Retrieval-Augmented Generation and AI Knowledge Systems
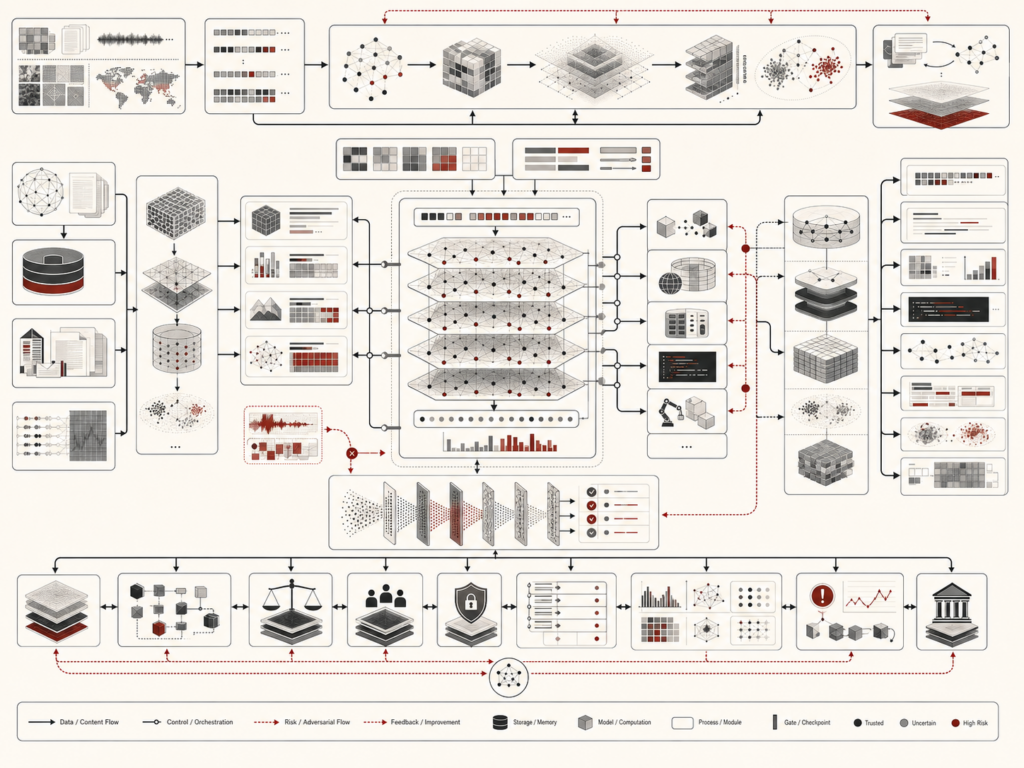
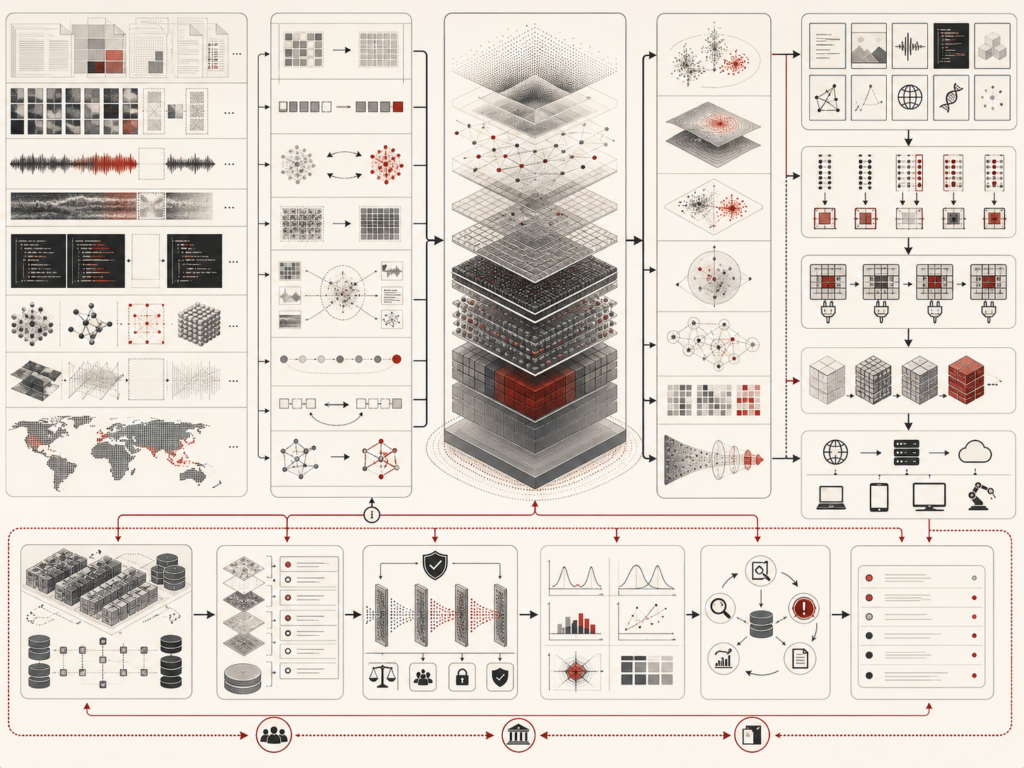
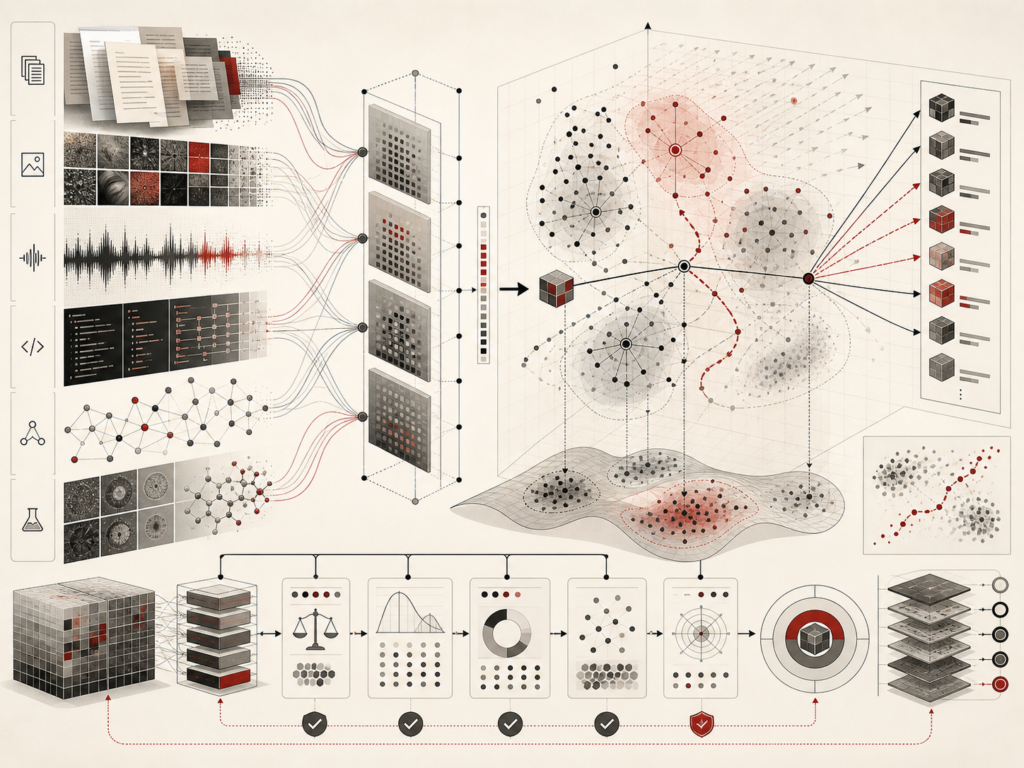
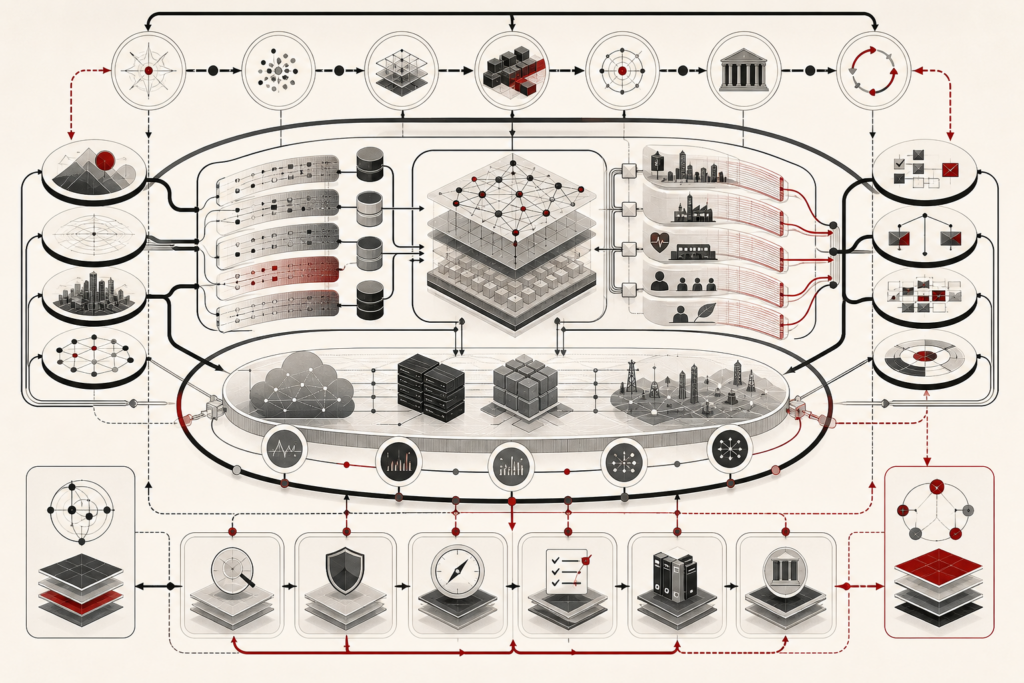
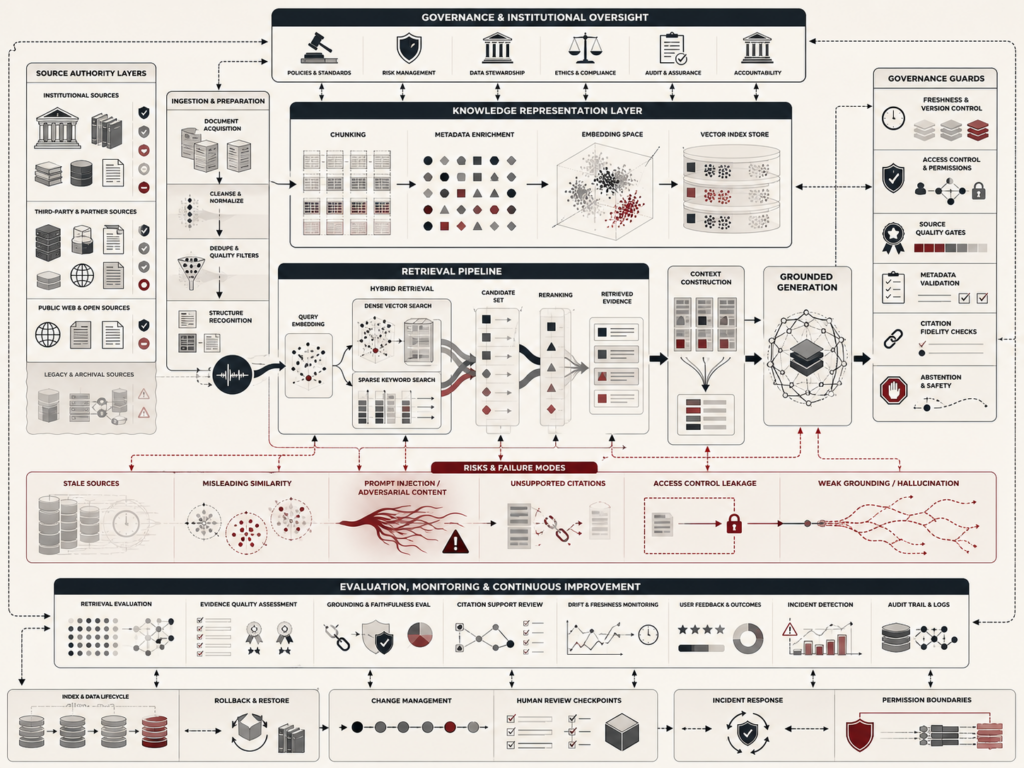
Retrieval-augmented generation and AI knowledge systems connect large language models with external sources of evidence so generated answers can be grounded, updated, cited, evaluated, and governed. Instead of relying only on information stored in model parameters, a RAG system searches documents, databases, knowledge bases, vector indexes, metadata catalogs, structured records, or search engines and conditions generation on retrieved evidence. This article explains the architecture of RAG systems, including document ingestion, chunking, embeddings, vector search, hybrid retrieval, reranking, context construction, grounded generation, citation fidelity, freshness, versioning, access control, prompt-injection defense, and monitoring. It argues that RAG should be treated not as a simple model enhancement, but as a governed AI knowledge architecture where source quality, retrieval design, security, evaluation, and institutional accountability determine trustworthiness.