
Last Updated May 10, 2026
Database systems and data architecture form the structural foundation of modern information environments. Every analytical platform, application ecosystem, reporting system, integration pipeline, machine learning workflow, and decision-support layer depends on some underlying design for how data is stored, related, constrained, queried, secured, moved, retained, and interpreted. Databases are often treated as technical utilities that sit behind applications, but they are also institutional systems of memory. They determine what an organization can know, what it can retrieve, what it can trust, what it can audit, and what it can build upon.
A database is not merely a container for records. It is a formal structure for representing entities, relationships, transactions, histories, states, events, and rules. Data architecture is broader still. It defines how databases, schemas, pipelines, warehouses, lakes, catalogs, governance controls, metadata systems, and analytical models fit together across an organization. A strong data architecture allows operational systems, analytical systems, and governance systems to work from coherent structures rather than disconnected files, duplicated extracts, and inconsistent definitions.
Main Library
Publications
Article Map
Data Systems & Analytics
Related Topic
Artificial Intelligence Systems
Related Topic
Intelligent Infrastructure Systems
Related Topic
Embedded & Edge Systems
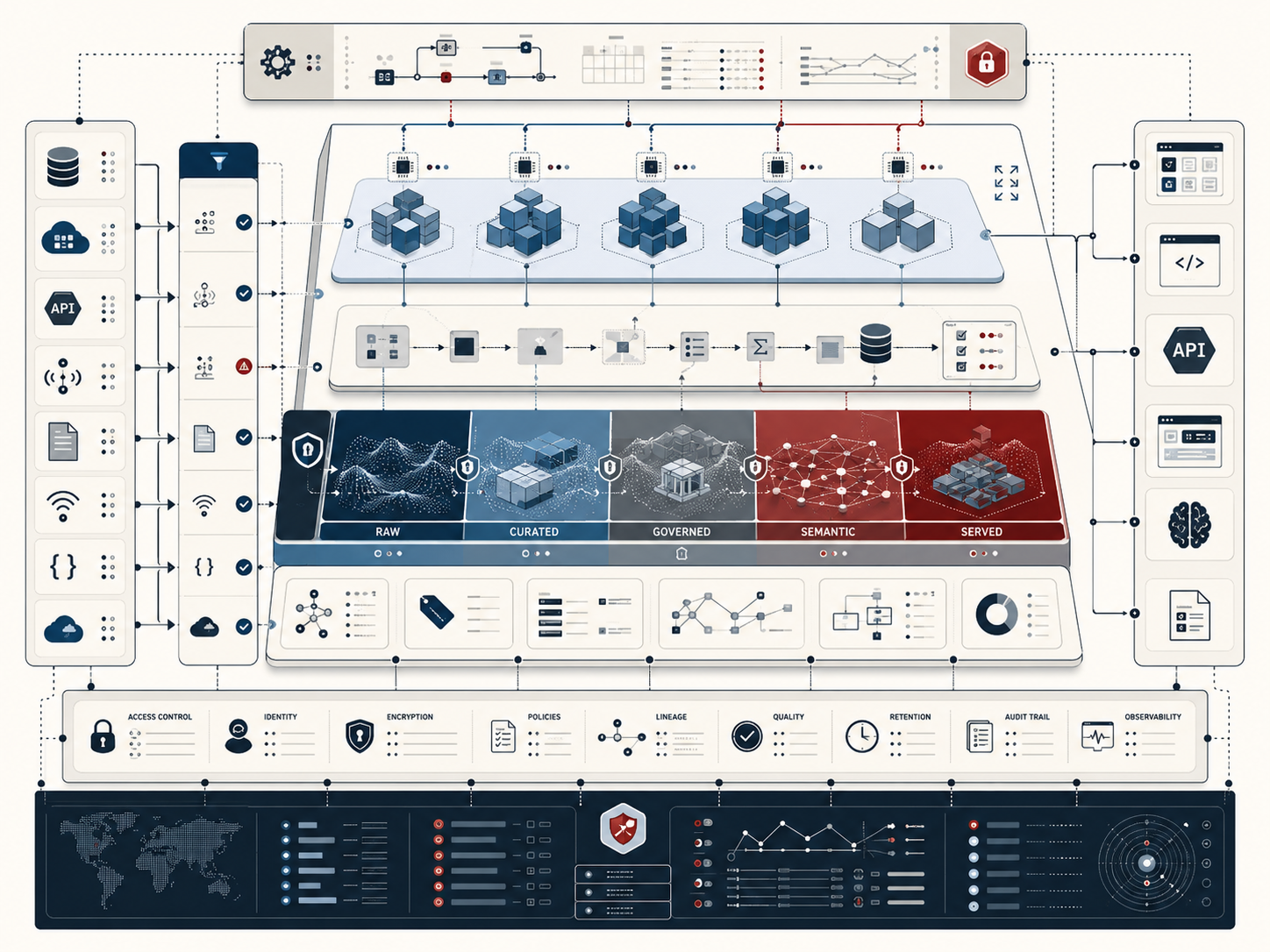
The importance of database systems becomes clearer when they are understood as both computational and organizational infrastructure. A database must support technical requirements such as consistency, durability, query performance, indexing, transactions, concurrency, replication, backup, and recovery. But it must also support institutional requirements such as ownership, accountability, documentation, privacy, security, retention, interpretability, and long-term reuse. Good data architecture sits at the intersection of these concerns.
Database systems and data architecture
Database systems are among the most important but least visible foundations of modern digital life. They support banking systems, public records, hospital systems, logistics networks, educational platforms, scientific datasets, environmental monitoring systems, e-commerce platforms, social media applications, public agencies, and organizational analytics. Wherever information must be stored, retrieved, validated, updated, analyzed, protected, or exchanged, some kind of database system is involved.
Data architecture gives those systems a broader design context. It asks how information should be organized across operational systems, analytical systems, integration platforms, storage layers, governance controls, and decision-support environments. It defines which data belongs where, how it moves, how it is modeled, how it is secured, how it is documented, how it is retained, and how different users can rely on it. Without architecture, databases may still function technically, but the organization’s information environment becomes fragmented, duplicative, and difficult to trust.
What a database system is
A database system is an organized environment for storing, managing, querying, and protecting data. It usually includes the database itself, a database management system, query interfaces, storage structures, transaction controls, indexing mechanisms, security controls, backup systems, and administrative tools. In relational systems, data is organized into tables, rows, columns, keys, constraints, and relationships. In other systems, data may be organized as documents, key-value pairs, graphs, time series, objects, events, or wide-column structures.
The central function of a database system is to make data durable, consistent, accessible, and meaningful. Durability means the system can preserve information across failures. Consistency means the system maintains defined rules about valid data states. Accessibility means users and applications can retrieve or modify data through controlled interfaces. Meaningfulness means the system’s structures reflect entities, relationships, and events in ways that can be understood and reused.
A database system therefore involves more than storage. It expresses assumptions about the world. A customer table, a patient record, a product catalog, a permit registry, a research sample, or a transaction ledger is never just a technical object. It is a modeled representation of reality, shaped by institutional categories, business rules, legal obligations, user needs, and historical decisions.
Data architecture, database architecture, and information architecture
Data architecture, database architecture, and information architecture overlap, but they are not identical. Database architecture focuses on the design of database systems themselves: schema structure, storage models, indexing, query performance, transactions, replication, backup, security, and administration. Data architecture is broader. It addresses the organization of data across systems, pipelines, platforms, domains, governance structures, analytical layers, metadata catalogs, and lifecycle processes. Information architecture is broader still in some contexts, focusing on how information is organized, classified, navigated, understood, and used by people.
This distinction matters because organizations often solve database problems while neglecting architectural problems. A database may be well-tuned and reliable within its own boundary while the wider data environment remains chaotic. Conversely, an organization may have impressive architecture diagrams but poorly designed databases underneath. Reliable systems require both levels: strong local database design and coherent enterprise data architecture.
Data architecture becomes especially important as organizations scale. A single application may be able to survive with a narrowly designed schema. An enterprise platform cannot. Once data must move among operational systems, warehouses, lakes, APIs, dashboards, machine learning models, compliance systems, and public reporting pipelines, architecture becomes the difference between reusable information and endless reconciliation.
Relational structure and transactional integrity
The relational model remains one of the most influential ideas in database history because it separates logical structure from physical storage and represents data through relations, attributes, keys, and constraints. Its enduring strength is not merely that it uses tables, but that it provides a disciplined way to represent relationships, avoid unnecessary duplication, enforce integrity, and query data declaratively.
Transactional integrity is equally important. Many database systems must support operations where multiple changes succeed or fail together. A payment, enrollment, inventory update, medical record change, or account transfer cannot be treated as a loose collection of unrelated writes. Transactional systems use principles often summarized as atomicity, consistency, isolation, and durability. These properties help ensure that data remains reliable even when multiple users, applications, or processes interact with it at the same time.
Relational systems are not the correct answer to every data problem, but their conceptual discipline remains foundational. Even when organizations use document stores, graph databases, event streams, lakehouse tables, or key-value stores, they still need to answer relational questions: What entities exist? What relationships matter? Which identifiers are stable? Which constraints protect validity? Which rules determine whether a record is complete, current, or trustworthy?
Schemas, keys, constraints, and normalization
Schema design is the practice of defining how data is structured. In relational systems, this includes tables, columns, data types, primary keys, foreign keys, uniqueness constraints, nullability rules, indexes, and relationships. In document or semi-structured systems, schema may be more flexible, but the underlying design questions remain: What entities are being represented? Which fields are required? Which identifiers connect records? Which rules protect the data from ambiguity or corruption?
Keys are especially important because they allow records to be distinguished and joined. A primary key identifies a record within a table. A foreign key connects one table to another. Natural keys may come from the real world, such as a code or account number. Surrogate keys are generated by the system. Poor key design can create duplicate entities, broken relationships, inconsistent joins, and analytical errors that propagate across the organization.
Normalization is a design approach that reduces redundancy and protects integrity by organizing data into coherent relations. It is especially useful in transactional systems where updates must be reliable and duplication can create contradictions. Analytical systems often use denormalized or dimensional structures for performance and usability, but even there, normalization remains conceptually important because it clarifies entities, relationships, and grain.
The grain of a table is one of the most important architectural decisions in data design. A table might represent one row per customer, one row per transaction, one row per product per day, one row per sensor reading, or one row per account-period. If the grain is unclear, downstream analytics become unstable. Metric definitions, joins, aggregations, and dashboards can all become unreliable because users are not working from a shared understanding of what each row represents.
Query processing, indexing, and physical design
Logical data design defines what the data means. Physical design affects how efficiently the system can store, retrieve, and process it. Indexes, partitions, clustering, compression, caching, materialized views, query plans, and storage layouts all shape database performance. A schema that looks elegant in logical form can become slow, expensive, or operationally fragile if physical design is ignored.
Indexes provide structured shortcuts for locating records. They can dramatically improve query performance, but they also impose maintenance costs during writes. Partitioning can improve performance and manageability by dividing data into meaningful segments such as dates, regions, tenants, or categories. Clustering can improve performance when related data is physically colocated. Materialized views can precompute common queries but require refresh strategies and governance.
Query processing is where the database system translates user intent into execution. A query optimizer evaluates possible execution plans and chooses a strategy for scanning, joining, filtering, aggregating, and returning results. Understanding query plans helps engineers and analysts diagnose slow queries, expensive joins, missing indexes, poor cardinality estimates, and inefficient access patterns.
Database architecture therefore requires both semantic clarity and mechanical realism. The system must represent the world accurately enough for users to trust it, but it must also process data efficiently enough for applications and analytics to work at scale.
Operational, analytical, and hybrid data stores
Operational databases and analytical databases serve different purposes. Operational systems are designed to support applications and transactions. They prioritize correctness, availability, concurrent updates, and predictable response times. Analytical systems are designed to support exploration, reporting, aggregation, modeling, and decision support. They prioritize scan performance, historical depth, dimensional analysis, and flexible query patterns.
This difference explains why data architecture often separates operational databases from warehouses, lakes, lakehouses, marts, cubes, semantic layers, and BI systems. Operational schemas are usually optimized around application workflows. Analytical schemas are usually organized around questions, metrics, dimensions, histories, and decision contexts. Moving data from operational systems into analytical systems requires transformation, modeling, documentation, testing, and governance.
Hybrid patterns have become more common as organizations seek lower latency and more integrated architectures. Some platforms support transactional and analytical workloads in closer proximity. Others use streaming pipelines, change data capture, or lakehouse tables to reduce delay between operational events and analytical availability. These patterns can be powerful, but they do not eliminate the need to distinguish between operational truth, analytical readiness, semantic certification, and governed consumption.
Distributed databases, replication, and consistency
As systems scale, database architecture often becomes distributed. Data may be replicated across regions, partitioned across nodes, cached near users, synchronized across systems, or streamed into downstream platforms. Distributed design supports availability, performance, resilience, and geographic reach, but it also introduces difficult tradeoffs.
Replication creates copies of data for availability, performance, or disaster recovery. Synchronous replication can protect consistency but may increase latency. Asynchronous replication can improve performance and availability but may allow temporary divergence. Sharding divides data across partitions or nodes, allowing larger scale but requiring careful key design and query routing. Eventual consistency can be acceptable for some workloads and unacceptable for others.
The architectural issue is not whether distributed systems are good or bad. It is whether their consistency, latency, recovery, and governance properties match the use case. A social feed, an inventory system, a public health registry, a financial ledger, and an environmental sensor network may all require different tradeoffs. Good data architecture makes those tradeoffs explicit rather than hiding them behind platform language.
Metadata, governance, lineage, and security
Database systems do not become trustworthy simply because they are technically available. Users need to know what data exists, where it came from, what it means, who owns it, how current it is, how it has changed, who can access it, and whether it is appropriate for a given use. Metadata, governance, lineage, and security make those questions answerable.
Metadata describes data assets. It may include names, definitions, schemas, owners, classifications, quality scores, freshness status, retention rules, lineage, access permissions, and usage patterns. Lineage shows how data moves and changes across systems. Governance defines policies and responsibilities. Security enforces access, privacy, encryption, auditability, and protection against misuse.
These elements must be treated as part of the architecture, not as after-the-fact documentation. A database without ownership becomes difficult to maintain. A schema without definitions becomes difficult to interpret. A table without lineage becomes difficult to trust. A warehouse without access control becomes a risk. A metric without semantic governance becomes a source of conflict.
Common failures in database and data architecture design
Several failures recur across database and data architecture work. One is schema drift, where structures change without adequate documentation, testing, or downstream coordination. Another is duplicate entity modeling, where customers, products, accounts, locations, or events are represented differently across systems. A third is weak grain definition, where tables are used without clarity about what one row means. A fourth is performance-first design without semantic discipline, where shortcuts improve speed but create long-term interpretive confusion.
Another common failure is analytical extraction without governance. Organizations often move data from operational systems into warehouses or lakes without clear ownership, lineage, certification, or quality checks. This creates large analytical environments that are technically impressive but difficult to trust. Users may have access to more data than ever before while still lacking confidence in definitions, freshness, completeness, or correctness.
There is also a failure of institutional memory. Databases often outlive the teams that created them. When design decisions are not documented, future users inherit structures they cannot explain. This is why data architecture must treat documentation, metadata, and governance as durable infrastructure rather than optional maintenance work.
What good looks like
A strong database system has clear entities, stable identifiers, well-defined relationships, appropriate constraints, reliable transactions, tested recovery procedures, useful indexes, documented schemas, and security controls. It supports the workload it was designed for without forcing every use case into the same structure. It can be monitored, tuned, backed up, restored, audited, and explained.
A strong data architecture extends those qualities across systems. Operational databases, analytical stores, integration pipelines, catalogs, semantic layers, dashboards, and governance processes fit together coherently. Data assets have owners. Tables have definitions. Metrics have certified logic. Lineage is visible. Access is controlled. Retention is planned. Quality checks are routine. Analytical users can find and understand trustworthy data without reverse-engineering every field from scratch.
Most importantly, good architecture makes data reusable without making it careless. It allows information to move, but not without controls. It allows analysis to scale, but not without meaning. It supports innovation, but not at the cost of trust. Under those conditions, database systems become more than backend infrastructure. They become durable foundations for institutional knowledge.
Python and R Workflows
Database systems and data architecture can be strengthened by translating design principles into reproducible workflows. The Python workflow below models relational schema design, indexing, and query-performance profiling. The R workflow models dimensional data-quality profiling for analytical systems. Together, they show how database architecture can be inspected not only as a conceptual design, but as a working system of tables, relationships, constraints, performance signals, and quality checks.
Python workflow: Relational schema design, indexing, and query-performance profiling
This Python workflow creates a small relational database in SQLite, defines primary keys and foreign keys, inserts sample data, creates an index, and profiles query performance. It demonstrates how schema structure, constraints, joins, and indexing work together. The example is intentionally simple, but the same pattern can be extended to larger systems where engineers need to validate schema design, test query performance, or demonstrate the consequences of indexing decisions.
import sqlite3
import pandas as pd
from time import perf_counter
connection = sqlite3.connect(":memory:")
connection.execute("PRAGMA foreign_keys = ON;")
schema_sql = """
CREATE TABLE customers (
customer_id INTEGER PRIMARY KEY,
customer_name TEXT NOT NULL,
region TEXT NOT NULL,
created_at TEXT NOT NULL
);
CREATE TABLE products (
product_id INTEGER PRIMARY KEY,
product_name TEXT NOT NULL,
product_category TEXT NOT NULL
);
CREATE TABLE orders (
order_id INTEGER PRIMARY KEY,
customer_id INTEGER NOT NULL,
order_date TEXT NOT NULL,
order_status TEXT NOT NULL,
FOREIGN KEY (customer_id) REFERENCES customers(customer_id)
);
CREATE TABLE order_items (
order_item_id INTEGER PRIMARY KEY,
order_id INTEGER NOT NULL,
product_id INTEGER NOT NULL,
quantity INTEGER NOT NULL CHECK (quantity > 0),
unit_price REAL NOT NULL CHECK (unit_price >= 0),
FOREIGN KEY (order_id) REFERENCES orders(order_id),
FOREIGN KEY (product_id) REFERENCES products(product_id)
);
"""
connection.executescript(schema_sql)
customers = pd.DataFrame([
(1, "Aster Public Health", "Midwest", "2026-01-01"),
(2, "Northline Energy", "West", "2026-01-03"),
(3, "Civic Water Authority", "South", "2026-01-05")
], columns=["customer_id", "customer_name", "region", "created_at"])
products = pd.DataFrame([
(1, "Sensor gateway", "infrastructure"),
(2, "Analytics subscription", "software"),
(3, "Field device", "hardware")
], columns=["product_id", "product_name", "product_category"])
orders = pd.DataFrame([
(1, 1, "2026-02-01", "complete"),
(2, 1, "2026-02-15", "complete"),
(3, 2, "2026-03-01", "pending"),
(4, 3, "2026-03-10", "complete")
], columns=["order_id", "customer_id", "order_date", "order_status"])
order_items = pd.DataFrame([
(1, 1, 1, 2, 500.00),
(2, 1, 2, 1, 1200.00),
(3, 2, 2, 1, 1200.00),
(4, 3, 3, 10, 175.00),
(5, 4, 1, 1, 500.00),
(6, 4, 2, 2, 1200.00)
], columns=["order_item_id", "order_id", "product_id", "quantity", "unit_price"])
customers.to_sql("customers", connection, if_exists="append", index=False)
products.to_sql("products", connection, if_exists="append", index=False)
orders.to_sql("orders", connection, if_exists="append", index=False)
order_items.to_sql("order_items", connection, if_exists="append", index=False)
revenue_query = """
SELECT
c.region,
p.product_category,
SUM(oi.quantity * oi.unit_price) AS revenue
FROM order_items oi
JOIN orders o
ON oi.order_id = o.order_id
JOIN customers c
ON o.customer_id = c.customer_id
JOIN products p
ON oi.product_id = p.product_id
WHERE o.order_status = 'complete'
GROUP BY c.region, p.product_category
ORDER BY revenue DESC;
"""
start = perf_counter()
revenue_by_region = pd.read_sql_query(revenue_query, connection)
elapsed_without_extra_index = perf_counter() - start
print("Revenue by region and category")
print(revenue_by_region)
print(f"Elapsed before additional index: {elapsed_without_extra_index:.6f} seconds")
query_plan_before = pd.read_sql_query(
"EXPLAIN QUERY PLAN " + revenue_query,
connection
)
print("\nQuery plan before additional index")
print(query_plan_before)
connection.execute("CREATE INDEX idx_orders_status_customer ON orders(order_status, customer_id);")
connection.execute("CREATE INDEX idx_order_items_order_product ON order_items(order_id, product_id);")
start = perf_counter()
revenue_by_region_indexed = pd.read_sql_query(revenue_query, connection)
elapsed_with_index = perf_counter() - start
query_plan_after = pd.read_sql_query(
"EXPLAIN QUERY PLAN " + revenue_query,
connection
)
print("\nElapsed after additional index: {:.6f} seconds".format(elapsed_with_index))
print("\nQuery plan after additional index")
print(query_plan_after)
schema_inventory = pd.read_sql_query("""
SELECT
name AS object_name,
type AS object_type,
sql AS definition
FROM sqlite_master
WHERE type IN ('table', 'index')
ORDER BY type, name;
""", connection)
print("\nSchema inventory")
print(schema_inventory)
connection.close()This workflow makes several architectural ideas visible. The schema uses primary keys, foreign keys, checks, and joins to protect meaning and integrity. The revenue query demonstrates how analytical questions depend on operational structure. The query plan shows how the database engine interprets the request. The indexes show that performance is not an abstract property of a database product; it depends on access patterns, schema design, and physical structures.
R workflow: Dimensional modeling and analytical data-quality profiling
This R workflow models a small dimensional analytical dataset and runs data-quality checks across facts, dimensions, grain, missing values, duplicate keys, referential integrity, and metric plausibility. It demonstrates how analytical architecture depends on more than moving data from operational systems into a warehouse. The warehouse or mart must preserve trustworthy joins, clear grain, valid dimensions, and reliable measures.
library(tidyverse)
dim_customer <- tribble(
~customer_key, ~customer_name, ~region,
101, "Aster Public Health", "Midwest",
102, "Northline Energy", "West",
103, "Civic Water Authority", "South"
)
dim_product <- tribble(
~product_key, ~product_name, ~category,
201, "Sensor gateway", "infrastructure",
202, "Analytics subscription", "software",
203, "Field device", "hardware"
)
fact_orders <- tribble(
~order_key, ~customer_key, ~product_key, ~order_date, ~quantity, ~revenue,
1, 101, 201, as.Date("2026-02-01"), 2, 1000,
2, 101, 202, as.Date("2026-02-01"), 1, 1200,
3, 101, 202, as.Date("2026-02-15"), 1, 1200,
4, 102, 203, as.Date("2026-03-01"), 10, 1750,
5, 103, 201, as.Date("2026-03-10"), 1, 500,
6, 103, 202, as.Date("2026-03-10"), 2, 2400
)
grain_check <- fact_orders %>%
count(order_key, customer_key, product_key, order_date, name = "row_count") %>%
filter(row_count > 1)
missingness_profile <- fact_orders %>%
summarise(across(
everything(),
~sum(is.na(.x)),
.names = "missing_{.col}"
))
customer_integrity_check <- fact_orders %>%
anti_join(dim_customer, by = "customer_key")
product_integrity_check <- fact_orders %>%
anti_join(dim_product, by = "product_key")
metric_quality_check <- fact_orders %>%
mutate(
revenue_per_unit = revenue / quantity,
invalid_quantity = quantity <= 0,
invalid_revenue = revenue < 0,
unusual_revenue_per_unit = revenue_per_unit > quantile(revenue_per_unit, 0.95) * 2
) %>%
filter(invalid_quantity | invalid_revenue | unusual_revenue_per_unit)
revenue_summary <- fact_orders %>%
left_join(dim_customer, by = "customer_key") %>%
left_join(dim_product, by = "product_key") %>%
group_by(region, category) %>%
summarise(
order_lines = n(),
total_quantity = sum(quantity),
total_revenue = sum(revenue),
average_revenue_per_line = mean(revenue),
.groups = "drop"
) %>%
arrange(desc(total_revenue))
quality_scorecard <- tibble(
check = c(
"duplicate_grain_rows",
"missing_values",
"customer_referential_integrity_failures",
"product_referential_integrity_failures",
"metric_quality_flags"
),
issue_count = c(
nrow(grain_check),
sum(missingness_profile),
nrow(customer_integrity_check),
nrow(product_integrity_check),
nrow(metric_quality_check)
)
) %>%
mutate(
status = if_else(issue_count == 0, "pass", "review")
)
quality_scorecard
revenue_summaryThis workflow shows how a dimensional model can be audited before it becomes a dashboard, report, or semantic-layer asset. The fact table is checked for grain problems, missing values, broken dimension relationships, and suspicious metric values. The resulting scorecard gives analysts and data engineers a simple way to evaluate whether an analytical dataset is ready for downstream use.
How these workflows strengthen database architecture
The Python workflow emphasizes the database as a structured computational system. It shows how schema design, constraints, joins, indexes, and query plans shape both correctness and performance. The R workflow emphasizes the analytical side of architecture. It shows how dimensions, facts, grain, referential integrity, and metric quality determine whether data can support trustworthy analysis.
Together, the workflows connect operational design to analytical reliability. A strong database architecture does not stop at tables, and a strong analytical architecture does not begin only at dashboards. The entire chain matters: operational schemas, data movement, transformed models, dimensional structures, semantic definitions, quality checks, and decision-support outputs. When those layers are aligned, data becomes reusable infrastructure rather than scattered evidence.
GitHub Repository
The companion repository for this article provides reproducible workflow examples for modeling cloud data platform architecture, lineage relationships, orchestration dependencies, freshness checks, governance risk, semantic consistency, and platform health audits in Python and R.
Conclusion
Database systems and data architecture are foundational because they determine how information is represented, protected, retrieved, related, and reused. Databases provide the durable structures that allow applications and analytical systems to function. Data architecture provides the wider design logic that connects those systems into coherent environments for governance, integration, analytics, and decision support.
The most important lesson is that database design is never merely technical. It is also semantic, institutional, and operational. A schema defines what counts as an entity. A key defines identity. A constraint defines validity. An index expresses expected access. A lineage record connects present use to prior transformation. A governance policy determines who can see, modify, retain, or explain data. These choices shape what an organization can know and how responsibly it can act on that knowledge.
Strong database systems make data reliable. Strong data architecture makes data usable across time, teams, and purposes. Together, they form the foundation on which modern analytics, governance, cloud platforms, AI systems, and decision-support environments depend.
Related articles
- Cloud Data Platforms and Modern Data Stack Architecture
- Data Integration and Interoperability
- Analytics Engineering and Semantic Layers
- Data Products and Self-Service Analytics
- Data Lifecycle Management and Retention
- Business Intelligence Systems and Decision Support
Further reading
- Connolly, T. and Begg, C. (2015) Database Systems: A Practical Approach to Design, Implementation, and Management. 6th edn. Harlow: Pearson.
- Date, C.J. (2019) Database Design and Relational Theory: Normal Forms and All That Jazz. 2nd edn. Sebastopol, CA: O’Reilly Media.
- Harrington, J.L. (2016) Relational Database Design and Implementation. 4th edn. Cambridge, MA: Morgan Kaufmann.
- Kimball, R. and Ross, M. (2013) The Data Warehouse Toolkit: The Definitive Guide to Dimensional Modeling. 3rd edn. Indianapolis: Wiley.
- Kleppmann, M. (2017) Designing Data-Intensive Applications. Sebastopol, CA: O’Reilly Media.
References
- ACM (1982) The 1981 ACM Turing Award Lecture: Relational Database: A Practical Foundation for Productivity. Available at: https://dl.acm.org/doi/10.1145/358396.358400
- Codd, E.F. (1970) A Relational Model of Data for Large Shared Data Banks. Available at: https://www.seas.upenn.edu/~zives/03f/cis550/codd.pdf
- PostgreSQL Global Development Group (2026) PostgreSQL Documentation. Available at: https://www.postgresql.org/docs/
- SQLite (2026) SQLite Documentation. Available at: https://www.sqlite.org/docs.html
- IBM (2026) What is a relational database? Available at: https://www.ibm.com/topics/relational-databases
- Microsoft (2026) SQL Server technical documentation. Available at: https://learn.microsoft.com/en-us/sql/sql-server/
- Oracle (2026) Database Concepts. Available at: https://docs.oracle.com/en/database/
- W3C (2014) RDF 1.1 Concepts and Abstract Syntax. Available at: https://www.w3.org/TR/rdf11-concepts/