
Last Updated May 11, 2026
Cloud-edge coordination and hybrid architectures examine how embedded, edge, and cloud systems divide computation, storage, control, inference, synchronization, policy, and operational authority across distributed layers. In embedded and edge systems, hybrid architecture is not merely a compromise between “local” and “remote.” It is the engineering discipline of assigning responsibility to the layer that can sustain it best while preserving responsiveness, resilience, observability, security, lifecycle control, and system-wide coherence.
Many embedded and edge systems fail conceptually because they are framed as a forced choice: either process everything locally or send everything to the cloud. Real systems rarely work that way. Devices and local nodes often need immediate responsiveness, partial autonomy, local safety behavior, privacy-aware handling, and continuity under disconnection, while cloud platforms remain valuable for fleet-wide visibility, long-horizon storage, centralized policy, model training, coordinated rollout, and cross-site comparison.
The deeper architectural question is therefore not whether a system is “cloud” or “edge.” It is how the layers coordinate: what is decided locally, what is synchronized upward, what remains authoritative centrally, what can continue during disconnection, what must fail closed, and how the system reconciles state when local and central views temporarily diverge. Strong hybrid systems are those in which local autonomy and central coordination reinforce one another rather than competing for control.
Main Library
Publications
Article Map
Embedded & Edge Systems
Related Topic
Edge Computing
Related Topic
Gateways & Aggregation
Related Topic
Edge AI
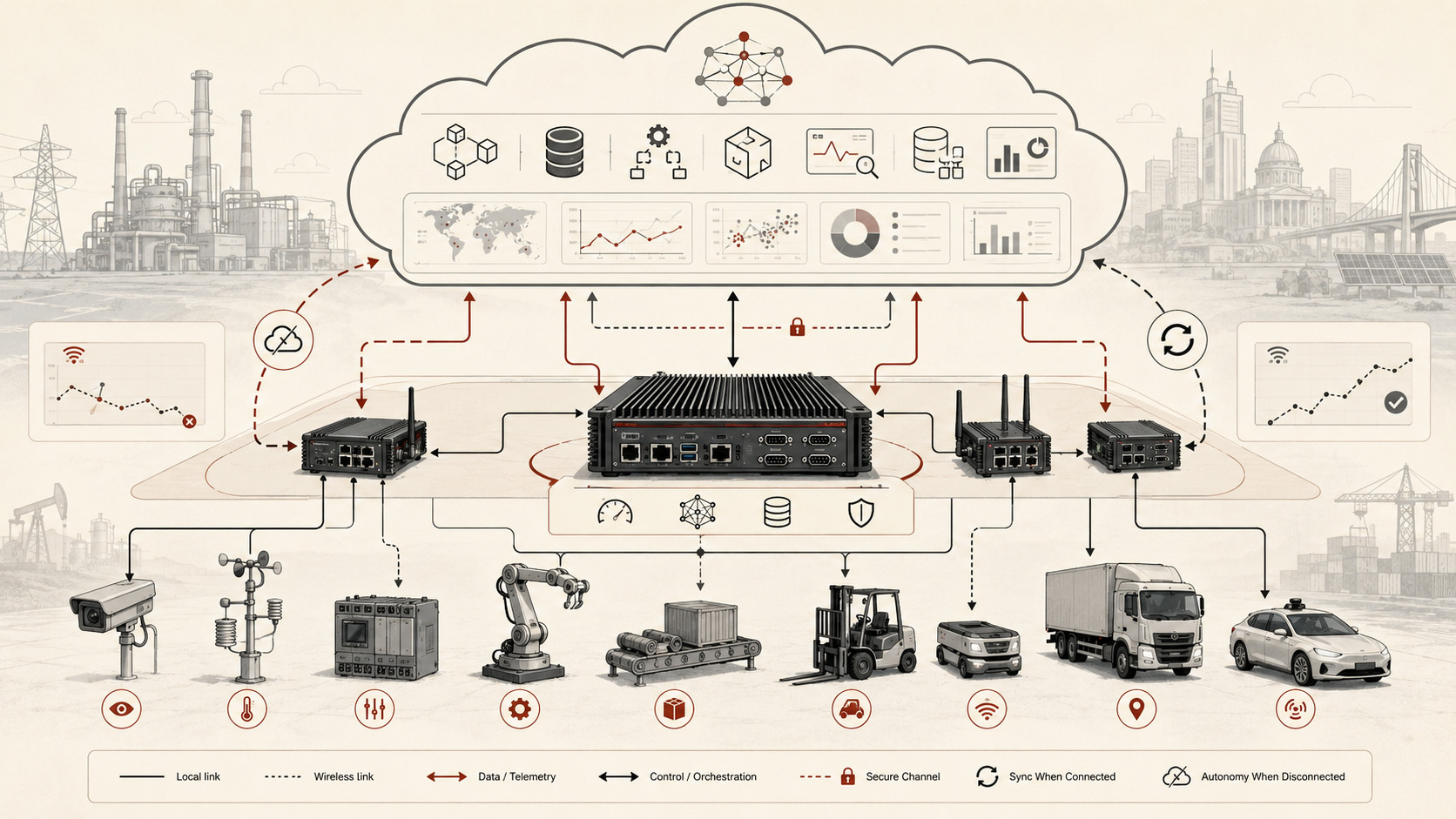
For engineers, hybrid architecture should be treated as a distributed responsibility model. The edge is not merely a smaller cloud, and the cloud is not merely a remote dashboard. Each layer has different timing, storage, security, privacy, lifecycle, compute, and authority characteristics. The strongest systems make these differences explicit through placement rules, synchronization contracts, degraded-mode policies, conflict-resolution rules, rollout controls, telemetry schemas, model lifecycle records, and operational evidence.
Engineering Problem
The engineering problem is how to coordinate distributed responsibility across local devices, gateways, site-edge systems, regional infrastructure, and cloud services without losing timing meaning, operational authority, security boundaries, or state coherence. A hybrid system must decide which layer should sense, preprocess, infer, store, buffer, synchronize, alert, control, retrain, update, and govern.
This is not a simple deployment question. Workload placement affects latency, bandwidth, privacy, fault tolerance, lifecycle management, cost, observability, and safety behavior. A function that works well in the cloud may be too slow or too disconnected for field action. A function that works well at the edge may be too opaque, inconsistent, or difficult to govern at fleet scale. A local model may support fast inference, but a central platform may be required to monitor drift, compare performance across sites, coordinate rollout, and preserve audit evidence.
Hybrid systems become fragile when responsibility boundaries are implicit. A local edge node may continue to act under an outdated policy. A cloud dashboard may merge stale local state with fresh central assumptions. A model update may reach some gateways but not others. A device may buffer events during disconnection without preserving enough lineage for later reconciliation. A security policy may assume continuous cloud reachability even when field devices must remain useful offline.
The practical question is therefore: can the architecture assign, synchronize, govern, and observe responsibilities across cloud and edge layers while preserving local continuity, central coherence, and recoverable evidence when the layers temporarily diverge?
Reference Architecture
A practical cloud-edge hybrid architecture can be understood as a layered coordination stack. The exact implementation may involve industrial gateways, cloud IoT services, Kubernetes-based edge clusters, message brokers, local databases, model runtimes, telemetry pipelines, device-management systems, or field-specific control systems, but the core architecture follows a common pattern.
| Layer | Engineering Role | Hybrid Concern | Evidence Artifact |
|---|---|---|---|
| Device layer | Senses, actuates, collects local measurements, executes firmware-level behavior | Real-time constraints, local safety, power, memory, connectivity limits | Device manifest, firmware version, telemetry schema |
| Gateway layer | Aggregates devices, translates protocols, buffers telemetry, hosts local rules | Protocol mediation, local resilience, selective uplink, site continuity | Gateway profile, buffer policy, protocol map |
| Site-edge layer | Runs local analytics, inference, coordination, dashboards, and operational logic | Local autonomy, policy enforcement, disconnection tolerance, site observability | Edge workload manifest, local policy record, sync log |
| Regional or intermediate edge | Aggregates multiple sites, provides lower-latency coordination than central cloud | Regional failover, partial centralization, multi-site state, latency reduction | Regional placement policy, replication log, failover record |
| Cloud control plane | Coordinates fleet policy, configuration, identity, updates, model lifecycle, and observability | Central governance, rollout discipline, fleet visibility, lifecycle evidence | Policy version, deployment manifest, audit log |
| Cloud data plane | Stores, processes, and analyzes cross-site telemetry and historical records | Long-horizon storage, analytics, benchmarking, cost, retention, data governance | Data retention policy, lineage record, aggregation schema |
| Model lifecycle layer | Trains, evaluates, deploys, monitors, and rolls back models | Model drift, version skew, edge inference authority, cloud governance | Model card, evaluation report, rollout record, drift log |
| Synchronization layer | Moves state, policy, configuration, telemetry, and updates among layers | Staleness, conflict, retries, eventual consistency, reconciliation | Sync manifest, reconciliation log, message age metrics |
| Security and trust layer | Manages identity, credentials, attestation, encryption, and trust boundaries | Credential rotation, offline trust, update integrity, compromised node containment | Trust policy, attestation record, key rotation log |
| Monitoring and recovery layer | Observes health, detects divergence, supports degraded modes and recovery | Connectivity loss, partial rollout, state drift, policy skew, incident reconstruction | Hybrid health report, incident timeline, recovery record |
This architecture makes hybrid coordination inspectable. It separates local operational authority from central governance, immediate control from long-horizon analytics, edge inference from cloud model lifecycle, and local state from synchronized system state. Without those distinctions, cloud-edge systems can appear connected while quietly drifting out of operational coherence.
Implementation Pattern
A rigorous hybrid implementation begins by defining what each layer owns. Engineers should specify which functions execute on-device, at the gateway, at the site edge, in a regional layer, or in the cloud; which layer is authoritative for each state; how long local autonomy remains valid; what must be synchronized; what may be buffered; what must fail closed; and how conflicts are reconciled.
| Artifact | Purpose | Typical Format |
|---|---|---|
| Layer responsibility matrix | Defines which functions belong to device, gateway, site edge, regional edge, or cloud | CSV, YAML, architecture decision record |
| Authority policy | Defines which layer can make which decisions and for how long | YAML, policy-as-code, governance record |
| Workload placement manifest | Defines where analytics, inference, buffering, synchronization, and control functions run | YAML, Helm values, deployment manifest |
| Synchronization contract | Defines message direction, cadence, freshness, retention, conflict behavior, and retry logic | JSON Schema, YAML, Protobuf, event contract |
| State lineage record | Tracks acquisition time, local decision time, sync time, cloud ingestion time, and version | SQL, event schema, JSONL, telemetry log |
| Conflict-resolution policy | Defines how state disagreement, version skew, and partial updates are resolved | YAML, runbook, reconciliation contract |
| Degraded-mode policy | Defines behavior under cloud outage, edge outage, stale policy, partial rollout, or local failure | YAML, runbook, state-machine manifest |
| Selective uplink policy | Defines what data stay local, what is aggregated, what is redacted, and what is transmitted | YAML, data-governance policy, pipeline config |
| Model lifecycle manifest | Defines model version, deployment scope, rollback policy, local inference authority, and monitoring | Model card, JSON, YAML, registry metadata |
| Hybrid telemetry schema | Defines what the system logs about state, policy, sync, divergence, connectivity, and recovery | SQL, JSON Schema, CSV, event stream schema |
The implementation goal is to make hybrid behavior testable. Engineers should be able to reconstruct what an edge node knew, which policy version it used, whether the cloud was reachable, how old the local state was, what decision was made locally, what was later synchronized, whether reconciliation changed the cloud view, and whether central governance remained intact.
Formal Model: Workload Placement, Authority, Synchronization, and Staleness
A useful formal model separates local edge state from cloud state and makes synchronization delay explicit. Let \(x_{e,t}\) represent edge-local state at time \(t\), \(x_{c,t}\) represent cloud-side state, and \(p_t\) represent the policy or configuration version available to the edge.
x_{e,t+1} = f_e(x_{e,t}, z_t, p_{e,t}, a_t)
\]
Interpretation: Edge state evolves from prior edge state, local observations \(z_t\), local policy \(p_{e,t}\), and local action \(a_t\). The edge can continue operating even when the cloud view is delayed or unavailable.
x_{c,t+1} = f_c(x_{c,t}, S(x_{e,t-\tau}), p_{c,t})
\]
Interpretation: Cloud state evolves from prior cloud state, synchronized edge information \(S(x_{e,t-\tau})\), and cloud policy \(p_{c,t}\). The delay \(\tau\) represents synchronization lag.
a_t \in A_{\mathrm{local}}(p_{e,t}, h_t, \Delta t_{\mathrm{offline}})
\]
Interpretation: Local actions must remain inside an authority window defined by edge policy, local health \(h_t\), and time since reliable cloud coordination. Local autonomy should not be unbounded.
d_t = D(x_{e,t}, x_{c,t}, p_{e,t}, p_{c,t}, m_{e,t}, m_{c,t})
\]
Interpretation: Divergence \(d_t\) measures the gap between edge state, cloud state, edge policy, cloud policy, edge model version, and cloud-approved model version. Hybrid systems should measure divergence rather than assuming synchronization is always coherent.
This formal structure matters because it prevents hybrid architecture from pretending that cloud and edge layers always share one state. They often do not. Strong systems preserve enough timing, lineage, version, and authority information to compare states honestly and reconcile them safely.
What Are Cloud-Edge Coordination and Hybrid Architectures?
Cloud-edge coordination refers to the structured interaction between local edge systems and upstream cloud platforms. Hybrid architectures are systems in which both layers remain essential: local layers provide responsiveness, continuity, privacy-aware processing, bandwidth reduction, and site-level autonomy, while cloud layers provide centralized management, fleet-scale analytics, long-term storage, model lifecycle governance, policy coordination, and cross-site learning.
What makes hybrid architecture distinct from simple distribution is that the relationship between layers must be designed explicitly. A local edge node is not merely a disconnected mini-cloud, and a cloud service is not merely a passive collector of edge outputs. Each layer carries different timing assumptions, governance burdens, authority boundaries, and responsibilities over system state.
In strong systems, the cloud and the edge are linked by clear contracts: what data are exchanged, what policies flow downward, what telemetry flows upward, which states are authoritative locally, which states are authoritative centrally, and how conflicts are resolved when conditions change. Without those contracts, hybrid systems become either over-centralized, operationally fragmented, or difficult to govern.
The Cloud-Edge Continuum and Responsibility Boundaries
Cloud-edge coordination is easiest to understand through the idea of a continuum. In practice, there are often several intermediate layers between a field device and a central cloud platform: device, gateway, site edge, regional edge, and cloud. Each layer has different proximity to physical events, different compute and storage capacity, different trust assumptions, and different tolerance for latency or disconnection.
This continuum matters because responsibility boundaries often align with intermediate layers rather than with one grand divide. Devices may sense and act. Gateways may translate protocols and buffer data. Site-level nodes may aggregate, host local analytics, enforce local policy, or run inference. Regional layers may coordinate multiple sites with lower latency than central cloud. Cloud platforms may coordinate models, policies, fleet metrics, identity, long-horizon storage, and cross-site state.
The architectural challenge is not to eliminate layers, but to assign each layer only the functions it can sustain well. Too much centralization makes the field brittle. Too much local autonomy can make the wider system opaque or inconsistent. Strong architectures make responsibility boundaries explicit so that functions do not blur under operational stress.
Workload Placement and Hybrid Function Allocation
The core question in hybrid architecture is workload placement: which functions belong on-device, at the gateway, at the local edge, in a regional layer, or in the cloud. Good placement decisions depend on latency sensitivity, bandwidth intensity, disconnection tolerance, privacy and trust constraints, lifecycle burden, compute demand, and the scale at which the function creates value.
| Function | Usually Edge-Appropriate When… | Usually Cloud-Appropriate When… |
|---|---|---|
| Immediate control | Physical timing, safety, or operational continuity requires local action | Control is advisory, slow-moving, or centrally coordinated |
| Sensor preprocessing | Raw data are high-volume, noisy, local, or privacy-sensitive | Raw data are needed for central analysis or regulatory retention |
| Inference | Latency, bandwidth, privacy, or offline operation matter | Large models, cross-site context, or central governance dominate |
| Model training | Local adaptation is tightly bounded and evidence-rich | Fleet-scale data, benchmarking, governance, and evaluation are required |
| Policy enforcement | Rules must continue during disconnection | Policy coordination, versioning, approval, and audit matter most |
| Long-horizon storage | Connectivity is intermittent and local buffering is necessary | Retention, analytics, search, compliance, and fleet comparison are required |
| Alerting | Local operators need immediate notification or action | Fleet-level escalation, ticketing, and cross-site response matter |
| Software updates | Staged rollout and local validation must protect continuity | Version governance, signatures, approval, and rollback coordination are central |
A weak architecture treats placement as a deployment detail. A strong one treats it as a system decision about where meaning, action, and coordination should live. The right placement is rarely permanent; it may change as connectivity, model size, security requirements, cost, or operational maturity change.
Authority, Control, and Decision Ownership
Hybrid architectures require a clear theory of authority. Which layer is allowed to make which decisions? What must be approved centrally? What remains locally authoritative when the cloud is unavailable? What local action must be logged for later review? These are not implementation details. They determine whether the system behaves predictably during stress, outage, conflict, or partial rollout.
Some decisions are naturally local: a safety-relevant threshold crossing, a local fail-safe, an immediate control adjustment, a buffering decision, or an anomaly classification that cannot wait for remote review. Others are naturally central: fleet-wide policy changes, coordinated model rollout, cross-site optimization, access governance, long-range benchmarking, and global configuration.
Problems arise when two layers appear to own the same decision. If an edge node believes it has authority to continue using an old policy, while the cloud believes the policy has been revoked, the architecture must define which interpretation prevails under which conditions. If an AI model is updated centrally but only partially deployed to the edge, the system must distinguish version skew from normal operation.
| Decision Type | Preferred Authority | Required Control |
|---|---|---|
| Immediate local safety response | Device, gateway, or site edge | Bounded local policy, fail-safe behavior, evidence logging |
| Fleet-wide policy update | Cloud control plane | Approval workflow, signed policy, staged rollout, rollback |
| Local anomaly classification | Edge runtime | Model version logging, confidence thresholds, fallback behavior |
| Model promotion to production | Cloud lifecycle governance | Evaluation evidence, approval, deployment ring, monitoring |
| Offline continuation | Edge within authority window | TTL, degraded mode, restricted action set, recovery sync |
| Cross-site optimization | Cloud or regional edge | Freshness checks, state lineage, consistency assumptions |
Good hybrid design separates local autonomy from central governance. Local systems may act within defined authority windows, while cloud systems retain broader coordination authority over fleet-wide behavior. The stronger the local authority, the more important observability, policy lineage, and reconciliation become.
Consistency Models, Conflict Resolution, and State Reconciliation
Hybrid systems should define their consistency model explicitly. Some data require strong coordination before action. Other data can tolerate eventual consistency. Some state can be merged automatically. Other state conflicts require human review because local context, safety, or policy authority matters.
This distinction is essential because hybrid systems often continue operating under partial connectivity. A site may make local decisions while the cloud is unavailable. A cloud platform may approve a new policy while some edge nodes remain disconnected. A gateway may buffer events and replay them later. A model may be rolled out to one ring while another ring remains on the previous version. These are normal hybrid conditions, not exceptional anomalies.
| State Type | Consistency Requirement | Conflict-Resolution Pattern | Why It Matters |
|---|---|---|---|
| Safety state | Conservative local truth dominates | Preserve local safe-stop or fault event; cloud cannot silently clear | Prevents central dashboards from hiding local safety behavior |
| Telemetry summary | Eventual consistency acceptable | Replay with acquisition time and ingestion time | Allows buffering without pretending delayed data are current |
| Policy version | Cloud-approved version is authoritative, but local TTL governs offline use | Flag drift; restrict local action after authority window expires | Prevents indefinite local use of stale policy |
| Model version | Approved model registry is authoritative | Track rollout ring, edge version, approved version, rollback status | Prevents silent model skew across the fleet |
| Local decision record | Append-only evidence | Do not overwrite; reconcile by adding cloud interpretation | Preserves audit trail and incident reconstruction |
| Configuration update | Versioned and signed | Reject unsigned or out-of-order updates; rollback if validation fails | Protects lifecycle governance and security |
Conflict resolution should not be hidden inside ad hoc merge logic. A mature hybrid architecture treats reconciliation as a first-class process with policy, logs, reason codes, and review pathways. The goal is not to eliminate all divergence; the goal is to detect, bound, and resolve divergence without losing evidence.
Synchronization, State Lineage, and Timing
Hybrid systems are fundamentally synchronization systems. Data, policies, configuration, derived state, event summaries, software packages, and learned model artifacts must move between layers without destroying timing meaning. A cloud system may receive delayed state from the edge, and an edge node may continue acting on policies synchronized earlier but no longer current upstream.
This makes state lineage a design concern. Systems should distinguish acquisition time, local decision time, edge persistence time, synchronization time, cloud ingestion time, and cloud interpretation time where those differences matter. Without that, hybrid systems can appear coherent while quietly merging stale local states with fresh upstream assumptions.
A_{\mathrm{state}} = t_{\mathrm{cloud\ ingest}} – t_{\mathrm{local\ acquisition}}
\]
Interpretation: State age measures how old local information is when it reaches the cloud. Hybrid systems should track this explicitly rather than treating all ingested data as equally current.
Reconciliation is not only a data-engineering problem. It is an authority problem. If the cloud and edge disagree, the system must know whether to preserve local action, overwrite local state, merge partial records, open an incident, hold deployment, or request human review. Strong architectures preserve enough timing and lineage information that cloud and edge states can be compared honestly rather than merely merged optimistically.
Disconnection, Degraded Modes, and Local Continuity
Hybrid systems are only meaningful if they specify how the edge behaves when the cloud is unavailable, delayed, degraded, or unreachable. This is one of the strongest reasons hybrid design exists at all. If every meaningful function requires continuous cloud reachability, the edge layer is mostly a relay. If the edge continues indefinitely without central governance, the cloud layer loses authority.
Degraded modes should therefore be treated as normal design states, not as exceptions. What continues locally? What is buffered? What actions are prohibited without cloud reachability? What policy remains valid? What state is later reconciled? What must fail closed, and what may continue under local policy? These are core architectural questions because systems often reveal their true structure only under degraded conditions.
| Condition | Local Behavior | Cloud Behavior | Recovery Requirement |
|---|---|---|---|
| Short cloud outage | Continue local operation within authority window | Mark site as delayed or partially unavailable | Replay buffered telemetry with timestamps and lineage |
| Long cloud outage | Restrict authority, reduce nonessential actions, preserve safety behavior | Escalate incident and block dependent rollouts | Reconcile policy, state, model versions, and event gaps |
| Stale local policy | Continue only if within policy validity window | Flag version skew and push update when available | Record which decisions used stale policy |
| Partial deployment | Run assigned version and report version identity | Track rollout completeness and block unsafe comparisons | Confirm version convergence or rollback |
| Local node failure | Fail over to gateway/site policy if available | Mark node unhealthy and preserve last known state | Recover with identity, configuration, and data integrity checks |
Good hybrid architectures preserve local usefulness without pretending that local operation and cloud-backed operation are equivalent states. Disconnected operation should be bounded, visible, and recoverable.
Data Movement, Selective Uplink, and Information Governance
Hybrid architectures rarely move all data equally. Some information remains local because it is too sensitive, too high-volume, too transient, or too operationally immediate to justify immediate cloud transport. Other information moves upward because it supports fleet-scale visibility, retrospective analysis, compliance, model improvement, or long-range optimization.
This makes selective uplink a governance problem as much as a bandwidth problem. The system should define what stays local, what is aggregated, what is filtered, what is redacted, what is sampled, what is compressed, and what qualifies as the cloud-facing representation of local conditions.
Good hybrid design preserves both efficiency and interpretability. Local processing should reduce transport burden without destroying the cloud layer’s ability to understand what the edge actually saw and did. A cloud summary that says “anomaly detected” is much less useful if it does not preserve model version, sensor context, time window, confidence, local policy, and whether raw evidence remains available locally for investigation.
Information governance should also account for retention asymmetry. Raw high-frequency data may be retained locally for only a short period, while summaries and incidents are retained centrally for longer horizons. Those choices should be explicit because they determine what can be reconstructed after an incident, audit, model-drift investigation, or operational dispute.
Cloud Control Planes and Edge Operational Planes
Hybrid architectures usually split operations into at least two planes. The cloud often provides the control plane: fleet visibility, identity, policy distribution, configuration management, model lifecycle, global dashboards, alerting integration, version governance, and audit records. The edge provides the operational plane: direct interaction with devices, low-latency rules, buffering, site-level coordination, and partial autonomy.
This split is useful because it preserves central manageability without forcing all operational meaning to be created centrally. Coordination flows downward, state flows upward, and local operations remain legible within the wider architecture. A mature hybrid system therefore does not confuse “centrally managed” with “centrally executed.”
Control-plane discipline is especially important for lifecycle management. A cloud system may approve a policy, but a gateway must receive it, validate it, store it, expose it to local runtime, report its version, and eventually prove whether it was used for a particular decision. Without that evidence chain, central governance may be more aspirational than real.
Edge operational planes need similar discipline. Local dashboards, logs, buffering, safety behavior, and site-level decisions should not become unmanaged side systems. They should remain visible enough that central operations can understand the edge without requiring every raw event to be uploaded immediately.
Rollout Rings, Version Governance, and Lifecycle Coordination
Hybrid systems need disciplined rollout mechanisms because software, configuration, policy, and model updates do not arrive everywhere at once. A cloud control plane may approve a change, but the actual fleet may pass through several intermediate states: staged rollout, partial deployment, validation failure, rollback, local hold, disconnected node, and eventual convergence.
Rollout rings make these states explicit. Early rings receive updates first, canary sites validate behavior, production rings follow only after evidence is acceptable, and disconnected or unhealthy nodes are held back. This is especially important for edge AI models, local safety policies, gateway runtime updates, and device firmware because a flawed update can affect physical systems, field operations, or local autonomy.
| Rollout Stage | Purpose | Required Evidence |
|---|---|---|
| Development or lab ring | Validate package, manifest, schema, and deployment mechanics | Unit tests, simulation output, manifest validation |
| Canary edge node | Expose update to limited field conditions | Health metrics, local logs, rollback readiness |
| Site pilot | Validate against site-level operations and gateway behavior | Sync lag, buffer behavior, local decision evidence |
| Regional ring | Expand across similar sites while monitoring variation | Drift metrics, policy skew, model skew, incident rate |
| Fleet rollout | Deploy broadly after evidence thresholds are met | Version convergence, failure rate, rollback status |
| Post-rollout monitoring | Confirm long-run stability and lifecycle evidence | Health trend, anomaly trend, state divergence, support tickets |
Version governance should treat the approved version, deployed version, active version, and decision-used version as separate signals. A gateway may have downloaded a model but not activated it. A policy may be active but not yet used for a decision. A device may report a firmware version but be running in degraded mode. These distinctions matter for auditability, safety, and incident reconstruction.
Security, Trust, and Hybrid Risk Surfaces
Hybrid architectures expand both capability and attack surface. They create multiple trust boundaries across devices, local runtimes, gateways, networks, intermediate services, cloud platforms, update channels, model registries, and administrative systems. Each boundary creates both functionality and risk.
The central security problem is not only protecting the cloud or hardening devices individually. It is preserving trustworthy coordination across layers. Model updates, credential distribution, configuration synchronization, policy propagation, local attestations, telemetry uploads, rollback commands, and cloud-mediated identity relationships all become security-sensitive.
| Trust Boundary | Risk | Control Pattern |
|---|---|---|
| Device to gateway | Rogue device, spoofed telemetry, weak identity, protocol abuse | Device identity, mutual authentication, protocol validation |
| Gateway to cloud | Credential theft, replay, unauthorized command, telemetry tampering | Credential rotation, signed messages, encrypted channels, replay protection |
| Cloud to edge policy | Malicious or accidental policy rollout | Signed policy bundles, staged rollout, approval workflow, rollback |
| Model registry to edge runtime | Model substitution, version skew, unvalidated model behavior | Model signatures, version pinning, deployment manifest, monitoring |
| Offline edge authority | Local system continues acting under invalid or compromised assumptions | Authority expiration, safe fallback, local attestation, incident flagging |
Strong hybrid architectures make trust boundaries explicit. They identify what is trusted locally, what is verified centrally, how authority is established across layers, how offline operation is bounded, and how the system behaves when one layer can no longer validate another cleanly.
Hybrid AI, Monitoring, and Model Lifecycle Coordination
Hybrid architecture becomes especially important once AI is introduced. Local edge nodes may run inference for low latency, privacy, bandwidth reduction, or offline continuity, while the cloud remains responsible for model training, evaluation, benchmarking, rollout orchestration, drift monitoring, incident review, and post-deployment governance.
This split can be powerful, but it introduces new coordination problems. A model may behave differently across sites because sensor placement, local environment, device hardware, data distributions, or operational practices differ. Telemetry may arrive late or incompletely. Some gateways may run a newer model while others remain on an older version. Local inference may be fast, but central monitoring may have delayed visibility into failure patterns.
Good hybrid AI architectures therefore separate local inference authority from cloud lifecycle governance. The edge may act quickly, but the cloud remains essential for broader evaluation, coordinated updates, rollback, and systemic oversight. A hybrid AI system should log model version, input context, inference time, confidence, local decision, fallback behavior, and post-deployment monitoring signals.
For embedded and edge systems, AI does not remove the need for hybrid architecture discipline. It increases it. Once local inference shapes physical or operational decisions, model lifecycle coordination becomes part of infrastructure governance.
Worked Example: Hybrid Edge-AI Gateway for Industrial Monitoring
Consider an industrial monitoring system that uses local sensors, an edge gateway, and a cloud platform. The device layer collects vibration, temperature, current, and acoustic readings. The gateway performs local filtering and anomaly inference. The cloud stores summaries, compares sites, retrains models, approves model rollouts, and coordinates fleet-level policy.
| Step | Hybrid Behavior | Engineering Evidence |
|---|---|---|
| Local acquisition | Sensors collect high-frequency signals near the equipment | Acquisition time, sensor ID, calibration status, raw-data retention policy |
| Edge preprocessing | Gateway filters, windows, and summarizes local data | Feature version, preprocessing config, local timestamp |
| Edge inference | Local model detects anomaly without waiting for cloud response | Model version, confidence, decision time, local policy version |
| Authority check | Gateway verifies whether local action is allowed under current authority window | Cloud reachability, offline duration, authority TTL, degraded-mode state |
| Selective uplink | Gateway uploads summary, anomaly evidence, and lineage while retaining raw data locally | Sync time, cloud ingestion time, state age, raw-data availability flag |
| Cloud monitoring | Cloud compares anomalies across sites and watches model drift | Fleet dashboard, drift metrics, model performance report |
| Model update | Cloud approves a new model and deploys it through rollout rings | Model card, signed artifact, rollout ring, active version |
| Reconciliation | Buffered events are replayed after connectivity loss | Conflict status, reconciliation result, incident timeline |
This example shows why hybrid architecture is not just connectivity. If the gateway detects an anomaly while offline, it may need to alert locally, buffer evidence, preserve raw data for a limited time, and later synchronize enough context for the cloud to interpret the event. If the cloud has approved a newer model but the gateway has not yet received it, the system must log the version skew rather than hiding it. If the gateway continues offline beyond its authority window, the system should restrict local behavior or enter a degraded mode.
The architecture succeeds only if local usefulness and central governance remain mutually intelligible. The edge must be able to act, but the cloud must later be able to understand what happened, why, under which policy, using which model, and with what evidence.
Data and Configuration Artifacts
Hybrid systems become easier to build, test, and maintain when their coordination assumptions are represented as data and configuration artifacts. Engineers should be able to inspect layer responsibilities, policy versions, synchronization rules, authority windows, degraded-mode behavior, selective uplink rules, model deployments, and reconciliation decisions without relying on undocumented architecture diagrams or tribal memory.
| Artifact | What It Captures | Engineering Purpose |
|---|---|---|
layer_responsibility_matrix.yml |
Which functions belong to device, gateway, site edge, regional edge, and cloud | Makes responsibility boundaries explicit |
authority_policy.yml |
Local authority windows, cloud authority, approval rules, fail-closed conditions | Prevents unclear decision ownership |
workload_placement.yml |
Where analytics, inference, buffering, control, and storage functions run | Connects architectural intent to deployment |
synchronization_contract.yml |
Cadence, direction, freshness, retry, conflict, and reconciliation rules | Makes synchronization behavior testable |
state_lineage_schema.sql |
Acquisition time, local decision time, sync time, cloud ingestion time, policy version | Preserves timing meaning across layers |
conflict_resolution_policy.yml |
How safety state, telemetry, policy, model, and configuration conflicts are resolved | Prevents silent overwrite of meaningful divergence |
degraded_mode_policy.yml |
Cloud outage, stale policy, local failure, partial rollout, and reconnection behavior | Turns disconnection into designed behavior |
rollout_policy.yml |
Canary, pilot, regional, fleet, rollback, and monitoring stages | Makes lifecycle change controlled and auditable |
selective_uplink_policy.yml |
What stays local, what is aggregated, what is redacted, and what is transmitted | Links bandwidth, privacy, and interpretability |
model_lifecycle_manifest.yml |
Model versions, rollout scope, evaluation state, rollback rules, monitoring signals | Coordinates edge inference with cloud governance |
hybrid_security_policy.yml |
Identity, credentials, attestation, signed updates, trust boundaries, offline authority | Protects coordination pathways |
hybrid_event_schema.sql |
Events for state sync, policy updates, connectivity, divergence, local decisions, recovery | Makes hybrid behavior queryable and auditable |
The goal is not to force a single hybrid platform. The goal is to make distributed responsibility inspectable. If coordination assumptions cannot be found in artifacts, they will be difficult to test, operate, secure, or recover after deployment.
Mathematical Lens: Placement Cost, State Age, Authority Windows, and Sync Drift
A practical mathematical lens for cloud-edge coordination begins with placement cost. A workload should run where the total cost of latency, bandwidth, privacy exposure, compute burden, lifecycle complexity, and governance risk is acceptable.
J(l) = \alpha L_l + \beta B_l + \gamma P_l + \delta C_l + \eta G_l
\]
Interpretation: \(J(l)\) is the placement cost for layer \(l\). \(L_l\) represents latency, \(B_l\) bandwidth cost, \(P_l\) privacy or exposure risk, \(C_l\) compute or operating cost, and \(G_l\) governance burden. The weights reflect system priorities.
A_{\mathrm{state}} = t_{\mathrm{cloud\ ingest}} – t_{\mathrm{local\ acquisition}}
\]
Interpretation: State age measures how old edge-originated information is when interpreted by the cloud. Fleet dashboards and reconciliation workflows should not treat stale state as current state.
\Delta p_t = p_{c,t} – p_{e,t}
\]
Interpretation: Policy drift \(\Delta p_t\) represents divergence between cloud policy and edge-local policy. Hybrid systems should detect and report version skew rather than hiding it.
\Delta t_{\mathrm{offline}} \leq T_{\mathrm{authority}}
\]
Interpretation: Offline local operation should remain within an authority window. After that window expires, the system may need to restrict actions, degrade behavior, or fail closed.
R_{\mathrm{converged}} = \frac{N_{\mathrm{target\ version}}}{N_{\mathrm{eligible\ nodes}}}
\]
Interpretation: Version convergence measures how much of the eligible fleet is actually running the intended policy, firmware, or model version. Approved does not mean deployed; deployed does not always mean active.
The key engineering point is that cloud-edge coordination should be measurable. State age, policy drift, model version skew, synchronization lag, buffer backlog, connectivity duration, offline authority time, and rollout convergence should be operational signals, not hidden assumptions.
Python Workflow: Cloud-Edge Placement, Synchronization, and Degraded-Mode Simulation
The companion Python workflow should model hybrid coordination across edge and cloud layers. It can simulate workload placement, local action during disconnection, buffered telemetry, synchronization lag, policy drift, model version skew, rollout convergence, and reconciliation after reconnection.
# Python Workflow: Cloud-Edge Placement, Synchronization, and Degraded-Mode Simulation
placement_score = (
alpha * latency_ms
+ beta * bandwidth_mb
+ gamma * privacy_risk
+ delta * compute_cost
+ eta * governance_burden
)
local_authorized = (
cloud_reachable
or offline_duration_s <= authority_window_s
)
if local_authorized:
local_decision = edge_policy.evaluate(local_state, model_version)
else:
local_decision = degraded_mode_policy.fallback(local_state)
sync_event = {
"acquisition_time": acquisition_time,
"local_decision_time": local_decision_time,
"sync_time": sync_time,
"cloud_ingest_time": cloud_ingest_time,
"policy_version_edge": edge_policy.version,
"policy_version_cloud": cloud_policy.version,
"model_version_edge": edge_model.version,
"approved_model_version": approved_model.version,
"reconciliation_status": reconciliation_status
}This workflow is useful because it makes hybrid assumptions executable. Engineers can test what happens when connectivity drops, state ages, local policies become stale, model versions diverge, buffers grow, cloud ingestion is delayed, rollout rings fail to converge, or reconciliation produces conflicts.
For production systems, the same workflow can be connected to logs from gateways, edge runtimes, cloud IoT services, streaming platforms, model registries, orchestration systems, and device-management services. The goal is not only simulation, but operational evidence that hybrid coordination is behaving as intended.
R Workflow: Hybrid Fleet Reliability and Synchronization Reporting
The companion R workflow should focus on reporting across devices, gateways, sites, policies, models, and synchronization events. It can summarize connectivity, buffer backlog, stale state, policy drift, model version skew, local decision counts, cloud reconciliation outcomes, rollout convergence, and degraded-mode frequency.
# R Workflow: Hybrid Fleet Reliability and Synchronization Reporting
hybrid_summary <- hybrid_events |>
dplyr::group_by(site_id, gateway_id, operating_mode) |>
dplyr::summarise(
events = dplyr::n(),
mean_state_age_s = mean(state_age_s, na.rm = TRUE),
max_sync_lag_s = max(sync_lag_s, na.rm = TRUE),
offline_event_rate = mean(cloud_reachable == FALSE, na.rm = TRUE),
degraded_mode_rate = mean(operating_mode == "degraded", na.rm = TRUE),
policy_drift_rate = mean(edge_policy_version != cloud_policy_version, na.rm = TRUE),
model_skew_rate = mean(edge_model_version != approved_model_version, na.rm = TRUE),
rollout_convergence_rate = mean(active_version == target_version, na.rm = TRUE),
reconciliation_conflicts = sum(reconciliation_status == "conflict", na.rm = TRUE),
.groups = "drop"
)This reporting layer helps distinguish isolated connectivity issues from systematic architecture problems. If one site has high policy drift, rollout coordination may be weak. If one gateway has persistent buffer backlog, bandwidth or uplink scheduling may be insufficient. If model skew is common, lifecycle governance may not match deployment reality. If local decisions continue long after authority windows expire, degraded-mode policy is too permissive.
For embedded and edge fleets, this kind of reporting is essential because hybrid failure often looks like ordinary latency, missing data, or partial observability until it is analyzed across sites and time.
Systems Code: Edge Runtimes, Gateways, MicroPython, TinyML, PYNQ, HDL, Bash, and Configuration
The companion repository should be useful to engineers because cloud-edge coordination crosses the full embedded, edge, and cloud-adjacent stack. It touches gateway services, local buffering, sync contracts, model manifests, telemetry schemas, policy validation, orchestration, device code, constrained inference, FPGA-backed preprocessing, and operational reporting.
| Folder | Engineering Role | Hybrid Use |
|---|---|---|
python/ |
Simulation and workflow automation | Placement scoring, sync lag, offline authority, reconciliation, policy drift |
r/ |
Reporting and descriptive analytics | Fleet reliability, synchronization, degraded-mode, policy/model skew reporting |
sql/ |
Queryable hybrid evidence | State lineage, sync events, local decisions, cloud ingestion, policy and model versions |
c/ |
Constrained device behavior | Local fallback, offline authority timer, telemetry packet formation |
cpp/ |
Gateway and edge runtime abstraction | Sync state machine, local policy enforcement, buffer management |
rust/ |
Safe systems validation | Policy-version checks, authority-window validation, sync contract validation |
go/ |
Operational services and telemetry utilities | Gateway sync service, event router, cloud-edge health API |
micropython/ |
Microcontroller prototypes | Local sensing, bounded offline behavior, buffered telemetry |
tinyml/ |
Constrained local inference | Local anomaly classification with model-version telemetry |
pynq/ |
FPGA-backed edge acceleration | Low-latency preprocessing before selective uplink |
hdl/ |
Hardware/software co-design | Stream timestamping, buffer watermarking, sync pulse, telemetry framing |
bash/ |
Repeatable workflow execution | Runs simulations, validates manifests, generates outputs and inventory |
config/ |
Machine-readable hybrid metadata | Layer responsibilities, authority policy, sync contracts, uplink policy, model lifecycle |
This stack matters because hybrid architecture is not created by cloud services alone. It is created by the way firmware, gateways, edge runtimes, policy systems, model registries, telemetry pipelines, and cloud platforms preserve a coherent division of responsibility.
Testing and Validation
Hybrid systems should be validated under the conditions that make hybrid architecture necessary: connectivity loss, delayed synchronization, local continuation, policy drift, partial rollout, stale telemetry, version skew, security-boundary failure, and recovery after reconnection.
A practical validation suite should answer these questions:
- Does each layer have a documented responsibility boundary?
- Can the edge continue useful operation during cloud disconnection without exceeding its authority window?
- Does local fallback behavior match degraded-mode policy?
- Are local decisions logged with policy version, model version, state age, and decision time?
- Can the cloud distinguish fresh state from stale state?
- Can buffered telemetry be replayed without losing acquisition time and lineage?
- Are policy updates, configuration changes, and model deployments versioned and auditable?
- Does the system detect policy drift and model version skew?
- Does reconciliation handle conflicts explicitly rather than silently overwriting state?
- Do rollout rings prevent unsafe fleet-wide changes?
- Are trust boundaries, credentials, signatures, and offline authority tested?
- Can the system recover after outage without double-counting events or hiding gaps?
Testing should include negative cases. Engineers should deliberately test cloud outage, gateway restart, partial deployment, stale policy, clock drift, message replay, model rollback, local buffer overflow, credential expiration, signed artifact rejection, rollout halt, and conflicting state reconciliation. Hybrid architectures fail most dangerously when they appear connected but are no longer coherent.
Operational Signals and Hybrid Observability
Hybrid observability is the ability to understand whether cloud and edge layers remain coordinated, not merely whether they are online. A gateway can be connected while running stale policy. A cloud dashboard can be populated with old state. A model can appear deployed while some edge nodes remain on earlier versions. A local node can continue acting long after its authority should have expired.
| Signal | What It Reveals | Why Engineers Need It |
|---|---|---|
| Cloud reachability | Whether the edge can communicate with the cloud control plane | Distinguishes normal operation from disconnected local continuity |
| Offline duration | How long local autonomy has continued without cloud coordination | Enforces authority windows and degraded modes |
| State age | How old edge-originated information is when interpreted centrally | Prevents stale state from appearing current |
| Sync lag | Delay between local event and cloud ingestion | Reveals synchronization bottlenecks |
| Buffer backlog | Unsent local events waiting for uplink | Identifies bandwidth, outage, or pipeline pressure |
| Policy version skew | Difference between cloud-approved and edge-local policy | Detects governance divergence |
| Model version skew | Difference between approved and deployed model versions | Supports safe AI lifecycle management |
| Rollout convergence | Whether eligible nodes are running the target active version | Distinguishes approval from actual deployment state |
| Local decision count | Number of decisions made without immediate cloud involvement | Shows how much authority the edge exercised |
| Reconciliation conflicts | Disagreements between local and cloud state | Prevents silent overwrite of meaningful divergence |
| Selective uplink rate | How much local information becomes cloud-visible | Connects bandwidth, privacy, and interpretability |
| Degraded-mode rate | How often the system enters limited local operation | Reveals resilience burden and field reliability |
| Recovery completeness | Whether state, policy, logs, and versions converged after outage | Supports incident review and operational trust |
Engineers should design these signals before deployment. If the system cannot reconstruct local decisions, policy versions, model versions, synchronization lag, state age, rollout state, and reconciliation outcomes, then hybrid behavior becomes difficult to govern.
Common Failure Modes
Cloud-edge systems fail in predictable ways because distributed layers do not automatically share one coherent state. Engineers should design architecture, tests, and observability around these failure modes from the beginning.
- Stale cloud state: the cloud interprets delayed edge data as current operational state.
- Stale edge policy: the edge continues acting under a policy that has changed upstream.
- Unbounded local autonomy: the edge continues decision-making beyond its valid authority window.
- Silent policy drift: cloud-approved and edge-local policies diverge without alerting.
- Model version skew: edge nodes run different model versions without clear lifecycle evidence.
- Rollout ambiguity: approved, deployed, active, and decision-used versions are treated as the same thing.
- Buffer overflow: local events are dropped during disconnection or uplink backlog.
- Reconciliation overwrite: cloud or edge state is overwritten without preserving conflict history.
- Clock drift: acquisition, decision, sync, and ingestion times become difficult to compare.
- Partial rollout: configuration, firmware, or model updates reach only part of the fleet.
- Trust-boundary failure: credentials, policy bundles, or model artifacts are accepted without sufficient verification.
- Selective uplink opacity: cloud summaries no longer preserve enough local context for interpretation.
- Operational plane fragmentation: local dashboards and cloud systems disagree about system state.
A mature hybrid architecture does not assume these failures can be eliminated. It makes them detectable, bounded, testable, recoverable, and reviewable.
Trade-Offs in Hybrid Architecture Design
Hybrid architectures are defined by trade-offs that cannot all be optimized at once. More local autonomy improves continuity and responsiveness but increases observability and governance burden. More cloud dependence simplifies some management tasks but weakens resilience under disconnection. More synchronization improves consistency but increases bandwidth and coordination cost. Less synchronization improves independence but risks divergence and policy drift.
The right hybrid design depends on purpose. Site operations, industrial control, remote monitoring, smart buildings, transportation systems, environmental sensing, and AI-enabled edge fleets all require different balances of local execution and central coordination.
Good hybrid architecture is therefore proportional. It places only the necessary authority and processing at each layer, then makes the relationship among those layers explicit. A passive sensing system may tolerate delayed cloud analysis. A local safety system may not. A fleet-wide AI model may need centralized governance, but local inference may still be necessary for latency or privacy. A gateway may buffer data for hours, but local authority to act may need to expire much sooner.
The central discipline is not choosing cloud or edge. It is assigning responsibility, measuring divergence, preserving evidence, and recovering coherence across layers that must cooperate under imperfect conditions.
Applications in Embedded and Edge Systems
Industrial hybrid control. Local edge nodes maintain continuity, site dashboards, buffering, and fast operational logic, while the cloud coordinates fleet-wide analytics, benchmarking, software rollout, and model lifecycle governance. This pattern is strongest where local interruption costs are high but fleet learning still matters.
Remote infrastructure monitoring. Environmental stations, utilities, transport infrastructure, and remote assets often use local buffering, summarization, and anomaly detection at the edge while relying on the cloud for long-horizon storage, portfolio comparison, and policy distribution. This pattern prioritizes survivability under intermittent connectivity.
Building and campus operations. Facilities often require local coordination of HVAC, access, occupancy, safety, or energy systems while still using cloud systems for central visibility, multi-site benchmarking, and optimization. Here the hybrid architecture exists to avoid forcing all building intelligence through one remote control surface.
Hybrid AI fleets. Devices or gateways run local models for latency, privacy, bandwidth reduction, or continuity, while cloud platforms handle monitoring, retraining, evaluation, approval, and rollout. This pattern depends on a disciplined split between edge inference and cloud lifecycle management.
Healthcare, mobility, and field systems. Safety-relevant or remote systems may require local responsiveness even when cloud services are unavailable, while still preserving central evidence, policy, and lifecycle governance. Hybrid architecture makes that balance explicit.
The unifying pattern is divided responsibility: local layers preserve immediate usefulness and continuity, while cloud layers preserve coordination, memory, governance, and fleet-scale learning.
Engineer Checklist
- Define which functions belong to device, gateway, site edge, regional edge, and cloud.
- Document local authority windows, cloud authority, approval rules, and fail-closed conditions.
- Separate acquisition time, local decision time, sync time, cloud ingestion time, and cloud interpretation time.
- Track edge policy version, cloud policy version, edge model version, approved model version, target version, active version, and rollout state.
- Define what continues during cloud outage, what is buffered, what is prohibited, and what must degrade.
- Set synchronization contracts for cadence, freshness, retry behavior, retention, and conflict handling.
- Define conflict-resolution rules for telemetry, safety state, policy version, model version, local decisions, and configuration updates.
- Design selective uplink policies that preserve interpretability, not only bandwidth savings.
- Log local decisions with policy version, model version, state age, confidence, and authority status.
- Use rollout rings for firmware, gateway runtime, policy, configuration, and model deployment.
- Test cloud outage, gateway restart, buffer overflow, stale policy, partial rollout, model rollback, and reconciliation conflict.
- Use trust controls for device identity, signed policy bundles, signed model artifacts, credential rotation, and offline authority.
- Monitor state age, sync lag, buffer backlog, degraded-mode rate, policy drift, model skew, rollout convergence, and recovery completeness.
- Confirm that edge inference, local control, and central governance remain distinguishable in logs and operations.
This checklist is intentionally practical. Hybrid systems become trustworthy when engineers can explain what the edge knew, what it decided, which policy or model it used, what the cloud knew, how old the synchronized state was, what version was active, and how the system recovered when the layers diverged.
GitHub Repository
This article is supported by a companion workflow that models cloud-edge coordination using workload placement, synchronization lag, state lineage, policy-version drift, model-version skew, degraded-mode behavior, rollout convergence, selective uplink, gateway buffering, telemetry schemas, and hybrid fleet reporting.
Where This Fits in the Series
This article extends the foundation established in Edge Computing Architectures, Gateways, Aggregation Layers, and Distributed Edge Infrastructure, Edge Analytics and Local Data Processing, and Edge AI and On-Device Machine Learning by focusing on how cloud and edge layers coordinate rather than simply coexist.
It also connects directly to Device Lifecycle Management and Over-the-Air Updating, Standards, Interoperability, and Governance in Edge Infrastructure, and Security in Embedded and Edge Systems Architecture, where synchronization, governance, trust, and lifecycle control become operational requirements rather than abstract architecture principles.
Related articles
- Embedded and Edge Systems: Real-Time Computing in Devices, Sensors, and Infrastructure
- Edge Computing Architectures
- Gateways, Aggregation Layers, and Distributed Edge Infrastructure
- Edge Analytics and Local Data Processing
- Edge AI and On-Device Machine Learning
- Distributed Monitoring Systems
- Device Lifecycle Management and Over-the-Air Updating
- Security in Embedded and Edge Systems Architecture
Further reading
- AWS (n.d.) AWS IoT Greengrass. Available at: https://docs.aws.amazon.com/greengrass/v2/developerguide/what-is-iot-greengrass.html
- LF Edge (2020) Overview of the LF Edge Taxonomy and Framework. Available at: https://lfedge.org/wp-content/uploads/sites/24/2020/07/LFedge_Whitepaper.pdf
- LF Edge (2022) Diving Deeper into the LF Edge Taxonomy and Projects. Available at: https://lfedge.org/wp-content/uploads/sites/24/2022/06/LFEdgeTaxonomyWhitepaper_062322.pdf
- IETF (2024) RFC 9556: Internet of Things (IoT) Edge Challenges and Functions. Available at: https://datatracker.ietf.org/doc/html/rfc9556
- Microsoft (2025) Introduction to the Azure Internet of Things (IoT). Available at: https://learn.microsoft.com/en-us/azure/iot/iot-introduction
- Microsoft (n.d.) Azure hybrid options. Available at: https://learn.microsoft.com/en-us/azure/architecture/guide/technology-choices/hybrid-considerations
- NIST (2026) Challenges to the Monitoring of Deployed AI Systems. Available at: https://nvlpubs.nist.gov/nistpubs/ai/NIST.AI.800-4.pdf
References
- AWS (n.d.) AWS IoT Greengrass. Available at: https://docs.aws.amazon.com/greengrass/v2/developerguide/what-is-iot-greengrass.html
- AWS (n.d.) Industrial IoT with AWS IoT Greengrass. Available at: https://docs.aws.amazon.com/whitepapers/latest/hybrid-architectures-to-address-personal-data-processing-requirements/industrial-iot-with-aws-iot-greengrass.html
- Azure (n.d.) Azure IoT documentation. Available at: https://learn.microsoft.com/en-us/azure/iot/
- IETF (2024) RFC 9556: Internet of Things (IoT) Edge Challenges and Functions. Available at: https://datatracker.ietf.org/doc/html/rfc9556
- LF Edge (2020) Overview of the LF Edge Taxonomy and Framework. Available at: https://lfedge.org/wp-content/uploads/sites/24/2020/07/LFedge_Whitepaper.pdf
- LF Edge (2022) Diving Deeper into the LF Edge Taxonomy and Projects. Available at: https://lfedge.org/wp-content/uploads/sites/24/2022/06/LFEdgeTaxonomyWhitepaper_062322.pdf
- Microsoft (2025) Introduction to the Azure Internet of Things (IoT). Available at: https://learn.microsoft.com/en-us/azure/iot/iot-introduction
- Microsoft (n.d.) Azure hybrid options. Available at: https://learn.microsoft.com/en-us/azure/architecture/guide/technology-choices/hybrid-considerations
- NIST (2021) Developing Cyber-Resilient Systems. Available at: https://nvlpubs.nist.gov/nistpubs/SpecialPublications/NIST.SP.800-160v2r1.pdf
- NIST (2026) Challenges to the Monitoring of Deployed AI Systems. Available at: https://nvlpubs.nist.gov/nistpubs/ai/NIST.AI.800-4.pdf