
Last Updated May 28, 2026
Enzymes, regulation, and biochemical pathways examine how living systems accelerate chemical reactions, coordinate metabolic activity, regulate pathway flux, and organize thousands of interconnected transformations into functionally coherent biological systems. Enzymes are central to life because most biochemical reactions compatible with living temperature, pressure, pH, and cellular organization would proceed far too slowly without catalysis. They lower activation barriers, stabilize transition states, orient substrates, coordinate cofactors, and make chemical transformation biologically useful. But enzyme biology is not only about speed. It is also about control: when reactions occur, where they occur, how strongly they proceed, how they are inhibited, how pathways are balanced, and how biochemical systems respond to changing internal and environmental conditions.
This article develops Enzymes, Regulation, and Biochemical Pathways as a foundational article within the Biology knowledge series. It treats enzymes not merely as isolated catalysts, but as elements of regulated biochemical systems that connect molecular structure to metabolism, physiology, development, disease, ecology, biotechnology, and systems biology. Enzymes allow cells to turn chemical possibility into organized biological function. Regulation allows that chemistry to remain adaptive rather than chaotic. Pathways allow individual catalytic reactions to become coordinated flows of matter, energy, and information.
Main Library
Publications
Article Map
Biology
Related Topic
Chemistry
Related Topic
Earth Science
Related Topic
Environmental Science
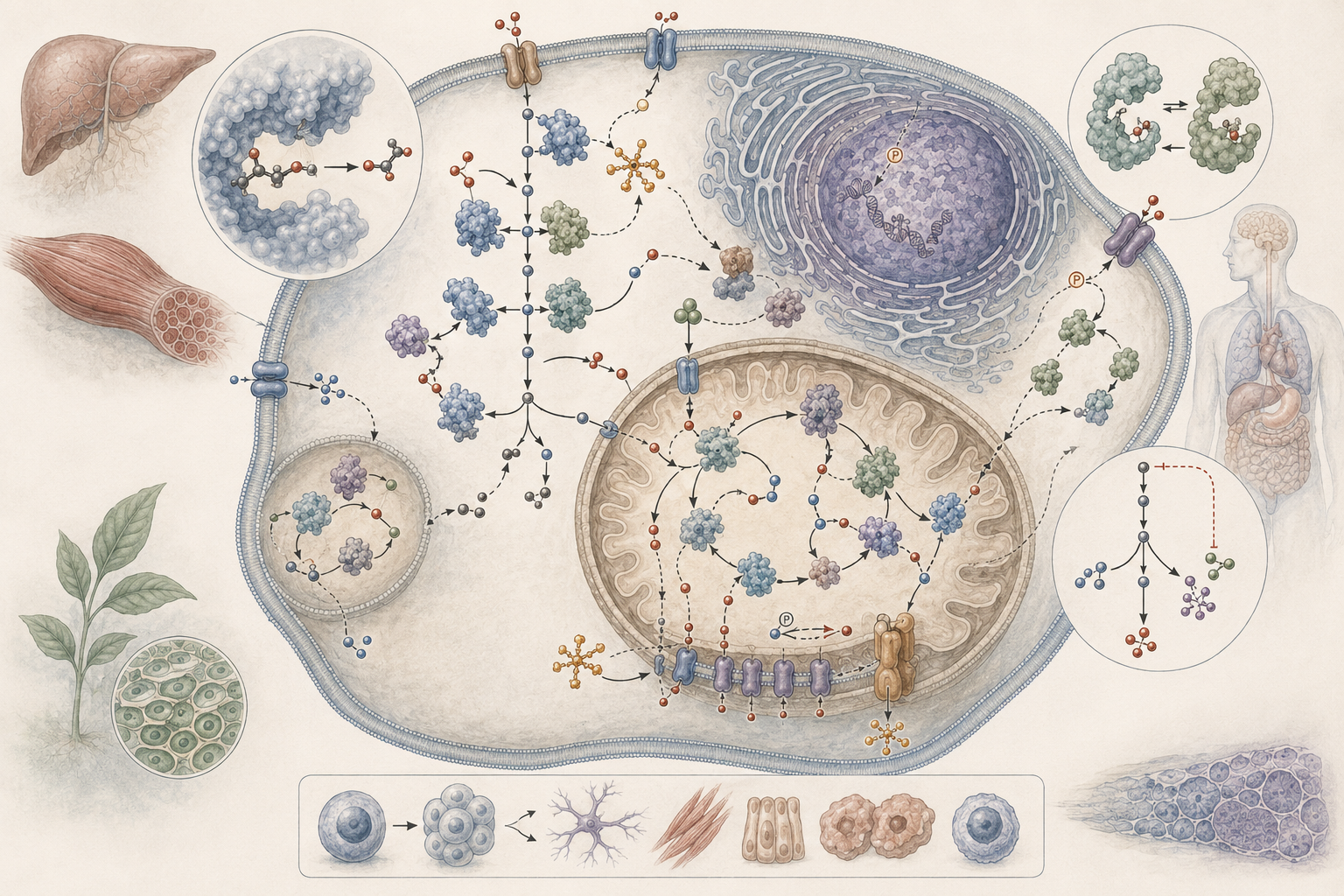
The article develops enzymes, regulation, and biochemical pathways across catalysis, activation energy, active sites, substrate specificity, cofactors, allostery, covalent modification, feedback inhibition, metabolic pathways, pathway flux, enzyme kinetics, Michaelis-Menten behavior, inhibition models, biochemical integration, physiology, microbial metabolism, plant pathways, marine and freshwater biochemistry, soil enzymes, disease mechanisms, drug discovery, biotechnology, and computational biology.
The article also extends enzyme biology into quantitative and computational analysis through Michaelis-Menten kinetics, catalytic efficiency, competitive and noncompetitive inhibition models, Hill-type allosteric response, feedback inhibition, pathway-flux simulation, enzyme-assay fitting, Lineweaver-Burk-style linearization as a teaching scaffold, pathway condition scoring, R workflows, Python workflows, SQL provenance structures, and a linked full-stack GitHub repository containing Python, R, Julia, Fortran, Rust, Go, C, C++, SQL, notebooks, data files, and reproducibility documentation.
What Enzymes Are
Enzymes are biological catalysts that accelerate chemical reactions without being consumed by those reactions. Most enzymes are proteins, though catalytic RNAs also exist. Their importance to biology is fundamental: without enzymatic catalysis, many reactions required for metabolism, signaling, repair, replication, detoxification, development, and regulation would proceed too slowly to support life under physiological conditions. Enzymes therefore make biological chemistry possible at the rates required by living systems.
To call enzymes catalysts is accurate but incomplete. Enzymes do not merely increase reaction speed in the abstract. They help channel biological chemistry into specific, regulated pathways that maintain living order. A cell is not a random chemical soup in which everything reacts with everything else. It is a highly organized system in which enzymes help determine when, where, and how specific reactions occur.
This is why enzymes sit near the center of biology. They connect molecular structure to metabolism, metabolism to physiology, physiology to development and disease, and biochemical transformation to larger organismal and ecological processes. Enzymes are not just molecular tools. They are one of the main ways life organizes chemistry into function.
Enzymes also make biological life conditional. Enzyme behavior depends on pH, temperature, ionic strength, cofactors, substrate concentration, cellular compartment, redox state, inhibitors, activators, and molecular context. This means that enzyme activity is not simply a property of a molecule in isolation. It is a property of a molecule operating under biological conditions.
Catalysis and the Problem of Biological Rate
A core problem for living systems is that many chemically possible reactions are biologically useless if they occur too slowly. Enzymes solve this problem by lowering the activation energy required for a reaction to proceed, often by stabilizing transition states, orienting substrates, creating favorable microenvironments, positioning catalytic residues, and coupling reactions to cofactors or energy carriers. This lowering of activation barriers allows reactions to occur at rates compatible with life.
This matters because biology operates under relatively mild conditions of temperature, pressure, and pH. Unlike industrial chemistry, cells cannot usually rely on extreme heat, strong solvents, high pressure, or harsh reaction conditions to drive chemical transformations. They need catalysts that work efficiently, selectively, reversibly, and regulably within narrow biological limits. Enzymes provide exactly this capability.
Rate is therefore not a trivial issue in biology. Metabolism, signaling, transport, growth, immunity, repair, detoxification, and adaptation all depend on reactions occurring with sufficient timing and coordination. A reaction that is thermodynamically possible but kinetically inaccessible cannot sustain life. To understand enzymes is to understand how living systems make chemistry fast enough, precise enough, and organized enough to sustain function.
Enzyme catalysis also shows why biological order is not static. Living systems are maintained through ongoing transformation. Enzymes do not merely preserve structure. They enable regulated change. A living cell survives because chemical reactions can be accelerated, coordinated, slowed, redirected, or shut down as conditions require.
Active Sites, Specificity, and Mechanism
Enzymes act through active sites, localized regions where substrates bind and chemical transformation occurs. The active site’s shape, charge distribution, hydrophobicity, flexibility, catalytic residues, and cofactor interactions help determine substrate recognition and reaction mechanism. This is one reason enzymes can be highly specific: they do not accelerate all reactions equally, but typically catalyze a narrow set of transformations with strong selectivity.
Specificity is biologically important because it prevents metabolic chaos. Cells depend on vast numbers of simultaneous reactions, and that requires chemical discrimination. An enzyme must not only accelerate a reaction. It must do so in a way that preserves pathway organization, reduces inappropriate side reactions, protects cellular integrity, and coordinates with other biochemical processes.
Mechanism also matters because enzyme function is dynamic. Binding can induce conformational change, catalytic residues can donate or withdraw protons, cofactors can transfer electrons or functional groups, metal ions can stabilize charges, and multistep reactions can be channeled through precisely arranged intermediates. Enzyme biology is therefore a study of form in motion: structure, binding, chemistry, and regulation working together.
This dynamic view helps explain why enzyme activity is sensitive to pH, temperature, ionic conditions, substrate availability, cofactor status, allosteric effectors, and cellular environment. Enzymes are molecular machines, but they are biological machines embedded in living conditions. Their performance depends not only on sequence and structure, but on the operating environment in which catalysis occurs.
Cofactors, Coenzymes, and Chemical Capability
Many enzymes require cofactors or coenzymes to carry out chemical transformations that amino-acid side chains alone cannot accomplish efficiently. Metal ions, heme groups, flavins, nicotinamide cofactors, pyridoxal phosphate, biotin, coenzyme A, tetrahydrofolate, and many other molecular partners extend enzymatic capability. They help transfer electrons, stabilize charges, carry chemical groups, activate substrates, or support structural integrity.
This matters because life depends on more than protein sequence. Enzyme function often requires nutritional, mineral, and redox context. A protein may be present but function poorly if its required cofactor is absent, oxidized, reduced, mislocalized, or unavailable. This is why vitamins, trace metals, dietary status, environmental chemistry, and cellular redox state can influence enzyme systems so profoundly.
Cofactors also connect enzyme biology to ecology and sustainability-adjacent biology. Iron, molybdenum, magnesium, zinc, copper, nickel, phosphorus, nitrogen, and sulfur all participate in biochemical systems. Limitation or excess of these elements can alter microbial metabolism, plant productivity, marine primary production, soil fertility, nitrogen cycling, methane production, and disease processes. Enzymes therefore connect elemental availability to biological function.
This also matters in biotechnology. Enzyme assays, fermentation systems, metabolic engineering, and biomanufacturing workflows may fail or underperform when cofactor balance is wrong. Catalysis is not just about having the right enzyme. It is about having the right enzyme in the right chemical system.
Regulation, Feedback, and Biochemical Control
Cells require more than catalysis. They require regulated catalysis. Enzyme activity is therefore controlled at multiple levels, including gene expression, translation, allosteric modulation, covalent modification, substrate availability, product inhibition, compartmentalization, cofactor state, protein-protein interaction, localization, and degradation. Regulation is one of the main ways cells coordinate biochemical behavior.
Feedback inhibition is one of the most familiar examples. A downstream product in a pathway may inhibit an upstream enzyme, thereby preventing wasteful overproduction and helping maintain balance. Other forms of regulation allow pathways to respond to energy state, nutrient availability, signaling context, oxidative stress, redox balance, toxic exposure, developmental state, immune activation, or environmental pressure. Regulation is therefore what makes enzymes part of a living system rather than merely a set of isolated catalysts.
This point is central to biology because cells must integrate competing demands. Energy production, biosynthesis, detoxification, storage, repair, stress response, and growth cannot all proceed maximally at once. Enzyme regulation is one of the major ways living systems resolve these conflicts and maintain dynamic order.
Regulation also gives biochemical pathways memory and responsiveness. A cell can shift from growth to repair, from storage to mobilization, from aerobic metabolism to stress response, or from basal activity to immune activation because enzyme systems are adjustable rather than fixed. Biochemical control is therefore one of the molecular foundations of biological adaptation.
Biochemical Pathways and Metabolic Integration
Biochemical pathways are linked sets of enzyme-catalyzed reactions through which substrates are transformed into products, intermediates are recycled, and matter and energy are routed into functionally meaningful outcomes. Glycolysis, the citric acid cycle, fatty acid synthesis, nucleotide synthesis, amino acid metabolism, photosynthesis, nitrogen assimilation, detoxification, fermentation, and countless other pathways all exemplify this logic. What makes pathways biologically powerful is not just that reactions occur in sequence, but that pathway organization allows coordination, branching, reversibility, storage, exchange, and control.
Pathways rarely exist in isolation. They share intermediates, compete for substrates, respond to common signals, draw on shared cofactors, and intersect through nodes of metabolic control. Certain enzymes and certain pathway positions become especially important because they regulate branch points, bottlenecks, irreversible steps, energy-coupled transitions, or shared biochemical routes. A pathway is therefore not merely a chain. It is part of a network.
This integration is one reason biology cannot be reduced to single-reaction thinking. A reaction may make sense only in pathway context, and a pathway may make sense only in cellular, physiological, ecological, or evolutionary context. Enzymes and pathways therefore have to be understood as elements of a larger biochemical architecture.
Pathway thinking also helps connect biochemistry to systems biology. Flux, control, feedback, constraint, and regulation become more important than the presence of enzymes alone. A pathway can contain all of its enzymes and still behave differently depending on substrate supply, allosteric state, compartmentalization, oxygen availability, redox balance, and energetic demand.
Enzymes in Physiology, Development, and Biological Function
Enzymes underlie physiology because biological function depends on regulated chemical transformation. Digestion, respiration, detoxification, biosynthesis, signaling, coagulation, contraction, neurotransmission, immunity, tissue repair, nitrogen handling, waste removal, and energy balance all depend on enzyme-controlled reactions. Physiological function is therefore inseparable from controlled biochemistry.
Physiological disruption often appears first as enzymatic disruption. A metabolic block, transport defect, cofactor deficiency, receptor-linked signaling failure, impaired degradation pathway, or abnormal catalytic activity can propagate outward into tissue dysfunction and disease. This is true in acute toxicity, inherited metabolic disease, endocrine disorder, inflammation, cancer, immune dysfunction, neurodegeneration, and many other settings.
Development also depends on enzyme systems. Cell differentiation, morphogenesis, epigenetic modification, extracellular matrix remodeling, hormone synthesis, programmed cell death, and cell-cycle control all require regulated enzymes. Development is not only a genetic process; it is a biochemical process coordinated through pathways that interpret and execute developmental programs.
Enzymes therefore matter not simply because they catalyze reactions, but because they determine whether biological systems can perform organized work under real conditions. Biological function is inseparable from regulated transformation. A tissue, organism, or ecosystem can be described structurally, but its continued life depends on pathway activity through time.
Ecology, Microbiology, and Biogeochemical Relevance
Enzymes are central to ecology because ecological systems are built from metabolizing organisms whose interactions transform energy and matter. Decomposition, nutrient cycling, carbon fixation, nitrification, denitrification, methanogenesis, fermentation, sulfate reduction, toxin degradation, lignin breakdown, cellulose decomposition, and organic matter turnover all depend on enzyme-mediated processes. In that sense, ecological function is inseparable from biochemical pathway function expressed across populations and communities.
Microbiology makes this especially clear. Microbes drive many of the transformations that regulate soil fertility, wastewater treatment, sediment chemistry, symbiosis, decomposition, food webs, methane flux, nitrogen cycling, and carbon turnover. Their ecological importance often lies not in visible size or organismal complexity, but in the catalytic capacities distributed through microbial communities.
This is one reason enzymes belong naturally within sustainability-adjacent biology. Biogeochemical cycles are not abstract planetary circulations detached from life. They are mediated by living systems, many of them microbial, acting through enzymes and pathways that determine how matter moves, accumulates, transforms, or is released under changing environmental conditions.
Enzyme activity therefore provides one of the biochemical bridges between organisms and planetary systems. Life shapes Earth partly by catalyzing its chemistry. That catalytic work is visible in soils, sediments, oceans, forests, wetlands, wastewater systems, host microbiomes, and agricultural landscapes.
Marine, Freshwater, Soil, Plant, and Fungal Relevance
Marine biology provides a strong example of enzyme-centered ecology. Marine primary production, nutrient uptake, microbial recycling, sulfur transformations, nitrogen metabolism, carbon fixation, coral symbiosis, and microbial loop dynamics all depend on enzyme systems expressed under changing conditions of light, temperature, oxygen, salinity, acidification, and nutrient availability. Enzyme activity helps shape plankton growth, fish physiology, algal blooms, marine microbial metabolism, and ocean biogeochemistry.
Freshwater biology shows similar dependence. Eutrophication, oxygen depletion, decomposition, organic matter turnover, algal blooms, sediment chemistry, pollutant breakdown, and nutrient recycling all involve pathway-level biochemical processes distributed across aquatic organisms and microbial communities. Freshwater systems are therefore not only hydrological and ecological systems. They are also enzyme-mediated biochemical systems.
Soil biology is deeply enzymatic. Soil microbes, fungi, plant roots, and invertebrates regulate decomposition, nutrient mobilization, carbon turnover, nitrogen transformation, phosphorus availability, organic matter stabilization, and the maintenance or loss of fertility through catalytic processes. Soil enzyme activity is often used as an indicator of soil biological function because it reflects active transformation rather than static composition alone.
Plant science and agroecology are equally relevant. Photosynthesis, respiration, nitrogen assimilation, lignin formation, starch metabolism, hormone synthesis, stress response, defense chemistry, flowering, and growth regulation all depend on enzyme systems integrated across cells, tissues, and environments. Fungi add still another layer because fungal extracellular enzymes are central to decomposition, symbiosis, wood decay, soil carbon cycling, and nutrient exchange. Forestry, restoration ecology, and food systems therefore depend not only on organisms in the large, but on the biochemical capacities through which those organisms live and respond.
Medical, Biomedical, and Disease Ecology Relevance
Enzymes are foundational to medicine and biomedicine because disease often reflects altered catalysis, misregulated pathways, abnormal signaling, enzyme deficiency, enzyme overactivity, or measurable enzyme release. Enzyme-linked diagnostics, biomarker interpretation, drug metabolism, coagulation pathways, inflammatory cascades, detoxification, inherited metabolic disease, mitochondrial disorders, and cancer metabolism all depend on enzyme biology.
Drug discovery also depends heavily on enzymes, both as targets and as tools. Kinases, proteases, polymerases, phosphatases, metabolic enzymes, oxidoreductases, transferases, and enzyme-linked receptors are central to pharmacology and therapeutic development. Enzymes are attractive drug targets because their activity can often be measured, inhibited, enhanced, or modified in controlled ways.
Disease ecology adds a broader layer. Pathogens depend on enzyme systems to invade, replicate, evade, metabolize, and persist, while hosts respond through their own regulated biochemical pathways. Environmental change can alter enzyme-mediated pathogen survival, host metabolism, vector biology, microbiome composition, and toxin processing. Enzyme function therefore links molecular mechanism to organismal health and ecological interaction.
This is why enzyme biology matters across clinical medicine and ecological health. It helps explain disease not only as symptom or pathogen presence, but as disrupted biochemical regulation under particular biological and environmental conditions. It also helps explain why the same enzyme or pathway can be therapeutic in one context, harmful in another, and ecologically decisive in a third.
Biotechnology, Bioinformatics, and Computational Relevance
Biotechnology extends enzyme biology into applied systems of design, measurement, and intervention. Industrial biocatalysis, metabolic engineering, high-throughput screening, fermentation, biosensor development, molecular diagnostics, synthetic biology, biomanufacturing, environmental biotechnology, enzyme engineering, and assay development all depend on understanding enzyme kinetics, regulation, pathway structure, and assay behavior.
Enzymes are also central to platform technologies. Polymerases enable amplification and sequencing. Ligases enable molecular assembly. Restriction enzymes support cloning. Reporter enzymes enable assay readouts. Reverse transcriptases enable RNA-to-DNA workflows. Engineered catalytic systems support biomanufacturing, drug discovery, environmental remediation, synthetic pathway construction, and diagnostic testing. In these contexts, enzyme biology is not only explanatory. It is operational.
Computational biology strengthens this further by allowing scientists to model kinetic parameters, simulate pathway behavior, estimate control coefficients, fit dose-response curves, compare inhibition models, analyze assay data, interpret flux constraints, and explore multiscale datasets. Enzymes thus become units not only of catalysis, but of inference, optimization, and intervention.
This makes enzyme biology one of the clearest meeting points between classical biochemistry and modern computational science. Kinetic equations, experimental assays, pathway networks, and code-based reproducibility all belong to the same scientific workflow. A modern enzyme study increasingly requires both biochemical interpretation and computational traceability.
Mathematical Lens
Modern enzyme biology is not only structural and mechanistic. It is also quantitative. Reaction velocities, substrate affinities, inhibition patterns, pathway fluxes, assay signals, catalytic efficiencies, feedback relationships, and allosteric responses can all be formalized mathematically and analyzed statistically. This makes enzyme biology especially suitable for computational workflows because quantitative interpretation is already built into the science.
A standard starting point is the Michaelis-Menten relation:
Interpretation: Michaelis-Menten kinetics links substrate concentration to enzyme-catalyzed reaction velocity.
where \(v\) is reaction velocity, \(V_{\max}\) is the maximal velocity at saturating substrate concentration, \([S]\) is substrate concentration, and \(K_m\) is the substrate concentration at which velocity is half-maximal under the classical model.
A useful comparative quantity is catalytic efficiency:
Interpretation: Catalytic efficiency compares turnover capacity with substrate requirement.
where \(k_{\mathrm{cat}}\) is the turnover number and \(K_m\) is the Michaelis constant. This matters because two enzymes can have similar maximal behavior under one assay condition yet differ substantially in how effectively they use low substrate concentrations.
A simplified competitive inhibition model can be written as:
Interpretation: Competitive inhibition increases the apparent substrate requirement in the classical model.
where \([I]\) is inhibitor concentration and \(K_i\) is the inhibition constant. This is useful because competitive inhibition increases the apparent \(K_m\) without changing \(V_{\max}\) in the classical model.
A simplified noncompetitive inhibition model can be written as:
Interpretation: Noncompetitive inhibition reduces apparent catalytic capacity rather than only competing with substrate.
This is useful because noncompetitive inhibition reduces apparent catalytic capacity rather than simply competing with substrate at the active site.
Some enzymes show cooperative or allosteric behavior that can be represented with a Hill-type curve:
Interpretation: Hill-type response captures cooperative, threshold-like, or allosteric enzyme behavior.
where \(n\) is the Hill coefficient and \(K\) is a half-response parameter. This is useful for capturing switch-like responses, cooperative binding, and pathway thresholds.
A compact pathway-flux approximation may be written as:
Interpretation: Pathway throughput can be constrained by the slowest or most limiting step.
where \(J\) is pathway flux and \(v_i\) are step-specific capacities. This is an oversimplified but useful teaching model because pathway throughput can be constrained by bottleneck steps rather than by average enzyme activity.
A simple product-feedback model can be written as:
Interpretation: Product feedback dampens upstream pathway velocity as downstream product accumulates.
where \([P]\) is product concentration and \(K_f\) is a feedback sensitivity parameter. This is useful because pathways often regulate themselves through downstream products that dampen upstream activity.
A Lineweaver-Burk-style reciprocal transformation can be written as:
Interpretation: Reciprocal linearization can teach parameter relationships, though nonlinear fitting is usually preferred for modern analysis.
This transformation is useful as a teaching scaffold, but modern enzyme analysis usually benefits from direct nonlinear fitting because reciprocal transformations can distort error structure.
Variables, Units, and Enzyme Interpretation
Quantitative enzyme biology depends on variables that connect reaction velocity, substrate concentration, enzyme capacity, inhibition, feedback, and pathway flux to biological interpretation. The table below summarizes several central quantities.
| Symbol or Term | Meaning | Typical Unit or Scale | Enzyme or Pathway Interpretation |
|---|---|---|---|
| \(v\) | Reaction velocity | concentration per time, product per time, assay units per time | Rate of enzyme-catalyzed product formation or substrate consumption |
| \(V_{\max}\) | Maximum reaction velocity | same as \(v\) | Upper reaction velocity under saturating substrate conditions |
| \([S]\) | Substrate concentration | mM, μM, mol/L, assay concentration | Amount of reactant available to the enzyme |
| \(K_m\) | Michaelis constant | same unit as substrate concentration | Substrate level associated with half-maximal velocity under classical assumptions |
| \(k_{\mathrm{cat}}\) | Turnover number | per second or per unit time | Number of substrate molecules converted per enzyme active site per unit time under saturating conditions |
| \(k_{\mathrm{cat}}/K_m\) | Catalytic efficiency | concentration-1 time-1 | Comparative measure of enzyme performance, especially under low substrate conditions |
| \([I]\) | Inhibitor concentration | mM, μM, mol/L, or assay concentration | Amount of inhibitory compound affecting enzyme activity |
| \(K_i\) | Inhibition constant | same unit as inhibitor concentration | Strength of inhibitor interaction in simplified inhibition models |
| \(n\) | Hill coefficient | dimensionless | Steepness or cooperativity of an allosteric response |
| \(K\) | Half-response parameter | same unit as substrate concentration | Substrate level associated with half-maximal Hill-type response |
| \([P]\) | Product concentration | mM, μM, mol/L, or assay concentration | Downstream product that may inhibit or regulate pathway activity |
| \(K_f\) | Feedback sensitivity parameter | same unit as product concentration | Product level associated with feedback dampening in a simplified model |
| \(J\) | Pathway flux | amount per time, concentration per time, or model-specific flux unit | Overall throughput through a pathway or pathway segment |
| \(v_i\) | Step-specific velocity or capacity | same as \(v\) or model-specific capacity | Rate or capacity of one enzyme-controlled step in a pathway |
The table shows why enzyme data require context. A velocity, \(K_m\), \(K_i\), or catalytic-efficiency value becomes biologically meaningful only when linked to assay conditions, enzyme identity, substrate, pH, temperature, cofactors, inhibitors, and cellular or ecological interpretation.
Worked Example: Reaction Velocity, Inhibition, and Efficiency
Suppose an enzyme has \(V_{\max}=120\) units/min and \(K_m=5\) mM. At substrate concentration \([S]=10\) mM, the predicted velocity is:
Interpretation: Reaction velocity depends on maximal capacity, substrate level, and the Michaelis constant.
Substituting the values:
Interpretation: The substrate concentration is twice \(K_m\), so the reaction is above half-maximal velocity.
Solving:
Interpretation: The predicted reaction velocity is 80 units per minute.
This is useful because it immediately connects substrate availability to expected catalytic performance. The same framework can be used in metabolic analysis, assay design, drug-response evaluation, environmental enzyme analysis, and engineered pathway optimization.
At \([S]=K_m\), the Michaelis-Menten equation simplifies to:
Interpretation: In the classical model, \(K_m\) is the substrate concentration associated with half-maximal velocity.
This is useful because it shows why \(K_m\) is interpreted as the half-maximal substrate concentration under classical Michaelis-Menten assumptions.
Now suppose \(V_{\max}=120\), \(K_m=5\), \([S]=10\), \([I]=4\), and \(K_i=2\). Under the competitive inhibition model:
Interpretation: The inhibitor increases the apparent substrate requirement by competing with substrate.
Solving:
Interpretation: The predicted inhibited velocity is 48 units per minute.
This is useful because it shows how inhibitor concentration can reduce velocity by increasing the effective substrate requirement.
Catalytic efficiency can also be compared. Suppose enzyme A has \(k_{\mathrm{cat}}=75\ \mathrm{s}^{-1}\) and \(K_m=5\ \mathrm{mM}\), while enzyme B has \(k_{\mathrm{cat}}=120\ \mathrm{s}^{-1}\) and \(K_m=12\ \mathrm{mM}\). Then:
Interpretation: Enzyme A has catalytic efficiency of 15 in the chosen reciprocal concentration-time units.
Interpretation: Enzyme B has higher turnover but lower catalytic efficiency under this comparison.
This shows why \(V_{\max}\) or \(k_{\mathrm{cat}}\) alone may be misleading. Enzyme performance depends on both turnover and substrate requirement.
Computational Modeling
Computational modeling helps make enzyme biology explicit because enzyme systems are quantitative, regulated, and context-sensitive. Michaelis-Menten curves link substrate to velocity. Inhibition models compare regulatory mechanisms. Hill curves represent cooperative response. Parameter-fitting workflows estimate kinetic quantities from assay data. Feedback models show how downstream products can dampen pathway flux. Bottleneck models identify limiting steps in simplified pathway systems.
The selected examples below focus on compact, reusable workflows: Michaelis-Menten curves, competitive and noncompetitive inhibition, nonlinear least-squares fitting, feedback-inhibited flux, catalytic efficiency comparison, grid-search fitting, and pathway bottleneck scoring. The GitHub repository extends the same logic into richer workflows for enzyme assay provenance, Lineweaver-Burk teaching plots, Hill allostery, condition scoring, SQL metadata structures, notebooks, validation scripts, and multi-language scientific-computing examples.
The purpose is not to reduce enzyme biology to equations alone. The purpose is to make catalytic evidence inspectable. An enzyme claim becomes stronger when substrate levels, velocity measurements, kinetic models, fitting assumptions, assay conditions, cofactors, inhibitors, and code are documented together.
R Workflow: Kinetics, Inhibition, Fitting, and Feedback Flux
R is useful for enzyme biology because it supports curve fitting, tabular analysis, model comparison, and reproducible reporting. The following workflow compares Michaelis-Menten kinetics under control, competitive inhibition, and noncompetitive inhibition; fits Michaelis-Menten parameters from synthetic assay data; and simulates feedback-inhibited pathway flux.
# Enzymes, Regulation, and Biochemical Pathways Workflow
#
# This workflow demonstrates four quantitative enzyme-biology tasks:
#
# 1. Compare Michaelis-Menten, competitive inhibition,
# and noncompetitive inhibition curves.
# 2. Fit Michaelis-Menten parameters from assay data.
# 3. Simulate product-feedback inhibition.
# 4. Identify a simplified pathway bottleneck.
#
# These examples can be adapted for enzyme assays, drug screening,
# metabolic engineering, environmental enzyme analysis, soil enzymes,
# marine biochemistry, and pathway modeling.
library(tibble)
library(dplyr)
# ------------------------------------------------------------
# 1. Michaelis-Menten and inhibition comparison
# ------------------------------------------------------------
kinetics_df <- tibble(
substrate_mM = seq(0.1, 30, length.out = 300)
) %>%
mutate(
Vmax = 120,
Km = 5,
inhibitor_mM = 4,
Ki_mM = 2,
control_velocity =
(Vmax * substrate_mM) / (Km + substrate_mM),
competitive_velocity =
(Vmax * substrate_mM) /
(Km * (1 + inhibitor_mM / Ki_mM) + substrate_mM),
noncompetitive_velocity =
(Vmax / (1 + inhibitor_mM / Ki_mM)) *
substrate_mM / (Km + substrate_mM)
)
half_max_row <- kinetics_df %>%
slice(which.min(abs(control_velocity - unique(Vmax) / 2)))
# ------------------------------------------------------------
# 2. Fit Michaelis-Menten parameters from synthetic assay data
# ------------------------------------------------------------
set.seed(42)
assay_df <- tibble(
substrate_mM = c(0.5, 1, 2, 4, 8, 12, 20, 30)
) %>%
mutate(
true_Vmax = 120,
true_Km = 5,
velocity_clean =
(true_Vmax * substrate_mM) / (true_Km + substrate_mM),
velocity_observed = velocity_clean + rnorm(n(), mean = 0, sd = 3)
)
fit <- nls(
velocity_observed ~ (Vmax * substrate_mM) / (Km + substrate_mM),
data = assay_df,
start = list(Vmax = 100, Km = 4)
)
fit_parameters <- tibble(
parameter = names(coef(fit)),
estimate = as.numeric(coef(fit))
)
assay_fit_df <- assay_df %>%
mutate(
predicted_velocity = predict(fit),
residual = velocity_observed - predicted_velocity
)
# ------------------------------------------------------------
# 3. Product-feedback inhibition
# ------------------------------------------------------------
feedback_df <- tibble(
substrate_mM = seq(0.1, 30, length.out = 200),
product_mM = seq(0, 20, length.out = 200)
) %>%
mutate(
Vmax = 120,
Km = 5,
Kf = 6,
base_velocity =
(Vmax * substrate_mM) / (Km + substrate_mM),
feedback_factor =
1 / (1 + product_mM / Kf),
feedback_velocity =
base_velocity * feedback_factor
)
# ------------------------------------------------------------
# 4. Simplified pathway bottleneck scoring
# ------------------------------------------------------------
pathway_df <- tibble(
step = c(
"uptake",
"activation",
"conversion",
"branch_commitment",
"product_release"
),
enzyme = c(
"transporter",
"kinase",
"isomerase",
"dehydrogenase",
"exporter"
),
capacity = c(88, 72, 95, 54, 80),
regulation_factor = c(0.95, 0.80, 0.90, 0.70, 0.85)
) %>%
mutate(
effective_capacity = capacity * regulation_factor
)
estimated_flux <- min(pathway_df$effective_capacity)
bottleneck_row <- pathway_df %>%
slice(which.min(effective_capacity))
print(head(round(kinetics_df, 4), 12))
print(tail(round(kinetics_df, 4), 12))
print(round(half_max_row, 4))
print(round(fit_parameters, 4))
print(round(assay_fit_df, 4))
print(head(round(feedback_df, 4), 12))
print(tail(round(feedback_df, 4), 12))
print(round(pathway_df, 3))
print(paste("Estimated pathway flux:", round(estimated_flux, 3)))
print(bottleneck_row)This R workflow is useful because enzyme biology often depends on comparing models rather than calculating one curve. Control kinetics, inhibitor behavior, fitted parameters, feedback dampening, and pathway bottlenecks can all be expressed in one reproducible structure.
Python Workflow: Kinetics, Efficiency, Parameter Fitting, and Bottlenecks
Python is useful for enzyme biology because it supports numerical modeling, parameter sweeps, assay pipelines, simulation, and reproducible computation. The following workflow computes Michaelis-Menten and inhibition curves, compares catalytic efficiency across enzyme variants, estimates kinetic parameters through grid search, and scores a simplified pathway bottleneck.
"""
Enzymes, Regulation, and Biochemical Pathways Workflow
This workflow demonstrates four quantitative enzyme-biology tasks:
1. Compare Michaelis-Menten, competitive inhibition, and
noncompetitive inhibition curves.
2. Compare enzyme variants by catalytic efficiency.
3. Fit Michaelis-Menten parameters by transparent grid search.
4. Estimate pathway bottlenecks from simplified capacity and regulation data.
The examples are compact, but the same structures can be extended to
enzyme assays, drug screening, metabolic engineering, environmental enzyme
analysis, soil enzymes, marine biochemistry, and systems biology.
"""
from __future__ import annotations
import numpy as np
import pandas as pd
def kinetics_and_inhibition(
vmax: float = 120.0,
km: float = 5.0,
inhibitor: float = 4.0,
ki: float = 2.0,
) -> pd.DataFrame:
"""
Compute control, competitive, and noncompetitive enzyme velocities.
"""
substrate = np.linspace(0.1, 30.0, 300)
control = (vmax * substrate) / (km + substrate)
competitive = (vmax * substrate) / (
km * (1.0 + inhibitor / ki) + substrate
)
noncompetitive = (
(vmax / (1.0 + inhibitor / ki)) * substrate / (km + substrate)
)
return pd.DataFrame(
{
"substrate_mM": substrate,
"control_velocity": control,
"competitive_velocity": competitive,
"noncompetitive_velocity": noncompetitive,
}
)
def catalytic_efficiency_table() -> pd.DataFrame:
"""
Compare enzyme variants by catalytic efficiency.
"""
enzymes = pd.DataFrame(
{
"enzyme": ["variant_A", "variant_B", "variant_C", "variant_D"],
"kcat_per_s": [75.0, 120.0, 45.0, 90.0],
"Km_mM": [5.0, 12.0, 2.5, 4.0],
}
)
enzymes["catalytic_efficiency"] = (
enzymes["kcat_per_s"] / enzymes["Km_mM"]
)
return enzymes.sort_values(
"catalytic_efficiency",
ascending=False,
)
def fit_michaelis_menten_by_grid_search() -> tuple[pd.DataFrame, pd.DataFrame]:
"""
Estimate Michaelis-Menten parameters through transparent grid search.
This is a teaching scaffold. In production workflows, nonlinear
optimization or Bayesian fitting may be more appropriate.
"""
rng = np.random.default_rng(42)
substrate = np.array([0.5, 1, 2, 4, 8, 12, 20, 30], dtype=float)
true_vmax = 120.0
true_km = 5.0
velocity_clean = (true_vmax * substrate) / (true_km + substrate)
velocity_observed = velocity_clean + rng.normal(0, 3, size=len(substrate))
vmax_grid = np.linspace(80, 150, 141)
km_grid = np.linspace(1, 12, 111)
rows = []
for vmax in vmax_grid:
for km in km_grid:
predicted = (vmax * substrate) / (km + substrate)
sse = float(np.sum((velocity_observed - predicted) ** 2))
rows.append(
{
"Vmax": vmax,
"Km": km,
"SSE": sse,
}
)
fit_df = pd.DataFrame(rows)
best = fit_df.sort_values("SSE").head(1)
assay_df = pd.DataFrame(
{
"substrate_mM": substrate,
"velocity_observed": velocity_observed,
}
)
best_vmax = float(best.iloc[0]["Vmax"])
best_km = float(best.iloc[0]["Km"])
assay_df["predicted_velocity"] = (
best_vmax * assay_df["substrate_mM"]
) / (best_km + assay_df["substrate_mM"])
assay_df["residual"] = (
assay_df["velocity_observed"] - assay_df["predicted_velocity"]
)
return best, assay_df
def pathway_bottleneck_scoring() -> tuple[pd.DataFrame, pd.Series]:
"""
Estimate simplified pathway bottleneck from capacity and regulation data.
"""
pathway = pd.DataFrame(
{
"step": [
"uptake",
"activation",
"conversion",
"branch_commitment",
"product_release",
],
"enzyme": [
"transporter",
"kinase",
"isomerase",
"dehydrogenase",
"exporter",
],
"capacity": [88, 72, 95, 54, 80],
"regulation_factor": [0.95, 0.80, 0.90, 0.70, 0.85],
}
)
pathway["effective_capacity"] = (
pathway["capacity"] * pathway["regulation_factor"]
)
bottleneck = pathway.loc[pathway["effective_capacity"].idxmin()]
return pathway, bottleneck
def main() -> None:
"""
Run compact enzyme-biology workflows.
"""
kinetics_df = kinetics_and_inhibition()
half_max_row = kinetics_df.iloc[
(kinetics_df["control_velocity"] - 60.0).abs().argmin()
]
efficiency_df = catalytic_efficiency_table()
best_fit, assay_fit = fit_michaelis_menten_by_grid_search()
pathway_df, bottleneck = pathway_bottleneck_scoring()
print("Michaelis-Menten and inhibition comparison:")
print(kinetics_df.head(12).round(4).to_string(index=False))
print(kinetics_df.tail(12).round(4).to_string(index=False))
print("\nApproximate half-maximal control row:")
print(half_max_row.round(4).to_string())
print("\nCatalytic efficiency comparison:")
print(efficiency_df.round(4).to_string(index=False))
print("\nBest Michaelis-Menten grid-search fit:")
print(best_fit.round(4).to_string(index=False))
print("\nAssay fit table:")
print(assay_fit.round(4).to_string(index=False))
print("\nPathway bottleneck scoring:")
print(pathway_df.round(3).to_string(index=False))
print("\nEstimated bottleneck:")
print(bottleneck.round(3).to_string())
if __name__ == "__main__":
main()This Python workflow is useful because enzyme biology often moves from molecular mechanism to inference. Kinetic models, catalytic-efficiency comparisons, parameter fitting, and pathway bottleneck scoring give scientists a transparent computational scaffold for interpreting catalytic function under constraint.
GitHub Repository
The article body includes compact R and Python examples so the biological and scientific argument remains readable. The full repository expands those examples into a broader computational enzyme-biology workflow, including Michaelis-Menten kinetics, competitive and noncompetitive inhibition, Hill-style allostery, catalytic efficiency comparison, assay parameter fitting, feedback-inhibited pathway flux, pathway bottleneck analysis, enzyme condition scoring, SQL provenance structures, reproducible data files, and full-stack scientific-computing examples across Python, R, Julia, Fortran, Rust, Go, C, C++, SQL, and notebooks.
Complete Code Repository
The full code distribution for this article, including selected article examples, expanded computational workflows, reproducible data structures, provenance documentation, and full-stack scientific-computing scaffolding, is available on GitHub.
Limits, Scaling, and Modern Pathway Thinking
Enzyme biology is foundational, but it is not simple. Kinetic parameters may change with pH, temperature, ionic conditions, cofactors, crowding, compartmentalization, post-translational modification, interacting pathways, redox state, and cellular architecture. A reaction characterized cleanly in vitro may behave differently in cells, tissues, microbiomes, soils, estuaries, organisms, or bioreactors. Pathway behavior may depend less on a single enzyme than on distributed control across multiple steps.
This is why modern pathway thinking increasingly emphasizes networks, flux, constraint, regulation, and system context. Enzymes remain central, but their importance is often relational rather than isolated. A key enzyme is often key because it sits at a branch point, couples pathways, mediates control under changing conditions, or constrains flux under real biological demand.
Models and workflows are useful because they clarify assumptions, expose patterns, and make comparison possible. But a Michaelis-Menten curve is not a full cell, a fitted \(K_m\) is not a complete pathway model, and a bottleneck score is not a replacement for biological interpretation. Quantitative enzyme biology is strongest when it supports mechanistic reasoning rather than replacing it.
In that sense, enzymes provide a model case for modern biology itself: mechanistic, quantitative, environmentally conditioned, computationally analyzable, and irreducible to any single scale of explanation. The strongest enzyme analysis connects molecular parameters to pathway context, cellular conditions, organismal function, ecological setting, and experimental provenance.
Why This Matters for Scientific Work
For working scientists, enzyme biology matters because many biological systems are governed not merely by the presence of molecules, but by the rates, controls, and constraints of their conversion. A metabolic phenotype may depend on flux through a branch point rather than total metabolite abundance alone. A microbial ecosystem may hinge on catalytic bottlenecks that regulate nitrogen turnover or carbon mineralization. A plant stress response may depend on enzyme regulation under drought or salinity rather than gross anatomical change. A disease process may depend on pathway dysregulation, cofactor limitation, altered catalytic efficiency, or abnormal enzyme release rather than the absence of a protein outright.
This means enzymes should often be treated as explanatory infrastructure rather than a narrow biochemistry topic. Physiologists need them because regulated chemistry underlies function. Ecologists need them because biogeochemical cycles are catalytic realities distributed across living systems. Biomedical scientists need them because diagnosis, therapy, and pharmacology are deeply enzyme-linked. Computational biologists need them because pathway models, assay data, kinetic inference, and flux analysis are core quantitative problems in modern biology.
The scientific importance of enzymes lies partly in this breadth. They are among the principal ways biology explains how living systems remain active, adaptive, constrained, vulnerable, and possible.
Enzyme biology is also practically actionable. Enzyme rates can be measured, inhibitors can be compared, kinetic parameters can be fitted, pathway flux can be estimated, cofactors can be controlled, and engineered variants can be optimized. This makes enzymes central to experimental design, clinical interpretation, biotechnology, environmental monitoring, and reproducible biological modeling.
Conclusion
Enzymes, regulation, and biochemical pathways show that life depends on organized catalysis. Enzymes lower activation barriers, coordinate reaction timing, regulate flux, and connect cellular chemistry to physiology, ecology, disease, and environmental change. They are therefore not merely molecular details within biology. They are among the principal ways biology explains how living systems turn chemistry into organized function.
To understand enzymes is to understand that life is not simply made of molecules. It is made of regulated transformations among molecules, ordered in time, space, and pathway context. That is why enzymes remain central not only to biochemistry and cell biology, but also to medicine, marine and freshwater biology, soil biology, plant science, fungal biology, microbiology, agroecology, disease ecology, biotechnology, and systems biology.
Enzyme biology is thus one of the clearest places where molecular precision meets systems-level consequence. It helps explain how living systems remain active, adaptive, vulnerable, and possible. Modern computational workflows deepen that understanding by making kinetic behavior, inhibition, feedback, assay fitting, and pathway bottlenecks transparent enough to test, compare, and reproduce.
Related Articles
- Biology
- Biomolecules and the Chemical Basis of Life
- Metabolism, Energy, and Biological Function
- Molecular Biology and the Flow of Genetic Information
- Cell Signaling, Communication, and Biological Coordination
- Physiology and the Regulation of Living Systems
- Microbiology and the Hidden Majority of Life
- Fungi and the Networks of Decomposition and Exchange
- Plant Biology and the Life of Primary Producers
- Biogeochemical Cycles and the Conditions of Habitability
- Immunology and Biological Defense
- Systems Biology and the Logic of Biological Integration
Further Reading
- Alberts, B. et al. (2002) ‘Catalysis and the use of energy by cells’, in Molecular Biology of the Cell. 4th edn. New York: Garland Science. Available at: https://www.ncbi.nlm.nih.gov/books/NBK26838/
- Alberts, B. et al. (2002) ‘Protein function’, in Molecular Biology of the Cell. 4th edn. New York: Garland Science. Available at: https://www.ncbi.nlm.nih.gov/books/NBK26911/
- Alberts, B. et al. (2002) ‘Regulation of protein function’, in Molecular Biology of the Cell. 4th edn. New York: Garland Science. Available at: https://www.ncbi.nlm.nih.gov/books/NBK9923/
- Alberts, B. et al. (2002) ‘The central role of enzymes as biological catalysts’, in The Cell: A Molecular Approach. 2nd edn. Sunderland, MA: Sinauer Associates. Available at: https://www.ncbi.nlm.nih.gov/books/NBK9921/
- Berg, J.M., Tymoczko, J.L. and Stryer, L. (2002) Biochemistry. 5th edn. New York: W.H. Freeman. Available at: https://www.ncbi.nlm.nih.gov/books/NBK21154/
- Borowy, C.S. et al. (2022) ‘Physiology, zero- and first-order kinetics’, in StatPearls. Treasure Island, FL: StatPearls Publishing. Available at: https://www.ncbi.nlm.nih.gov/books/NBK499866/
- Delaune, K.P. et al. (2022) ‘Physiology, noncompetitive inhibitor’, in StatPearls. Treasure Island, FL: StatPearls Publishing. Available at: https://www.ncbi.nlm.nih.gov/books/NBK545242/
- Konieczny, L. (2023) Interrelationship in Organized Biological Systems. Available at: https://www.ncbi.nlm.nih.gov/books/NBK599594/
- Konieczny, L. (2023) Regulation in Biological Systems. Available at: https://www.ncbi.nlm.nih.gov/books/NBK599592/
- Lewis, T. (2023) ‘Biochemistry, proteins enzymes’, in StatPearls. Treasure Island, FL: StatPearls Publishing. Available at: https://www.ncbi.nlm.nih.gov/books/NBK554481/
- NCBI Bookshelf (2012) Basics of Enzymatic Assays for HTS. Available at: https://www.ncbi.nlm.nih.gov/sites/books/NBK92007/
- Wintheiser, G.A. et al. (2022) ‘Physiology, tyrosine kinase receptors’, in StatPearls. Treasure Island, FL: StatPearls Publishing. Available at: https://www.ncbi.nlm.nih.gov/books/NBK538532/
References
- Alberts, B. et al. (2002) ‘Catalysis and the use of energy by cells’, in Molecular Biology of the Cell. 4th edn. New York: Garland Science. Available at: https://www.ncbi.nlm.nih.gov/books/NBK26838/
- Alberts, B. et al. (2002) ‘Protein function’, in Molecular Biology of the Cell. 4th edn. New York: Garland Science. Available at: https://www.ncbi.nlm.nih.gov/books/NBK26911/
- Alberts, B. et al. (2002) ‘Regulation of protein function’, in Molecular Biology of the Cell. 4th edn. New York: Garland Science. Available at: https://www.ncbi.nlm.nih.gov/books/NBK9923/
- Alberts, B. et al. (2002) ‘The central role of enzymes as biological catalysts’, in The Cell: A Molecular Approach. 2nd edn. Sunderland, MA: Sinauer Associates. Available at: https://www.ncbi.nlm.nih.gov/books/NBK9921/
- Berg, J.M., Tymoczko, J.L. and Stryer, L. (2002) Biochemistry. 5th edn. New York: W.H. Freeman. Available at: https://www.ncbi.nlm.nih.gov/books/NBK21154/
- Borowy, C.S. et al. (2022) ‘Physiology, zero- and first-order kinetics’, in StatPearls. Treasure Island, FL: StatPearls Publishing. Available at: https://www.ncbi.nlm.nih.gov/books/NBK499866/
- Delaune, K.P. et al. (2022) ‘Physiology, noncompetitive inhibitor’, in StatPearls. Treasure Island, FL: StatPearls Publishing. Available at: https://www.ncbi.nlm.nih.gov/books/NBK545242/
- Konieczny, L. (2023) Interrelationship in Organized Biological Systems. Available at: https://www.ncbi.nlm.nih.gov/books/NBK599594/
- Konieczny, L. (2023) Regulation in Biological Systems. Available at: https://www.ncbi.nlm.nih.gov/books/NBK599592/
- Lewis, T. (2023) ‘Biochemistry, proteins enzymes’, in StatPearls. Treasure Island, FL: StatPearls Publishing. Available at: https://www.ncbi.nlm.nih.gov/books/NBK554481/
- NCBI Bookshelf (2012) Basics of Enzymatic Assays for HTS. Available at: https://www.ncbi.nlm.nih.gov/sites/books/NBK92007/
- Wintheiser, G.A. et al. (2022) ‘Physiology, tyrosine kinase receptors’, in StatPearls. Treasure Island, FL: StatPearls Publishing. Available at: https://www.ncbi.nlm.nih.gov/books/NBK538532/