Model Validation, Benchmarking, and Generalization Theory
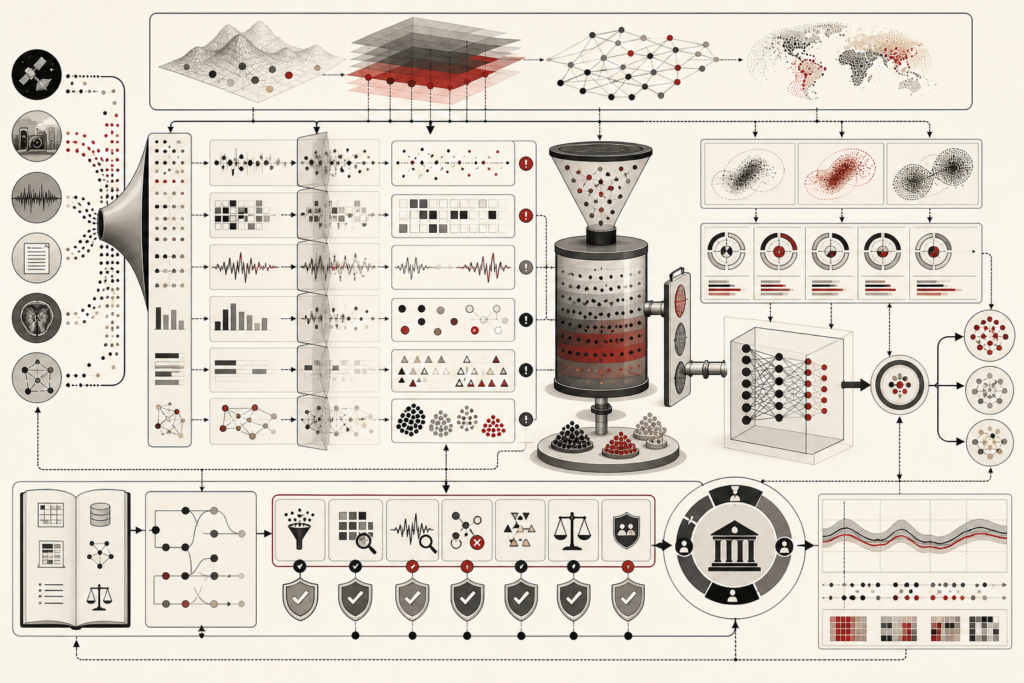
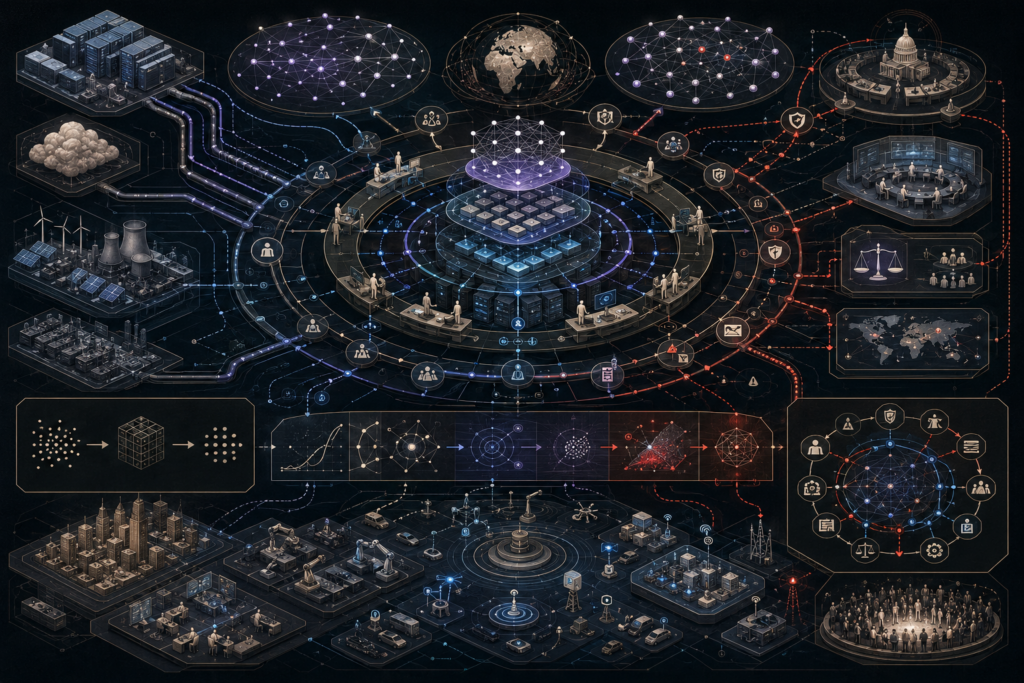
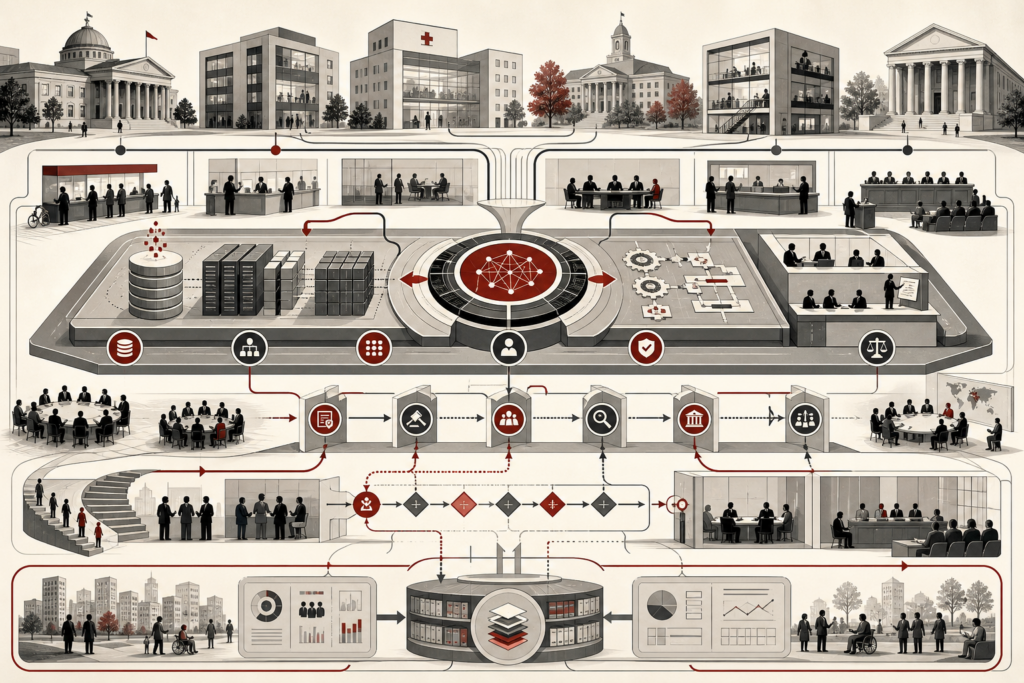
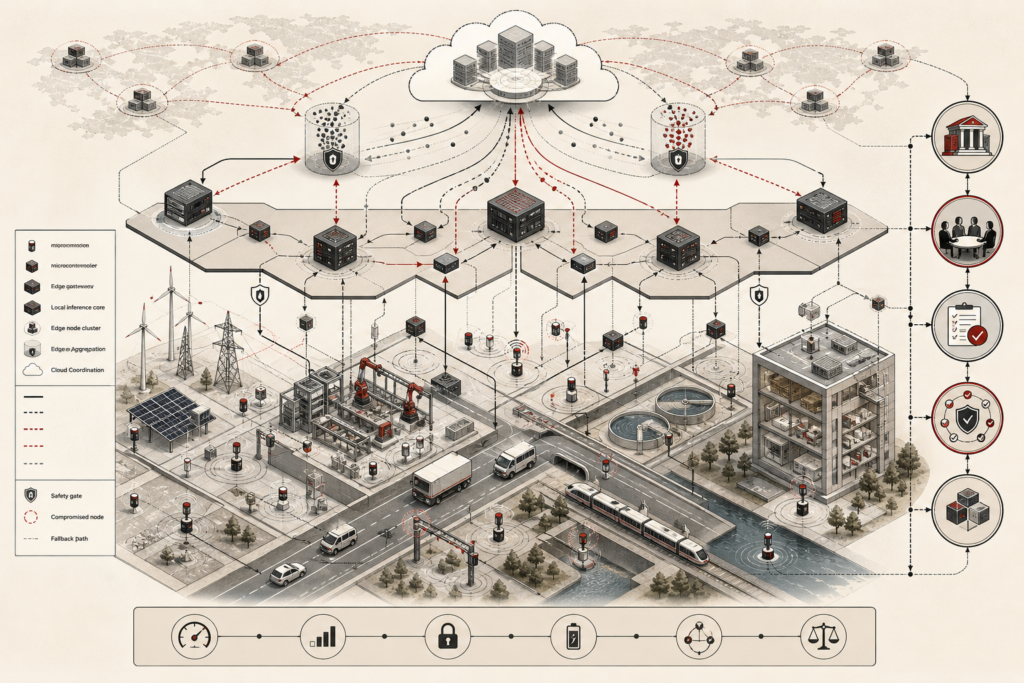
Model validation, benchmarking, and generalization theory examine whether machine learning systems produce reliable, reproducible, and transferable results beyond their training data. This article explains empirical risk, expected risk, generalization gaps, VC theory, PAC learning, model capacity, train-validation-test splits, cross-validation, resampling, overfitting, underfitting, metric alignment, benchmark saturation, distribution shift, external validity, uncertainty estimation, calibration, system-level evaluation, and governance. It shows why model evaluation cannot be reduced to a single score, since performance claims depend on validation design, dataset structure, benchmark quality, calibration, robustness, and deployment context. The article also introduces mathematical lenses for risk estimation, validation loss, cross-validation, distribution shift, calibration, expected calibration error, and benchmark saturation, alongside Python and R workflows for generalization-gap diagnostics, calibration analysis, benchmark comparison, distribution-shift testing, and validation governance.