
Last Updated May 11, 2026
Feature engineering and data representation are the disciplines through which raw observations are converted into forms that models can actually learn from. Predictive performance depends not only on algorithm choice, hyperparameter tuning, and validation design, but also on how the problem is represented before learning begins. A model does not learn directly from reality. It learns from encoded variables, transformed inputs, aggregated signals, derived interactions, temporal summaries, sparse vectors, embeddings, and numerical representations that stand in for the world. Feature engineering is the practice of constructing those representations. Data representation is the broader question of what form information takes when it becomes input to a learning system.
This topic matters because models can only exploit structure that their inputs make visible. A weak representation can make a learnable problem appear difficult, while a strong representation can allow even a relatively simple model to perform well. Representation determines how categories are encoded, how time is expressed, how nonlinearities are surfaced, how sparsity is handled, how interactions become visible, and whether the resulting feature space supports learning or obscures it. Good feature engineering makes patterns legible. Bad feature engineering can bury them, distort them, or leak future information into the model in ways that create the illusion of predictive power.
Main Library
Publications
Article Map
Data Systems & Analytics
Related Topic
Artificial Intelligence Systems
Related Topic
Data Systems & Analytics
Related Topic
Institutions & Governance
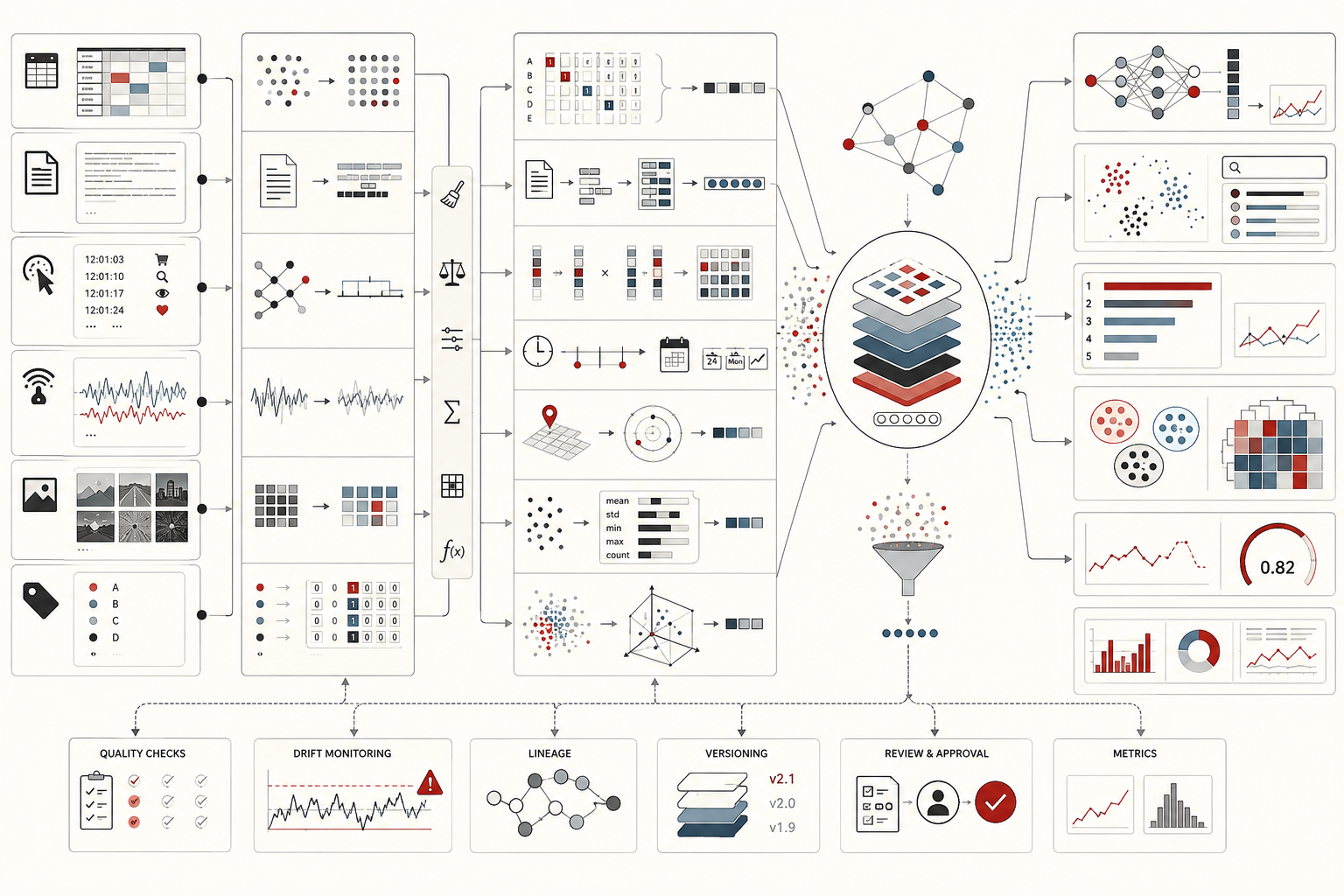
This article builds on the themes developed in Predictive Analytics and Machine Learning Models, Model Training and Validation, Model Evaluation and Performance Metrics, Data Cleaning and Data Quality Management, Reproducible Analytics and Versioned Data Workflows, and Data Governance and Stewardship. If model training explains how a learner fits parameters, and model evaluation explains whether the resulting system performs acceptably, feature engineering explains what the model is allowed to perceive in the first place.
Representation as model design
The strongest way to understand feature engineering is as model design before the model. A feature space is not a neutral translation of raw data into numbers. It is a structured proposal about what matters, what can be compared, what should be considered similar, what should be treated as distinct, what time horizon is relevant, and what signal should be available to the learning algorithm.
This matters because the learning algorithm only operates on what the representation supplies. If cyclical time is encoded as a simple integer, the model may not understand that 23:00 is close to 00:00. If a categorical variable is encoded as an arbitrary ordinal number, the model may infer false ordering. If a transaction history is collapsed into a single lifetime count, recency and trajectory may disappear. If a high-cardinality category is one-hot encoded without enough observations, sparsity may overwhelm learning. If a feature contains information from after the prediction time, the evaluation may look impressive while the deployed system fails.
Representation is therefore one of the most consequential and least visible parts of modeling. It is where domain knowledge, statistical reasoning, computational design, and governance discipline meet. A good representation makes relevant structure learnable. A poor representation can make the wrong structure easy to learn.
What feature engineering and data representation mean
Feature engineering is the process of creating, transforming, selecting, encoding, or aggregating variables so that they become useful inputs for modeling. Data representation is the broader question of how raw information becomes structured input for an algorithmic system. This includes the conversion of raw categories to vectors, text to tokens or embeddings, dates to cyclical features, continuous variables to transformed scales, transaction histories to recency-frequency summaries, and unstructured data to numerical representations.
Feature engineering includes familiar practices such as scaling, normalization, binning, one-hot encoding, feature crossing, lag creation, rolling aggregation, text vectorization, date decomposition, missingness indicators, target-independent smoothing, and domain-specific derived variables. Data representation also includes more general representational forms such as sparse matrices, embeddings, compressed components, learned latent spaces, images, sequences, graphs, and multimodal feature spaces.
The important distinction is that representation begins before feature selection. Feature selection chooses among already-constructed features. Feature engineering creates or transforms the representational space from which the model can learn. A model cannot select a signal that was never made visible.
Why representation matters
Representation matters because algorithms do not automatically discover every relevant structure. The same phenomenon can be encoded in ways that are more or less learnable depending on the model family, data volume, sample structure, and operational context. A linear model may struggle with raw cyclical variables but perform well once periodic structure is represented explicitly. A tree-based model may exploit thresholds naturally but still require well-defined categorical handling. A distance-based model may fail if variables are not scaled. A text model may depend critically on tokenization, vocabulary construction, and vectorization.
Representation also determines what kind of generalization becomes plausible. If a model sees only raw identifiers, it may memorize rather than learn transferable structure. If it sees derived rates, ratios, temporal recency, domain thresholds, or meaningful interactions, it may learn patterns that better reflect the system being modeled. Feature engineering is therefore not merely “preprocessing.” It is one of the primary places where modeling assumptions become material.
At a deeper level, representation affects the inductive bias of the learning system. It shapes which patterns are easy to detect, which interactions remain hidden, which forms of smoothness or discontinuity become natural, and which kinds of similarity are available. Representation can make learning easier by placing structure into the input space before training begins.
From raw data to model-usable features
Raw data often arrives in forms that are not immediately useful for conventional estimators: free text, timestamps, identifiers, nested logs, transaction histories, images, sparse categories, geospatial records, sensor streams, or heterogeneous business tables. Before these records can support modeling, they usually need to be converted into structured feature representations.
This conversion step is not merely technical. It determines which patterns the model can access. A transaction history can become a lifetime count, a recency-frequency-monetary summary, a lagged time series, a rolling window, a sequence embedding, or a graph representation. Each choice makes different forms of signal visible and suppresses others. A timestamp can become elapsed time, day of week, month, hour, season, holiday indicator, time since last action, or cyclical sine-cosine pair. A category can become one-hot columns, a frequency encoding, a hashing representation, an embedding, or a target-independent grouping.
Representation is therefore selective. It is an implicit theory of what information matters for the prediction task. The key question is not simply “can this raw field be converted into numbers?” It is “what numerical representation makes the relevant structure learnable without contaminating the evaluation or distorting the domain?”
Representation as inductive bias
Feature engineering places an inductive bias into the system before training begins. A binned feature says that threshold-like regions may matter more than tiny continuous variation. A one-hot encoding says that categories are discrete and unordered. A cyclical encoding says that closeness wraps around periodically rather than moving linearly from low to high. A feature cross says that interaction structure should be visible to the learner rather than hidden inside separate additive columns.
This matters because representation and model family work together. A strong representation can allow a relatively simple estimator to perform well by making important structure explicit. A weak representation can force a flexible estimator to spend capacity rediscovering structure that could have been encoded directly. In some cases, feature engineering substitutes for model complexity. In others, it prepares data for models that learn representations internally.
Representation choices are therefore epistemic choices. They determine what the model is allowed to consider similar, what kinds of variation are treated as meaningful, what is compressed, what is separated, and what is excluded. In serious modeling work, these choices deserve documentation and review because they shape the claims the model can later support.
Numerical features, scaling, and transformation
Numerical variables often seem straightforward, but they require representation choices too. Raw magnitude is not always the best representation for downstream learning. Some models are sensitive to scale. Some are helped by standardized inputs. Some benefit when skewed variables are log-transformed. Some require normalization because distance or gradient behavior depends on relative magnitude. Others can exploit raw thresholds but still benefit from derived rates, ratios, or winsorized values when outliers distort behavior.
Common numerical transformations include standard scaling, min-max scaling, robust scaling, log transforms, power transforms, quantile transforms, clipping, binning, spline features, polynomial expansions, and domain-specific ratios. Each transformation changes the geometry of the feature space. A log transform makes multiplicative differences more linear. A standard scaler makes variables comparable in magnitude. Binning can expose threshold behavior. Spline features can represent smooth nonlinear relationships. Ratios can express domain structure that raw columns obscure.
Good numerical feature engineering asks: does raw scale distort the model, does the variable have a nonlinear relationship with the outcome, does a threshold or regime change matter, does the variable require a denominator, and will the transformation be available consistently at prediction time?
Categorical data, one-hot encoding, and beyond
Categorical variables require special care because many algorithms require numerical input while categories represent discrete states, identities, labels, or vocabularies. One-hot encoding is one of the most common strategies: each category becomes its own indicator column, preserving category identity without imposing false numerical order.
But one-hot encoding is not always appropriate. When the number of categories is large, one-hot representation can become high-dimensional and sparse. It may increase memory cost, training time, inference latency, and overfitting risk. Rare categories may have too few examples for stable learning. Unknown categories may appear in production. A representation that works well for a small vocabulary can become fragile at enterprise scale.
Alternatives include grouping rare categories, out-of-vocabulary buckets, hashing, frequency encoding, ordinal encoding when genuine order exists, learned embeddings, and domain-driven category hierarchies. The right choice depends on cardinality, sample size, model family, interpretability needs, deployment constraints, and whether similarity among categories should be represented.
Categorical encoding is therefore never just formatting. It determines how difference, similarity, sparsity, and identity become numerical.
Feature crosses, interactions, and nonlinearity
Some patterns are conditional. The effect of one feature depends on another. A channel may matter differently by plan type. A region may matter differently by season. A device type may matter differently by time of day. A pricing variable may matter only for a certain customer segment. If these interactions are not visible in the representation, some model families may struggle to learn them.
Feature crosses make such interactions explicit by combining categorical or bucketed features. Crosses are especially useful for linear models because they allow nonlinear or conditional structure to enter the feature space without changing the estimator itself. Polynomial features, interaction terms, and crossed categories all perform variations of this logic: they add structure to the input space so the model can learn relationships that are not visible from raw additive features alone.
The risk is dimensional explosion. Crosses can rapidly increase sparsity and overfitting risk, especially when sample size is limited. Feature crosses should therefore be justified by domain logic, evaluated inside validation workflows, and reviewed for cardinality and stability. A cross that encodes meaningful interaction can improve learning. A cross that merely multiplies categories can create noise.
Embeddings and learned representations
Embeddings represent categories, tokens, entities, or other objects as dense numerical vectors. Instead of giving every category its own sparse column, an embedding maps each item into a lower-dimensional space where proximity can reflect learned similarity. This is especially useful for high-cardinality categorical variables, text, recommender systems, search, product catalogs, user histories, and language-model-based workflows.
Embeddings mark a conceptual shift. Instead of manually specifying all structure through engineered variables, the system learns a representation. This can improve performance, reduce dimensionality, and support richer notions of similarity. But it also changes the interpretive character of the feature space. A one-hot column is directly interpretable. A learned embedding dimension may not be. A dense vector may perform well while making it harder to explain which aspects of the original data matter.
Embeddings therefore sit between classical feature engineering and representation learning. They do not eliminate the need for feature governance. They increase the need to document training data, embedding model version, dimensionality, refresh cadence, downstream use, bias risk, drift monitoring, and whether the embedding is stable enough for the task.
Time, cycles, and structured temporal features
Temporal variables are rich because time is both ordered and cyclical. A raw timestamp can support many representations: elapsed time, tenure, recency, day of week, hour of day, month, season, holiday indicator, lagged value, rolling average, time since last event, time until expiration, or temporal cohort. Each representation answers a different analytical question.
Cyclical time deserves special treatment. Raw integer encodings of hour, month, or day can obscure the fact that the boundary wraps around. December is close to January. Sunday is close to Monday. Hour 23 is close to hour 0. Sine and cosine encodings can represent that circular structure:
x_{\sin} = \sin\left(\frac{2\pi t}{P}\right), \quad x_{\cos} = \cos\left(\frac{2\pi t}{P}\right)
\]
Interpretation: A cyclical time value \(t\) with period \(P\), such as hour of day or month of year, can be represented with sine and cosine features so that the model sees the periodic boundary correctly.
Temporal representation also creates leakage risk. Features must respect the prediction cutoff time. Aggregations should include only information available before prediction. If a feature uses future behavior, post-outcome events, or full-period statistics that would not exist in deployment, evaluation becomes contaminated. Temporal feature engineering is therefore one of the most important places where model validity and data governance meet.
High dimensionality, sparsity, and representation cost
Feature engineering often increases dimensionality. One-hot encodings, feature crosses, text vectors, hashed features, and interaction matrices can produce thousands or millions of possible columns. Many of these spaces are sparse: most observations activate only a small number of features.
Sparsity is not always bad. Sparse representations can be computationally efficient and statistically useful when paired with appropriate models and regularization. But sparsity has costs. It can increase memory demands, reduce statistical stability for rare features, create brittle category behavior, and make monitoring harder. High dimensionality can also make validation more fragile if the sample size is small relative to the feature space.
Representation cost should therefore be measured. Useful representation metrics include feature count, density, sparsity ratio, out-of-vocabulary rate, rare-category share, selected-feature share, leakage-flag count, and approved-feature share. These are not glamorous metrics, but they help teams understand whether a feature space is becoming too large, too sparse, too ungoverned, or too unstable for reliable use.
Feature selection and dimensional discipline
Once features exist, analysts often need to reduce them. Feature selection retains a subset of constructed features using univariate methods, model-based importance, regularization, recursive elimination, stability selection, domain review, or governance criteria. Selection can reduce noise, improve interpretability, shorten training time, and reduce overfitting risk.
But feature selection is not the same as feature engineering. Engineering creates the representation. Selection narrows it. A model cannot select a signal that was never represented. Conversely, feature engineering without selection can create a bloated and unstable feature space. The two practices should work together.
Feature selection also needs careful validation. If selection is performed before splitting data, or if selection uses the full dataset, leakage can enter the evaluation. Selection should happen inside the training workflow, with validation and test data transformed according to choices made from the training set. Dimensional discipline is therefore both statistical and procedural.
Dimensionality reduction and compression
Feature selection keeps a subset of original or engineered features. Dimensionality reduction creates a new lower-dimensional representation from the existing feature space. Principal components, matrix factorization, autoencoders, embeddings, topic models, and other compression techniques can reduce redundancy, manage collinearity, represent latent structure, and make high-dimensional problems more tractable.
Compression creates tradeoffs. It may improve generalization and computational efficiency, but it can weaken direct semantic interpretability. A principal component may summarize variation across many inputs but may not correspond neatly to a domain concept. An embedding may preserve useful similarity while making individual dimensions hard to explain. An autoencoder may compress signal effectively but require stronger monitoring and documentation.
The question is not whether compression is good or bad. The question is whether the compressed representation preserves the structure required by the task, avoids leakage, remains stable enough over time, and can be governed for the intended use.
Domain knowledge and derived variables
Some of the most powerful features are derived from domain knowledge rather than generic transformation routines. Ratios, rates, recency measures, grouped histories, exposure-adjusted measures, seasonality indicators, threshold flags, physical constraints, clinical summaries, financial ratios, supply-chain lags, and operational aggregates can make a problem more learnable because they represent structure that domain experts already understand.
This is where feature engineering becomes interdisciplinary. Good features often emerge from conversations among analysts, engineers, domain experts, operators, stewards, and reviewers. A raw field may have a misleading name. A value may be unavailable at prediction time. A ratio may require a denominator that changes across populations. A business rule may have changed halfway through the training window. Domain knowledge helps prevent technically valid transformations from becoming semantically wrong features.
Derived variables should therefore be documented like analytical claims. The feature registry should record source fields, transformation logic, cutoff time, owner, assumptions, known limitations, and review status. Domain-derived features can be powerful, but they must remain auditable.
Matching representation to model family
A “good” representation is partly defined by the model family it supports. Linear models often benefit from scaling, feature crosses, basis expansions, and explicit interactions because they learn additive relationships in the supplied feature space. Tree-based models often handle thresholds and monotonic splits more naturally, but they still depend on sensible categorical handling, temporal representation, and leakage-free derived variables. Distance-based methods require scaling and careful representation of similarity. Neural models may learn representations internally but still depend on input structure, normalization, tokenization, embeddings, and data volume.
This means representation and algorithm are coupled design choices. It is not enough to ask whether a feature is meaningful in the abstract. The feature must be meaningful for the estimator, validation design, deployment environment, and interpretability requirement. A dense embedding may help a neural recommender but be less useful for a regulated scorecard that requires direct explanation. A feature cross may help a linear model but be redundant for a sufficiently flexible tree ensemble. A raw numeric variable may work for a tree but require scaling for a distance-based method.
Modeling maturity comes from treating feature design and estimator choice as one integrated system.
Representation failure modes and leakage risk
Feature engineering fails in recognizable ways. A representation may impose false order on categories, hide cyclical structure, collapse distributions into misleading averages, explode dimensionality without enough data, underrepresent rare but important cases, overfit to noise, or create features that are unavailable at prediction time.
The most dangerous failure is leakage. Leakage occurs when the feature space contains information that would not legitimately be available when the model is used. This can happen through post-outcome variables, future aggregations, full-dataset statistics, target-derived encodings, validation leakage during feature selection, or preprocessing fitted before data splitting. Leakage is dangerous because it can produce impressive validation scores that disappear in deployment.
A feature can be highly predictive and still invalid. Predictiveness is not enough. The feature must be available, legitimate, stable, and consistent with the prediction setting. Feature engineering is therefore part of model evaluation discipline. A model cannot be considered trustworthy if its representation violates time, availability, or governance constraints.
A mathematical lens for representation integrity
Feature engineering can be understood mathematically as a transformation from raw observations to model input:
X^{*} = \phi(X)
\]
Interpretation: Raw data \(X\) becomes model-usable representation \(X^{*}\) through a transformation function \(\phi\). Feature engineering is the design, documentation, validation, and governance of \(\phi\).
A feature space can be evaluated by representation integrity:
R_j = w_A A_j + w_L L_j + w_T T_j + w_Q Q_j + w_I I_j + w_S S_j
\]
Interpretation: Representation integrity \(R_j\) for feature \(j\) can combine prediction-time availability \(A_j\), leakage safety \(L_j\), transformation validity \(T_j\), quality checks \(Q_j\), interpretability \(I_j\), and stability \(S_j\).
Leakage can be represented as an availability condition:
A_j(t_p) =
\begin{cases}
1, & \text{if feature } j \text{ is available at prediction time } t_p \\
0, & \text{otherwise}
\end{cases}
\]
Interpretation: A feature should be treated as invalid for prediction if it is not available at prediction time, even if it is strongly predictive during offline analysis.
Feature crossing expands categorical feature space:
|X_{a \times b}| = |X_a| \cdot |X_b|
\]
Interpretation: Crossing two categorical features multiplies cardinality. Feature crosses can reveal interactions, but they can also increase sparsity and overfitting risk.
Sparsity can be summarized as:
S = 1 – \frac{\text{nonzero entries}}{\text{total entries}}
\]
Interpretation: Sparse representations can be efficient and useful, but high sparsity should be monitored because rare or thinly observed features may produce unstable learning.
A governance-oriented representation score can combine technical and operational checks:
G = \alpha R + \beta P + \gamma M – \delta H
\]
Interpretation: A representation governance score \(G\) can combine representation integrity \(R\), prediction-time parity \(P\), monitoring readiness \(M\), and leakage or harm flags \(H\). The point is not to replace judgment, but to make review criteria explicit.
This mathematical lens makes feature engineering less mysterious. A feature space is not just “the data.” It is a transformation system whose assumptions, risks, and costs can be evaluated.
Python Workflow: Feature Engineering Scorecard
The following Python workflow demonstrates how a feature engineering process can create simple numerical, categorical, crossed, temporal, and leakage-review features while producing a representation integrity scorecard.
#!/usr/bin/env python3
"""
Python Workflow: Feature Engineering Scorecard
This compact workflow shows how raw observations can be converted into
engineered features while preserving representation integrity checks.
"""
from __future__ import annotations
import math
from dataclasses import dataclass
from datetime import datetime, timezone
@dataclass
class RawObservation:
entity_id: str
event_time: str
signup_time: str
region: str
channel: str
plan_type: str
monthly_spend: float
events_30d: int
days_since_last_event: int
def parse_dt(value: str) -> datetime:
return datetime.fromisoformat(value.replace("Z", "+00:00"))
def cyclical_hour_features(timestamp: str) -> tuple[float, float]:
hour = parse_dt(timestamp).hour
return (
math.sin(2 * math.pi * hour / 24),
math.cos(2 * math.pi * hour / 24),
)
def bucket_days_since_last_event(days: int) -> str:
if days <= 7:
return "0_7"
if days <= 14:
return "8_14"
return "15_plus"
def engineer_features(row: RawObservation) -> dict[str, object]:
event_time = parse_dt(row.event_time)
signup_time = parse_dt(row.signup_time)
hour_sin, hour_cos = cyclical_hour_features(row.event_time)
return {
"entity_id": row.entity_id,
"log_monthly_spend": round(math.log1p(row.monthly_spend), 6),
"days_since_last_event_bucket": bucket_days_since_last_event(row.days_since_last_event),
"region_one_hot_key": f"region={row.region}",
"channel_plan_cross": f"{row.channel}__{row.plan_type}",
"event_hour_sin": round(hour_sin, 6),
"event_hour_cos": round(hour_cos, 6),
"tenure_days": (event_time - signup_time).days,
}
def feature_available_at_prediction_time(feature_name: str) -> bool:
invalid_features = {"future_support_ticket_count", "post_outcome_refund_count"}
return feature_name not in invalid_features
def representation_integrity(
status_score: float,
leakage_safety: float,
transformation_validity: float,
quality_score: float,
selection_score: float,
) -> float:
return round(
0.25 * status_score
+ 0.25 * leakage_safety
+ 0.25 * transformation_validity
+ 0.15 * quality_score
+ 0.10 * selection_score,
3,
)
def main() -> None:
row = RawObservation(
entity_id="u001",
event_time="2026-01-15T10:00:00Z",
signup_time="2025-05-01T08:00:00Z",
region="north",
channel="organic",
plan_type="basic",
monthly_spend=29.0,
events_30d=18,
days_since_last_event=2,
)
print(engineer_features(row))
feature_scores = {
"log_monthly_spend": representation_integrity(1.0, 1.0, 1.0, 1.0, 1.0),
"channel_plan_cross": representation_integrity(0.7, 0.6, 0.7, 0.6, 0.7),
"future_support_ticket_count": representation_integrity(0.15, 0.0, 0.0, 0.0, 0.0),
}
print(feature_scores)
for feature_name in feature_scores:
print(
feature_name,
"available_at_prediction_time=",
feature_available_at_prediction_time(feature_name),
)
if __name__ == "__main__":
main()
This workflow shows that feature engineering is not only about creating more columns. It is about preserving the relationship among raw data, transformation logic, cutoff time, leakage risk, feature status, and model use. A feature that improves offline performance but fails prediction-time availability is not a useful feature; it is a contaminated evaluation artifact.
R Workflow: Feature Registry, Encoding, Leakage, Selection, and Representation Summary
The following R workflow summarizes feature families, transformation rules, quality checks, selection status, and representation metrics. It supports a recurring review process: which features are approved, which transformations are fitted safely, which features carry leakage risk, which encodings are high-cardinality, and which representation sets are sparse, unapproved, or revision-prone?
#!/usr/bin/env Rscript
# R Workflow: Feature Registry, Encoding, Leakage, Selection,
# and Representation Summary
registry <- data.frame(
feature_id = c(
"feat001", "feat002", "feat003", "feat004", "feat005",
"feat006", "feat007", "feat008", "feat009", "feat010"
),
feature_family = c(
"numerical", "numerical", "numerical_binned", "categorical",
"categorical_cross", "temporal", "temporal", "embedding",
"leakage_candidate", "numerical"
),
status = c(
"approved", "approved", "in_review", "approved", "in_review",
"approved", "approved", "planned", "needs_revision", "approved"
),
leakage_risk = c(
"low", "low", "low", "low", "medium",
"low", "low", "medium", "high", "low"
),
stringsAsFactors = FALSE
)
rules <- data.frame(
rule_id = paste0("rule", sprintf("%03d", 1:10)),
rule_type = c(
"numerical_transform", "standard_scaler", "binner",
"one_hot_encoder", "feature_cross", "cyclical_encoding",
"cyclical_encoding", "embedding_model", "post_outcome_aggregation",
"date_difference"
),
fit_scope = c(
"training_only", "training_only", "training_only", "training_only",
"training_only", "no_fit", "no_fit", "training_only",
"full_dataset", "no_fit"
),
allowed_at_prediction_time = c(
TRUE, TRUE, TRUE, TRUE, TRUE, TRUE, TRUE, TRUE, FALSE, TRUE
),
review_status = c(
"approved", "approved", "in_review", "approved", "in_review",
"approved", "approved", "planned", "needs_revision", "approved"
),
stringsAsFactors = FALSE
)
checks <- data.frame(
check_id = paste0("chk", sprintf("%03d", 1:6)),
check_type = c(
"missingness", "scale_fit", "bin_coverage",
"oov_handling", "cardinality", "leakage_check"
),
status = c("pass", "pass", "warn", "pass", "warn", "fail"),
severity = c("medium", "high", "medium", "medium", "medium", "critical"),
stringsAsFactors = FALSE
)
selection <- data.frame(
selection_id = paste0("sel", sprintf("%03d", 1:6)),
selection_method = c(
"mutual_information", "mutual_information", "mutual_information",
"chi_square", "regularized_model", "mutual_information"
),
selected = c(TRUE, TRUE, TRUE, TRUE, TRUE, FALSE),
selection_status = c("approved", "approved", "in_review", "approved", "in_review", "blocked_leakage"),
stringsAsFactors = FALSE
)
representations <- data.frame(
representation_name = c(
"baseline_numeric",
"categorical_one_hot",
"feature_cross_expanded",
"embedding_candidate",
"legacy_feature_set"
),
feature_count = c(4, 12, 24, 128, 18),
sparsity_ratio = c(0.08, 0.75, 0.86, 0.00, 0.69),
oov_rate = c(0.00, 0.02, 0.04, 0.00, 0.08),
leakage_flag_count = c(0, 0, 0, 0, 1),
approved_feature_share = c(1.00, 0.92, 0.75, 0.40, 0.50),
status = c("approved", "approved", "in_review", "planned", "needs_revision"),
stringsAsFactors = FALSE
)
family_summary <- aggregate(
feature_id ~ feature_family + status + leakage_risk,
data = registry,
FUN = length
)
names(family_summary) <- c(
"feature_family",
"status",
"leakage_risk",
"feature_count"
)
rule_summary <- aggregate(
rule_id ~ rule_type + fit_scope + allowed_at_prediction_time + review_status,
data = rules,
FUN = length
)
names(rule_summary) <- c(
"rule_type",
"fit_scope",
"allowed_at_prediction_time",
"review_status",
"rule_count"
)
quality_summary <- aggregate(
check_id ~ check_type + status + severity,
data = checks,
FUN = length
)
names(quality_summary) <- c("check_type", "status", "severity", "check_count")
selection_summary <- aggregate(
selection_id ~ selection_method + selected + selection_status,
data = selection,
FUN = length
)
names(selection_summary) <- c(
"selection_method",
"selected",
"selection_status",
"feature_count"
)
representation_summary <- aggregate(
cbind(feature_count, sparsity_ratio, oov_rate, leakage_flag_count, approved_feature_share) ~ status,
data = representations,
FUN = mean
)
dir.create("outputs", showWarnings = FALSE, recursive = TRUE)
write.csv(family_summary, "outputs/feature_family_summary_r.csv", row.names = FALSE)
write.csv(rule_summary, "outputs/transformation_rule_summary_r.csv", row.names = FALSE)
write.csv(quality_summary, "outputs/feature_quality_summary_r.csv", row.names = FALSE)
write.csv(selection_summary, "outputs/feature_selection_summary_r.csv", row.names = FALSE)
write.csv(representation_summary, "outputs/representation_summary_r.csv", row.names = FALSE)
cat("Wrote feature engineering registry, rule, quality, selection, and representation summaries.\n")
This workflow treats the feature set as an auditable design object. It does not only ask which features exist. It asks how they were produced, whether they are available at prediction time, whether they carry leakage risk, whether they are approved, and whether the representation is becoming too sparse or under-governed.
Feature engineering in the analytical workflow
Feature engineering belongs throughout the analytical workflow. During exploration, it helps analysts discover which structures may matter. During model development, it shapes the hypothesis space available to the learner. During validation, it must be embedded inside pipelines so transformations are fitted and applied correctly. During deployment, it becomes part of the operational interface between source data systems and model behavior. During monitoring, feature distributions, missingness, OOV rates, drift, and prediction-time availability must be watched.
This lifecycle view matters because feature engineering often becomes institutional infrastructure. Once a feature is used in production, it is no longer a notebook trick. It is a reusable representation that depends on source systems, transformation jobs, scheduling, lineage, ownership, monitoring, and review. If the source definition changes, the model may change. If the pipeline fails, predictions may degrade. If a category appears that was not present in training, the representation may behave unexpectedly.
Feature engineering therefore connects data systems to machine learning systems. It is the bridge between raw operational data and model input. That bridge must be versioned, tested, monitored, and governed.
Feature stores, lineage, and operational representation
In mature environments, feature engineering often moves from ad hoc scripts into feature stores, transformation pipelines, registries, or shared semantic layers. This shift is important because the same feature may be used across multiple models, reports, monitoring systems, and decision tools. Shared features need definitions, owners, freshness expectations, offline/online consistency, training-serving parity, lineage, and approval status.
Feature lineage should connect raw source fields to transformed feature values, training datasets, validation runs, model versions, and monitoring records. Without lineage, it becomes difficult to explain why a model changed, whether a feature was available at prediction time, whether a transformation was refit incorrectly, or which downstream models are affected by a source-system change.
Feature stores and registries do not solve representation design by themselves. They make representation operationally manageable. The intellectual work remains: deciding what the feature means, how it should be computed, whether it is valid, and what risks it carries. The operational layer helps preserve those decisions over time.
Governance and institutional accountability
Feature engineering becomes a governance issue whenever model outputs affect decisions, resources, services, opportunities, risk review, public systems, or human welfare. Representation choices can affect who is visible to the model, which histories matter, which signals are privileged, which proxies enter the system, and which forms of error become likely. A feature may be technically legal but ethically questionable, statistically useful but operationally unstable, or predictive because it encodes a proxy for a sensitive or institutionally problematic factor.
Governance should therefore review more than final model scores. It should review features, transformations, cutoff times, proxies, source systems, missingness patterns, category behavior, embeddings, drift, and operational availability. A high-performing model built on invalid or harmful representation is not a trustworthy system.
This does not mean every feature requires a formal committee. It means consequential features need accountable owners, documentation, review status, lineage, and monitoring. Feature engineering is part of the evidentiary basis for model use. It should be visible enough that later reviewers can understand what the model was allowed to learn from.
Applications across domains
Feature engineering matters across predictive domains. In finance, models may depend on ratios, exposure measures, payment histories, recency indicators, risk buckets, and interaction terms. In healthcare, features may summarize clinical histories, lab trends, medication exposures, time since diagnosis, or clinically meaningful thresholds. In operations, telemetry may need lags, rolling averages, event counts, anomaly windows, seasonality flags, and sensor-derived features. In marketing and customer analytics, recency-frequency-monetary summaries, channel interactions, tenure, engagement windows, and plan transitions may matter. In text, search, and recommender systems, tokenization, vectorization, embeddings, and sequence representations shape what semantic structure is visible.
In public systems, representation choices can shape not only performance but fairness, interpretability, and accountability. A model may fail to represent people, neighborhoods, institutions, or histories adequately if raw data reflects unequal measurement, biased collection, missingness, or proxy structure. Feature engineering can either surface these issues or hide them. It is therefore not a purely technical activity.
Across domains, the central question remains the same: what representation makes the relevant signal learnable without distorting the problem, contaminating evaluation, or hiding critical structure from downstream reasoning?
Implementation principles for high-integrity feature engineering
Start with prediction time. Define when the prediction is made before deciding which features are valid.
Document raw-to-feature lineage. Every consequential feature should connect to source fields, transformation logic, owner, and review status.
Fit transformations only on training data. Scaling, selection, imputation, encoding vocabularies, and learned transformations should be fit within the training workflow and applied to validation and test data.
Represent categories without false order. Use one-hot encoding, grouping, hashing, or embeddings when unordered categories should not be treated as ranked numbers.
Control high cardinality. Track sparsity, rare categories, OOV rates, feature count, and sample size per category.
Expose temporal structure carefully. Use recency, lags, rolling windows, and cyclical encodings where appropriate, but ensure all time-derived features respect the prediction cutoff.
Use feature crosses when interactions matter. Crosses should be justified by domain logic or validation evidence, not added indiscriminately.
Review embeddings as learned infrastructure. Document embedding model, dimension, training data, refresh cadence, intended use, and drift concerns.
Separate feature engineering from feature selection. Engineering creates representation; selection narrows it. Both should occur inside valid workflows.
Treat leakage as a blocking issue. A feature that is unavailable, future-derived, target-derived, or post-outcome should be blocked no matter how predictive it appears.
| Control | Purpose | Failure it prevents |
|---|---|---|
| Prediction-time availability check | Confirms that features exist when the model is used | Future-derived or deployment-unavailable features |
| Training-only transform fitting | Fits scalers, imputers, selectors, and encoders without validation leakage | Full-dataset preprocessing contamination |
| Feature registry | Records feature name, source, transformation, owner, status, and risk | Orphaned features and undocumented model inputs |
| Categorical encoding review | Checks one-hot, OOV, hashing, grouping, and embedding choices | False ordinal meaning and high-cardinality instability |
| Temporal cutoff review | Ensures lags, windows, recency, and cycles respect prediction time | Temporal leakage and invalid retrospective features |
| Dimensionality and sparsity review | Tracks feature count, density, rare categories, and sample support | Overfit sparse representations and unstable feature crosses |
| Selection-inside-validation workflow | Performs feature selection without peeking at validation/test data | Selection leakage and inflated model performance |
| Representation monitoring | Tracks missingness, drift, OOV rate, source changes, and feature freshness | Production decay hidden behind stale feature assumptions |
GitHub Repository
This article can be paired with a companion code workflow that models feature engineering as representation-integrity infrastructure. The example includes raw observations, feature registries, transformation rules, feature quality checks, selection scores, representation metrics, SQL schemas, scorecard scripts, typed contracts, Quarto report templates, leakage checklists, representation review canvases, and multi-language examples across Python, R, Julia, SQL, Go, Rust, C, C++, TypeScript, and Terraform placeholders.
The companion repository provides a vendor-neutral feature engineering and data representation scaffold with numerical transformations, categorical encodings, feature crosses, cyclical time features, leakage checks, feature registry review, representation readiness scoring, SQL governance queries, reproducible reporting templates, typed contracts, documentation, and CI smoke-test patterns.
Conclusion
Feature engineering and data representation are central to trustworthy predictive analytics because models learn from representations, not from reality itself. The form of the input space determines which structures are visible, which similarities are meaningful, which interactions can be learned, which temporal patterns can be detected, and which risks may enter the model unnoticed.
The deeper point is that representation is not preprocessing trivia. It is part of model design, model evaluation, and model governance. Numerical transformations, categorical encodings, temporal features, feature crosses, embeddings, derived variables, selection methods, compression techniques, and leakage checks all shape model behavior before training begins. High-integrity feature engineering makes these choices explicit, reviewable, and operationally stable. In data-intensive organizations, that is not merely a modeling skill. It is a condition of responsible machine-learning practice.
Related articles
- Data Systems and Analytics knowledge series
- Predictive Analytics and Machine Learning Models
- Model Training and Validation
- Model Evaluation and Performance Metrics
- Data Cleaning and Data Quality Management
- Reproducible Analytics and Versioned Data Workflows
- Data Governance and Stewardship
Further reading
- Bishop, C.M. (2006) Pattern Recognition and Machine Learning. New York: Springer.
- Hastie, T., Tibshirani, R. and Friedman, J. (2009) The Elements of Statistical Learning. 2nd edn. New York: Springer.
- James, G., Witten, D., Hastie, T. and Tibshirani, R. (2021) An Introduction to Statistical Learning. 2nd edn. New York: Springer.
- Molnar, C. (2024) Interpretable Machine Learning. 2nd edn. Available at: https://christophm.github.io/interpretable-ml-book/
- Murphy, K.P. (2012) Machine Learning: A Probabilistic Perspective. Cambridge, MA: MIT Press.
- NIST (2023) Artificial Intelligence Risk Management Framework (AI RMF 1.0). Gaithersburg, MD: National Institute of Standards and Technology.
References
- scikit-learn developers (n.d.) Feature extraction. Available at: https://scikit-learn.org/stable/modules/feature_extraction.html
- scikit-learn developers (n.d.) Preprocessing data. Available at: https://scikit-learn.org/stable/modules/preprocessing.html
- scikit-learn developers (n.d.) Feature selection. Available at: https://scikit-learn.org/stable/modules/feature_selection.html
- scikit-learn developers (n.d.) Time-related feature engineering. Available at: https://scikit-learn.org/stable/auto_examples/applications/plot_cyclical_feature_engineering.html
- Google for Developers (2025) Categorical data: Vocabulary and one-hot encoding. Available at: https://developers.google.com/machine-learning/crash-course/categorical-data/one-hot-encoding
- Google for Developers (2025) Categorical data: Feature crosses. Available at: https://developers.google.com/machine-learning/crash-course/categorical-data/feature-crosses
- Google for Developers (2026) Obtaining embeddings. Available at: https://developers.google.com/machine-learning/crash-course/embeddings/obtaining-embeddings
- Google for Developers (2025) Numerical data: Binning. Available at: https://developers.google.com/machine-learning/crash-course/numerical-data/binning
- Hastie, T., Tibshirani, R. and Friedman, J. (2009) The Elements of Statistical Learning. Available at: https://hastie.su.domains/pub.htm
- NIST (2023) Artificial Intelligence Risk Management Framework (AI RMF 1.0). Available at: https://nvlpubs.nist.gov/nistpubs/ai/nist.ai.100-1.pdf
- NIST (n.d.) AI RMF Playbook. Available at: https://www.nist.gov/itl/ai-risk-management-framework/nist-ai-rmf-playbook
- NIST (2024) Artificial Intelligence Risk Management Framework: Generative Artificial Intelligence Profile. Available at: https://nvlpubs.nist.gov/nistpubs/ai/NIST.AI.600-1.pdf