
Last Updated May 11, 2026
Data products and self-service analytics have become central to the modern analytics stack because organizations increasingly need more than centralized reporting. They need reusable, trustworthy, discoverable analytical assets that allow domain teams, analysts, operators, executives, researchers, and frontline decision-makers to answer questions without recreating the same transformations, definitions, joins, filters, and datasets each time. In that sense, a data product is not merely a dataset published for others to consume. It is a governed, documented, maintained analytical resource designed to serve a real user need with defined quality expectations, ownership, semantics, access patterns, lifecycle status, and support responsibilities.
Self-service analytics, meanwhile, is the organizational capability that allows users to explore, interpret, and act on trusted analytical resources without depending on a bottlenecked central team for every query, dashboard, report, metric, or extract. The two concepts are therefore tightly coupled. Weak data products make self-service chaotic. Weak self-service practices turn even well-built data products into underused technical artifacts. Mature analytics requires both: reusable products that encode trustworthy meaning and consumption environments that allow people to use those products responsibly.
Main Library
Publications
Article Map
Data Systems & Analytics
Related Topic
Artificial Intelligence Systems
Related Topic
Intelligent Infrastructure Systems
Related Topic
Economic Systems
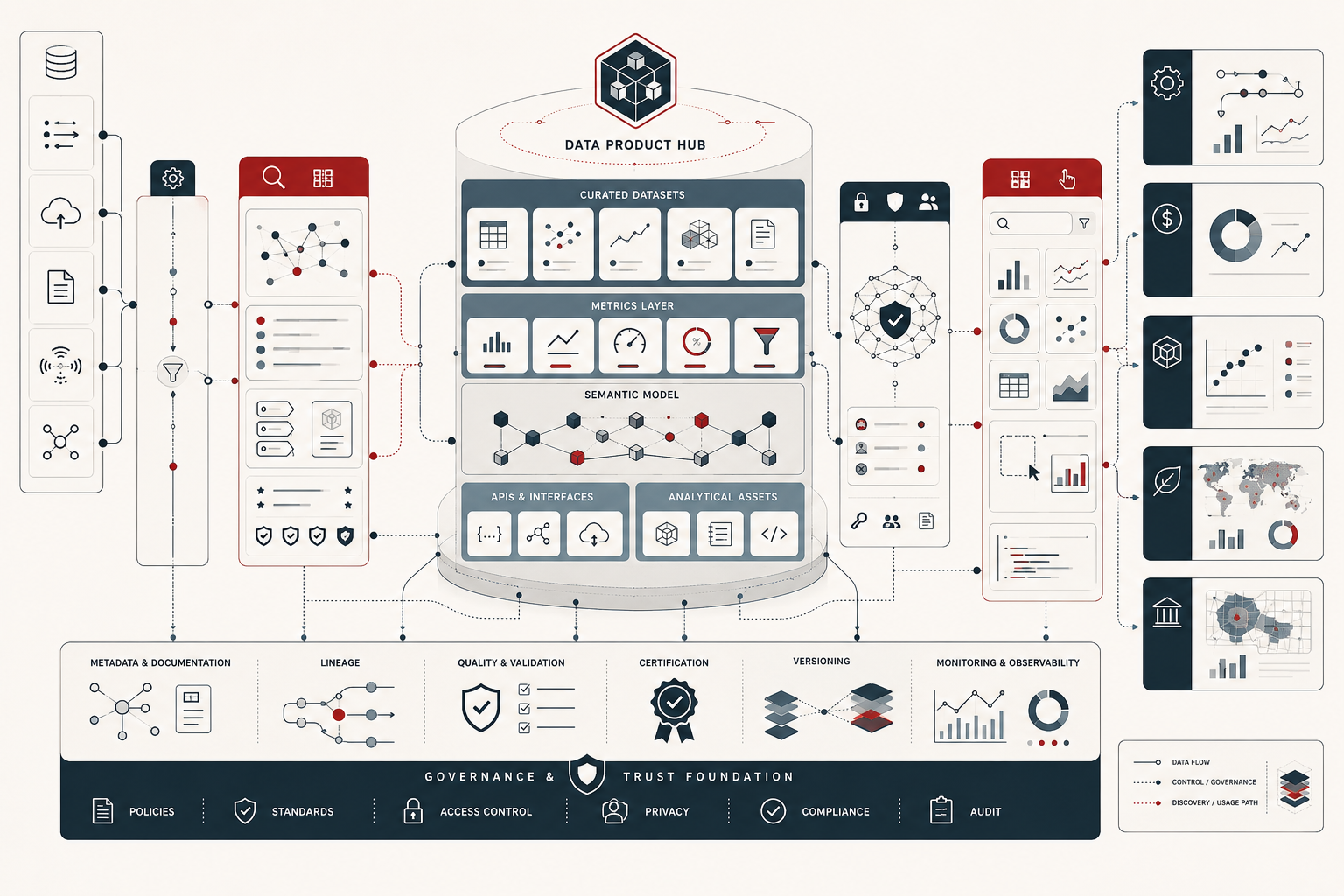
This matters because many organizations have already learned that unrestricted access to raw tables is not the same as analytical empowerment. If business users are given direct access to fragmented schemas, inconsistent definitions, undocumented joins, shifting field names, unverified metrics, and unknown data freshness, so-called self-service usually produces metric drift, duplicate dashboards, contradictory answers, and declining trust. The problem is not broader participation in analytics. The problem is the absence of structured products between source complexity and end-user decision-making. A mature analytics environment therefore depends on a middle layer: reliable data products shaped by domain context, semantic standardization, governance controls, quality expectations, metadata, lineage, and service-oriented maintenance.
Seen from this perspective, data products and self-service analytics are not just technical trends. They are part of a broader reorganization of analytical work. Centralized data teams can no longer sustainably answer every question, build every dashboard, interpret every domain nuance, and mediate every business definition for every team. At the same time, purely decentralized analytics often fragments meaning and weakens accountability. The strategic answer is not total centralization or total decentralization, but a layered model in which shared platforms, semantic standards, governance mechanisms, and domain-owned analytical products make broader participation possible without sacrificing trust.
What is a data product?
A data product is best understood as a maintained analytical asset created for consumption by a defined user group. It is not simply a table, file, report, extract, or dashboard. It is a product because it has users, purpose, standards, ownership, documentation, an implied service commitment, and an expected decision context. Good data products have clear interfaces, known inputs, stable semantics, discoverable metadata, documented quality expectations, access controls, lifecycle rules, and identifiable stewards. They are designed for reuse rather than one-off extraction.
The product framing matters because it shifts attention from production to utility. Traditional internal data work often ends when a dataset is loaded, a transformation runs, or a report is delivered. Product thinking begins there. It asks whether the resource is understandable, discoverable, sufficiently documented, semantically consistent, fit for analytical purpose, governed according to sensitivity, and maintained as requirements evolve. It also asks whether the product reduces duplicated effort for real users. A table that no one can confidently interpret is not yet a useful product, even if it is technically accessible.
A strong data product usually includes several elements. It has a business description that explains what the product represents and why it matters. It has explicit definitions for core entities, measures, dimensions, and inclusion rules. It has metadata describing freshness, grain, source lineage, access conditions, quality expectations, and sensitivity. It has testing and observability rules to detect failures or drift. It has a maintained owner or steward, often within a domain that understands both the underlying process and the needs of consumers. It has a consumption surface, whether that is a certified table, semantic model, API, feature store object, notebook-ready view, dashboard source, governed extract, or data-sharing interface.
The key point is that a data product is not defined by format. It is defined by accountability and usability. A product exists when data is shaped into an asset that other people can responsibly use.
Data products, semantic assets, and consumption surfaces
It is important to distinguish among three layers that are often blurred together. A data product is the governed analytical resource itself: the maintained asset with ownership, documentation, quality expectations, lifecycle status, and a defined consumer purpose. A certified semantic asset is the layer of shared business meaning that makes the product interpretable and consistent across users: governed metrics, conformed dimensions, entity definitions, approved calculation logic, and reusable business rules. A self-service consumption surface is the interface through which users interact with those resources: dashboards, BI tools, notebooks, query workbenches, APIs, embedded analytics, planning tools, or natural-language analytics interfaces.
This distinction matters because many organizations claim to have data products when they have only published tables, and claim to have self-service when they have only deployed dashboard tools. In mature environments, the three layers reinforce one another. The data product provides the reusable resource. The semantic layer protects interpretive consistency. The consumption surface allows broader use. When any one of these layers is missing, analytical trust declines. A table without shared semantics invites disagreement. A semantic model without a maintained product underneath it becomes brittle. A dashboard without governed logic becomes a polished surface over unresolved ambiguity.
The cleanest architecture separates these layers while keeping them connected. The product should expose reusable data with documented purpose and ownership. The semantic layer should define the meaning of key metrics and entities. The consumption surface should provide the right interface for the user’s task. An executive dashboard, analyst notebook, operational API, and AI retrieval layer may all consume the same underlying product, but they should not independently redefine its meaning.
Why self-service analytics needs data products
Self-service analytics is often framed as giving users tools. That is only partly true. Tools matter, but self-service succeeds primarily when users can rely on trustworthy inputs. Without that foundation, self-service becomes an exercise in unmanaged interpretation. Users spend their time locating data, guessing joins, rebuilding metrics, reconciling conflicting outputs, and deciding which dashboard to believe rather than answering meaningful questions. The real enabler of self-service is therefore not unrestricted access. It is well-structured access to shared analytical products.
This is where data products become institutionally important. They reduce repeated analytical labor. Instead of each analyst recreating customer lifetime value, churn logic, supplier risk exposure, fulfillment delay definitions, experiment-readout rules, emissions intensity calculations, or financial reconciliation logic from raw sources, a governed data product can expose those concepts through stable, documented interfaces. The data product becomes a reusable unit of analytical infrastructure. Self-service then operates on top of that infrastructure, allowing users to explore questions, build dashboards, test hypotheses, communicate findings, and support decisions without reproducing foundational modeling work every time.
In practice, this means self-service analytics is strongest when it sits above curated, semantically governed layers rather than directly on top of operational complexity. Business users need a shared vocabulary and governed logic if their independent analyses are to remain institutionally coherent. Without that coherence, self-service may increase analytical activity while reducing comparability.
A simple product model for analytical trust
A data product can be understood as a structured relationship among data, meaning, quality, ownership, access, and use. The product is not just the dataset. It is the governed bundle that makes the dataset usable in a decision context.
P = f(D, S, Q, O, A, L, U)
\]
Interpretation: A data product \(P\) depends on underlying data \(D\), semantic definitions \(S\), quality controls \(Q\), ownership \(O\), access policy \(A\), lineage \(L\), and user context \(U\).
This simple model helps explain why product thinking is stronger than dataset publication. A dataset may contain useful records, but without semantic definitions, consumers may not know what fields mean. Without quality controls, they may not know whether the data is fit for use. Without ownership, they may not know who resolves problems. Without access policy, sensitive data may be overexposed or underused. Without lineage, downstream users may not know where the data came from. Without user context, the asset may not answer a real decision need.
The same model also clarifies product maturity. Early-stage products may have data and basic documentation. Stronger products have certified metrics, active owners, automated quality checks, usage monitoring, lineage, lifecycle status, and clear support expectations. Mature self-service analytics depends on moving products toward that stronger state.
Data products as units of ownership and service
One of the most important contributions of the data product concept is that it clarifies ownership. In many organizations, analytical assets are everybody’s problem and therefore nobody’s responsibility. Tables appear without documentation. Dashboards persist after their creators leave. Metrics change without notice. Business rules drift across teams. Source systems evolve without downstream impact analysis. Data products counter this ambiguity by assigning stewardship and service responsibility. Someone owns the product, maintains its quality, communicates changes, and remains accountable for its fitness for use.
This ownership model does not mean every domain should independently define everything. That would simply recreate fragmentation at a higher level. Instead, ownership should be layered. Domain teams often own product-specific logic because they understand the business process, exceptions, operational context, and interpretation requirements. Platform and governance teams provide shared infrastructure, security, cataloging, quality frameworks, lineage, interoperability standards, and lifecycle controls. Shared semantic definitions may be centrally coordinated where cross-domain comparability is essential.
From a service perspective, a good data product resembles a managed internal offering. Consumers should know what it contains, who it is for, how often it updates, what quality checks are in place, how to access it, how changes are communicated, and how to raise issues. This is product thinking translated into the internal data environment. The shift is subtle but powerful. It changes the question from “Did we publish the table?” to “Can another team confidently use this resource in a real decision context?”
The architecture of self-service analytics
Self-service analytics should be understood as a layered architecture rather than a single tool category. At the bottom are source systems and event streams that record operational activity. Above them sit ingestion and integration processes, followed by analytical storage and transformation layers. Above those sit semantic models, governed metrics, reusable dimensions, productized datasets, and certified data products. Only then do self-service interfaces become reliable: BI tools, notebooks, ad hoc query surfaces, natural-language analytics, planning tools, embedded analytical applications, and AI-assisted exploration interfaces.
This layered model clarifies why self-service often fails in immature data environments. Organizations sometimes buy a new dashboarding platform, query interface, or conversational analytics tool and assume self-service will follow. But front-end interfaces cannot compensate for unresolved entity duplication, inconsistent temporal logic, weak metadata, unclear ownership, poor lineage, or absent governance. Self-service is not a shortcut around data management. It is the payoff from doing data management well enough that more people can safely and confidently use the results.
The strongest approaches to self-service analytics therefore place heavy emphasis on semantic mediation, domain-owned products, and governed platform services rather than on visualization features alone. The aim is to allow more people to answer more questions without multiplying institutional inconsistency. In effect, data products turn backend complexity into consumable analytical services, while self-service analytics turns those services into broader organizational capability.
Semantic consistency and metric trust
Perhaps the single greatest threat to self-service analytics is semantic inconsistency. If different teams define customer, order, active user, margin, downtime, emissions intensity, supplier delay, churn, incident severity, or revenue differently, then self-service can increase analytical velocity while simultaneously reducing interpretive coherence. A proliferation of dashboards does not necessarily indicate analytical maturity. It may indicate that an organization has lost control of meaning.
Data products help address this by embedding semantics into reusable assets. A well-designed product does not merely expose fields. It expresses business concepts through governed models and documented definitions. This is where semantic layers, certified metrics, dimensional standards, reference entities, master data, and business glossaries become crucial. Rather than asking every consumer to reverse engineer meaning from raw schemas, the organization builds meaning into the product itself.
This is also why metadata, cataloging, and lineage matter so much. Consumers need to know not only what a field is called, but what it means, how it was derived, how current it is, which systems feed it, who owns it, which quality checks apply, and whether it is approved for decision-critical use. In high-trust environments, a user can move from a dashboard or table to its definition, from the definition to its transformation logic, and from that logic to the accountable team. That traceability is a precondition for responsible self-service.
Governance without recentralization
One of the persistent misconceptions in analytics strategy is that governance and self-service are opposed. In reality, self-service without governance creates fragmentation, while governance without self-service recreates bottlenecks. The challenge is not choosing one over the other. It is building a form of governance that enables speed without surrendering coherence.
In practical terms, this usually means federated governance. Common policies exist for identity, access, stewardship, quality controls, metadata standards, privacy requirements, retention, lineage, product certification, and cross-domain definitions. But product ownership and product evolution may remain distributed across business domains. Governance then functions as a coordinating layer rather than a command-and-control gate on every analytical question.
This kind of structure matters because self-service is sustainable only when there are clear rules for what can be used, by whom, under what conditions, with what documentation, and with what accountability when something changes or fails. Good governance does not prevent reuse. It makes reuse trustworthy.
The aim is not to return every question to a central reporting queue. It is to define the conditions under which decentralized use can remain coherent. A governed self-service environment should make it clear which products are certified, which are experimental, which are deprecated, which metrics are approved for official reporting, and which analyses require methodological review.
Quality, observability, and product service expectations
A data product should have explicit quality expectations. Consumers need to know whether the product is fresh, complete, valid, reconciled, stable, and fit for its intended use. Quality expectations may include freshness windows, row-count thresholds, null-rate limits, accepted value ranges, referential integrity checks, reconciliation totals, duplicate-detection rules, schema compatibility tests, drift monitoring, or anomaly alerts.
Observability turns these expectations into ongoing operational signals. A product should not only be documented at launch. It should be monitored as sources change, pipelines fail, schemas evolve, and consumer demand shifts. Product owners should know when freshness expectations are missed, when quality checks warn or fail, when usage declines, when consumers repeatedly ask for the same missing field, and when downstream dashboards or APIs depend on a product that is changing.
This is where service expectations become useful. Some organizations may use formal service-level agreements. Others may use lighter-weight support expectations. The point is the same: users should know what level of reliability the product is designed to provide. A decision-critical finance product, an experimental growth product, and a deprecated legacy extract should not be treated as equivalent. Product status should be visible.
Catalogs, lineage, and discoverability
Self-service analytics depends on discoverability. Users cannot responsibly reuse products they cannot find, understand, or evaluate. A useful catalog does more than list assets. It helps users determine whether a product is relevant, trusted, current, governed, and appropriate for their use case. At minimum, catalog entries should include product owner, domain, description, grain, freshness, sensitivity, access policy, semantic definitions, lineage, certification status, quality indicators, and lifecycle stage.
Lineage connects discoverability to accountability. A user should be able to see which upstream sources feed a product and which downstream dashboards, notebooks, APIs, models, or decision systems depend on it. This matters during change. If an upstream source changes, lineage helps identify affected products. If a product is deprecated, lineage helps identify affected consumers. If a metric is challenged, lineage helps trace its derivation.
Catalogs can also fail. A catalog that simply inventories assets without improving interpretability becomes catalog theater. It may make the environment look governed while leaving users confused. The measure of catalog success is not the number of assets listed. It is whether users can find the right product, understand it, access it appropriately, and trust it enough for the intended decision.
Self-service literacy and decision context
Self-service analytics is not only an infrastructure problem. It is also a literacy problem. Users need enough analytical judgment to understand what a product can and cannot support. They need to know the difference between certified reporting and exploratory analysis, between a metric and a proxy, between a correlation and a causal claim, between a dashboard trend and a defensible decision, between a fresh product and a stale one, and between an approved semantic definition and an ad hoc calculation.
This does not mean every business user must become a data scientist. It means self-service systems should include guidance, training, examples, interpretation notes, and clear boundaries. The interface should help users understand the product’s grain, filters, exclusions, confidence level, update cadence, and intended use. Product documentation should explain not only what fields mean, but also how the product should be interpreted.
Decision context matters because not every analytical question should be self-served in the same way. Routine operational monitoring may be appropriate for broad self-service. Formal regulatory reporting, statistical inference, public claims, financial disclosures, high-stakes policy decisions, or automated decision systems may require stricter review. Mature self-service analytics broadens access while preserving methodological seriousness where consequences are higher.
Data products, AI, and analytical reuse
Data products are increasingly important for AI systems because AI workloads require trustworthy, well-documented, governed data assets. Feature stores, retrieval systems, vector databases, model evaluation datasets, prompt-grounding corpora, monitoring datasets, and feedback loops all depend on the same foundations: ownership, provenance, quality, access control, semantics, and lifecycle management. Weak data products become weak AI foundations.
AI also increases the importance of self-service boundaries. Natural-language interfaces may allow more people to ask questions of data, but they do not eliminate the need for governed products underneath. A conversational interface over inconsistent metrics can produce confident but misleading answers. A retrieval system over poorly documented documents can produce weak grounding. A model trained or evaluated on unclear data can inherit hidden assumptions. AI can make data more accessible, but it can also amplify confusion when the underlying products are not trustworthy.
The stronger pattern is to treat data products as reusable foundations for both human and machine consumption. A certified product can support dashboards, notebooks, APIs, model features, retrieval contexts, and decision workflows because its meaning and governance are explicit. That does not make every use automatically safe, but it gives teams a stronger basis for reuse and review.
Common failure modes
There are several recurring ways in which data products and self-service analytics fail.
One is product in name only: a team publishes a table and calls it a data product, but provides no documentation, quality guarantees, ownership, usage context, or semantic clarity.
Another is tool-first self-service: the organization expands dashboarding, query access, or natural-language analytics before addressing metric standardization, data quality, lineage, and governance.
A third is domain isolation: each domain builds products independently without sufficient shared entities, standards, interoperability, or cross-domain semantic coordination.
A fourth is stewardship decay: products are created but not maintained, versioned, monitored, communicated, deprecated, or retired.
A fifth is catalog theater: assets are listed in a catalog but remain hard to understand, hard to trust, or hard to use.
A sixth is metric proliferation: teams create many local definitions for the same business concept, leaving consumers to decide which number is correct.
A seventh is overpromised autonomy: users are encouraged to answer any question independently, even when the question requires statistical review, methodological care, or certified reporting.
Mature self-service analytics does not eliminate analytical roles. It redistributes them. Central experts still matter, but they focus less on repetitive extraction and more on platform design, semantic governance, high-value modeling, training, product standards, and methodological support.
What good looks like
A strong data product and self-service environment has several recognizable features. Core analytical domains expose certified products with clear business purpose and identified owners. Consumers can discover those products through a catalog that includes definitions, lineage, freshness, access conditions, lifecycle status, and quality indicators. Metric logic is standardized through governed models or semantic layers. Domain teams can evolve products, but within shared interoperability and governance rules. Business users can answer routine and moderately complex questions without waiting in a queue, yet decision-critical reporting remains consistent across the organization. Quality checks detect schema changes, freshness failures, missingness, duplicate records, invalid values, and anomalous behavior before trust collapses. Training and documentation support analytical literacy so users understand not just how to click, but how to interpret.
Most importantly, the environment changes how work happens. Analysts spend less time rebuilding common logic. Business teams spend less time arguing over whose number is correct. Data teams spend less time serving as human APIs for repetitive requests. Product owners gain feedback on how their assets are used. Governance teams gain visibility into access, lifecycle, sensitivity, and quality. Leadership gains faster access to comparable, auditable evidence. Under those conditions, self-service is not a slogan. It is an operational capability grounded in disciplined design.
| Control | Purpose | Failure it prevents |
|---|---|---|
| Product ownership | Assigns stewardship and service responsibility | Orphaned tables, abandoned dashboards, and unclear accountability |
| Semantic certification | Stabilizes metrics, entities, dimensions, and definitions | Metric drift and contradictory reporting |
| Quality checks | Monitors freshness, validity, completeness, and reconciliation | Self-service use of broken or stale data |
| Catalog metadata | Makes products discoverable and interpretable | Users guessing which asset is trustworthy |
| Lineage | Connects products to upstream sources and downstream consumers | Unknown impact from changes and deprecations |
| Access policy | Aligns product use with sensitivity and user role | Overexposure, underuse, or inconsistent permission handling |
| Lifecycle status | Distinguishes draft, beta, active, deprecated, and retired assets | Continued reliance on obsolete or experimental products |
| User literacy | Supports responsible interpretation and decision context | Misuse of self-service tools for inappropriate claims |
Data products, self-service, and organizational learning
At a deeper level, data products and self-service analytics matter because they reshape how organizations learn. When analytical resources are discoverable, documented, reusable, and interpretable, knowledge does not remain trapped in individual analysts, brittle dashboards, local spreadsheets, or one-off projects. It becomes part of institutional memory. Reusable products preserve logic, assumptions, definitions, and quality expectations across time. Self-service interfaces widen access to those shared resources. Governance structures maintain coherence as more actors participate. The result is not just faster reporting, but a more cumulative form of organizational intelligence.
This is especially important in complex institutions where teams are distributed across functions, regions, regulatory contexts, or time horizons. Productized analytics can make cross-domain coordination more feasible because it turns local process knowledge into consumable organizational assets. A finance data product can support revenue analysis. A customer product can support service improvement. An operations product can support supply-chain resilience. A sustainability product can support climate and risk reporting. An experiment-readout product can support product learning. Each becomes more valuable when its definitions and assumptions are visible.
In that sense, data products are not only technical constructs. They are vehicles for scaling institutional knowledge without collapsing into either central bottleneck or uncontrolled analytical pluralism.
A mathematical lens for data products and self-service trust
Data products can also be evaluated through a simple mathematical lens. The purpose of the model is not to reduce product judgment to a single number, but to make the dimensions of trust explicit. A usable data product is not only a dataset with rows and columns. It is a governed analytical asset whose value depends on quality, semantic clarity, ownership, lineage, access control, and actual use.
R_i = w_Q Q_i + w_S S_i + w_O O_i + w_L L_i + w_A A_i + w_U U_i
\]
Interpretation: The readiness score \(R_i\) for data product \(i\) is a weighted combination of quality \(Q_i\), semantic certification \(S_i\), ownership maturity \(O_i\), lineage coverage \(L_i\), access-policy maturity \(A_i\), and demonstrated user adoption \(U_i\).
The weights should sum to one:
w_Q + w_S + w_O + w_L + w_A + w_U = 1
\]
Interpretation: The scoring model should be transparent about how much importance is assigned to each component of product readiness. A regulated finance product, for example, may assign more weight to quality, lineage, and access control, while an exploratory growth product may assign more weight to usage and iteration speed.
This model also clarifies why self-service analytics cannot be measured by dashboard usage alone. A product with high usage but weak semantics may spread confusion quickly. A product with strong documentation but no adoption may be well designed but institutionally irrelevant. A product with high quality but unclear ownership may become fragile over time.
A second useful model is the relationship between self-service trust, product readiness, and semantic consistency:
T_i = R_i \times C_i
\]
Interpretation: Self-service trust \(T_i\) for product \(i\) depends on product readiness \(R_i\) multiplied by semantic consistency \(C_i\). Even a technically strong product becomes less trustworthy if consumers define its metrics differently across dashboards, notebooks, reports, and decision workflows.
Semantic consistency can be approximated by comparing the number of certified metric definitions to the number of competing local definitions:
C_m = \frac{1}{1 + D_m}
\]
Interpretation: Semantic consistency \(C_m\) for metric \(m\) declines as definition drift \(D_m\) increases. If there is one certified definition and few competing local definitions, consistency remains high. If many teams recreate the same metric differently, consistency falls.
Self-service analytics should therefore be evaluated as a trust system rather than a usage system alone. The organization should ask not only how many people are using dashboards, notebooks, APIs, or natural-language interfaces, but whether those users are working from governed products with stable meaning, visible quality, documented lineage, and accountable ownership.
Python Workflow: Data Product Readiness Scorecard
The following Python workflow shows how a simple data product registry can be scored using quality, semantic certification, ownership, lineage, access policy, and usage signals. In a production environment, these inputs would usually come from a catalog, semantic layer, quality-monitoring service, access-control system, lineage platform, and usage logs. Here, the example is intentionally compact so the logic remains visible.
#!/usr/bin/env python3
"""
Python Workflow: Data Product Readiness Scorecard
This example scores data products using several dimensions:
- quality score
- semantic certification
- ownership maturity
- lineage coverage
- access-policy maturity
- self-service usage
The goal is not to create a universal formula. The goal is to show how
data product readiness can be modeled as a transparent, auditable score.
"""
from __future__ import annotations
import csv
from dataclasses import dataclass
from pathlib import Path
@dataclass
class DataProduct:
product_id: str
name: str
domain: str
owner: str
quality_score: float
semantic_status: str
has_lineage: bool
access_model: str
dashboard_views: int
notebook_sessions: int
api_calls: int
def semantic_score(status: str) -> float:
"""Convert semantic certification status into a numerical score."""
scores = {
"certified": 1.0,
"reviewed": 0.7,
"uncertified": 0.2,
}
return scores.get(status, 0.0)
def ownership_score(owner: str) -> float:
"""A named non-empty owner is the minimum ownership signal."""
return 1.0 if owner.strip() else 0.0
def lineage_score(has_lineage: bool) -> float:
"""Lineage coverage supports auditability and change-impact analysis."""
return 1.0 if has_lineage else 0.0
def access_policy_score(access_model: str) -> float:
"""More governed access models receive higher scores."""
scores = {
"row-column-security": 1.0,
"role-based": 0.85,
"restricted": 0.75,
"open-internal": 0.4,
}
return scores.get(access_model, 0.5)
def usage_score(product: DataProduct) -> float:
"""
Normalize usage into a simple 0-1 adoption score.
In practice, this should be benchmarked against expected product audience.
"""
total_usage = (
product.dashboard_views
+ product.notebook_sessions
+ product.api_calls
)
return min(total_usage / 500.0, 1.0)
def readiness_score(product: DataProduct) -> float:
"""
Weighted product-readiness score.
Weights:
- quality: 30%
- semantic certification: 20%
- ownership: 15%
- lineage: 15%
- access policy: 10%
- usage: 10%
"""
return round(
0.30 * product.quality_score
+ 0.20 * semantic_score(product.semantic_status)
+ 0.15 * ownership_score(product.owner)
+ 0.15 * lineage_score(product.has_lineage)
+ 0.10 * access_policy_score(product.access_model)
+ 0.10 * usage_score(product),
3,
)
def main() -> None:
products = [
DataProduct(
product_id="dp_customer_360",
name="Customer 360 Analytical Product",
domain="customer",
owner="customer-domain",
quality_score=0.96,
semantic_status="certified",
has_lineage=True,
access_model="role-based",
dashboard_views=170,
notebook_sessions=31,
api_calls=505,
),
DataProduct(
product_id="dp_revenue_mart",
name="Revenue Performance Product",
domain="finance",
owner="finance-domain",
quality_score=0.98,
semantic_status="certified",
has_lineage=True,
access_model="row-column-security",
dashboard_views=219,
notebook_sessions=17,
api_calls=190,
),
DataProduct(
product_id="dp_legacy_extract",
name="Legacy Dashboard Extract",
domain="legacy",
owner="central-bi",
quality_score=0.62,
semantic_status="uncertified",
has_lineage=False,
access_model="open-internal",
dashboard_views=20,
notebook_sessions=1,
api_calls=0,
),
]
output_path = Path("outputs/product_readiness_scorecard_python.csv")
output_path.parent.mkdir(parents=True, exist_ok=True)
with output_path.open("w", newline="", encoding="utf-8") as handle:
writer = csv.DictWriter(
handle,
fieldnames=[
"product_id",
"name",
"domain",
"owner",
"semantic_status",
"quality_score",
"readiness_score",
],
)
writer.writeheader()
for product in products:
writer.writerow(
{
"product_id": product.product_id,
"name": product.name,
"domain": product.domain,
"owner": product.owner,
"semantic_status": product.semantic_status,
"quality_score": product.quality_score,
"readiness_score": readiness_score(product),
}
)
print(f"Wrote {output_path}")
if __name__ == "__main__":
main()
This workflow makes the governance logic inspectable. Product-readiness scoring should not be hidden inside a dashboard or a vendor tool. The criteria should be visible enough for data owners, analysts, governance teams, and product consumers to debate whether the weights reflect the organization’s actual risk profile and decision context.
R Workflow: Self-Service Usage and Product Health
The following R workflow summarizes product health and self-service adoption by combining product metadata with usage signals. It is designed for the kind of recurring product review that governance teams, analytics engineering teams, and domain owners might run monthly or quarterly.
#!/usr/bin/env Rscript
# R Workflow: Self-Service Usage and Product Health
#
# This workflow summarizes data products by domain, lifecycle status,
# semantic certification, and self-service usage. It uses base R so the
# example remains portable and easy to run.
products <- data.frame(
product_id = c(
"dp_customer_360",
"dp_revenue_mart",
"dp_supply_delay",
"dp_product_usage",
"dp_legacy_extract"
),
domain = c(
"customer",
"finance",
"operations",
"product",
"legacy"
),
semantic_status = c(
"certified",
"certified",
"certified",
"certified",
"uncertified"
),
lifecycle_status = c(
"active",
"active",
"active",
"active",
"deprecated"
),
quality_score = c(0.96, 0.98, 0.91, 0.94, 0.62),
stringsAsFactors = FALSE
)
usage <- data.frame(
product_id = c(
"dp_customer_360",
"dp_revenue_mart",
"dp_supply_delay",
"dp_product_usage",
"dp_legacy_extract"
),
dashboard_views = c(170, 219, 97, 152, 20),
notebook_sessions = c(31, 17, 13, 45, 1),
api_calls = c(505, 190, 75, 315, 0),
stringsAsFactors = FALSE
)
# Join product metadata to usage data.
product_usage <- merge(products, usage, by = "product_id", all.x = TRUE)
# Replace missing usage values with zero.
usage_columns <- c("dashboard_views", "notebook_sessions", "api_calls")
product_usage[usage_columns][is.na(product_usage[usage_columns])] <- 0
# Compute total observed self-service use.
product_usage$total_usage <- (
product_usage$dashboard_views +
product_usage$notebook_sessions +
product_usage$api_calls
)
# Create a simple health label for governance review.
product_usage$product_health <- ifelse(
product_usage$semantic_status == "certified" &
product_usage$lifecycle_status == "active" &
product_usage$quality_score >= 0.90,
"decision-ready",
"review-needed"
)
# Summarize product health by domain.
domain_health <- aggregate(
product_id ~ domain + product_health,
data = product_usage,
FUN = length
)
names(domain_health) <- c("domain", "product_health", "product_count")
# Summarize self-service usage by domain.
domain_usage <- aggregate(
total_usage ~ domain,
data = product_usage,
FUN = sum
)
# Write outputs.
dir.create("outputs", showWarnings = FALSE, recursive = TRUE)
write.csv(
product_usage,
"outputs/self_service_product_usage_r.csv",
row.names = FALSE
)
write.csv(
domain_health,
"outputs/domain_product_health_r.csv",
row.names = FALSE
)
write.csv(
domain_usage,
"outputs/domain_self_service_usage_r.csv",
row.names = FALSE
)
cat("Wrote R self-service usage and product health outputs.\n")
This workflow supports a practical governance question: which products are being used, which are decision-ready, and which need review before they become a foundation for broader self-service analytics? It also distinguishes usage from trust. A product can be heavily used and still require review if its semantic status, quality score, or lifecycle status is weak.
GitHub Repository
This article can be paired with a companion code workflow that models data products and self-service analytics as a governed analytical operating system. The example includes a product registry, semantic metric catalog, access-event table, quality-check inventory, lineage map, SQL schemas, readiness scorecards, typed contracts, lifecycle documentation, and multi-language examples across Python, R, Julia, SQL, Go, Rust, C, C++, TypeScript, and Terraform placeholders.
Complete Code RepositoryThe companion repository provides a vendor-neutral data product and self-service analytics scaffold with product readiness scoring, semantic metric coverage, usage summaries, quality-check reporting, lineage modeling, access-policy examples, lifecycle checklists, typed contracts, documentation, and CI smoke-test patterns.
Conclusion
Data products and self-service analytics should be understood as mutually dependent parts of a mature analytics architecture. Data products turn raw, fragmented, operational complexity into reusable analytical assets with ownership, semantics, documentation, quality expectations, access controls, lifecycle status, and service expectations. Certified semantic assets ensure that those products are interpreted consistently across teams and use cases. Self-service consumption surfaces then allow a wider range of users to explore, interpret, and act on those resources without waiting for centralized teams to mediate every question.
The strategic aim is not unrestricted access, but trustworthy access. It is not analytical decentralization for its own sake, but scalable decision support built on shared meaning, maintained products, governed infrastructure, and responsible interpretation. When organizations get this right, they move beyond dashboard proliferation and toward a more durable form of analytical capability. They build environments in which data is not only stored, but productized; not only visible, but interpretable; not only queried, but trusted.
That is the real promise of self-service analytics: not infinite autonomy, but broader, faster, more reliable participation in evidence-based organizational learning and decision-making.
Related articles
- Analytics Engineering and Semantic Layers
- Metadata, Data Catalogs, and Lineage
- Data Quality Metrics and Observability
- Business Intelligence Systems and Decision Support
- Data Governance and Stewardship
- Master Data Management and Entity Resolution
Further reading
- Dehghani, Z. (2022) Data Mesh: Delivering Data-Driven Value at Scale. Sebastopol, CA: O’Reilly Media.
- Kimball, R. and Ross, M. (2013) The Data Warehouse Toolkit: The Definitive Guide to Dimensional Modeling. 3rd edn. Indianapolis: Wiley.
- Kleppmann, M. (2017) Designing Data-Intensive Applications. Sebastopol, CA: O’Reilly Media.
- Redman, T.C. (2008) Data Driven: Profiting from Your Most Important Business Asset. Boston: Harvard Business Press.
- Sharda, R., Delen, D. and Turban, E. (2018) Business Intelligence, Analytics, and Data Science: A Managerial Perspective. 4th edn. Harlow: Pearson.
- Wang, R.Y. (ed.) (2021) Data Quality: Dimensions, Measurement, Strategy, Management, and Governance. Singapore: World Scientific.
References
- Ain, N.U., Vaia, G., DeLone, W.H. and Waheed, M. (2019) ‘Two decades of research on business intelligence system adoption, utilization and success – A systematic literature review’, Decision Support Systems, 125, 113113. Available at: https://doi.org/10.1016/j.dss.2019.113113
- Amazon Web Services (2026) What is a Data Mesh? Available at: https://aws.amazon.com/what-is/data-mesh/
- Bernardo, B.M.V. et al. (2024) ‘Data governance & quality management—Innovation and breakthroughs across different fields’, Journal of Innovation & Knowledge, 9(4), 100598. Available at: https://www.sciencedirect.com/science/article/pii/S2444569X24001379
- Databricks (2025) What is Data Mesh? Available at: https://www.databricks.com/blog/what-is-data-mesh
- Microsoft (2026) Executive strategy for unifying your data for AI and analytics. Cloud Adoption Framework. Available at: https://learn.microsoft.com/en-us/azure/cloud-adoption-framework/data/executive-strategy-unify-data-platform
- Microsoft (2026) Data contracts. Cloud Adoption Framework. Available at: https://learn.microsoft.com/en-us/azure/cloud-adoption-framework/scenarios/cloud-scale-analytics/architectures/data-contracts
- National Institute of Standards and Technology (2024) NIST Research Data Framework (RDaF): Version 2.0. NIST Special Publication 1500-18r2. Available at: https://www.nist.gov/publications/nist-research-data-framework-rdaf-version-20
- National Institute of Standards and Technology (2024) Data Governance and Management Profile. Available at: https://www.nist.gov/privacy-framework/new-projects/data-governance-and-management-profile
- Phillips-Wren, G., Daly, M. and Burstein, F. (2021) ‘Reconciling business intelligence, analytics and decision support systems: More data, deeper insight’, Decision Support Systems, 146, 113560. Available at: https://www.loyola.edu/sellinger-business/faculty-research/directory/phillips-wren.html