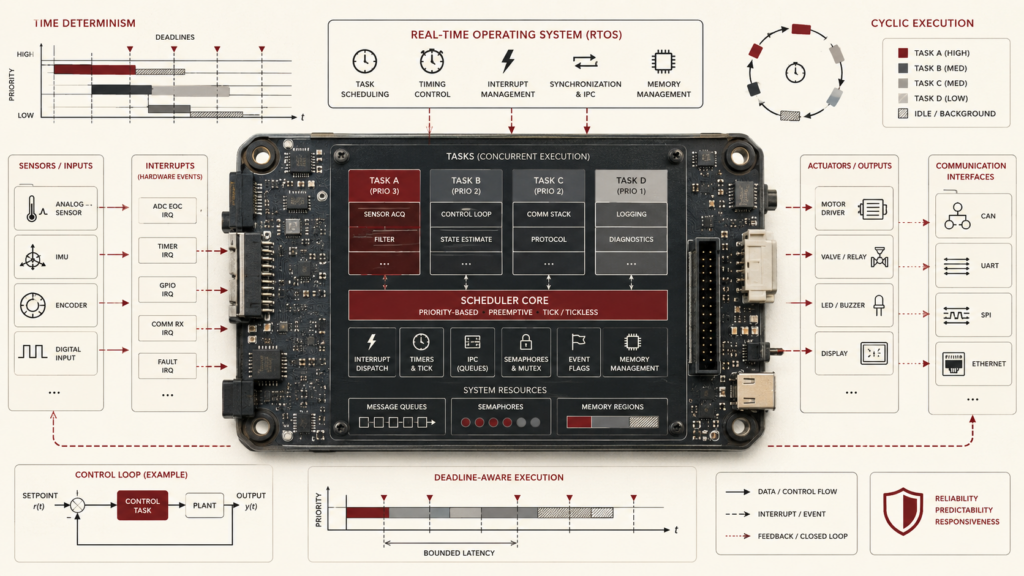
Real-Time Operating Systems in Embedded Computing
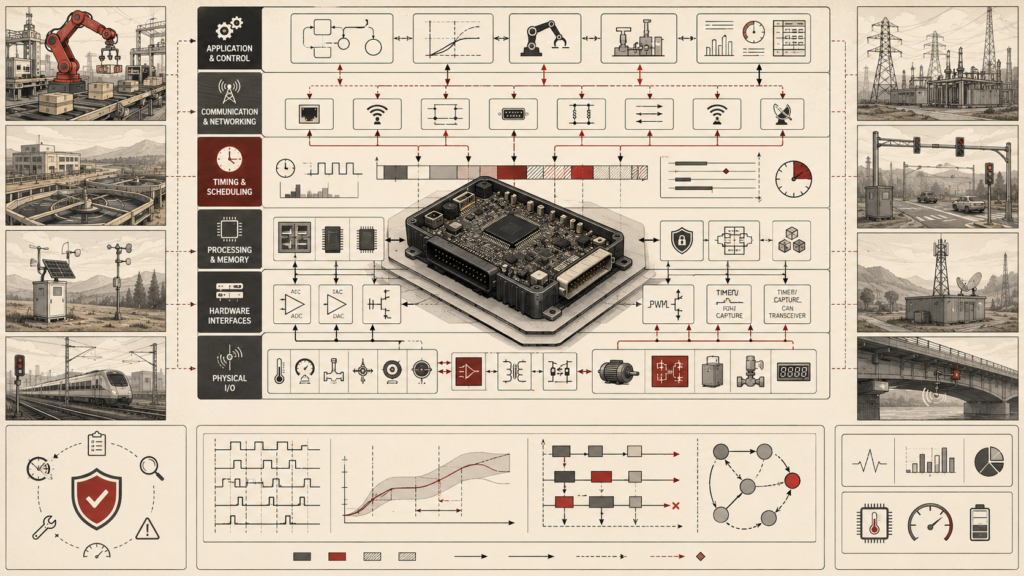
Real-time operating systems structure embedded software so devices can coordinate tasks, interrupts, timing, synchronization, memory, and power behavior within defined temporal bounds. This article frames the RTOS as a temporal control architecture rather than a generic multitasking convenience. It examines task models, priorities, schedulability, worst-case execution time, response time, jitter, interrupt latency, deferred work, synchronization hazards, priority inversion, stack discipline, queue sizing, tickless idle, sleep coordination, runtime tracing, and field telemetry. The article also introduces mathematical models, Python and R workflows, systems-code scaffolding, and verification gates for designing embedded systems whose concurrency remains bounded, observable, power-aware, and testable under realistic operating conditions.