Experimental Design and Causal Inference: Randomization, Identification, and Causal Claims
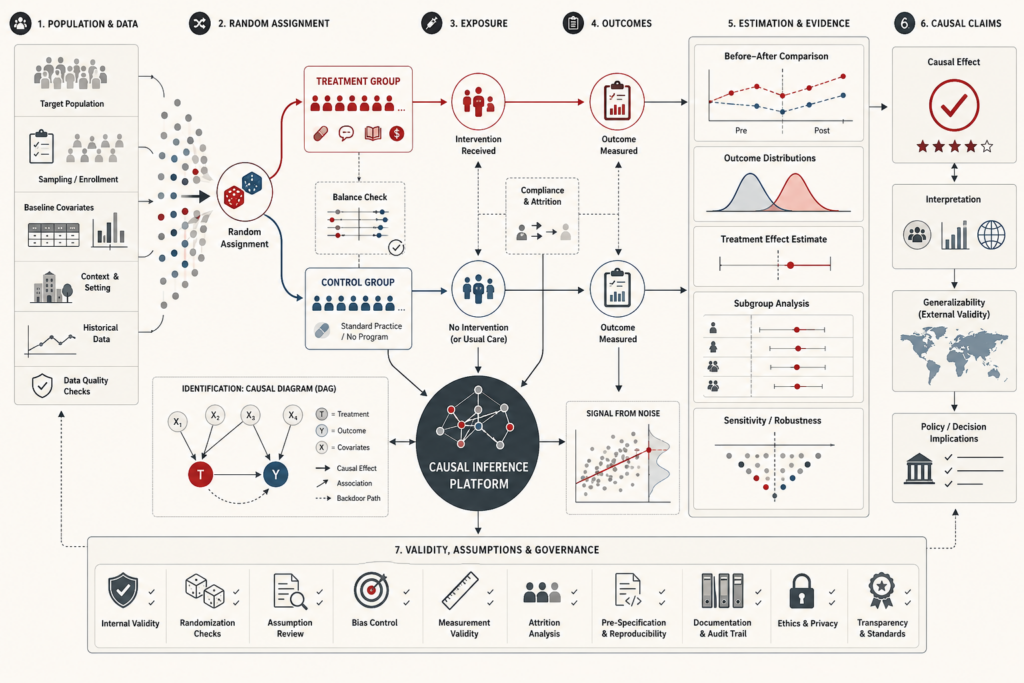
Experimental design and causal inference determine whether an analysis can move responsibly from observed association to credible claims about intervention. This article frames causal reasoning as design-governed evidence: the disciplined process of defining interventions, comparison conditions, outcomes, units, estimands, identification strategies, assumptions, validity threats, and robustness checks before making causal claims. It explains why prediction, correlation, and regression are not enough to answer questions about what would change under treatment, policy, exposure, or institutional action. The article also examines counterfactual reasoning, potential outcomes, randomization, blocking, factorial design, treatment effects, DAGs, backdoor adjustment, quasi-experiments, difference-in-differences, regression discontinuity, target-trial emulation, confounding, selection bias, post-treatment bias, transportability, and governance. Mathematical examples and Python/R workflows show how teams can evaluate causal readiness, assumption strength, effect estimates, validity risks, and evidentiary limits.