Master Data Management and Entity Resolution in Modern Data Systems
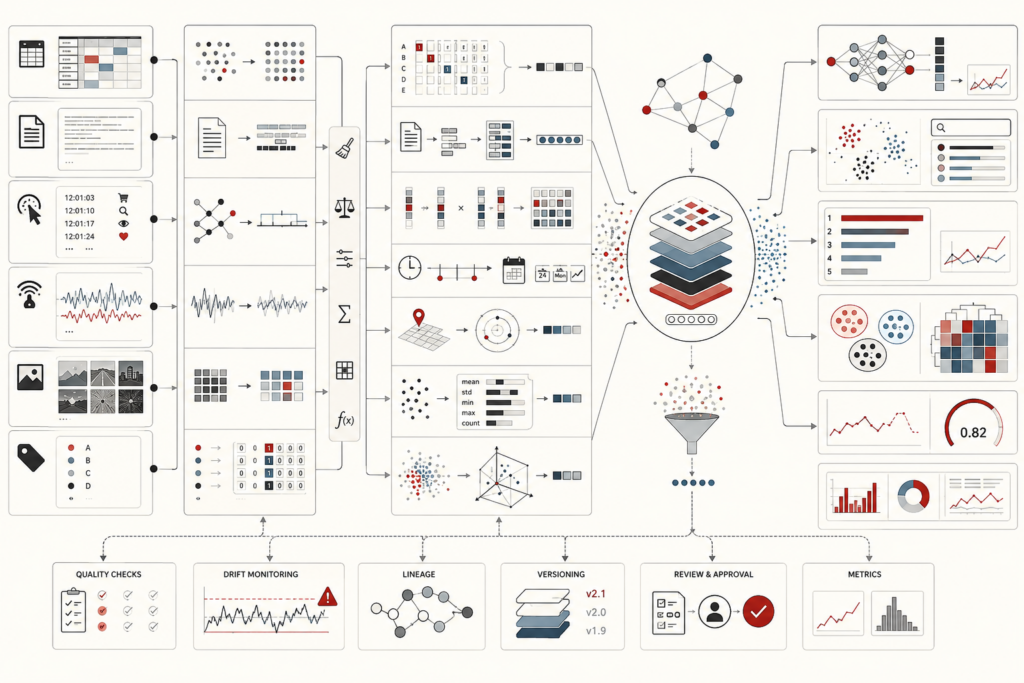
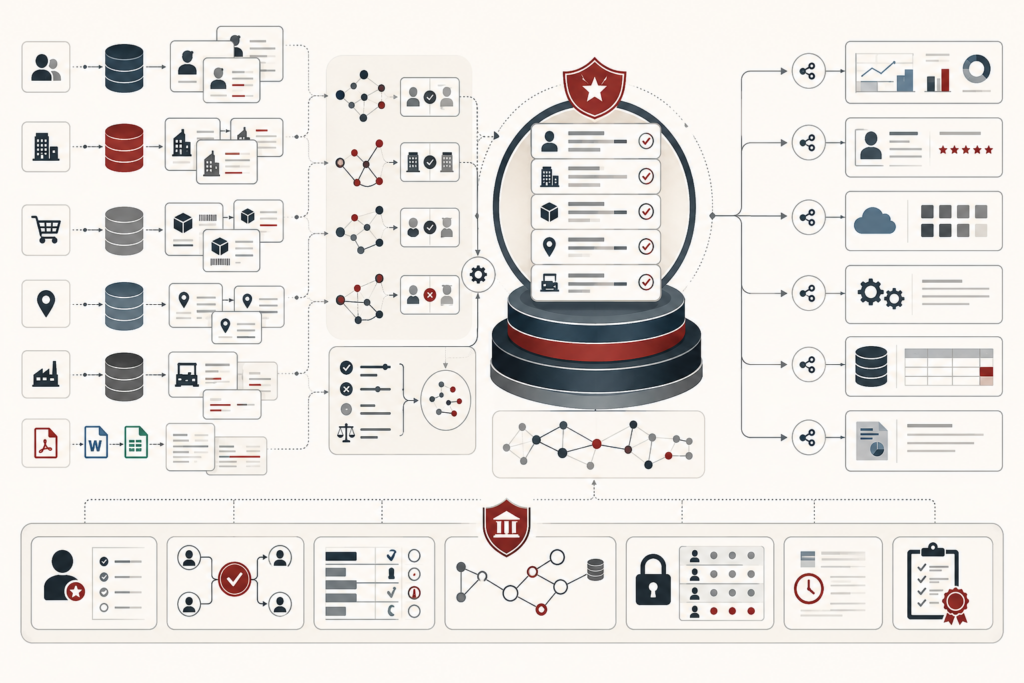
Master data management and entity resolution make core organizational entities trustworthy across fragmented systems. This article frames MDM not as simple deduplication, but as representational governance: the discipline of defining, matching, stewarding, versioning, and authorizing the entities that data systems claim to describe. It explains how customers, suppliers, facilities, products, legal entities, households, and assets become unstable when identifiers, names, hierarchies, and source-system meanings diverge. The article examines deterministic, probabilistic, hybrid, and graph-based matching; precision-recall trade-offs; survivorship rules; golden records; stewardship workflows; hierarchy modeling; legal-entity identifiers; privacy risks; and regulated identity-resolution limits. A mathematical lens and Python/R workflows show how teams can evaluate match confidence, merge risk, master-entity maturity, stewardship burden, and lineage. Its central argument is that trustworthy analytics depends on governing identity itself.