
Last Updated May 11, 2026
Gateways, aggregation layers, and distributed edge infrastructure examine the intermediary systems that connect field devices, local processing, site-level operations, and upstream platforms into coherent embedded and edge architectures. These layers are not mere networking plumbing. They are where protocol translation, buffering, store-and-forward continuity, local coordination, policy enforcement, identity mediation, selective uplink, partial autonomy, and site-level resilience often become operationally real.
Many distributed embedded systems fail conceptually because they are imagined as a simple two-layer stack: devices below and cloud services above. Real deployments are usually more complex. Sensors, controllers, actuators, local networks, industrial protocols, edge runtimes, gateways, aggregation services, site dashboards, regional systems, and cloud platforms must coordinate across unreliable links, mixed device capabilities, changing policy, intermittent connectivity, and unequal timing requirements.
The architectural question is therefore not only how to connect devices to upstream systems. It is how to assign responsibility across the edge continuum: what field devices should do, what gateways should mediate, what aggregation layers should synthesize, what site systems should decide locally, what cloud platforms should govern centrally, and how evidence should be preserved when local and upstream views diverge. Strong distributed edge infrastructure makes those responsibility boundaries explicit, testable, observable, secure, and recoverable.
Main Library
Publications
Article Map
Embedded & Edge Systems
Related Topic
Data Systems & Analytics
Related Topic
Intelligent Infrastructure
Related Topic
Environmental Monitoring
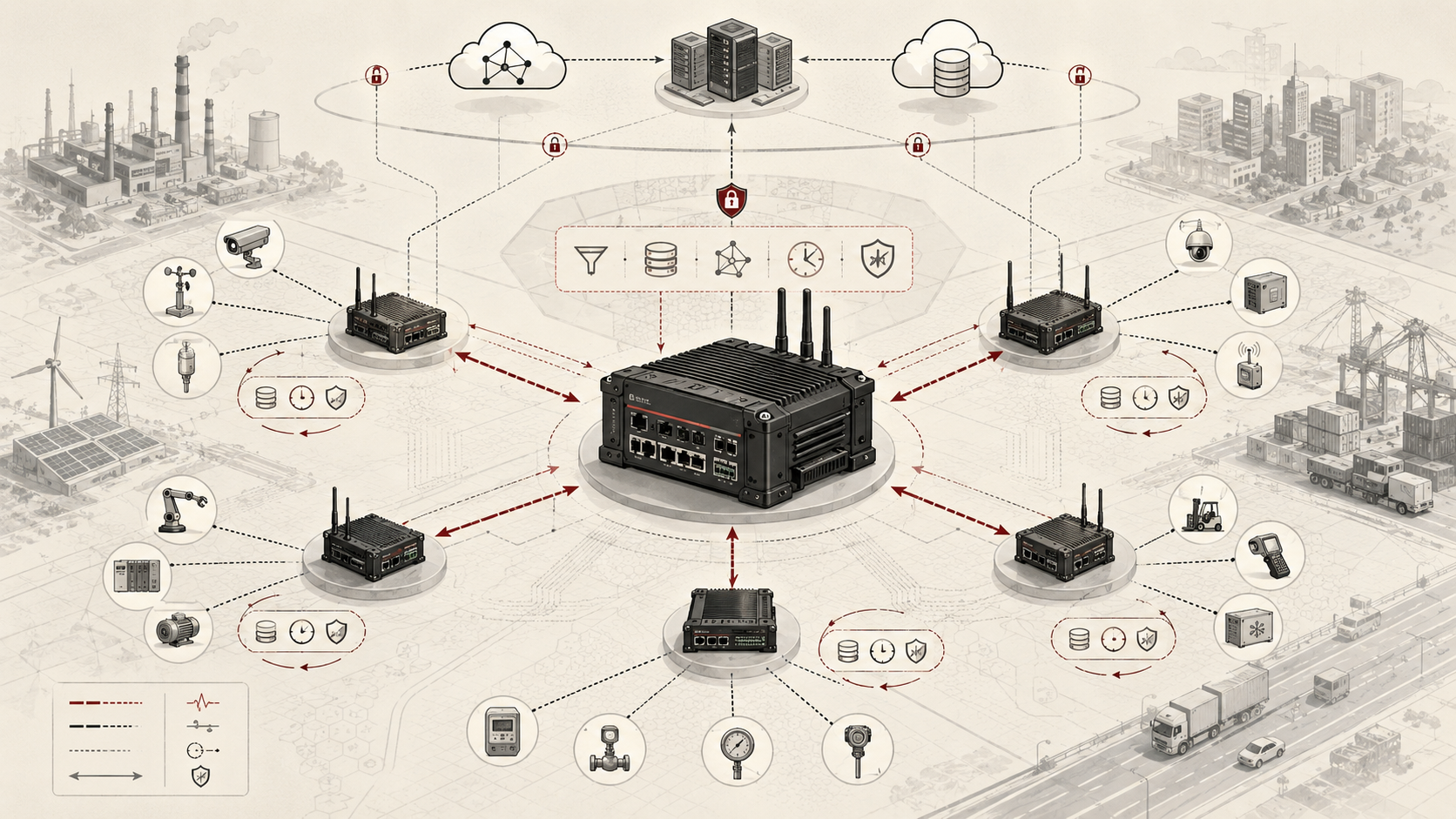
For engineers, gateways and aggregation layers should be treated as managed infrastructure, not incidental boxes between devices and cloud services. They define local trust boundaries, topology, timing, buffering, protocol mediation, data quality, failure containment, and operational visibility. A gateway that merely forwards packets may connect systems; a gateway that preserves timing, identity, lineage, health, and policy context can make distributed edge infrastructure governable.
Engineering Problem
The engineering problem is how to connect many constrained, heterogeneous, intermittently available, locally situated devices into a coherent operational system without losing identity, timing, quality, security, or responsibility. A distributed edge architecture must decide which functions happen at the device, which happen at the gateway, which happen in a site aggregation layer, and which remain the responsibility of upstream platforms.
This is not simply a networking problem. Gateways and aggregation layers shape how local data become meaningful. They determine whether timestamps survive translation, whether device identity remains traceable, whether local state is qualified by freshness and quality, whether data can be buffered during outages, whether downstream protocols can be normalized without losing context, and whether local decisions can be reconstructed later.
Intermediate layers become fragile when they are treated as invisible infrastructure. A gateway may buffer data but discard acquisition time. It may translate protocols but lose device-specific quality indicators. It may aggregate measurements but hide missing children. It may enforce local policy but fail to record which policy version was used. It may improve connectivity while weakening evidence.
The practical question is therefore: can the gateway and aggregation architecture preserve local continuity, site-level meaning, trust boundaries, protocol interoperability, data lineage, and operational evidence while connecting diverse devices to larger systems?
Reference Architecture
A practical distributed edge architecture can be understood as a layered system. The exact implementation may involve industrial controllers, IoT devices, Modbus or OPC UA gateways, MQTT brokers, field buses, edge servers, local databases, cloud IoT platforms, Kubernetes-based edge runtimes, or custom aggregation services. The architectural pattern is broadly consistent.
| Layer | Engineering Role | Gateway / Aggregation Concern | Evidence Artifact |
|---|---|---|---|
| Field device layer | Senses, actuates, measures, controls, or emits local telemetry | Constrained compute, local protocol, intermittent availability, physical placement | Device manifest, firmware version, sensor profile |
| Local network / fieldbus layer | Connects devices using local physical or logical communication systems | Bandwidth, addressing, bus load, timing, errors, topology | Fieldbus profile, address map, bus-health log |
| Gateway layer | Terminates local protocols, normalizes data, buffers events, and mediates identity | Protocol translation, trust boundary, device parenting, store-and-forward | Gateway manifest, protocol map, buffer policy |
| Aggregation layer | Combines device streams into site, subsystem, or operational state | Freshness, lineage, quality, derived metrics, missing-device awareness | Aggregation schema, site-state record, freshness report |
| Local edge runtime | Hosts local analytics, rules, inference, coordination, dashboards, and policy logic | Partial autonomy, local decision-making, degraded operation, policy versioning | Runtime manifest, local decision log, policy record |
| Site operations layer | Supports local operators, maintenance, alarms, and site-level workflows | Human visibility, incident response, local override, operational continuity | Dashboard record, alarm log, incident timeline |
| Upstream platform layer | Provides fleet management, long-horizon storage, analytics, policy, and governance | Central coordination, lifecycle control, auditability, cross-site comparison | Cloud ingestion log, fleet report, deployment manifest |
| Security and trust layer | Manages identity, certificates, credentials, signing, attestation, and access | Gateway compromise, downstream trust, upstream trust, credential rotation | Trust policy, certificate record, attestation log |
| Observability and recovery layer | Monitors health, lag, buffer pressure, missing devices, and recovery behavior | Outage recovery, replay order, data gaps, topology failures, local drift | Gateway health report, sync log, recovery record |
This architecture makes the intermediary layers visible. It separates connectivity from interpretation, forwarding from aggregation, gateway identity from child-device identity, and local continuity from upstream visibility. Without those distinctions, distributed edge infrastructure may appear connected while still being difficult to trust, maintain, or reconstruct after failure.
Implementation Pattern
A rigorous gateway and aggregation implementation begins by defining the boundary responsibilities of each intermediary layer. Engineers should specify which devices are parented by which gateways, which protocols are translated, which metadata must survive translation, which data are buffered, which streams are aggregated, which state is exposed upstream, what local policies are enforced, and how degraded connectivity is handled.
| Artifact | Purpose | Typical Format |
|---|---|---|
| Gateway manifest | Defines gateway identity, hardware, runtime, location, downstream devices, and upstream targets | YAML, JSON, asset inventory |
| Child-device registry | Maps downstream devices to gateway parents, protocols, identities, and expected heartbeat behavior | CSV, SQL, JSON |
| Protocol map | Defines how local protocol fields map to normalized telemetry or command schemas | YAML, JSON Schema, mapping table |
| Aggregation contract | Defines how raw device streams become site-level state, quality bands, alarms, or summaries | YAML, SQL, analytics config |
| Buffer policy | Defines queue limits, retention, replay order, backpressure, priority, and drop behavior | YAML, runtime config |
| Replay and deduplication policy | Defines event IDs, replay ordering, duplicate handling, late-arrival handling, and idempotency | YAML, stream contract, event schema |
| Selective forwarding policy | Defines what stays local, what is summarized, what is forwarded immediately, and what is uplinked later | YAML, stream config, policy-as-code |
| Local policy manifest | Defines local rules, authority, policy versions, degraded-mode actions, and decision logging | YAML, JSON, ruleset manifest |
| Site-state schema | Defines derived site-level state, freshness, missing-device counts, quality indicators, and lineage | SQL, JSON Schema, event schema |
| Gateway security profile | Defines identity, certificates, credentials, trust boundaries, attestation, and update integrity | YAML, IAM policy, certificate inventory |
| Gateway telemetry schema | Defines health, queue depth, protocol errors, device availability, sync lag, and recovery events | SQL, JSON Schema, event stream |
The implementation goal is to make intermediary behavior inspectable. Engineers should be able to reconstruct which gateway saw which device, when the measurement was acquired, how it was translated, whether it was buffered, how it contributed to site-level state, whether the upstream system received it late, and whether any local policy acted on it before central visibility.
Research-Grade Framing: Gateways as Evidence Infrastructure
A research-grade gateway is not only a transport component. It is evidence infrastructure. It mediates what the rest of the system can later know about local reality: which device produced a signal, when it was acquired, how it was transformed, whether it was fresh, whether it passed validation, whether it was buffered, whether it was summarized, and whether it was forwarded or retained locally.
This framing matters because many distributed edge failures are not caused by total disconnection. They are caused by partial meaning loss. A cloud dashboard may continue receiving data while child-device identity has collapsed. A site summary may continue updating while half the downstream devices are stale. A gateway may reconnect and replay buffered records while upstream systems misinterpret delayed data as current state. A protocol translator may normalize values while discarding units, calibration state, or quality flags.
A mature gateway and aggregation architecture therefore asks not only “Did the message arrive?” but “Did the message preserve enough meaning to remain trustworthy?”
| Evidence Dimension | Question | Required Gateway / Aggregation Evidence |
|---|---|---|
| Identity | Can the system trace the event to the original child device? | Child-device ID, parent gateway ID, protocol address, registry version |
| Time | Can the system distinguish acquisition, receipt, aggregation, upload, and ingestion time? | Event-time lineage, replay sequence, upstream ingestion time |
| Quality | Does the system know whether the input was valid, stale, missing, estimated, or low confidence? | Quality flags, freshness, sensor health, protocol error context |
| Transformation | Can engineers inspect how protocol fields became normalized fields? | Protocol map version, unit conversion, schema validation record |
| Aggregation | Can the site summary be traced back to contributing devices and time windows? | Aggregation contract, input count, missing-child count, lineage completeness |
| Forwarding | Can engineers explain why something was forwarded, summarized, retained, or dropped? | Selective forwarding rule, buffer policy, priority, drop reason |
| Recovery | Can the system reconstruct behavior after outage, replay, or gateway restart? | Recovery log, replay window, duplicate handling, gap report |
This evidence-centered view makes gateways and aggregation layers part of the system’s epistemic foundation. They determine not only what flows upward, but what remains knowable about the local system after the fact.
Formal Model: Device Streams, Gateway State, Aggregation, and Uplink
A useful formal model separates device-level observations, gateway-local state, aggregation logic, and upstream synchronization. Let \(z_{i,t}\) represent the observation from child device \(i\) at time \(t\), \(g_t\) represent gateway-local state, \(s_t\) represent derived site-level state, and \(u_t\) represent upstream uplink output.
g_{t+1} = G(g_t, z_{1:n,t}, q_t, p_t)
\]
Interpretation: Gateway state evolves from prior gateway state, observations from downstream devices, queue or buffer state \(q_t\), and local policy \(p_t\). The gateway is an active intermediary, not merely a wire.
s_t = A(z_{1:n,t}, h_{1:n,t}, \ell_{1:n,t})
\]
Interpretation: Aggregated site state \(s_t\) is derived from device observations, health indicators \(h_{1:n,t}\), and lineage records \(\ell_{1:n,t}\). Strong aggregation includes data quality and device availability, not only values.
u_t = F(s_t, q_t, b_t, \pi_t)
\]
Interpretation: Upstream output \(u_t\) is produced by selective forwarding function \(F\), based on site state, queue state, bandwidth condition \(b_t\), and forwarding policy \(\pi_t\).
A_{\mathrm{uplink}} = t_{\mathrm{upstream\ ingest}} – t_{\mathrm{local\ acquisition}}
\]
Interpretation: Uplink age measures how old a locally acquired event is when interpreted upstream. Store-and-forward systems should preserve acquisition time, not only upload time.
This formal structure prevents a common mistake: treating the gateway as an invisible transport element. In real distributed edge systems, gateways and aggregation layers transform availability, identity, timing, state, evidence, and meaning.
What Are Gateways, Aggregation Layers, and Distributed Edge Infrastructure?
Gateways are intermediary nodes that connect downstream devices to broader systems, often handling protocol conversion, message routing, buffering, local processing, and secure communication. Aggregation layers are the logical or physical layers that collect device-level outputs and transform them into higher-order state such as site summaries, combined telemetry, local alarms, delayed-device awareness, or qualified event streams. Distributed edge infrastructure is the wider fabric of these components across the edge continuum.
What makes these layers distinct from raw device networking is that they create local operational meaning. A gateway is not valuable only because it relays packets. It becomes valuable when it allows many devices to participate in a local system that can continue to coordinate, filter, store, or act even when upstream services are degraded or absent.
An aggregation layer is not just a larger gateway. Its purpose is not merely to connect, but to synthesize. It creates a structured local representation of conditions from many downstream sources. That difference matters because the gateway primarily manages interaction across boundaries, while the aggregation layer primarily manages interpretation across many signals.
Gateways as Boundary and Translation Devices
A gateway is best understood as a boundary device. It sits at the edge between one environment and another: between constrained and less constrained networks, between field protocols and cloud protocols, between downstream devices and upstream policy, or between local autonomy and remote coordination.
This boundary role has several architectural consequences. First, the gateway often terminates one trust or transport model and originates another. Second, it may be the point where local identities are related to upstream identities. Third, it can normalize or translate protocols so that heterogeneous downstream devices can be incorporated into a more coherent site system.
The gateway therefore answers a practical question: how do unlike devices participate in one larger architecture without forcing every endpoint to speak the same language, carry the same trust burden, maintain the same compute capacity, or preserve the same network relationship?
Good gateway design preserves semantic context across the boundary. A device reading should not lose its physical unit, acquisition time, calibration state, device identity, quality flag, or lineage simply because it passed through protocol translation. The translation boundary should make systems more interoperable without making them less trustworthy.
Aggregation Layers and Site-Level Meaning
Aggregation layers matter because device-level signals are often too granular, numerous, or context-poor to be useful on their own. A site may contain dozens, hundreds, or thousands of sensors, controllers, and downstream devices. What operators often need is not every raw event, but a structured view of local state: current health, unusual conditions, delayed devices, aggregated measurements, quality bands, local trends, and known data gaps.
A good aggregation layer therefore does more than sum or batch data. It preserves freshness, distinguishes raw from derived values, qualifies local state with device availability or quality context, and creates a site-level representation that is more useful than a loose collection of downstream streams.
This is the core distinction from the gateway. The gateway makes communication and coordination possible. The aggregation layer turns many device outputs into something that can be understood and acted upon at the level of a site, subsystem, or operation.
| Aggregation Concern | Weak Pattern | Stronger Pattern |
|---|---|---|
| Freshness | Aggregate whatever values are present | Include sample age, missing-device count, and stale-data flags |
| Lineage | Expose only final summary | Track which devices, timestamps, and transformations contributed |
| Quality | Treat all inputs as equally valid | Include sensor health, calibration, confidence, and protocol error context |
| Timing | Use gateway upload time as event time | Preserve local acquisition time, aggregation time, and upstream ingestion time |
| Interpretability | Compress raw streams into opaque scores | Provide derived state with enough metadata for review and debugging |
Aggregation is strongest when it improves meaning without erasing evidence.
Distributed Edge Topologies and Parent–Child Relationships
Distributed edge infrastructure is shaped by topology. Some systems use a single gateway with many children. Others use nested gateways, peer-assisted local infrastructure, site hierarchies, regional aggregation layers, or local edge servers that connect field controllers to upstream services. These topology choices determine failure modes, coordination costs, trust boundaries, and operational visibility.
A single gateway can simplify management but create a concentration point. A nested hierarchy can improve containment and locality while increasing complexity. A peer topology can improve resilience while making coordination and conflict resolution harder. A site-level aggregation tier can provide stronger local meaning but may become a new operational dependency.
| Topology | Strength | Risk | Best Fit |
|---|---|---|---|
| Single gateway with many child devices | Simple parent-child management and local buffering | Concentration point and possible bottleneck | Small sites, constrained IoT fleets, simple field deployments |
| Nested gateways | Local containment and hierarchical scaling | More complex routing, trust, and lineage | Large industrial or remote infrastructure systems |
| Site aggregation layer above gateways | Creates site-level state across multiple local systems | Can hide device-level context if poorly designed | Facilities, campuses, plants, logistics systems |
| Peer-assisted edge mesh | Resilience and local redundancy | Conflict resolution and consistency complexity | Remote systems, mobile systems, intermittently connected environments |
| Regional aggregation layer | Multi-site coordination with lower latency than central cloud | Additional operational layer to manage and secure | Distributed infrastructure, utilities, transportation, environmental monitoring |
Strong architectures choose topology in relation to physical layout, trust boundaries, bandwidth constraints, latency needs, and what must continue during partition or outage. Topology is not a diagramming detail. It is a design decision about operational responsibility.
Buffering, Store-and-Forward, and Intermittent Connectivity
One of the core jobs of gateways and aggregation layers is to absorb discontinuity. Field networks sleep, radio paths degrade, cloud links fail, downstream devices appear intermittently, and local systems may need to continue even when upstream visibility is delayed. In these conditions, buffering is not merely a performance feature. It is part of the architecture of continuity.
Store-and-forward logic is especially important because it preserves the distinction between local acquisition time and upstream ingestion time. A gateway that backfills without preserving ordering, timestamps, lineage, and local state can produce an upstream system that looks current while actually reflecting delayed local history.
Good buffering design therefore answers several questions: how much can be queued, which records have priority, what happens under backpressure, what is dropped first, what must never be dropped, how replay order is preserved, how duplicates are handled, and how upstream systems distinguish delayed records from current ones.
| Buffering Concern | Engineering Requirement | Operational Signal |
|---|---|---|
| Queue depth | Bounded storage with known high-water marks | Buffer backlog, high-watermark events |
| Replay order | Preserve acquisition order or event-time ordering where required | Replay sequence ID, duplicate count |
| Retention | Define how long raw, summary, and incident records survive locally | Oldest buffered record age |
| Backpressure | Define local behavior when upstream is slow or unavailable | Uplink pressure, drop count, degraded mode |
| Priority | Separate routine telemetry from safety, incident, or diagnostic evidence | Priority queue occupancy |
| Lineage | Preserve acquisition, gateway receipt, aggregation, and upload times | State age, sync lag, lineage completeness |
Intermediate layers deserve explicit architectural treatment because continuity is not automatic. It has to be designed, bounded, measured, and recovered.
Replay Semantics, Deduplication, and Conflict Handling
Store-and-forward systems need explicit replay semantics. When a gateway reconnects after an outage, upstream systems may suddenly receive old events, duplicate events, out-of-order events, or events produced under a policy version that has since changed. Without replay discipline, recovery can corrupt the upstream picture of local reality.
A strong gateway architecture should define whether event processing is at-most-once, at-least-once, or effectively-once through idempotency keys. It should distinguish event time from processing time and ingestion time. It should preserve sequence IDs, batch IDs, child-device IDs, policy versions, and buffer-window metadata. It should also make late arrivals visible rather than allowing them to silently alter current state.
| Replay Issue | Risk | Design Response |
|---|---|---|
| Duplicate replay | Upstream counts the same local event twice | Idempotency key, event ID, replay batch ID |
| Out-of-order arrival | Derived state is computed in incorrect sequence | Event-time ordering, sequence number, watermarking |
| Late data | Old data overwrites or distorts current state | Late-arrival policy, state correction record, review flag |
| Policy-version mismatch | Events produced under old local policy are interpreted under new central policy | Decision-used policy version and policy lineage |
| Partial replay | Some buffered data arrive while other data are lost or retained | Gap detection, batch completeness flag, buffer-loss record |
| Conflict with upstream state | Cloud view and replayed local evidence disagree | Reconciliation status, preserve local evidence, add cloud interpretation |
Recovery should add evidence, not erase it. A mature replay architecture preserves the history of what happened locally, when it became visible upstream, and how disagreements were resolved.
Protocol Mediation and Heterogeneous Device Fleets
Most real edge deployments are heterogeneous. They mix sensors, legacy controllers, field buses, industrial protocols, IP-based services, proprietary device interfaces, and cloud-facing APIs. Gateways often exist because no single end-to-end protocol model is realistic.
This means gateways are often protocol mediators as much as compute hosts. They can bridge differences in addressing, trust, scheduling, data representation, message expectations, timing guarantees, and error behavior. But mediation is not free. Every translation risks losing context or introducing hidden assumptions.
Strong gateway design therefore aims for interoperability without epistemic loss. Local meanings, timestamps, units, data quality, calibration state, device identity, and protocol error context should survive the act of translation as much as possible. Otherwise, the system becomes more connected but less trustworthy.
| Protocol Mediation Issue | Risk | Design Response |
|---|---|---|
| Unit mismatch | Values are normalized incorrectly or interpreted inconsistently | Unit map, schema validation, physical-unit metadata |
| Timestamp loss | Upload time replaces acquisition time | Preserve acquisition, gateway receipt, aggregation, and ingestion timestamps |
| Identity collapse | Many child devices appear as one gateway source | Parent-child registry and child-device identity propagation |
| Quality flag loss | Derived systems cannot distinguish good, stale, estimated, or invalid data | Quality and confidence fields in normalized schema |
| Protocol error hiding | Upstream systems see missing or smooth data without local error context | Protocol error logs and health telemetry |
| Command semantic mismatch | Upstream command does not map safely to downstream device behavior | Command contract, validation, safety envelope, local rejection reason |
The gateway’s translation work should be auditable. Engineers should be able to inspect how a downstream device field became an upstream event, summary, command, alarm, or derived state.
Local Coordination, Policy, and Partial Autonomy
Gateways and aggregation layers increasingly do more than move data. They host rules, local policy, coordination logic, and partial autonomy. A gateway may coordinate many child devices. An aggregation layer may evaluate site-wide conditions that no individual downstream node can evaluate on its own.
This raises an important architectural distinction: a gateway may serve as the point where local policy is enforced, where multiple child devices are coordinated, or where local analytical or operational decisions are made before upstream review. Such local autonomy can improve responsiveness and resilience, but it also increases the interpretive authority of intermediary nodes.
The stronger the local decision role, the more important it becomes to preserve visibility into what the gateway or aggregation layer did, why it did it, and under what policy version or runtime state it acted. Local autonomy should be bounded by clear authority rules, observable decision logs, and degraded-mode behavior.
| Local Function | Why It Belongs at the Gateway or Aggregation Layer | Evidence Required |
|---|---|---|
| Local alarm generation | Operators may need immediate notice before cloud review | Trigger condition, input state, policy version, alarm time |
| Child-device coordination | No single device has full local context | Device set, coordination rule, affected devices, decision log |
| Selective uplink | Raw data volume may exceed bandwidth or storage budget | Forwarding rule, retained local evidence, summary lineage |
| Local inference | Latency, bandwidth, privacy, or outage conditions require local decision support | Model version, input window, confidence, fallback status |
| Degraded-mode operation | Local system must continue under upstream outage | Connectivity status, authority window, fallback action, recovery record |
Partial autonomy is useful only when it remains explainable. Gateways and aggregation services should produce enough evidence to show how local state was formed and how local decisions were made.
Gateway SLOs, Capacity Budgets, and Operational Limits
Gateway architecture becomes much more useful when its expected behavior is expressed as service-level objectives and capacity budgets. These do not need to mimic cloud-platform SLOs exactly. They should be tailored to edge conditions: device freshness, buffer durability, replay lag, protocol error tolerance, gateway CPU and memory pressure, local storage limits, and selective-uplink behavior.
Without explicit operating limits, gateway problems often appear only after downstream systems notice missing data or operators notice stale dashboards. A better design defines acceptable ranges before deployment and then monitors them continuously.
| Gateway Objective | Example SLO or Budget | Failure Implication |
|---|---|---|
| Child-device freshness | 95% of expected child devices report within freshness threshold | Site summaries may be stale or incomplete |
| Buffer durability | Gateway can retain priority events for defined outage window | Outage creates unrecoverable data gaps |
| Replay lag | Buffered priority events replay within target time after reconnect | Upstream recovery remains delayed or misleading |
| Protocol error rate | Error rate remains below threshold per protocol family | Mediation layer may be weakening data quality |
| Lineage completeness | Events preserve required identity, timing, quality, and transformation metadata | Debugging, audit, and incident reconstruction are compromised |
| Aggregation confidence | Site summaries disclose stale, missing, and low-confidence inputs | Operators may overtrust derived state |
| Selective-uplink context | Summaries retain enough evidence pointers for investigation | Bandwidth savings come at the cost of interpretability |
| Gateway runtime capacity | CPU, memory, disk, queue, and component health remain within thresholds | Gateway becomes a hidden bottleneck or failure concentrator |
These objectives turn gateway behavior into an engineering surface. The gateway is no longer simply “working” or “down.” It can be fresh or stale, bounded or overloaded, lineage-preserving or evidence-losing, synchronized or delayed, healthy or degraded.
Deployment, Management, and Operational Control Planes
Distributed edge infrastructure is sustainable only if it can be managed as infrastructure rather than as a collection of hand-maintained local machines. Gateways and aggregation layers create a management problem as well as a data problem. Component deployment, dependency control, update sequencing, health monitoring, certificate handling, trust-store management, configuration drift, and rollback all become part of the architecture.
A gateway that works technically but cannot be updated, observed, or governed at fleet scale is not a mature architectural layer. The same is true of aggregation services that cannot be versioned, audited, or recovered predictably.
A strong operational control plane should track gateway version, runtime health, local components, policy versions, downstream device availability, buffer pressure, security state, and deployment history. It should distinguish desired configuration, deployed configuration, active configuration, and decision-used configuration. Those distinctions matter when field behavior diverges from central assumptions.
Management discipline is especially important when gateways host local inference, protocol mediation, or policy enforcement. Once the gateway becomes part of the system’s decision fabric, it must be governed as an operational actor rather than treated as a passive connector.
Security, Trust, and Intermediary Risk
Intermediary infrastructure introduces special security risks because it often concentrates data, keys, policies, credentials, protocol access, and operational authority. A gateway that translates protocols, buffers data, and hosts local logic can become both an enabler of resilience and a high-value point of compromise.
Good architecture should therefore treat gateways and aggregation layers as trust boundaries with explicit identity, certificate, update, and observability requirements. In practice, every added intermediary increases local capability and local attack surface at the same time.
| Security Concern | Gateway / Aggregation Risk | Control Pattern |
|---|---|---|
| Child-device impersonation | Gateway accepts telemetry from unauthorized downstream devices | Device identity, allowlist, mutual authentication where feasible |
| Protocol abuse | Malformed or malicious local traffic crosses into upstream systems | Protocol validation, schema enforcement, rate limiting |
| Credential compromise | Gateway credentials expose many downstream devices or site data | Credential rotation, scoped identity, hardware root of trust where appropriate |
| Unsafe update | Compromised component changes gateway behavior | Signed updates, staged rollout, rollback, attestation |
| Buffered data exposure | Local retained data becomes an attractive target | Encryption at rest, retention limits, secure deletion, access control |
| Policy tampering | Local rules are changed without upstream governance | Signed policy bundles, version checks, local decision logging |
Strong edge design does not avoid intermediary layers, but it makes their trust role visible and governable. It should be possible to answer not just what these layers do, but what they are trusted to do and how that trust is maintained over time.
Worked Example: Industrial Site Gateway and Aggregation Layer
Consider an industrial site with motor controllers, temperature sensors, vibration sensors, power meters, and legacy field devices. A gateway receives device-level telemetry from several local protocols, normalizes it into a common schema, buffers records during outages, and forwards selected summaries upstream. A site aggregation layer combines multiple device streams into equipment-health and site-health summaries.
| Step | Gateway / Aggregation Behavior | Engineering Evidence |
|---|---|---|
| Device acquisition | Child devices report measurements over local protocols | Device ID, protocol address, acquisition time, quality flag |
| Protocol translation | Gateway maps local fields into normalized telemetry | Protocol map version, unit conversion, validation status |
| Buffering | Gateway queues events when upstream connectivity is degraded | Queue depth, priority, replay sequence, oldest record age |
| Aggregation | Aggregation layer produces site-level equipment-health state | Contributing device count, missing-device count, freshness, confidence |
| Selective uplink | Only summaries, incidents, and priority diagnostics are forwarded immediately | Forwarding policy, retained local evidence pointer, uplink time |
| Local policy action | Gateway or site layer triggers a local alarm before upstream review | Policy version, input state, reason code, local decision time |
| Reconnect and replay | Buffered records are replayed after connectivity returns | Replay batch ID, duplicate handling, gap report, reconciliation status |
| Upstream interpretation | Cloud or central platform stores summaries and compares across sites | Ingestion time, state age, site-state version, lineage completeness |
This example shows why gateways and aggregation layers are not passive infrastructure. They determine what the upstream system can know about the local site. If the gateway preserves acquisition time, identity, quality, policy version, and replay semantics, the system can recover meaning after outage. If it discards those details, the cloud may receive data while losing the ability to interpret what actually happened.
The architecture succeeds when local continuity and upstream understanding reinforce each other. The site can keep operating locally, while central systems can later reconstruct the local timeline, data quality, device availability, and aggregation logic.
Data and Configuration Artifacts
Gateway and aggregation systems become easier to build, test, and maintain when their assumptions are represented as data and configuration artifacts. Engineers should be able to inspect topology, protocol mediation, child-device identity, aggregation rules, buffer policy, local policy, trust boundaries, and telemetry schemas without relying only on architecture diagrams or tribal memory.
| Artifact | What It Captures | Engineering Purpose |
|---|---|---|
gateway_manifest.yml |
Gateway identity, location, runtime, hardware, upstream targets, and managed components | Makes the gateway a governed infrastructure asset |
child_device_registry.csv |
Downstream devices, protocols, addresses, expected heartbeats, and parent gateway | Preserves parent-child topology and device accountability |
protocol_map.yml |
Field-protocol mappings to normalized telemetry and command schemas | Makes translation auditable and testable |
aggregation_contract.yml |
How device-level streams become site-level state, alarms, quality bands, and summaries | Prevents opaque aggregation |
buffer_policy.yml |
Queue limits, priority, replay order, retention, backpressure, and drop behavior | Defines continuity under intermittent connectivity |
replay_policy.yml |
Event IDs, batch IDs, replay order, deduplication, late data, and gap reporting | Prevents recovery from corrupting upstream state |
selective_forwarding_policy.yml |
What is forwarded immediately, summarized, retained locally, or dropped under pressure | Links bandwidth, evidence, and operational visibility |
local_policy_manifest.yml |
Local rules, authority, policy version, decision logs, and degraded-mode behavior | Bounds partial autonomy |
gateway_slo.yml |
Freshness, buffer, replay, protocol error, lineage, and runtime health targets | Makes gateway reliability measurable |
site_state_schema.sql |
Derived site-level state, freshness, missing devices, quality indicators, and lineage | Makes aggregation queryable and auditable |
gateway_security_profile.yml |
Identity, certificates, trust stores, signing rules, attestation, and credential rotation | Protects intermediary trust boundaries |
gateway_event_schema.sql |
Telemetry for health, buffer backlog, protocol errors, child-device state, sync lag, and recovery | Makes gateway behavior observable |
The goal is not to force a single gateway platform. The goal is to make intermediary responsibility inspectable. If gateway and aggregation assumptions cannot be found in artifacts, they will be difficult to test, secure, operate, or recover after deployment.
Mathematical Lens: Aggregation, Freshness, Buffer Risk, and Gateway Load
A practical mathematical lens for gateways and aggregation layers begins with site-level aggregation. Device-level values become useful only when they are combined with freshness, health, quality, and lineage.
s_t = A(z_{1:n,t}, h_{1:n,t}, q_{1:n,t}, \ell_{1:n,t})
\]
Interpretation: Site state \(s_t\) is produced by aggregation function \(A\) using device observations \(z\), health indicators \(h\), quality indicators \(q\), and lineage records \(\ell\). Aggregation should not erase uncertainty or missing-device context.
F_i(t) = t_{\mathrm{now}} – t_{\mathrm{acquisition},i}
\]
Interpretation: Freshness \(F_i(t)\) measures the age of device \(i\)’s latest valid measurement. A site summary should expose freshness instead of treating stale values as current.
B_{t+1} = \min(B_{\max}, B_t + \lambda_t – \mu_t)
\]
Interpretation: Buffer backlog \(B_t\) grows when local event arrival rate \(\lambda_t\) exceeds uplink service rate \(\mu_t\). Backlog is a continuity signal and a risk signal.
\rho = \frac{\lambda}{\mu}
\]
Interpretation: Gateway utilization \(\rho\) compares incoming workload with service capacity. As \(\rho\) approaches or exceeds 1, latency, backlog, and data-loss risk increase.
C_{\mathrm{loss}} = w_1 D_{\mathrm{drop}} + w_2 A_{\mathrm{stale}} + w_3 E_{\mathrm{lineage}} + w_4 R_{\mathrm{replay}}
\]
Interpretation: Context-loss cost combines dropped data, stale aggregation, lineage error, and replay risk. A gateway can reduce bandwidth while increasing interpretive risk if context is discarded.
Q_{\mathrm{site}} = 1 – \left(\alpha M + \beta S + \gamma E + \delta L\right)
\]
Interpretation: A simple site-quality score can penalize missing devices \(M\), stale inputs \(S\), protocol errors \(E\), and lineage gaps \(L\). The exact weights should reflect the system’s operational risk.
The key engineering point is that gateway quality should be measured. Buffer backlog, stale-device rate, missing-child count, protocol error rate, replay lag, context-loss risk, lineage completeness, and site-state confidence should be operational signals, not hidden implementation details.
Python Workflow: Gateway Buffering, Aggregation, and Selective Uplink Simulation
The companion Python workflow should model a gateway with child devices, local buffering, aggregation, selective uplink, intermittent connectivity, and site-state reporting. The goal is to make gateway responsibilities executable rather than purely conceptual.
# Python Workflow: Gateway Buffering, Aggregation, and Selective Uplink Simulation
device_event = {
"device_id": device_id,
"gateway_id": gateway_id,
"local_acquisition_time": acquisition_time,
"measurement": measurement,
"quality": quality_flag,
"protocol": protocol_name
}
normalized_event = protocol_map.normalize(device_event)
gateway_buffer.enqueue(
normalized_event,
priority=forwarding_policy.priority(normalized_event)
)
site_state = aggregation_contract.compute(
events=gateway_buffer.recent_events(window_s=60),
child_health=child_device_registry.health_snapshot(),
preserve_lineage=True
)
uplink_batch = selective_forwarding_policy.select(
site_state=site_state,
buffer=gateway_buffer,
cloud_reachable=cloud_reachable,
bandwidth_available=bandwidth_available
)This workflow is useful because it separates device input, protocol normalization, buffering, aggregation, selective forwarding, and upstream synchronization. Engineers can test what happens when child devices go missing, cloud connectivity drops, uplink bandwidth shrinks, buffers fill, protocol errors rise, or aggregation includes stale data.
For production systems, the same workflow can be connected to logs from industrial gateways, MQTT brokers, edge runtimes, local databases, IoT platforms, cloud ingestion services, and site dashboards. The point is not only simulation, but evidence that gateways and aggregation layers are preserving meaning under operational stress.
R Workflow: Gateway Fleet Reliability and Aggregation Reporting
The companion R workflow should focus on reporting across gateways, sites, protocols, child devices, and aggregation layers. It can summarize buffer backlog, missing-child rate, stale-device rate, protocol errors, replay lag, selective-uplink rate, site-state quality, and gateway health.
# R Workflow: Gateway Fleet Reliability and Aggregation Reporting
gateway_summary <- gateway_events |>
dplyr::group_by(site_id, gateway_id, protocol_family) |>
dplyr::summarise(
events = dplyr::n(),
mean_buffer_backlog = mean(buffer_backlog, na.rm = TRUE),
max_replay_lag_s = max(replay_lag_s, na.rm = TRUE),
stale_device_rate = mean(device_freshness_s > freshness_threshold_s, na.rm = TRUE),
missing_child_rate = mean(child_device_status == "missing", na.rm = TRUE),
protocol_error_rate = mean(protocol_error == TRUE, na.rm = TRUE),
selective_uplink_rate = mean(forwarded_upstream == TRUE, na.rm = TRUE),
context_loss_events = sum(lineage_complete == FALSE, na.rm = TRUE),
.groups = "drop"
)This reporting layer helps distinguish isolated device failures from gateway or aggregation architecture problems. High stale-device rates may indicate weak child-device monitoring. High protocol errors may reveal mediation problems. Rising buffer backlog may indicate insufficient uplink capacity or poor selective-forwarding policy. Missing lineage may indicate that aggregation is improving summaries while weakening evidence.
For distributed edge systems, this kind of reporting is essential because intermediary failures often look like ordinary missing data until analyzed across gateways, protocols, sites, and time.
Systems Code: Gateways, MicroPython, TinyML, PYNQ, HDL, Bash, and Configuration
The companion repository should be useful to engineers because gateway and aggregation architecture crosses the full embedded and edge stack. It touches device code, protocol normalization, buffer management, local aggregation, telemetry schemas, gateway services, edge runtimes, constrained inference, hardware acceleration, HDL stream handling, and operational reporting.
| Folder | Engineering Role | Gateway / Aggregation Use |
|---|---|---|
python/ |
Simulation and workflow automation | Gateway buffering, aggregation, selective uplink, freshness, replay lag |
r/ |
Reporting and descriptive analytics | Gateway fleet reliability, protocol error, stale-device, and aggregation reporting |
sql/ |
Queryable gateway evidence | Child-device registry, gateway events, site state, buffer records, protocol errors |
c/ |
Constrained gateway and device-adjacent logic | Telemetry packet formation, buffer watermark, child heartbeat checking |
cpp/ |
Gateway runtime and state-machine abstraction | Protocol mediation, aggregation state, gateway health state machine |
rust/ |
Safe systems validation | Schema validation, protocol-map checks, buffer-policy validation, identity checks |
go/ |
Operational services and telemetry utilities | Gateway event router, local broker, uplink service, health API |
micropython/ |
Microcontroller prototypes | Child-device heartbeat and local telemetry prototype |
tinyml/ |
Constrained local inference | Gateway-side anomaly or device-health classification |
pynq/ |
FPGA-backed edge acceleration | Low-latency preprocessing, stream timestamping, buffer watermark acceleration |
hdl/ |
Hardware/software co-design | Telemetry framing, stream timestamping, buffer watermarks, sync pulses |
bash/ |
Repeatable workflow execution | Runs simulations, validates manifests, generates outputs and inventory |
config/ |
Machine-readable gateway metadata | Gateway manifests, protocol maps, aggregation contracts, buffer policies |
This stack matters because gateway and aggregation architecture is not created by a single product category. It is created by the way devices, protocols, buffers, local runtimes, data models, trust boundaries, and upstream systems preserve coherent responsibility across the edge continuum.
Testing and Validation
Gateway and aggregation systems should be validated under the conditions that make intermediary infrastructure necessary: heterogeneous devices, intermittent connectivity, protocol errors, downstream outages, buffer pressure, stale data, replay after disconnection, partial local autonomy, and upstream recovery.
A practical validation suite should answer these questions:
- Does the gateway preserve child-device identity, acquisition time, quality flags, and physical units during protocol translation?
- Can downstream devices be mapped reliably to parent gateways, protocols, addresses, and expected heartbeat behavior?
- Does the aggregation layer expose stale-device, missing-device, and quality information rather than hiding it inside summaries?
- Does buffering preserve order, lineage, priority, and replay semantics under upstream outage?
- Does replay preserve idempotency, duplicate handling, sequence order, and late-arrival metadata?
- Does selective forwarding preserve enough context for upstream interpretation?
- Are local policies versioned, signed where appropriate, and logged when used for decisions?
- Can the gateway reject malformed or unauthorized downstream traffic?
- Are buffer overflow, cloud outage, gateway restart, downstream device dropout, and protocol error scenarios tested?
- Can the system distinguish local acquisition time, gateway receipt time, aggregation time, upload time, and upstream ingestion time?
- Can operators reconstruct what happened after reconnect, replay, or incident recovery?
Testing should include negative cases. Engineers should deliberately test missing child devices, duplicate events, stale telemetry, invalid protocol fields, queue overflow, upstream outage, bad certificates, unsigned component updates, malformed commands, local policy drift, and replay conflicts. Gateway failures are dangerous when they make the system look connected while silently degrading timing, identity, quality, or evidence.
Operational Signals and Gateway Observability
Gateway observability is the ability to understand whether intermediary infrastructure is preserving local meaning, not merely whether it is online. A gateway can be reachable while child devices are missing, buffers are full, protocol errors are rising, data are stale, or aggregation is hiding quality problems.
| Signal | What It Reveals | Why Engineers Need It |
|---|---|---|
| Child-device heartbeat | Whether downstream devices are present and reporting | Prevents aggregation from hiding missing endpoints |
| Device freshness | Age of latest valid reading per child device | Distinguishes current state from stale local memory |
| Protocol error rate | Local bus, driver, parser, mapping, or device communication problems | Identifies mediation failures |
| Buffer backlog | Queued local events waiting for forwarding | Reveals uplink pressure and continuity risk |
| Replay lag | Delay between local acquisition and upstream ingestion | Prevents delayed records from appearing current |
| Duplicate replay rate | How often events are replayed or received more than once | Tests idempotency and replay controls |
| Lineage completeness | Whether events preserve device identity, timing, quality, and transformations | Supports debugging, audit, and incident reconstruction |
| Aggregation quality score | How much site state depends on stale, missing, or low-confidence inputs | Prevents overconfident summaries |
| Selective uplink rate | Share of local records sent upstream | Connects bandwidth savings to interpretability risk |
| Gateway runtime health | CPU, memory, disk, component, and runtime state | Identifies infrastructure pressure before data loss |
| Policy version | Which local rules are active or decision-used | Supports governance of partial autonomy |
| Trust state | Certificate, credential, attestation, and update validity | Protects intermediary trust boundaries |
| Recovery completeness | Whether buffered events, state, and lineage converged after outage | Supports operational confidence after disruption |
Engineers should design these signals before deployment. If the system cannot reconstruct child-device state, gateway translation, buffer behavior, aggregation quality, and upstream replay, then distributed edge behavior becomes difficult to trust.
Common Failure Modes
Gateway and aggregation systems fail in predictable ways because intermediary layers mediate identity, timing, protocol, storage, and meaning. Engineers should design architecture, tests, and observability around these failure modes from the beginning.
- Identity collapse: multiple child devices appear upstream as one gateway source without preserved child identity.
- Timestamp loss: upstream systems treat gateway upload time as measurement acquisition time.
- Opaque aggregation: site-level summaries hide stale devices, missing devices, or low-quality inputs.
- Protocol context loss: translation discards units, calibration state, quality flags, or local error conditions.
- Buffer overflow: gateway storage fills during outage or uplink pressure, causing silent loss.
- Replay confusion: delayed events are ingested as if they reflect current state.
- Duplicate event amplification: replay or retry logic causes upstream double counting.
- Gateway concentration failure: many downstream devices become unavailable because one gateway fails.
- Policy drift: local gateway rules differ from upstream approved policy without clear evidence.
- Security concentration: gateway credentials or trust stores expose many downstream devices.
- Management drift: gateway components, dependencies, certificates, or configurations diverge across sites.
- Selective-uplink opacity: upstream systems receive summaries without enough retained local context.
- Unbounded local autonomy: gateway decisions continue without authority windows, logging, or recovery procedures.
A mature gateway architecture does not assume these failures can be eliminated. It makes them detectable, bounded, testable, recoverable, and reviewable.
Trade-Offs in Gateway and Aggregation Design
Gateways, aggregation layers, and distributed edge infrastructure are defined by trade-offs that cannot all be optimized at once. More local coordination can improve latency and resilience but increase management burden and concentration risk. More aggregation can reduce bandwidth and improve site-level meaning but risk losing raw context. Richer gateway logic can improve local autonomy but can also make field behavior harder to interpret or audit.
The right design depends on purpose. A transparent gateway for downstream device connectivity, a local industrial edge server, a site-level aggregation tier, a multi-hop remote infrastructure hierarchy, and a managed edge runtime all answer different problems.
Good architecture is proportional. It gives each intermediary layer only the responsibilities it can sustain well and makes those responsibilities explicit. A gateway should not become an undocumented local brain. An aggregation layer should not create polished summaries that hide uncertainty. A buffer should not preserve continuity by destroying timing meaning. A protocol translator should not produce interoperability by erasing local context.
The central discipline is not adding more layers. It is assigning responsibility, preserving evidence, and making intermediary behavior observable across the edge continuum.
Applications in Embedded and Edge Systems
Industrial site gateway. In industrial settings, gateways often collect telemetry from many controllers or devices, host local protocol mediation, and maintain site continuity when upstream systems are degraded. The gateway is less a simple bridge than a local operational boundary.
Site aggregation tier. In plants, campuses, or facilities, aggregation layers often sit above gateways and below cloud services, combining multiple local streams into site-level state. This may include delayed-device awareness, rolled-up environmental conditions, combined alarm views, local health dashboards, and quality-qualified operational summaries.
Downstream IoT gateway. In IoT fleets, a gateway may serve as the parent for child devices, carrying cloud connectivity and identity mediation for devices that cannot or should not connect directly. Here the gateway’s role is architectural containment: it reduces complexity at the edge of the fleet.
Remote infrastructure hierarchy. In utilities, environmental monitoring, transportation, and remote assets, gateways and aggregation nodes often exist to preserve continuity under intermittent connectivity. Their main value is not simply low latency, but survivability: the system remains locally coherent even when upstream visibility is delayed.
Distributed edge runtime. In broader edge architectures, intermediary nodes host components, rules, and services that coordinate many downstream devices while still syncing with central control planes. This pattern turns the gateway or local edge server into a managed execution layer, not only a transport layer.
The unifying pattern is intermediary responsibility: gateways and aggregation layers make local device ecosystems operationally coherent before they become upstream data streams.
Engineer Checklist
- Define which functions belong to field devices, gateways, aggregation layers, site-edge systems, and upstream platforms.
- Maintain a child-device registry with gateway parent, protocol, identity, address, heartbeat expectation, and firmware version.
- Preserve acquisition time, gateway receipt time, aggregation time, upload time, and upstream ingestion time.
- Document protocol maps so units, quality flags, calibration state, and device identity survive translation.
- Define aggregation contracts that include freshness, missing-device count, lineage, confidence, and quality context.
- Set buffer policies for queue size, priority, replay order, retention, drop behavior, and backpressure.
- Define replay semantics, idempotency keys, late-arrival behavior, duplicate handling, and gap reporting.
- Use selective forwarding policies that preserve interpretability, not only bandwidth efficiency.
- Log local gateway decisions with policy version, input state, reason code, confidence, and authority status.
- Track gateway runtime health, protocol error rate, buffer backlog, child-device availability, replay lag, and lineage completeness.
- Protect gateways as trust boundaries with identity, credential rotation, signed updates, attestation, and scoped access.
- Test outage, buffer overflow, protocol failure, missing child devices, malformed telemetry, replay, duplicate events, and recovery.
- Confirm that aggregation improves site-level meaning without erasing raw evidence needed for debugging or incident review.
This checklist is intentionally practical. Gateways and aggregation layers become trustworthy when engineers can explain what each intermediary saw, how it translated local signals, what it buffered, what it summarized, what it forwarded, what it retained, and how it recovered when connectivity or device availability degraded.
GitHub Repository
This article is supported by a companion workflow that models gateway and aggregation architecture using child-device registries, protocol maps, buffer policies, replay semantics, aggregation contracts, selective forwarding, site-state schemas, gateway health telemetry, store-and-forward simulation, and fleet-level reporting.
Where This Fits in the Series
This article extends the foundation established in Edge Computing Architectures, Distributed Monitoring Systems, Internet of Things Sensor Architectures, and Edge Analytics and Local Data Processing by focusing on the intermediary layers that connect device-level systems to site-level and cloud-level architectures.
It also connects directly to Cloud-Edge Coordination and Hybrid Architectures, Device Lifecycle Management and Over-the-Air Updating, Standards, Interoperability, and Governance in Edge Infrastructure, and Security in Embedded and Edge Systems Architecture, where intermediary trust, lifecycle control, standardization, and hybrid coordination become operational requirements.
Related articles
- Embedded and Edge Systems: Real-Time Computing in Devices, Sensors, and Infrastructure
- Edge Computing Architectures
- Distributed Monitoring Systems
- Internet of Things Sensor Architectures
- Edge Analytics and Local Data Processing
- Edge AI and On-Device Machine Learning
- Cloud-Edge Coordination and Hybrid Architectures
- Security in Embedded and Edge Systems Architecture
Further reading
- LF Edge (2020) Overview of the LF Edge Taxonomy and Framework. Available at: https://lfedge.org/wp-content/uploads/sites/24/2020/07/LFedge_Whitepaper.pdf
- LF Edge (2022) Diving Deeper into the LF Edge Taxonomy and Projects. Available at: https://lfedge.org/wp-content/uploads/sites/24/2022/06/LFEdgeTaxonomyWhitepaper_062322.pdf
- IETF (2024) RFC 9556: Internet of Things (IoT) Edge Challenges and Functions. Available at: https://datatracker.ietf.org/doc/html/rfc9556
- AWS (n.d.) AWS IoT Greengrass. Available at: https://docs.aws.amazon.com/greengrass/v2/developerguide/what-is-iot-greengrass.html
- AWS (n.d.) Configure a SiteWise Edge gateway. Available at: https://docs.aws.amazon.com/iot-sitewise/latest/userguide/configure-gateway-ggv2.html
- Microsoft (2026) Azure IoT Edge documentation. Available at: https://learn.microsoft.com/en-us/azure/iot-edge/
- Microsoft (2026) Use Azure IoT Edge as a gateway for downstream devices. Available at: https://learn.microsoft.com/en-us/azure/iot-edge/iot-edge-as-gateway
References
- AWS (n.d.) AWS IoT Greengrass. Available at: https://docs.aws.amazon.com/greengrass/v2/developerguide/what-is-iot-greengrass.html
- AWS (n.d.) AWS-provided components for Greengrass. Available at: https://docs.aws.amazon.com/greengrass/v2/developerguide/public-components.html
- AWS (n.d.) IoT SiteWise processor component. Available at: https://docs.aws.amazon.com/greengrass/v2/developerguide/iotsitewise-processor-component.html
- AWS (n.d.) Configure a SiteWise Edge gateway. Available at: https://docs.aws.amazon.com/iot-sitewise/latest/userguide/configure-gateway-ggv2.html
- IETF (2024) RFC 9556: Internet of Things (IoT) Edge Challenges and Functions. Available at: https://datatracker.ietf.org/doc/html/rfc9556
- LF Edge (2020) Overview of the LF Edge Taxonomy and Framework. Available at: https://lfedge.org/wp-content/uploads/sites/24/2020/07/LFedge_Whitepaper.pdf
- LF Edge (2022) Diving Deeper into the LF Edge Taxonomy and Projects. Available at: https://lfedge.org/wp-content/uploads/sites/24/2022/06/LFEdgeTaxonomyWhitepaper_062322.pdf
- Microsoft (2026) Azure IoT Edge documentation. Available at: https://learn.microsoft.com/en-us/azure/iot-edge/
- Microsoft (2026) Azure IoT Edge runtime and architecture explained. Available at: https://learn.microsoft.com/en-us/azure/iot-edge/iot-edge-runtime
- Microsoft (2026) Use Azure IoT Edge as a gateway for downstream devices. Available at: https://learn.microsoft.com/en-us/azure/iot-edge/iot-edge-as-gateway
- Microsoft (2026) Create transparent gateway device using Azure IoT Edge. Available at: https://learn.microsoft.com/en-us/azure/iot-edge/how-to-create-transparent-gateway