
Last Updated May 12, 2026
Reliability and fault tolerance in embedded devices examine how systems continue to operate correctly, safely, or at least acceptably in the presence of faults, degradation, and unexpected conditions. In embedded computing, dependable behavior is not only a matter of component quality. It is the product of architectural decisions about detection, containment, recovery, redundancy, supervision, safe-state behavior, diagnostics, and graceful degradation under real-world stress.
Embedded devices rarely operate in ideal environments. They may be exposed to temperature variation, electrical noise, unstable power, electromagnetic interference, memory wear, communication errors, mechanical stress, timing jitter, sensor drift, unexpected user input, or software defects that only appear after long deployment. In these settings, failure is not always binary. A device may degrade gradually, misread a sensor intermittently, lose state, deadlock under rare timing conditions, corrupt memory, recover from one fault only to be left vulnerable to another, or continue operating while silently producing low-integrity outputs.
Reliability concerns the probability that a system performs its intended function correctly over time under stated conditions. Fault tolerance concerns the ability of the system to continue operating, safely or acceptably, even when faults occur. These are related but not identical ideas. A highly reliable device may rarely fail, yet have poor fault tolerance when it does. A fault-tolerant device may continue operating through faults, yet do so at greater architectural complexity, energy cost, verification burden, or diagnostic burden. The design question is not simply how to avoid faults altogether, but how to make credible faults detectable, bounded, recoverable, and non-catastrophic.
This is why dependable embedded design frequently includes watchdog timers, sanity checks, CRCs, ECC or parity where available, brownout detection, supervisory logic, reset strategy, state validation, redundant sensing, diagnostic counters, rollback paths, health monitors, persistent fault records, and controlled fallback modes. Reliability in the field depends not on one protective mechanism, but on whether these mechanisms form a coherent recovery architecture.
Main Library
Publications
Article Map
Embedded & Edge Systems
Related Topic
Intelligent Infrastructure
Related Topic
Data Systems & Analytics
Related Topic
AI Systems
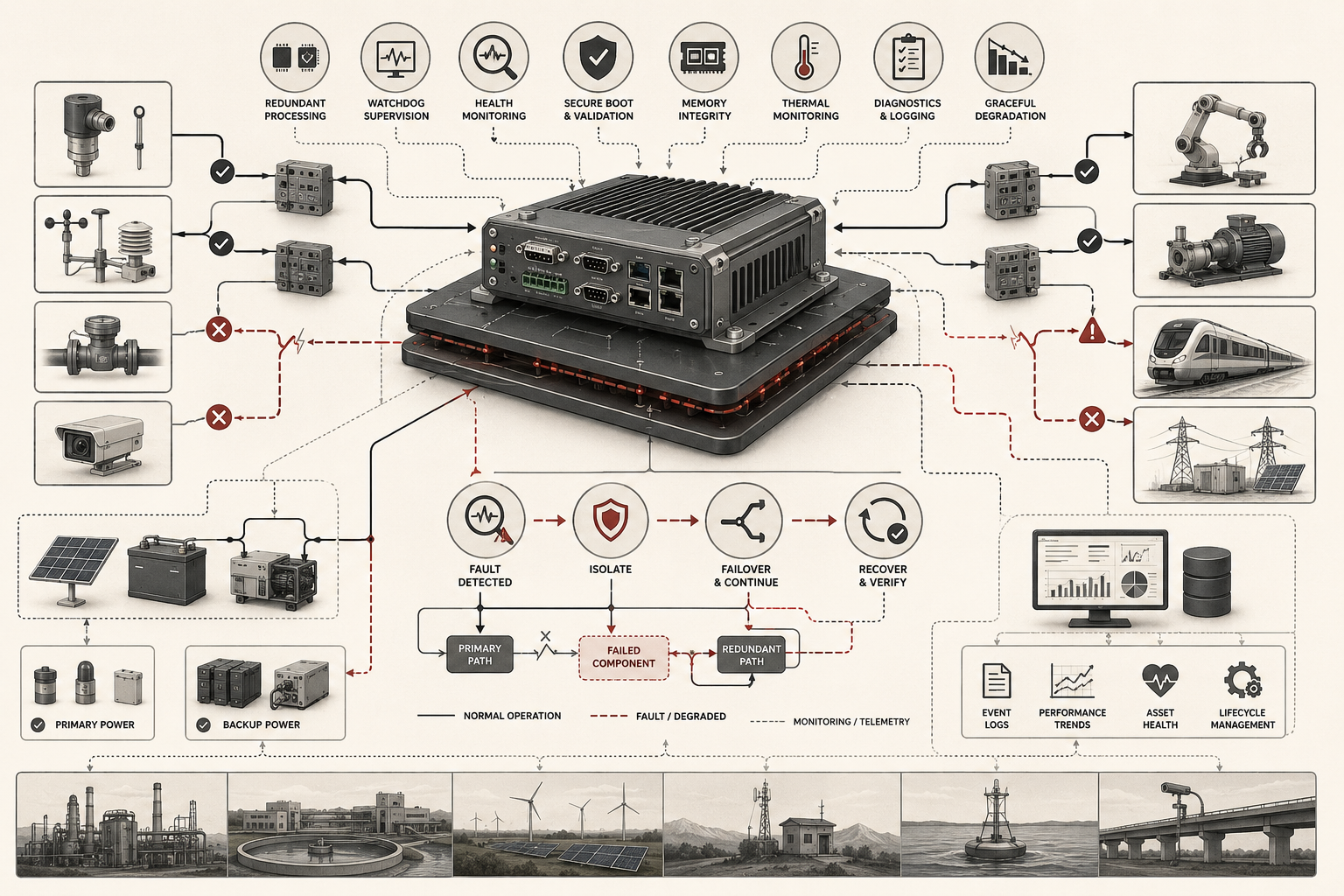
The engineering question is therefore not whether faults can be eliminated. They cannot. The real question is whether the device can detect abnormal conditions early, prevent local faults from becoming system-wide failures, preserve enough evidence for diagnosis, and transition into recovery, degraded operation, or safe state without creating disproportionate harm.
Engineering Problem
The engineering problem is how to make an embedded device dependable when faults are expected, operating conditions are imperfect, and human intervention may be delayed, expensive, or impossible. A field device may need to continue sensing during communication loss. A motor-control subsystem may need to enter a non-hazardous state after a timing violation. A medical-adjacent monitor may need to preserve evidence after a reset. A remote gateway may need to recover from brownout without corrupting local state. A battery-powered node may need to degrade sampling before energy collapse.
Dependability therefore requires more than avoiding defects. It requires a fault model, detection mechanisms, containment boundaries, recovery hierarchy, safe-state definitions, diagnostic records, and an operational understanding of which functions are essential, optional, degraded, or unsafe. A system that merely runs correctly under nominal conditions is not yet dependable. It becomes dependable only when its behavior under abnormal conditions is intentional, bounded, testable, and observable.
A rigorous design should be able to answer several questions. What faults are credible? Which faults are transient, intermittent, permanent, latent, cascading, or common-cause? Which faults can be masked, retried, reset, isolated, ignored, or deferred to maintenance? Which faults require safe-state transition? What evidence is preserved after recovery? How many repeated resets indicate a persistent failure? What degraded modes are allowed? Which subsystems must remain alive for the system to be considered healthy?
The key shift is from “prevent all faults” to “control fault propagation.” Embedded reliability is strongest when faults are noticed before they become errors, errors are contained before they become failures, and failures are managed before they become hazardous, unrecoverable, or operationally misleading.
Reference Architecture
A practical reliability and fault-tolerance architecture can be understood as a layered dependability stack. The exact implementation may involve bare-metal firmware, RTOS tasks, watchdog peripherals, brownout detectors, supervisor ICs, memory protection, CRCs, redundant sensors, fault counters, persistent logs, diagnostics, reset-cause registers, edge telemetry, or lifecycle-management systems. The architectural responsibilities remain consistent.
| Layer | Engineering Role | Dependability Concern | Evidence Artifact |
|---|---|---|---|
| Fault model | Defines credible hardware, software, power, communication, timing, and environmental faults | Transient, intermittent, permanent, common-cause, cascading, latent faults | Fault model, hazard note, FMEA/FMEDA-style table, risk register |
| Detection layer | Identifies abnormal conditions before they propagate | Timeouts, CRC failures, sensor plausibility, voltage faults, timing faults, memory corruption | Diagnostic checks, detection coverage matrix, event counters |
| Supervision layer | Monitors liveness, progress, timing, and subsystem health | Deadlock, task starvation, missed deadlines, stalled peripherals, stuck loops | Watchdog policy, health consensus, heartbeat records, reset-cause log |
| Containment layer | Prevents local faults from corrupting the whole system | Memory corruption, task isolation, peripheral failure, invalid shared state | Partition map, interface contract, restart domain, memory-boundary note |
| Recovery layer | Restores service or enters a defined degraded mode | Retry, local reset, subsystem restart, full reboot, rollback, safe shutdown | Recovery policy, reset hierarchy, rollback record, degraded-mode log |
| Redundancy layer | Provides alternative paths, backup resources, comparison mechanisms, or voting logic | Sensor disagreement, communication failover, duplicate storage, lockstep comparison | Redundancy map, voter policy, diversity rationale, failover test |
| State-integrity layer | Protects persistent and runtime state from corruption | Flash wear, incomplete writes, invalid config, corrupted checkpoints, stale state | CRC records, versioned config, last-known-good state, checkpoint manifest |
| Safe-state layer | Defines non-hazardous or acceptable behavior under severe faults | Actuator disablement, output clamp, alarm state, reduced function, shutdown | Safe-state definition, transition rule, verification test |
| Observability layer | Reports reliability evidence from the field | Reset rates, watchdog events, degraded modes, fault recurrence, uptime, fault density | Telemetry schema, fleet report, fault log, incident review |
| Lifecycle response layer | Connects fault evidence to service, update, replacement, and design decisions | Firmware updates, replacement thresholds, recurring faults, field-service prioritization | Runbook, maintenance record, update policy, service threshold |
This architecture separates failure prevention from fault management. A device is not reliable merely because it has a watchdog, a reset button, a supervisor IC, or a redundant sensor. It becomes dependable when detection, containment, recovery, safe-state behavior, and evidence work together as a coherent system.
Implementation Pattern
A rigorous implementation begins by defining the device’s dependability requirements before selecting mechanisms. The system should identify essential functions, tolerable degradation, safety boundaries, expected fault classes, detection coverage, recovery actions, diagnostic evidence, and field-maintenance responses.
| Artifact | Purpose | Typical Format |
|---|---|---|
| Fault model | Lists credible faults and classifies them as transient, intermittent, permanent, latent, cascading, or common-cause | Markdown, YAML, FMEA-style table |
| Health policy | Defines what conditions must be true before the device is considered healthy | YAML, state machine, watchdog policy |
| Watchdog strategy | Defines watchdog timeout, window behavior, servicing criteria, escalation, and reset handling | Firmware config, runbook, timing analysis |
| Recovery hierarchy | Defines retry, local reset, subsystem restart, degraded mode, full reboot, safe shutdown, and maintenance escalation | State machine, YAML, design document |
| Safe-state definition | Defines outputs, actuators, communications, stored state, and operator-visible behavior under severe fault conditions | Safety note, requirements table, verification checklist |
| Diagnostic telemetry schema | Defines reset causes, fault counters, degraded-mode entries, timing faults, and recovery outcomes | SQL, JSON Schema, CSV, telemetry contract |
| Persistent-state policy | Defines atomic writes, CRCs, versioning, rollback, wear management, and last-known-good records | YAML, firmware design note, test plan |
| Fault-injection plan | Defines how timeouts, communication failures, brownouts, bad sensor values, watchdog starvation, and memory faults are simulated | Python workflow, test script, HIL procedure |
| Fleet reliability report | Tracks reset rates, watchdog events, degraded states, firmware versions, and recurring faults across devices | R report, CSV, dashboard, incident summary |
| Maintenance threshold | Defines when repeated faults require firmware update, field service, hardware replacement, or retirement | Runbook, operational policy, service ticket rule |
The implementation goal is to make dependable behavior explicit. Engineers should be able to reconstruct what went wrong, what detected it, what recovery path executed, whether recovery succeeded, what state was preserved or discarded, and whether the device remained fit for service afterward.
Research-Grade Framing: Dependability as Controlled Failure
Reliability and fault tolerance should be framed as the architecture of controlled failure. This is not pessimism. It is engineering realism. Embedded systems operate in the physical world, where power rails sag, sensors drift, memory wears, buses stall, tasks deadlock, electromagnetic interference can corrupt state, and firmware assumptions eventually meet unanticipated conditions.
A dependable device is therefore not one that claims fault-free operation. It is one that reduces the probability of unacceptable failure, detects abnormal behavior early, limits propagation, preserves essential service when possible, and makes recovery evidence visible. The most important question is not whether the device can run a demonstration under nominal conditions. It is whether the device behaves predictably when assumptions fail.
| Dependability Dimension | Question | Required Evidence |
|---|---|---|
| Fault awareness | Does the design identify credible faults before deployment? | Fault model, risk register, fault-class table |
| Detection coverage | Can the system notice the faults that matter? | Coverage matrix, diagnostic tests, fault-injection evidence |
| Containment | Can local faults be prevented from cascading? | Partition map, interface boundaries, restart domains |
| Recovery | Does the system have defined recovery actions? | Recovery hierarchy, reset policy, degraded-mode log |
| Safe behavior | Are dangerous or unacceptable outputs prevented under severe fault? | Safe-state definition, verification test, actuator/output policy |
| Evidence | Can engineers diagnose what happened after recovery? | Reset-cause records, fault counters, crash logs, telemetry |
| Lifecycle response | Can repeated field faults trigger service, rollback, redesign, or retirement? | Fleet reliability report, maintenance threshold, incident review |
In this framing, fault tolerance is not a bag of protective features. It is a disciplined relationship between expected faults, detection mechanisms, containment boundaries, recovery behavior, safe-state definitions, and operational evidence.
Formal Model: Faults, Errors, Failures, and Recovery
A useful formal model separates the occurrence of a fault, the creation of an erroneous internal state, the propagation of that error into a service failure, and the recovery or degradation response. Let \(F(t)\) represent the occurrence of a fault, \(E(t)\) the internal error state, \(Y(t)\) the externally visible service output, \(D(t)\) the detection state, and \(R(t)\) the recovery response.
F(t) \rightarrow E(t) \rightarrow \text{Failure}(Y(t))
\]
Interpretation: A fault does not necessarily become a failure. Dependable architecture attempts to interrupt the path from fault to internal error or from internal error to externally visible failure.
D(t) = I(E(t) \notin \mathcal{S}_{\mathrm{valid}})
\]
Interpretation: Detection can be modeled as an indicator that the system state has left the valid operating set. Watchdogs, plausibility checks, timing monitors, CRCs, voltage monitors, and state validators approximate this test from different angles.
R(t) \in \{\text{retry}, \text{local reset}, \text{subsystem restart}, \text{degraded mode}, \text{full reboot}, \text{safe shutdown}\}
\]
Interpretation: Recovery is a bounded set of designed responses. A dependable system chooses a response proportional to fault severity, recurrence, and safety implications.
A = \frac{\mathrm{MTBF}}{\mathrm{MTBF} + \mathrm{MTTR}}
\]
Interpretation: Availability depends on mean time between failures and mean time to repair or recover. Fault tolerance can improve effective availability by reducing recovery time or preserving degraded service.
This formal structure matters because reliability and fault tolerance are not vague aspirations. They involve measurable relationships among fault rate, detection coverage, recovery time, degraded-service behavior, safety constraints, and evidence retained for diagnosis.
What Are Reliability and Fault Tolerance?
Reliability is the ability of an embedded device to perform its intended function correctly over a defined period under stated conditions. It asks whether the device continues doing what it is supposed to do without unacceptable interruption, corruption, or degradation.
Fault tolerance is the ability of the system to continue operating, at least in some acceptable or safe manner, despite the occurrence of faults. It asks what happens after something goes wrong and whether the system can detect, contain, compensate for, or recover from that condition.
These concepts overlap, but they are not interchangeable. Reliability emphasizes sustained correct operation over time. Fault tolerance emphasizes resilience in the presence of faults. In embedded systems, both matter because devices often run unattended, interact with physical processes, and cannot assume that failure will be obvious, localized, or easily corrected by human intervention.
A useful extension of this distinction is graceful degradation. A system may not preserve full functionality under fault, yet still preserve its most important services or remain in a safe operating envelope. That is often the practical goal in embedded systems. The device does not need to be invulnerable. It needs to fail proportionately, transparently, and recoverably.
Faults, Errors, and Failures
A useful way to think about dependable embedded systems is to distinguish among faults, errors, and failures. A fault is an underlying defect or abnormal condition, such as a memory bit upset, voltage drop, worn sensor, timing race, corrupted communication frame, invalid configuration, or damaged peripheral. An error is the incorrect internal state that results from that fault, such as a corrupted value, invalid pointer, missed timing deadline, inconsistent buffer contents, or stale state. A failure occurs when that internal error propagates outward and the system no longer provides its intended service.
This distinction matters because architecture can intervene at multiple stages. A fault may be prevented, detected, tolerated, or masked before it produces an error. An error may be contained before it becomes a visible failure. A visible failure may still be managed so that it becomes recoverable rather than catastrophic. Fault tolerance begins with understanding where intervention is still possible.
Embedded design benefits from treating faults as heterogeneous rather than generic. Some faults are transient, such as electromagnetic interference or a temporary communication glitch. Others are intermittent, recurring under specific operating conditions. Others are permanent, such as worn flash cells, damaged peripherals, failed sensors, or degraded connectors. A good fault-tolerance strategy distinguishes among these classes because retry, reset, fallback, replacement, and safe shutdown are not equally appropriate for all of them.
Reliability as a System Property
Reliability in embedded devices is not determined by any single part. It emerges from the interaction of hardware quality, firmware discipline, timing margins, power integrity, communications robustness, thermal behavior, mechanical installation, maintenance, and operating environment. A reliable system is one in which these elements remain aligned long enough and well enough that the device continues to perform its intended role.
That means reliability cannot be reduced to component datasheets or mean time between failures alone. A device may use excellent parts and still behave unreliably if firmware leaves race conditions unresolved, if brownout recovery is poor, if interrupts starve critical tasks, if watchdog servicing is meaningless, if persistent state is written unsafely, or if sensor calibration drifts without detection. Conversely, a modest platform can achieve good practical reliability when supervision, reset handling, state validation, conservative margins, and diagnostic evidence are designed well.
In embedded and edge systems, reliability is also inseparable from observability. The system must know enough about itself to notice when behavior is drifting, timing is unstable, memory is corrupted, sensors are implausible, or peripherals have become unresponsive. Without that visibility, latent faults persist until they become failures in the field.
Reliability should therefore be understood as an architectural property of sustained coherence. The device remains reliable when its assumptions about timing, sensing, control, memory, communication, and power continue to hold under realistic conditions. Once those assumptions are violated repeatedly without detection or mitigation, reliability degrades whether or not the headline hardware remains nominally intact.
Fault Tolerance and Graceful Degradation
Fault tolerance is the discipline of continuing operation when faults occur. Sometimes that means maintaining full service. More often it means maintaining essential service, preserving safety, or degrading gracefully instead of failing abruptly. A system may reduce update frequency, fall back to a backup sensor, reset a peripheral, isolate a failed module, disable a nonessential function, switch to a conservative control mode, or enter a safe limited mode while still preserving core functions.
Graceful degradation is especially important in embedded devices because not every fault justifies full shutdown. A remote monitoring device that loses one optional measurement channel may still provide useful data. A robotics subsystem that detects degraded sensing may reduce performance and request service rather than continuing at full risk. A communication device may temporarily fall back to a slower but more robust mode. An environmental node may reduce sampling to preserve battery while maintaining heartbeat telemetry.
Fault tolerance therefore depends on clear architectural priorities: what must always work, what may fail softly, what can be retried, what must be isolated, what evidence must be preserved, and what conditions require transition to a safe state. Without that hierarchy, systems either overreact to minor faults or underreact to dangerous ones.
A system without a defined degradation model is not truly fault tolerant. It is merely hoping that faults will stay small. Dependable design instead specifies which functions are mission-critical, which are optional, and which combinations of degraded behavior are still acceptable.
Fault Detection, Supervision, and Diagnostics
Reliable embedded devices must detect abnormal conditions early enough to do something useful about them. Detection mechanisms may include watchdog supervision, checksum or CRC verification, parity or ECC memory protection, voltage and clock monitors, plausibility checks on sensor inputs, timing monitors, communication timeouts, self-tests, stack guards, brownout flags, and periodic sanity checks on state or outputs.
Detection is not only about adding alarms. It is about making fault boundaries visible. A sensor reading outside physical possibility should not silently propagate into control logic. A communication buffer that stops changing should not be treated as fresh data. A peripheral that fails to acknowledge configuration should not be assumed to be healthy. A persistent-state record that fails CRC should not be trusted merely because it is present in flash. Detection logic transforms unknown failure into a condition the system can classify and manage.
In more demanding designs, diagnostics also need to support post-fault understanding. Reset-cause registers, crash logs, fault counters, last-known-good state, brownout history, degraded-mode entries, and telemetry about recovery outcomes all make it more likely that faults can be traced rather than merely experienced. A device that resets cleanly but leaves no evidence may recover operationally while still remaining architecturally mysterious.
Supervision should also be layered. One mechanism rarely catches every class of problem. A watchdog may detect system liveness failure, while CRC checks catch frame corruption, voltage monitors catch power instability, and plausibility logic catches sensor anomalies. The purpose of layered supervision is not redundancy for its own sake, but coverage across different fault classes and propagation paths.
Watchdog Timers and Recovery Control
The watchdog timer is one of the most familiar mechanisms in fault-tolerant embedded design because it supervises software liveness. If firmware enters an infinite loop, deadlocks, starves a critical task, or otherwise fails to make expected progress, the watchdog can trigger a reset or recovery response.
But watchdogs are more subtle than they first appear. A poorly designed watchdog can be fed by code that is still running but functionally broken. A timeout that is too short may create spurious resets; one that is too long may delay recovery beyond usefulness. Windowed watchdogs add a further constraint by detecting not only late servicing but also servicing that occurs too early, which helps catch certain classes of faulty control flow.
For that reason, watchdog design should be tied to meaningful liveness criteria. The system should only service the watchdog when critical tasks, timing conditions, communication health, state validation, and subsystem checks indicate genuine health, not merely because some code path is still executing. In stronger architectures, watchdog servicing becomes the result of a health consensus rather than a blind periodic action.
Recovery control also matters. A watchdog reset is not itself a reliability strategy unless the system knows what to do afterward. The reset path must validate state, record cause where possible, determine whether repeated resets indicate a persistent fault, and choose whether the next boot should attempt normal service or enter safer fallback behavior.
Redundancy, Diversity, and Error Containment
Fault tolerance often depends on redundancy, but redundancy can take many forms. It may involve duplicate sensors, mirrored memory, backup communication channels, spare processing resources, dual power paths, independent clocks, or lockstep execution in which parallel units compare behavior.
Yet redundancy only helps when faults can be compared, isolated, or voted on meaningfully. Two identical sensors mounted in the same failure-prone location may not provide useful independence. Two software copies with the same hidden bug are not diversity. A backup communication path that shares the same damaged connector may not provide real failover. Good fault-tolerant architecture therefore combines redundancy with independence, comparison logic, and error containment.
Error containment can be achieved through memory protection, subsystem isolation, strict interface boundaries, guarded communication paths, process supervision, or explicit restart domains in which one failed peripheral or task can be reinitialized without destabilizing the rest of the system. The principle is simple: not every local fault should be allowed to become a system-wide failure.
Diversity is often as important as duplication. Alternate sensing modalities, independently developed checks, different timing paths, simpler fallback logic, or conservative backup modes can provide stronger protection than merely copying the same vulnerable mechanism twice. Dependable architecture is not only about having backups. It is about ensuring that backups fail differently enough to matter.
Recovery, Reset Strategy, and Safe State Design
Once a fault is detected, the system needs a recovery strategy. That may involve retrying an operation, resetting a peripheral, rolling back to default configuration, restarting a task, rebooting the whole device, switching to a redundant channel, reducing service, disabling an actuator, or entering a safe state. Recovery should never be treated as an improvised afterthought. It is part of the device’s intended behavior under stress.
Reset strategy is especially important. Not all resets are equal. A processor reset may leave peripherals in a problematic state. A brownout recovery may require integrity checks before service resumes. A partial subsystem reset may preserve enough state to resume quickly, but may also preserve corrupted assumptions. Good recovery design therefore specifies what is reinitialized, what is validated, what is discarded, what is preserved, and how the system decides it is safe to resume service.
Safe state design is equally important in devices that control physical processes. Sometimes the right response to a severe fault is continued degraded operation. Sometimes it is orderly shutdown, actuator disablement, output clamping, alarm signaling, or transition to a non-hazardous output state. The system should not have to improvise those decisions at the moment of failure.
A strong recovery hierarchy usually proceeds from least disruptive to most disruptive action: retry, local reset, subsystem restart, degraded mode, full reboot, safe shutdown. That hierarchy helps prevent the system from treating every anomaly as catastrophic while still preserving a path to stronger interventions when local recovery no longer works.
Software Reliability in Embedded Devices
Many embedded faults are ultimately software faults, even when triggered by hardware or environment. Concurrency bugs, missed deadlines, stale data, unbounded retries, memory corruption, ISR misuse, stack overflow, invalid state transitions, blocking calls in timing-sensitive paths, and unvalidated assumptions about peripheral state can all undermine reliability.
Good practice includes bounded execution, explicit timeout handling, validation of external inputs, cautious use of shared state, careful stack sizing, fault logging, robust state-machine design, static analysis where appropriate, deterministic startup, and clear ownership of persistent state. In RTOS-based systems, reliability also depends on priority discipline, synchronization correctness, avoiding priority inversion, bounding queue growth, and avoiding the temptation to treat watchdog resets as substitutes for root-cause control.
A reliable embedded software system does not assume the happy path. It assumes timeouts, corrupted frames, delayed peripherals, unexpected wake-ups, invalid inputs, rare interleavings, and low-power recovery will eventually happen, and it prepares for them structurally rather than rhetorically.
Software reliability also depends on keeping failure handling explicit. Silent retries, swallowed error codes, ambiguous state transitions, optimistic assumptions about peripheral recovery, or hidden reset loops all reduce the system’s ability to remain interpretable under fault. The more hidden the failure logic, the more fragile the field behavior tends to become.
Reliability Observability and Field Evidence
Reliability cannot be improved if the field system leaves no evidence. Embedded devices should report enough operational telemetry to distinguish healthy operation, degraded operation, repeated recovery, and unresolved fault recurrence. This is especially important for remote devices, edge gateways, environmental monitors, industrial controllers, and infrastructure systems where maintenance may depend on sparse evidence.
Useful reliability signals include uptime, reset cause, watchdog reset count, brownout count, fault counters, last fault class, degraded-mode entries, sensor fault flags, communication timeout rates, CRC failures, queue overruns, stack-watermark warnings, memory-allocation failures, flash-write failures, firmware version, configuration version, and recovery outcome. These signals should be treated as part of the device’s diagnostic contract.
Observability also changes design incentives. A system that resets silently may look stable because it eventually returns to service. A system that reports reset cause, fault recurrence, and degraded-mode time allows engineers to see whether it is truly reliable or merely recovering repeatedly. Field evidence is the difference between hidden fragility and disciplined dependability engineering.
The device should not only survive faults. It should make its fault history legible.
Mathematical Lens: Reliability, Failure Rate, Coverage, Recovery, and Availability
A mathematical lens helps connect dependability mechanisms to system behavior. Let \(R(t)\) be reliability over time, \(\lambda\) the failure rate under a simple exponential model, \(C_d\) detection coverage, \(C_r\) recovery coverage, \(\mathrm{MTBF}\) mean time between failures, and \(\mathrm{MTTR}\) mean time to repair or recover.
R(t) = e^{-\lambda t}
\]
Interpretation: Under a simple constant-failure-rate model, reliability decreases over time. Real embedded systems often have more complex failure behavior, but the model helps connect time, failure rate, and expected service continuity.
A = \frac{\mathrm{MTBF}}{\mathrm{MTBF} + \mathrm{MTTR}}
\]
Interpretation: Availability improves when failures happen less often or recovery happens faster. Fault tolerance often improves effective availability by reducing downtime or preserving degraded service.
C_{\mathrm{effective}} = C_d \cdot C_r
\]
Interpretation: Effective fault coverage depends on both detection and recovery. A detected fault without a useful recovery path may still become a failure; an available recovery path is ineffective if the fault is never detected.
T_{\mathrm{recovery}} = T_{\mathrm{detect}} + T_{\mathrm{isolate}} + T_{\mathrm{restore}} + T_{\mathrm{validate}}
\]
Interpretation: Recovery time includes detection, isolation, restoration, and validation. A fast reset is not enough if the device resumes service with corrupted state or without validating safe operation.
D_{\mathrm{safe}} = I(Y(t) \in \mathcal{Y}_{\mathrm{safe}})
\]
Interpretation: Safe behavior can be modeled as whether the system output remains inside the allowed safe-output set. In physical systems, dependable behavior often means constraining outputs even when full service cannot be preserved.
These equations are intentionally compact. Their purpose is to make dependability trade-offs explicit: lower failure rate, higher detection coverage, better recovery coverage, shorter recovery time, and safe output constraints are distinct engineering objectives.
Python Workflow: Fault Injection, Recovery Coverage, and Availability Simulation
The companion Python workflow models embedded dependability as a sequence of faults, detections, recoveries, degraded states, and service outcomes. It simulates fault classes such as communication timeout, sensor fault, brownout, memory corruption, watchdog timeout, persistent-state corruption, queue overload, and safe-state transition. It then evaluates detection coverage, recovery coverage, recovery time, degraded-service duration, and effective availability.
The workflow is designed to answer practical engineering questions. Which faults are detected? Which are missed? Which recoveries succeed? Which faults cause full service loss? How does watchdog timeout affect downtime? How does repeated reset behavior indicate persistent fault? How does degraded operation change effective availability? Which mechanisms provide the most coverage for the fault classes that matter?
Useful outputs include a fault-event table, recovery-outcome summary, availability estimate, coverage-by-fault-class report, degraded-mode timeline, and plots of uptime versus fault density. In a production setting, this workflow could be adapted into a predeployment reliability model or a postdeployment fleet-analysis tool.
The purpose is not to claim precise prediction from simple models. It is to make assumptions visible and testable before field failures reveal them the hard way.
R Workflow: Fleet Reliability, Reset Patterns, and Fault-Tolerance Reporting
The companion R workflow treats reliability as a fleet-observability problem. It summarizes reset causes, watchdog events, brownout counts, degraded-mode entries, communication failures, sensor fault rates, firmware versions, uptime, and recovery outcomes across devices.
This matters because many reliability issues appear only at fleet scale. One device may reset occasionally because of local power conditions. A firmware version may show a higher watchdog-reset rate. A specific sensor interface may produce intermittent fault flags under temperature stress. A subgroup of gateways may exhibit repeated communication timeouts after a configuration change. Fleet reporting helps distinguish isolated failures from systemic design weaknesses.
Useful R outputs include reliability-by-device reports, reset-cause distributions, watchdog-reset trends, degraded-mode frequency, firmware-version comparisons, mean time between reset estimates, and field-service prioritization tables. These reports support maintenance, firmware rollback, design review, root-cause analysis, and lifecycle management.
A dependable embedded fleet is not only built. It is watched, measured, and improved over time.
Systems Code: Watchdogs, State Machines, Rust Validation, Go Telemetry, PYNQ, HDL, and Bash
The companion systems stack demonstrates how reliability and fault tolerance appear across embedded and edge implementation layers.
The C example focuses on firmware-adjacent logic: health flags, watchdog-servicing criteria, fault counters, degraded-mode classification, and safe-state transition. The C++ example models a reliability state machine that separates normal service, suspected fault, degraded service, recovery, repeated failure, and safe shutdown. The Rust example validates reliability manifests and ensures required fault model, watchdog, recovery, and safe-state fields are present before deployment. The Go example sketches a fleet telemetry utility that aggregates reset causes and device-health events.
MicroPython provides a prototype for watchdog-like heartbeat behavior, local diagnostic flags, and degraded-mode telemetry on constrained boards. TinyML can support local anomaly screening where appropriate, but it should never replace explicit supervision and quality logic. PYNQ support can demonstrate hardware-assisted monitoring, timestamping, or fault-event capture. HDL examples can model watchdog counters, heartbeat monitors, timeout detectors, reset sequencing, or safe-output gating.
The Bash scripts tie these pieces together by validating manifests, running Python and R workflows, generating outputs, and checking repository structure. The goal is not to turn the article into a full safety certification package. The goal is to provide an engineering scaffold that mirrors the real dependability problems embedded teams face in the field.
Technical Verification Gates
Reliability and fault tolerance should pass explicit verification gates before deployment and during operation. These gates prevent the design from being judged only by nominal functionality.
| Gate | Verification Question | Evidence Required |
|---|---|---|
| Fault-model gate | Are credible hardware, software, power, timing, communication, and environmental faults identified? | Fault model, fault-class table, design review record |
| Detection gate | Can the system detect faults before unacceptable propagation? | Coverage matrix, fault-injection test, diagnostic log |
| Watchdog gate | Is the watchdog serviced only when meaningful health conditions are satisfied? | Watchdog policy, timing analysis, task-health checklist |
| Containment gate | Can local faults be isolated without corrupting the whole system? | Restart-domain map, memory/interface boundaries, subsystem reset test |
| Recovery gate | Are recovery actions proportional, bounded, and validated before service resumes? | Recovery hierarchy, reset test, last-known-good validation, rollback test |
| Safe-state gate | Do severe faults lead to non-hazardous or acceptable outputs? | Safe-state definition, output clamp test, actuator-disable verification |
| Evidence gate | Can engineers reconstruct what happened after fault and recovery? | Reset-cause log, fault counters, telemetry schema, incident report |
| Lifecycle gate | Do repeated field faults trigger service, rollback, redesign, or retirement thresholds? | Fleet reliability report, service threshold, firmware rollback rule, maintenance ticket |
These gates reinforce the central principle: a device is not dependable because it has protective features. It is dependable when those features are tied to explicit fault assumptions, tested recovery behavior, safe-state constraints, and field evidence.
Testing and Validation
Testing dependability requires more than running nominal functional tests. A reliability test plan should deliberately introduce abnormal conditions and verify that the device detects, contains, recovers, or enters safe state as designed. This includes communication dropouts, corrupted packets, bad sensor values, stuck peripherals, delayed tasks, brownouts, watchdog timeouts, invalid configuration, flash-write interruption, queue overload, repeated reset cycles, and interrupted update paths.
Validation should include at least six layers. First, configuration validation checks watchdog policy, recovery hierarchy, and safe-state definitions. Second, software validation checks timeouts, state-machine transitions, stack usage, shared-state access, and error handling. Third, hardware validation checks power integrity, brownout behavior, supervisor signals, memory protection, and peripheral recovery. Fourth, fault-injection validation checks whether expected faults are detected and handled correctly. Fifth, field validation checks whether diagnostic telemetry reveals real-world fault patterns. Sixth, lifecycle validation checks whether repeated faults trigger service, firmware update, rollback, or redesign.
Negative testing is essential. The system should be tested for failures that engineers hope will never occur: stuck watchdog service, repeated brownout, corrupted persistent state, missing sensor heartbeat, invalid timestamp, communication replay, impossible sensor values, task starvation, and interrupted firmware update. If these cases are never tested, the recovery architecture is partly fictional.
A dependable embedded device should not merely pass when everything works. It should fail in ways that are constrained, observable, and aligned with its safety and service requirements.
Common Failure Modes
Reliability failures often hide behind apparent recovery. A device that keeps rebooting may still appear intermittently online. A sensor subsystem that resets successfully may continue producing untrustworthy values. A watchdog that fires regularly may mask a root-cause defect. A communication retry loop may preserve eventual delivery while destroying real-time behavior.
Common hardware-adjacent failures include brownout loops, insufficient decoupling, EMI-induced faults, connector intermittency, thermal stress, sensor degradation, flash wear, peripheral lockup, and memory corruption. Common firmware failures include unbounded retries, blocking calls, priority inversion, stack overflow, ISR misuse, race conditions, invalid state-machine transitions, stale data, and silent error swallowing. Common recovery failures include resetting without validating state, feeding the watchdog from unhealthy code, failing to preserve reset cause, reusing corrupted configuration, or entering a degraded mode with no exit criteria.
A particularly important failure mode is false dependability. The system appears robust because it recovers often, but the recovery evidence shows recurring unresolved faults. Dependable engineering does not celebrate repeated recovery without root-cause review. Recovery is valuable, but repeated recovery is also a signal.
Trade-Offs in Dependable Embedded Design
Reliability and fault tolerance come with costs. Redundancy consumes space, energy, and money. More diagnostics use memory and bandwidth. Additional checks can increase latency. Recovery logic adds complexity. Conservative design margins may limit throughput or feature density. Persistent logging may accelerate storage wear if not designed carefully. Supervisory mechanisms may create nuisance resets if poorly tuned.
For that reason, dependable embedded architecture is always a question of proportionality. The objective is not to eliminate every possible fault at unlimited expense. It is to decide which faults matter most, which failures are unacceptable, what degree of recovery is necessary, and what operational envelope the device must survive.
A battery-powered environmental sensor, an industrial controller, a wearable monitor, a vehicle subsystem, and a medical-adjacent device will all answer these questions differently. What unites them is the underlying principle: reliability and fault tolerance must be designed in deliberately. They do not emerge automatically from good intentions or isolated component choices.
Dependable design is best treated as a prioritization problem. Every device has a fault budget, a complexity budget, an energy budget, and an operational risk profile. The architectural task is to align those budgets rather than maximizing protection in one dimension while quietly undermining the others.
Applications in Embedded and Edge Systems
Reliability and fault tolerance matter across industrial automation, automotive control, medical devices, remote sensing, robotics, communications infrastructure, storage systems, environmental monitoring, energy systems, transportation, and intelligent edge platforms.
In remote edge systems, fault tolerance is often tied closely to recoverability because physical maintenance may be infrequent. In safety-sensitive systems, it is tied to containment and safe-state behavior. In long-lived sensing platforms, it is tied to drift detection, brownout handling, storage integrity, and graceful degradation over time. In gateway and infrastructure systems, it is tied to telemetry, restart domains, offline operation, and recovery from network partition.
What changes across domains is not whether reliability matters, but what form acceptable degradation takes. An environmental logger may survive with sparse data and delayed uploads. A motor-control subsystem may require immediate containment and deterministic shutdown. A field gateway may need to buffer locally and replay safely after reconnection. The system’s operational context determines what counts as dependable behavior.
Engineer Checklist
| Question | Why It Matters |
|---|---|
| Is there an explicit fault model? | Prevents reliability design from becoming a collection of disconnected protective features. |
| Are faults classified as transient, intermittent, permanent, latent, cascading, or common-cause? | Ensures retry, reset, fallback, and service responses are proportional. |
| Is watchdog servicing tied to meaningful system health? | Prevents unhealthy firmware from feeding the watchdog while the device is functionally broken. |
| Are recovery actions layered from least disruptive to safest fallback? | Allows proportional response while preserving escalation paths for persistent faults. |
| Is persistent state validated after reset or brownout? | Prevents corrupted configuration or stale state from surviving recovery. |
| Are safe states defined for physical outputs? | Ensures severe faults do not produce hazardous or unacceptable behavior. |
| Are reset causes, fault counters, and degraded modes observable? | Supports field diagnosis, firmware improvement, and maintenance prioritization. |
| Does repeated recovery trigger review rather than being treated as success? | Prevents recovery mechanisms from masking unresolved systemic faults. |
GitHub Repository
This article is supported by a companion workflow that treats reliability and fault tolerance as an embedded dependability architecture: fault models, watchdog policies, recovery hierarchies, safe-state definitions, diagnostic telemetry, Python fault-injection simulation, R fleet-reliability reporting, SQL evidence schemas, systems-code examples, manifests, tests, and runbooks.
Where This Fits in the Series
This article extends the foundation established in Embedded Systems Architecture, Microcontrollers and System-on-Chip Design, Data Acquisition and Embedded Sensor Interfaces, Real-Time Operating Systems in Embedded Computing, Firmware, Hardware Abstraction, and Device Control, and Low-Power Embedded System Design by focusing on how embedded devices remain dependable when conditions are imperfect and faults occur.
It also prepares the way for deeper work on safety-critical design, runtime assurance, secure update systems, edge observability, cyber-physical resilience, and dependable intelligent infrastructure.
Related articles
- Embedded Systems Architecture
- Real-Time Operating Systems in Embedded Computing
- Firmware, Hardware Abstraction, and Device Control
- Low-Power Embedded System Design
- Edge Computing Architectures
- Cyber-Physical Systems and Hardware Integration
Further reading
- Arm (n.d.) Cortex-R5. Available at: https://www.arm.com/products/silicon-ip-cpu/cortex-r/cortex-r5.
- Arm (2022) The flexible approach to adding Functional Safety to a CPU. Available at: https://developer.arm.com/community/arm-community-blogs/b/embedded-and-microcontrollers-blog/posts/flexible-approach-to-adding-functional-safety-to-a-cpu.
- Burns, A. and Wellings, A.J. (2009) Real-Time Systems and Programming Languages. 4th edn. Harlow: Addison-Wesley.
- Lee, E.A. and Seshia, S.A. (2017) Introduction to Embedded Systems: A Cyber-Physical Systems Approach. 2nd edn. Cambridge, MA: MIT Press.
- Microchip Technology Inc. (2011) Watchdog Timer and Power-Saving Modes. Available at: https://ww1.microchip.com/downloads/aemDocuments/documents/OTH/ProductDocuments/ReferenceManuals/dsPIC33EPIC24EFRM-WatchdogTimerandPower-SavingModes-DS70615C.pdf.
- Texas Instruments (2017) What is a watchdog timer and why is it important? Available at: https://www.ti.com/lit/SSZTAH7.
- Zephyr Project (n.d.) Watchdog. Available at: https://docs.zephyrproject.org/latest/hardware/peripherals/watchdog.html.
References
- Arm (n.d.) Cortex-R4. Available at: https://www.arm.com/products/silicon-ip-cpu/cortex-r/cortex-r4.
- Arm (n.d.) Cortex-R5. Available at: https://www.arm.com/products/silicon-ip-cpu/cortex-r/cortex-r5.
- Arm (2015) Addressing functional safety applications with Arm Cortex-R5. Available at: https://developer.arm.com/community/arm-community-blogs/b/embedded-and-microcontrollers-blog/posts/addressing-functional-safety-applications-with-arm-cortex-r5.
- Arm (2022) The flexible approach to adding Functional Safety to a CPU. Available at: https://developer.arm.com/community/arm-community-blogs/b/embedded-and-microcontrollers-blog/posts/flexible-approach-to-adding-functional-safety-to-a-cpu.
- Burns, A. and Wellings, A.J. (2009) Real-Time Systems and Programming Languages. 4th edn. Harlow: Addison-Wesley.
- Lee, E.A. and Seshia, S.A. (2017) Introduction to Embedded Systems: A Cyber-Physical Systems Approach. 2nd edn. Cambridge, MA: MIT Press.
- Microchip Technology Inc. (2011) Watchdog Timer and Power-Saving Modes. Available at: https://ww1.microchip.com/downloads/aemDocuments/documents/OTH/ProductDocuments/ReferenceManuals/dsPIC33EPIC24EFRM-WatchdogTimerandPower-SavingModes-DS70615C.pdf.
- Texas Instruments (2017) What is a watchdog timer and why is it important? Available at: https://www.ti.com/lit/SSZTAH7.
- Texas Instruments (2022) Watchdog Timer Overview. Available at: https://www.ti.com/video/6313371139112.
- Zephyr Project (n.d.) API Documentation: Watchdog. Available at: https://docs.zephyrproject.org/latest/doxygen/html/group__watchdog__interface.html.
- Zephyr Project (n.d.) Watchdog. Available at: https://docs.zephyrproject.org/latest/hardware/peripherals/watchdog.html.
- Zephyr Project (n.d.) Watchdog Sample. Available at: https://docs.zephyrproject.org/latest/samples/drivers/watchdog/README.html.