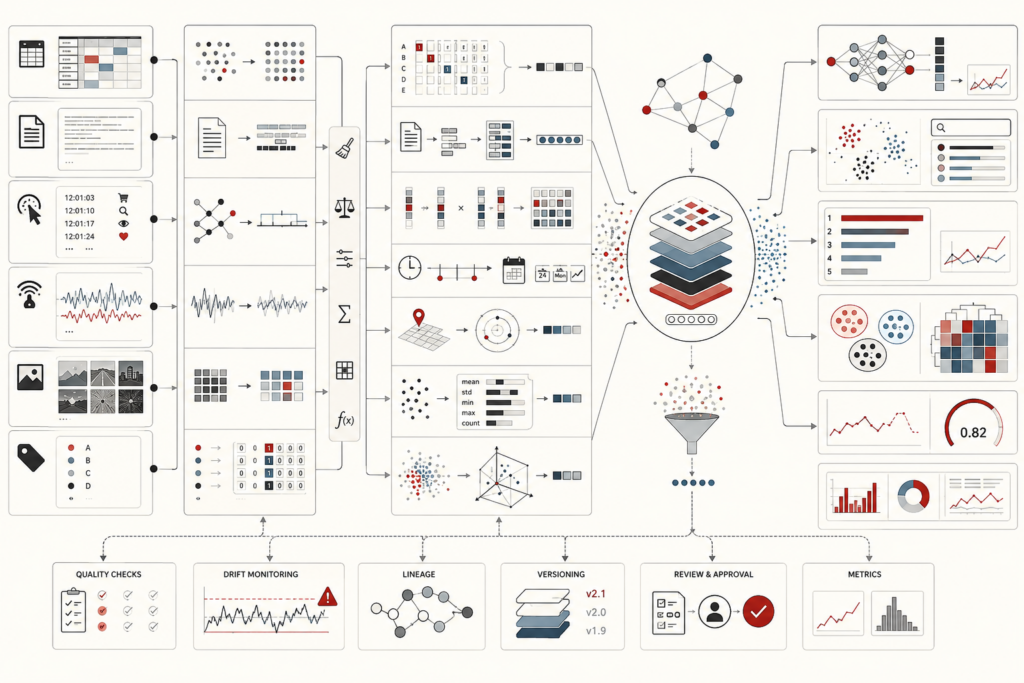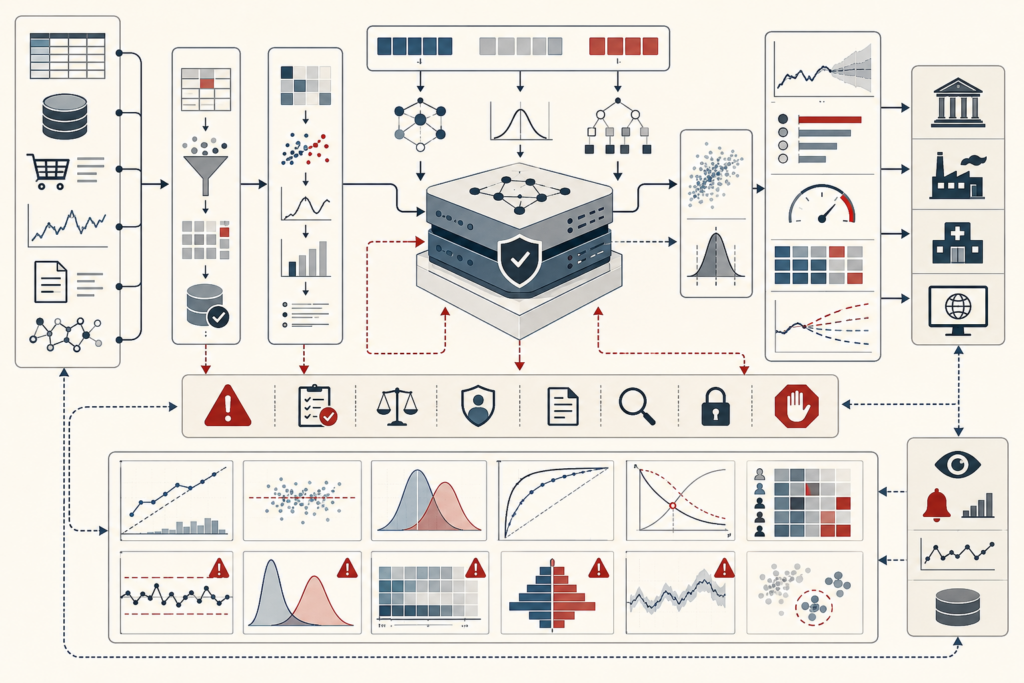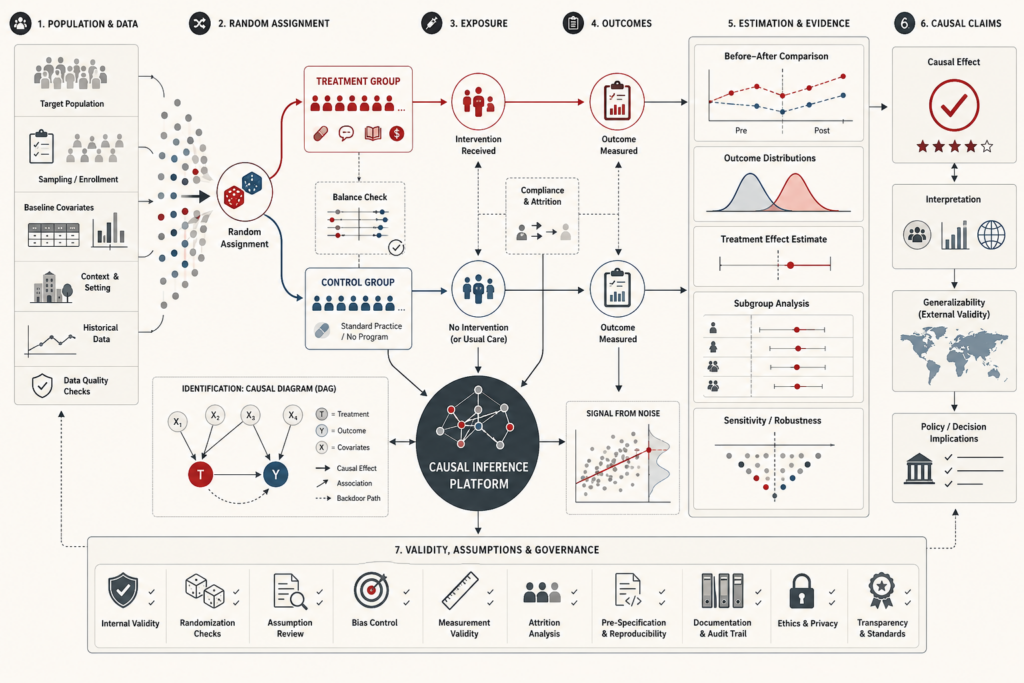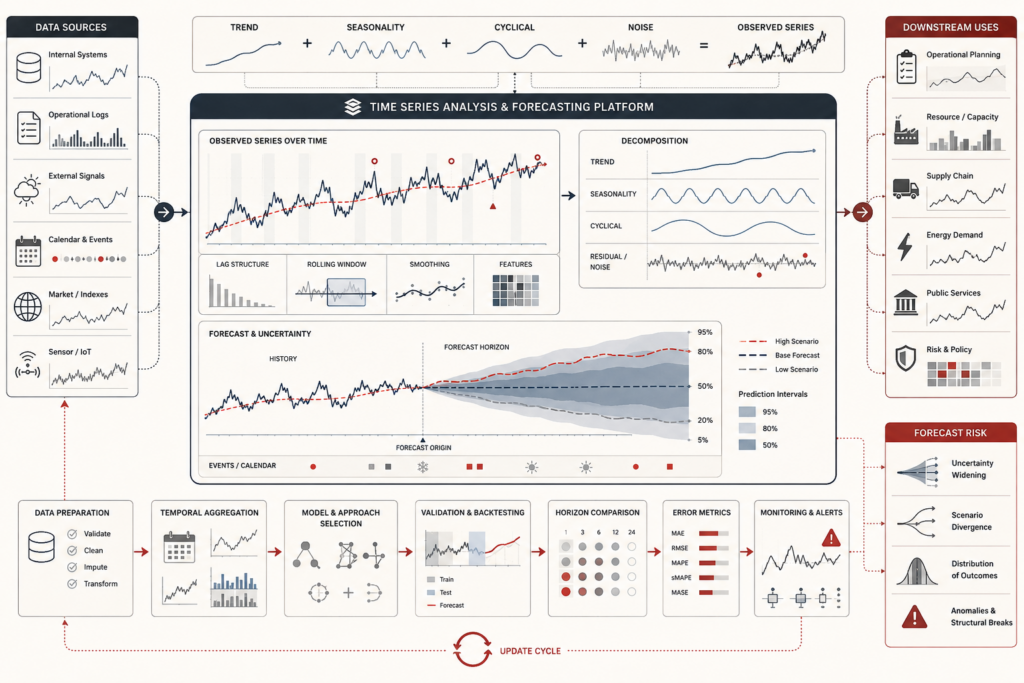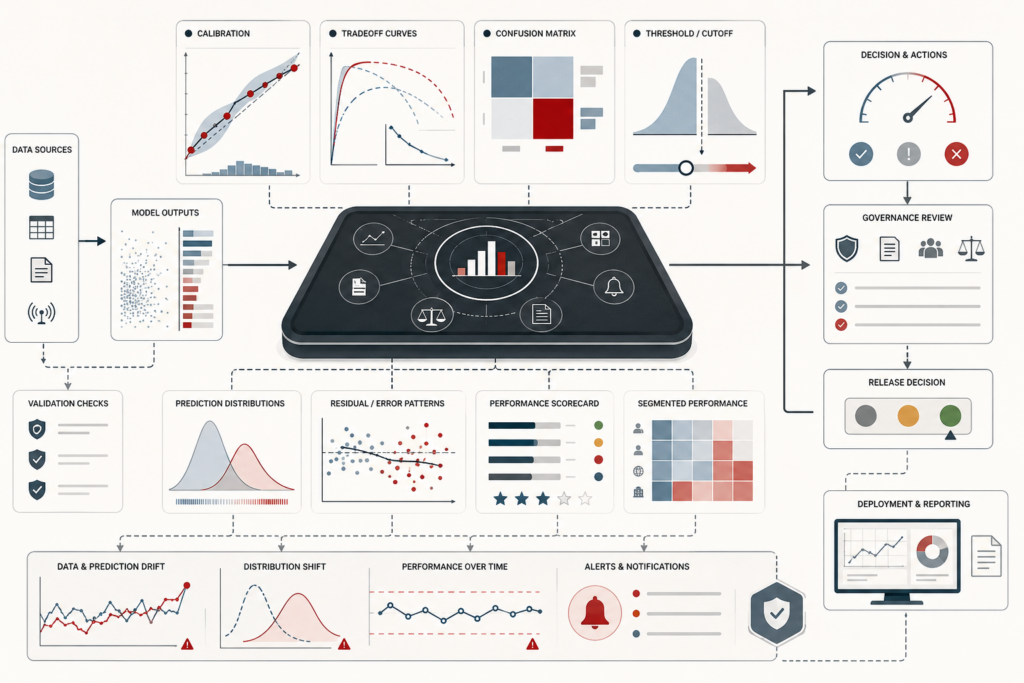
Model Evaluation and Performance Metrics: Calibration, Thresholds, and Model Quality
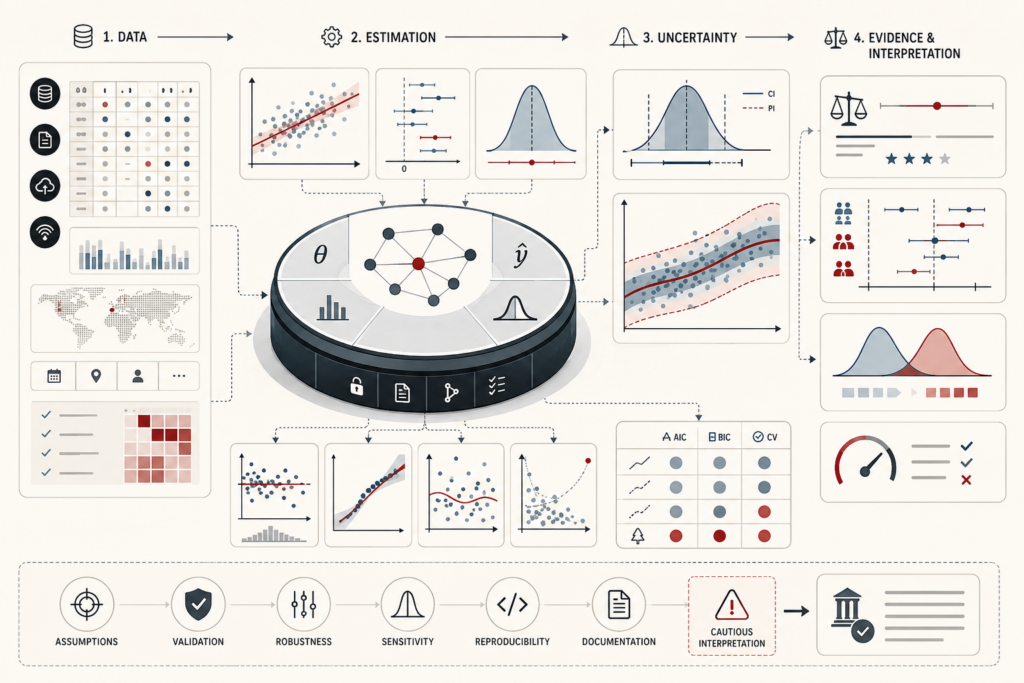
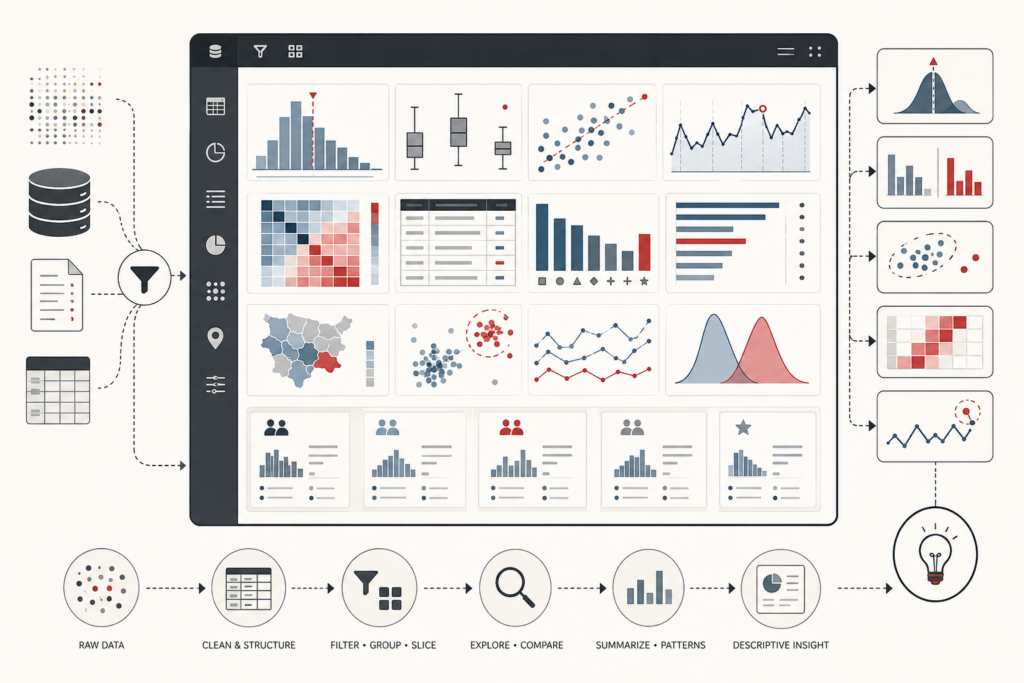
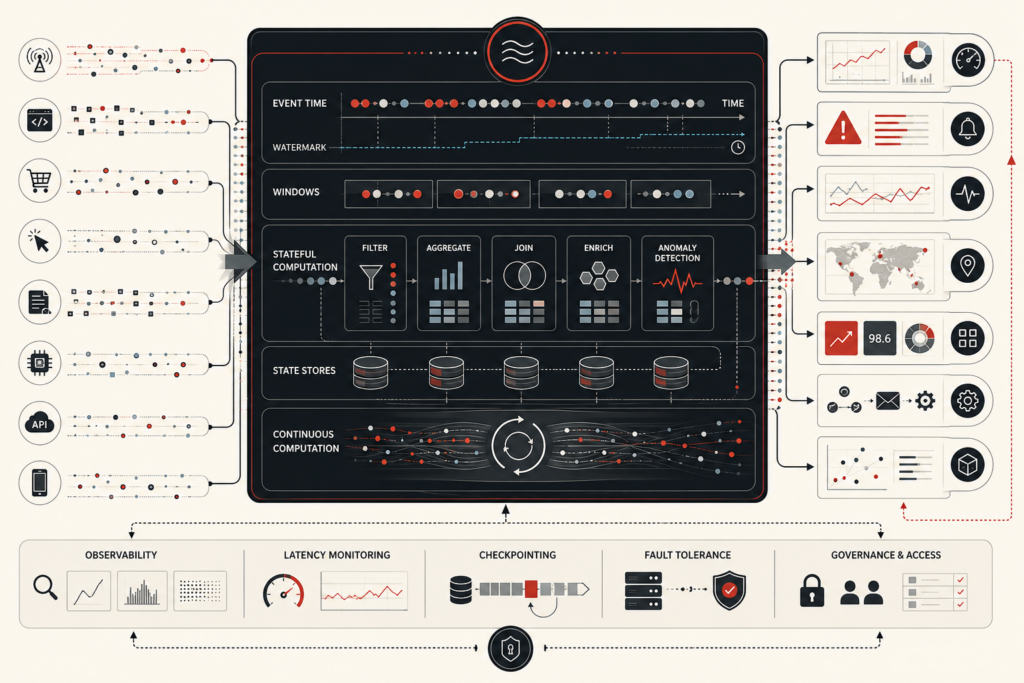
Model evaluation and performance metrics determine whether a predictive system is fit for the task it is meant to perform. This article frames evaluation not as a final scoreboard, but as model-quality evidence: the disciplined assessment of metrics, thresholds, calibration, error distributions, subgroup performance, monitoring drift, and governance limits. It explains why accuracy, precision, recall, ROC-AUC, average precision, Brier score, log loss, MAE, RMSE, and tail-error measures each answer different questions. The article also examines proper scoring rules, threshold policy, rare-event imbalance, calibration gaps, multiclass aggregation, metric uncertainty, lifecycle monitoring, and institutional accountability. A mathematical lens and Python/R workflows show how teams can evaluate classification behavior, probability quality, regression error, subgroup stability, monitoring flags, and risk-based model readiness.