
Last Updated May 12, 2026
Edge computing architectures examine how computation, storage, messaging, analytics, inference, and coordination are distributed closer to where data are generated and where actions must often be taken. In embedded and edge systems, edge computing is not simply “less cloud.” It is an architectural response to latency, bandwidth, resilience, privacy, autonomy, trust, and operational-continuity constraints that make centralized processing alone insufficient.
Edge computing is best understood as a placement problem. Compute resources are positioned closer to data sources and points of action when doing so materially improves system behavior. That improvement may take the form of lower latency, reduced network dependency, stronger local autonomy, lower transport cost, tighter privacy control, better field continuity, or more resilient operation under disconnection. The architecture matters because these benefits do not emerge automatically from moving software outward. They depend on how responsibilities are partitioned across devices, gateways, local edge nodes, regional edge infrastructure, and cloud services.
This architectural shift matters because many embedded systems cannot wait for distant cloud processing without sacrificing responsiveness, robustness, safety, or operational clarity. Industrial control, robotics, distributed monitoring, video analytics, utility infrastructure, connected vehicles, environmental sensing, and site-scale automation all face conditions in which transport delay, intermittent connectivity, privacy constraints, physical proximity, or sheer data volume make centralized architectures weaker than hybrid ones. Edge computing becomes valuable when locality improves behavior in ways that centralized coordination alone cannot sustain.
Edge architecture is therefore not only about where software runs. It is about which decisions belong on-device, at a gateway, at a local edge node, at a regional edge layer, or in the cloud; what must continue during disconnection; what data must remain local; what can be summarized or selectively uplinked; what trust boundaries are crossed; what runtime assurance is required; and what level of coordination or aggregation should happen before information is sent upstream. Once framed that way, edge computing becomes a question of operational responsibility rather than a slogan about infrastructure placement.
Main Library
Publications
Article Map
Embedded & Edge Systems
Related Topic
Data Systems & Analytics
Related Topic
Artificial Intelligence Systems
Related Topic
Intelligent Infrastructure
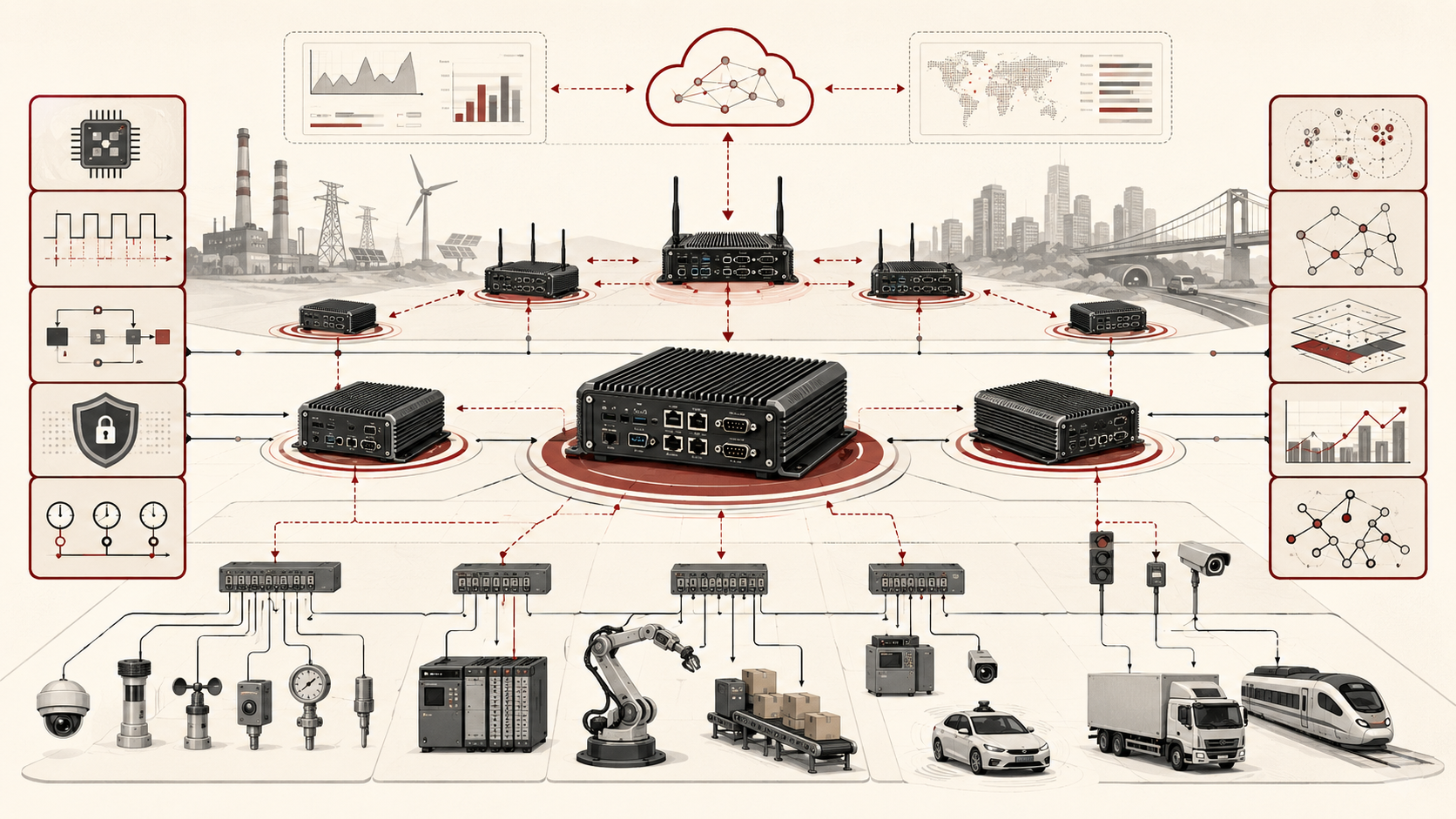
For engineers, edge computing should be treated as a managed systems architecture, not as a generic deployment location. It determines where data are transformed, where local actions are authorized, where failures are absorbed, where software versions are controlled, where trust is rooted, where privacy boundaries are enforced, and where upstream coordination resumes after disconnection. A strong edge architecture does not simply push compute outward; it makes responsibility, timing, authority, evidence, runtime assurance, and recovery explicit at every layer.
Engineering Problem
The engineering problem is how to distribute computing responsibilities across constrained devices, gateways, local edge nodes, regional infrastructure, and cloud systems without losing timing guarantees, operational continuity, security, manageability, data lineage, or governance. Edge computing is valuable only when local placement improves system behavior under real constraints. A workload that can run at the edge is not automatically a workload that should run there.
Edge systems become difficult because they mix physical context with distributed computing. A cloud application can often assume abundant compute, centralized observability, stable connectivity, and uniform deployment control. An edge system cannot. It may operate in factories, vehicles, substations, hospitals, farms, buildings, field stations, robots, or remote infrastructure, where devices are physically exposed, networks are unreliable, local timing matters, and failures can affect real-world operations.
Weak edge architectures often blur responsibility. They move containers outward but do not specify which layer owns sensing, preprocessing, inference, buffering, local action, safety fallback, privacy filtering, update control, trust verification, watchdog recovery, or incident evidence. They lower latency for one workflow while increasing version skew, security exposure, troubleshooting complexity, or data ambiguity across the fleet. They preserve local autonomy but fail to define what local decisions are still authorized during disconnection.
The practical question is therefore: can the architecture place each workload at the layer where it best satisfies latency, bandwidth, privacy, resilience, trust, and governance requirements while remaining observable, updateable, secure, bounded, and recoverable over the life of the system?
Reference Architecture
A practical edge computing architecture can be understood as a layered responsibility stack. The exact implementation may involve microcontrollers, embedded Linux devices, gateways, local Kubernetes clusters, industrial PCs, message brokers, time-series databases, cloud IoT platforms, edge AI runtimes, local storage, hardware roots of trust, and remote management services. The underlying responsibilities remain broadly consistent.
| Layer | Engineering Role | Architectural Concern | Evidence Artifact |
|---|---|---|---|
| Endpoint device | Performs sensing, actuation, firmware execution, immediate control, and local safety handling | Real-time behavior, power, memory, calibration, physical exposure | Device manifest, firmware version, calibration record, local health report |
| Embedded runtime | Runs device-level logic, drivers, preprocessing, TinyML, local rules, or hardware interfaces | Timing, memory, watchdog behavior, hardware access, deterministic execution | Runtime manifest, build manifest, watchdog log |
| Gateway layer | Aggregates devices, translates protocols, buffers data, normalizes telemetry, and enforces local policy | Protocol mediation, local storage, version skew, child-device coverage | Gateway inventory, protocol map, buffer ledger, child-device map |
| Local edge node | Runs site-level analytics, dashboards, event processing, local inference, and limited coordination | Site autonomy, workload orchestration, local data retention, operator visibility | Site-edge manifest, workload inventory, local event log |
| Regional edge | Coordinates multiple sites or low-latency regional workloads | Cross-site latency, aggregation, failover, policy synchronization | Regional routing map, latency profile, synchronization report |
| Cloud layer | Provides fleet management, model training, long-horizon analytics, archival storage, identity, and policy coordination | Central governance, large-scale analytics, deployment control, global visibility | Fleet inventory, model registry, policy registry, deployment history |
| Management plane | Deploys, configures, monitors, updates, rolls back, and inventories edge assets | Lifecycle governance, drift, staged rollout, operational ownership | Deployment manifest, rollout ring, rollback record, version inventory |
| Security and trust layer | Protects device identity, secure boot, attestation, credentials, updates, and local authority | Physical exposure, tampering, secret handling, trust propagation | Attestation record, key inventory, signed update log, trust profile |
| Observability layer | Captures telemetry about latency, connectivity, backlog, versions, failures, and local decisions | Debugging, incident reconstruction, SLO monitoring, auditability | Telemetry schema, SLO report, incident log, event evidence |
| Runtime assurance layer | Monitors watchdogs, heartbeats, resource pressure, degraded modes, restart behavior, and safety boundaries | Fail-safe/fail-operational behavior, bounded autonomy, recovery sequencing | Runtime assurance policy, watchdog report, degraded-mode trace |
This architecture makes edge computing visible as a responsibility-placement system. It separates physical interaction from local coordination, local coordination from fleet governance, and fleet governance from long-horizon analytics. Without those distinctions, the edge can become a distributed blind spot: close to the field, but difficult to understand, update, or trust.
Implementation Pattern
A rigorous edge computing implementation begins by defining the workload, the placement rationale, the local constraints, the trust boundary, the data-flow contract, the offline behavior, the management path, the runtime-assurance policy, and the recovery plan. Engineers should specify not only where software runs, but why that layer is the correct layer and what evidence will prove the placement remains healthy after deployment.
| Artifact | Purpose | Typical Format |
|---|---|---|
| Edge topology manifest | Defines device, gateway, local edge, regional edge, and cloud relationships | YAML, JSON, architecture inventory |
| Workload placement matrix | Maps workloads to layers using latency, bandwidth, privacy, continuity, trust, and manageability criteria | YAML, CSV, design record |
| Latency and bandwidth budget | Defines timing and transport constraints across each path | YAML, benchmark report, SLO document |
| Offline mode policy | Defines what continues, degrades, buffers, stops, or requires manual approval during disconnection | YAML, runbook, safety policy |
| Runtime assurance policy | Defines watchdogs, heartbeats, local health checks, restart thresholds, degraded modes, and failover behavior | YAML, safety case, runtime monitor config |
| Data-locality policy | Defines what remains local, what is summarized, what is redacted, and what is forwarded | YAML, privacy control, schema contract |
| Trust boundary manifest | Defines device identity, secure boot, attestation, secret handling, signed updates, and workload provenance | YAML, attestation profile, security architecture |
| Fleet inventory schema | Defines assets, hardware class, software versions, configuration state, ownership, and location | SQL, JSON Schema, asset registry |
| Deployment and rollback plan | Defines rollout rings, staged updates, health gates, rollback triggers, and recovery behavior | YAML, CI/CD manifest, runbook |
| Telemetry schema | Defines observability records for latency, backlog, version skew, disconnection, trust state, and local actions | SQL, JSON Schema, metrics contract |
| Incident reconstruction policy | Defines what evidence must be retained to explain local behavior after failures | Runbook, retention policy, event schema |
The implementation goal is to make edge responsibility inspectable. Engineers should be able to reconstruct which layer ran each workload, why it ran there, what constraints shaped that decision, what happened during disconnection, what data moved upstream, what remained local, which version was active, what local authority was exercised, and whether the system stayed inside its operational envelope.
Research-Grade Framing: Edge Computing as Responsibility Placement
Edge computing should be framed as responsibility placement. It is the architecture of assigning computation, data retention, decision authority, trust, and recovery responsibilities to layers that are physically and operationally closer to the systems they support. This matters because edge architecture changes not only where code runs, but where responsibility resides.
A device that buffers locally during outage is responsible for continuity. A gateway that normalizes telemetry is responsible for preserving measurement meaning. A local edge node that runs anomaly detection is responsible for first-stage interpretation. A site-level system that continues operating offline is responsible for bounded autonomy. A cloud service that coordinates fleet-wide policy is responsible for version governance and long-horizon analysis. The system is clear only when these responsibilities are explicit.
| Responsibility Dimension | Question | Required Edge Evidence |
|---|---|---|
| Placement rationale | Why does this workload run at this layer? | Workload placement matrix, latency/bandwidth/privacy/continuity justification |
| Timing | Can the layer meet the required response window? | Latency budget, p95/p99 timing report, local action trace |
| Continuity | What functions continue during disconnection? | Offline mode policy, buffer ledger, reconnect replay record |
| Data locality | What data stay local, and what leaves? | Data-locality policy, selective uplink log, retention record |
| Authority | What decisions can be made locally? | Local decision policy, safety envelope, fallback log |
| Runtime assurance | How does the local layer detect and contain runtime degradation? | Watchdog trace, heartbeat status, resource envelope, recovery sequence |
| Trust | How does the system know local software and devices are legitimate? | Secure boot state, attestation record, signed update log, SBOM, workload provenance |
| Fleet governance | Can the system see, update, and roll back distributed workloads? | Fleet inventory, version map, rollout record, rollback result |
| Interpretability | Can local transformations and actions be reconstructed? | Telemetry schema, lineage record, incident evidence package |
In this framing, edge computing is not primarily a location strategy. It is a system of accountable delegation across layers that must continue to function under latency, disconnection, physical exposure, privacy constraint, trust uncertainty, and operational pressure.
Formal Model: Workload Placement, Latency, Trust, and Continuity
A useful formal model separates workloads, layers, constraints, and placement decisions. Let \(w_i\) represent workload \(i\), \(l_j\) represent layer \(j\) in the edge continuum, and \(P(w_i, l_j)\) indicate placement of a workload at a layer.
P^\* (w_i) = \arg\min_{l_j} \ C(w_i, l_j)
\]
Interpretation: The preferred placement \(P^\*(w_i)\) is the layer that minimizes total architectural cost \(C\), including latency, bandwidth, security, management, and resilience costs.
C(w_i, l_j) = \alpha L_{ij} + \beta B_{ij} + \gamma S_{ij} + \delta M_{ij} + \eta R_{ij} – \kappa A_{ij}
\]
Interpretation: Placement cost can combine latency \(L\), bandwidth \(B\), security exposure \(S\), management burden \(M\), resilience risk \(R\), and autonomy benefit \(A\). The weights reflect system priorities.
L_{\mathrm{path}} = L_{\mathrm{sense}} + L_{\mathrm{compute}} + L_{\mathrm{network}} + L_{\mathrm{queue}} + L_{\mathrm{act}}
\]
Interpretation: End-to-end latency includes sensing, computation, network transport, queueing, and action. Edge computing often matters because it reduces network and queueing components in time-sensitive pathways.
D_{\mathrm{uplink}} = D_{\mathrm{raw}} – D_{\mathrm{filtered}} – D_{\mathrm{summarized}} – D_{\mathrm{retained}}
\]
Interpretation: Uplink data volume depends on how much raw data are filtered, summarized, or retained locally. Bandwidth savings should be measured against evidence loss.
A_{\mathrm{service}} = 1 – \prod_{k=1}^{n}(1 – A_k)
\]
Interpretation: Redundant edge layers can improve service availability when designed properly, but only if failover and state synchronization are engineered.
T_{\mathrm{effective}} = T_{\mathrm{identity}} \cdot T_{\mathrm{boot}} \cdot T_{\mathrm{runtime}} \cdot T_{\mathrm{update}} \cdot T_{\mathrm{telemetry}}
\]
Interpretation: Effective trust depends on identity, boot integrity, runtime integrity, update integrity, and trustworthy telemetry. A weak link can undermine the local edge layer.
R_{\mathrm{assurance}} = f(H, W, Q, \Theta, \rho)
\]
Interpretation: Runtime assurance depends on health signals \(H\), watchdogs \(W\), queue/resource state \(Q\), operating thresholds \(\Theta\), and recovery policy \(\rho\). Edge autonomy should be bounded by observable health.
This formal structure helps prevent vague edge design. It makes placement, latency, bandwidth reduction, availability, trust, and runtime assurance explicit enough to compare alternatives.
Placement Rubric: Device, Gateway, Local Edge, Regional Edge, or Cloud?
Engineers need a practical rubric for deciding where a workload belongs. The simplest useful method is to evaluate the workload against timing, data volume, privacy, offline requirement, local authority, trust requirement, compute demand, update cadence, and fleet-governance need. The result should be a documented placement decision, not an implicit deployment habit.
| Criterion | Device | Gateway | Local Edge | Regional Edge | Cloud |
|---|---|---|---|---|---|
| Hard real-time or safety response | Strong fit | Limited fit | Usually too far | Poor fit | Poor fit |
| Protocol translation and child-device aggregation | Poor fit | Strong fit | Moderate fit | Poor fit | Poor fit |
| Site-level analytics and operator visibility | Limited fit | Moderate fit | Strong fit | Moderate fit | Moderate fit |
| Low-latency multi-site coordination | Poor fit | Poor fit | Limited fit | Strong fit | Moderate fit |
| Fleet-wide model training or policy coordination | Poor fit | Poor fit | Limited fit | Moderate fit | Strong fit |
| Raw-data minimization before uplink | Strong fit | Strong fit | Strong fit | Moderate fit | Poor fit if raw data must remain local |
| Rapid experimentation and centralized governance | Limited fit | Moderate fit | Moderate fit | Moderate fit | Strong fit |
| Offline continuity | Strong fit | Strong fit | Strong fit | Limited fit | Poor fit |
A strong placement decision should be accompanied by a failure-mode statement. For each workload, engineers should specify what happens if the cloud is unreachable, the gateway fails, the local edge node restarts, the workload crashes, the update fails, the clock drifts, the buffer fills, or the trust state becomes uncertain. Placement is incomplete until degradation and recovery are defined.
What Is Edge Computing Architecture?
Edge computing architecture is the structural arrangement through which computation, storage, messaging, analytics, inference, and control are positioned outside or alongside centralized cloud environments so that processing occurs closer to where data are produced and consumed. What distinguishes edge architecture from general distributed computing is the importance of locality. The architecture is shaped by physical context, timing urgency, network conditions, privacy boundaries, and operational dependence on nearby computation.
The goal is not decentralization for its own sake. It is a better fit between where data arise and where they must be interpreted or acted upon. In strong architectures, the edge exists because local computation materially improves the behavior of the overall system. In weak ones, “edge” becomes little more than redistributed complexity.
That means edge architecture should not be reduced to “running some containers near devices.” It is a systems decision about where intelligence lives, where risk is absorbed, where evidence is retained, where trust is rooted, and where operational continuity is protected. Edge architecture becomes meaningful when locality changes what the system can safely, efficiently, and reliably do.
The Edge Continuum: Device, Gateway, Local Edge, Regional Edge, Cloud
Edge systems are usually better understood as a continuum than as a single location. In practical architectures, this often means several layers: the embedded endpoint, a nearby gateway or local controller, an on-premises or near-premises edge node, a regional edge layer, and one or more upstream cloud services.
This layered view is useful because different responsibilities naturally settle at different points. Sensor acquisition and immediate control often belong on the device. Protocol translation, buffering, and local coordination often belong at gateways. Site dashboards, cross-device fusion, local analytics, inference, and limited autonomy often belong on a local edge server. Low-latency multi-site coordination may belong at a regional edge layer. Long-horizon analytics, cross-site comparison, model training, archival retention, identity governance, and broad fleet policy often belong in the cloud.
| Layer | Typical Responsibilities | Should Usually Avoid |
|---|---|---|
| Endpoint device | Sensing, actuation, local safety, real-time firmware, simple inference, watchdog behavior | Large-scale analytics, complex orchestration, broad policy decisions |
| Gateway | Protocol translation, buffering, aggregation, child-device coordination, local filtering | Unbounded decision authority, opaque transformation, hidden single points of failure |
| Local edge node | Site-level analytics, dashboards, local databases, event processing, local inference, operator visibility | Global governance, unmanaged local shadow platforms |
| Regional edge | Low-latency cross-site coordination, regional failover, aggregate routing, regional policy cache | Replacing fleet-wide governance without adequate visibility |
| Cloud | Fleet management, identity, model training, archival storage, cross-site analytics, policy coordination | Hard real-time dependency for local safety or continuity-critical functions |
The important architectural point is that these layers should be distinguished by responsibility rather than by branding. A system becomes clearer when each layer has a defensible role and becomes brittle when layers are duplicated, blurred, or overloaded.
Workload Placement and Architectural Boundaries
The central design question in edge computing is workload placement: which tasks should run where, under what constraints, and with what fallback behavior. A tighter way to make placement decisions is to evaluate each workload against latency sensitivity, bandwidth intensity, disconnection tolerance, trust boundary, data-locality requirement, safety relevance, and fleet-manageability.
Tasks with hard real-time or safety implications, high raw data volume, strict privacy constraints, or disconnection requirements often belong on-device or at the local edge. Tasks that require cross-site context, long-horizon analytics, model training, archival storage, or centralized policy coordination often belong upstream. Many workloads sit between these extremes and need hybrid patterns: local first-stage processing, selective uplink, central review, and managed feedback into edge configuration.
| Placement Criterion | Device / Gateway Bias | Cloud / Upstream Bias |
|---|---|---|
| Latency sensitivity | Immediate response, control loop, local alarm, safety fallback | Delayed analysis, reporting, long-horizon optimization |
| Bandwidth intensity | High-volume raw video, vibration, audio, or telemetry requiring local reduction | Compact summaries, selected events, manageable historical records |
| Disconnection tolerance | Must continue during outage | Can wait for connectivity |
| Privacy and locality | Raw data should remain local or be minimized before transmission | Data are approved for broader aggregation or central analysis |
| Cross-site context | Local context sufficient | Fleet-wide context required |
| Fleet manageability | Simple stable logic, small update surface | Rapid iteration, complex models, broad policy control |
| Trust boundary | Can be protected and attested locally | Requires centralized identity, audit, or policy enforcement |
| Runtime assurance | Local watchdogs and bounded degraded modes can maintain safe behavior | Central review, analytics, and long-horizon governance can refine policy |
A weak architecture treats placement as deployment convenience. A strong one treats it as a systems decision about time, risk, and responsibility. The question is not where a workload can run, but where it should run if the system is to remain responsive, explainable, secure, bounded, and governable under load, interruption, and growth.
Latency, Bandwidth, and Real-Time Responsiveness
Latency is one of the clearest motivations for edge computing. Some applications degrade rapidly when decisions depend on distant round trips. Robotics perception, industrial alarms, machine safety interlocks, smart-building response, local video analytics, and field monitoring may all require local interpretation before upstream systems can respond. In those cases, computation near the point of data generation is not a luxury but a requirement for acceptable behavior.
Bandwidth matters just as much. Video streams, high-rate sensor data, acoustic signals, vibration data, and dense industrial telemetry can overwhelm networks if every raw signal is sent upstream continuously. Edge processing can reduce transport load by filtering, compressing, summarizing, buffering, event-qualifying, or performing inference locally before only relevant outputs are transmitted.
But it is important not to reduce edge value to speed alone. Lower latency and reduced bandwidth are compelling only when paired with intelligible workload boundaries. Otherwise the system may become faster locally while becoming harder to understand globally. A local edge node that reduces bandwidth by discarding raw evidence without lineage may improve transport efficiency while weakening auditability and incident analysis.
| Design Goal | Edge Pattern | Validation Evidence |
|---|---|---|
| Lower reaction time | Run control-relevant logic near sensing and actuation | End-to-end latency budget, p95/p99 local response time |
| Reduce uplink volume | Filter, summarize, event-detect, or infer locally | Raw bytes vs. forwarded bytes, compression report, retained-evidence policy |
| Preserve local continuity | Buffer and act locally during outage | Offline test, buffer ledger, replay log |
| Keep data local | Retain raw data on-site and uplink summaries or alerts | Data-locality policy, selective-uplink record |
| Improve operator response | Expose site-level dashboards and alarms locally | Local UI availability, alarm trace, operator acknowledgement log |
Edge architecture is strongest when latency and bandwidth benefits are measured together with evidence retention, freshness, and downstream interpretability.
Resilience, Autonomy, and Offline Operation
Edge architectures are often justified not only by speed but by survivability. A site, vehicle, building, robot, field station, or industrial process may need to continue operating when cloud connectivity is degraded or unavailable. This makes autonomy an architectural property rather than a marketing claim.
A resilient edge system should make clear what functions remain available during disconnection, what data are buffered locally, what decisions are still authorized, what safety envelopes apply, what external dependencies are lost, and how the system resynchronizes with upstream services when links return. Edge architectures that appear sophisticated while depending on constant cloud reachability often fail at the exact moment they are most needed.
| Offline Condition | Good Edge Behavior | Evidence Required |
|---|---|---|
| Cloud unavailable | Continue local sensing, buffering, essential rules, and safe local actions | Offline mode log, local action policy, buffer status |
| Gateway isolated | Endpoint devices maintain safety-critical local behavior | Device fallback mode, watchdog log, child-device state |
| Local edge node degraded | Gateway or endpoint path degrades gracefully rather than failing silently | Health-state transition, degraded-mode event |
| Buffer pressure | Prioritize high-value records and preserve drop reasons | Priority queue state, drop ledger, retention policy |
| Reconnect | Replay delayed records with event time, upload time, and idempotency keys | Replay batch, duplicate handling, gap record |
Good offline behavior is not accidental. It is designed. The system should know what it can still sense, infer, decide, store, and report under degraded connectivity. It should also know what it cannot safely continue doing without central coordination.
Runtime Assurance, Degraded Modes, and Local Authority
Edge autonomy is only responsible when it is bounded by runtime assurance. A device, gateway, or local edge node that can act locally must also be able to monitor its own health, detect degradation, enter a safe mode, limit authority, restart failed components, preserve evidence, and recover in a controlled sequence. Otherwise local autonomy becomes uncontrolled local behavior.
Runtime assurance is the engineering layer that asks whether the local system should still be trusted to continue its current function. This includes watchdog timers, heartbeat monitoring, queue-depth thresholds, memory and CPU pressure, thermal limits, clock synchronization, storage pressure, child-device coverage, update status, workload restart count, and connectivity quality. In high-consequence systems, runtime assurance should distinguish fail-safe behavior from fail-operational behavior. Some workloads should stop safely when trust is uncertain. Others should continue in a limited mode because stopping would create greater risk.
| Runtime Condition | Fail-Safe Response | Fail-Operational Response | Required Evidence |
|---|---|---|---|
| Watchdog timeout | Stop unsafe local action and restart workload | Shift to redundant runtime or simpler fallback rule | Watchdog reset record, restart count, affected workload |
| High CPU or memory pressure | Shed noncritical workloads | Prioritize control, alarms, and buffering | Resource trace, queue depth, shed-workload log |
| Thermal stress | Throttle or stop optional compute | Continue safety-critical sensing and local alarms | Thermal state, throttle event, degraded-mode record |
| Clock drift | Flag timestamps and suppress time-sensitive decisions | Use local monotonic ordering until synchronization returns | Clock offset, sync status, replay correction |
| Trust-state uncertainty | Restrict local authority and require re-attestation | Continue only preapproved low-risk functions | Attestation result, trust transition, authority limit |
| Connectivity loss | Disable cloud-dependent decisions | Continue bounded local policies and buffer evidence | Offline-mode log, buffer ledger, reconnect replay |
This layer is what separates fieldable edge architecture from distributed software placed near devices. Runtime assurance defines how the edge behaves when it is no longer fully healthy, fully connected, fully synchronized, or fully trusted.
Data Locality, Privacy, and Information Flow
Processing data at the edge is often valuable because not all data should travel equally far. Some information is too voluminous, some too sensitive, and some too locally meaningful to justify immediate upstream transmission. Edge architectures can therefore preserve privacy, reduce exposure, and keep high-volume raw data local while still exporting summaries, alerts, features, model outputs, or evidence pointers.
This means edge architecture is also an information-governance problem. The system should specify what remains local, what is aggregated, what is redacted or transformed, what is retained, what is dropped, and what constitutes a complete enough record for downstream users. Data locality is not only a performance optimization. It is part of how the architecture defines trust, exposure, and operational meaning.
| Information Flow | Edge Architecture Pattern | Governance Question |
|---|---|---|
| Raw data retained locally | Keep video, audio, vibration, or sensitive records on-site | How long is raw evidence retained, and who can access it? |
| Features forwarded upstream | Compute summaries, embeddings, or event metrics locally | Do features leak sensitive information or obscure evidence? |
| Events forwarded immediately | Send fault, warning, security, or anomaly records with priority | What evidence explains the event? |
| Summaries batched | Transmit routine telemetry periodically | How is freshness preserved? |
| Records suppressed or dropped | Filter low-value or policy-restricted data | Are drop reasons and policy versions retained? |
Strong architectures do not simply move less data. They move the right data, in the right form, under the right qualifiers, with enough lineage for downstream interpretation.
Gateways, Edge Nodes, and Intermediate Coordination
Intermediate nodes are often what make edge systems practical. Gateways and local edge nodes can perform protocol translation, buffering, normalization, rule execution, local analytics, local inference, site dashboards, and cross-device coordination. In many real deployments, they are the layer that turns many local endpoints into a coherent site-level system.
But intermediate layers also introduce concentration points. A gateway failure may isolate many healthy endpoints at once. A local edge node may become a silent bottleneck or an opaque source of transformed data if it aggregates aggressively without preserving lineage. Good edge architecture therefore uses intermediate layers to simplify and stabilize the wider system without allowing those layers to become hidden single points of meaning.
| Intermediate Function | Engineering Value | Architectural Risk | Control |
|---|---|---|---|
| Protocol translation | Connects heterogeneous devices to common systems | Loss of source semantics or unit meaning | Protocol map, unit schema, source lineage |
| Buffering | Preserves continuity during outages | Stale replay or silent data loss | Buffer ledger, replay policy, drop reason |
| Aggregation | Reduces transport and organizes site-level data | Opaque summarization | Aggregation manifest, raw-window pointer |
| Local coordination | Enables cross-device logic and site-level response | Overbroad local authority | Decision policy, safety envelope |
| Local dashboards | Supports site operators without cloud dependency | Mismatch between local and upstream state | Freshness markers, sync status, local/cloud state comparison |
A gateway or local edge node should remain legible as a boundary layer: it mediates, coordinates, and protects, but it should not obscure what has been measured locally or how that local information has been transformed.
Deployment, Orchestration, and Fleet Management
Once computation is distributed into the field, deployment and lifecycle management become first-class architectural concerns. This includes versioning, configuration, staged rollout, rollback, health reporting, workload scheduling, inventory, and explicit control over what runs where.
A proof-of-concept edge deployment can survive manual administration. A real edge fleet cannot. Strong edge architectures therefore include management planes and operational workflows as part of the design, not as afterthoughts added once nodes are already in the field.
Fleet management must also respect heterogeneity. Edge fleets often contain multiple hardware classes, firmware versions, runtime environments, gateway types, network profiles, accelerator capabilities, trust states, and ownership boundaries. A single update strategy may not work across all devices. Workload placement and orchestration must account for memory, CPU, accelerator support, storage, power, network reachability, trust posture, and local operational constraints.
| Fleet Management Concern | Engineering Requirement | Evidence Artifact |
|---|---|---|
| Inventory | Know device, gateway, local edge, hardware class, software version, owner, and site | Fleet inventory schema, asset registry |
| Configuration | Version local policies, workload settings, credentials, and telemetry contracts | Configuration manifest, drift report |
| Deployment | Stage rollouts across canary, pilot, regional, and fleet rings | Rollout plan, health gate, deployment log |
| Rollback | Restore known-good workload, configuration, or firmware versions | Rollback artifact, recovery test |
| Health monitoring | Detect offline nodes, degraded runtimes, backlog, resource pressure, and version skew | Telemetry report, SLO dashboard |
| Ownership | Map operational responsibility across site, gateway, platform, and cloud teams | Ownership matrix, incident runbook |
| Supply-chain evidence | Track artifacts, SBOMs, signatures, workload provenance, and update origin | SBOM, signed artifact record, provenance manifest |
This also means that architecture should respect operational ownership. The people responsible for maintaining the site, the gateway, the local applications, and the cloud services may not be the same people. Edge design becomes stronger when those ownership boundaries are visible in the architecture itself.
Security, Hardware Trust, and Platform Integrity
Edge computing increases exposure because compute and data move into environments that are often less controlled than centralized data centers. This makes hardware-rooted trust, secure boot, measured boot, attestation, trusted execution environments, protected key handling, signed updates, workload provenance, SBOMs, credential rotation, and runtime integrity especially important. Edge systems often rely on physically accessible devices, mixed-ownership environments, and intermediate nodes that carry both data and operational authority.
Security in this context is architectural rather than add-on. It includes how devices prove identity, how software is trusted, how local nodes are updated, how secrets are protected, how telemetry can be trusted, how rollback is verified, and how much authority is granted to each layer of the edge continuum.
| Security Concern | Risk | Control Pattern |
|---|---|---|
| Device identity | Unauthorized devices join the fleet | Hardware identity, certificates, enrollment policy |
| Boot integrity | Compromised firmware or bootloader runs locally | Secure boot, measured boot, attestation |
| Runtime tampering | Local workload behavior changes without authorization | Runtime integrity checks, signed workloads, monitoring |
| Secret exposure | Keys or credentials leak from physically exposed devices | Protected storage, rotation, least privilege |
| Update compromise | Malicious or incorrect updates reach edge nodes | Signed updates, staged rollout, rollback verification |
| Supply-chain compromise | Unknown or unverified workload artifacts are deployed | SBOM, provenance record, signature verification, policy gate |
| Telemetry manipulation | Cloud sees false health, event, or security state | Signed telemetry, attestation-linked reporting, anomaly checks |
| Overbroad local authority | Local node takes actions beyond its validated scope | Decision policy, authorization boundary, safety envelope |
| Privilege creep | Workloads accumulate unnecessary local permissions | Least privilege, workload sandboxing, local access review |
A system that distributes compute outward but not trust outward coherently is likely to become operationally fragile. Every outward movement of software or state is also a movement of risk.
Edge AI and Distributed Inference
Edge architectures increasingly support AI and ML inference close to the point of sensing or action. This can reduce latency, preserve privacy, and lower transport requirements by turning raw inputs into local classifications, scores, detections, or actions before only selective information moves upstream.
But edge AI also raises design questions about model versioning, explainability, drift, validation, backend compatibility, confidence thresholds, fallback behavior, and when inference results should be trusted locally versus verified centrally. Edge AI therefore does not replace edge architecture; it intensifies the need for it.
| Edge AI Concern | Architectural Question | Evidence Required |
|---|---|---|
| Model placement | Should inference run on-device, gateway, local edge, regional edge, or cloud? | Latency, memory, bandwidth, privacy, and runtime justification |
| Model version | Which model generated the local result? | Model version, model hash, active model inventory |
| Runtime backend | Was inference CPU, NPU, DSP, GPU, FPGA, or MCU-based? | Runtime manifest, backend validation report |
| Confidence | Was the local prediction strong enough to use? | Confidence score, threshold, fallback record |
| Drift | Are field inputs departing from training assumptions? | Feature summary, confidence distribution, anomaly-rate trend |
| Local authority | What can the model output influence locally? | Decision policy, safety envelope, local action trace |
| Failure containment | What happens when inference is stale, low confidence, or invalid? | Fallback path, safety filter, model-health telemetry |
The key issue is not whether a model can run at the edge, but whether the surrounding system can govern that model responsibly across devices, versions, sites, runtimes, accelerators, confidence thresholds, and changing field conditions.
Observability, Telemetry, and Operational Evidence
Edge observability is not merely cloud monitoring extended to more nodes. It is the ability to understand distributed local behavior under intermittent connectivity, heterogeneous hardware, version skew, local decision-making, trust-state changes, and runtime degradation. A device may be online but stale, healthy but running an old policy, connected but overloaded, or locally active while cloud state is delayed.
Strong observability therefore captures both system health and architectural meaning. Engineers need to know which workloads are running where, what versions are active, what data are buffered, whether local outputs are fresh, what decisions were made locally, what was forwarded upstream, and what happened during outage or recovery.
| Observability Dimension | Signal | Why It Matters |
|---|---|---|
| Connectivity | Online, offline, degraded, reconnect, packet loss, uplink delay | Distinguishes local operation from upstream visibility |
| Workload state | Active workload, version, resource use, restart count | Detects drift, crash loops, and placement mismatch |
| Resource pressure | CPU, memory, storage, thermal state, accelerator load, queue depth | Detects overload before local behavior fails |
| Buffer state | Backlog, retention pressure, drop reason, replay lag | Shows whether local evidence survives outages |
| Clock state | Clock drift, sync status, monotonic ordering, event-time accuracy | Protects timestamp validity and replay interpretation |
| Local decision trace | Rule/model version, input window, local action, confidence, fallback | Supports incident reconstruction |
| Trust state | Boot status, attestation, update signature, credential age | Shows whether local reports should be trusted |
| Fleet state | Version skew, hardware coverage, site health, rollout ring | Supports fleet governance |
Without edge observability, distributed computing becomes distributed uncertainty. The architecture may still run, but engineers cannot tell whether it is behaving correctly.
Worked Example: Industrial Site Edge Architecture During Cloud Outage
Consider an industrial site with vibration sensors, temperature monitors, programmable controllers, machine status signals, a local gateway, a site-edge node, and upstream cloud coordination. The architecture must support low-latency local alarms, raw-window retention for incidents, buffering during outages, site-level dashboards, fleet-level analytics, model updates, and secure device management.
Now add a concrete failure scenario: the cloud link becomes unavailable for forty-five minutes while one rotating machine begins showing abnormal vibration. The endpoint continues sampling. The embedded runtime computes a local health flag. The gateway buffers feature windows and event records. The local edge node raises a site alarm because the fault rule is within its authorized local decision boundary. The site dashboard shows a degraded connectivity banner, local event time, buffer backlog, and raw-window retention status. Noncritical video summaries are throttled. Priority telemetry is retained. When cloud connectivity returns, the gateway replays delayed records with event time, upload time, ingestion time, idempotency keys, and gap markers.
| Layer | Responsibility During Outage | Engineering Evidence |
|---|---|---|
| Sensor endpoint | Acquire vibration, temperature, and status signals | Sensor ID, calibration state, acquisition time, firmware version |
| Embedded runtime | Validate samples, compute simple health flags, maintain watchdog behavior | Runtime version, watchdog log, missing-sample rate |
| Gateway | Translate protocols, buffer telemetry, normalize units, route priority events | Protocol map, buffer ledger, child-device inventory, unit schema |
| Local edge node | Run site analytics, local dashboard, anomaly detection, raw-window retention | Workload manifest, local event log, raw-window pointer |
| Cloud | Unavailable during outage; resumes fleet visibility after replay | Reconnect event, replay batch, ingestion-time record, gap summary |
A concrete architecture budget makes the placement problem clearer. The values below are illustrative, but this kind of artifact should exist before deployment.
| Architecture Budget | Example Target | Validation Evidence |
|---|---|---|
| Local alarm latency | p95 sensing-to-local-alert below 100 ms | Latency benchmark, local event trace |
| Gateway buffer endurance | Retain priority telemetry for expected outage window | Buffer pressure test, retention ledger |
| Raw-window retention | Retain incident raw windows for bounded forensic period | Retention policy, raw-window pointer |
| Selective uplink | Forward faults immediately when connected; batch normal summaries | Forwarding policy, uplink log |
| Offline mode | Continue sensing, local alarms, buffering, and site dashboard during cloud outage | Offline test, reconnect replay record |
| Degraded-mode behavior | Shed noncritical workloads while preserving safety, alarms, and evidence | Degraded-mode trace, workload-shedding record |
| Update safety | Use canary rollout and rollback for gateway and edge workloads | Rollout ring, rollback test, version inventory |
| Trust boundary | Devices and workloads prove identity and integrity | Attestation result, signed update record, SBOM/provenance manifest |
| Fleet governance | Cloud tracks active versions, site state, and policy compliance after reconnect | Fleet report, version skew summary, SLO dashboard |
This example shows why edge computing architecture is not simply a deployment pattern. It is a way of distributing responsibility so that the site remains responsive locally while still participating in fleet-wide governance and long-horizon analysis after connectivity returns.
Deployment Readiness Gate
An engineering-grade edge computing deployment should pass a readiness gate before field rollout. The gate should verify not only that workloads start successfully, but that the complete edge-to-cloud responsibility chain is observable, secure, bounded, and recoverable.
| Readiness Check | Pass Condition | Why It Matters |
|---|---|---|
| Topology manifest complete | Devices, gateways, local edge nodes, regional edge layers, and cloud relationships documented | Prevents ambiguity about architectural responsibility |
| Workload placement justified | Each workload has latency, bandwidth, privacy, continuity, trust, and manageability rationale | Prevents arbitrary edge placement |
| Latency budget passed | End-to-end p95/p99 paths meet timing targets | Protects real-time and near-real-time behavior |
| Offline mode tested | Disconnection, buffering, local action, and reconnect replay are validated | Protects operational continuity |
| Runtime assurance tested | Watchdogs, heartbeats, restart thresholds, degraded modes, and safety boundaries validated | Protects bounded local autonomy |
| Selective uplink tested | Raw, feature, event, summary, suppressed, and dropped records follow policy | Connects bandwidth reduction to evidence governance |
| Security posture verified | Device identity, secure boot, signed updates, SBOM/provenance, and trust boundaries validated | Protects exposed local infrastructure |
| Fleet inventory deployed | Hardware class, workload version, configuration, and ownership are visible | Supports lifecycle governance |
| Rollback path ready | Known-good workload and configuration versions can be restored | Limits field damage from failed updates |
| Observability schema deployed | Connectivity, latency, backlog, version, trust, resource pressure, and local decision signals visible | Makes distributed behavior inspectable |
| Incident reconstruction ready | Local decision, data lineage, replay, degraded-mode, and trust evidence can be reconstructed | Supports audit and debugging after failures |
This readiness gate separates a promising edge prototype from a fieldable edge architecture. It turns local deployment into accountable infrastructure.
Data and Configuration Artifacts
Edge computing systems become easier to build, test, and maintain when their assumptions are represented as machine-readable artifacts. Engineers should be able to inspect topology, workload placement, latency budgets, offline behavior, runtime assurance, data locality, trust boundaries, fleet inventory, deployment plans, telemetry schemas, and incident evidence requirements without relying only on diagrams or institutional memory.
| Artifact | What It Captures | Engineering Purpose |
|---|---|---|
edge_topology_manifest.yml |
Devices, gateways, local edge nodes, regional edge, cloud services, and ownership | Makes architecture structure inspectable |
workload_placement_matrix.csv |
Workload-to-layer mapping with rationale and constraints | Prevents arbitrary workload placement |
latency_bandwidth_budget.yml |
Path-level timing and transport budgets | Makes responsiveness measurable |
offline_mode_policy.yml |
What continues, degrades, buffers, stops, or requires review during outage | Defines continuity boundaries |
runtime_assurance_policy.yml |
Watchdogs, heartbeats, degraded modes, fail-safe/fail-operational behavior, and recovery sequencing | Bounds local autonomy |
data_locality_policy.yml |
What stays local, what is summarized, what is forwarded, what is dropped | Governs privacy and evidence flow |
trust_boundary_manifest.yml |
Device identity, secure boot, attestation, secret handling, signed updates, and workload provenance | Protects local compute authority |
fleet_inventory_schema.sql |
Queryable device, gateway, workload, version, owner, and site state | Supports fleet governance |
deployment_rollout_plan.yml |
Canary, pilot, regional, and fleet rollout stages with health gates | Controls update risk |
edge_telemetry_schema.json |
Connectivity, latency, backlog, local action, resource pressure, trust state, and version signals | Makes edge behavior observable |
incident_reconstruction_policy.yml |
Evidence required to explain local behavior after failure | Supports audit, debugging, and accountability |
The goal is not to force one edge platform. The goal is to make distributed responsibility inspectable. If edge architecture assumptions cannot be found in artifacts, they will be difficult to test, secure, update, or explain after deployment.
Mathematical Lens: Placement, Latency, Bandwidth, Availability, and Cost
A practical mathematical lens for edge computing begins with placement quality. The architecture should not merely move workloads outward; it should improve the system’s combined latency, bandwidth, privacy, autonomy, trust, and management profile.
L_{\mathrm{edge}} = L_{\mathrm{device}} + L_{\mathrm{gateway}} + L_{\mathrm{edge}} + L_{\mathrm{queue}} + L_{\mathrm{action}}
\]
Interpretation: Local edge latency includes device processing, gateway processing, edge-node computation, queueing, and local action. Cloud round-trip delay is avoided only if the decision path truly stays local.
R_{\mathrm{uplink}} = 1 – \frac{D_{\mathrm{forwarded}}}{D_{\mathrm{raw}}}
\]
Interpretation: Uplink reduction measures how much raw data volume is reduced by local filtering, summarization, buffering, or inference.
C_{\mathrm{placement}} = C_{\mathrm{compute}} + C_{\mathrm{network}} + C_{\mathrm{storage}} + C_{\mathrm{management}} + C_{\mathrm{risk}}
\]
Interpretation: Placement cost includes not only compute and network cost, but also storage, management burden, and risk. Edge placement can reduce one cost while increasing another.
O_{\mathrm{offline}} = \frac{F_{\mathrm{available\ offline}}}{F_{\mathrm{required\ during\ outage}}}
\]
Interpretation: Offline operability measures how much required functionality remains available during disconnection. A value below 1 indicates incomplete continuity.
V_{\mathrm{skew}} = \frac{N_{\mathrm{noncompliant\ versions}}}{N_{\mathrm{fleet}}}
\]
Interpretation: Version skew measures the share of the fleet running non-approved workload, firmware, model, rule, or configuration versions.
Q_{\mathrm{edge}} = w_1 S_{\mathrm{latency}} + w_2 S_{\mathrm{bandwidth}} + w_3 S_{\mathrm{continuity}} + w_4 S_{\mathrm{privacy}} + w_5 S_{\mathrm{trust}} + w_6 S_{\mathrm{assurance}} – w_7 C_{\mathrm{management}}
\]
Interpretation: Edge architecture quality can be framed as the weighted value of latency, bandwidth, continuity, privacy, trust, and runtime-assurance benefits minus management burden.
The key engineering point is that edge architecture should be measurable. Latency, bandwidth reduction, offline operability, version skew, trust posture, buffer endurance, runtime assurance, and management burden should be operational signals, not hidden assumptions.
Python Workflow: Edge Workload Placement and Continuity Simulation
The companion Python workflow should model edge architecture as a placement and continuity problem. It can score workloads against latency, bandwidth, privacy, offline requirement, trust boundary, runtime assurance, and management burden, then simulate connectivity loss, local buffering, selective uplink, version skew, resource pressure, and rollback readiness.
# Python Workflow: Edge Workload Placement and Continuity Simulation
placement_score = (
weights["latency"] * workload.latency_sensitivity
+ weights["bandwidth"] * workload.raw_data_volume
+ weights["privacy"] * workload.privacy_requirement
+ weights["continuity"] * workload.offline_requirement
+ weights["trust"] * layer.trust_score
+ weights["assurance"] * layer.runtime_assurance_score
- weights["management"] * layer.management_burden
)
candidate_layer = min(
edge_layers,
key=lambda layer: placement_cost(workload, layer)
)
offline_ready = (
candidate_layer.can_run_offline
and buffer.endurance_hours >= workload.required_outage_hours
and local_policy.authorizes_required_actions
and runtime_assurance.degraded_mode_defined
and rollback.ready
)
edge_event = {
"workload_id": workload.id,
"assigned_layer": candidate_layer.name,
"placement_score": placement_score,
"p95_latency_ms": latency_model.p95(candidate_layer, workload),
"uplink_reduction": data_flow.uplink_reduction(workload),
"offline_ready": offline_ready,
"trust_state": candidate_layer.trust_state,
"runtime_assurance_state": runtime_assurance.state,
"watchdog_resets": runtime_assurance.watchdog_resets,
"resource_pressure": runtime_assurance.resource_pressure,
"version_compliant": workload.version == workload.approved_version
}This workflow is useful because it converts edge architecture from a diagram into a testable design record. Engineers can evaluate whether workloads were placed for defensible reasons, whether the local layer can survive outage, whether version skew is increasing, whether latency budgets are met, whether degraded modes are defined, and whether bandwidth reduction is preserving enough evidence for downstream interpretation.
For production systems, the same workflow can connect to fleet inventories, telemetry streams, deployment records, network measurements, device attestation records, SBOM/provenance manifests, runtime-assurance logs, and incident-reconstruction systems.
R Workflow: Edge Fleet Reporting and Architecture Health Analysis
The companion R workflow should focus on descriptive reporting across sites, gateways, hardware classes, workload placements, connectivity states, workload versions, latency budgets, buffer states, offline readiness, runtime-assurance state, and trust posture. It can summarize where edge architecture is healthy, overloaded, stale, disconnected, insecure, or difficult to govern.
# R Workflow: Edge Fleet Reporting and Architecture Health Analysis
edge_fleet_summary <- edge_inventory |>
dplyr::group_by(site_id, layer, hardware_class, workload_family) |>
dplyr::summarise(
assets = dplyr::n(),
online_rate = mean(connectivity_state == "online", na.rm = TRUE),
degraded_rate = mean(health_state == "degraded", na.rm = TRUE),
p95_latency_ms = quantile(latency_ms, 0.95, na.rm = TRUE),
latency_violation_rate = mean(latency_ms > latency_budget_ms, na.rm = TRUE),
mean_buffer_backlog = mean(buffer_backlog, na.rm = TRUE),
offline_ready_rate = mean(offline_ready == TRUE, na.rm = TRUE),
version_skew_rate = mean(active_version != approved_version, na.rm = TRUE),
trust_verified_rate = mean(trust_state == "verified", na.rm = TRUE),
runtime_assurance_ready_rate = mean(runtime_assurance_state == "ready", na.rm = TRUE),
watchdog_reset_rate = mean(watchdog_resets > 0, na.rm = TRUE),
rollback_ready_rate = mean(rollback_ready == TRUE, na.rm = TRUE),
.groups = "drop"
)This reporting layer helps distinguish architectural problems from simple device problems. High latency may indicate workload misplacement. High buffer backlog may indicate insufficient local storage or weak uplink policy. Version skew may reveal lifecycle management gaps. Low trust verification may indicate insecure local authority. Frequent watchdog resets may show that runtime assurance is containing a problem that still needs root-cause analysis. Low offline readiness may show that an edge system is still cloud-dependent despite its architecture.
For edge fleets, this kind of reporting is essential because distributed systems can appear healthy at the cloud level while local sites are stale, overloaded, misconfigured, disconnected, untrusted, or operating under degraded authority.
Systems Code: TinyML, MicroPython, C/C++, Rust, Go, PYNQ, HDL, Bash, and Configuration
The companion repository should be useful to engineers because edge computing architecture crosses the full embedded and distributed stack. It touches device firmware, gateway logic, workload placement, local telemetry, buffering, selective uplink, fleet inventory, trust boundaries, rollout plans, runtime assurance, PYNQ/FPGA acceleration, HDL stream handling, and reporting workflows.
| Folder | Engineering Role | Edge Architecture Use |
|---|---|---|
python/ |
Simulation and architecture workflow automation | Workload placement scoring, latency/bandwidth modeling, outage simulation |
r/ |
Fleet reporting and descriptive analytics | Latency, version skew, trust posture, rollback readiness, offline readiness |
sql/ |
Queryable fleet and topology evidence | Assets, workloads, versions, telemetry, trust state, incidents |
c/ |
Firmware-adjacent local behavior | Watchdog, local state, offline mode, minimal telemetry framing |
cpp/ |
Edge runtime and state-machine abstraction | Workload health, connectivity state, fallback, local action boundaries |
rust/ |
Safe systems validation | Topology validation, workload placement checks, trust-policy validation |
go/ |
Operational services and telemetry utilities | Fleet inventory API, edge event router, health reporting service |
micropython/ |
Microcontroller prototypes | Local heartbeat, simple offline state, sensor-summary emission |
tinyml/ |
Constrained local inference | Minimal event classification at endpoint or gateway layer |
pynq/ |
FPGA-backed edge acceleration | Low-latency local preprocessing and stream acceleration |
hdl/ |
Hardware/software co-design | Stream timestamping, local event triggers, telemetry framing, gateway interfaces |
bash/ |
Repeatable workflow execution | Runs simulations, validates manifests, generates outputs and inventory |
config/ |
Machine-readable architecture metadata | Topology, placement, latency, offline mode, runtime assurance, trust, data locality, rollout |
This stack matters because edge architecture is not produced by one platform, one runtime, or one cloud service. It is produced by the interaction among devices, gateways, local edge nodes, telemetry, security, lifecycle management, runtime assurance, and operational governance.
Testing and Validation
Edge computing architectures should be validated under the conditions that make edge computing necessary: low-latency response, high-volume data, intermittent connectivity, local buffering, physical exposure, staged updates, version skew, workload failure, gateway degradation, local edge node restart, trust-state uncertainty, and partial cloud outage.
A practical validation suite should answer these questions:
- Does each workload have a documented placement rationale?
- Does total end-to-end latency meet local timing budgets?
- Does local processing reduce bandwidth without destroying needed evidence?
- Does offline mode preserve required sensing, buffering, local action, and operator visibility?
- Does reconnect replay preserve event time, upload time, ingestion time, and idempotency?
- Can gateways fail without leaving child devices unsafe or invisible?
- Are device identity, boot integrity, workload signatures, update provenance, and trust state verified?
- Can runtime assurance detect watchdog resets, resource pressure, clock drift, queue depth, and degraded mode?
- Can staged rollout and rollback work across heterogeneous hardware classes?
- Can the fleet inventory identify active versions, approved versions, configuration drift, trust state, and ownership?
- Can incident reconstruction explain what the local edge layer sensed, transformed, retained, decided, suppressed, and forwarded?
Testing should include negative cases. Engineers should deliberately test cloud outage, gateway failure, local edge node failure, full buffer, stale replay, duplicate events, invalid credentials, failed update, unsigned workload, invalid SBOM/provenance, version skew, latency spikes, thermal pressure, clock drift, child-device loss, watchdog reset, and local action outside authority. Edge computing failures are dangerous when local systems continue behaving in the field while central systems no longer understand what is happening.
Operational Signals and Edge Architecture Observability
Edge architecture observability is the ability to understand whether distributed responsibilities remain healthy, not merely whether nodes are online. A gateway can be online but overloaded. A local edge node can be running but stale. A device can be connected but untrusted. A workload can be active but running the wrong version. A site can be locally operational while cloud visibility is delayed.
| Signal | What It Reveals | Why Engineers Need It |
|---|---|---|
| Connectivity state | Online, degraded, offline, reconnecting, or intermittent | Distinguishes local state from cloud visibility |
| Workload placement | Which layer runs each workload | Detects placement drift or unsupported deployment |
| Active version | Firmware, workload, model, rule, and configuration versions | Detects version skew |
| Latency | Device-to-action, gateway, edge-node, and uplink timing | Confirms responsiveness and budget compliance |
| Resource pressure | CPU, memory, storage, queue depth, accelerator utilization, and thermal state | Detects overload before local behavior fails |
| Watchdog and restart state | Watchdog resets, crash loops, restart count, degraded-mode entries | Shows whether runtime assurance is containing instability |
| Clock state | Clock drift, sync status, monotonic ordering, event-time confidence | Protects timing interpretation and replay integrity |
| Buffer backlog | Queued local records waiting for forwarding | Reveals outage pressure and data-loss risk |
| Replay lag | Delay between event occurrence and upstream visibility | Prevents stale state from appearing current |
| Offline readiness | Whether required functions can continue without cloud connectivity | Measures continuity instead of assuming it |
| Trust state | Identity, boot, attestation, runtime, update integrity, and workload provenance | Shows whether local authority should be trusted |
| Rollback readiness | Whether known-good versions can be restored | Limits damage from failed updates |
| Local action trace | What decisions were made locally and why | Supports incident reconstruction |
| Data-locality status | What raw, feature, summary, or event data left the site | Supports privacy and evidence governance |
| Ownership state | Which team owns device, gateway, edge, and cloud responsibilities | Reduces incident ambiguity |
Engineers should design these signals before deployment. If the system cannot reconstruct placement, version, latency, backlog, trust, local decisions, runtime assurance, and data flow, then edge architecture becomes difficult to operate at scale.
Common Failure Modes
Edge computing architectures fail in predictable ways because they combine physical systems, distributed software, intermittent connectivity, local autonomy, runtime degradation, and fleet management. Engineers should design architecture, tests, and observability around these failure modes from the beginning.
- Placement by convenience: workloads are moved outward without a clear latency, bandwidth, privacy, continuity, or trust rationale.
- Cloud dependency hidden inside edge design: the system claims local autonomy but fails when upstream services are unavailable.
- Opaque gateway transformation: gateways normalize or aggregate data without preserving source lineage.
- Version skew: devices, gateways, local edge nodes, or models run inconsistent versions without clear inventory.
- Stale replay: delayed local outputs are interpreted upstream as current state.
- Buffer collapse: local storage fills and drops evidence without priority policy or drop reason.
- Overbroad local authority: local nodes make decisions beyond validated safety or policy boundaries.
- Weak trust propagation: edge nodes run software that cannot be attested, signed, or verified.
- Runtime assurance gap: watchdogs, heartbeats, degraded modes, or resource limits are missing or not monitored.
- Management plane gap: field nodes cannot be reliably updated, rolled back, inventoried, or monitored.
- Single point of site meaning: a gateway or local edge node becomes the only place where data are transformed, but its transformations are not observable.
- Fleet-level blindness: cloud services see periodic summaries but not enough local context to detect site degradation.
- Supply-chain opacity: firmware, containers, models, or scripts are deployed without provenance, SBOMs, or signed artifacts.
- Ownership ambiguity: device, gateway, site, and cloud teams lack clear operational boundaries during incidents.
A mature edge architecture does not assume these failures can be eliminated. It makes them detectable, bounded, testable, recoverable, and reviewable.
Trade-Offs in Edge Computing Design
Edge computing architectures are defined by trade-offs that cannot all be optimized at once. More local compute can reduce latency and bandwidth use but increase device cost, management burden, update complexity, and security exposure. More centralization can simplify governance and analytics but weaken resilience under disconnection and increase transport dependence. More local autonomy can preserve continuity but requires stronger local decision boundaries, runtime assurance, and incident evidence.
The right architecture therefore depends on purpose. Factory control, smart buildings, site analytics, connected mobility, infrastructure monitoring, robotics, environmental sensing, and consumer edge devices all answer the placement question differently. Good edge architecture is proportional: it places the minimum necessary capability at each layer to preserve responsiveness, trust, continuity, and operational coherence without turning the field into an unmanageable shadow data center.
Edge architecture is strongest when each layer carries only the responsibilities it can sustain well. Devices should not become unmanaged servers. Gateways should not become opaque authorities. Local edge nodes should not become hidden cloud substitutes. Cloud services should not be hard dependencies for local safety or continuity-critical behavior.
The central discipline is not pushing computation outward as far as possible. It is placing the right computation at the right layer under the right constraints, with the right evidence and recovery path.
Applications in Embedded and Edge Systems
Industrial site edge. In factories, plants, and process environments, local edge nodes often aggregate machine telemetry, run rules or anomaly detection near the line, preserve operations during upstream outages, and expose dashboards or alerts without forcing every decision through a distant cloud. This pattern prioritizes deterministic local behavior, bounded latency, and clear separation between site autonomy and fleet-level analytics.
Building and campus edge. In commercial buildings, hospitals, campuses, and similar facilities, gateways and local edge servers coordinate HVAC, access systems, occupancy signals, camera analytics, and energy telemetry. The architecture matters because these systems often need local continuity and privacy-aware processing while still supporting broader portfolio reporting or optimization upstream.
Utility and remote infrastructure edge. In water systems, substations, pipelines, environmental stations, and remote infrastructure, edge nodes are often justified by intermittent connectivity and the need for local buffering, event detection, and partial autonomy. Here, edge computing is less about raw speed than about survivability: the system must continue sensing, storing, and sometimes acting even when central coordination is delayed.
Edge AI and local perception. In video analytics, robotics, mobile systems, and intelligent sensing, edge nodes may perform inference close to the point of observation so that raw streams do not have to travel continuously upstream. This makes model lifecycle, backend validation, confidence logic, runtime assurance, and selective uplink part of the architecture rather than separate machine-learning concerns.
Connected mobility and vehicles. Vehicles, drones, and mobile robots often require local perception, control, buffering, and degraded-mode operation because cloud connectivity cannot be assumed at every moment. Edge architecture determines what can be decided locally and what requires upstream coordination.
Environmental and field monitoring. Remote sensing networks, ecological stations, water-quality monitors, acoustic sensors, and camera traps often use edge architectures to reduce uplink load, preserve local evidence, and support delayed synchronization. In these systems, edge value is often tied to energy, connectivity, and evidence-retention constraints.
What unites these patterns is not one platform or one hardware profile. It is the need to place computation close enough to data and action that the system behaves better than it would under a purely centralized model. Edge computing is therefore best understood as a response to physical and operational reality rather than as a branding layer on top of distributed systems.
Engineer Checklist
- Define which workloads belong on-device, at the gateway, at the local edge, at the regional edge, and in the cloud.
- Document placement rationale using latency, bandwidth, privacy, continuity, trust, safety, runtime assurance, and manageability criteria.
- Measure end-to-end latency paths, not only compute time at one layer.
- Define what continues, degrades, buffers, stops, or requires manual review during disconnection.
- Preserve acquisition time, processing time, buffer-entry time, upload time, and ingestion time where replay matters.
- Version firmware, workloads, models, rules, configurations, runtime-assurance policies, and selective-uplink policies.
- Maintain a fleet inventory covering hardware class, site, owner, active version, approved version, trust state, resource envelope, and rollback readiness.
- Use signed updates, secure boot, attestation, credential rotation, SBOMs, workload provenance, and least-privilege local authority where appropriate.
- Monitor connectivity, local latency, CPU, memory, storage, thermal state, queue depth, buffer backlog, replay lag, workload health, version skew, trust state, watchdog resets, and local action traces.
- Test cloud outage, gateway failure, buffer pressure, duplicate replay, stale data, failed update, rollback, clock drift, watchdog reset, and trust verification.
- Confirm that bandwidth reduction does not destroy evidence needed for debugging, incident review, privacy governance, or audit.
- Make local edge behavior useful to operators without making local transformation invisible to engineers.
This checklist is intentionally practical. Edge computing becomes trustworthy when engineers can explain what runs where, why it runs there, what happens during disconnection, what data move upstream, what remains local, what decisions are authorized locally, what runtime-assurance boundaries apply, and how the fleet can be updated, rolled back, and audited.
GitHub Repository
This article is supported by a companion workflow that models edge computing architecture using topology manifests, workload placement matrices, latency and bandwidth budgets, offline mode policies, runtime-assurance policies, data-locality rules, trust-boundary manifests, fleet inventory schemas, deployment and rollback plans, telemetry schemas, incident reconstruction policies, and multi-language engineering examples.
Where This Fits in the Series
This article provides the architectural foundation for the broader Embedded and Edge Systems series. It connects directly to Gateways, Aggregation Layers, and Distributed Edge Infrastructure, Edge Analytics and Local Data Processing, Edge AI and On-Device Machine Learning, and Cloud-Edge Coordination and Hybrid Architectures, where specific edge responsibilities become more specialized.
It also supports articles on Internet of Things Sensor Architectures, Data Acquisition and Embedded Sensor Interfaces, Privacy and Local Data Processing at the Edge, and Security in Embedded and Edge Systems Architecture, where locality, trust, telemetry, and lifecycle governance shape how physical systems become distributed computational systems.
Related articles
- Embedded and Edge Systems: Real-Time Computing in Devices, Sensors, and Infrastructure
- Distributed Monitoring Systems
- Internet of Things Sensor Architectures
- Environmental Sensor Networks
- Data Acquisition and Embedded Sensor Interfaces
- Reliability and Fault Tolerance in Embedded Devices
- Edge Analytics and Local Data Processing
- Edge AI and On-Device Machine Learning
Further reading
- ETSI (2025) GS MEC 003 V4.1.1: Multi-access Edge Computing (MEC); Framework and Reference Architecture. Available at: https://www.etsi.org/deliver/etsi_gs/mec/001_099/003/04.01.01_60/gs_mec003v040101p.pdf
- LF Edge (2020) Overview of the LF Edge Taxonomy and Framework. Available at: https://lfedge.org/wp-content/uploads/sites/24/2020/07/LFedge_Whitepaper.pdf
- IETF (2024) RFC 9556: Internet of Things (IoT) Edge Challenges and Functions. Available at: https://datatracker.ietf.org/doc/html/rfc9556
- NIST (2022) Hardware-Enabled Security: Enabling a Layered Approach to Platform Security for Cloud and Edge Computing Use Cases. Available at: https://nvlpubs.nist.gov/nistpubs/ir/2022/Nist.IR.8320.pdf
- AWS (n.d.) AWS IoT Greengrass. Available at: https://docs.aws.amazon.com/greengrass/v2/developerguide/what-is-iot-greengrass.html
- Microsoft (2026) Azure IoT Edge documentation. Available at: https://learn.microsoft.com/en-us/azure/iot-edge/
- NIST (2022) Edge AI. Available at: https://www.nist.gov/programs-projects/edge-ai
References
- AWS (n.d.) AWS IoT Greengrass. Available at: https://docs.aws.amazon.com/greengrass/v2/developerguide/what-is-iot-greengrass.html
- AWS (n.d.) IoT Edge computing – AWS Well-Architected IoT Lens. Available at: https://docs.aws.amazon.com/wellarchitected/latest/iot-lens/iot-edge-computing.html
- ETSI (n.d.) Multi-access Edge Computing (MEC). Available at: https://www.etsi.org/technologies/multi-access-edge-computing
- ETSI (2025) GS MEC 003 V4.1.1: Multi-access Edge Computing (MEC); Framework and Reference Architecture. Available at: https://www.etsi.org/deliver/etsi_gs/mec/001_099/003/04.01.01_60/gs_mec003v040101p.pdf
- IETF (2024) RFC 9556: Internet of Things (IoT) Edge Challenges and Functions. Available at: https://datatracker.ietf.org/doc/html/rfc9556
- LF Edge (n.d.) What is LF Edge?. Available at: https://lfedge.org/
- LF Edge (2020) Overview of the LF Edge Taxonomy and Framework. Available at: https://lfedge.org/wp-content/uploads/sites/24/2020/07/LFedge_Whitepaper.pdf
- Microsoft (2026) Azure IoT Edge documentation. Available at: https://learn.microsoft.com/en-us/azure/iot-edge/
- NIST (2022) Edge AI. Available at: https://www.nist.gov/programs-projects/edge-ai
- NIST (2022) Hardware-Enabled Security: Enabling a Layered Approach to Platform Security for Cloud and Edge Computing Use Cases. NIST IR 8320. Available at: https://nvlpubs.nist.gov/nistpubs/ir/2022/NIST.IR.8320.pdf
- Shi, W., Cao, J., Zhang, Q., Li, Y. and Xu, L. (2016) ‘Edge Computing: Vision and Challenges’, IEEE Internet of Things Journal, 3(5), pp. 637–646.