
Last Updated May 10, 2026
Representation learning and embedding spaces are central to modern artificial intelligence because they allow machines to transform complex data into structured mathematical spaces where similarity, meaning, behavior, and pattern can be computed. Text, images, audio, video, code, molecules, users, documents, graphs, transactions, and scientific observations can all be represented as vectors. Once transformed into vectors, these objects can be compared, clustered, retrieved, visualized, classified, generated, ranked, recommended, and monitored.
The importance of representation learning is that AI systems rarely operate directly on raw reality. They operate on representations. A model does not understand a sentence, image, protein, customer, document, or city in the human sense. It learns a coordinate system in which patterns become computationally useful. Embedding spaces are therefore not merely technical conveniences. They are the hidden geometry through which AI systems organize information, similarity, relevance, and decision-making.
The central argument is that embedding spaces should be understood as learned infrastructures of meaning: powerful, useful, approximate, biased, domain-dependent, and in need of evaluation and governance. They make semantic search, retrieval-augmented generation, recommender systems, multimodal AI, anomaly detection, document clustering, scientific discovery, and knowledge navigation possible. But they also shape what a system can find, relate, prioritize, exclude, and misinterpret.
Main Library
Publications
Article Map
Artificial Intelligence Systems
Related Topic
Data Systems & Analytics
Related Topic
Embedded & Edge Systems
Related Topic
Intelligent Infrastructure Systems
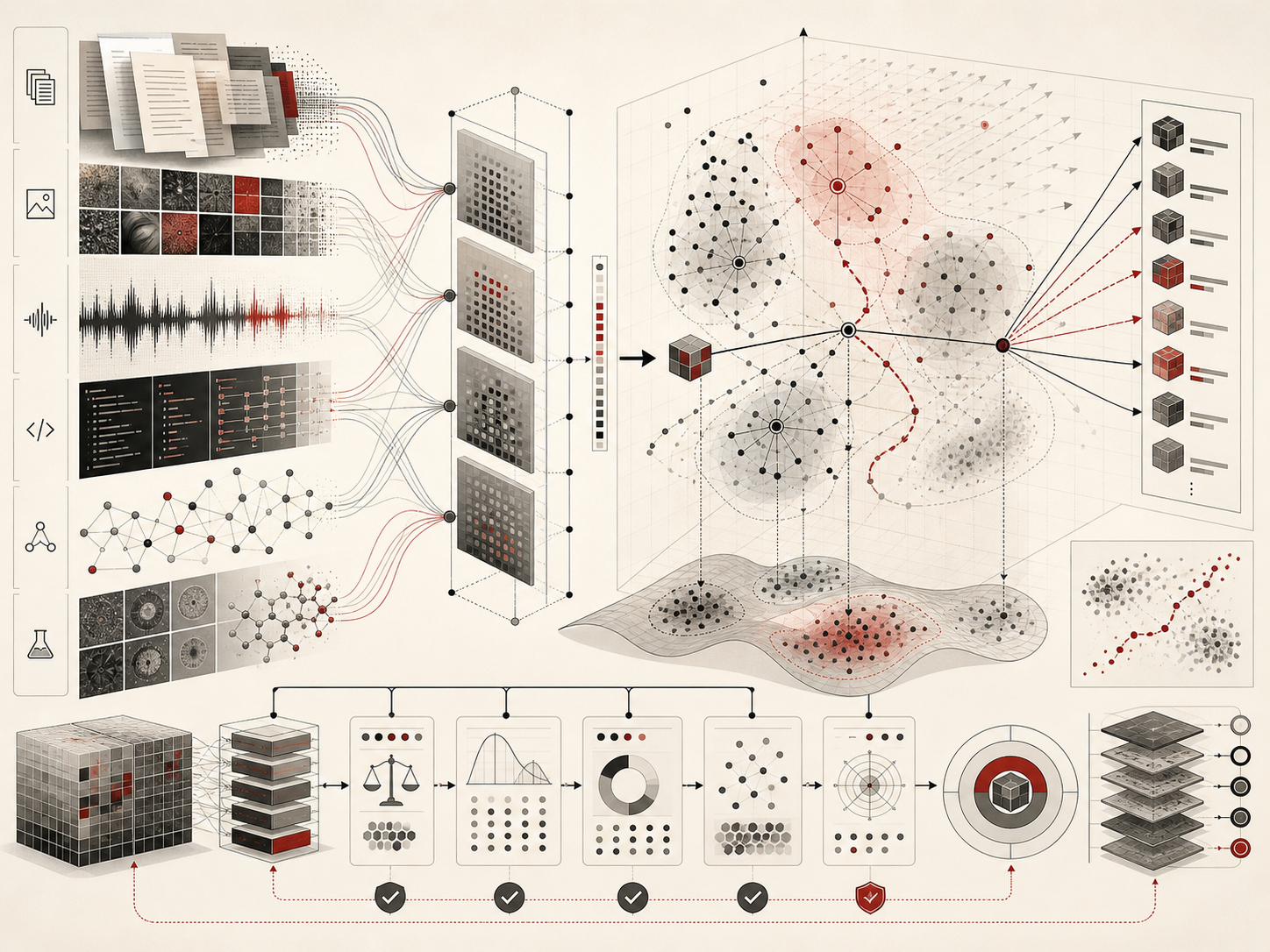
This article develops Representation Learning and Embedding Spaces as an advanced article within the Artificial Intelligence Systems knowledge series. It explains learned features, dense vectors, semantic neighborhoods, vector search, language embeddings, deep representations, contrastive learning, multimodal embeddings, retrieval systems, dimensionality reduction, evaluation, bias, drift, governance, and operational infrastructure. Selected Python and R examples appear here, while the full GitHub repository contains expanded computational scaffolding for embedding generation, vector search, similarity diagnostics, clustering review, SQL schemas, governance metadata, documentation templates, and reproducible notebooks.
Why Representation Learning Matters
Representation learning matters because raw data is rarely useful to AI systems in its original form. Images are arrays of pixels. Text is a sequence of tokens. Audio is a waveform. Molecules can be represented as graphs. User behavior appears as sparse interaction logs. Documents may be long, noisy, multilingual, and structurally inconsistent. Sensor systems produce time series with missing values, anomalies, and measurement error. To learn from these data forms, AI systems require representations that preserve relevant structure while making computation possible.
Traditional machine learning often depended on hand-engineered features. Humans selected measurable properties, transformed them into tables, and trained models on those features. Representation learning shifts part of that burden to the model. Instead of specifying every feature manually, the system learns internal representations that help solve a task. In deep learning, these representations are often distributed across many dimensions and layers. They are not usually interpretable as simple human-readable variables, but they can encode useful structure.
This change is one reason modern AI systems have become so flexible. The same representational logic supports machine translation, semantic search, image classification, recommender systems, anomaly detection, document retrieval, speech recognition, multimodal models, protein modeling, and generative AI. Once an object can be represented as a vector, it can be placed inside a computational geometry. Distances, angles, neighborhoods, clusters, and trajectories become meaningful system operations.
But representation learning also creates a deeper governance problem. If an AI system makes decisions through learned representations, then the representation itself shapes what the system can see. A bad representation can make important differences invisible, turn weak correlations into apparent similarity, bury minority cases inside dominant clusters, or retrieve plausible but unsupported results. The learned coordinate system becomes part of the institution’s epistemology: the way it recognizes, sorts, searches, ranks, and acts.
Representation \neq Reality
\]
Interpretation: Embeddings are learned approximations of data relationships. They can be useful without being neutral, complete, true, or appropriate for every task.
For that reason, representation learning should not be treated as a hidden technical preprocessing step. It is part of the design of knowledge systems, retrieval systems, decision-support tools, recommender systems, scientific analysis workflows, and foundation-model infrastructure. The representation determines what kind of computation becomes possible and what kind of error becomes likely.
From Hand-Engineered Features to Learned Representations
A feature is a measurable property used by a model. In earlier machine learning workflows, features were often designed manually: word counts, color histograms, edge detectors, demographic fields, transaction counts, statistical summaries, or domain-specific indicators. These features could be powerful, but they required substantial expertise and often failed to generalize across domains.
Representation learning allows models to learn features from data. In neural networks, intermediate layers transform inputs into increasingly abstract representations. A computer vision model may learn edges, textures, shapes, parts, objects, and scenes. A language model may learn syntax, topic, semantics, discourse structure, and task-relevant patterns. A recommender system may learn user and item embeddings that encode behavioral similarity. A scientific model may learn latent structure in molecular, climate, genomic, or materials data.
The transition from engineered features to learned representations changes the nature of AI design. It improves flexibility, but it also creates new interpretability and governance challenges. If a model learns a representation automatically, developers must still ask what the representation encodes, what it omits, what biases it preserves, where it fails, and how it changes over time.
| Approach | How Features Are Created | Strength | Governance Challenge |
|---|---|---|---|
| Hand-engineered features | Humans define variables, transformations, and indicators. | Often interpretable and domain-specific. | May miss complex structure or encode human assumptions too rigidly. |
| Classical statistical features | Summaries such as counts, means, frequencies, ratios, or lags. | Useful for transparent modeling and structured data. | Can flatten context and ignore unstructured meaning. |
| Learned neural representations | Models learn internal transformations from data and objective functions. | Captures complex patterns across text, images, audio, graphs, and sequences. | Harder to interpret, audit, and explain. |
| Embedding spaces | Objects are mapped into dense vector spaces. | Supports similarity, retrieval, clustering, recommendation, and search. | Similarity can be biased, task-dependent, or mistaken for truth. |
| Foundation-model representations | Large models learn reusable representations at scale. | Transfers across many downstream tasks. | Inherited risks propagate into adapted systems. |
Note: Learned representations reduce the need for manual feature design, but they do not remove the need for evaluation, documentation, and accountability.
The older feature-engineering paradigm placed many assumptions in visible variables. The learned-representation paradigm moves many assumptions into model architecture, training data, loss functions, optimization, and embedding geometry. That makes AI systems more powerful but also harder to inspect. Responsible practice requires new forms of review: nearest-neighbor inspection, probing, retrieval evaluation, bias testing, drift monitoring, and domain-specific validation.
Feature\ Design \rightarrow Representation\ Governance
\]
Interpretation: As systems move from manually engineered features to learned embeddings, governance must shift toward evaluating the learned space itself.
Embedding Spaces as Learned Geometry
An embedding maps an object into a vector space. The object may be a word, sentence, paragraph, image, audio clip, product, user, chemical compound, graph node, scientific measurement, or institutional record. The embedding represents the object as a point in a high-dimensional space.
The power of embedding spaces comes from geometry. Objects that are similar under the learned representation should be near one another. Objects that are unrelated should be farther apart. Directions in the space may correspond to semantic, stylistic, behavioral, visual, or structural changes. Clusters may reveal groups. Boundaries may support classification. Nearest neighbors may support search and recommendation.
But embedding spaces are not neutral maps of reality. They are learned from data, objectives, architectures, preprocessing decisions, and evaluation criteria. Two embedding models trained on different data or different objectives may organize the same objects differently. A legal document embedding model, a medical embedding model, a general web embedding model, and a code embedding model may all represent “risk,” “evidence,” “function,” or “system” in different ways. An embedding space is therefore a model of relevance, not a universal truth.
| Geometric Idea | System Operation | Use Case | Governance Concern |
|---|---|---|---|
| Distance | Measures how far objects are from one another. | Nearest-neighbor search, clustering, anomaly detection. | Distance may not correspond to meaningful or safe similarity. |
| Angle | Compares vector direction, often through cosine similarity. | Semantic search and document retrieval. | High similarity may reflect topic overlap rather than evidence support. |
| Neighborhood | Defines which objects are close to a query or example. | Recommendation, related content, similar-case retrieval. | Neighborhoods can reproduce bias or omit minority cases. |
| Cluster | Groups objects that are close under the embedding model. | Topic modeling, dataset inspection, segmentation. | Clusters may reflect artifacts, language, source type, or platform bias. |
| Direction | Captures possible semantic or behavioral change in vector space. | Analogy, style shift, concept movement, latent editing. | Directions can be unstable, overinterpreted, or socially biased. |
| Projection | Maps high-dimensional embeddings into two or three dimensions. | Visualization and exploratory diagnostics. | Projection can distort original distances and exaggerate patterns. |
Note: Embedding geometry is operationally useful, but every geometric interpretation should be tested against the task, domain, and consequence of use.
Similarity \neq Relevance \neq Evidence
\]
Interpretation: Two objects can be close in embedding space without one being relevant, authoritative, current, or evidentially supportive for the user’s task.
Embedding spaces are most useful when their geometry is aligned with the system’s purpose. A search system may need topical similarity. A legal system may need controlling authority. A medical system may need clinical relevance. A recommender system may need user preference, novelty, and fairness. A scientific system may need physical validity. A single embedding space cannot be assumed to encode all of these priorities equally.
Language Embeddings: Words, Sentences, and Documents
Language embeddings are among the most influential forms of representation learning. Earlier systems often represented words through sparse vectors, such as one-hot encodings or bag-of-words features. These representations could count word occurrence, but they did not directly encode semantic similarity. “Cat” and “feline” might appear unrelated if they were treated as separate symbols.
Word embeddings changed this by representing words as dense vectors learned from language use. The intuition is distributional: words appearing in similar contexts often have related meanings. Systems such as word2vec and GloVe helped demonstrate that semantic and syntactic relationships could be encoded in vector spaces. These representations made it possible to compare words, identify analogies, cluster semantic neighborhoods, and improve downstream natural language processing tasks.
Modern language systems extend this idea from words to sentences, paragraphs, documents, and whole conversations. Sentence embeddings and document embeddings allow semantic search, clustering, topic organization, duplicate detection, retrieval-augmented generation, and knowledge-base navigation. Instead of matching exact keywords, the system can retrieve material that is conceptually similar to a query.
This is powerful, but it requires caution. Similarity is model-dependent. A document may be close to a query because it shares topic, style, vocabulary, genre, institutional context, or accidental correlations. Semantic retrieval should therefore be evaluated against actual user tasks, not assumed to be correct because vectors are mathematically near.
| Embedding Level | What Is Represented? | Common Use | Risk |
|---|---|---|---|
| Word embeddings | Individual word or token meanings learned from context. | Similarity, analogy, lexical semantics, early NLP pipelines. | Can encode social stereotypes and context-insensitive meaning. |
| Sentence embeddings | Short passages or statements. | Semantic search, paraphrase detection, clustering. | May miss negation, nuance, stance, or source authority. |
| Document embeddings | Longer records, articles, reports, policies, or cases. | Document retrieval, topic organization, recommendation. | Long documents may be compressed too aggressively. |
| Chunk embeddings | Sections or passages split from larger documents. | Retrieval-augmented generation and evidence retrieval. | Poor chunking can separate claims from context. |
| Contextual embeddings | Tokens or passages represented in context. | Modern transformer-based language systems. | Representations vary with prompt, context, and model layer. |
Note: Language embeddings make semantic computation possible, but semantic closeness must not be confused with accuracy, authority, or evidence.
Language embeddings also inherit the politics of language data. Words, phrases, and topics are not equally represented across languages, dialects, communities, professions, and institutions. A model trained on dominant-language web data may perform poorly for minority languages, technical domains, local knowledge, marginalized communities, or specialized legal and scientific usage. Evaluation should therefore include the language communities and document genres the system is meant to serve.
Deep Representations and Hierarchical Abstraction
Deep learning systems learn representations across layers. Early layers often encode simpler patterns, while later layers encode more abstract task-relevant structure. In image models, earlier layers may respond to edges or textures, while later layers may encode object parts or categories. In language models, earlier representations may capture token-level structure, while later layers may capture syntax, semantics, discourse, and task-specific patterns.
This hierarchy is one reason deep learning works across complex data types. Instead of relying on a single flat feature table, deep networks compose transformations. Each layer reshapes the representation space. By the time data reaches a later layer, it may be organized in ways that are useful for classification, generation, retrieval, or reasoning.
However, deep representations are difficult to interpret. A single dimension may not correspond to a clear human concept. Meaning may be distributed across many dimensions. Similarity may vary across layers. A representation useful for one task may fail for another. This creates a need for probing, visualization, ablation, stress testing, and task-specific evaluation.
| Layer Pattern | Common Representation | Example | Evaluation Need |
|---|---|---|---|
| Early layers | Low-level features or local patterns. | Edges in images, subword patterns in text, frequency patterns in audio. | Check robustness to noise and preprocessing changes. |
| Middle layers | Composed features and intermediate structure. | Object parts, phrase structure, motifs, local dependencies. | Probe whether useful structure is being learned. |
| Late layers | Task-relevant abstractions. | Class, topic, intent, object category, semantic cluster. | Evaluate against downstream task performance and failure modes. |
| Embedding head | Vector representation used for retrieval or comparison. | Sentence embedding, image embedding, user embedding. | Evaluate similarity, ranking, bias, and drift. |
| Projection layer | Task-specific transformation of hidden states. | Contrastive projection, classification head, retrieval embedding. | Check whether projection distorts meaning or overfits task. |
Note: Different layers may encode different forms of structure. The “best” representation depends on the task and the governance question.
Deep representations also complicate explanation. A system may classify an image, retrieve a document, or recommend an item because of distributed relationships across thousands of dimensions. Inspecting one dimension will rarely explain the decision. Review therefore often relies on multiple tools: nearest neighbors, counterfactual examples, feature probes, activation analysis, embedding visualization, error slices, and human domain review.
Layer\ Choice = Meaning\ Choice
\]
Interpretation: Which layer or representation is used can change what similarity means, what clusters form, and what downstream system behavior emerges.
Contrastive Learning and Semantic Alignment
Contrastive learning trains embedding spaces by comparing examples. The system learns by identifying which pairs should be close and which should be far apart. In language, positive pairs may be paraphrases. In images, positive pairs may be augmented views of the same image. In multimodal systems, positive pairs may be an image and its caption. Negative pairs are examples that should not be treated as equivalent.
This learning paradigm is especially important because it creates useful representations without requiring every example to have a traditional class label. Instead, the system learns relational structure. It learns that two views belong together, that a caption corresponds to an image, or that a sentence pair expresses similar meaning. This makes contrastive learning central to modern semantic search, multimodal AI, and representation learning at scale.
The governance challenge is that contrastive learning depends heavily on pair construction. What counts as a positive pair? What counts as a negative pair? Are negatives truly unrelated, or only superficially different? Do the pairings encode cultural assumptions, platform biases, captioning errors, or historical inequities? Embedding spaces inherit these design decisions.
| Design Choice | Role | Example | Failure Risk |
|---|---|---|---|
| Positive pairs | Define what should be close in embedding space. | Paraphrases, augmented images, image-caption pairs. | Noisy positives teach false similarity. |
| Negative pairs | Define what should be separated. | Unrelated passages, nonmatching images, unrelated captions. | False negatives push related items apart. |
| Augmentations | Define invariances the representation should preserve. | Cropping, masking, color jitter, paraphrase, time shift. | Important task information may be removed. |
| Similarity metric | Defines how closeness is measured. | Cosine similarity, dot product, learned distance. | Metric may not align with user relevance. |
| Batch composition | Controls which negatives are compared during training. | Large batches with many examples. | Training dynamics may reward dataset artifacts. |
| Temperature | Controls sharpness of separation. | Lower temperature emphasizes sharper distinctions. | Can over-separate or over-cluster examples. |
Note: Contrastive learning does not only learn similarity. It learns the similarity assumptions built into pair construction, augmentation, and objective design.
Positive\ Pair = Modeling\ Assumption
\]
Interpretation: When a system decides two examples should be close, it is making an assumption about relevance, equivalence, or invariance that should be validated downstream.
Contrastive learning has become especially important for multimodal systems because it allows different forms of data to enter a shared representational space. But alignment at scale can be fragile. A caption may not fully describe an image. An image may contain multiple people, objects, or cultural meanings. A code comment may be outdated. A scientific label may be incomplete. Contrastive learning can create impressive retrieval behavior, but the source pairings still require scrutiny.
Multimodal Embedding Spaces
Multimodal embedding spaces align different types of data within a shared or coordinated representational structure. Text and images can be embedded so that an image of a forest is close to captions about forests. Audio and text can be aligned for speech understanding. Code and natural language can be aligned for programming assistance. Molecules and text can be aligned for scientific retrieval. Graphs and documents can be connected for knowledge systems.
Multimodal embedding spaces are powerful because they allow one modality to retrieve, condition, or interpret another. A text query can search an image database. An image can retrieve captions. A scientific abstract can retrieve related datasets. A user question can retrieve relevant documents before a language model answers. This is one of the foundations of retrieval-augmented generation and multimodal AI systems.
But multimodal alignment is not neutral. Captions may describe images incompletely. Training data may reflect cultural stereotypes. Visual concepts may be overrepresented or underrepresented. Text may impose categories that distort visual or social reality. A shared embedding space can make cross-modal retrieval appear natural while hiding the assumptions that made alignment possible.
| Modalities | Shared-Space Capability | Use Case | Governance Concern |
|---|---|---|---|
| Text + image | Search images with text or classify images using language prompts. | Visual search, captioning, zero-shot classification. | Captions may be incomplete, biased, or misleading. |
| Text + audio | Align speech, sound, transcript, and description. | Speech recognition, accessibility, audio search. | Accent, dialect, surveillance, consent, and noise bias. |
| Text + code | Connect code functions with natural-language descriptions. | Code search, documentation, programming assistance. | Insecure patterns, licensing, stale comments, incorrect explanations. |
| Text + scientific data | Connect literature, measurements, datasets, and models. | Scientific retrieval, hypothesis discovery, evidence mapping. | Metadata quality, uncertainty, reproducibility, and domain validity. |
| Graph + document | Align entities, relationships, documents, and knowledge structures. | Knowledge graphs, enterprise search, compliance retrieval. | Incorrect entity resolution or relationship inference. |
Note: Multimodal embeddings allow cross-modal retrieval, but alignment should be evaluated for each modality, community, and use context.
Multimodal embeddings are increasingly important for AI systems that interpret diagrams, images, audio, maps, code, tables, and documents together. In high-stakes domains, however, cross-modal similarity is not enough. A medical image, legal exhibit, climate map, infrastructure photograph, or satellite observation requires domain-specific validation. The system must know whether it is retrieving something visually similar, semantically related, scientifically relevant, or legally authoritative.
Embedding-Based Retrieval and Vector Search
Embedding spaces become operationally important when they are used for retrieval. In semantic search, a query is embedded into a vector, stored documents are embedded into vectors, and the system retrieves nearest neighbors. This allows search based on meaning rather than exact word overlap.
Embedding-based retrieval supports semantic search across documents, retrieval-augmented generation, recommendation systems, duplicate and near-duplicate detection, customer support knowledge bases, scientific literature mapping, image and video search, code search, anomaly detection, and similar-case retrieval in decision support.
At scale, vector search requires specialized infrastructure. Exact nearest-neighbor search can become expensive when millions or billions of vectors are involved. Approximate nearest-neighbor methods trade exactness for speed, often using indexing structures, quantization, graph-based search, or GPU acceleration. This makes embedding spaces part of infrastructure, not just modeling.
Retrieval quality depends on the embedding model, chunking strategy, metadata, indexing method, similarity metric, filtering rules, freshness, evaluation set, and downstream workflow. A retrieval system can fail because the embedding model is weak, because documents are chunked poorly, because metadata is missing, because the vector index is stale, or because retrieved passages are not actually useful to the user.
| Pipeline Layer | Function | Failure Mode | Governance Control |
|---|---|---|---|
| Source corpus | Defines what can be searched. | Missing, stale, low-authority, or restricted sources enter retrieval. | Source registry, access rules, authority labels. |
| Chunking | Splits documents into retrievable units. | Evidence is separated from context, definitions, or caveats. | Structure-aware chunking and chunk review. |
| Embedding model | Maps queries and records into vector space. | Similarity does not match domain relevance. | Model selection, domain evaluation, versioning. |
| Vector index | Stores and searches embeddings efficiently. | Stale, incomplete, or approximate results degrade retrieval. | Index build records, refresh schedule, health checks. |
| Similarity metric | Ranks candidates by closeness. | Metric favors topical overlap over useful evidence. | Metric evaluation and ranking tests. |
| Metadata filters | Restrict results by domain, date, authority, or permission. | Relevant but unauthorized or outdated records appear. | Freshness, authority, and access filtering. |
| Downstream use | Feeds search results into users, models, or workflows. | Retrieved material is overtrusted or misused. | Grounding review, citation checks, user feedback. |
Note: Vector search is not only a similarity operation. It is an information infrastructure with source, index, metadata, access, freshness, and evaluation requirements.
Vector\ Search = Embedding + Index + Metadata + Evaluation
\]
Interpretation: Reliable semantic retrieval depends on the full retrieval system, not only on the embedding vector or similarity score.
Embedding-based retrieval becomes especially consequential when used inside retrieval-augmented generation. If retrieved passages are weak, stale, biased, or irrelevant, a language model may generate a confident answer from poor evidence. In that setting, embedding quality becomes part of answer quality. Retrieval is not a background utility; it is an epistemic gate.
Dimensionality Reduction and Visualization
Embedding spaces are often high-dimensional. Visualization methods such as t-SNE and UMAP project high-dimensional vectors into two or three dimensions so that humans can inspect clusters, neighborhoods, outliers, and structure. These visualizations can help identify topic clusters, dataset imbalance, mislabeled examples, anomalous samples, domain drift, or representation collapse.
However, visualization is not the same as explanation. Low-dimensional projections distort the original geometry. Distances in a two-dimensional plot may not match distances in the original embedding space. Clusters may appear sharper or more separated than they really are. Different parameters can produce different visual impressions.
Embedding visualization is therefore best used as an exploratory diagnostic, not as proof. It can suggest questions: Why are these documents clustered? Why are these samples isolated? Why are these categories overlapping? Why did the model place these examples together? It should be paired with quantitative evaluation and domain review.
| Visualization Use | What It Can Reveal | What It Cannot Prove | Responsible Use |
|---|---|---|---|
| Cluster inspection | Possible topic, class, or source groupings. | That clusters are meaningful in the original space. | Check clusters against labels, metadata, and human review. |
| Outlier detection | Items far from apparent groups. | That outliers are errors or anomalies. | Inspect examples and domain context. |
| Bias exploration | Potential groupings around social categories. | That visual separation fully captures bias. | Pair with quantitative association and subgroup tests. |
| Drift monitoring | Possible movement of new data relative to old data. | That drift is operationally harmful. | Pair with retrieval and performance metrics. |
| Dataset debugging | Duplicates, mislabeled samples, mixed domains, or artifacts. | That projection geometry is faithful. | Use as a triage tool, not final evidence. |
Note: Embedding plots are useful for exploration, but low-dimensional projections should not be treated as faithful maps of the original high-dimensional space.
Projection \neq Explanation
\]
Interpretation: A two-dimensional embedding plot can help humans inspect patterns, but it distorts high-dimensional geometry and should not be treated as proof.
Visualization can be particularly useful in editorial, scientific, and governance workflows because it gives reviewers a way to ask better questions. But it should remain tied to evidence: nearest neighbors, cluster labels, retrieval quality, known metadata, errors, and downstream performance. A beautiful embedding plot can still represent a bad retrieval system.
Evaluating Embedding Spaces
Embedding spaces should be evaluated according to the tasks they support. A good embedding for semantic search may not be ideal for classification. A good embedding for clustering may not be ideal for recommendation. A general-purpose embedding may underperform in specialized domains such as law, medicine, engineering, finance, or sustainability science.
| Evaluation Dimension | Question | Example Measure | Governance Relevance |
|---|---|---|---|
| Retrieval quality | Are relevant items retrieved near the top? | Recall@k, precision@k, MRR, nDCG. | Tests whether users can find what they need. |
| Semantic similarity | Do distances correspond to human similarity judgments? | Correlation with annotated similarity scores. | Checks whether geometry matches human meaning. |
| Clustering structure | Do meaningful groups form in the space? | Silhouette score, cluster purity, adjusted Rand index. | Supports topic organization and dataset inspection. |
| Classification usefulness | Do embeddings support downstream prediction? | Accuracy, F1, AUC with a simple classifier. | Tests whether representations preserve task-relevant information. |
| Robustness | Do embeddings remain stable under paraphrase, noise, or domain shift? | Perturbation tests, domain transfer tests. | Prevents brittle retrieval and classification. |
| Bias and fairness | Do representations encode harmful associations? | Association tests, subgroup retrieval analysis. | Detects unequal or harmful geometry. |
| Interpretability | Can neighborhoods and dimensions be meaningfully inspected? | Nearest-neighbor review, probing, concept tests. | Supports review and contestability. |
| Operational performance | Can retrieval run at required scale and latency? | Index build time, query latency, memory use. | Determines production feasibility. |
| Freshness and drift | Does the embedding system remain valid as data changes? | Embedding drift metrics, retrieval regression tests. | Prevents stale or degraded retrieval. |
Note: Embedding evaluation should be grounded in use. A high benchmark score or appealing visualization does not prove the space is appropriate for a specific institutional task.
The most important principle is that embedding evaluation should be grounded in use. A beautiful visualization or high benchmark score does not guarantee that an embedding space is appropriate for a specific institutional task. Domain-specific evaluation is essential. A semantic search system for sustainability articles, a legal retrieval system, a medical imaging system, and a product recommender all require different definitions of success.
Evaluation should also include failure cases. Which relevant documents are consistently missed? Which retrieved items are semantically close but not useful? Which communities, languages, or topics are underrepresented? Which queries produce low-similarity results? Which old sources remain too prominent? Which new documents are not properly indexed? These questions turn embedding evaluation from an abstract metric exercise into system governance.
Good\ Embedding = Useful\ for\ a\ Defined\ Task
\]
Interpretation: Embedding quality is not universal. It must be evaluated against the task, domain, users, sources, and consequences of use.
Bias, Drift, and Representation Governance
Embedding spaces can encode and reproduce bias. If training data contains stereotypes, omissions, slurs, unequal visibility, or historical discrimination, these patterns may appear in vector neighborhoods. Terms associated with gender, race, class, religion, nationality, disability, occupation, or geography may cluster in ways that reflect social bias. In recommender systems, user and item embeddings may reproduce historical exclusion or unequal exposure. In document retrieval, underrepresented topics may be harder to find.
Representation drift is another problem. Embedding models, data distributions, user queries, document collections, and institutional vocabularies change over time. A retrieval system that worked well at launch may degrade as new documents are added, terminology changes, or user behavior shifts. Embedding governance should therefore include monitoring.
A responsible embedding system should document which embedding model is used, what data it was trained or fine-tuned on, what similarity metric is used, how documents or objects are chunked, how vectors are indexed, how retrieval quality is evaluated, how bias and subgroup performance are reviewed, how stale embeddings are refreshed, how users can report poor retrieval or harmful associations, and how embedding versions are tracked.
| Governance Object | What Must Be Documented? | Why It Matters | Failure if Missing |
|---|---|---|---|
| Embedding model | Model name, version, training context, intended use. | Defines the geometry used by the system. | Teams cannot trace changes in retrieval behavior. |
| Corpus and data sources | Indexed documents, images, records, metadata, permissions. | Defines what can be found or recommended. | Stale, low-quality, or unauthorized content may shape results. |
| Chunking strategy | How long records are split and labeled. | Determines retrieval granularity and context preservation. | Claims may be separated from evidence or caveats. |
| Similarity metric | Cosine, dot product, Euclidean, learned metric, reranking logic. | Defines what “near” means. | Search may optimize the wrong kind of similarity. |
| Index version | Vector index build, refresh schedule, approximate-search settings. | Controls retrieval reproducibility. | Teams cannot know which results users saw. |
| Bias review | Association tests, subgroup retrieval, harmful-neighborhood inspection. | Detects unequal representation behavior. | Bias persists invisibly inside vector geometry. |
| Drift monitoring | Embedding movement, query behavior, retrieval regressions. | Tracks whether the system remains valid over time. | Search quality degrades silently. |
Note: Embedding spaces are infrastructure. They organize what a system can find, relate, recommend, and ignore.
Embedding\ Governance = Model\ Version + Corpus + Metric + Monitoring
\]
Interpretation: A governed embedding system tracks the model, indexed corpus, similarity metric, vector index, evaluation set, and monitoring signals together.
Representation governance also requires user feedback. Embedding systems often fail in ways users notice before metrics do: irrelevant search results, missing documents, biased recommendations, repeated near-duplicates, stale sources, or strange clusters. Feedback loops should be structured so these reports can update evaluation sets, metadata, chunking, index refresh, or model selection.
Common Failure Modes
Representation learning and embedding spaces often fail when vector similarity is mistaken for meaning, truth, or system readiness. A retrieved document may be close to a query while still being outdated, incomplete, low-authority, or irrelevant to the user’s decision. A cluster may look coherent while reflecting source type rather than content. A recommendation may look personalized while reinforcing past exclusion.
| Failure Mode | Description | Likely Consequence | Governance Response |
|---|---|---|---|
| Similarity mistaken for truth | Nearby vectors are treated as factually or evidentially related. | Semantic retrieval returns plausible but unsupported material. | Use source support, authority, freshness, and citation checks. |
| Task mismatch | Embedding model is good for one task but used for another. | Search, clustering, or classification quality degrades. | Evaluate embeddings against the actual use case. |
| Bias as geometry | Harmful associations become neighborhoods, directions, or clusters. | Unequal retrieval, recommendation, or classification behavior. | Run bias tests and subgroup retrieval review. |
| Projection overconfidence | Low-dimensional plots are treated as faithful maps. | Reviewers overinterpret visual clusters. | Use visualization only as exploratory evidence. |
| Chunking failure | Documents are split poorly before embedding. | Retrieval loses definitions, caveats, or evidence context. | Use structure-aware chunking and chunk diagnostics. |
| Stale index | Embeddings or vector indexes are not refreshed. | New or corrected sources are not retrieved properly. | Track index versions and refresh schedules. |
| Metadata poverty | Vectors lack source, date, authority, permissions, or category metadata. | System cannot filter or audit retrieval. | Require metadata schema and validation. |
| Representation drift | Data, language, users, or model versions change over time. | Retrieval quality decays silently. | Monitor drift, query failures, and retrieval regressions. |
Note: Many embedding failures are not visible from the vector alone. They appear when vector behavior is connected to sources, users, workflows, and consequences.
The most dangerous failure mode is false relevance. A result can look semantically right while failing the actual task. For knowledge systems, this is especially important: an embedding system may retrieve material that sounds related but does not answer the question, does not support the claim, or should not be used as authority. This is why embedding governance must connect similarity to evidence, metadata, and institutional purpose.
Limits and Open Problems
Representation learning and embedding spaces have major limitations. Similarity is not truth: nearby vectors are not necessarily factually, ethically, or causally related. Embeddings are task-dependent: a useful representation for one task may fail for another. Bias can be geometric: harmful social associations may be encoded as neighborhoods, directions, or clusters. Visualizations can mislead: low-dimensional maps can distort high-dimensional relationships.
Retrieval can appear authoritative. Semantic search may return plausible but incomplete or low-quality material. Embedding drift is real: changes in data, models, queries, and domains can degrade retrieval over time. Vector systems need governance: model versions, indexes, chunking, metadata, and evaluation sets must be tracked.
Several open problems remain difficult. How should embedding spaces be evaluated when user intent is ambiguous? How should systems distinguish topical similarity from evidence support? How should embedding bias be measured across languages, cultures, and domains without reducing social harm to a single metric? How should vector databases preserve access control and provenance at scale? How should organizations detect when an embedding model update changes the meaning of old neighborhoods?
Another open problem is interpretability. Embeddings are powerful because they compress complex structure into vectors, but that compression makes them hard to explain. Users often want to know why a document was retrieved, why a product was recommended, why a case was considered similar, or why a record was flagged as anomalous. Similarity scores alone are rarely enough. Responsible systems need explanation layers that connect vector similarity to metadata, source content, task relevance, and human review.
The goal is not to reject embeddings. They are among the most useful tools in modern AI. The goal is to understand them as learned coordinate systems that require evaluation, monitoring, and institutional accountability. Embedding spaces shape what AI systems can perceive as similar, relevant, meaningful, or retrievable. That makes them foundational infrastructure for artificial intelligence systems.
Mathematical Lens
A representation model maps an input object into a vector.
z = f_{\theta}(x)
\]
Interpretation: The function \(f_{\theta}\) maps an input \(x\) into an embedding vector \(z\). The parameters \(\theta\) are learned from data. The embedding \(z\) is the model’s learned representation of the object.
If two objects are represented as vectors, similarity can be computed geometrically. A common measure is cosine similarity.
s(z_i,z_j)
=
\frac{z_i \cdot z_j}{\|z_i\|\,\|z_j\|}
\]
Interpretation: Cosine similarity measures the angle between two vectors. It is widely used in semantic search because it compares direction rather than raw magnitude.
Nearest-neighbor retrieval searches for the most similar embeddings.
i^{*}
=
\arg\max_{i \in \mathcal{D}}
s(z_q,z_i)
\]
Interpretation: Given a query embedding \(z_q\), the system retrieves the item \(i\) in database \(\mathcal{D}\) whose embedding \(z_i\) is most similar to the query.
Contrastive learning trains representations by pulling related examples together and pushing unrelated examples apart.
\mathcal{L}_{i,j}
=
-\log
\frac{\exp(s(z_i,z_j)/\tau)}
{\sum_{k=1}^{N}\exp(s(z_i,z_k)/\tau)}
\]
Interpretation: A positive pair \((i,j)\) is encouraged to have high similarity relative to other examples \(k\). The temperature parameter \(\tau\) controls how sharply the model separates similarities.
Triplet loss expresses a related idea using an anchor, positive example, and negative example.
\mathcal{L}_{triplet}
=
\max\left(0,\ d(z_a,z_p)-d(z_a,z_n)+m\right)
\]
Interpretation: The anchor \(z_a\) should be closer to the positive example \(z_p\) than to the negative example \(z_n\) by at least margin \(m\). This objective supports metric learning and similarity-based retrieval.
Dimensionality reduction maps high-dimensional embeddings into lower-dimensional visualization spaces.
y_i = g(z_i),
\qquad
y_i \in \mathbb{R}^{2}
\]
Interpretation: A projection function \(g\) maps high-dimensional embedding \(z_i\) into a two-dimensional point \(y_i\) for visualization. The visualization is an approximation, not the original embedding geometry.
Retrieval quality can be summarized by whether relevant items appear in the top \(k\) results.
Recall@k
=
\frac{|Relevant \cap Retrieved_k|}
{|Relevant|}
\]
Interpretation: Recall@k measures how much of the relevant set appears in the top \(k\) retrieved results. It is useful when missing relevant material is costly.
Embedding drift can be monitored by measuring how much representations change over time.
Drift_t
=
\frac{1}{n}
\sum_{i=1}^{n}
\left(1-s(z_i^{(t)},z_i^{(t-1)})\right)
\]
Interpretation: Drift can be approximated by comparing embeddings for the same or comparable items across time. Large drift may indicate model, data, or domain change.
A governance review rule can route embedding systems for review when retrieval or representation quality falls below thresholds.
Review =
\begin{cases}
1, & Recall@k \leq \tau_R \\
1, & BiasRisk \geq \tau_B \\
1, & Drift_t \geq \tau_D \\
1, & MetadataCompleteness \leq \tau_M \\
1, & IndexFreshness \leq \tau_F \\
0, & \mathrm{otherwise}
\end{cases}
\]
Interpretation: Embedding systems should be reviewed when retrieval quality is weak, bias risk is high, drift is large, metadata is incomplete, or the vector index is stale.
Variables and System Interpretation
| Symbol or Term | Meaning | Embedding Interpretation | System Relevance |
|---|---|---|---|
| \(x\) | Input object | Text, image, audio, document, user, item, graph node, or scientific sample. | Raw object being represented. |
| \(f_{\theta}\) | Representation model | Learned function mapping inputs to vectors. | Defines the embedding space. |
| \(\theta\) | Model parameters | Learned weights of the representation system. | Encodes training data and objective effects. |
| \(z\) | Embedding vector | Coordinate representation of an object. | Used for similarity, retrieval, clustering, and classification. |
| \(z_q\) | Query embedding | Vector representation of a search query. | Used in semantic retrieval. |
| \(\mathcal{D}\) | Embedding database | Collection of stored vectors. | Supports vector search and retrieval systems. |
| \(s(z_i,z_j)\) | Similarity function | Cosine similarity, dot product, or distance-derived similarity. | Defines what “near” means. |
| \(d(z_i,z_j)\) | Distance function | Euclidean distance, cosine distance, or learned metric. | Used in metric learning and clustering. |
| \(\tau\) | Temperature | Controls contrastive separation sharpness. | Affects learned alignment and retrieval behavior. |
| \(m\) | Margin | Required separation in triplet loss. | Shapes embedding neighborhoods. |
| \(y_i\) | Projected point | Low-dimensional visualization coordinate. | Useful for inspection but can distort geometry. |
| \(Retrieved_k\) | Top retrieved items | Nearest neighbors returned for a query. | Object of retrieval evaluation. |
| \(\tau\) | Governance threshold | Review boundary for recall, bias, drift, metadata, or freshness. | Turns embedding diagnostics into governance actions. |
Note: Embedding variables are not only mathematical symbols. They describe the operational structure of search, recommendation, clustering, retrieval, and AI knowledge systems.
Worked Example: Semantic Knowledge Retrieval
Consider a sustainability knowledge platform with thousands of articles, references, datasets, code examples, and glossary entries. A keyword search for “water stress” may miss documents about drought, groundwater depletion, watershed resilience, hydrological risk, irrigation pressure, or freshwater change. An embedding-based system can represent documents and queries in semantic space, allowing the platform to retrieve related content even when exact words differ.
A simple retrieval workflow would include:
- Split long articles into meaningful chunks.
- Attach metadata such as article title, category, date, author, and source type.
- Embed each chunk using a selected representation model.
- Store embeddings in a vector index.
- Embed the user query.
- Retrieve nearest neighbors by cosine similarity or another metric.
- Filter by metadata, freshness, domain, or authority.
- Return relevant passages, not just document titles.
- Evaluate retrieval quality using known query-answer pairs.
- Monitor poor searches and update chunking, metadata, or embeddings.
The system’s quality depends on the representation. If embeddings are too general, they may miss domain-specific distinctions. If chunks are too large, retrieval may be vague. If chunks are too small, context may be lost. If metadata is weak, the system may retrieve semantically related but low-authority material. If the embedding model changes, retrieval behavior may shift. Semantic retrieval is therefore a full AI system, not merely a vector operation.
Suppose a user searches for “community flood resilience.” A weak embedding system might retrieve any article containing floods, storms, or infrastructure. A better system would distinguish flood hazard, community capacity, local knowledge, emergency response, public health, housing vulnerability, insurance, drainage systems, and governance. A governed system would also consider source authority, publication date, article category, and whether the retrieved passage actually supports the user’s question.
Query \rightarrow Embedding \rightarrow Retrieval \rightarrow Metadata\ Filter \rightarrow Review
\]
Interpretation: Semantic retrieval becomes reliable when vector similarity is combined with metadata, authority, freshness, evaluation, and human review where needed.
Computational Modeling
Computational modeling can make representation governance concrete. An embedding workflow can generate vectors, search nearest neighbors, compute similarity, evaluate retrieval quality, inspect clusters, detect drift, and produce governance reports. A vector-search workflow can show which documents are returned, which metadata filters were applied, whether similarity is high enough to trust, and whether a query should be routed for review.
The examples below are intentionally lightweight and educational. They do not replace production embedding models, vector databases, approximate nearest-neighbor indexes, domain-specific retrieval benchmarks, or bias audits. Their purpose is to show how representation learning can be evaluated as a system rather than as a hidden model component.
A mature production system would connect these workflows to real embedding models, vector indexes, source registries, metadata schemas, access controls, evaluation queries, user feedback, drift monitors, and governance dashboards. The goal is not merely to retrieve similar vectors. The goal is to ensure that similarity serves the actual knowledge, search, recommendation, or decision-support task.
Python Workflow: Embedding Search and Governance Review
The following Python workflow creates a small synthetic document collection, builds lightweight hashed text embeddings without external dependencies, performs cosine-similarity retrieval, and generates a governance review table for embedding-based search. In production, this structure could be replaced with a domain-specific embedding model and a vector database.
"""
Representation Learning and Embedding Spaces
Python workflow:
- Build a lightweight dependency-free embedding index.
- Perform cosine-similarity retrieval.
- Combine similarity with metadata and authority signals.
- Produce governance diagnostics for semantic search.
- Export retrieval results and review summaries.
This example uses hashed text embeddings so it can run without external
model downloads. In production, replace hashed_embedding() with a domain-
specific embedding model and connect the workflow to a vector database.
"""
from __future__ import annotations
from pathlib import Path
import hashlib
import re
import numpy as np
import pandas as pd
RANDOM_SEED = 42
EMBEDDING_DIM = 128
OUTPUT_DIR = Path("outputs")
OUTPUT_DIR.mkdir(exist_ok=True)
DOCUMENTS = [
{
"doc_id": "D001",
"title": "AI Safety and System Reliability",
"category": "AI Systems",
"source_type": "article",
"authority_score": 0.92,
"freshness_score": 0.88,
"text": (
"AI safety depends on reliability, monitoring, evaluation, "
"incident response, and lifecycle assurance."
),
},
{
"doc_id": "D002",
"title": "Data Governance and Provenance",
"category": "AI Systems",
"source_type": "article",
"authority_score": 0.89,
"freshness_score": 0.91,
"text": (
"Data lineage, metadata, provenance, audit trails, and stewardship "
"support trustworthy AI systems."
),
},
{
"doc_id": "D003",
"title": "Environmental Monitoring",
"category": "Sustainability",
"source_type": "article",
"authority_score": 0.86,
"freshness_score": 0.84,
"text": (
"Environmental monitoring uses sensors, satellite data, uncertainty, "
"and governance to track ecological change."
),
},
{
"doc_id": "D004",
"title": "Generative AI and Synthetic Content",
"category": "AI Systems",
"source_type": "article",
"authority_score": 0.84,
"freshness_score": 0.82,
"text": (
"Generative AI systems produce synthetic content and require "
"provenance, disclosure, review, and governance."
),
},
{
"doc_id": "D005",
"title": "Vector Search and Semantic Retrieval",
"category": "Knowledge Systems",
"source_type": "technical_note",
"authority_score": 0.88,
"freshness_score": 0.93,
"text": (
"Embedding spaces allow semantic search, nearest-neighbor retrieval, "
"vector databases, and relevance ranking."
),
},
{
"doc_id": "D006",
"title": "Infrastructure and Smart Networks",
"category": "Infrastructure",
"source_type": "article",
"authority_score": 0.82,
"freshness_score": 0.79,
"text": (
"Smart infrastructure uses sensors, prediction, optimization, "
"networks, and monitoring to improve resilience."
),
},
{
"doc_id": "D007",
"title": "Community Flood Resilience",
"category": "Sustainability",
"source_type": "article",
"authority_score": 0.87,
"freshness_score": 0.86,
"text": (
"Community flood resilience depends on local knowledge, drainage, "
"housing vulnerability, public health, and emergency response."
),
},
]
def tokenize(text: str) -> list[str]:
"""Tokenize text into simple lowercase word units."""
return re.findall(r"[a-zA-Z][a-zA-Z0-9_-]*", text.lower())
def stable_hash(token: str) -> int:
"""Create a stable integer hash for a token."""
digest = hashlib.sha256(token.encode("utf-8")).hexdigest()
return int(digest[:12], 16)
def hashed_embedding(text: str, dim: int = EMBEDDING_DIM) -> np.ndarray:
"""
Create a simple hashed bag-of-words embedding.
This is not a substitute for a trained semantic embedding model, but it
illustrates vectorization, normalization, and cosine retrieval.
"""
vector = np.zeros(dim, dtype=float)
for token in tokenize(text):
index = stable_hash(token) % dim
sign = 1 if stable_hash(token + "_sign") % 2 == 0 else -1
vector[index] += sign
norm = np.linalg.norm(vector)
if norm == 0:
return vector
return vector / norm
def cosine_similarity(a: np.ndarray, b: np.ndarray) -> float:
"""Compute cosine similarity for normalized or unnormalized vectors."""
denominator = np.linalg.norm(a) * np.linalg.norm(b)
if denominator == 0:
return 0.0
return float(np.dot(a, b) / denominator)
def build_embedding_index(documents: list[dict]) -> pd.DataFrame:
"""Embed each document and return a searchable table."""
rows = []
for document in documents:
embedding_text = (
document["title"]
+ " "
+ document["category"]
+ " "
+ document["source_type"]
+ " "
+ document["text"]
)
embedding = hashed_embedding(embedding_text)
rows.append(
{
**document,
"embedding": embedding,
"embedding_norm": float(np.linalg.norm(embedding)),
}
)
return pd.DataFrame(rows)
def search(index: pd.DataFrame, query: str, top_k: int = 4) -> pd.DataFrame:
"""Search documents using cosine similarity and metadata-aware scoring."""
query_embedding = hashed_embedding(query)
results = index.copy()
results["similarity"] = results["embedding"].apply(
lambda embedding: cosine_similarity(query_embedding, embedding)
)
results["retrieval_score"] = (
0.70 * results["similarity"]
+ 0.18 * results["authority_score"]
+ 0.12 * results["freshness_score"]
)
results["review_flag"] = (
(results["similarity"] < 0.10)
| (results["authority_score"] < 0.80)
| (results["freshness_score"] < 0.75)
| (results["embedding_norm"] < 0.95)
)
columns = [
"doc_id",
"title",
"category",
"source_type",
"authority_score",
"freshness_score",
"similarity",
"retrieval_score",
"review_flag",
]
return results.sort_values("retrieval_score", ascending=False)[columns].head(top_k)
def create_governance_summary(index: pd.DataFrame, queries: list[str]) -> pd.DataFrame:
"""Create governance diagnostics for a set of representative queries."""
rows = []
for query in queries:
results = search(index, query, top_k=3)
rows.append(
{
"query": query,
"top_result": results.iloc[0]["title"],
"top_similarity": results.iloc[0]["similarity"],
"mean_top3_similarity": results["similarity"].mean(),
"mean_top3_authority": results["authority_score"].mean(),
"mean_top3_freshness": results["freshness_score"].mean(),
"review_flags": int(results["review_flag"].sum()),
}
)
summary = pd.DataFrame(rows)
summary["query_review_required"] = (
(summary["top_similarity"] < 0.12)
| (summary["mean_top3_authority"] < 0.82)
| (summary["review_flags"] > 0)
)
return summary
def main() -> None:
"""Run embedding search and governance review."""
index = build_embedding_index(DOCUMENTS)
queries = [
"How do AI systems monitor reliability and incidents?",
"What supports data lineage and provenance?",
"How does semantic retrieval use vector embeddings?",
"How should synthetic content be governed?",
"How does community flood resilience relate to public health?",
]
all_results = []
for query in queries:
results = search(index, query, top_k=4)
results.insert(0, "query", query)
all_results.append(results)
retrieval_results = pd.concat(all_results, ignore_index=True)
governance_summary = create_governance_summary(index, queries)
export_index = index.drop(columns=["embedding"])
export_index.to_csv(
OUTPUT_DIR / "python_embedding_index_metadata.csv",
index=False,
)
retrieval_results.to_csv(
OUTPUT_DIR / "python_embedding_search_results.csv",
index=False,
)
governance_summary.to_csv(
OUTPUT_DIR / "python_embedding_governance_summary.csv",
index=False,
)
memo = f"""# Embedding Search Governance Memo
Documents indexed: {len(index)}
Queries reviewed: {len(queries)}
Mean top-result similarity: {governance_summary["top_similarity"].mean():.4f}
Mean top-three authority: {governance_summary["mean_top3_authority"].mean():.4f}
Queries requiring review: {int(governance_summary["query_review_required"].sum())}
Queries with review flags: {int((governance_summary["review_flags"] > 0).sum())}
Interpretation:
- Embedding-based retrieval should be evaluated with representative queries.
- Similarity should be combined with metadata, authority, and freshness signals.
- Low-similarity retrieval should trigger review rather than automatic trust.
- Embedding model version, chunking, metadata, and vector index status should be documented.
- Search failures should feed back into evaluation sets, metadata rules, and index refresh policy.
"""
(OUTPUT_DIR / "python_embedding_governance_memo.md").write_text(memo)
print(retrieval_results)
print(governance_summary)
print(memo)
if __name__ == "__main__":
main()
This workflow treats semantic retrieval as a governed knowledge-system process. It does not rely only on cosine similarity. It also combines similarity with source authority, freshness, metadata, review flags, and representative query evaluation. That mirrors the article’s central argument: embedding spaces become institutional infrastructure when they determine what users and AI systems can retrieve.
R Workflow: Similarity, Clustering, and Embedding Diagnostics
The following R workflow creates synthetic embeddings for documents, computes cosine similarity, produces a nearest-neighbor table, summarizes cluster diagnostics, and exports governance signals. It is designed as a lightweight statistical review pattern for embedding systems.
# Representation Learning and Embedding Spaces
# R workflow: similarity, clustering, and embedding diagnostics.
set.seed(42)
n_docs <- 100
embedding_dim <- 12
metadata <- data.frame(
doc_id = paste0("D", sprintf("%03d", 1:n_docs)),
domain = sample(
c(
"AI Systems",
"Sustainability",
"Infrastructure",
"Knowledge Systems"
),
size = n_docs,
replace = TRUE
),
authority_score = runif(n_docs, min = 0.55, max = 0.98),
freshness_score = runif(n_docs, min = 0.50, max = 0.99)
)
embeddings <- matrix(
rnorm(n_docs * embedding_dim),
nrow = n_docs,
ncol = embedding_dim
)
# Add domain structure so the synthetic embedding space has interpretable clusters.
for (i in 1:n_docs) {
if (metadata$domain[i] == "AI Systems") {
embeddings[i, 1:3] <- embeddings[i, 1:3] + 1.2
} else if (metadata$domain[i] == "Sustainability") {
embeddings[i, 4:6] <- embeddings[i, 4:6] + 1.2
} else if (metadata$domain[i] == "Infrastructure") {
embeddings[i, 7:9] <- embeddings[i, 7:9] + 1.2
} else {
embeddings[i, 10:12] <- embeddings[i, 10:12] + 1.2
}
}
normalize_rows <- function(x) {
norms <- sqrt(rowSums(x^2))
x / norms
}
cosine_matrix <- function(x) {
normalized <- normalize_rows(x)
normalized %*% t(normalized)
}
similarity <- cosine_matrix(embeddings)
nearest_neighbors <- data.frame()
for (i in 1:n_docs) {
scores <- similarity[i, ]
scores[i] <- -Inf
neighbor_index <- which.max(scores)
nearest_neighbors <- rbind(
nearest_neighbors,
data.frame(
doc_id = metadata$doc_id[i],
domain = metadata$domain[i],
nearest_neighbor = metadata$doc_id[neighbor_index],
neighbor_domain = metadata$domain[neighbor_index],
similarity = similarity[i, neighbor_index],
same_domain = metadata$domain[i] == metadata$domain[neighbor_index],
authority_score = metadata$authority_score[i],
freshness_score = metadata$freshness_score[i]
)
)
}
cluster_fit <- kmeans(embeddings, centers = 4, nstart = 20)
cluster_review <- data.frame(
doc_id = metadata$doc_id,
domain = metadata$domain,
cluster = cluster_fit$cluster,
authority_score = metadata$authority_score,
freshness_score = metadata$freshness_score
)
cluster_summary <- aggregate(
cbind(authority_score, freshness_score) ~ domain + cluster,
data = cluster_review,
FUN = mean
)
domain_summary <- aggregate(
cbind(similarity, same_domain, authority_score, freshness_score) ~ domain,
data = nearest_neighbors,
FUN = mean
)
nearest_neighbors$review_required <- nearest_neighbors$similarity < 0.25 |
nearest_neighbors$same_domain == FALSE |
nearest_neighbors$authority_score < 0.70 |
nearest_neighbors$freshness_score < 0.70
governance_summary <- data.frame(
documents_reviewed = n_docs,
mean_nearest_neighbor_similarity = mean(nearest_neighbors$similarity),
same_domain_neighbor_rate = mean(nearest_neighbors$same_domain),
cluster_count = length(unique(cluster_fit$cluster)),
total_within_cluster_sum_of_squares = cluster_fit$tot.withinss,
mean_authority_score = mean(metadata$authority_score),
mean_freshness_score = mean(metadata$freshness_score),
nearest_neighbor_review_required = sum(nearest_neighbors$review_required)
)
dir.create("outputs", recursive = TRUE, showWarnings = FALSE)
write.csv(
nearest_neighbors,
"outputs/r_nearest_neighbor_review.csv",
row.names = FALSE
)
write.csv(
cluster_review,
"outputs/r_embedding_cluster_review.csv",
row.names = FALSE
)
write.csv(
cluster_summary,
"outputs/r_embedding_cluster_summary.csv",
row.names = FALSE
)
write.csv(
domain_summary,
"outputs/r_embedding_domain_summary.csv",
row.names = FALSE
)
write.csv(
governance_summary,
"outputs/r_embedding_governance_summary.csv",
row.names = FALSE
)
print("Nearest-neighbor review")
print(head(nearest_neighbors, 10))
print("Cluster summary")
print(cluster_summary)
print("Domain summary")
print(domain_summary)
print("Governance summary")
print(governance_summary)
This R workflow mirrors the embedding-governance structure in a compact statistical form. It summarizes nearest-neighbor behavior, same-domain retrieval, clustering structure, authority, freshness, and review flags so the geometry of the embedding space can be interpreted as an operational system rather than only a mathematical object.
GitHub Repository
The article body includes selected computational examples so the conceptual and mathematical argument remains readable. The full repository can hold expanded workflows for embedding generation, vector search, similarity metrics, clustering diagnostics, vector-index metadata, governance review, retrieval evaluation, dimensionality reduction, drift monitoring, bias diagnostics, and API/dashboard tooling.
From Vector Space to Accountable Meaning
Representation learning and embedding spaces show why modern artificial intelligence depends on learned infrastructures of meaning. A text, image, audio clip, molecule, document, user, or sensor record becomes computationally usable because a model maps it into a space where similarity, distance, clustering, retrieval, classification, and recommendation can operate. This is one of the central technical foundations of contemporary AI.
The central lesson is that embeddings are powerful because they make meaning computable, but they are risky because they make meaning approximate. A vector space is not the world. It is a learned geometry shaped by training data, objectives, architecture, preprocessing, metric choice, index design, metadata, and deployment context. Similarity can be useful, but it can also be biased, stale, shallow, or misleading.
This article also shows why embedding systems require governance. Vector search, semantic retrieval, RAG pipelines, recommender systems, multimodal search, scientific discovery tools, and knowledge platforms all depend on the quality of the representation space. Responsible teams should document embedding models, source corpora, chunking rules, index versions, similarity metrics, evaluation sets, bias checks, drift signals, and user feedback loops.
The strongest embedding systems will not be those that merely produce dense vectors at scale. They will be those that connect vector similarity to source authority, task relevance, metadata, freshness, access control, evaluation, and accountability. Representation learning gives AI systems their learned coordinate systems. Governance determines whether those coordinates serve knowledge, discovery, and responsible action rather than false relevance or invisible bias.
Within the Artificial Intelligence Systems knowledge series, this article belongs near Machine Learning Foundations: How Systems Learn from Data, Deep Learning Systems: Representation, Scale, and Generalization, Self-Supervised Learning and Foundation Models, Transfer Learning, Fine-Tuning, and Model Adaptation, Retrieval-Augmented Generation and AI Knowledge Systems, Natural Language Processing and Computational Language Systems, Generative AI and Synthetic Content Systems, and Data Governance, Provenance, and Lineage in AI Systems. It provides the representational layer for understanding how AI systems organize meaning before they search, generate, recommend, classify, or decide.
Related Articles
- Artificial Intelligence Systems
- Machine Learning Foundations: How Systems Learn from Data
- Deep Learning Systems: Representation, Scale, and Generalization
- Self-Supervised Learning and Foundation Models
- Transfer Learning, Fine-Tuning, and Model Adaptation
- Large Language Models and Foundation Model Systems
- Retrieval-Augmented Generation and AI Knowledge Systems
- Natural Language Processing and Computational Language Systems
- Speech Recognition and Multimodal AI Systems
- Generative AI and Synthetic Content Systems
- Data Governance, Provenance, and Lineage in AI Systems
- Model Validation, Benchmarking, and Generalization Theory
Further Reading
- Goodfellow, I., Bengio, Y. and Courville, A. (2016) Deep Learning. MIT Press. Available at: https://www.deeplearningbook.org/
- Mikolov, T., Chen, K., Corrado, G. and Dean, J. (2013) ‘Efficient Estimation of Word Representations in Vector Space’. Available at: https://arxiv.org/abs/1301.3781
- Pennington, J., Socher, R. and Manning, C.D. (2014) ‘GloVe: Global Vectors for Word Representation’, Proceedings of the 2014 Conference on Empirical Methods in Natural Language Processing. Available at: https://aclanthology.org/D14-1162/
- Vaswani, A. et al. (2017) ‘Attention Is All You Need’, Advances in Neural Information Processing Systems. Available at: https://arxiv.org/abs/1706.03762
- Reimers, N. and Gurevych, I. (2019) ‘Sentence-BERT: Sentence Embeddings using Siamese BERT-Networks’. Available at: https://arxiv.org/abs/1908.10084
- Radford, A. et al. (2021) ‘Learning Transferable Visual Models From Natural Language Supervision’. Available at: https://arxiv.org/abs/2103.00020
- Johnson, J., Douze, M. and Jégou, H. (2017) ‘Billion-scale similarity search with GPUs’. Available at: https://arxiv.org/abs/1702.08734
- van der Maaten, L. and Hinton, G. (2008) ‘Visualizing Data using t-SNE’, Journal of Machine Learning Research. Available at: https://www.jmlr.org/papers/v9/vandermaaten08a.html
- McInnes, L., Healy, J. and Melville, J. (2018) ‘UMAP: Uniform Manifold Approximation and Projection for Dimension Reduction’. Available at: https://arxiv.org/abs/1802.03426
- NIST (2023) Artificial Intelligence Risk Management Framework (AI RMF 1.0). Available at: https://www.nist.gov/publications/artificial-intelligence-risk-management-framework-ai-rmf-10
References
- Goodfellow, I., Bengio, Y. and Courville, A. (2016) Deep Learning. MIT Press. Available at: https://www.deeplearningbook.org/
- Johnson, J., Douze, M. and Jégou, H. (2017) ‘Billion-scale similarity search with GPUs’. Available at: https://arxiv.org/abs/1702.08734
- McInnes, L., Healy, J. and Melville, J. (2018) ‘UMAP: Uniform Manifold Approximation and Projection for Dimension Reduction’. Available at: https://arxiv.org/abs/1802.03426
- Mikolov, T., Chen, K., Corrado, G. and Dean, J. (2013) ‘Efficient Estimation of Word Representations in Vector Space’. Available at: https://arxiv.org/abs/1301.3781
- NIST (2023) Artificial Intelligence Risk Management Framework (AI RMF 1.0). Available at: https://www.nist.gov/publications/artificial-intelligence-risk-management-framework-ai-rmf-10
- Pennington, J., Socher, R. and Manning, C.D. (2014) ‘GloVe: Global Vectors for Word Representation’, Proceedings of the 2014 Conference on Empirical Methods in Natural Language Processing. Available at: https://aclanthology.org/D14-1162/
- Radford, A. et al. (2021) ‘Learning Transferable Visual Models From Natural Language Supervision’. Available at: https://arxiv.org/abs/2103.00020
- Reimers, N. and Gurevych, I. (2019) ‘Sentence-BERT: Sentence Embeddings using Siamese BERT-Networks’. Available at: https://arxiv.org/abs/1908.10084
- van der Maaten, L. and Hinton, G. (2008) ‘Visualizing Data using t-SNE’, Journal of Machine Learning Research. Available at: https://www.jmlr.org/papers/v9/vandermaaten08a.html
- Vaswani, A. et al. (2017) ‘Attention Is All You Need’, Advances in Neural Information Processing Systems. Available at: https://arxiv.org/abs/1706.03762