
Last Updated May 10, 2026
Edge AI and distributed intelligence refer to artificial intelligence systems that move computation, learning, inference, coordination, and decision-making closer to where data is generated, rather than relying exclusively on centralized cloud infrastructure. This paradigm transforms AI from a remote service into a distributed system of interacting devices, sensors, gateways, embedded processors, edge servers, cloud platforms, local operators, and human-governed workflows operating across heterogeneous physical and digital environments.
Edge AI emerges in response to fundamental limits of centralized architectures: latency, bandwidth, privacy, resilience, energy, data sovereignty, real-time control, cyber-physical safety, and operational continuity. In centralized AI, data often moves to the model. In edge and distributed intelligence systems, models, updates, inference, summaries, alerts, and coordination move closer to data sources. This shift is especially important for industrial monitoring, autonomous systems, smart infrastructure, healthcare devices, environmental sensing, robotics, transportation, energy systems, agriculture, logistics, security, and cyber-physical systems where decisions must occur locally, quickly, and reliably.
The central argument of this article is that edge AI is not merely AI “deployed on smaller devices.” It is a systems architecture for distributing intelligence across networks. The key question is not whether edge or cloud is better in the abstract. The stronger question is which tasks should occur at the device, which should occur at the edge, which should occur in the cloud, and how the whole distributed system should be governed, secured, monitored, updated, and held accountable. Edge intelligence makes AI more local, responsive, resilient, and privacy-aware, but it also multiplies the number of nodes, dependencies, vulnerabilities, and governance responsibilities that must be managed.
Main Library
Publications
Article Map
Artificial Intelligence Systems
Related Topic
Embedded & Edge Systems
Related Topic
Intelligent Infrastructure Systems
Related Topic
Environmental Monitoring Systems
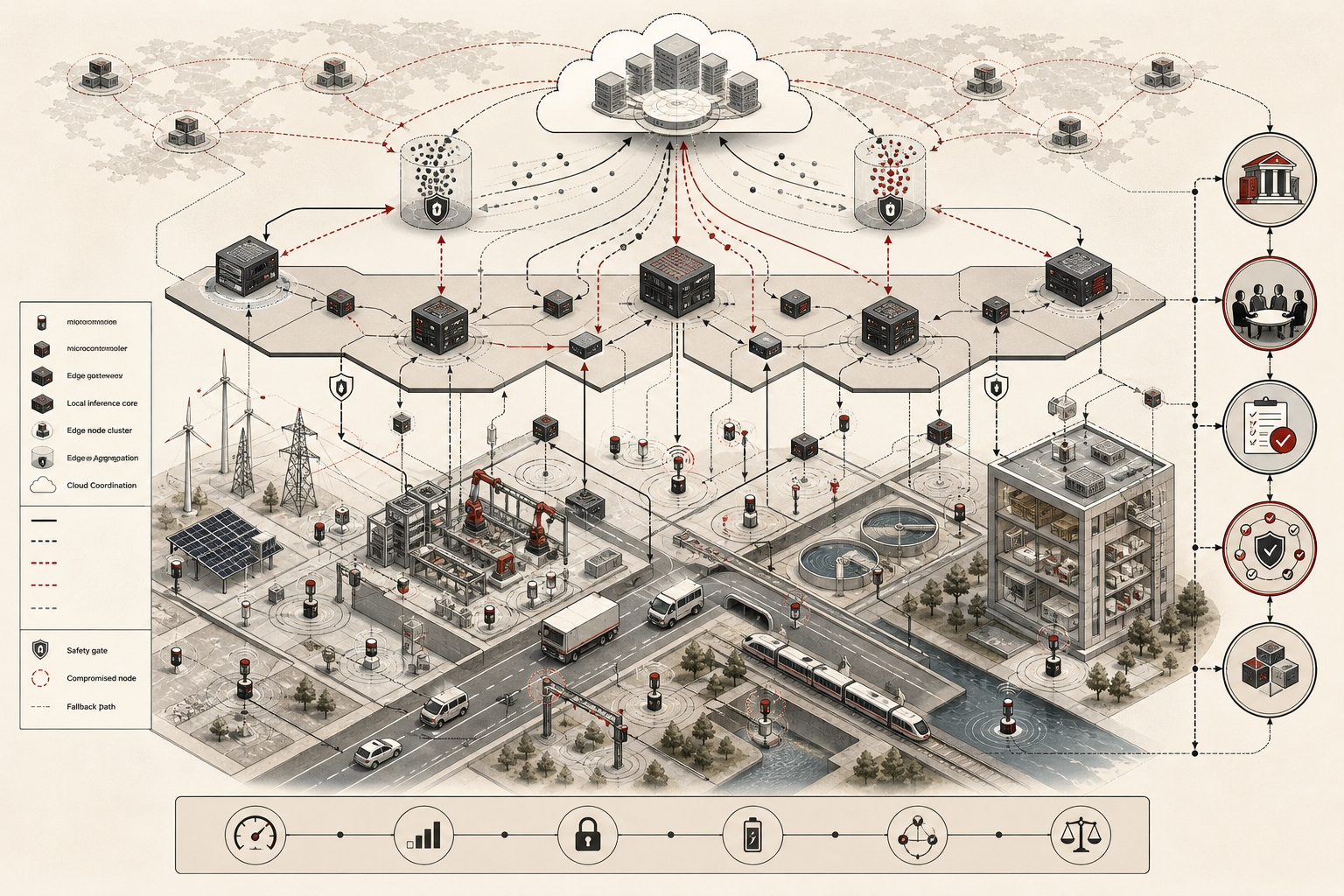
This article develops Edge AI and Distributed Intelligence as an advanced article within the Artificial Intelligence Systems knowledge series. It explains edge intelligence, distributed AI, multi-access edge computing, cloud-edge-device architectures, federated learning, distributed optimization, resource-constrained inference, TinyML, latency and bandwidth constraints, resilience, fault tolerance, privacy, secure aggregation, adversarial risk, governance, and cyber-physical integration. Selected Python and R examples appear here, while the full GitHub repository contains expanded computational scaffolding for edge-node simulation, federated averaging, latency-budget modeling, bandwidth analysis, node-failure resilience, governance scoring, SQL metadata, and advanced Jupyter notebooks.
Why Edge AI and Distributed Intelligence Matter
Edge AI matters because many important AI systems cannot wait for centralized cloud processing. A smart grid fault, an autonomous vehicle hazard, an industrial vibration anomaly, a wildfire sensor signal, a medical-device alert, a robotic control adjustment, a traffic-safety event, or a water-system failure may require local inference under strict latency, bandwidth, privacy, and reliability constraints. In these settings, intelligence must be close to the event.
Centralized cloud AI remains powerful for large-scale training, storage, orchestration, analytics, fleet management, benchmarking, and complex inference. But cloud-only architectures can create dependency on network availability, expose sensitive data to transmission risk, impose bandwidth costs, increase latency, centralize operational control, and introduce single points of failure. Edge AI changes the architecture by distributing computation across local devices, gateways, edge servers, and cloud backends.
The central systems question is therefore not “edge or cloud?” The stronger question is: which tasks should occur at the device, which should occur at the edge, which should occur in the cloud, and how should the whole system be governed? Edge AI is not a rejection of cloud AI. It is a reallocation of intelligence across a layered computational system.
Distributed\ Intelligence = Local\ Inference + Networked\ Coordination + Cloud\ Governance
\]
Interpretation: Edge AI combines local decision capacity with distributed coordination and cloud-scale governance, analytics, and model management.
| Constraint | Centralized AI Risk | Edge AI Response | Example |
|---|---|---|---|
| Latency | Cloud round trips may be too slow for real-time action. | Run inference close to the event. | Industrial safety, robotics, autonomous systems. |
| Bandwidth | Raw data streams are expensive or impossible to transmit continuously. | Filter, summarize, classify, or compress locally. | Video analytics, sensor networks, environmental monitoring. |
| Privacy | Sensitive raw data leaves local environments. | Keep raw data local and transmit only updates or summaries. | Healthcare devices, mobile systems, public infrastructure. |
| Resilience | Cloud or network failure can interrupt decision capacity. | Preserve local autonomy and fallback behavior. | Smart grids, emergency response, remote operations. |
| Energy and cost | Continuous transmission and centralized inference may be costly. | Use efficient local inference and selective transmission. | Agriculture, logistics, remote sensing, industrial IoT. |
| Data sovereignty | Data transfer may violate local rules, contracts, or governance norms. | Train or infer near the jurisdiction or owner of the data. | Cross-institution healthcare, government, finance, research networks. |
| Cyber-physical control | Delayed or unavailable inference can affect physical safety. | Close the loop between sensing, inference, and action locally. | Transportation, water systems, energy systems, factories. |
Note: Edge AI is most valuable where time, bandwidth, privacy, resilience, and physical action make centralized processing insufficient.
Foundations of Edge AI and Distributed Intelligence
Edge intelligence refers to the execution of AI tasks near the sources of data. These tasks may include inference, filtering, compression, anomaly detection, feature extraction, local adaptation, privacy-preserving learning, device-level control, and context-sensitive alerting. Distributed intelligence generalizes this idea by describing systems in which multiple computational agents cooperate, coordinate, or learn across a network.
A centralized AI pattern can be represented as:
Data \rightarrow Cloud \rightarrow Model \rightarrow Decision
\]
Interpretation: In centralized AI, data is transmitted to a remote cloud system where model computation and decision support occur.
An edge AI pattern can be represented as:
Data_{local} \rightarrow Edge\ Model \rightarrow Local\ Decision
\]
Interpretation: In edge AI, local data is processed near its source, enabling faster and more context-sensitive decisions.
Distributed intelligence can be represented as:
\{Node_1,Node_2,\ldots,Node_n\} \rightarrow Coordinated\ Intelligence
\]
Interpretation: Distributed intelligence emerges from multiple nodes coordinating across a network.
The result is a shift from monolithic machine learning to networked intelligence. In these systems, intelligence is not concentrated in a single model or server. It is distributed across devices, data flows, communication protocols, model updates, local decisions, and governance mechanisms.
| Concept | Meaning | System Role | Governance Concern |
|---|---|---|---|
| Edge AI | AI computation performed near data sources. | Enables low-latency inference, filtering, and local response. | Local models must be monitored, updated, and secured. |
| Distributed intelligence | Intelligence produced by multiple interacting computational nodes. | Coordinates sensing, inference, learning, and action across networks. | Failures, updates, and responsibilities are distributed. |
| Device layer | Sensors, microcontrollers, embedded processors, mobile devices, robots. | Collects data and may perform inference or control. | Physical security, energy limits, and update integrity matter. |
| Edge layer | Gateways, local servers, industrial controllers, edge clusters. | Aggregates local signals and performs heavier local computation. | Controls access, orchestration, and local decision workflows. |
| Cloud layer | Centralized training, analytics, storage, orchestration, and fleet management. | Coordinates models, updates, monitoring, and governance at scale. | Must not become a single point of failure or opaque control center. |
| Federated learning | Shared learning without centralizing raw data. | Trains global models from local updates. | Requires secure aggregation, privacy protection, and client governance. |
Note: Edge AI is best understood as a layered architecture that distributes computation, data, and authority across devices, edge systems, and cloud coordination.
Architectural Models: Cloud, Edge, Device, and Hybrid Systems
Edge AI systems usually operate across several layers. The device layer includes sensors, cameras, microcontrollers, mobile devices, robots, meters, medical devices, vehicles, and embedded systems. The edge layer includes gateways, industrial controllers, base-station compute, local servers, edge clusters, and multi-access edge computing environments. The cloud layer provides centralized model training, storage, orchestration, analytics, fleet management, large-scale inference, and governance services. The application layer includes human interfaces, dashboards, alerts, control systems, decision workflows, and institutional processes.
A hybrid cloud-edge-device architecture can be represented as:
Device \leftrightarrow Edge \leftrightarrow Cloud \leftrightarrow Governance
\]
Interpretation: Hybrid architectures coordinate computation across devices, edge infrastructure, cloud systems, and governance controls.
Centralized architectures are useful when computation is heavy, latency is less critical, and data can be transmitted lawfully and securely. Edge architectures are useful when low latency, privacy, reliability, or bandwidth reduction is essential. Hybrid architectures are increasingly dominant because they allow different parts of the workload to run where they make the most sense.
The architecture should follow the task. A wind-turbine vibration alert may need immediate edge inference. Long-term fleet analytics may belong in the cloud. Model updates may be coordinated centrally while raw data remains local. Governance must cover all layers because failures can occur at any point in the distributed system.
| Architecture | Where Computation Occurs | Best Fit | Key Risk |
|---|---|---|---|
| Cloud-only AI | Remote data centers and centralized model services. | Large-scale training, heavy inference, analytics, long-horizon modeling. | Latency, bandwidth, network dependence, centralization, privacy exposure. |
| Device AI | On sensors, embedded processors, phones, robots, or microcontrollers. | Immediate local inference and ultra-low-latency control. | Compute, memory, energy, update, and security constraints. |
| Edge AI | On gateways, local servers, edge clusters, or base-station compute. | Local aggregation, anomaly detection, inference, and coordination. | Operational complexity and distributed security exposure. |
| Hybrid cloud-edge AI | Tasks distributed across device, edge, and cloud layers. | Systems that need both local autonomy and global coordination. | Lineage, update governance, and failure propagation across layers. |
| Federated architecture | Local clients train or adapt models; a server aggregates updates. | Privacy-sensitive, cross-institution, or data-sovereign learning. | Non-IID data, malicious clients, privacy leakage, communication overhead. |
| Split computing | Model computation is divided between device, edge, and cloud. | Workloads where local preprocessing and remote heavy computation both matter. | Partition failure, dependency on link quality, and attack-surface expansion. |
Note: Architecture is a governance decision as much as a technical decision, because it determines where data moves, where authority sits, and where failure can occur.
Distributed Artificial Intelligence and Multi-Agent Systems
Distributed artificial intelligence provides a theoretical foundation for edge AI. In distributed AI, multiple agents operate with partial information, local objectives, communication constraints, and coordination mechanisms. Each node may observe only part of the environment, but collective behavior can produce system-level intelligence.
A multi-agent system can be represented as:
Agent_i=(State_i,Policy_i,Observation_i,Communication_i)
\]
Interpretation: Each agent has a local state, policy, observation stream, and communication channel.
The distributed system can be represented as a graph:
G=(V,E,W)
\]
Interpretation: A distributed intelligence network includes nodes \(V\), edges \(E\), and communication or dependency weights \(W\).
This graph view is essential. Distributed intelligence is shaped by topology: which nodes communicate, how frequently they communicate, how reliable the links are, which nodes are trusted, which nodes fail, which nodes coordinate updates, and which nodes control shared resources.
Distributed AI systems exhibit local autonomy, partial observability, coordination, emergent behavior, heterogeneity, and resilience. The challenge is that distributed systems can also fail in distributed ways. Errors can propagate through communication channels, compromised nodes can poison updates, synchronization can break, and inconsistent local decisions can create system-level instability.
| Property | System Meaning | Potential Benefit | Failure Mode |
|---|---|---|---|
| Local autonomy | Nodes can act without constant cloud control. | Improves latency, continuity, and local responsiveness. | Local decisions may diverge from system goals. |
| Partial observability | Each node sees only part of the environment. | Supports scalable local sensing. | Nodes may make decisions from incomplete context. |
| Coordination | Nodes exchange messages, updates, alerts, or model parameters. | Enables collective intelligence and shared learning. | Communication failures or malicious messages can destabilize the system. |
| Heterogeneity | Nodes differ in hardware, data, energy, sensors, and reliability. | Allows flexible deployment across real environments. | Model performance and update quality vary across nodes. |
| Emergent behavior | System outcomes arise from interactions among nodes. | Enables adaptation and collective response. | Unexpected cascades, oscillations, or conflicting actions can emerge. |
| Resilience | Some failures can be absorbed locally. | Reduces dependence on one centralized service. | Distributed failure modes become harder to detect and audit. |
Note: Distributed intelligence creates both distributed capability and distributed responsibility.
Federated Learning and Distributed Optimization
Federated learning is one of the most important paradigms in distributed intelligence. It enables multiple clients to train a shared model without centralizing all raw data. Each client trains locally and sends model updates or gradients to an aggregator. The aggregator combines these updates into a new global model.
A standard federated objective can be written as:
\min_w \sum_{i=1}^{n} p_i F_i(w)
\]
Interpretation: Federated learning minimizes a weighted combination of local loss functions \(F_i(w)\) across distributed clients.
The FedAvg update can be represented as:
w_{t+1}=\sum_{i=1}^{n} p_i w_{t,i}
\]
Interpretation: The next global model is a weighted average of client model updates.
Federated learning is especially useful when raw data is sensitive, large, legally restricted, locally governed, or expensive to transfer. It is relevant for mobile devices, healthcare systems, industrial sites, financial institutions, public agencies, smart infrastructure, and cross-organization research collaborations.
However, federated learning is not a complete privacy solution by itself. Model updates can leak information. Clients may be malicious. Data may be non-IID, meaning each client’s local distribution differs from others. Devices may drop out. Communication may be expensive. Secure aggregation, differential privacy, robust aggregation, client selection, and governance controls are often needed.
| Dimension | Benefit | Risk | Control |
|---|---|---|---|
| Raw data locality | Raw data can remain on local devices or institutional systems. | Local data may still be poorly governed or biased. | Local data-quality checks and participant governance. |
| Shared model learning | Clients contribute to a global model without centralizing records. | Non-IID data can reduce convergence and fairness. | Client weighting, personalization, and subgroup evaluation. |
| Privacy protection | Less raw data moves across networks. | Gradients or model updates may leak information. | Secure aggregation and differential privacy. |
| Communication efficiency | Only updates may be transmitted instead of raw data. | Frequent updates can still be bandwidth-intensive. | Update compression, client sampling, and communication scheduling. |
| Resilience | Learning can continue across many clients. | Client dropout or unreliable nodes can distort updates. | Robust aggregation and availability-aware scheduling. |
| Security | Distributed learning avoids a single raw-data repository. | Malicious clients can poison updates. | Trust scoring, anomaly detection, signed updates, and robust aggregation. |
| Governance | Data rights can remain more local. | Responsibility for model outcomes becomes distributed. | Federated participation agreements, audit logs, and update provenance. |
Note: Federated learning shifts the AI problem from centralized data collection to distributed optimization, communication, security, and governance.
Edge Computing and Resource-Constrained Inference
Edge devices operate under constraints that cloud systems often avoid. They may have limited processors, memory, storage, battery life, thermal capacity, network access, and maintenance windows. Edge AI therefore requires model and system design that respects physical limits.
A resource constraint can be represented as:
Compute_{model} \leq Compute_{device}
\]
Interpretation: A model can run at the edge only if its compute demand fits within the device’s compute budget.
A broader edge-feasibility condition is:
Feasible = 1 \quad \mathrm{if} \quad Latency \leq L_{max},\ Energy \leq E_{max},\ Memory \leq M_{max}
\]
Interpretation: Edge deployment is feasible only when latency, energy, and memory remain within device limits.
Common strategies include model compression, quantization, pruning, knowledge distillation, early-exit architectures, hardware-aware neural architecture search, TinyML, split computing, and event-driven inference. The best edge AI system is not necessarily the most accurate model in isolation. It is the model that satisfies the application’s accuracy, latency, energy, cost, reliability, security, maintainability, and governance requirements.
| Strategy | What It Does | Why It Helps | Tradeoff |
|---|---|---|---|
| Quantization | Uses lower-precision numerical representations. | Reduces memory and compute cost. | May reduce accuracy or require careful calibration. |
| Pruning | Removes unnecessary weights, neurons, or structures. | Reduces model size and inference cost. | Can damage performance if too aggressive. |
| Knowledge distillation | Trains a smaller model to approximate a larger model. | Makes powerful behavior more deployable at the edge. | Distilled models may inherit teacher limitations. |
| Early exits | Allows simple cases to finish inference before full computation. | Saves latency and energy. | Requires confidence calibration and fallback design. |
| TinyML | Runs machine learning on ultra-low-power microcontrollers. | Supports remote, battery-powered, and embedded applications. | Severe memory, compute, and update constraints. |
| Split computing | Divides computation across device, edge, and cloud layers. | Balances local speed with remote capacity. | Requires reliable partitioning, communication, and security. |
| Event-driven inference | Runs models only when triggers or anomalies occur. | Saves energy and bandwidth. | Trigger logic may miss rare or subtle events. |
Note: Edge AI design is a multi-objective optimization problem, not a simple accuracy race.
Latency, Bandwidth, and Real-Time Constraints
Latency is central to edge AI. If a system must respond within milliseconds, cloud round trips may be too slow or unreliable. Edge processing reduces delay by keeping inference close to the physical event.
Total cloud-based latency can be represented as:
T_{cloud}=T_{uplink}+T_{cloud\_infer}+T_{downlink}
\]
Interpretation: Cloud inference latency includes upload time, remote inference time, and download time.
Edge inference latency can be represented as:
T_{edge}=T_{local\_infer}+T_{local\_act}
\]
Interpretation: Edge inference latency includes local inference and local action time.
Bandwidth constraints also matter. High-resolution video, industrial sensor streams, environmental data, vehicle telemetry, medical monitoring, smart-grid measurements, and security systems can generate enormous data volumes. Transmitting all raw data to the cloud may be technically or economically infeasible.
A bandwidth-reduction ratio can be written as:
B_{save}=1-\frac{B_{edge\_output}}{B_{raw}}
\]
Interpretation: Bandwidth savings increase when the edge transmits compact outputs instead of raw data.
Edge AI often converts high-volume raw streams into smaller local signals: alerts, classifications, compressed features, anomalies, summaries, or control actions. This is not only an efficiency gain. It changes what information leaves the local environment, which also affects privacy, security, and data governance.
| Question | Why It Matters | Cloud-Only Risk | Edge Design Response |
|---|---|---|---|
| How fast must the system respond? | Some physical systems require millisecond-scale action. | Network latency exceeds response budget. | Use local inference and local actuation. |
| How much raw data is generated? | Continuous streams can overwhelm networks. | Bandwidth costs or loss of visibility. | Filter, compress, summarize, or detect anomalies locally. |
| What happens when connectivity fails? | Cloud dependence can break operational continuity. | No inference, monitoring, or control during outage. | Local fallback and offline-safe modes. |
| What data must leave the local environment? | Transmission affects privacy, sovereignty, and attack surface. | Sensitive raw data moves unnecessarily. | Transmit metadata, alerts, or model updates instead of raw records. |
| How variable is network performance? | Latency and jitter can destabilize real-time systems. | Unpredictable response times. | Design for worst-case local response requirements. |
Note: Edge AI is often justified when latency and bandwidth constraints are not incidental but central to system safety and usefulness.
Resilience, Fault Tolerance, and System Robustness
Distributed intelligence can improve resilience by avoiding dependence on a single centralized system. If one node fails, other nodes may continue operating. If cloud connectivity is lost, local systems may still perform safety-critical inference. If one sensor degrades, neighboring sensors may compensate.
A resilience score can be represented as:
R=1-P(System\ Failure)
\]
Interpretation: Resilience increases as the probability of system-level failure decreases.
For independent redundant nodes, a simple availability model is:
P(All\ Fail)=\prod_{i=1}^{n} q_i
\]
Interpretation: If node failures are independent, the probability that all nodes fail is the product of individual failure probabilities \(q_i\).
But distributed systems also introduce new fragilities. Nodes may disagree. Updates may be inconsistent. Local models may drift. Network partitions may isolate components. Malicious nodes may inject bad updates. Overly tight coupling can create cascading failures.
Resilience requires local fallback modes, redundant sensing and computation, health monitoring, graceful degradation, rollback, fail-safe behavior, robust aggregation, anomaly detection, incident response, and clear authority for override and recovery. Distributed intelligence should therefore be designed not only for performance, but for failure.
| Resilience Feature | Purpose | Failure It Addresses | Design Requirement |
|---|---|---|---|
| Local fallback | Maintain basic function without cloud connectivity. | Network outage or cloud service disruption. | Define safe offline operating modes. |
| Redundancy | Use multiple sensors, nodes, or pathways. | Single node or sensor failure. | Avoid hidden common-mode failures. |
| Graceful degradation | Reduce capability safely rather than fail catastrophically. | Resource exhaustion, model uncertainty, partial data loss. | Prioritize safety-critical functions. |
| Health monitoring | Detect node, sensor, model, and communication problems. | Silent drift or degraded local performance. | Monitor edge nodes as first-class system components. |
| Rollback | Return to a known safe model or configuration. | Bad model update, poisoning, or deployment defect. | Version edge models and update packages. |
| Robust aggregation | Limit the influence of bad or malicious updates. | Federated poisoning or anomalous clients. | Use anomaly detection, trust scores, and robust statistics. |
| Human override | Allow authorized intervention when automated behavior is unsafe. | Incorrect local action or conflicting signals. | Preserve meaningful operational authority. |
Note: Distributed resilience requires both technical redundancy and governance clarity about who can intervene when edge systems fail.
Security, Privacy, and Trust in Distributed AI
Edge AI and distributed intelligence alter the security and privacy landscape. On one hand, local processing can reduce exposure by keeping raw data near its source. On the other hand, distributing intelligence across many devices expands the attack surface. Each node can become a target.
Security risks include device compromise, malicious model updates, data poisoning, model inversion, membership inference, adversarial inputs, software supply-chain vulnerabilities, unauthorized edge access, insecure communication channels, physical tampering, weak update mechanisms, and poorly governed third-party components.
A trust-weighted aggregation can be represented as:
w_{t+1}=\sum_{i=1}^{n} \alpha_i w_{t,i}
\]
Interpretation: Distributed model updates can be aggregated with trust weights \(\alpha_i\) assigned to participating nodes.
Secure aggregation can help protect individual updates by allowing an aggregator to compute a sum or average without directly observing each client’s contribution. Differential privacy can add noise to reduce leakage risk. Robust aggregation can reduce the influence of malicious or anomalous clients. Hardware security modules, trusted execution environments, signed updates, attestation, secure boot, and remote integrity checks can strengthen node trust.
Privacy-preserving edge AI is not achieved by architecture alone. It requires cryptography, access control, lifecycle governance, security monitoring, consent or authorization models, and careful limitation of what is collected, transmitted, retained, and reused.
| Risk | How It Appears | Consequence | Control |
|---|---|---|---|
| Device compromise | An attacker controls or modifies an edge node. | False data, malicious inference, or unauthorized access. | Secure boot, attestation, patching, and device identity. |
| Data poisoning | Local data is manipulated before training or inference. | Model learns corrupted signals. | Data validation, anomaly detection, and provenance. |
| Model-update poisoning | Malicious clients send harmful updates. | Global model degrades or embeds backdoors. | Robust aggregation and trust scoring. |
| Privacy leakage | Updates reveal information about local data. | Sensitive patterns are inferred from gradients or parameters. | Secure aggregation and differential privacy. |
| Adversarial inputs | Inputs are crafted to fool edge models. | Incorrect local action in real time. | Robustness testing and uncertainty thresholds. |
| Supply-chain compromise | Firmware, packages, or update channels are compromised. | Attackers gain fleet-scale influence. | Signed updates, dependency review, and release controls. |
| Physical tampering | Devices are modified, damaged, stolen, or spoofed. | Local integrity and trust are compromised. | Tamper detection and node quarantine procedures. |
Note: Distributed intelligence expands the perimeter of AI security. Every node becomes part of the trust boundary.
Integration with Infrastructure and Cyber-Physical Systems
Edge AI is especially important in cyber-physical systems where computation interacts with the physical world. Examples include smart grids, water systems, transportation networks, buildings, factories, farms, ports, hospitals, environmental monitoring networks, and emergency-response systems.
A cyber-physical feedback loop can be represented as:
Sensor \rightarrow Edge\ Inference \rightarrow Control\ Action \rightarrow Physical\ System \rightarrow Sensor
\]
Interpretation: Edge AI can close the loop between sensing, inference, control, physical response, and renewed sensing.
This connects directly to intelligent infrastructure systems. In physical systems, latency and reliability are not abstract metrics. They affect safety, resilience, energy use, environmental performance, service continuity, and public trust. A delayed or incorrect inference can cause material consequences.
Cyber-physical edge AI requires stronger assurance than ordinary analytics. Systems must be tested under environmental variation, sensor failure, communication interruption, cyberattack, maintenance conditions, abnormal operating states, and model uncertainty. They must also include human override and fail-safe behavior where appropriate.
| Domain | Edge AI Function | Why Local Intelligence Matters | Governance Requirement |
|---|---|---|---|
| Smart grids | Fault detection, load balancing, asset monitoring. | Power disruptions require fast local response. | Fail-safe control, cybersecurity, and audit logs. |
| Water systems | Leak detection, contamination alerts, pump monitoring. | Sensor events may require immediate operational action. | Data quality, maintenance records, and public-health escalation. |
| Transportation | Traffic sensing, vehicle coordination, hazard detection. | Latency directly affects safety. | Safety assurance and human override. |
| Industrial systems | Predictive maintenance, anomaly detection, process control. | Equipment failures can be costly or dangerous. | Operational validation and incident response. |
| Healthcare devices | Local monitoring, alerts, adaptive support. | Health signals may be sensitive and time-critical. | Privacy, reliability, clinical review, and device safety. |
| Environmental monitoring | Wildfire, flood, biodiversity, and pollution detection. | Remote sites may lack reliable connectivity. | Sensor calibration, local validation, and public alert protocols. |
| Agriculture | Soil sensing, irrigation optimization, crop monitoring. | Local context and bandwidth constraints matter. | Device maintenance, data ownership, and equitable access. |
Note: Cyber-physical edge AI must be evaluated as infrastructure, not merely as software.
Governance in Distributed Intelligence Systems
Distributed intelligence complicates governance because control is distributed across many nodes, owners, environments, vendors, jurisdictions, and update cycles. Traditional governance often assumes a centralized system with a clear owner, dataset, model, and deployment point. Edge AI breaks that simplicity.
A governance function for distributed AI can be represented as:
G_{dist}=f(Node\ Trust,Update\ Control,Data\ Rights,Monitoring,Auditability,Accountability)
\]
Interpretation: Distributed AI governance depends on node trust, update control, data rights, monitoring, auditability, and accountability.
Governance questions include: Who owns each node? Who controls model updates? Which data remains local? Which metadata is transmitted? How are compromised nodes detected? How are local decisions audited? How are edge models versioned? How are failures reported? Who is responsible when distributed decisions cause harm? How are privacy, consent, and data sovereignty enforced?
This connects to AI Governance and Regulatory Systems, Data Governance, Provenance, and Lineage in AI Systems, and Systemic Risk, Feedback Loops, and Cascading Failures in AI Systems. Distributed AI needs governance that follows models and decisions across the network, not governance that only reviews a central server.
| Governance Area | Question | Risk If Weak | Evidence or Control |
|---|---|---|---|
| Node inventory | What nodes are active, where are they, and who owns them? | Ungoverned devices become shadow AI infrastructure. | Node registry, owner records, location and function metadata. |
| Model versioning | Which model is running on each node? | Inconsistent or outdated models produce conflicting decisions. | Edge model registry and signed update history. |
| Update control | Who can deploy or roll back updates? | Compromised or unreviewed updates propagate across the fleet. | Release approvals, cryptographic signing, rollback plan. |
| Data rights | What data can be used, retained, or transmitted? | Local data is reused beyond consent, license, or jurisdictional limits. | Rights metadata and data minimization policy. |
| Monitoring | How are drift, failure, compromise, and performance degradation detected? | Distributed failures remain invisible until harm occurs. | Health signals, alerts, drift metrics, and incident logs. |
| Auditability | Can local decisions be reconstructed and reviewed? | Edge decisions become untraceable. | Decision logs, model lineage, update provenance. |
| Accountability | Who is responsible for local and system-level outcomes? | Distributed control creates responsibility gaps. | Named owners, escalation paths, and governance review bodies. |
Note: Distributed AI governance must be network-aware, lifecycle-aware, and accountable across device, edge, and cloud layers.
Limits and Tradeoffs
Edge AI and distributed intelligence involve tradeoffs. Local processing can reduce latency and improve privacy, but edge devices may be less powerful than cloud systems. Federated learning can reduce raw-data centralization, but it increases communication complexity and can still leak information through updates. Distributed resilience can reduce single points of failure, but coordination failures can create new risks.
Major limits include limited device compute, limited memory and storage, battery and energy constraints, heterogeneous hardware, intermittent connectivity, non-IID local data, communication overhead, security exposure across many nodes, model drift across environments, difficult auditability, complex update governance, and unclear accountability in distributed failures.
A tradeoff relationship can be represented as:
System\ Value = f(Accuracy,Latency,Privacy,Energy,Cost,Resilience,Governance)
\]
Interpretation: Edge AI system value depends on multiple competing criteria rather than accuracy alone.
The central lesson is that edge AI is not automatically better than cloud AI. It is better when local processing, privacy, resilience, and real-time action matter enough to justify the added complexity of distributed system design.
| Design Goal | Edge AI Advantage | Tradeoff | Mitigation |
|---|---|---|---|
| Low latency | Inference happens close to the event. | Local models may be smaller or less accurate. | Use hybrid fallback, calibration, and edge-specific validation. |
| Privacy | Raw data may remain local. | Updates, metadata, or outputs may still leak information. | Secure aggregation, differential privacy, and minimization. |
| Bandwidth savings | Transmit summaries instead of raw streams. | Central systems may lose detailed visibility. | Preserve selective raw evidence under governed conditions. |
| Resilience | Local autonomy reduces central dependency. | Distributed nodes can disagree or drift. | Health monitoring, synchronization, and rollback. |
| Energy efficiency | Local filtering can reduce transmission energy. | Inference may drain constrained devices. | TinyML, event triggers, duty cycling, and hardware-aware design. |
| Governance | Local control can support data sovereignty. | Distributed accountability becomes complex. | Node registries, lineage, update logs, and clear ownership. |
Note: The right edge architecture depends on the operational problem, not on a generic preference for decentralization.
Mathematical Lens
A distributed intelligence network can be represented as:
G=(V,E,W)
\]
Interpretation: A distributed AI system can be modeled as a graph with nodes \(V\), edges \(E\), and communication weights \(W\).
A federated learning objective is:
\min_w \sum_{i=1}^{n} p_i F_i(w)
\]
Interpretation: The global model minimizes a weighted combination of local client objectives.
The FedAvg update is:
w_{t+1}=\sum_{i=1}^{n} p_i w_{t,i}
\]
Interpretation: The next global model is formed by averaging client model updates.
Cloud inference latency is:
T_{cloud}=T_{uplink}+T_{cloud\_infer}+T_{downlink}
\]
Interpretation: Cloud latency includes upload, remote inference, and return communication time.
Edge inference latency is:
T_{edge}=T_{local\_infer}+T_{local\_act}
\]
Interpretation: Edge latency includes local inference and local action time.
Bandwidth savings can be written as:
B_{save}=1-\frac{B_{edge\_output}}{B_{raw}}
\]
Interpretation: Bandwidth savings increase when compact edge outputs replace raw data transmission.
A resource-feasibility condition is:
Feasible = 1 \quad \mathrm{if} \quad Latency \leq L_{max},\ Energy \leq E_{max},\ Memory \leq M_{max}
\]
Interpretation: Edge deployment is feasible only when latency, energy, and memory remain within constraints.
A resilience score is:
R=1-P(System\ Failure)
\]
Interpretation: System resilience increases as the probability of system-level failure decreases.
A distributed governance function is:
G_{dist}=f(Node\ Trust,Update\ Control,Data\ Rights,Monitoring,Auditability,Accountability)
\]
Interpretation: Distributed governance depends on trusted nodes, controlled updates, data rights, monitoring, auditability, and accountability.
This mathematical lens shows that edge AI is a systems problem involving graph structure, latency, bandwidth, resource constraints, federated optimization, resilience, trust, and governance.
Variables and System Interpretation
| Symbol or Term | Meaning | Typical Type | System Interpretation |
|---|---|---|---|
| \(V\) | Nodes | Devices or agents. | Sensors, gateways, edge servers, clients, or distributed AI agents. |
| \(E\) | Edges | Network links. | Communication or dependency links between nodes. |
| \(W\) | Weights | Link weights. | Latency, bandwidth, trust, cost, or dependency strength across links. |
| \(w\) | Model parameters | Learned vector. | Shared or local model state in federated or distributed learning. |
| \(F_i(w)\) | Local loss | Client objective. | Model loss on node or client \(i\). |
| \(p_i\) | Client weight | Aggregation weight. | Contribution of client \(i\), often based on local data size, trust, or participation weight. |
| \(T_{cloud}\) | Cloud inference latency | Time. | Total delay for transmitting data to cloud inference and receiving response. |
| \(T_{edge}\) | Edge inference latency | Time. | Total delay for local inference and local action. |
| \(B_{raw}\) | Raw bandwidth demand | Data rate. | Bandwidth required to transmit unprocessed data. |
| \(B_{edge\_output}\) | Edge output bandwidth | Data rate. | Bandwidth required to transmit compressed outputs, alerts, or features. |
| \(R\) | Resilience score | System property. | Ability of the distributed system to continue functioning under failure. |
| \(G_{dist}\) | Distributed governance function | Governance construct. | Rules and monitoring for nodes, updates, data rights, auditability, and responsibility. |
| Non-IID data | Non-identically distributed data | Federated learning challenge. | Local data distributions differ across clients or environments. |
| Edge governance | Distributed control and accountability | Governance construct. | Rules and monitoring for nodes, updates, data rights, auditability, and responsibility. |
Note: Edge AI should be evaluated as a distributed system. Accuracy matters, but latency, bandwidth, energy, memory, resilience, security, and governance often determine whether deployment is viable.
Worked Example: Edge Inference versus Cloud Inference
Suppose an industrial monitoring system needs to detect equipment anomalies within:
L_{max}=100\ \mathrm{ms}
\]
Interpretation: The system must respond within 100 milliseconds.
A cloud inference pipeline has:
T_{uplink}=55,\quad T_{cloud\_infer}=35,\quad T_{downlink}=45
\]
Interpretation: Upload, cloud inference, and return communication require 55, 35, and 45 milliseconds.
The total cloud latency is:
T_{cloud}=55+35+45=135\ \mathrm{ms}
\]
Interpretation: Cloud inference exceeds the required latency budget.
An edge model has:
T_{local\_infer}=42,\quad T_{local\_act}=18
\]
Interpretation: Local inference and local action require 42 and 18 milliseconds.
The total edge latency is:
T_{edge}=42+18=60\ \mathrm{ms}
\]
Interpretation: Edge inference satisfies the latency requirement.
If the raw sensor stream requires:
B_{raw}=100\ \mathrm{MB/s}
\]
Interpretation: Sending raw data to the cloud would require 100 megabytes per second.
But the edge output requires:
B_{edge\_output}=5\ \mathrm{MB/s}
\]
Interpretation: Sending edge summaries or alerts requires only 5 megabytes per second.
The bandwidth savings are:
B_{save}=1-\frac{5}{100}=0.95
\]
Interpretation: Edge processing reduces transmitted bandwidth by 95 percent.
This example shows why edge AI can be essential for time-critical infrastructure systems. The edge model may be smaller than the cloud model, but it can satisfy latency and bandwidth constraints that the cloud pipeline cannot.
| Metric | Cloud Inference | Edge Inference | Interpretation |
|---|---|---|---|
| Latency budget | 100 ms | The system must respond within 100 milliseconds. | |
| Total latency | 135 ms | 60 ms | Cloud exceeds the budget; edge satisfies it. |
| Raw bandwidth | 100 MB/s | Not transmitted continuously. | Raw stream transmission is costly. |
| Edge output bandwidth | Not applicable. | 5 MB/s | Edge sends compact outputs or alerts. |
| Bandwidth savings | 0% | 95% | Local processing sharply reduces transmission demand. |
| System implication | Better for deep centralized analytics. | Better for fast local response. | Hybrid design may use edge for action and cloud for long-term learning. |
Note: Edge inference can be preferable even when a cloud model is more powerful, because real systems must satisfy latency, bandwidth, resilience, and governance constraints.
Computational Modeling
Computational modeling can make edge AI system design concrete. A latency model can compare cloud and edge inference. A federated learning model can simulate local updates and global aggregation. A resilience model can simulate node failures. A governance model can score update control, auditability, node trust, and data-rights coverage. A SQL schema can document nodes, models, update rounds, local data constraints, latency budgets, security status, and governance reviews.
The selected examples below use lightweight synthetic workflows so the article remains readable and WordPress-friendly. The GitHub repository extends the same logic into advanced notebooks, federated averaging simulations, latency-budget analysis, bandwidth savings models, node-failure resilience, distributed governance metadata, SQL schemas, and reproducible outputs.
Edge\ AI\ Fitness = Latency + Bandwidth + Resource\ Feasibility + Trust + Governance
\]
Interpretation: Edge AI deployment should be evaluated through technical performance, resource feasibility, trust, and governance readiness together.
Python Workflow: Edge Nodes, Federated Averaging, and Latency Budgets
Python is useful for simulating edge-node constraints, federated averaging, latency budgets, bandwidth savings, and governance diagnostics.
"""
Edge AI and Distributed Intelligence
Python workflow: edge nodes, federated averaging, and latency budgets.
This educational example demonstrates:
1. edge-node resource profiles
2. cloud versus edge latency analysis
3. bandwidth savings from local processing
4. federated averaging
5. node-level trust and governance diagnostics
6. governance-ready output files
It uses synthetic data for illustration.
"""
from __future__ import annotations
from pathlib import Path
import numpy as np
import pandas as pd
RANDOM_SEED = 42
rng = np.random.default_rng(RANDOM_SEED)
OUTPUT_DIR = Path("outputs")
OUTPUT_DIR.mkdir(parents=True, exist_ok=True)
LATENCY_BUDGET_MS = 100
PARAMETER_DIMENSION = 5
def build_edge_nodes(n_nodes: int = 8) -> pd.DataFrame:
"""Create synthetic edge-node profiles."""
nodes = pd.DataFrame(
{
"node_id": [f"edge_node_{i:02d}" for i in range(1, n_nodes + 1)],
"local_examples": rng.integers(250, 1800, size=n_nodes),
"edge_inference_ms": rng.uniform(18, 70, size=n_nodes),
"local_action_ms": rng.uniform(8, 25, size=n_nodes),
"uplink_ms": rng.uniform(35, 90, size=n_nodes),
"cloud_inference_ms": rng.uniform(25, 45, size=n_nodes),
"downlink_ms": rng.uniform(30, 80, size=n_nodes),
"raw_bandwidth_mb_s": rng.uniform(20, 150, size=n_nodes),
"edge_output_mb_s": rng.uniform(1, 8, size=n_nodes),
"node_trust": rng.uniform(0.70, 0.98, size=n_nodes),
"governance_review_complete": rng.choice(
[0, 1],
size=n_nodes,
p=[0.25, 0.75],
),
}
)
return nodes
def score_edge_nodes(nodes: pd.DataFrame) -> pd.DataFrame:
"""Compute edge, cloud, bandwidth, and governance diagnostics."""
scored = nodes.copy()
scored["cloud_latency_ms"] = (
scored["uplink_ms"]
+ scored["cloud_inference_ms"]
+ scored["downlink_ms"]
)
scored["edge_latency_ms"] = (
scored["edge_inference_ms"]
+ scored["local_action_ms"]
)
scored["latency_savings_ms"] = (
scored["cloud_latency_ms"]
- scored["edge_latency_ms"]
)
scored["bandwidth_savings"] = (
1 - scored["edge_output_mb_s"] / scored["raw_bandwidth_mb_s"]
)
scored["edge_meets_budget"] = (
scored["edge_latency_ms"] <= LATENCY_BUDGET_MS
)
scored["cloud_meets_budget"] = (
scored["cloud_latency_ms"] <= LATENCY_BUDGET_MS
)
scored["distributed_risk"] = (
0.40 * (1 - scored["node_trust"])
+ 0.35 * (1 - scored["governance_review_complete"])
+ 0.25 * (~scored["edge_meets_budget"]).astype(int)
)
return scored
def simulate_client_updates(nodes: pd.DataFrame) -> pd.DataFrame:
"""Simulate local client model updates for one federated round."""
update_values = rng.normal(
loc=0.0,
scale=1.0,
size=(len(nodes), PARAMETER_DIMENSION),
)
client_updates = pd.DataFrame(
update_values,
columns=[f"param_{j}" for j in range(PARAMETER_DIMENSION)],
)
client_updates["node_id"] = nodes["node_id"].values
client_updates["local_examples"] = nodes["local_examples"].values
client_updates["node_trust"] = nodes["node_trust"].values
return client_updates
def federated_average(client_updates: pd.DataFrame) -> pd.DataFrame:
"""
Compute a simple FedAvg update weighted by local examples.
In real deployments, weighting may also consider trust, data quality,
client reliability, privacy constraints, and security review.
"""
total_examples = client_updates["local_examples"].sum()
weights = client_updates["local_examples"] / total_examples
global_update = {}
for column in [f"param_{j}" for j in range(PARAMETER_DIMENSION)]:
global_update[column] = float((weights * client_updates[column]).sum())
return pd.DataFrame([global_update])
def trust_weighted_average(client_updates: pd.DataFrame) -> pd.DataFrame:
"""
Compute a trust-weighted model update.
This is a simplified educational pattern. Production systems require
stronger robust aggregation, anomaly detection, secure aggregation,
and privacy protection.
"""
raw_weights = (
client_updates["local_examples"]
* client_updates["node_trust"]
)
weights = raw_weights / raw_weights.sum()
global_update = {}
for column in [f"param_{j}" for j in range(PARAMETER_DIMENSION)]:
global_update[column] = float((weights * client_updates[column]).sum())
return pd.DataFrame([global_update])
def build_governance_summary(nodes: pd.DataFrame) -> pd.DataFrame:
"""Summarize edge deployment readiness."""
return pd.DataFrame(
[
{
"metric": "share_edge_meets_latency_budget",
"value": nodes["edge_meets_budget"].mean(),
},
{
"metric": "share_cloud_meets_latency_budget",
"value": nodes["cloud_meets_budget"].mean(),
},
{
"metric": "mean_latency_savings_ms",
"value": nodes["latency_savings_ms"].mean(),
},
{
"metric": "mean_bandwidth_savings",
"value": nodes["bandwidth_savings"].mean(),
},
{
"metric": "mean_node_trust",
"value": nodes["node_trust"].mean(),
},
{
"metric": "share_governance_review_complete",
"value": nodes["governance_review_complete"].mean(),
},
{
"metric": "mean_distributed_risk",
"value": nodes["distributed_risk"].mean(),
},
]
)
def write_governance_memo(
nodes: pd.DataFrame,
governance_summary: pd.DataFrame,
) -> None:
"""Write a plain-language governance memo for edge AI review."""
highest_risk = nodes.sort_values(
"distributed_risk",
ascending=False,
).head(3)
memo = "# Edge AI and Distributed Intelligence Governance Memo\n\n"
memo += "Highest-risk edge nodes:\n"
for _, row in highest_risk.iterrows():
memo += (
f"- {row['node_id']}: distributed_risk={row['distributed_risk']:.3f}, "
f"edge_latency_ms={row['edge_latency_ms']:.1f}, "
f"node_trust={row['node_trust']:.3f}, "
f"governance_review_complete={int(row['governance_review_complete'])}\n"
)
memo += "\nGovernance summary:\n"
for _, row in governance_summary.iterrows():
memo += f"- {row['metric']}: {row['value']:.3f}\n"
memo += (
"\nInterpretation:\n"
"- Edge deployment should be evaluated across latency, bandwidth, trust, and governance readiness.\n"
"- Federated aggregation should not rely only on local data volume; trust and security matter.\n"
"- Nodes that fail governance review should not receive critical model updates without remediation.\n"
"- Edge systems require model versioning, update control, health monitoring, and incident response.\n"
)
(OUTPUT_DIR / "python_edge_ai_governance_memo.md").write_text(memo)
def main() -> None:
nodes = build_edge_nodes()
scored_nodes = score_edge_nodes(nodes)
client_updates = simulate_client_updates(scored_nodes)
fedavg_update = federated_average(client_updates)
trust_update = trust_weighted_average(client_updates)
governance_summary = build_governance_summary(scored_nodes)
scored_nodes.to_csv(
OUTPUT_DIR / "python_edge_ai_nodes.csv",
index=False,
)
client_updates.to_csv(
OUTPUT_DIR / "python_edge_ai_client_updates.csv",
index=False,
)
fedavg_update.to_csv(
OUTPUT_DIR / "python_edge_ai_fedavg_update.csv",
index=False,
)
trust_update.to_csv(
OUTPUT_DIR / "python_edge_ai_trust_weighted_update.csv",
index=False,
)
governance_summary.to_csv(
OUTPUT_DIR / "python_edge_ai_governance_summary.csv",
index=False,
)
write_governance_memo(scored_nodes, governance_summary)
display_cols = [
"node_id",
"edge_latency_ms",
"cloud_latency_ms",
"latency_savings_ms",
"bandwidth_savings",
"edge_meets_budget",
"cloud_meets_budget",
"distributed_risk",
]
print("Edge-node diagnostics")
print(scored_nodes[display_cols])
print("\nFederated averaging update")
print(fedavg_update)
print("\nTrust-weighted update")
print(trust_update)
print("\nGovernance summary")
print(governance_summary)
if __name__ == "__main__":
main()
This workflow shows how edge AI can be evaluated as a system: latency, bandwidth, local data volume, federated aggregation, trust, and governance coverage all matter.
R Workflow: Distributed Intelligence Risk and Resource Scoring
R is useful for scoring edge deployments across resource constraints, resilience, privacy, and governance readiness.
# Edge AI and Distributed Intelligence
#
# R workflow: distributed intelligence risk and resource scoring.
#
# This educational workflow simulates:
# - edge deployment readiness
# - latency and bandwidth diagnostics
# - resource constraint scoring
# - distributed governance risk
# - governance-ready output files
set.seed(42)
nodes <- data.frame(
node_id = paste0("edge_node_", sprintf("%02d", 1:8)),
compute_capacity = runif(8, 0.45, 0.95),
model_compute_demand = runif(8, 0.30, 0.90),
memory_capacity = runif(8, 0.40, 0.95),
model_memory_demand = runif(8, 0.25, 0.90),
energy_budget = runif(8, 0.45, 0.95),
model_energy_demand = runif(8, 0.25, 0.88),
edge_latency_ms = runif(8, 35, 90),
cloud_latency_ms = runif(8, 80, 180),
raw_bandwidth_mb_s = runif(8, 20, 150),
edge_output_mb_s = runif(8, 1, 8),
node_trust = runif(8, 0.65, 0.98),
governance_review = sample(
c(0, 1),
8,
replace = TRUE,
prob = c(0.25, 0.75)
)
)
nodes$compute_feasible <-
nodes$model_compute_demand <= nodes$compute_capacity
nodes$memory_feasible <-
nodes$model_memory_demand <= nodes$memory_capacity
nodes$energy_feasible <-
nodes$model_energy_demand <= nodes$energy_budget
nodes$latency_feasible <-
nodes$edge_latency_ms <= 100
nodes$deployment_feasible <-
nodes$compute_feasible &
nodes$memory_feasible &
nodes$energy_feasible &
nodes$latency_feasible
nodes$latency_gain <-
nodes$cloud_latency_ms - nodes$edge_latency_ms
nodes$bandwidth_savings <-
1 - nodes$edge_output_mb_s / nodes$raw_bandwidth_mb_s
nodes$resource_margin <-
0.34 * (nodes$compute_capacity - nodes$model_compute_demand) +
0.33 * (nodes$memory_capacity - nodes$model_memory_demand) +
0.33 * (nodes$energy_budget - nodes$model_energy_demand)
nodes$distributed_risk <-
0.30 * (1 - nodes$node_trust) +
0.25 * (1 - nodes$governance_review) +
0.20 * (!nodes$deployment_feasible) +
0.15 * pmax(0, -nodes$resource_margin) +
0.10 * (!nodes$latency_feasible)
summary_table <- data.frame(
metric = c(
"share_deployment_feasible",
"mean_latency_gain",
"mean_bandwidth_savings",
"mean_resource_margin",
"mean_node_trust",
"mean_distributed_risk",
"share_governance_review_complete"
),
value = c(
mean(nodes$deployment_feasible),
mean(nodes$latency_gain),
mean(nodes$bandwidth_savings),
mean(nodes$resource_margin),
mean(nodes$node_trust),
mean(nodes$distributed_risk),
mean(nodes$governance_review)
)
)
dir.create("outputs", recursive = TRUE, showWarnings = FALSE)
write.csv(
nodes,
"outputs/r_edge_ai_nodes.csv",
row.names = FALSE
)
write.csv(
summary_table,
"outputs/r_edge_ai_summary.csv",
row.names = FALSE
)
memo <- paste0(
"# Edge AI Distributed Intelligence Risk and Resource Memo\n\n",
"Share deployment feasible: ",
round(mean(nodes$deployment_feasible), 3), "\n",
"Mean latency gain: ",
round(mean(nodes$latency_gain), 3), " ms\n",
"Mean bandwidth savings: ",
round(mean(nodes$bandwidth_savings), 3), "\n",
"Mean node trust: ",
round(mean(nodes$node_trust), 3), "\n",
"Mean distributed risk: ",
round(mean(nodes$distributed_risk), 3), "\n",
"Share governance review complete: ",
round(mean(nodes$governance_review), 3), "\n\n",
"Interpretation:\n",
"- Edge deployment should satisfy compute, memory, energy, and latency constraints.\n",
"- Latency gain alone is not enough; governance review and node trust also matter.\n",
"- Nodes with negative resource margins may fail under real operating conditions.\n",
"- Distributed governance should track deployment feasibility, update control, security, and accountability.\n"
)
writeLines(
memo,
"outputs/r_edge_ai_governance_memo.md"
)
print("Edge nodes ordered by distributed risk")
print(nodes[order(-nodes$distributed_risk), ])
print("Summary table")
print(summary_table)
cat(memo)
This workflow treats edge AI deployment as a multi-constraint system. A node must satisfy compute, memory, energy, latency, trust, and governance requirements before it should be considered deployment-ready.
GitHub Repository
The article body includes selected computational examples so the conceptual and mathematical argument remains readable. The full repository contains expanded computational infrastructure: advanced Jupyter notebooks, edge-node simulation, federated averaging, latency-budget analysis, bandwidth savings, resource-constrained deployment, node-trust scoring, distributed governance metadata, SQL schemas, and reproducible outputs.
Complete Code Repository
The full code distribution for this article includes Python, R, SQL, Julia, governance documentation, edge-node simulation, federated learning simulations, edge-latency diagnostics, bandwidth-savings analysis, resource feasibility scoring, node-trust diagnostics, distributed governance metadata, reproducible outputs, and audit scaffolding for studying edge AI and distributed intelligence.
From Centralized AI to Distributed Intelligence
Edge AI and distributed intelligence show that the future of AI systems is not only about larger models in centralized data centers. It is also about placing intelligence where data, decisions, and physical processes actually occur. Edge systems reduce latency, preserve local data, improve resilience, reduce bandwidth demand, and support real-time cyber-physical action. Federated learning and distributed optimization extend this shift by allowing shared learning across decentralized data sources.
The central lesson is that edge AI is a systems architecture, not simply a deployment location. It requires careful allocation of tasks across device, edge, and cloud layers; resource-aware model design; latency and bandwidth analysis; security and privacy protections; resilience engineering; and distributed governance. Edge intelligence increases local autonomy, but it also multiplies the number of nodes that must be monitored, secured, updated, audited, and held accountable.
Within the Artificial Intelligence Systems knowledge series, this article belongs near AI Infrastructure: Data Pipelines, Compute, and Deployment Systems, Real-Time AI Systems and Autonomous Decision-Making, AI Agents, Tool Use, and Workflow Automation, Robustness and Adversarial Resilience in Machine Learning, Systemic Risk, Feedback Loops, and Cascading Failures in AI Systems, and AI Governance and Regulatory Systems. It provides the distributed architecture layer for understanding how AI capability becomes local, real-time, resilient, privacy-aware, and governable across networks.
The final point is practical. Edge AI should be adopted when the system genuinely requires local intelligence, not because decentralization sounds inherently superior. The best architecture is the one that places computation, data, authority, and accountability where they can best support the purpose of the system while protecting safety, privacy, resilience, and public trust.
Related Articles
- Artificial Intelligence Systems
- AI Infrastructure: Data Pipelines, Compute, and Deployment Systems
- Real-Time AI Systems and Autonomous Decision-Making
- AI Agents, Tool Use, and Workflow Automation
- Robustness and Adversarial Resilience in Machine Learning
- Systemic Risk, Feedback Loops, and Cascading Failures in AI Systems
- Data Governance, Provenance, and Lineage in AI Systems
- Data Systems & Analytics
- Embedded & Edge Systems
- Intelligent Infrastructure Systems
- Environmental Monitoring Systems
- AI Governance and Regulatory Systems
Further Reading
- Satyanarayanan, M. (2017) ‘The Emergence of Edge Computing’, Computer, 50(1), pp. 30–39. Available at: https://elijah.cs.cmu.edu/DOCS/satya-edge2016.pdf
- Zhou, Z. et al. (2019) ‘Edge Intelligence: Paving the Last Mile of Artificial Intelligence with Edge Computing’. Available at: https://arxiv.org/abs/1905.10083
- ETSI (2026) ‘Multi-access Edge Computing’. Available at: https://www.etsi.org/technologies/multi-access-edge-computing
- McMahan, H.B. et al. (2017) ‘Communication-Efficient Learning of Deep Networks from Decentralized Data’, Proceedings of Machine Learning Research, 54, pp. 1273–1282. Available at: https://proceedings.mlr.press/v54/mcmahan17a.html
- Li, Q. et al. (2023) ‘A Survey on Federated Learning Systems: Vision, Hype and Reality for Data Privacy and Protection’, IEEE Transactions on Knowledge and Data Engineering, 35(4), pp. 3347–3366. Available at: https://arxiv.org/abs/1907.09693
- Bonawitz, K. et al. (2017) ‘Practical Secure Aggregation for Privacy-Preserving Machine Learning’, Proceedings of the 2017 ACM SIGSAC Conference on Computer and Communications Security. Available at: https://dl.acm.org/doi/10.1145/3133956.3133982
- Poncinelli Filho, C. et al. (2022) ‘Distributed Machine Learning at the Edge: A Systematic Review’, Sensors, 22(7), 2665. Available at: https://pmc.ncbi.nlm.nih.gov/articles/PMC9002674/
- Warden, P. and Situnayake, D. (2019) TinyML: Machine Learning with TensorFlow Lite on Arduino and Ultra-Low-Power Microcontrollers. Sebastopol: O’Reilly. Available at: https://tinymlbook.com/
- NIST (2023) Artificial Intelligence Risk Management Framework (AI RMF 1.0). Available at: https://www.nist.gov/publications/artificial-intelligence-risk-management-framework-ai-rmf-10
References
- Bonawitz, K. et al. (2017) ‘Practical Secure Aggregation for Privacy-Preserving Machine Learning’, Proceedings of the 2017 ACM SIGSAC Conference on Computer and Communications Security. Available at: https://dl.acm.org/doi/10.1145/3133956.3133982
- ETSI (2026) ‘Multi-access Edge Computing’. Available at: https://www.etsi.org/technologies/multi-access-edge-computing
- Li, Q. et al. (2023) ‘A Survey on Federated Learning Systems: Vision, Hype and Reality for Data Privacy and Protection’, IEEE Transactions on Knowledge and Data Engineering, 35(4), pp. 3347–3366. Available at: https://arxiv.org/abs/1907.09693
- McMahan, H.B. et al. (2017) ‘Communication-Efficient Learning of Deep Networks from Decentralized Data’, Proceedings of Machine Learning Research, 54, pp. 1273–1282. Available at: https://proceedings.mlr.press/v54/mcmahan17a.html
- NIST (2023) Artificial Intelligence Risk Management Framework (AI RMF 1.0). Available at: https://www.nist.gov/publications/artificial-intelligence-risk-management-framework-ai-rmf-10
- Poncinelli Filho, C. et al. (2022) ‘Distributed Machine Learning at the Edge: A Systematic Review’, Sensors, 22(7), 2665. Available at: https://pmc.ncbi.nlm.nih.gov/articles/PMC9002674/
- Satyanarayanan, M. (2017) ‘The Emergence of Edge Computing’, Computer, 50(1), pp. 30–39. Available at: https://elijah.cs.cmu.edu/DOCS/satya-edge2016.pdf
- Warden, P. and Situnayake, D. (2019) TinyML: Machine Learning with TensorFlow Lite on Arduino and Ultra-Low-Power Microcontrollers. Sebastopol: O’Reilly. Available at: https://tinymlbook.com/
- Zhou, Z. et al. (2019) ‘Edge Intelligence: Paving the Last Mile of Artificial Intelligence with Edge Computing’. Available at: https://arxiv.org/abs/1905.10083