AI in Health, Medicine, and Clinical Decision Support
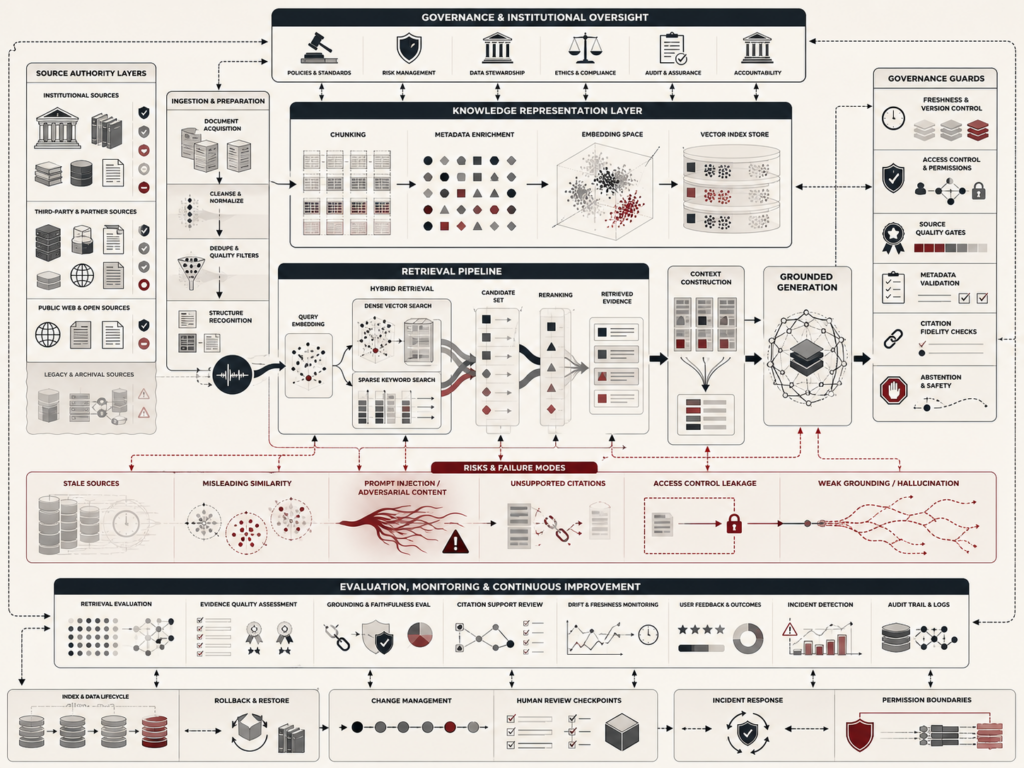
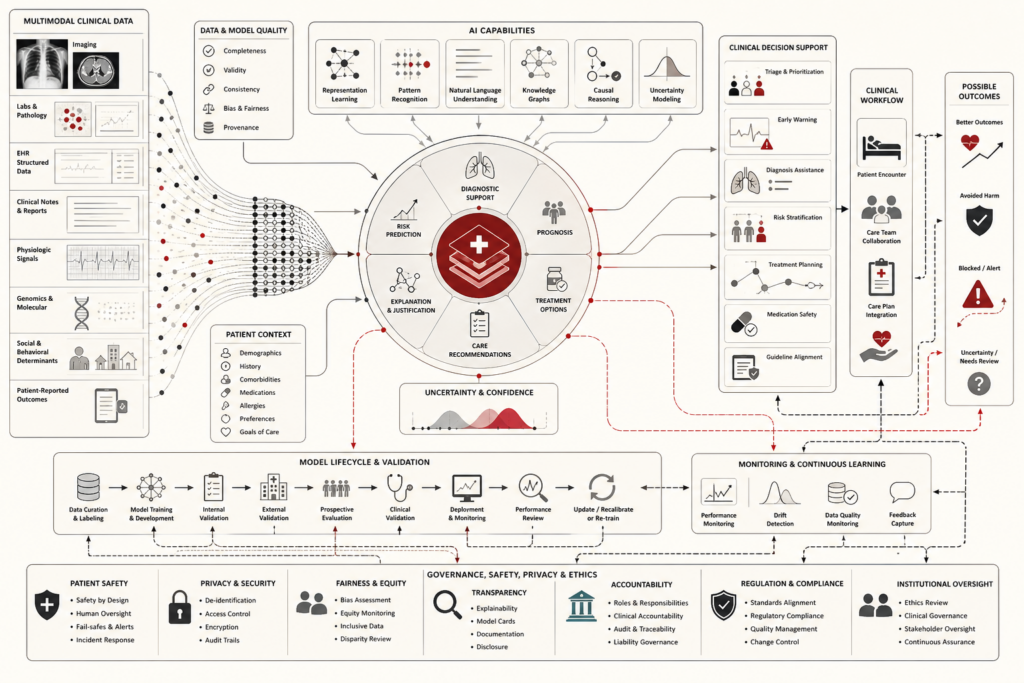
AI in health, medicine, and clinical decision support refers to the use of artificial intelligence systems to assist clinical reasoning, diagnosis, triage, imaging interpretation, risk prediction, treatment planning, documentation, workflow coordination, population health, biomedical research, and patient-facing health services. These systems can identify patterns in images, laboratory data, electronic health records, waveforms, genomics, clinical notes, sensor streams, and patient histories. This article explains clinical decision support, diagnostic AI, imaging systems, risk prediction, early warning models, large language models in clinical workflows, privacy, security, bias, equity, regulation, validation, monitoring, drift, change control, and governance. It argues that clinical AI should be treated as a medical, technical, organizational, ethical, and regulatory system because patient safety, professional responsibility, and institutional trust are central to responsible deployment.