Self-Supervised Learning and Foundation Models
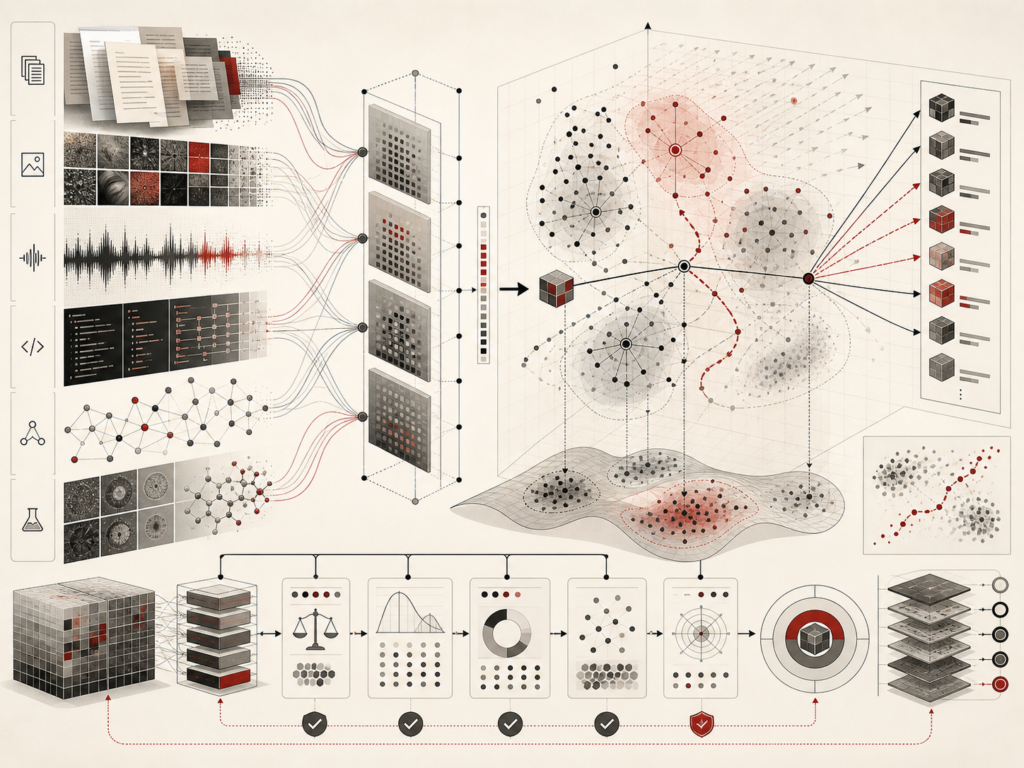
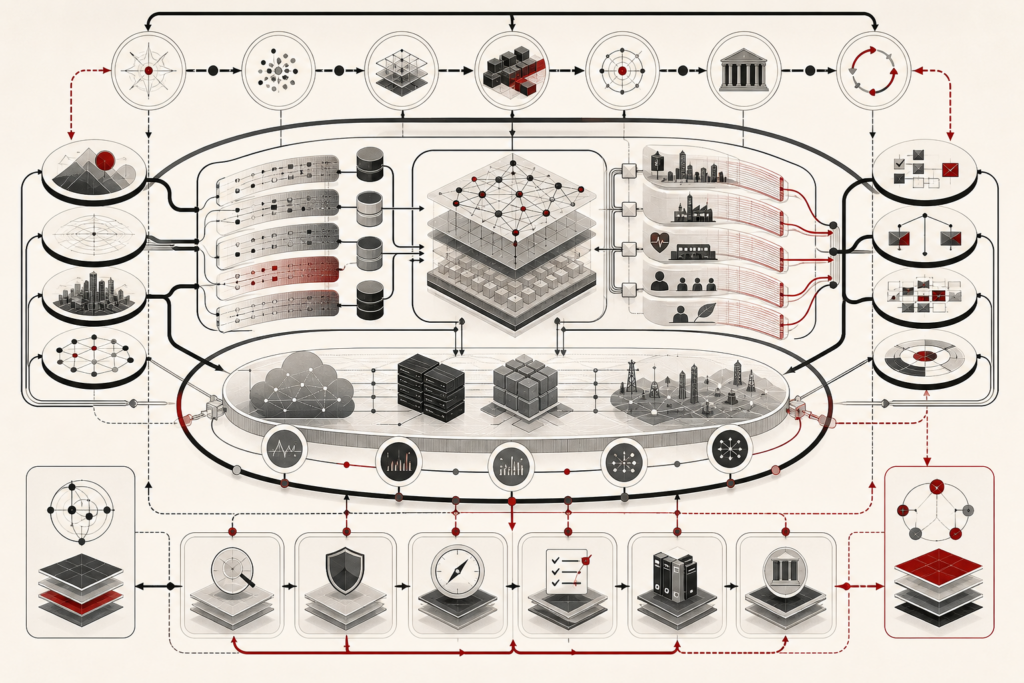
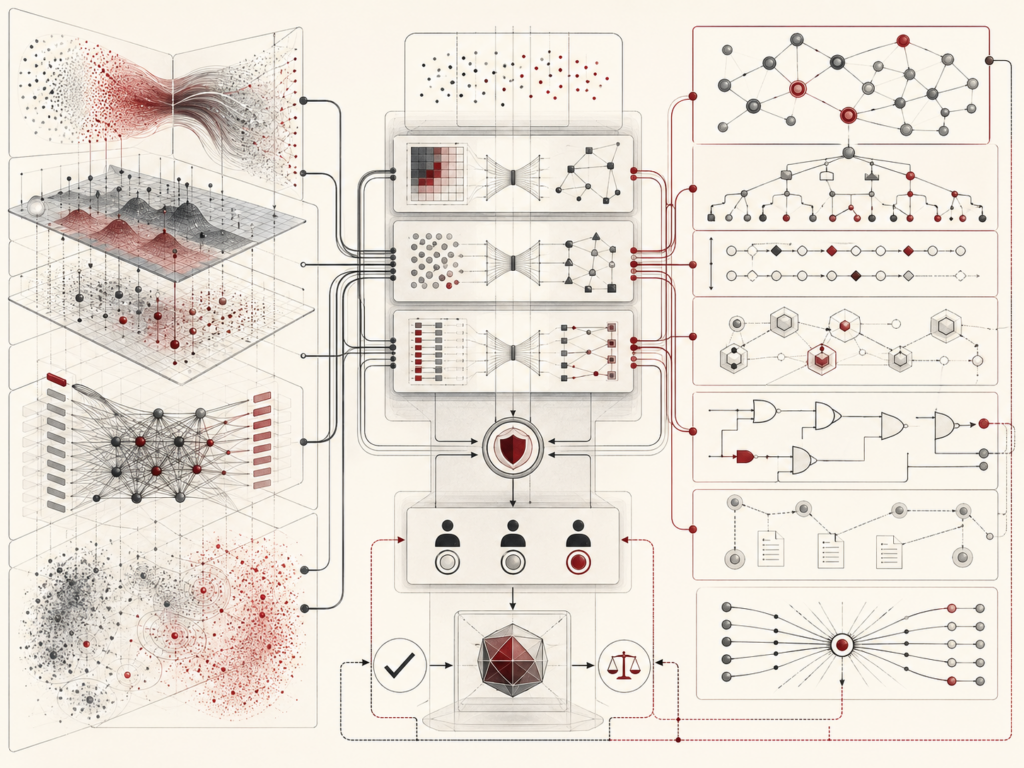
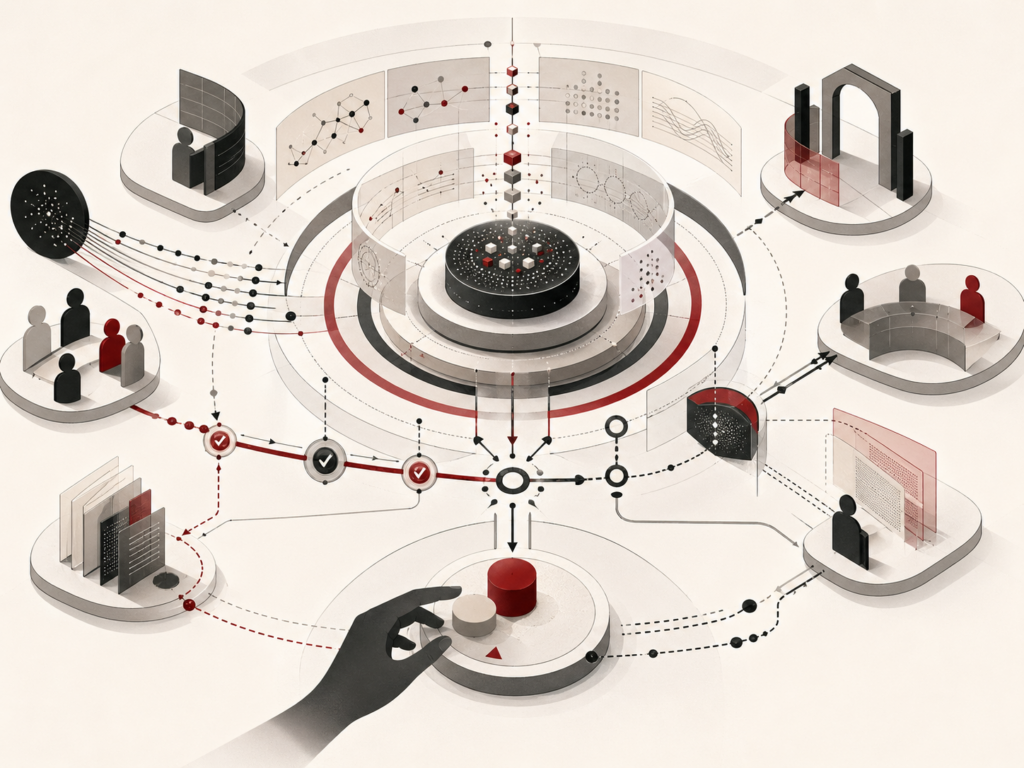
Self-supervised learning and foundation models explain how modern AI systems learn from the structure of large-scale data without requiring manual labels for every task. Instead of depending only on supervised examples, these systems create learning signals from masked tokens, next-token prediction, reconstructed image patches, contrastive pairs, multimodal alignment, code structure, scientific data, and other internal patterns. This article explains how self-supervised objectives support reusable representations, foundation models, language modeling, masked autoencoding, contrastive learning, multimodal AI, transfer learning, prompting, fine-tuning, retrieval, and downstream adaptation. It also examines risks involving data provenance, bias, privacy, memorization, grounding, scale, compute cost, benchmark limits, and correlated downstream failures. The central argument is that foundation models are not just models; they are reusable AI infrastructure requiring evaluation, monitoring, governance, and institutional accountability.