
Last Updated May 28, 2026
Biomolecules and the chemical basis of life examine how living systems are built from carbohydrates, lipids, proteins, nucleic acids, water, ions, cofactors, and metabolites whose interactions make cellular structure, metabolism, heredity, regulation, adaptation, and biological continuity possible. Living systems are not made from arbitrary matter. They depend on a distinctive chemical architecture: carbon-based molecules operating in water, organized by membranes, shaped by energy flow, regulated through enzymes and signals, and preserved through nucleic-acid information. Biomolecules therefore provide the chemical substrate through which life stores energy, builds structure, catalyzes reactions, transmits information, responds to environments, and persists across generations.
This article develops Biomolecules and the Chemical Basis of Life as a foundational article within the Biology knowledge series. It treats biomolecules not as a simple inventory of molecular classes, but as a framework for understanding how chemical structure becomes biological function. Carbohydrates store energy, build extracellular structures, and support recognition. Lipids form membranes, store energy, and mediate signaling. Proteins catalyze reactions, carry signals, build structures, transport substances, and regulate cellular behavior. Nucleic acids store, transmit, and express hereditary information. Smaller molecules, ions, cofactors, and metabolites connect these macromolecular systems into living networks.
Main Library
Publications
Article Map
Biology
Related Topic
Chemistry
Related Topic
Earth Science
Related Topic
Environmental Science
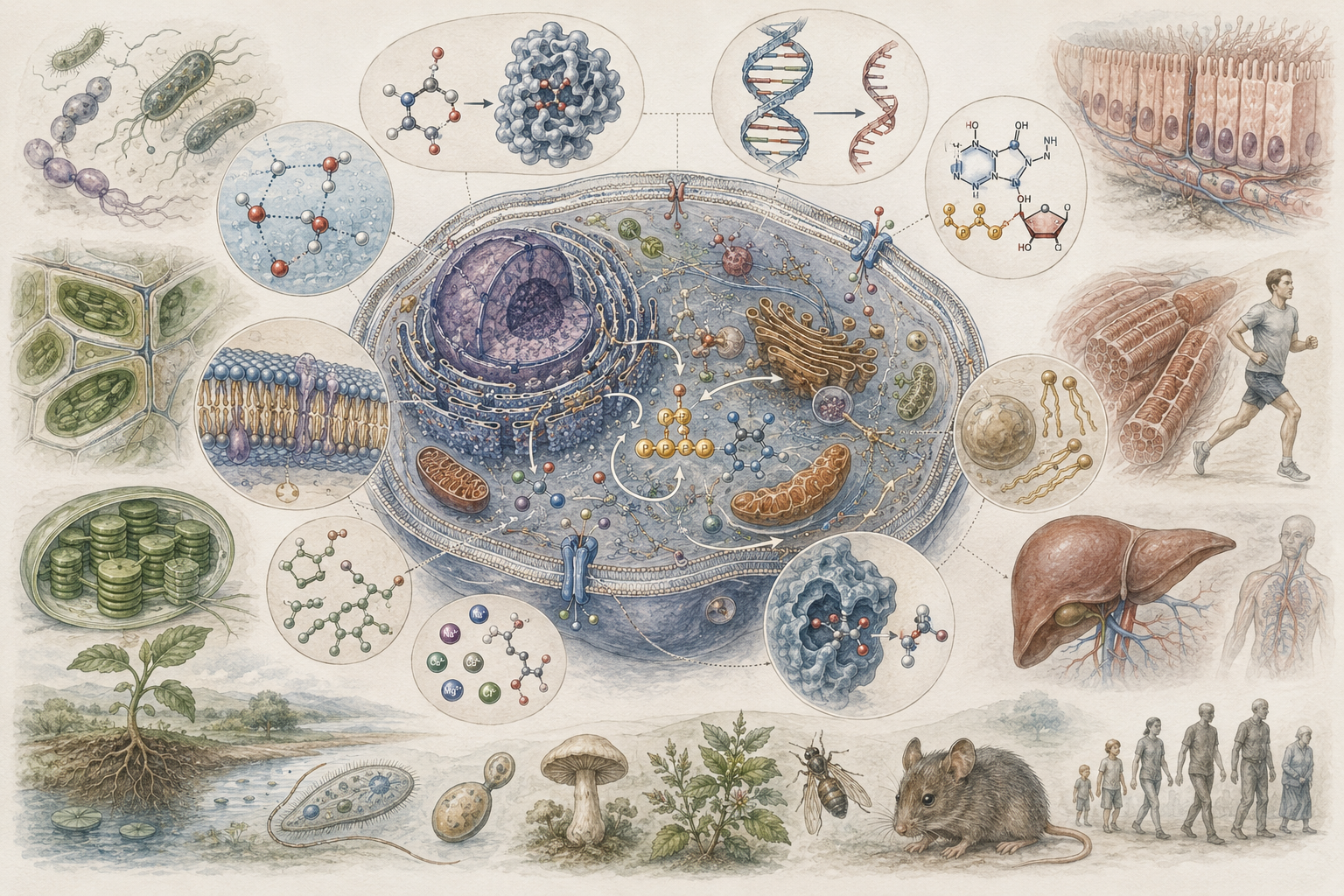
The article develops biomolecular biology across carbon chemistry, water, functional groups, macromolecules, monomers, polymers, carbohydrates, lipids, proteins, nucleic acids, metabolism, catalysis, membranes, heredity, molecular recognition, biomolecular turnover, ecological nutrient cycling, marine biochemistry, disease mechanisms, biotechnology, bioinformatics, molecular data, and computational life science. It shows why the chemical basis of life is not separate from cell theory, metabolism, molecular biology, ecology, medicine, or systems biology, but foundational to all of them.
The article also extends biomolecular biology into quantitative and computational analysis through molecular composition accounting, carbon-to-nitrogen ratios, amino-acid composition, nucleotide GC content, Michaelis-Menten enzyme kinetics, diffusion and molecular transport, ligand-binding curves, polymerization mass balances, biomolecular abundance normalization, sequence-feature extraction, macromolecule condition scoring, R workflows, Python workflows, SQL provenance structures, and a linked full-stack GitHub repository containing Python, R, Julia, Fortran, Rust, Go, C, C++, SQL, notebooks, data files, validation notes, and reproducibility documentation.
Why life has a chemical basis
Biology ultimately studies living systems, but living systems are made possible by chemistry. Cells, tissues, organisms, populations, and ecosystems do not float above the chemical world. They are chemically organized systems whose structures and functions depend on molecules with specific properties: bonds, shapes, charges, solubilities, interaction patterns, reaction rates, and energetic constraints. Biomolecules provide the basis for energy storage, membrane boundaries, catalysis, signaling, information storage, molecular recognition, inheritance, and biological repair. Without them, there would be no cell structure, no metabolism, no regulation, and no continuity of life across generations.
Yet biology is not simply chemistry with additional terminology. The chemical basis of life matters because biomolecules do not merely exist in isolation. They are organized within cells and living systems in ways that support regulated process. A protein does not matter only as a chain of amino acids. It matters as an enzyme, receptor, scaffold, transporter, motor, antibody, or signaling element within a coordinated biological context. DNA does not matter only as a polymer. It matters because it stores and transmits biological information in cells and lineages. Lipids do not matter only as hydrophobic molecules. They matter because they create selective boundaries and organized biological space.
The chemical basis of life is therefore not a reduction of biology to chemistry, but a recognition that living order depends on distinctive chemical organization. Biology asks how molecules are built, how they interact, how they are transformed, how they are inherited, how they are regulated, and how they become functional within cells, organisms, and ecosystems. Biomolecules are the materials through which living order becomes physically possible.
This distinction is important. A molecule can be chemically interesting without being biologically organized. A metabolite, polymer, ion, or lipid becomes biologically meaningful when it participates in regulated pathways, cellular compartments, energy transformations, information systems, ecological exchanges, or evolutionary continuity. Biomolecular biology therefore sits at the meeting point of chemistry, cell biology, physiology, ecology, medicine, and systems science.
Water, carbon, and the conditions for biological chemistry
Life’s chemistry depends fundamentally on the properties of water and carbon. Water provides the medium in which most biological reactions occur, supports transport and solvation, buffers temperature, and helps shape molecular behavior through polarity, hydrogen bonding, ionization, and hydrophobic effects. Carbon makes biological complexity possible because it forms stable covalent bonds with itself and with hydrogen, oxygen, nitrogen, sulfur, and phosphorus, allowing a vast range of molecular architectures. These features make carbon-based chemistry especially suited to the formation of polymers, membranes, metabolites, and information-carrying molecules.
The significance of water and carbon is not only chemical but biological. Membrane structure depends on interactions between water and amphipathic lipids. Protein folding depends strongly on aqueous conditions and hydrophobic collapse. Metabolism relies on solution chemistry, enzyme-substrate interactions, transport gradients, and proton transfers. Nucleic-acid structure depends on hydrogen bonding, base stacking, charged backbones, and hydration. The chemical basis of life therefore begins with a physical environment in which biomolecular organization becomes possible.
Water also matters because biological molecules are not simply dissolved in it as passive solutes. Water participates in hydrolysis and condensation reactions, mediates noncovalent interactions, structures hydration shells around ions and macromolecules, and shapes the energetic costs of folding, binding, and membrane formation. The cell is an aqueous system, but it is not a dilute textbook beaker. It is crowded, compartmentalized, ion-rich, metabolically active, and full of macromolecular surfaces.
Life is chemically specific not only because of what molecules it uses, but because of the medium and constraints under which those molecules operate. Biomolecules function in water, across membranes, within compartments, under pH constraints, in the presence of ions and cofactors, and through energy-coupled reactions. The chemistry of life is therefore chemical, physical, and organizational at the same time.
Functional groups and the logic of molecular interaction
Biomolecular function depends strongly on functional groups: chemically reactive or interaction-prone parts of molecules that shape solubility, charge, hydrogen bonding, acidity, polarity, hydrophobicity, and binding behavior. Hydroxyl, carbonyl, carboxyl, amino, sulfhydryl, phosphate, and methyl groups all help determine how biomolecules interact with water, ions, membranes, proteins, nucleic acids, and metabolites. Functional groups are therefore one of the main ways chemistry becomes biological specificity.
This matters because biological systems depend on selective interaction. Enzymes recognize substrates through shape, charge, polarity, and local chemistry. Nucleic acids pair through hydrogen bonding and base geometry. Proteins fold through interactions among side chains and water. Membranes form because amphipathic lipids contain hydrophilic and hydrophobic regions. Cell signaling depends on molecular recognition, phosphorylation, binding pockets, receptors, and conformational change. Functional groups make this specificity chemically possible.
Functional groups also make biomolecules modifiable. Phosphorylation, methylation, acetylation, glycosylation, oxidation, reduction, ubiquitination, lipidation, and other modifications alter molecular behavior by changing charge, shape, binding capacity, stability, localization, or interaction networks. This is one reason biomolecular chemistry is so central to regulation. Biological systems do not only build molecules; they modify them dynamically.
Biomolecular life is therefore neither random nor purely mechanical. It is chemically patterned. The ability of molecules to bind, fold, assemble, catalyze, transport, encode information, and participate in regulation depends on structured chemical features distributed across biological macromolecules and small molecules.
The major classes of biomolecules
Most biological textbooks and reference works identify four major classes of biological macromolecules: carbohydrates, lipids, proteins, and nucleic acids. Together, these constitute the major organic components of cells and perform distinct but overlapping functions. Carbohydrates contribute to energy storage, structural materials, and cell recognition. Lipids are central to membranes, energy storage, and signaling. Proteins carry out catalysis, structure, transport, signaling, and regulation. Nucleic acids store, transmit, and help express hereditary information.
These classes are useful because they organize biochemical diversity into functionally meaningful categories, but living chemistry also depends on many smaller molecules and ions. Amino acids, nucleotides, monosaccharides, fatty acids, cofactors, salts, metals, vitamins, gases, redox carriers, and metabolites all participate in the construction and operation of macromolecular systems. Biology therefore treats biomolecules not as isolated categories but as interacting layers of chemical organization that together support life.
The most important point is that biomolecules become biological through organization. A molecule may store energy, but it matters biologically when its storage and release are regulated. A polymer may carry information, but it matters biologically when that information is copied, expressed, repaired, and inherited. A lipid may self-assemble in water, but it matters biologically when that assembly becomes a membrane that controls exchange. Biomolecular classes are therefore starting points for understanding living systems, not final explanations.
This is why biomolecular biology connects directly to cell theory. A cell is not alive because it contains a list of molecular ingredients. It is alive because those ingredients are spatially organized, energetically coupled, enzymatically transformed, selectively transported, chemically modified, genetically regulated, and reproduced through time.
Carbohydrates: structure, energy, and recognition
Carbohydrates range from simple sugars to large polysaccharides and serve several essential biological roles. They provide readily accessible energy, form structural materials, and participate in molecular recognition. Glucose and related sugars are central to cellular metabolism, while polysaccharides such as starch, glycogen, cellulose, chitin, and extracellular matrix carbohydrates support energy storage, structural integrity, or environmental interaction depending on organism and context.
Biologically, carbohydrates matter because their functions depend on both chemistry and context. A sugar can be a fuel, a storage form, a structural component, or part of a recognition system depending on how it is linked, modified, and located. The difference between starch, glycogen, and cellulose is not simply that all are built from glucose; it is how glucose units are connected, branched, organized, and used. Structure governs function.
Carbohydrates also support cell identity and communication. Glycoproteins, glycolipids, and extracellular carbohydrate structures participate in recognition, adhesion, immune response, development, host-pathogen interaction, and tissue organization. Glycobiology is therefore not merely about energy storage. It is also about the chemical language of cell surfaces and extracellular environments.
Carbohydrates support ecological and planetary processes as well. Photosynthesis fixes carbon into carbohydrate-rich molecules. Plant cellulose shapes terrestrial biomass. Microbial and fungal decomposition breaks complex carbohydrates back into smaller units. Marine polysaccharides contribute to microbial loops and carbon export. Soil organic matter includes carbohydrate-derived residues and microbial products. Carbohydrates therefore connect cellular metabolism to food webs, agriculture, forests, carbon cycling, and decomposition.
Lipids: membranes, storage, and chemical environment
Lipids are a diverse class of hydrophobic or amphipathic molecules that include fats, oils, phospholipids, glycolipids, sterols, waxes, and other membrane-associated compounds. Their defining feature is not a single monomeric architecture but a shared behavior in water: many lipids do not dissolve appreciably in water, while amphipathic lipids arrange themselves into bilayers, micelles, or other structures because they contain both hydrophobic and hydrophilic regions. This makes lipids indispensable for membrane formation, energy storage, insulation, signaling, and chemical compartmentalization.
Membranes are especially important because they make cellular life possible. A cell requires a boundary that is stable yet selectively permeable, and lipid bilayers provide the physical basis for that boundary. Lipids also shape membrane fluidity, curvature, permeability, protein function, vesicle formation, organelle identity, and signaling. The chemical basis of life therefore includes not only informational and catalytic molecules but also the molecular means of separation, compartmentalization, and transport.
Lipids also matter in ecology and medicine. Membrane composition affects thermal tolerance, salinity response, pathogen entry, drug delivery, neural function, inflammation, and metabolic disease. Marine organisms may adjust lipid composition under temperature and pressure conditions. Plants use lipids in membranes, cuticles, signaling, and seed storage. Animals store substantial energy in lipid form. Lipids therefore connect chemical hydrophobicity to membrane biology, organismal physiology, environmental stress, and disease.
The importance of lipids also shows why biomolecular biology cannot be reduced to sequence analysis alone. Proteins and nucleic acids are sequence-defined polymers, but lipid biology depends on hydrophobic chemistry, membrane environments, fatty-acid composition, sterols, head groups, curvature, and phase behavior. Living systems require this non-sequence chemical architecture to become bounded, compartmentalized, and responsive.
Proteins: catalysis, structure, and dynamic function
Proteins are naturally occurring polymers composed of amino acids linked by peptide bonds, and they are among the most functionally versatile biomolecules in living systems. They serve as enzymes, structural materials, transporters, receptors, hormones, antibodies, motors, scaffolds, channels, pumps, and regulators. Their functional diversity arises from amino-acid sequence, three-dimensional folding, chemical environment, post-translational modification, and interaction with other molecules.
Protein structure is commonly described at primary, secondary, tertiary, and quaternary levels. Primary structure is amino-acid sequence. Secondary structure includes local patterns such as alpha helices and beta sheets. Tertiary structure is the overall three-dimensional conformation of a single polypeptide. Quaternary structure describes assemblies of multiple subunits. These levels are analytically useful because protein function depends on shape, charge distribution, binding sites, flexibility, and conformational change.
Proteins matter profoundly for the chemical basis of life because they convert chemical possibility into organized biological action. Enzymes accelerate reactions that would otherwise be too slow for life to proceed efficiently. Structural proteins stabilize tissues and cells. Regulatory proteins coordinate responses to internal and external change. Transport proteins move substances across membranes. Receptors connect environmental signals to cellular responses. In this sense, proteins are among the chief dynamic agents through which biomolecular order becomes physiological and developmental order.
Proteins also make biology vulnerable. Misfolding, aggregation, mutation, inappropriate cleavage, altered phosphorylation, abnormal glycosylation, degradation failure, or mistargeting can produce disease. Conversely, protein engineering, antibody design, enzyme optimization, structural biology, and proteomics make proteins central to biotechnology and medicine. Protein science is therefore both fundamental and applied.
Nucleic acids: information, heredity, and expression
Nucleic acids are the primary information-carrying molecules of the cell. DNA stores hereditary information, while RNA participates in information transfer, regulation, catalysis, and protein synthesis. Chemically, nucleic acids are polymers of nucleotides; biologically, they are central to heredity, gene expression, and evolutionary continuity. They are indispensable because they provide a stable yet copyable medium through which living systems preserve instructions and transmit them across generations.
The significance of nucleic acids extends beyond storage. They connect chemistry to information. The chemical basis of life is therefore not only energetic or structural. It is also informational. Living systems differ from many nonliving systems not merely because they are chemically complex, but because they encode, copy, regulate, and express information in chemically embodied form. Nucleic acids are central to that fact.
RNA is especially important because it links information to function. Messenger RNA carries coding information, ribosomal RNA participates in protein synthesis, transfer RNA links codons to amino acids, and many regulatory RNAs influence gene expression. DNA provides long-term hereditary continuity, but RNA demonstrates how biomolecular information can also be active, regulatory, catalytic, and dynamic.
Nucleic acids also make modern biology computational. DNA and RNA sequences can be stored, compared, aligned, counted, modeled, and linked to gene expression, protein coding, regulatory function, phylogeny, and disease. This is one reason biomolecular biology has become deeply data-rich. Nucleic acids are chemical polymers, but they are also analyzable information-bearing structures.
Metabolites, cofactors, ions, and small-molecule life
The chemical basis of life also depends on smaller molecules. Metabolites are intermediates and products of biochemical reactions. Cofactors help enzymes catalyze reactions. Ions contribute to charge balance, membrane potentials, enzyme activity, osmotic regulation, signaling, and structural stability. Vitamins, metals, nucleotides, amino acids, fatty acids, sugars, organic acids, gases, and redox carriers all participate in the living chemical network.
This matters because macromolecules do not operate alone. Enzymes often require cofactors. Membrane potentials depend on ions. ATP and redox carriers couple energy transformation to work. Metal ions help stabilize structures and participate in catalysis. Metabolites serve as substrates, signals, inhibitors, and building blocks. Cells are therefore not only built from large molecules but animated by small-molecule flux.
Small molecules are also central to ecology and medicine. Nutrient availability shapes microbial growth, plant productivity, and trophic transfer. Metabolites can signal stress, disease, symbiosis, or environmental state. Drugs are often small molecules designed to bind proteins, nucleic acids, membranes, or metabolic pathways. The chemical basis of life therefore includes both macromolecular architecture and small-molecule circulation.
In systems biology, metabolites and cofactors often reveal the active state of a biological system more directly than genes alone. Gene sequences show capacity; metabolites often show current activity. For that reason, metabolomics, flux analysis, redox biology, and ion physiology are essential complements to genomics and proteomics.
From chemistry to cells
Biomolecules become biologically meaningful in the cell. Cells are not random mixtures of biomolecules, but highly organized systems in which membranes create compartments, proteins carry out catalysis and signaling, carbohydrates support energy and recognition, nucleic acids store and express information, and metabolites connect pathways into living networks. The cell is therefore the level at which the chemical basis of life becomes organizationally visible.
This point is crucial because it links biochemistry to cell theory and physiology. The chemical basis of life is not simply a topic about molecules. It is a topic about how molecules participate in living systems. Biomolecules matter because they are the chemical substrate of cellular order, developmental continuity, metabolism, adaptation, and inheritance.
A cell is not alive because it contains biomolecules in bulk. It is alive because biomolecules are spatially arranged, energetically coupled, selectively transported, enzymatically transformed, genetically regulated, repaired, recycled, and reproduced. The chemical basis of life therefore becomes biological only through organization.
This also explains why biomolecular dysfunction can scale upward. A single mutation can alter a protein. A protein alteration can disrupt a pathway. A pathway disruption can change cell behavior. Cellular dysfunction can become tissue disease, organismal pathology, ecological vulnerability, or evolutionary consequence. Biomolecules are chemical objects, but their significance often emerges through biological scale.
Ecological, sustainability, and environmental relevance
Biomolecules matter ecologically. Primary production, decomposition, nutrient cycling, trophic transfer, symbiosis, disease dynamics, and ecosystem resilience all depend on the synthesis, transformation, and breakdown of biomolecules. Ecological systems are not only flows of organisms and populations; they are also flows of carbon compounds, lipids, proteins, nucleic acids, and metabolites through food webs and biogeochemical cycles.
Ecologists therefore encounter biomolecules not merely as cellular components but as part of larger cycles of energy and matter. Carbon fixation builds carbohydrates and other organic compounds. Consumers transform macromolecules into biomass, energy, and waste. Decomposers break biological materials back into simpler forms. Microbes transform nitrogenous compounds, sulfur compounds, carbon substrates, and dissolved organic matter. The chemical basis of life is thus inseparable from ecosystem function.
This is where biomolecules become sustainability-adjacent. Soil fertility depends on organic matter, microbial enzymes, plant residues, and nutrient availability. Food systems depend on carbohydrates, proteins, lipids, micronutrients, and metabolic pathways. Climate feedbacks depend partly on carbon storage, decomposition, methane production, plant biomass, and microbial metabolism. Biomolecular turnover is therefore part of the material basis of sustainability.
Pollution and environmental stress are also biomolecular problems. Toxins can bind proteins, damage membranes, alter DNA, disrupt endocrine signaling, shift metabolism, or change microbial enzyme systems. Climate stress can alter protein stability, membrane composition, metabolic rates, photosynthesis, and stress metabolites. Environmental change becomes biological in part by altering biomolecular structure and function.
Marine, freshwater, soil, plant, and microbial relevance
Marine biology gives biomolecular life a distinctive environmental context. Marine organisms live under strong gradients of salinity, pressure, light, temperature, oxygen availability, and nutrient distribution. Membrane lipids, osmolytes, pigments, proteins, nucleic-acid regulation, and metabolic pathways all matter for how marine organisms survive, grow, reproduce, and adapt. Phytoplankton productivity, microbial loops, coral symbiosis, and marine food webs all depend on biomolecular processes expressed under oceanic conditions.
Freshwater systems likewise depend on biomolecular processes. Algal blooms, microbial respiration, decomposition, dissolved organic matter, nutrient cycling, and food-web transfer all involve biomolecular synthesis and breakdown. Freshwater stressors such as eutrophication, pollution, warming, and hypoxia alter biomolecular activity by changing oxygen, nutrients, pH, temperature, and community composition.
Soil biology depends on biomolecular turnover at extraordinary complexity. Plant residues, microbial biomass, fungal enzymes, extracellular polymers, root exudates, proteins, carbohydrates, lipids, nucleic acids, and humic materials all contribute to soil function. Plant science is equally biomolecular: photosynthetic pigments, carbohydrate allocation, cell-wall polymers, lipid membranes, proteins, nucleic acids, hormones, and defense compounds all shape growth and resilience.
Microbiology reveals perhaps the most intense biomolecular diversity. Microbes use many substrates, electron donors, electron acceptors, enzymes, membrane systems, polymers, and metabolic pathways. They build biofilms, cycle nutrients, metabolize pollutants, transform soils and sediments, and shape host health. Biomolecules therefore connect microbial life to ecosystems, agriculture, medicine, and environmental change.
Medical, biomedical, and disease ecology relevance
Biomolecules are central to medicine and biomedicine because health and disease depend on molecular structure and function. Disorders of glucose handling, lipid metabolism, protein folding, membrane transport, DNA integrity, RNA regulation, enzyme activity, receptor signaling, and metabolite balance all have clinical significance. Cancer, inherited disease, neurodegeneration, metabolic syndromes, immune dysfunction, cardiovascular disease, and infectious disease all involve disruption of biomolecular processes.
Medical professionals and biomedical scientists therefore study biomolecules not only as abstract chemistry but as operational determinants of diagnosis, mechanism, and treatment. Enzymes become drug targets. Lipids shape membrane pharmacology and inflammation. Proteins can misfold, aggregate, or become autoantigens. Nucleic acids can mutate, regulate, and become diagnostic markers. Metabolites can reveal disease state. The chemical basis of life is therefore also part of the chemical basis of disease.
Disease ecology also depends on biomolecular systems. Pathogens use proteins, lipids, carbohydrates, and nucleic acids to enter hosts, evade immunity, replicate, and persist. Hosts respond through antibodies, receptors, inflammatory mediators, antimicrobial peptides, mucus, barriers, signaling pathways, and metabolic shifts. Environmental conditions alter these interactions by changing nutrition, temperature, hydration, toxin exposure, and organismal stress. Biomolecules therefore connect molecular medicine to ecological health.
This is also why biomolecular literacy matters beyond the laboratory. Public health, nutrition, pharmacology, toxicology, infectious disease, environmental medicine, and conservation biology all depend on understanding how molecules shape living systems under real conditions.
Biotechnology, bioinformatics, and computational relevance
Biotechnology operationalizes biomolecules. Protein engineering, nucleic-acid analysis, lipid-based delivery systems, metabolic engineering, sequencing workflows, fermentation systems, biosensors, diagnostics, cell culture, vaccine platforms, and assay development all depend on understanding biomolecular structure and function. Once the chemistry of life becomes experimentally tractable, it can support applied systems of production, intervention, screening, measurement, and design.
Bioinformatics and computational biology deepen this further. Sequence analysis, protein prediction, metabolomic analysis, molecular simulation, structural databases, pathway modeling, molecular docking, high-throughput screening, and reproducible statistical workflows all treat biomolecules as structured data as well as chemical entities. Biomolecules are now studied simultaneously as molecules, functions, signals, networks, and data objects.
This computational shift matters because biomolecular science increasingly requires traceability and reproducibility. A sequence result should be linked to data sources, preprocessing, analytical assumptions, and interpretation. A metabolomics comparison should record normalization, units, batch handling, and uncertainty. A protein model should distinguish prediction from empirical structure. A kinetic model should make parameter assumptions explicit. Biomolecular science is therefore increasingly a computational and data-governance problem as well as a laboratory discipline.
The strongest biomolecular workflows connect wet-lab measurement, chemical reasoning, statistical analysis, and transparent data infrastructure. A molecule can be assayed, sequenced, modeled, normalized, visualized, stored, and compared, but those steps must remain biologically and chemically interpretable.
Mathematical lens
Biomolecular life is not only descriptive. It is also quantitative. Reaction rates, concentration changes, molecular abundance, sequence composition, binding affinity, diffusion, metabolic flux, and molecular turnover can often be represented mathematically and analyzed statistically or computationally. This does not replace biological interpretation, but it makes biomolecular behavior more explicit, testable, and reproducible.
A standard model for enzyme-catalyzed reaction rate is the Michaelis-Menten equation:
Interpretation: Michaelis-Menten kinetics links substrate concentration to enzyme-catalyzed reaction velocity.
where \(v\) is reaction velocity, \(V_{\max}\) is the maximum rate, \([S]\) is substrate concentration, and \(K_m\) is the Michaelis constant. This matters because it links molecular interaction to measurable biochemical behavior.
A simple diffusive approximation is Fick’s first law:
Interpretation: Fickian diffusion relates molecular flux to the concentration gradient across distance.
where \(J\) is flux, \(D\) is the diffusion coefficient, and \(\frac{dC}{dx}\) is the concentration gradient. This is useful for thinking about nutrient transport, membrane crossing, concentration-driven movement in cells and tissues, and chemical gradients in aquatic or soil environments.
A simple one-site binding relation can be written as:
Interpretation: Ligand binding links ligand concentration to fractional occupancy of a binding site.
where \(\theta\) is fractional occupancy, \([L]\) is ligand concentration, and \(K_d\) is the dissociation constant. This is useful because many biomolecular processes involve reversible binding: receptors, enzymes, transcription factors, antibodies, transporters, and signaling proteins.
For a DNA sequence, GC content can be written as:
Interpretation: GC content measures the fraction of nucleotides that are guanine or cytosine.
This is useful because nucleotide composition can influence genome analysis, primer design, sequence comparison, melting behavior, and microbial or evolutionary interpretation.
For a protein sequence, the fraction of amino acid \(a\) can be written as:
Interpretation: Amino-acid composition expresses how much of a protein sequence is made up of a given residue.
where \(n_a\) is the count of amino acid \(a\), and \(N\) is total sequence length. This is useful because amino-acid composition can shape charge, hydrophobicity, disorder, localization, and structural tendencies.
A simple biomolecular fraction for class \(i\) can be written as:
Interpretation: Biomolecular fraction normalizes one molecular class by the total measured biomolecular mass.
where \(m_i\) is the measured mass of biomolecular class \(i\), and the denominator is the total measured biomolecular mass across classes. This is useful for comparing molecular composition across samples, cell types, organisms, or environmental conditions.
Variables, units, and biomolecular interpretation
Quantitative biomolecular biology depends on variables that connect molecular concentration, reaction rate, binding, composition, sequence structure, and biological interpretation. The table below summarizes several central quantities.
| Symbol or Term | Meaning | Typical Unit or Scale | Biomolecular Interpretation |
|---|---|---|---|
| \(v\) | Reaction velocity | concentration per time or amount per time | Rate of product formation or substrate consumption in an enzyme reaction |
| \(V_{\max}\) | Maximum reaction velocity | same as \(v\) | Upper reaction rate under saturating substrate conditions |
| \([S]\) | Substrate concentration | molarity, mass per volume, or assay units | Amount of reactant available to an enzyme |
| \(K_m\) | Michaelis constant | same as \([S]\) | Substrate concentration associated with half-maximal velocity under Michaelis-Menten assumptions |
| \(J\) | Flux | amount per area per time | Rate of molecular movement across a surface or spatial gradient |
| \(D\) | Diffusion coefficient | area per time | How rapidly a molecule spreads through a medium |
| \(C\) | Concentration | molarity, mass per volume, or relative abundance | Amount of biomolecule, solute, ligand, nutrient, or metabolite per volume |
| \(x\) | Distance | length | Spatial dimension over which concentration changes |
| \(\theta\) | Fractional occupancy | fraction from 0 to 1 | Share of binding sites occupied by ligand |
| \([L]\) | Ligand concentration | same concentration unit as \(K_d\) | Signal or binding molecule available for molecular interaction |
| \(K_d\) | Dissociation constant | same as \([L]\) | Ligand concentration associated with half occupancy in a simple binding model |
| \(GC\) | GC content | fraction or percentage | Fraction of DNA sequence composed of guanine and cytosine |
| \(A,T,G,C\) | Nucleotide counts | counts | Number of adenine, thymine, guanine, and cytosine bases in DNA |
| \(f_a\) | Amino-acid fraction | fraction from 0 to 1 | Proportion of protein sequence made up of amino acid \(a\) |
| \(m_i\) | Mass of biomolecular class \(i\) | mass, usually mg or μg | Measured abundance of a biomolecular class in a sample |
| \(F_i\) | Normalized biomolecular fraction | fraction from 0 to 1 | Share of total measured biomolecular mass represented by class \(i\) |
The table shows why biomolecular analysis requires both measurement and interpretation. A sequence, mass, concentration, velocity, or binding constant becomes biologically meaningful only when connected to molecular context, cellular function, experimental design, and biological scale.
Worked example: enzyme velocity and GC content
Suppose \(V_{\max}=100\), \(K_m=3\), and \([S]=6\). Under the Michaelis-Menten model:
Interpretation: Reaction velocity depends on maximum rate, substrate concentration, and enzyme-substrate affinity structure.
Substituting the values:
Interpretation: The substrate concentration is twice the Michaelis constant, so the reaction is above half-maximal velocity.
Solving:
Interpretation: The estimated reaction velocity is 66.67 in the chosen assay units.
This is useful because it converts substrate concentration into an interpretable reaction velocity. It also shows why enzyme kinetics is one of the main bridges between molecular interaction and measurable biochemical behavior.
Sequence composition can be analyzed similarly. Suppose a DNA sequence contains \(A=30\), \(T=25\), \(G=20\), and \(C=25\). Then:
Interpretation: GC content compares guanine and cytosine counts against total nucleotide count.
Solving:
Interpretation: The GC content is 45 percent.
This is useful because composition becomes a measurable sequence feature rather than a qualitative description. Similar logic supports primer design, genome comparison, microbial sequence analysis, and molecular evolution workflows.
Computational modeling
Computational modeling helps make biomolecular biology explicit because biomolecules can be counted, normalized, sequenced, compared, modeled, and interpreted across experiments. Reaction-rate curves can summarize enzyme behavior. Binding curves can describe molecular occupancy. Composition tables can compare biomolecular classes across samples. Sequence-feature extraction can connect DNA or protein sequences to measurable chemical properties. Diffusion models can express molecular transport under gradients.
The selected examples below focus on compact, reusable workflows: Michaelis-Menten kinetics, ligand binding, biomolecular composition normalization, DNA GC content, protein sequence features, hydrophobic and charged residue fractions, and sample-level molecular summaries. The GitHub repository extends the same logic into richer workflows for polymerization mass balance, C:N:P ratio summaries, metabolite tables, biomolecular condition scoring, SQL provenance, notebooks, validation scripts, and multi-language examples.
The purpose is not to reduce biomolecules to spreadsheets or equations. The purpose is to make biomolecular evidence inspectable. A biomolecular claim becomes stronger when the measurement, model, parameter, sequence, normalization method, and biological interpretation are documented together.
R workflow: kinetics, binding, composition, and GC content
R is useful for biomolecular analysis because it supports statistical modeling, tabular summaries, sequence-feature calculations, and reproducible reporting. The following workflow computes Michaelis-Menten velocities, ligand-binding occupancy, biomolecular composition fractions, and DNA GC content.
# Biomolecular Biology Workflow
#
# This workflow demonstrates four foundational biomolecular tasks:
#
# 1. Compute a Michaelis-Menten enzyme-kinetics curve.
# 2. Compute a one-site ligand-binding curve.
# 3. Normalize biomolecular composition by total measured mass.
# 4. Calculate DNA GC content from a sequence.
#
# These examples can be adapted for enzyme assays, receptor binding,
# metabolite summaries, environmental biomolecular samples,
# molecular biology workflows, and biotechnology pipelines.
library(tibble)
library(dplyr)
# ------------------------------------------------------------
# 1. Michaelis-Menten enzyme kinetics
# ------------------------------------------------------------
kinetics_df <- tibble(
substrate = seq(0.1, 30, length.out = 300)
) %>%
mutate(
Vmax = 100,
Km = 3,
velocity = (Vmax * substrate) / (Km + substrate)
)
# ------------------------------------------------------------
# 2. One-site ligand-binding curve
# ------------------------------------------------------------
binding_df <- tibble(
ligand = seq(0.1, 50, length.out = 300)
) %>%
mutate(
Kd = 8,
fraction_bound = ligand / (Kd + ligand)
)
# ------------------------------------------------------------
# 3. Biomolecular composition summary
# ------------------------------------------------------------
composition_df <- tibble(
sample = c("cell_extract_A", "cell_extract_B", "marine_microbe", "plant_leaf"),
carbohydrate_mg = c(18.2, 14.5, 9.1, 24.8),
lipid_mg = c(7.6, 10.2, 5.7, 8.4),
protein_mg = c(31.4, 28.6, 22.3, 27.5),
nucleic_acid_mg = c(4.8, 5.1, 3.9, 4.2)
) %>%
mutate(
total_biomolecule_mg =
carbohydrate_mg + lipid_mg + protein_mg + nucleic_acid_mg,
carbohydrate_fraction = carbohydrate_mg / total_biomolecule_mg,
lipid_fraction = lipid_mg / total_biomolecule_mg,
protein_fraction = protein_mg / total_biomolecule_mg,
nucleic_acid_fraction = nucleic_acid_mg / total_biomolecule_mg,
protein_to_nucleic_acid_ratio = protein_mg / nucleic_acid_mg
)
# ------------------------------------------------------------
# 4. DNA GC content
# ------------------------------------------------------------
dna_sequence <- "ATGCGCGTATTAACCGGTTAGCGCGATATCGCGTA"
sequence_vector <- strsplit(dna_sequence, split = "")[[1]]
base_counts <- table(sequence_vector)
get_base_count <- function(base) {
ifelse(base %in% names(base_counts), as.numeric(base_counts[[base]]), 0)
}
A_count <- get_base_count("A")
T_count <- get_base_count("T")
G_count <- get_base_count("G")
C_count <- get_base_count("C")
gc_summary <- tibble(
sequence_length = length(sequence_vector),
A = A_count,
T = T_count,
G = G_count,
C = C_count,
gc_content = (G_count + C_count) / (A_count + T_count + G_count + C_count)
)
print(head(round(kinetics_df, 4), 12))
print(tail(round(kinetics_df, 4), 12))
print(head(round(binding_df, 4), 12))
print(tail(round(binding_df, 4), 12))
print(composition_df %>% mutate(across(where(is.numeric), ~ round(.x, 4))))
print(gc_summary)This workflow is useful because biomolecular function often depends on reaction rates, binding relationships, normalized composition, and sequence features. A working scientist could extend it to replicate-aware enzyme assays, nonlinear parameter estimation, confidence intervals, metabolomic normalization, or comparative sequence analysis.
Python workflow: composition, kinetics, binding, and sequence features
Python is useful for biomolecular workflows because it supports tabular analysis, sequence parsing, numerical modeling, pipeline design, and reproducible data processing. The following workflow normalizes biomolecular composition, computes enzyme kinetics and binding curves, and extracts DNA and protein sequence features.
"""
Biomolecular Biology Computational Workflow
This workflow demonstrates four biomolecular analysis tasks:
1. Normalize biomolecular composition across samples.
2. Compute Michaelis-Menten enzyme kinetics.
3. Compute one-site ligand-binding occupancy.
4. Extract DNA and protein sequence features.
The examples are compact, but the same structures can be extended to
enzyme assays, receptor binding, metabolomics, proteomics, sequence
analysis, environmental biomolecular samples, and biotechnology pipelines.
"""
from __future__ import annotations
from collections import Counter
import numpy as np
import pandas as pd
def normalize_biomolecular_composition() -> pd.DataFrame:
"""
Normalize biomolecular class abundances by total measured mass.
"""
composition = pd.DataFrame(
{
"sample": ["cell_extract_A", "cell_extract_B", "marine_microbe", "plant_leaf"],
"carbohydrate_mg": [18.2, 14.5, 9.1, 24.8],
"lipid_mg": [7.6, 10.2, 5.7, 8.4],
"protein_mg": [31.4, 28.6, 22.3, 27.5],
"nucleic_acid_mg": [4.8, 5.1, 3.9, 4.2],
}
)
biomolecule_columns = [
"carbohydrate_mg",
"lipid_mg",
"protein_mg",
"nucleic_acid_mg",
]
composition["total_biomolecule_mg"] = composition[biomolecule_columns].sum(axis=1)
for col in biomolecule_columns:
fraction_col = col.replace("_mg", "_fraction")
composition[fraction_col] = composition[col] / composition["total_biomolecule_mg"]
composition["protein_to_nucleic_acid_ratio"] = (
composition["protein_mg"] / composition["nucleic_acid_mg"]
)
return composition
def michaelis_menten_curve(
vmax: float = 100.0,
km: float = 3.0,
max_substrate: float = 30.0,
n_points: int = 300,
) -> pd.DataFrame:
"""
Compute Michaelis-Menten enzyme velocity across substrate levels.
"""
substrate = np.linspace(0.1, max_substrate, n_points)
velocity = (vmax * substrate) / (km + substrate)
return pd.DataFrame(
{
"substrate": substrate,
"velocity": velocity,
"Vmax": vmax,
"Km": km,
}
)
def ligand_binding_curve(
kd: float = 8.0,
max_ligand: float = 50.0,
n_points: int = 300,
) -> pd.DataFrame:
"""
Compute fractional occupancy for a one-site binding model.
"""
ligand = np.linspace(0.1, max_ligand, n_points)
fraction_bound = ligand / (kd + ligand)
return pd.DataFrame(
{
"ligand": ligand,
"fraction_bound": fraction_bound,
"Kd": kd,
}
)
def sequence_feature_summary() -> pd.DataFrame:
"""
Extract compact DNA and protein sequence features.
"""
dna_sequence = "ATGCGCGTATTAACCGGTTAGCGCGATATCGCGTA"
protein_sequence = "MKWVTFISLLFLFSSAYSRGVFRRDTHKSEIAHRFKDLGE"
dna_counts = Counter(dna_sequence)
dna_length = len(dna_sequence)
gc_content = (
dna_counts.get("G", 0) + dna_counts.get("C", 0)
) / dna_length
protein_counts = Counter(protein_sequence)
protein_length = len(protein_sequence)
hydrophobic_residues = set("AILMFWYV")
charged_residues = set("DEKRH")
polar_residues = set("STNQCY")
hydrophobic_fraction = sum(
protein_counts.get(residue, 0) for residue in hydrophobic_residues
) / protein_length
charged_fraction = sum(
protein_counts.get(residue, 0) for residue in charged_residues
) / protein_length
polar_fraction = sum(
protein_counts.get(residue, 0) for residue in polar_residues
) / protein_length
return pd.DataFrame(
[
{
"sequence_type": "DNA",
"length": dna_length,
"gc_content": gc_content,
"hydrophobic_fraction": np.nan,
"charged_fraction": np.nan,
"polar_fraction": np.nan,
},
{
"sequence_type": "protein",
"length": protein_length,
"gc_content": np.nan,
"hydrophobic_fraction": hydrophobic_fraction,
"charged_fraction": charged_fraction,
"polar_fraction": polar_fraction,
},
]
)
def main() -> None:
"""
Run compact biomolecular analysis examples.
"""
composition = normalize_biomolecular_composition()
kinetics = michaelis_menten_curve()
binding = ligand_binding_curve()
sequence_features = sequence_feature_summary()
print("Biomolecular composition summary:")
print(composition.round(4).to_string(index=False))
print("\nMichaelis-Menten kinetics:")
print(kinetics.head(12).round(4).to_string(index=False))
print(kinetics.tail(12).round(4).to_string(index=False))
print("\nLigand-binding curve:")
print(binding.head(12).round(4).to_string(index=False))
print(binding.tail(12).round(4).to_string(index=False))
print("\nDNA and protein sequence features:")
print(sequence_features.round(4).to_string(index=False))
if __name__ == "__main__":
main()This Python workflow is useful because biomolecules are both chemical structures and analyzable data objects. Raw molecular abundance values often need normalization. Enzyme and binding behavior can be modeled across concentrations. DNA and protein sequences can be transformed into features that support comparison, interpretation, and downstream biological workflows.
GitHub repository
The article body includes compact R and Python examples so the biological and scientific argument remains readable. The full repository expands those examples into a more rigorous computational biomolecular-biology workflow, including biomolecular composition accounting, macromolecule fraction normalization, carbon-nitrogen-phosphorus ratio summaries, Michaelis-Menten kinetics, ligand-binding curves, diffusion-gradient modeling, DNA GC content, protein sequence-feature extraction, amino-acid composition, hydrophobic and charged residue fractions, polymerization mass-balance examples, macromolecule condition scoring, SQL provenance structures, validation notes, reproducible data files, and full-stack scientific-computing examples across Python, R, Julia, Fortran, Rust, Go, C, C++, SQL, and notebooks.
Limits, scaling, and modern biomolecular thinking
Biomolecules are foundational, but they are not simple. A molecule’s biological meaning depends on concentration, location, modification, folding, interaction partners, environmental conditions, cellular compartment, developmental stage, and evolutionary history. A protein sequence is not the same as a functional protein in context. A lipid species is not the same as a membrane. A DNA sequence is not the same as gene expression. A metabolite abundance value is not the same as flux through a pathway.
This is why modern biomolecular thinking increasingly emphasizes systems, context, and measurement. Molecular biology, biochemistry, structural biology, metabolomics, proteomics, lipidomics, genomics, and systems biology all study biomolecules, but each emphasizes different layers of organization. The challenge is to connect chemical structure to cellular function, molecular abundance to pathway behavior, sequence to expression, and biomolecular mechanisms to organismal and ecological outcomes.
Models and workflows are useful because they clarify assumptions, expose constraints, and make comparison possible. But an enzyme equation is not a full metabolic system, a GC-content score is not a complete genome interpretation, and a composition table is not a full cell. Quantitative biomolecular biology is strongest when it supports mechanistic reasoning rather than replacing it.
This caution is especially important in computational biology and biotechnology. A predicted protein structure is not the same as an experimentally solved structure. A metabolomics table is not automatically a metabolic pathway. A binding curve measured in vitro may not predict cellular response in vivo. Modern biomolecular science must therefore pair computation with experimental context, metadata, and biological interpretation.
Why this matters for scientific work
For working scientists, biomolecules matter because many biological problems become intelligible only when chemical structure, concentration, reaction, and organization are considered together. A disease phenotype may depend on protein folding, not just gene presence. A marine stress response may depend on membrane lipid composition, not just temperature. A soil process may depend on microbial enzymes and organic matter chemistry, not just species lists. A cell-culture experiment may fail because medium composition, metabolites, ions, osmolarity, and energy state alter biomolecular behavior.
This means biomolecules should often be treated as explanatory infrastructure rather than a narrow biochemistry topic. Cell biologists need them because cellular structure is built from biomolecular organization. Ecologists need them because nutrient cycling and food webs are built from biomolecular transformation. Biomedical scientists need them because disease frequently begins as molecular dysfunction. Computational biologists need them because sequences, structures, molecular abundances, and pathway data are central to modern biological inference.
The scientific importance of biomolecules lies partly in this breadth. They are among the principal ways biology explains how life stores energy, builds structure, catalyzes change, transmits information, responds to environments, and persists through time.
Biomolecules also matter because they make biology experimentally actionable. Molecules can be purified, sequenced, measured, inhibited, engineered, compared, modeled, and tracked. This makes biomolecular science one of the strongest bridges between biological theory and applied scientific work in medicine, environmental science, biotechnology, agriculture, and public health.
Conclusion
Biomolecules and the chemical basis of life show that living systems are chemically specific without being chemically simple. Carbohydrates, lipids, proteins, and nucleic acids provide the structural, energetic, catalytic, informational, and regulatory basis of cells and organisms. Water, ions, cofactors, metabolites, and smaller molecules connect those macromolecules into active living networks. Yet biology does not stop at naming these molecular classes. It asks how they are organized, regulated, transformed, inherited, and embedded within living systems across scales.
To understand biomolecules scientifically is therefore to understand one of the deepest foundations of life: that living order depends on chemistry organized into dynamic, regulated, historically continuous systems. Biomolecules are not merely cellular ingredients. They are the chemical media through which life stores energy, builds boundaries, accelerates reactions, transmits information, recognizes signals, repairs damage, adapts to conditions, and remains possible.
The chemical basis of life is therefore one of biology’s central explanatory frameworks. It links molecules to cells, cells to organisms, organisms to ecosystems, and biological mechanisms to medicine, biotechnology, and environmental change. Biomolecules make life physically possible, but biological organization makes biomolecules living.
Related articles
- Biology
- What Is Biology?
- Biology and the Scientific Understanding of Living Order
- Cell Theory and the Basic Unit of Life
- Water, Energy, and the Material Conditions of Life
- Cell Structure, Membranes, and Organelles
- Metabolism, Energy, and Biological Function
- Enzymes, Regulation, and Biochemical Pathways
- DNA, RNA, and the Molecular Logic of Life
- Molecular Biology and the Flow of Genetic Information
- Genes, Inheritance, and the Principles of Heredity
- Systems Biology and the Logic of Biological Integration
Further reading
- Alberts, B. et al. (2002) ‘The molecular composition of cells’, in Molecular Biology of the Cell. 4th edn. New York: Garland Science. Available at: https://www.ncbi.nlm.nih.gov/books/NBK9879/
- Berg, J.M., Tymoczko, J.L. and Stryer, L. (2002) Biochemistry. 5th edn. New York: W.H. Freeman. Available at: https://www.ncbi.nlm.nih.gov/books/NBK21154/
- Cooper, G.M. (2000) ‘The molecules of cells’, in The Cell: A Molecular Approach. 2nd edn. Sunderland, MA: Sinauer Associates. Available at: https://www.ncbi.nlm.nih.gov/books/NBK9879/
- National Research Council (1989) ‘Molecular structure and function’, in Opportunities in Biology. Washington, DC: National Academies Press. Available at: https://www.ncbi.nlm.nih.gov/books/NBK217812/
- National Research Council (1994) Complex Carbohydrates in Drug Research. Washington, DC: National Academies Press. Available at: https://www.ncbi.nlm.nih.gov/books/NBK218559/
- OpenStax (2018) ‘Synthesis of biological macromolecules’, in Biology 2e. Available at: https://openstax.org/books/biology-2e/pages/3-1-synthesis-of-biological-macromolecules
- OpenStax (2018) ‘Carbohydrates’, in Biology 2e. Available at: https://openstax.org/books/biology-2e/pages/3-2-carbohydrates
- OpenStax (2018) ‘Lipids’, in Biology 2e. Available at: https://openstax.org/books/biology-2e/pages/3-3-lipids
- OpenStax (2018) ‘Proteins’, in Biology 2e. Available at: https://openstax.org/books/biology-2e/pages/3-4-proteins
- OpenStax (2018) ‘Nucleic acids’, in Biology 2e. Available at: https://openstax.org/books/biology-2e/pages/3-5-nucleic-acids
- RCSB Protein Data Bank (2026) Protein Data Bank. Available at: https://www.rcsb.org/
- UniProt Consortium (2026) UniProt: the Universal Protein Knowledgebase. Available at: https://www.uniprot.org/
References
- Alberts, B. et al. (2002) ‘The molecular composition of cells’, in Molecular Biology of the Cell. 4th edn. New York: Garland Science. Available at: https://www.ncbi.nlm.nih.gov/books/NBK9879/
- Berg, J.M., Tymoczko, J.L. and Stryer, L. (2002) Biochemistry. 5th edn. New York: W.H. Freeman. Available at: https://www.ncbi.nlm.nih.gov/books/NBK21154/
- Cooper, G.M. (2000) ‘The molecules of cells’, in The Cell: A Molecular Approach. 2nd edn. Sunderland, MA: Sinauer Associates. Available at: https://www.ncbi.nlm.nih.gov/books/NBK9879/
- National Research Council (1989) ‘Molecular structure and function’, in Opportunities in Biology. Washington, DC: National Academies Press. Available at: https://www.ncbi.nlm.nih.gov/books/NBK217812/
- National Research Council (1994) Complex Carbohydrates in Drug Research. Washington, DC: National Academies Press. Available at: https://www.ncbi.nlm.nih.gov/books/NBK218559/
- OpenStax (2018) ‘Carbohydrates’, in Biology 2e. Available at: https://openstax.org/books/biology-2e/pages/3-2-carbohydrates
- OpenStax (2018) ‘Lipids’, in Biology 2e. Available at: https://openstax.org/books/biology-2e/pages/3-3-lipids
- OpenStax (2018) ‘Nucleic acids’, in Biology 2e. Available at: https://openstax.org/books/biology-2e/pages/3-5-nucleic-acids
- OpenStax (2018) ‘Proteins’, in Biology 2e. Available at: https://openstax.org/books/biology-2e/pages/3-4-proteins
- OpenStax (2018) ‘Synthesis of biological macromolecules’, in Biology 2e. Available at: https://openstax.org/books/biology-2e/pages/3-1-synthesis-of-biological-macromolecules
- RCSB Protein Data Bank (2026) Protein Data Bank. Available at: https://www.rcsb.org/
- UniProt Consortium (2026) UniProt: the Universal Protein Knowledgebase. Available at: https://www.uniprot.org/