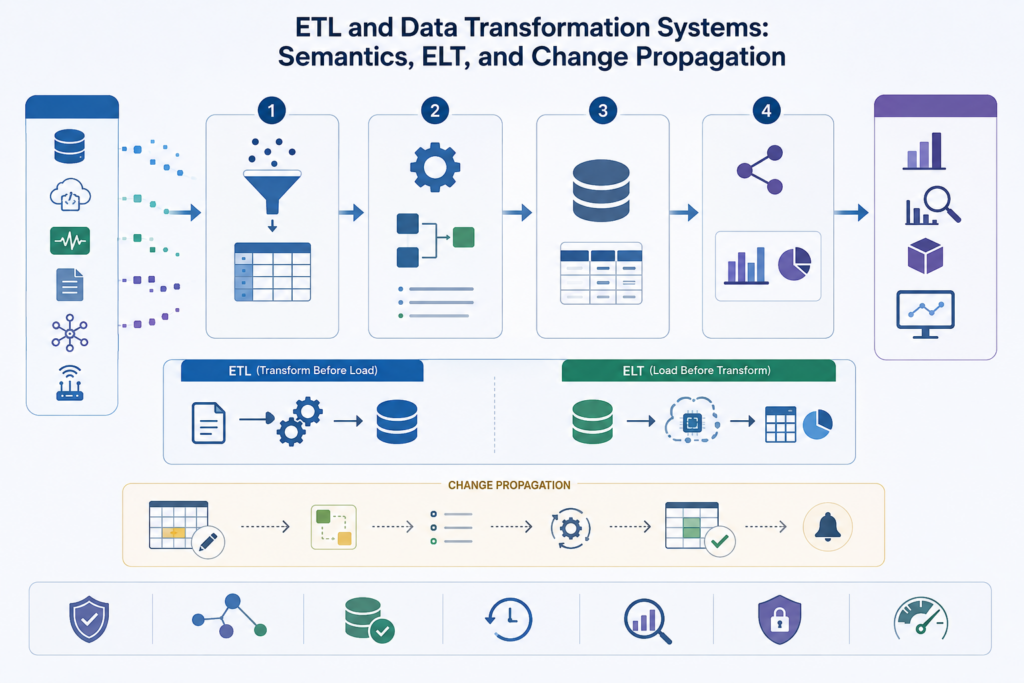
ETL and Data Transformation Systems: Semantics, ELT, and Change Propagation
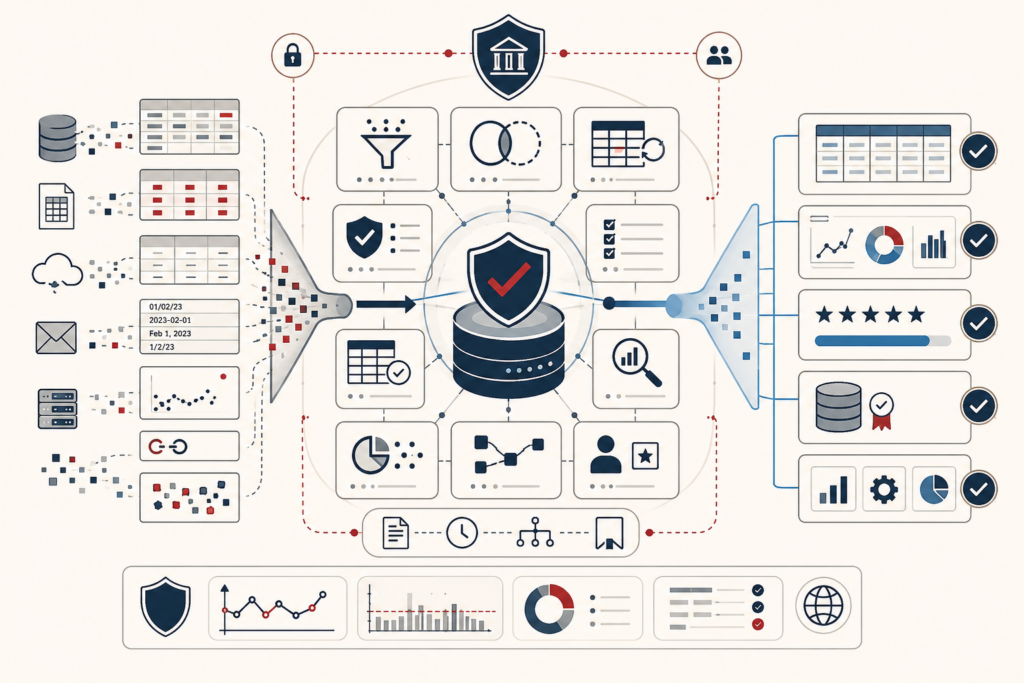
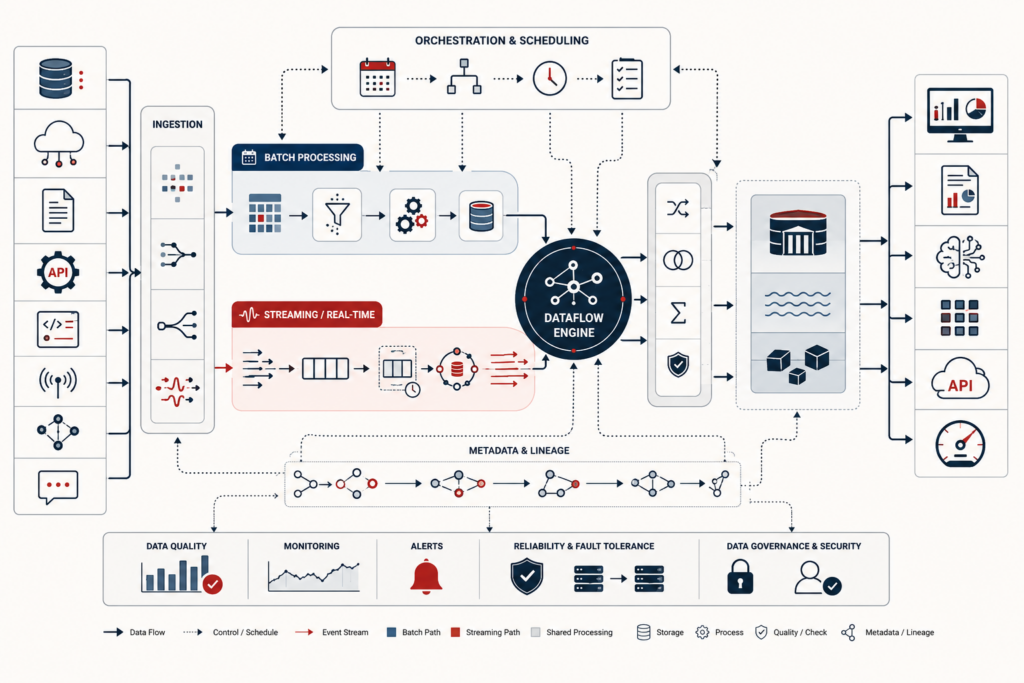
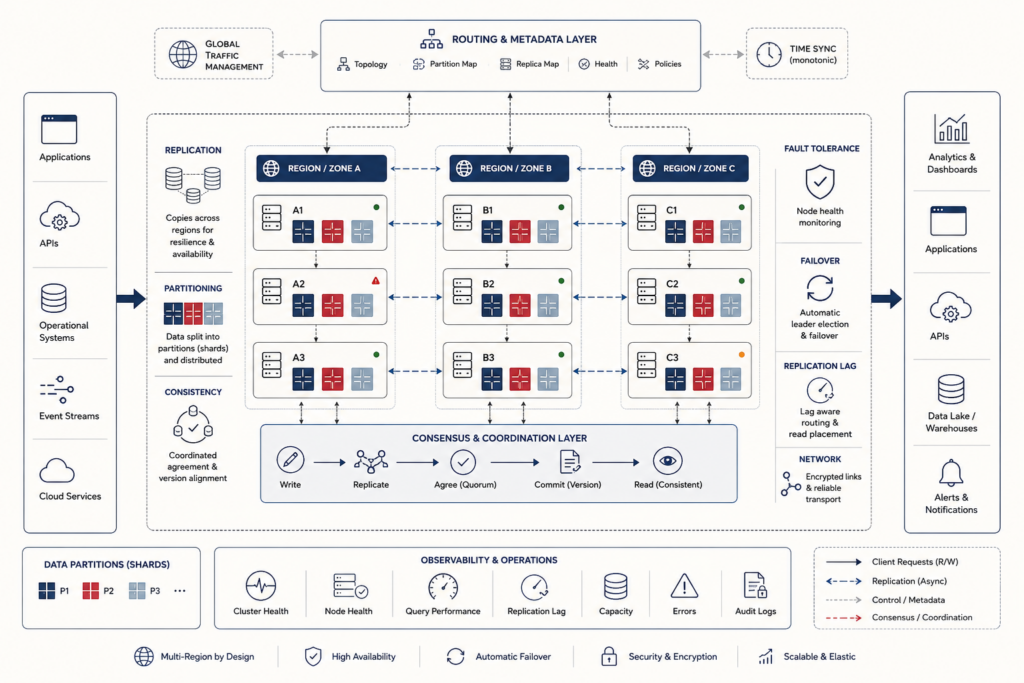
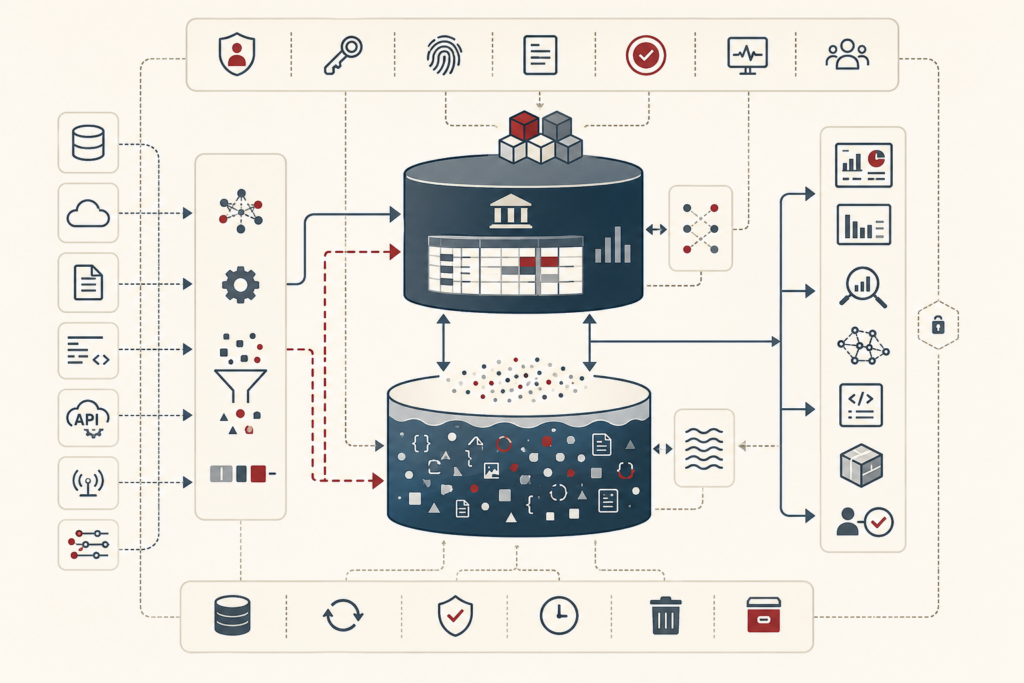
ETL and data transformation systems convert heterogeneous operational data into governed, analyzable, and reusable downstream state. This article frames ETL not as background plumbing, but as semantic infrastructure: the executable layer where source records are extracted, staged, mapped, cleansed, validated, conformed, merged, and loaded into canonical targets. It explains why source systems rarely share analytical meaning, why transformation logic stabilizes institutional definitions, and how ETL/ELT patterns differ in where computation occurs. The article also examines staging areas, canonical models, target schemas, data quality gates, surrogate keys, slowly changing state, CDC, idempotent merge logic, replay, orchestration, lineage, rejected-record quarantine, and transformation governance. Mathematical examples and Python/R workflows show how teams can evaluate mapping coverage, rejected records, CDC operations, canonical outputs, lineage records, transformation tests, and ETL-readiness scores.