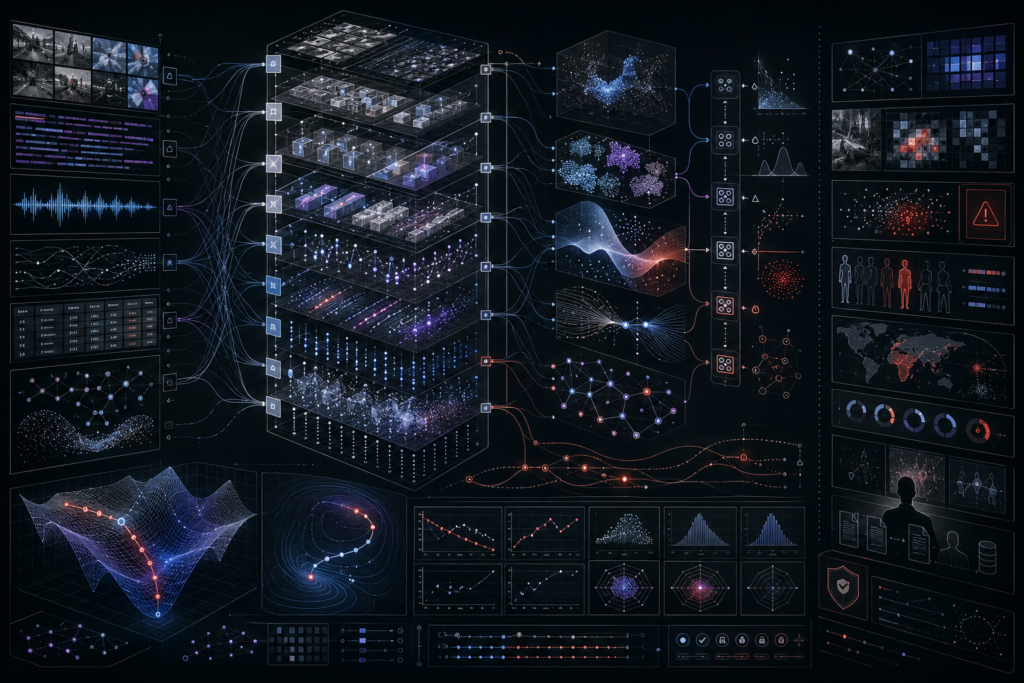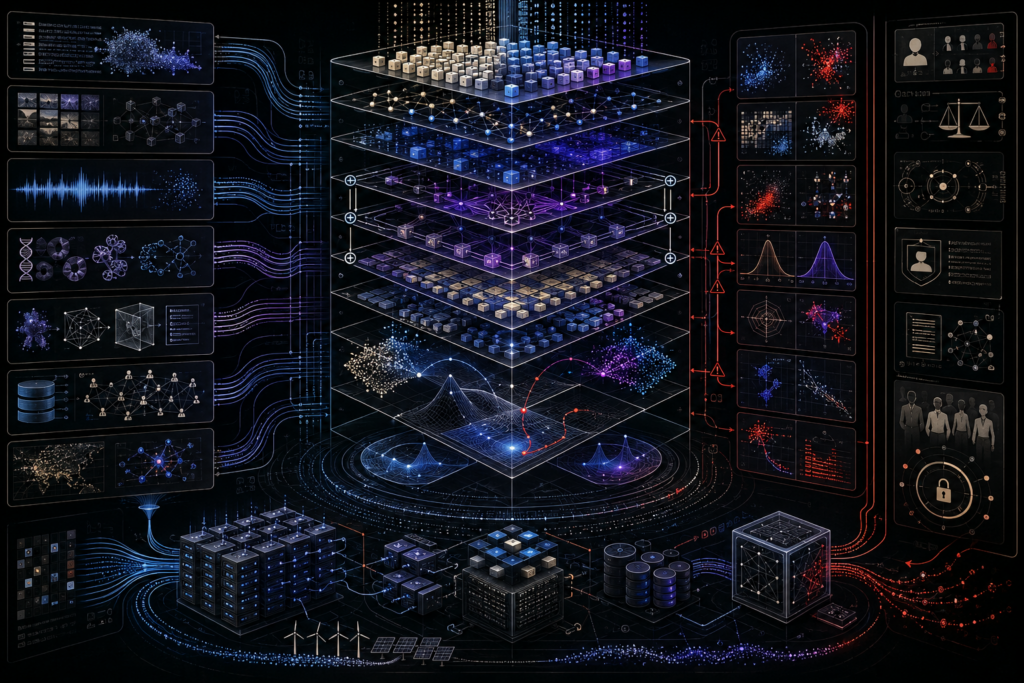
Deep Learning Systems: Representation, Scale, and Generalization
Deep learning systems use large-scale neural architectures to learn hierarchical representations from data, enabling AI models to generalize across complex domains such as language, vision, speech, biology, multimodal reasoning, and scientific discovery. This article explains representation learning, the manifold hypothesis, depth, compositionality, expressive power, scaling laws, transformers, attention, overparameterization, double descent, emergent capabilities, optimization geometry, infrastructure, robustness, and governance. It also introduces mathematical lenses for composed neural functions, layer transformations, residual connections, empirical risk, attention, scaling behavior, generalization gaps, and distribution shift, alongside Python and R workflows for representation geometry, scaling-law simulation, and generalization diagnostics. By connecting neural representation to compute, data, architecture, deployment, and institutional power, it frames deep learning as an auditable systems regime rather than a model class alone.