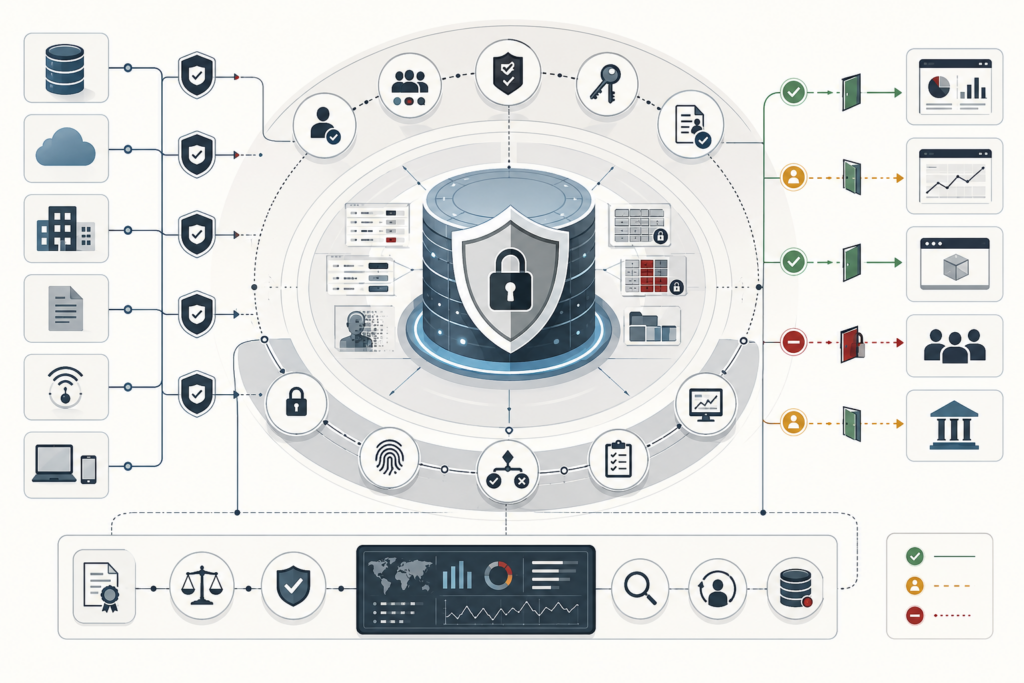
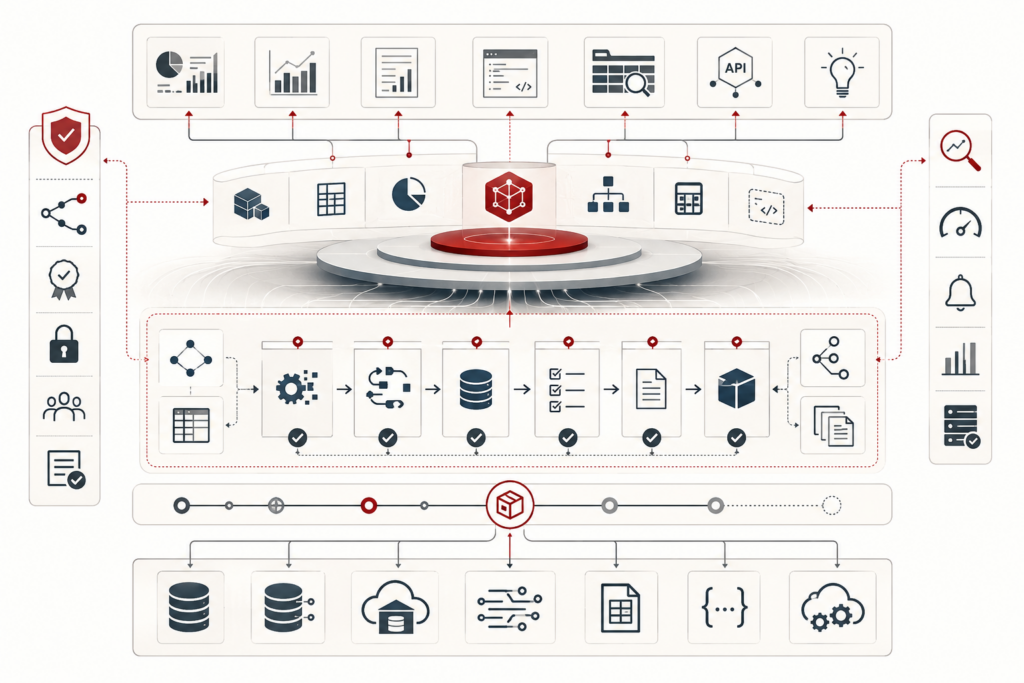
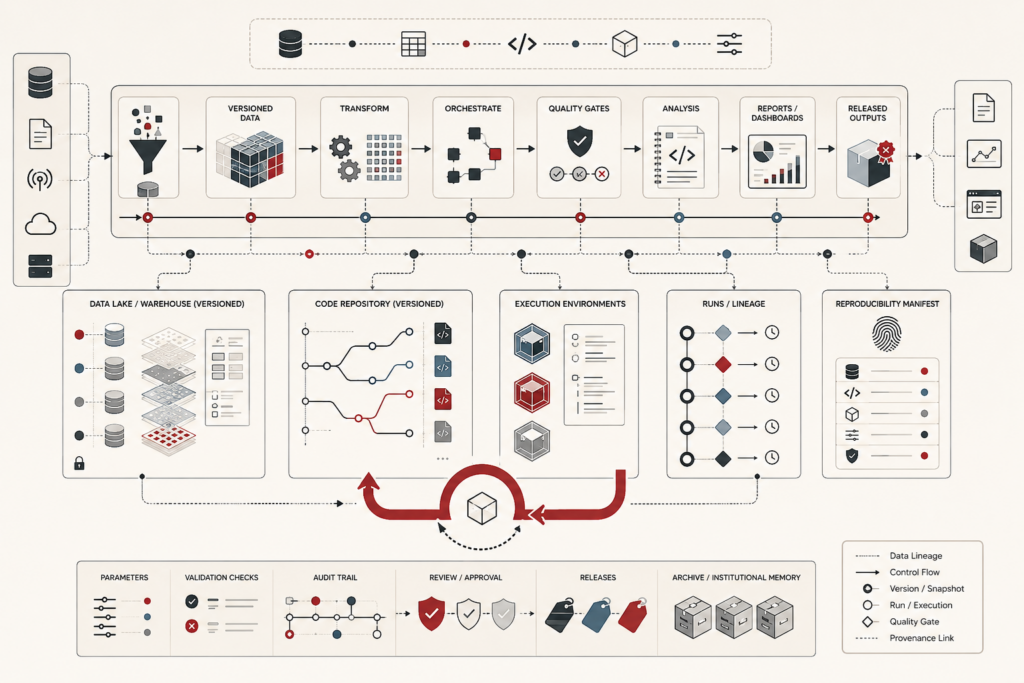
Reproducible analytics and versioned data workflows make analytical results inspectable, rerunnable, and trustworthy. In modern data systems, dashboards, models, reports, and metrics are constantly shaped by changing data, evolving schemas, revised code, updated dependencies, shifting definitions, and new execution environments. Without disciplined versioning and provenance, organizations may not know which inputs, assumptions, parameters, workflow steps, or runtime conditions produced a result. This article explains reproducibility as a systems property rather than a matter of notebook hygiene alone. It examines repeatability, provenance, versioned data workflows, lineage, environment capture, release management, quality gates, auditability, and institutional memory. The central argument is that trustworthy analytics depends on preserving the full evidence chain behind a result so that changes can be explained, outputs can be defended, and future teams can build on prior work rather than rediscovering it.