
Last Updated May 11, 2026
Distributed data systems exist because a single machine, a single disk, or a single database instance eventually becomes an architectural limit. As data volumes grow, workloads intensify, users become geographically dispersed, and uptime expectations harden, organizations are forced to move beyond centralized storage toward systems that partition data across nodes, replicate state across machines or regions, and coordinate reads and writes under conditions of latency, failure, and uncertainty. Distributed data systems are therefore not merely “bigger databases.” They are a distinct class of information architecture defined by the need to preserve useful data behavior even when computation and storage are spread across multiple networked components.
The field matters because modern analytical and operational systems rarely live in one place. Cloud platforms span regions and availability zones. Digital services require continuous uptime despite hardware failure. Sensor networks and global applications generate geographically distributed streams of state. Machine learning pipelines, event platforms, and large-scale transactional systems all depend on data architectures that can continue functioning when nodes fail, networks delay, clocks drift, replicas lag, or parts of the system become temporarily unreachable. The central question is therefore not whether data can be stored, but how data can remain available, durable, consistent enough, performant, recoverable, and explainable under distribution.
Main Library
Publications
Article Map
Data Systems & Analytics
Related Topic
Database Architecture
Related Topic
Data Pipelines
Related Topic
Streaming Analytics
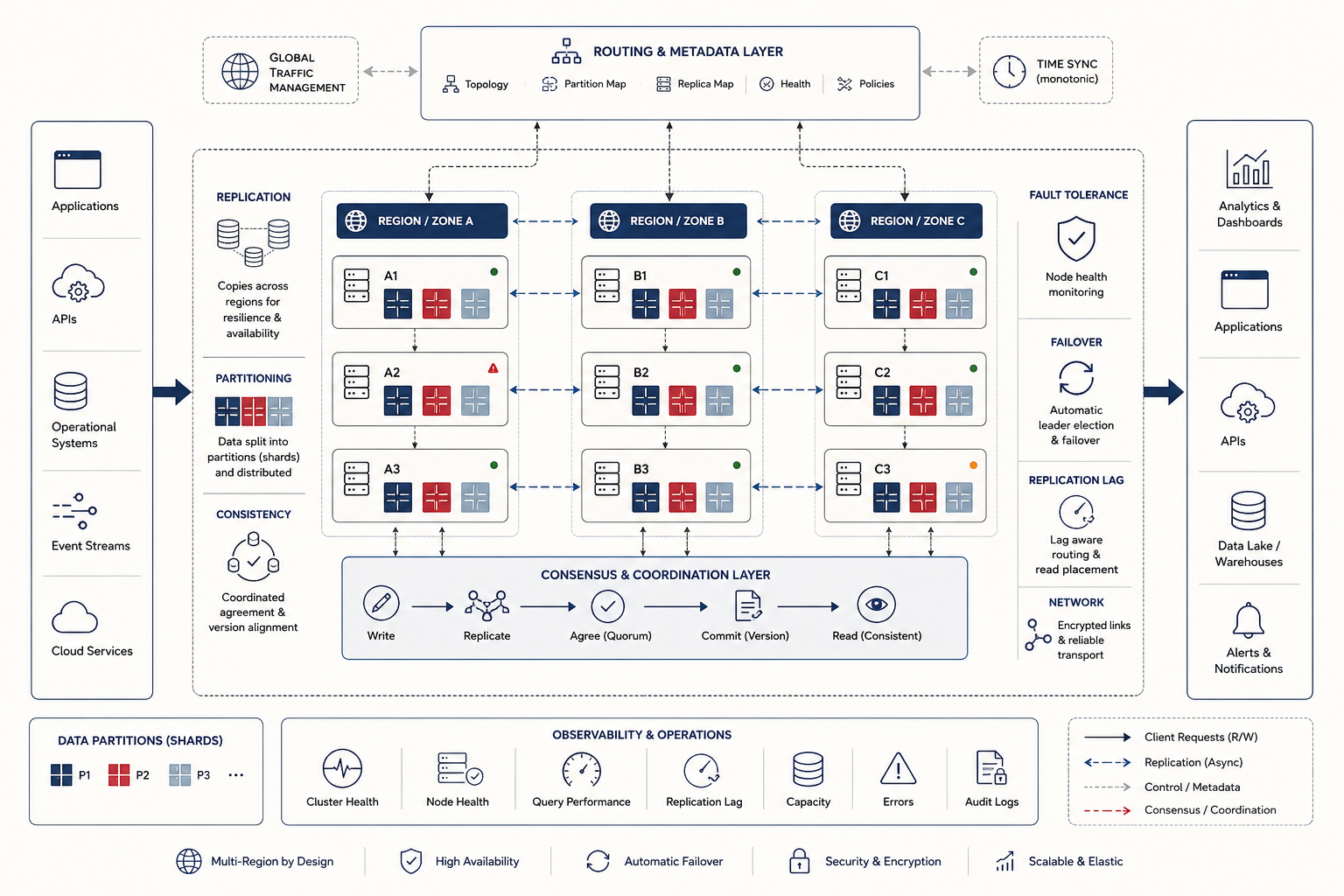
Distributed data systems are shaped by persistent tensions. Data can be replicated for durability and low-latency access, but replication creates coordination problems. Data can be partitioned for scale, but partitioning complicates cross-partition queries and transactions. Systems can favor strong consistency, but stronger coordination adds latency and can reduce availability under partition. Systems can favor availability and partition tolerance, but then must confront stale reads, conflict resolution, and weaker guarantees. The architecture of a distributed data system is therefore an exercise in disciplined tradeoff rather than universal optimization.
This article should be read alongside Database Systems and Data Architecture, Relational Databases and SQL Systems, Data Warehouses and Data Lakes, Data Pipelines and Data Processing Systems, Streaming Data and Real-Time Analytics, Cloud Data Platforms and Modern Data Stack Architecture, Metadata, Data Catalogs, and Lineage, and Reproducible Analytics and Versioned Data Workflows. Distribution is where data architecture becomes explicitly concerned with failure, geography, coordination, latency, and recoverable state.
Distribution as coordination under failure
The strongest way to understand distributed data systems is as coordination under failure. A centralized database may be complicated, but many of its assumptions are still local: storage, memory, transaction logs, locks, buffers, and query execution can be managed inside one machine or one tightly coupled system boundary. A distributed data system breaks that local assumption. State is spread across machines that communicate over networks, fail independently, recover at different times, and observe events in different orders.
This changes the nature of data management. A distributed system must decide where data lives, how many copies exist, which copy is authoritative, how writes are acknowledged, how reads are served, how stale a read may be, how failures are detected, how leaders are elected, how partitions are repaired, how conflicting writes are reconciled, and how users or operators can explain what happened after a failure.
That is why distributed data systems should be treated as institutional coordination systems, not only storage systems. They preserve data behavior across fault domains. They make tradeoffs among consistency, availability, latency, durability, locality, and recoverability. They also create the evidence trail needed to understand state after partial failure, failover, replica lag, conflict resolution, or recovery.
What distributed data systems mean
A distributed data system is a data storage, processing, or management system whose state is spread across multiple machines that communicate over a network. Those machines may be located in one data center, across availability zones, across regions, or across geographically distant sites. What distinguishes the system is not merely that it has many nodes, but that it must behave meaningfully in the presence of network delay, partial failure, concurrent updates, replica divergence, and the absence of a perfectly shared global clock.
In centralized systems, many design assumptions remain implicit: memory is local, storage is directly attached, failure is often total rather than partial, and coordination can rely on shared hardware assumptions. In distributed systems, those assumptions break down. Nodes can fail independently. Messages can be delayed, reordered, duplicated, or lost. Replicas can diverge temporarily. Clocks can disagree. A distributed data architecture must therefore make explicit decisions about partitioning, replication, consistency, coordination, conflict resolution, and recovery.
For that reason, distributed data systems are best understood as a response to the limits of centralization. They arise where scale, resilience, geography, latency, or availability requirements exceed what a single-instance architecture can reasonably support.
Why distribution becomes necessary
Distribution becomes necessary for at least four recurring reasons. First, scale: workloads eventually exceed the storage, memory, compute, or I/O capacity of one machine. Second, availability: systems that cannot tolerate a single point of failure must replicate state across independent nodes. Third, geographic locality: globally distributed applications need data access close enough to users or services to keep latency acceptable. Fourth, organizational continuity: durable systems often require redundancy across fault domains so that hardware loss, power failure, or regional disruption does not eliminate access to critical state.
Google’s Spanner paper makes this logic explicit at global scale. Spanner is described as a scalable, multi-version, synchronously replicated, globally distributed database designed to support externally consistent distributed transactions across datacenters. Amazon’s Dynamo reflects a different pressure: high availability for key-value workloads, including object versioning and application-assisted conflict resolution under some failure scenarios. These systems illustrate that distribution is not one problem with one answer. It is a family of architectural responses to different operational priorities.
The design question is therefore not simply “should the system be distributed?” Many modern systems already are. The harder question is what the distribution is meant to protect: throughput, geographic latency, uptime, strong consistency, regional fault tolerance, elastic scale, auditability, or some combination of these properties.
Partitioning and horizontal scale
One of the most fundamental techniques in distributed data systems is partitioning, often called sharding. Partitioning divides data into subsets that can be stored and served by different nodes. This allows the system to scale horizontally rather than depending on a single ever-larger machine. Partitioning can be based on hash ranges, key ranges, geographic boundaries, customer tenancy, temporal windows, workload class, or other domain-specific rules.
Partitioning is powerful because it distributes storage and load. But it also introduces architectural consequences. A query that once touched one table on one machine may now need to locate and coordinate data across many shards. Rebalancing partitions when nodes are added or removed becomes a system concern. Hotspots can arise if partition keys distribute unevenly. Cross-partition joins and transactions become more expensive because the system must coordinate across network boundaries rather than within one local engine.
Good distributed design therefore depends on choosing partition strategies that align with workload patterns. A partition key that works for write distribution may not work for analytical reads. A geographic partition may improve locality but complicate global consistency. A tenant-based partition may simplify ownership but produce uneven load. Partitioning is not just a scaling tactic. It is a structural decision about how data and access paths are broken across the system.
Replication, durability, and locality
Replication creates multiple copies of data across machines so that the system can tolerate failures, improve durability, and often reduce read latency by serving data from a nearer or healthier replica. Replication is essential to distributed resilience, but it creates one of the field’s core difficulties: multiple copies of state must remain coherent enough for the system’s intended guarantees.
Replication design includes several choices. How many replicas should exist? Where should they be placed? Are writes acknowledged after one replica, a quorum, or all replicas? Are reads served from leaders, followers, local replicas, or any available copy? Can replicas diverge temporarily? How is divergence detected? How are stale replicas repaired? How are conflicting writes resolved?
Replication also serves locality. A globally distributed service may place replicas closer to users or dependent services to reduce access latency. But locality and consistency often pull in opposite directions: the more the system insists on coordinated agreement before reads or writes complete, the more wide-area latency enters the critical path. Distributed architecture therefore must decide not only where data should be copied, but what level of agreement is required before the system treats a value as committed or safe to read.
Consistency models and coordination
Distributed data systems differ profoundly in their consistency models: the guarantees they provide about what reads can observe after writes occur. Stronger models aim to make a distributed system behave more like a single coherent database. Weaker models accept that replicas may temporarily disagree, or that reads may lag recent writes, in exchange for performance, latency, or availability benefits.
This is why coordination becomes central. If a system wants strong consistency, it must impose enough order on distributed operations that clients observe a coherent view of state. If a system relaxes consistency, it reduces coordination costs but must accept potential anomalies, stale reads, or conflict-resolution logic. The real issue is not whether consistency matters; it is which form of consistency is necessary for the application’s meaning and risk profile.
Modern discussions of distributed storage often distinguish among linearizability, serializability, causal consistency, snapshot isolation, read-your-writes guarantees, monotonic reads, eventual consistency, and related models. These are not textbook abstractions alone. They define the user-visible and application-visible semantics of the system. A banking ledger, a shopping cart, a search index, an analytics rollup, and a cache may legitimately require different guarantees.
CAP, availability, and partition tolerance
No discussion of distributed data systems is complete without the influence of the CAP theorem. In simplified form, CAP is commonly presented as saying that in the presence of a network partition, a system cannot simultaneously provide strong consistency and full availability. Later discussions have repeatedly clarified that the theorem is specifically about behavior under partition and about particular forms of consistency and availability, not about a simplistic three-way menu for all circumstances. That nuance matters because CAP is often misused as a slogan rather than understood as a boundary condition on design.
The enduring value of CAP is that it forces architectural honesty. If a network splits, and parts of the system cannot communicate, what should happen? Should the system reject some operations to preserve a stronger consistency guarantee? Or should it remain available and reconcile divergent state later? Systems like Dynamo leaned toward availability and conflict tolerance for particular workloads. Systems like Spanner pursued strong consistency with substantial coordination and infrastructure support.
The deeper lesson is that distributed architecture is governed by failure assumptions. Design choices that seem easy in normal operation become difficult when networks partition, nodes disappear, and global agreement cannot be taken for granted. CAP does not make architecture simple. It prevents architecture from pretending that partition behavior does not matter.
Quorums, replica agreement, and tunable consistency
Many replicated systems use quorums to manage agreement among replicas. A write quorum defines how many replicas must acknowledge a write before it is considered successful. A read quorum defines how many replicas are consulted before a read is returned. If read and write quorums overlap, a read has a better chance of observing the latest committed write, depending on the system’s assumptions and implementation.
Quorum design is one way systems tune the relationship among consistency, latency, and availability. A larger write quorum provides stronger durability and agreement but can reduce availability if replicas are slow or unreachable. A larger read quorum can reduce stale reads but increases read latency and cost. A smaller quorum can improve availability and responsiveness but may increase the risk of stale reads or conflicting versions.
This is why quorum policies should be explicit and workload-specific. A financial ledger may require majority writes and majority reads. A search index may tolerate eventual consistency. A user-profile cache may accept stale reads if it improves availability, while a configuration system may require strict coordination. Quorums make distribution concrete: they define how many nodes must agree before the system acts as though a value is true.
| Design lever | What it controls | Common tradeoff |
|---|---|---|
| Partitioning | How data is divided across nodes or shards | Scale and parallelism versus cross-shard complexity |
| Replication factor | How many copies of data exist | Durability and availability versus storage and coordination cost |
| Replica placement | Where copies are located across zones or regions | Locality and fault tolerance versus wide-area latency |
| Read quorum | How many replicas must answer a read | Freshness versus latency and availability |
| Write quorum | How many replicas must acknowledge a write | Durability and consistency versus write availability |
| Consistency model | What reads are allowed to observe after writes | Stronger semantics versus coordination cost |
| Conflict resolution | How divergent versions are reconciled | Availability and autonomy versus application complexity |
| Consensus protocol | How nodes agree on log order, leadership, or commits | Correctness and recovery versus latency and operational complexity |
Distributed transactions and global state
Distributed transactions are difficult because they require coordinated state change across nodes that may fail independently and communicate over unreliable networks. In a single-node database, atomicity and isolation are already nontrivial. In a distributed system, the problem becomes harder because a transaction may span partitions, replicas, or regions.
Spanner is especially important here because it showed that a globally distributed system could support externally consistent transactions at scale by combining synchronous replication, multiversion concurrency control, and a time API that exposes clock uncertainty. That design is significant not because every system should imitate it, but because it demonstrates the infrastructure cost and conceptual sophistication required to make a distributed database behave as though one coherent transaction order exists across wide-area deployments.
Other systems choose differently. Some avoid distributed transactions where possible, preferring partition-local operations, asynchronous propagation, idempotent workflows, saga-like compensation, or application-level reconciliation. The architectural question is always the same: where is global atomicity essential, and where can the system safely tolerate looser coordination?
Consensus, ordering, and failure handling
Because distributed systems cannot rely on a single shared control point, many of them depend on consensus or leader-based coordination mechanisms to establish order, membership, and commit decisions. Consensus protocols and ordered log replication allow a group of nodes to agree on a sequence of operations even when some participants fail.
What matters at the architectural level is not only the specific protocol but the problem it solves: distributed nodes need shared decisions about leadership, writes, configuration changes, or log order. Without such mechanisms, replicated state can drift in ways that make recovery, replay, and correctness difficult to reason about. Consensus therefore sits at the heart of many CP-style systems and of many internal control planes even when user-facing data paths present a simpler abstraction.
Failure handling depends on these ordering choices. A system must know whether a write committed, which replica is authoritative, whether a node is merely slow or actually failed, and how state should be repaired after recovery. Distributed systems engineering is therefore as much about failure semantics as about storage semantics. A reliable distributed database is not merely one that stores data on several machines. It is one that can explain and recover its state when some of those machines disagree.
Conflict resolution, versioning, and reconciliation
Systems that favor availability or multi-leader writes often need explicit strategies for dealing with conflicting versions. A conflict can arise when two clients update the same logical item through different replicas before those replicas coordinate. The system may later discover that it has multiple plausible versions of the same key.
Conflict resolution strategies vary. Some systems use last-writer-wins, which is simple but can discard meaningful updates. Others use vector clocks or version vectors to detect concurrent writes and expose conflicts. Some use application-assisted reconciliation, where business logic determines how values should be merged. Some data types support conflict-free merges when operations are commutative or monotonic. Others require human stewardship or explicit repair.
The key point is that conflict resolution is not merely a technical cleanup step. It defines what the system believes about truth under concurrency. For a shopping cart, merging items may be acceptable. For a financial ledger, silent last-writer-wins would be dangerous. For a session store, stale conflict resolution may be tolerable. For configuration metadata, it may be unacceptable. Distributed architecture must therefore connect conflict policy to the meaning and risk of the data being managed.
Architectural styles: CP, AP, and mixed systems
Distributed data systems are often described in terms of CP and AP orientations. CP-oriented systems tend to preserve stronger consistency through coordination, even if that means reduced availability under partition. AP-oriented systems tend to preserve availability and continuity of service, accepting weaker consistency and later reconciliation when communication is disrupted. In practice, many real systems are more hybrid than these labels imply. They may offer mixed guarantees, tune consistency by workload, or separate metadata coordination from data-plane flexibility.
Dynamo became emblematic of the availability-first tradition, sacrificing strong consistency in some failure scenarios while prioritizing always-on behavior for critical key-value workloads. Spanner became emblematic of globally distributed strong transactional coordination. Neither should be treated as a universal template. Each reveals a different answer to the same design problem: what must the system protect first when distribution makes everything simultaneously harder?
This is why distributed architecture cannot be chosen by fashion. The right design depends on workload shape, latency budget, conflict tolerance, business consequences of stale reads, and the institutional need for auditability or strict correctness. One architecture may be appropriate for a product catalog cache and deeply inappropriate for a ledger. Another may be right for control-plane metadata but too expensive for large-scale analytics. Distribution is not one architecture. It is a family of negotiated guarantees.
Observability, auditing, and operational trust
Distributed data systems are notoriously difficult to reason about because failure can be partial, state can be replicated, and timing can change behavior. For that reason, observability is not a secondary operational convenience. It is part of the architecture of trust. Operators need visibility into lag, quorum health, replica divergence, leader election, failed writes, rebalancing, repair, snapshot age, conflict rates, and the state of recovery mechanisms.
Auditable distributed systems are especially important where data supports financial, legal, safety-critical, scientific, or public-sector decisions. It is not enough for a system to “usually work.” Stakeholders must often be able to reconstruct what happened, where a value came from, which replica accepted a write, whether a quorum was achieved, which leader was active, and how conflicts or failovers were resolved.
This connects distributed data systems back to the broader problem of trustworthy analytics. Architecture is not only a matter of technical scale. It is also a matter of defensible evidence, accountable state, and systems that remain intelligible under stress. A distributed data system becomes trustworthy when its guarantees, tradeoffs, and failure behavior are visible enough to be governed.
A mathematical lens for distributed data systems
A distributed cluster can be represented as a set of nodes and communication links:
G = (N, E)
\]
Interpretation: The distributed system graph \(G\) contains nodes \(N\) and network links \(E\). Data behavior depends not only on stored values, but on which nodes can communicate and how reliably they do so.
A partition function maps keys to shards:
s = h(k) \bmod S
\]
Interpretation: Key \(k\) is mapped to shard \(s\) by hash function \(h\) over \(S\) shards. Partition strategy affects load balance, locality, routing, and cross-shard coordination.
Replication factor defines how many copies of each shard exist:
R_s = \{r_{s1}, r_{s2}, \ldots, r_{sn}\}
\]
Interpretation: Shard \(s\) has replica set \(R_s\) with \(n\) replicas. Replica placement affects durability, availability, locality, and failure tolerance.
A read and write quorum intersect when:
R_q + W_q > N
\]
Interpretation: If read quorum \(R_q\) plus write quorum \(W_q\) is greater than replication factor \(N\), then read and write quorums must overlap. This is one foundation for stronger read-after-write behavior in quorum systems, depending on implementation details.
A majority-replicated group can tolerate a limited number of failures:
f = \left\lfloor \frac{N – 1}{2} \right\rfloor
\]
Interpretation: A majority-quorum group with \(N\) replicas can typically tolerate \(f\) failed replicas while still preserving majority agreement.
Replica lag can be represented as the difference between committed and applied log positions:
L_i = C – A_i
\]
Interpretation: Replica lag \(L_i\) is the gap between commit index \(C\) and applied index \(A_i\) for replica \(i\). High lag affects freshness, failover safety, and read correctness.
A distributed-readiness score can combine partition health, replica health, quorum policy, operation success, conflict resolution, consensus health, and failover performance:
Q_d = w_PP_d + w_RR_d + w_QQ_d + w_OO_d + w_CC_d + w_SS_d + w_FF_d
\]
Interpretation: Distributed readiness \(Q_d\) can combine partition health \(P_d\), replica health \(R_d\), quorum policy \(Q_d\), operation health \(O_d\), conflict resolution \(C_d\), consensus health \(S_d\), and failover performance \(F_d\).
The purpose of this mathematical lens is not to reduce distributed systems to formulas. It is to make their hidden structure visible: keys map to shards, shards replicate across nodes, quorums define agreement, lag measures divergence, and readiness depends on whether those mechanisms work under failure.
Python Workflow: Distributed Data Systems Quorum, Replication, and Readiness Scorecard
The following Python workflow demonstrates how a distributed-system review can evaluate shard routing, quorum intersection, replica lag, operation health, conflict resolution, consensus events, failover drills, and distributed-readiness scoring.
#!/usr/bin/env python3
"""
Python Workflow: Distributed Data Systems Quorum, Replication,
and Readiness Scorecard
This compact example treats distributed data systems as coordination evidence:
partitioning, replication, quorums, lag, conflicts, consensus, failover,
and readiness scoring.
"""
from __future__ import annotations
import hashlib
from statistics import mean
def stable_hash(value: str) -> int:
return int(hashlib.sha256(value.encode("utf-8")).hexdigest(), 16)
def key_to_shard(key: str, shard_count: int) -> int:
return stable_hash(key) % shard_count
def quorum_intersects(replication_factor: int, read_quorum: int, write_quorum: int) -> bool:
return read_quorum + write_quorum > replication_factor
def tolerated_majority_failures(replication_factor: int) -> int:
return max(0, (replication_factor - 1) // 2)
def status_score(value: str) -> float:
return {
"healthy": 1.0,
"pass": 1.0,
"success": 1.0,
"approved": 1.0,
"resolved": 0.9,
"in_review": 0.65,
"warn": 0.45,
"pending": 0.35,
"lagging": 0.45,
"degraded": 0.25,
"partial": 0.25,
"failed": 0.0,
}.get(value, 0.5)
def distributed_readiness_score(
node_health: float,
shard_health: float,
quorum_policy: float,
operation_health: float,
conflict_resolution: float,
consensus_health: float,
failover_health: float,
) -> float:
return round(
0.16 * node_health
+ 0.16 * shard_health
+ 0.16 * quorum_policy
+ 0.14 * operation_health
+ 0.12 * conflict_resolution
+ 0.12 * consensus_health
+ 0.14 * failover_health,
3,
)
def main() -> None:
keys = [
"user:1001",
"order:2050",
"cart:9188",
"session:8801",
"ledger:4555",
]
routing = [
{
"key": key,
"shard": key_to_shard(key, shard_count=5),
"hash_bucket": stable_hash(key) % 10000,
}
for key in keys
]
print({"shard_routing": routing})
quorum_policies = [
{
"workload": "financial_ledger",
"n": 3,
"r": 2,
"w": 2,
"model": "linearizable",
"status": "approved",
},
{
"workload": "analytics_rollup",
"n": 3,
"r": 1,
"w": 1,
"model": "eventual",
"status": "approved",
},
{
"workload": "configuration_metadata",
"n": 5,
"r": 3,
"w": 3,
"model": "linearizable",
"status": "approved",
},
]
policy_scores = []
for policy in quorum_policies:
intersects = quorum_intersects(policy["n"], policy["r"], policy["w"])
write_majority = policy["w"] > policy["n"] / 2
score = (
0.45 * int(intersects)
+ 0.35 * int(write_majority)
+ 0.20 * status_score(policy["status"])
)
policy_scores.append(score)
print({
"workload": policy["workload"],
"quorums_intersect": intersects,
"tolerated_majority_failures": tolerated_majority_failures(policy["n"]),
"policy_score": round(score, 3),
})
replicas = [
{"shard": "s001", "node": "n001", "is_leader": True, "lag_ops": 0, "state": "healthy"},
{"shard": "s001", "node": "n002", "is_leader": False, "lag_ops": 2, "state": "healthy"},
{"shard": "s001", "node": "n004", "is_leader": False, "lag_ops": 8, "state": "healthy"},
{"shard": "s005", "node": "n005", "is_leader": True, "lag_ops": 80, "state": "degraded"},
{"shard": "s005", "node": "n001", "is_leader": False, "lag_ops": 3, "state": "healthy"},
{"shard": "s005", "node": "n003", "is_leader": False, "lag_ops": 4, "state": "healthy"},
]
shard_health = []
for shard in sorted({replica["shard"] for replica in replicas}):
shard_replicas = [replica for replica in replicas if replica["shard"] == shard]
max_lag = max(replica["lag_ops"] for replica in shard_replicas)
healthy_ratio = mean([
1.0 if replica["state"] == "healthy" else 0.25
for replica in shard_replicas
])
leader_present = any(replica["is_leader"] for replica in shard_replicas)
lag_score = max(0.0, 1.0 - min(max_lag / 200.0, 1.0))
score = round(0.45 * healthy_ratio + 0.35 * lag_score + 0.20 * int(leader_present), 3)
shard_health.append(score)
print({
"shard": shard,
"max_lag_ops": max_lag,
"leader_present": leader_present,
"shard_health_score": score,
})
operations = [
{"operation": "write", "latency_ms": 24, "status": "committed", "consistency": "linearizable"},
{"operation": "read", "latency_ms": 30, "status": "served", "consistency": "linearizable"},
{"operation": "write", "latency_ms": 180, "status": "partial", "consistency": "quorum_not_met"},
{"operation": "read", "latency_ms": 142, "status": "served", "consistency": "stale_possible"},
]
operation_scores = []
for operation in operations:
quorum_ok = operation["consistency"] != "quorum_not_met"
latency_score = max(0.0, 1.0 - min(operation["latency_ms"] / 250.0, 1.0))
score = round(0.55 * int(quorum_ok) + 0.30 * latency_score + 0.15 * status_score(operation["status"]), 3)
operation_scores.append(score)
print({"operation_health_score": round(mean(operation_scores), 3)})
conflicts = [
{"strategy": "last_writer_wins", "status": "resolved"},
{"strategy": "vector_clock_merge", "status": "in_review"},
{"strategy": "application_reconciliation", "status": "pending"},
]
consensus_events = [
{"event": "heartbeat", "result": "success"},
{"event": "append_entries", "result": "success"},
{"event": "leader_degraded", "result": "warn"},
{"event": "leader_transfer", "result": "success"},
]
failovers = [
{"scenario": "leader_failure", "recovery_seconds": 22, "data_loss": 0, "status": "pass"},
{"scenario": "zone_outage", "recovery_seconds": 80, "data_loss": 0, "status": "pass"},
{"scenario": "regional_latency_spike", "recovery_seconds": 280, "data_loss": 0, "status": "warn"},
]
conflict_score = mean([status_score(item["status"]) for item in conflicts])
consensus_score = mean([status_score(item["result"]) for item in consensus_events])
failover_score = mean([
0.45 * max(0.0, 1.0 - min(item["recovery_seconds"] / 300.0, 1.0))
+ 0.35 * (1.0 if item["data_loss"] == 0 else 0.0)
+ 0.20 * status_score(item["status"])
for item in failovers
])
print({
"distributed_readiness_score": distributed_readiness_score(
node_health=0.86,
shard_health=mean(shard_health),
quorum_policy=mean(policy_scores),
operation_health=mean(operation_scores),
conflict_resolution=conflict_score,
consensus_health=consensus_score,
failover_health=failover_score,
)
})
if __name__ == "__main__":
main()
This workflow treats distributed data systems as coordination evidence. It does not only list nodes and shards. It evaluates how keys route to shards, whether quorum policies intersect, how far replicas lag, whether operations meet expected guarantees, whether conflicts are resolved, and whether failover behavior is good enough for the workload.
R Workflow: Distributed Cluster, Replica Lag, Quorum Policy, Conflict, and Failover Summary
The following R workflow summarizes node health, replica lag, quorum policies, operation latency, conflict resolution status, consensus events, and failover drills.
#!/usr/bin/env Rscript
# R Workflow: Distributed Cluster, Replica Lag,
# Quorum Policy, Conflict, and Failover Summary
nodes <- data.frame(
node_id = c("n001", "n002", "n003", "n004", "n005", "n006"),
region = c("us-central", "us-central", "us-central", "us-east", "us-west", "eu-west"),
role = c("leader", "follower", "follower", "follower", "follower", "follower"),
status = c("healthy", "healthy", "healthy", "healthy", "degraded", "healthy"),
cpu_utilization = c(0.62, 0.57, 0.53, 0.49, 0.83, 0.46),
network_rtt_ms = c(8, 9, 10, 42, 68, 118),
stringsAsFactors = FALSE
)
replicas <- data.frame(
shard_id = c("s001", "s001", "s001", "s005", "s005", "s005"),
node_id = c("n001", "n002", "n004", "n005", "n001", "n003"),
is_leader = c(1, 0, 0, 1, 0, 0),
lag_ops = c(0, 2, 8, 80, 3, 4),
replica_state = c("in_sync", "in_sync", "in_sync", "degraded", "in_sync", "in_sync"),
stringsAsFactors = FALSE
)
policies <- data.frame(
workload = c("financial_ledger", "analytics_rollup", "configuration_metadata"),
replication_factor = c(3, 3, 5),
read_quorum = c(2, 1, 3),
write_quorum = c(2, 1, 3),
consistency_model = c("linearizable", "eventual", "linearizable"),
availability_orientation = c("CP", "AP", "CP"),
status = c("approved", "approved", "approved"),
stringsAsFactors = FALSE
)
policies$quorum_intersection <- ifelse(
policies$read_quorum + policies$write_quorum > policies$replication_factor,
1,
0
)
operations <- data.frame(
shard_id = c("s001", "s001", "s005", "s005"),
operation_type = c("write", "read", "write", "read"),
client_region = c("us-central", "us-east", "us-west", "eu-west"),
latency_ms = c(24, 30, 180, 142),
result_status = c("committed", "served", "partial", "served"),
consistency_observed = c("linearizable", "linearizable", "quorum_not_met", "stale_possible"),
stringsAsFactors = FALSE
)
conflicts <- data.frame(
shard_id = c("s002", "s005", "s005"),
resolution_strategy = c("last_writer_wins", "vector_clock_merge", "application_reconciliation"),
resolution_status = c("resolved", "in_review", "pending"),
stringsAsFactors = FALSE
)
consensus <- data.frame(
shard_id = c("s001", "s002", "s005", "s005"),
event_type = c("heartbeat", "append_entries", "leader_degraded", "leader_transfer"),
result = c("success", "success", "warn", "success"),
stringsAsFactors = FALSE
)
failovers <- data.frame(
scenario = c("leader_failure", "zone_outage", "regional_latency_spike"),
recovery_time_seconds = c(22, 80, 280),
data_loss_observed = c(0, 0, 0),
drill_status = c("pass", "pass", "warn"),
stringsAsFactors = FALSE
)
node_summary <- aggregate(
cbind(cpu_utilization, network_rtt_ms) ~ region + role + status,
data = nodes,
FUN = mean
)
replica_lag_summary <- aggregate(
lag_ops ~ shard_id + replica_state,
data = replicas,
FUN = function(x) c(replica_count = length(x), mean_lag = mean(x), max_lag = max(x))
)
replica_lag_summary <- do.call(data.frame, replica_lag_summary)
names(replica_lag_summary) <- c(
"shard_id",
"replica_state",
"replica_count",
"mean_lag_ops",
"max_lag_ops"
)
quorum_summary <- aggregate(
quorum_intersection ~ availability_orientation + consistency_model + status,
data = policies,
FUN = mean
)
operation_summary <- aggregate(
latency_ms ~ shard_id + operation_type + result_status + consistency_observed,
data = operations,
FUN = function(x) c(operation_count = length(x), mean_latency = mean(x), max_latency = max(x))
)
operation_summary <- do.call(data.frame, operation_summary)
names(operation_summary) <- c(
"shard_id",
"operation_type",
"result_status",
"consistency_observed",
"operation_count",
"mean_latency_ms",
"max_latency_ms"
)
conflict_summary <- aggregate(
shard_id ~ resolution_strategy + resolution_status,
data = conflicts,
FUN = length
)
names(conflict_summary) <- c(
"resolution_strategy",
"resolution_status",
"conflict_count"
)
consensus_summary <- aggregate(
shard_id ~ event_type + result,
data = consensus,
FUN = length
)
names(consensus_summary) <- c(
"event_type",
"result",
"event_count"
)
failover_summary <- aggregate(
recovery_time_seconds ~ scenario + drill_status,
data = failovers,
FUN = function(x) c(drill_count = length(x), mean_recovery = mean(x), max_recovery = max(x))
)
failover_summary <- do.call(data.frame, failover_summary)
names(failover_summary) <- c(
"scenario",
"drill_status",
"drill_count",
"mean_recovery_time_seconds",
"max_recovery_time_seconds"
)
dir.create("outputs", showWarnings = FALSE, recursive = TRUE)
write.csv(node_summary, "outputs/node_summary_r.csv", row.names = FALSE)
write.csv(replica_lag_summary, "outputs/replica_lag_summary_r.csv", row.names = FALSE)
write.csv(quorum_summary, "outputs/quorum_summary_r.csv", row.names = FALSE)
write.csv(operation_summary, "outputs/operation_summary_r.csv", row.names = FALSE)
write.csv(conflict_summary, "outputs/conflict_summary_r.csv", row.names = FALSE)
write.csv(consensus_summary, "outputs/consensus_summary_r.csv", row.names = FALSE)
write.csv(failover_summary, "outputs/failover_summary_r.csv", row.names = FALSE)
cat("Wrote distributed cluster, replica, quorum, operation, conflict, consensus, and failover summaries.\n")
This workflow treats distributed health as multidimensional. Uptime matters, but so do replica lag, quorum design, observed consistency, conflict resolution, consensus events, and failover performance.
Applications across domains
Distributed data systems underpin a wide range of modern infrastructures. Global commerce platforms rely on them for highly available user state and transactions. Cloud-native applications use them to survive zone and region failures. Financial and operational systems use them where durability and continuity matter across multiple sites. Sensor and telemetry networks use them to ingest geographically dispersed data. Machine-learning and large-scale analytics pipelines use them to store and process massive distributed datasets. Public and infrastructure systems increasingly depend on them wherever continuity, geographic spread, resilience, and auditability are non-negotiable.
In analytics environments, distribution supports large-scale storage, parallel query execution, distributed object storage, lakehouse tables, cross-region replication, and resilient pipelines. In operational environments, distribution supports low-latency reads, fault-tolerant writes, failover, leader election, and durable event logs. In AI systems, distribution supports feature stores, vector stores, training-data lakes, model metadata, and inference-serving state.
Across all these domains, the central architectural challenge is the same: how to preserve useful semantics when the system no longer lives in one place. Distributed data systems are the answer modern computing gives to that question.
Implementation principles for high-integrity distributed data systems
Define the workload’s consistency needs. Linearizability, serializability, causal consistency, read-your-writes, and eventual consistency are not interchangeable.
Partition according to access patterns. Shard keys should reflect workload distribution, query paths, tenant boundaries, geography, and hotspot risks.
Make replication policy explicit. Replication factor, placement, leader/follower roles, and repair processes should be visible.
Document read and write quorums. Quorum policy should be tied to workload risk, latency, and failure tolerance.
Monitor replica lag. Commit index, applied index, snapshot age, and lag should be operational metrics, not hidden internals.
Test failover regularly. Recovery time, leader election, data loss, and client behavior should be measured through drills.
Treat conflict resolution as governance. Last-writer-wins, vector-clock merge, application reconciliation, and human stewardship have different consequences.
Preserve operation evidence. Logs should record write acknowledgments, read paths, quorum status, latency, leader state, and consistency observations.
Separate control-plane and data-plane guarantees. Metadata coordination may need stronger consistency than large analytical data paths.
Connect architecture to consequence. A cache, ledger, search index, profile store, and configuration service should not be forced into the same consistency model by default.
| Control | Purpose | Failure it prevents |
|---|---|---|
| Shard map | Documents how keys route to partitions | Opaque routing, hotspots, and weak impact analysis |
| Replica placement policy | Controls durability, locality, and zone or region resilience | Correlated failures and avoidable latency |
| Quorum policy | Defines how many replicas must participate in reads and writes | Unclear freshness, durability, or availability guarantees |
| Consistency model documentation | States what reads can observe after writes | Application assumptions exceeding system guarantees |
| Replica lag monitoring | Tracks divergence between committed and applied state | Stale reads, unsafe failover, and hidden replica drift |
| Consensus event logging | Records leadership, terms, log replication, and election behavior | Unexplainable failover or commit uncertainty |
| Conflict-resolution register | Tracks divergent versions and reconciliation strategy | Silent overwrites or unresolved application-level conflicts |
| Failover drills | Measures recovery time, data loss, and operational response | Untested resilience assumptions |
GitHub Repository
This article can be paired with a companion code workflow that models distributed data systems as coordination evidence infrastructure. The example includes cluster nodes, shard maps, replica status, quorum policies, operation logs, conflict records, consensus events, failover drills, shard-routing examples, SQL schemas, Python and R workflows, Julia scoring, typed contracts, Quarto report templates, and multi-language examples across Python, R, Julia, SQL, Go, Rust, C, C++, TypeScript, and Terraform placeholders.
The companion repository provides a vendor-neutral distributed data systems scaffold with partitioning examples, shard routing, replica lag monitoring, quorum policy evaluation, operation-health scoring, conflict-resolution tracking, consensus-event review, failover-drill summaries, SQL governance queries, reproducible reporting templates, typed contracts, documentation, and CI smoke-test patterns.
Conclusion
Distributed data systems exist because modern data requirements often exceed the limits of centralized architecture. They allow systems to scale horizontally, survive failures, reduce geographic latency, and preserve continuity across fault domains. But distribution does not make data management easier. It makes tradeoffs explicit: partitioning complicates coordination, replication complicates consistency, locality complicates global agreement, and high availability complicates conflict handling.
The deeper point is that distributed systems are not merely technical scale mechanisms. They are systems of negotiated truth under failure. They decide what it means for a write to commit, a read to be fresh, a replica to be healthy, a leader to be authoritative, a conflict to be resolved, and a system to remain available when the network no longer behaves ideally. In mature data architecture, distributed-system design is therefore inseparable from observability, governance, auditability, and institutional trust.
Related articles
- Data Systems & Analytics
- Database Systems and Data Architecture
- Relational Databases and SQL Systems
- Data Warehouses and Data Lakes
- Data Pipelines and Data Processing Systems
- Streaming Data and Real-Time Analytics
- Cloud Data Platforms and Modern Data Stack Architecture
- Reproducible Analytics and Versioned Data Workflows
Further reading
- Gray, J. and Reuter, A. (1992) Transaction Processing: Concepts and Techniques. San Francisco: Morgan Kaufmann.
- Kleppmann, M. (2017) Designing Data-Intensive Applications. Sebastopol, CA: O’Reilly Media.
- Özsu, M.T. and Valduriez, P. (2020) Principles of Distributed Database Systems. 4th edn. Cham: Springer.
- Tanenbaum, A.S. and van Steen, M. (2017) Distributed Systems. 3rd edn. Amsterdam: Maarten van Steen.
- Kossmann, D., Kraska, T. and Loesing, S. (2010) ‘An evaluation of alternative architectures for transaction processing in the cloud’, Proceedings of the 2010 ACM SIGMOD International Conference on Management of Data.
References
- Bailis, P. and Ghodsi, A. (2013) ‘Eventual Consistency Today: Limitations, Extensions, and Beyond’, Communications of the ACM, 56(5). Available at: https://dl.acm.org/doi/fullHtml/10.1145/2447976.2447992
- Bailis, P. et al. (2014) ‘Highly Available Transactions: Virtues and Limitations’, Proceedings of the VLDB Endowment, 7(3). Available at: https://amplab.cs.berkeley.edu/wp-content/uploads/2013/10/hat-vldb2014.pdf
- Corbett, J.C. et al. (2012) Spanner: Google’s Globally-Distributed Database. Proceedings of OSDI 2012. Available at: https://research.google/pubs/spanner-googles-globally-distributed-database-2/
- DeCandia, G. et al. (2007) Dynamo: Amazon’s Highly Available Key-value Store. Proceedings of SOSP 2007. Available at: https://www.amazon.science/publications/dynamo-amazons-highly-available-key-value-store
- Gilbert, S. and Lynch, N. (2002) Brewer’s Conjecture and the Feasibility of Consistent, Available, Partition-Tolerant Web Services. Available at: https://users.ece.cmu.edu/~adrian/731-sp04/readings/GL-cap.pdf
- Ongaro, D. and Ousterhout, J. (2014) In Search of an Understandable Consensus Algorithm. USENIX ATC 2014. Available at: https://www.usenix.org/conference/atc14/technical-sessions/presentation/ongaro
- Panda, A. et al. (2013) ‘CAP for Networks’, Proceedings of the 2nd ACM Symposium on Cloud Computing. Available at: https://dl.acm.org/doi/pdf/10.1145/2491185.2491186
- Brewer, E. (2012) Spanner, TrueTime and the CAP Theorem. Google Research. Available at: https://research.google/pubs/spanner-truetime-and-the-cap-theorem/