
Last Updated May 28, 2026
DNA, RNA, and the molecular logic of life examine how living systems store hereditary information, copy it across generations, interpret it within cells, regulate it across time and context, and convert it into biological function. This topic sits near the center of biology because it explains one of life’s deepest achievements: the ability to preserve information materially while also using that information dynamically across cells, tissues, organisms, populations, and environments.
DNA provides a comparatively stable medium of hereditary storage. RNA provides a more diverse and dynamic set of informational, structural, catalytic, and regulatory molecules. Protein synthesis is one of the major ways encoded information becomes embodied biological activity. Yet the molecular logic of life is not a rigid one-way script. It is a regulated, context-dependent system shaped by replication, transcription, translation, repair, chromatin organization, RNA diversity, environmental response, and evolutionary history.
Main Library
Publications
Article Map
Biology
Related Library
Natural Science
Related Topic
Mathematical Modeling
Related Topic
Data Systems & Analytics
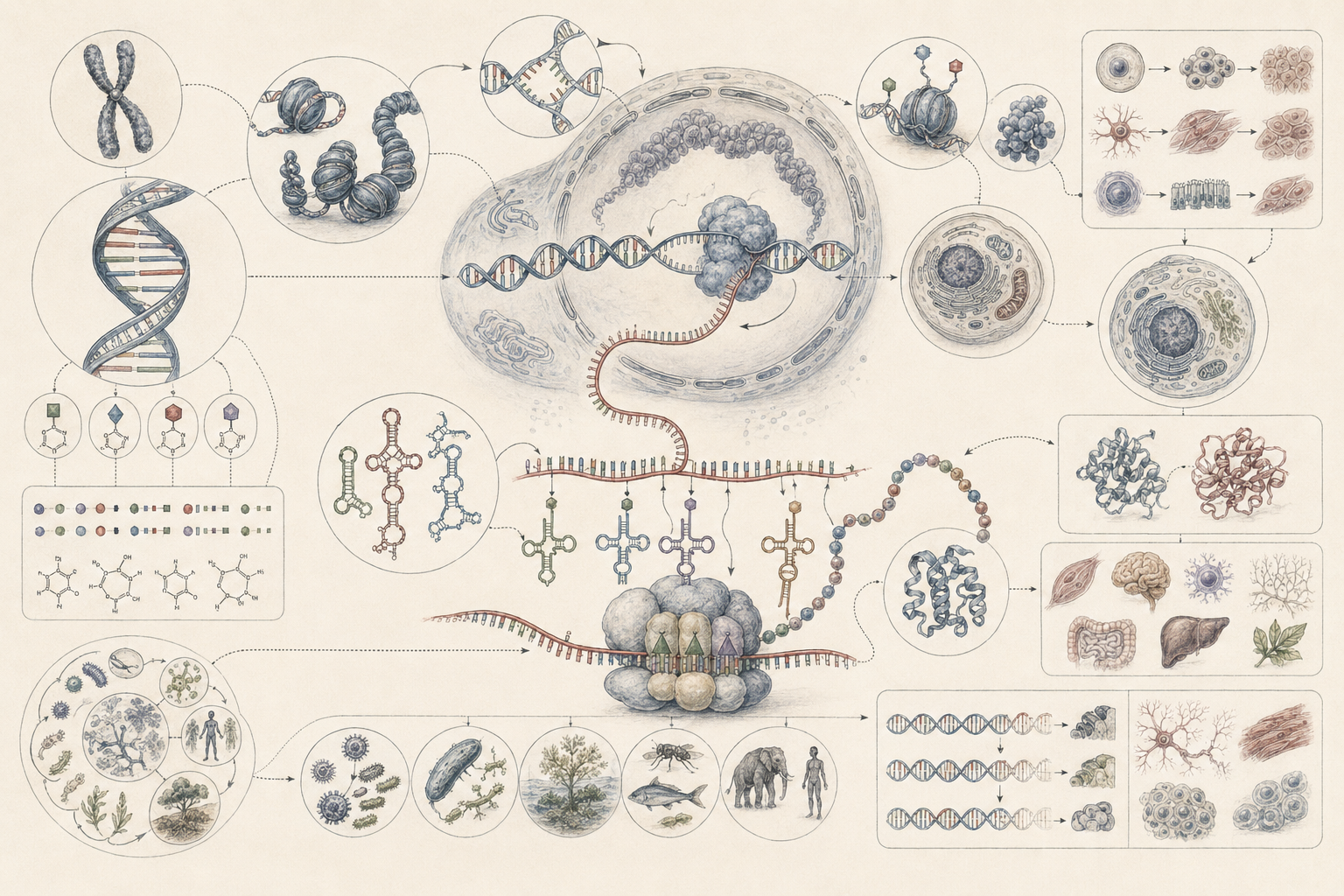
What DNA and RNA Are
DNA and RNA are nucleic acids that occupy a central place in modern biology because they help explain how hereditary information is stored, transmitted, regulated, and expressed. DNA is generally the primary hereditary storage medium in cellular life, while RNA performs a wider range of roles than a simple intermediary description suggests, including coding, structural, catalytic, and regulatory functions.
This makes DNA and RNA foundational not only to genetics but to biology as a whole. They are not merely chemical substances present in cells. They are among the major ways biological continuity becomes materially stable while still allowing regulation, variation, and evolutionary change. DNA helps preserve sequence information across cell divisions and generations. RNA helps mobilize, interpret, diversify, and regulate that information within living time.
The molecular logic of life therefore begins with a simple but profound fact: living systems preserve information in matter while also using that information dynamically. DNA and RNA are central to that achievement. They allow life to be simultaneously stable and responsive, inherited and regulated, continuous and historically open to change.
This dual role is one reason nucleic acids are so scientifically powerful. They can be studied as molecules, but also as information-bearing structures. A DNA sequence is a chemical polymer, a hereditary record, a regulatory substrate, a comparative dataset, and a historical trace of evolutionary process. RNA is likewise not one thing biologically. It can be a message, a structural component, a regulatory molecule, a catalytic participant, a viral genome, or an experimental readout of cellular state.
DNA as Hereditary Storage
DNA is especially important because it combines relative stability with copyability. Its double-helical structure, complementary base pairing, and template-based replication make it well suited to long-term hereditary storage. Replication mechanisms can preserve sequence with high fidelity while still permitting rare changes that later become biologically consequential.
This stability matters because heredity depends on continuity. Without a relatively robust information-bearing medium, organisms could not preserve developmental programs, physiological capacities, or lineage identity across generations. DNA does not function alone, but it does provide one of the most important long-term material bases of biological continuity.
Yet DNA storage is not passive. DNA exists within chromatin, chromosomes, repair systems, replication forks, regulatory landscapes, and cellular surveillance mechanisms. The fact that DNA is stable does not mean it is inert. It is biologically active in part because cells continuously maintain, copy, package, protect, and interpret it.
This is why DNA should be understood as both a molecule and a system-level biological substrate. Its sequence matters, but so do its organization, accessibility, repair, replication timing, chromosomal position, and regulatory context. DNA stores information, but life depends on the regulated management of that stored information.
DNA also matters because it links individual organisms to deep biological history. Each genome carries inherited variation, ancestral traces, evolutionary constraints, duplicated segments, regulatory architectures, mutation histories, and lineage-specific adaptations. DNA is therefore not only a cell-level molecule. It is also a historical substrate through which biology studies continuity across generations and divergence across evolutionary time.
RNA as Information Intermediary and Regulatory System
RNA is often introduced as the molecule that carries information from DNA to the protein-synthesis machinery, but this is only part of its biological importance. RNA performs many roles in the cell, from carrying instructions for protein synthesis to regulating genes, participating in ribosomal structure, interacting with proteins, shaping transcript stability, and contributing to RNA processing. Messenger RNA, transfer RNA, ribosomal RNA, microRNA, small interfering RNA, long noncoding RNA, and other RNA classes extend RNA function well beyond simple messenger status.
This broader understanding matters because it changes the logic of molecular biology. RNA is not only an intermediate step between DNA and protein. It is part of the machinery of translation, part of regulatory networks, and in some biological contexts part of catalytic function itself. Molecular life therefore depends not on a single informational line, but on layered nucleic-acid systems whose roles differ in stability, timing, structure, regulation, and function.
RNA’s dynamism also makes it central to regulation. Transcript abundance, RNA processing, splicing, localization, turnover, translation efficiency, and noncoding regulatory activity all shape how genetic information becomes biologically effective in particular cells under particular conditions. RNA therefore helps explain why the same genome can support many biological states.
RNA is also a key bridge between molecular biology and environmental response. RNA abundance can change rapidly when cells encounter stress, pathogens, nutrient limitation, salinity shifts, temperature change, oxygen stress, developmental signals, or immune activation. In that sense, RNA often records living response more immediately than DNA sequence itself. DNA may define inherited capacity; RNA often reveals which parts of that capacity are being mobilized.
The Classical Flow of Genetic Information
The classical framework of molecular biology is often summarized as the flow of information from DNA to RNA to protein. This remains powerful because it captures a major directional logic of hereditary expression: DNA is replicated, transcribed into RNA, and translated into protein.
But the strength of this framework lies in disciplined use, not oversimplification. It does not mean RNA is biologically trivial, that all genes encode proteins, that regulation is secondary, or that information flow is never modified, interrupted, reversed, or context-dependent. Modern molecular biology has deepened rather than erased the central logic by showing how much complexity surrounds and conditions it.
The classical flow therefore remains foundational, but it is best understood as a structured principle within a larger molecular system. It gives biology a core logic without pretending that all molecular reality is linear or simple. DNA, RNA, and protein synthesis remain central, but they operate within networks of regulation, repair, chromatin architecture, cellular state, environmental response, and evolutionary history.
This distinction matters scientifically. A linear diagram is helpful for orientation, but living systems are regulated systems, not static diagrams. Gene expression depends on chromatin accessibility, transcriptional regulation, RNA processing, translation control, protein folding, modification, localization, degradation, and feedback from cellular and environmental state. The flow of genetic information is real, but it is not merely mechanical. It is conditional, regulated, and embedded.
Replication, Transcription, and Translation
Replication, transcription, and translation are three of the most important molecular processes in biology because they connect continuity to function. Replication copies hereditary material before cell division. Transcription produces RNA from DNA templates. Translation converts nucleotide information in messenger RNA into amino acid sequence through ribosomal machinery.
These processes matter because they are not simply chemical events. They are coordinated biological mechanisms supported by enzymes, accessory proteins, template recognition, proofreading, error correction, molecular machines, and cellular regulation. A living cell does not merely contain DNA, RNA, and proteins. It actively manages the transitions among them.
This is one reason molecular biology became so scientifically powerful. It rendered life experimentally legible at a level where continuity, change, and function could be tracked through identifiable molecular processes. The central transitions from DNA to RNA to protein made heredity, variation, development, disease, and evolution more mechanistically understandable.
Replication preserves information, transcription mobilizes information, and translation converts information into molecular function. Together, they form one of the most important process architectures in biology.
Each process also has its own failure modes and regulatory sensitivities. Replication errors can become mutations. Transcriptional disruption can alter gene expression. Translation defects can impair protein production. Misfolded or mistargeted proteins can disrupt cellular function. DNA-RNA biology therefore explains not only normal function, but also vulnerability, pathology, adaptation, and evolutionary change.
Genetic Code, Ribosomes, and Protein Synthesis
The genetic code refers to the correspondence between nucleotide triplets and amino acids during translation. Ribosomes interpret this code through coordinated interaction with messenger RNA and transfer RNAs, producing polypeptides that later fold into functional proteins.
This matters because protein synthesis is one of the main ways hereditary information becomes embodied biological activity. Enzymes, structural proteins, receptors, transporters, motors, transcription factors, and signaling molecules all depend on translation. The code is therefore not an abstract symbolic system detached from life. It is one of the major bridges between stored sequence and biological function.
The ribosome is central here because it shows that the molecular logic of life is machinic in a precise biological sense: informational sequence is read through a regulated molecular apparatus that couples codon recognition to peptide assembly. That is one of the clearest places where heredity becomes function.
Protein synthesis also makes clear that molecular biology is relational. DNA sequence matters because it can be transcribed; RNA matters because it can be interpreted; ribosomes matter because they coordinate translation; proteins matter because they alter cellular activity. No single component explains the system alone.
This is also where biological information becomes embodied. A codon is not merely a symbol. It participates in a cellular process that requires amino acids, transfer RNAs, ribosomes, energy, initiation factors, elongation factors, termination mechanisms, folding environments, and quality control. The genetic code operates as biology only because it is embedded in molecular machinery.
Regulation, Chromatin, and Context-Dependent Expression
DNA sequence alone does not explain when or where genes are active. Modern molecular biology therefore places strong emphasis on regulation, chromatin structure, and context-dependent expression. Gene expression can behave like both an on/off switch and a volume control. Chromatin organization matters because it affects accessibility to replication and transcription machinery, and more condensed or more open states alter transcriptional access.
This is why the molecular logic of life is not rigid. The same genome can support very different patterns of activity in different cell types, developmental stages, physiological states, and environmental conditions. Regulation is one of the main ways biological specificity emerges from shared hereditary material.
In practical terms, regulation means that stored information becomes biologically meaningful only under conditions of access, timing, dosage, and cellular interpretation. Sequence is foundational, but expression is conditional. Gene regulation, chromatin accessibility, enhancer activity, transcription-factor binding, RNA processing, and transcript turnover all help determine which molecular possibilities become actual biological states.
This regulatory view is essential for understanding development, physiology, disease, adaptation, and ecology. A genome is not simply read. It is interpreted.
Regulation also provides a bridge between molecular biology and environmental biology. Cells alter expression in response to nutrient availability, pathogens, toxins, temperature, light, salinity, oxygen, pH, mechanical stress, hormones, and developmental signals. These responses do not rewrite the whole genome. They alter the use of inherited information under living conditions. Molecular biology therefore explains how inherited stability and environmental responsiveness coexist.
Mutation, Repair, and Molecular Change
DNA must be both stable and changeable if life is to persist and evolve. Mutation introduces sequence change, while repair systems help preserve viability by correcting many forms of damage and replication error. This duality is biologically important because it links molecular biology to evolution, disease, and adaptation.
Too much instability threatens viability. Too little variation would constrain long-term evolutionary possibility. The molecular logic of life therefore depends on a balance between fidelity and change. Replication must be accurate enough to preserve continuity, but not so perfect that hereditary systems become permanently closed to variation.
Repair is as important as mutation in this balance. Biology is not only a science of how information changes, but of how living systems actively preserve usable continuity under conditions of chemical and environmental threat. DNA repair, proofreading, recombination, checkpoint systems, and damage response mechanisms all help determine the boundary between viable continuity and destructive instability.
This is why mutation and repair matter across medicine, cancer biology, microbial evolution, conservation genetics, and environmental biology. Molecular change is not merely an abstract source of variation. It is one of the places where life’s need for stability meets its openness to history.
RNA adds another layer to this story. RNA molecules can be processed, edited, degraded, stabilized, localized, translated, or silenced. In RNA viruses, RNA can also serve directly as hereditary material. Molecular change therefore occurs through both stable genomic inheritance and dynamic regulatory systems. DNA-RNA biology must account for both long-term continuity and short-term molecular responsiveness.
DNA, RNA, and Biological Function Across Scales
DNA and RNA are foundational not because they replace higher levels of biology, but because they help explain how higher levels are possible. Development depends on regulated gene expression. Physiology depends on molecular pathways, proteins, and signaling systems whose production and turnover are genetically and transcriptionally controlled. Reproduction depends on replication and transmission of hereditary material. Immune response depends on regulated molecular activation. Metabolism depends on enzymes whose synthesis and control are molecularly mediated.
This means molecular biology must be understood across scales. The same informational logic that governs transcription in a single cell can shape tissue differentiation, organismal stress response, population adaptation, and ecosystem resilience over time. Molecular processes are therefore not merely beneath organismal biology. They are part of what makes it intelligible.
The importance of DNA and RNA lies in this explanatory reach: they connect material sequence to functional organization without collapsing the richness of life into a single level of analysis. Nucleic-acid systems help biology explain how cells remember, respond, differentiate, reproduce, repair, and evolve.
This scale-spanning role is especially important for scientists working across disciplinary boundaries. A marine biologist may use RNA expression to interpret heat stress. A plant scientist may use DNA markers to study drought tolerance. A medical researcher may study mutation and expression in disease. A microbial ecologist may use environmental DNA and RNA to infer community composition and activity. DNA-RNA biology gives these fields a shared molecular language while preserving their different biological contexts.
Ecology, Evolution, and Sustainability-Adjacent Biology
Molecular biology is deeply relevant to ecology and sustainability-adjacent biology because organisms respond to environments through regulated molecular systems. Stress tolerance, nutrient use, symbiosis, host-pathogen interaction, adaptive response, and population persistence all have molecular dimensions. Environmental change becomes biologically real in part through changes in expression, repair, sequence integrity, and selection on variants.
Evolutionary biology is especially important here because sequence change, gene duplication, recombination, horizontal transfer, and regulatory divergence contribute to long-term adaptation and diversification. Molecular biology therefore gives ecology and evolution a mechanistic layer without replacing population- or ecosystem-level explanation.
This matters for sustainability because resilience, vulnerability, and adaptive capacity are not only ecological abstractions. They are partly rooted in molecular capacities distributed across populations, species, and communities under changing environmental conditions. Molecular diversity, regulatory plasticity, repair capacity, and expression response can influence whether organisms endure stress, adapt, or decline.
This perspective is especially important under rapid environmental change. Climate warming, acidification, drought, pollution, eutrophication, salinization, deoxygenation, habitat fragmentation, invasive species, and disease emergence can all become visible at the molecular level before they are obvious at population or ecosystem scale. DNA and RNA therefore help scientists read early biological response, hidden variation, and emerging risk.
Marine, Freshwater, Soil, Plant, and Microbial Relevance
Marine biology makes the ecological importance of DNA and RNA especially vivid. Marine microbes, phytoplankton, coral symbionts, fishes, and invertebrates regulate gene expression in response to warming, salinity shifts, oxygen stress, acidification, pathogens, and nutrient limitation. Molecular biology is therefore central not only to laboratory genomics, but to understanding how ocean life responds to environmental change.
Freshwater biology presents similar molecular challenges under eutrophication, pollution, thermal stress, hydrologic disturbance, and habitat fragmentation. Soil biology and microbiology are equally molecular, since decomposition, nutrient cycling, carbon turnover, horizontal gene exchange, biofilm formation, and microbial resilience depend on gene-regulated metabolism and genetic variation distributed across communities.
Plant science and agroecology also depend on this molecular logic. Photosynthesis, stress response, nutrient uptake, flowering, seed development, disease resistance, and root-microbe communication all involve regulated DNA-RNA-protein systems. Forestry, restoration ecology, and food systems therefore increasingly rely on molecular methods and molecular understanding.
Across these fields, DNA and RNA are not only laboratory topics. They are part of how living systems respond to climate stress, ecosystem disturbance, pathogens, nutrient constraints, and restoration challenges. They also help reveal biological activity that may not be visible through morphology alone: hidden microbial communities, stress-response transcripts, adaptive alleles, pathogen variants, and regulatory shifts that shape ecological outcomes.
Medical, Biomedical, and Disease Ecology Relevance
DNA and RNA are foundational to medicine and biomedicine because heredity, mutation, expression, and molecular regulation all shape disease, diagnosis, and therapy. Cancer involves genomic instability and altered expression. Infectious disease depends on host-pathogen interaction at molecular interfaces. Developmental disorders can arise from inherited or de novo changes in sequence or regulation. Molecular diagnostics increasingly rely on amplification, sequencing, and expression-based detection.
RNA has also become especially prominent in contemporary biomedicine because it is central not only to normal gene expression but also to therapeutic design, viral biology, and molecular diagnostics. RNA abundance, RNA processing, RNA stability, and RNA-based regulation are now important across cancer biology, immunology, virology, developmental disease, and biotechnology.
Disease ecology adds another scale: hosts differ in inherited susceptibility, pathogens evolve through molecular change, and environments shape transmission and selective pressures. DNA and RNA therefore connect molecular mechanism to clinical outcome and ecological dynamics. A pathogen genome, a host transcriptome, a tumor mutation profile, or an environmental DNA signal can all become evidence in the study of disease.
This molecular evidence matters because disease often begins before symptoms are visible. A mutation may alter risk, a transcriptomic pattern may signal stress, a viral RNA sequence may reveal transmission history, and an expression shift may indicate immune activation or therapeutic response. DNA-RNA biology therefore gives medicine and public health a way to detect, classify, compare, and intervene in biological processes with high precision.
Biotechnology, Bioinformatics, and Computational Relevance
Biotechnology extends DNA and RNA biology into applied systems of analysis, intervention, and design. Recombinant DNA technology, cloning, amplification, sequencing, gene editing, molecular diagnostics, transcriptomics, metagenomics, synthetic biology, and RNA-based therapeutics all depend on understanding how nucleic-acid information is stored, copied, read, regulated, and modified.
Bioinformatics strengthens this transformation by allowing sequence alignment, assembly, annotation, expression analysis, variant calling, comparative genomics, transcript quantification, codon analysis, and molecular data integration at scales impossible without computation. Molecular information becomes not only a biochemical substrate but also a structured analyzable data object.
This makes DNA and RNA among the clearest examples of biology becoming data-rich without ceasing to be biological. Molecules of heredity are also analyzable information structures, and useful modern biology increasingly depends on both interpretations at once. The scientific value of DNA-RNA biology now depends heavily on reproducible workflows, transparent assumptions, careful provenance, and computational literacy.
This also creates a responsibility for scientific documentation. A sequence result is not merely a string of bases. It is produced through sampling, extraction, sequencing, quality control, alignment, reference choice, filtering, annotation, normalization, and interpretation. Transcriptomics likewise depends on experimental design, sequencing depth, normalization method, batch effects, tissue identity, time point, condition, and biological context. DNA-RNA biology is therefore also a reproducibility and data-governance problem.
Mathematical Lens
Modern DNA-RNA biology is not only mechanistic. It is also quantitative. Replication fidelity, transcript abundance, decay rates, sequence similarity, mutation frequency, codon usage, GC fraction, expression change, and molecular condition scores can all be analyzed mathematically and computationally. This makes molecular biology especially suitable for reproducible statistical workflows.
A simple model for transcript decay is:
m(t)=m_0e^{-kt}
\]
Interpretation: Transcript abundance declines through time according to initial abundance and decay rate.
where \(m(t)\) is transcript abundance at time \(t\), \(m_0\) is initial abundance, and \(k\) is the decay constant.
The corresponding half-life is:
t_{1/2}=\frac{\ln 2}{k}
\]
Interpretation: Transcript half-life is the time required for RNA abundance to decline by half.
This is useful because RNA abundance depends not only on production, but also on turnover.
A more realistic continuous model for transcript abundance is:
\frac{dm}{dt}=\alpha(t)-\beta m
\]
Interpretation: Transcript abundance reflects a dynamic balance between production and degradation.
where \(\alpha(t)\) is the effective production rate and \(\beta\) is the degradation constant. This is useful because expression often reflects dynamic balance between synthesis and loss, not decay alone.
A common measure of differential expression between two conditions is:
\log_2FC=\log_2\left(\frac{E_2+\epsilon}{E_1+\epsilon}\right)
\]
Interpretation: Log2 fold change expresses expression differences on a symmetric scale.
where \(E_1\) and \(E_2\) are expression levels in two different conditions and \(\epsilon\) is a small pseudocount. This is useful because doubling and halving become easy to interpret.
A simple observed difference between equal-length sequences can be written as:
d=\frac{m}{L}
\]
Interpretation: Observed sequence difference is the fraction of aligned positions that differ.
where \(m\) is the number of mismatches and \(L\) is sequence length.
A Jukes-Cantor correction gives:
d_{\mathrm{JC}}=-\frac{3}{4}\ln\left(1-\frac{4d}{3}\right)
\]
Interpretation: Jukes-Cantor correction adjusts observed difference for hidden substitutions under a simple evolutionary model.
This is useful because raw mismatch counts can underestimate deeper divergence when multiple substitutions occur at the same site.
A simple GC-content measure is:
GC=\frac{G+C}{A+T+G+C}
\]
Interpretation: GC content measures the fraction of DNA bases that are guanine or cytosine.
For RNA datasets, \(U\) replaces \(T\). This is useful because composition can influence thermodynamics, codon usage, sequencing behavior, genome organization, and comparative molecular interpretation.
For a codon \(c\), a simple codon frequency is:
f_c=\frac{n_c}{\sum_j n_j}
\]
Interpretation: Codon frequency measures how often codon \(c\) appears relative to all codons observed.
where \(n_c\) is the count of codon \(c\) and \(\sum_j n_j\) is the total number of codons observed. This is useful because coding sequences are not only strings to compare; they also carry compositional and translational patterns.
A simple mutation-rate estimate can be written as:
\mu=\frac{m}{N\cdot L\cdot g}
\]
Interpretation: Mutation rate estimates observed mutations relative to genomes, sites, and generations surveyed.
where \(m\) is the number of observed mutations, \(N\) is the number of genomes or individuals observed, \(L\) is the number of sites surveyed, and \(g\) is the number of generations or replication cycles. This is useful because molecular change must be interpreted relative to opportunity for mutation.
Variables, Units, and DNA-RNA Interpretation
Quantitative DNA-RNA biology depends on variables that connect abundance, decay, expression change, sequence composition, molecular distance, mutation, and translation to biological interpretation. The table below summarizes several central quantities.
| Symbol or Term | Meaning | Typical Unit or Scale | DNA-RNA Interpretation |
|---|---|---|---|
| \(m(t)\) | Transcript abundance at time \(t\) | counts, TPM, normalized expression, fluorescence, or arbitrary units | Amount of RNA transcript measured or modeled at a given time |
| \(m_0\) | Initial transcript abundance | same as \(m(t)\) | Starting transcript level before decay or perturbation |
| \(k\) | Decay constant | per unit time | Rate of exponential transcript loss |
| \(t_{1/2}\) | Transcript half-life | time | Time required for transcript abundance to decline by half |
| \(\alpha(t)\) | Production rate | abundance per time | Time-dependent synthesis or transcriptional input |
| \(\beta\) | Degradation constant | per unit time | Rate of transcript removal in production-decay models |
| \(E_1, E_2\) | Expression values in two conditions | counts, normalized counts, TPM, FPKM, fluorescence, or assay units | Molecular expression levels being compared across conditions |
| \(\epsilon\) | Pseudocount | same as expression value | Small value used to avoid division by zero in fold-change calculations |
| \(\log_2FC\) | Log2 fold change | log2 ratio | Symmetric measure of expression change between conditions |
| \(d\) | Observed sequence distance | fraction from 0 to 1 | Share of aligned positions with mismatches |
| \(d_{\mathrm{JC}}\) | Jukes-Cantor corrected distance | substitutions per site under a simple model | Corrected molecular distance accounting for hidden substitutions |
| \(G,C,A,T,U\) | Nucleotide counts | counts | Observed number of nucleotide bases in DNA or RNA sequence |
| \(GC\) | GC content | fraction or percentage | Share of DNA or RNA sequence composed of guanine and cytosine |
| \(f_c\) | Codon frequency | fraction or percentage | Relative use of codon \(c\) in a coding sequence or dataset |
| \(n_c\) | Codon count | count | Number of times codon \(c\) appears in a sequence or dataset |
| \(\mu\) | Mutation rate | mutations per site per generation or replication cycle | Mutation frequency normalized by opportunity for mutation |
| \(N\) | Number of genomes or individuals observed | count | Sample size for mutation-rate estimation |
| \(L\) | Sequence length or surveyed sites | base pairs, nucleotides, amino acids, or sites | Number of positions available for comparison or mutation |
| \(g\) | Generations or replication cycles | count | Number of opportunities for mutation across time |
The table shows why molecular data require careful interpretation. A transcript count, distance value, mutation-rate estimate, GC fraction, codon-frequency table, or fold-change score becomes biologically meaningful only when linked to sampling design, normalization, organism, tissue, environment, and measurement method.
Worked Example: Transcript Half-Life, log2 Fold Change, and Sequence Distance
Suppose a transcript starts at \(m_0=100\) arbitrary units and declines to 25 units after 4 hours. Under the exponential decay model:
m(t)=m_0e^{-kt}
\]
Interpretation: Transcript abundance declines exponentially when decay rate is approximately constant.
Substituting the values:
25=100e^{-4k}
\]
Interpretation: The observed decline can be used to estimate the transcript decay constant.
Dividing both sides by 100:
0.25=e^{-4k}
\]
Interpretation: The transcript has declined to 25 percent of its initial abundance.
Taking the natural logarithm:
\ln(0.25)=-4k
\]
Interpretation: Log transformation converts the exponential decay relation into a solvable linear expression.
Solving:
k=\frac{\ln 4}{4}\approx 0.3466\ \mathrm{h}^{-1}
\]
Interpretation: The estimated decay constant is approximately 0.3466 per hour.
The half-life is:
t_{1/2}=\frac{\ln 2}{k}\approx 2.0\ \mathrm{h}
\]
Interpretation: The transcript half-life is approximately 2 hours under these conditions.
This is useful because it turns transcript decline into an interpretable dynamic parameter rather than a descriptive observation alone.
Expression change can be interpreted similarly. If a transcript increases from 40 units in condition 1 to 160 units in condition 2, then:
\log_2\left(\frac{160}{40}\right)=\log_2(4)=2
\]
Interpretation: A fourfold increase corresponds to a log2 fold change of 2.
This is useful because a fourfold increase becomes \(+2\), while a fourfold decrease becomes \(-2\), creating a symmetric scale for molecular comparison.
Sequence comparison can also be analyzed quantitatively. Suppose two equal-length DNA sequences have 3 mismatches across 30 aligned sites. Then:
d=\frac{3}{30}=0.10
\]
Interpretation: The observed p-distance is 0.10, meaning 10 percent of aligned sites differ.
A Jukes-Cantor correction gives:
d_{\mathrm{JC}}=-\frac{3}{4}\ln\left(1-\frac{4(0.10)}{3}\right)\approx 0.107
\]
Interpretation: The corrected distance is slightly larger because it accounts for possible hidden substitutions.
This is useful because molecular comparison often begins with observed difference but must consider hidden substitutions over evolutionary time.
Computational Modeling
Computational modeling helps make DNA-RNA biology explicit because genetic information can be copied, counted, compared, translated, summarized, normalized, and analyzed across many scales. Transcript-decay models estimate RNA stability. Production-decay models represent expression dynamics under changing regulatory input. Fold-change calculations compare expression across conditions. PCA-style ordination summarizes sample-level expression patterns. Sequence-distance calculations compare molecular similarity. Codon-usage summaries connect nucleotide sequence to translation patterns. Mutation-rate formulas relate observed molecular change to opportunity for mutation.
The selected examples below focus on compact, reusable workflows: transcript half-life estimation, production-decay simulation, expression matrix summarization, log2 fold change, PCA-style ordination, codon usage, GC content, sequence distance, Jukes-Cantor correction, translation scaffolds, and pairwise distance matrices. The GitHub repository extends the same logic into richer workflows for molecular condition scoring, SQL provenance, notebooks, validation scripts, and multi-language scientific-computing examples.
The purpose is not to reduce DNA-RNA biology to code. The purpose is to make molecular evidence inspectable. A molecular claim becomes stronger when sequences, counts, normalization methods, model assumptions, sample metadata, and analytical code are documented together.
R Workflow: Transcript Decay, Production-Decay Dynamics, Expression Change, PCA, and Codon Usage
R is useful for DNA-RNA biology because it supports statistical modeling, expression summaries, matrix workflows, reproducible reporting, and sequence-feature calculations. The following workflow estimates transcript half-life, simulates production-decay expression dynamics, compares expression across conditions, creates a PCA-style ordination scaffold, and calculates codon usage and GC content.
# DNA, RNA, and the Molecular Logic of Life Workflow
#
# This workflow demonstrates five quantitative DNA-RNA biology tasks:
#
# 1. Fit an exponential transcript-decay model and estimate half-life.
# 2. Simulate production-decay expression dynamics under regulatory input.
# 3. Summarize an expression matrix and calculate log2 fold change.
# 4. Create a PCA-style ordination scaffold from expression data.
# 5. Calculate codon usage and GC content from a coding sequence.
#
# These examples can be adapted for transcriptomics, molecular ecology,
# microbial gene-expression studies, plant stress biology, diagnostics,
# biotechnology, and computational biology.
library(tibble)
library(dplyr)
library(tidyr)
library(stringr)
# ------------------------------------------------------------
# 1. Transcript decay and half-life estimation
# ------------------------------------------------------------
decay_df <- tibble(
time_h = c(0, 1, 2, 3, 4, 5, 6),
expr = c(100, 76, 59, 42, 25, 19, 14)
)
decay_fit <- lm(log(expr) ~ time_h, data = decay_df)
k_est <- -coef(decay_fit)[["time_h"]]
m0_est <- exp(coef(decay_fit)[["(Intercept)"]])
half_life_h <- log(2) / k_est
decay_summary <- tibble(
k_est = k_est,
m0_est = m0_est,
half_life_h = half_life_h,
r_squared_log_space = summary(decay_fit)$r.squared
)
decay_result <- decay_df %>%
mutate(
predicted_expr = exp(predict(decay_fit)),
residual = expr - predicted_expr
)
# ------------------------------------------------------------
# 2. Production-decay expression dynamics
# ------------------------------------------------------------
simulate_production_decay <- function(
times,
alpha_base = 2,
alpha_pulse = 18,
pulse_start = 2,
pulse_end = 5,
beta = 0.35,
m0 = 5
) {
expression <- numeric(length(times))
expression[1] <- m0
for (i in 2:length(times)) {
dt <- times[i] - times[i - 1]
alpha_t <- ifelse(
times[i - 1] >= pulse_start & times[i - 1] <= pulse_end,
alpha_pulse,
alpha_base
)
dm <- alpha_t - beta * expression[i - 1]
expression[i] <- max(expression[i - 1] + dm * dt, 0)
}
tibble(time_h = times, expression = expression)
}
production_decay_df <- simulate_production_decay(seq(0, 12, by = 0.1))
# ------------------------------------------------------------
# 3. Expression matrix, log2 fold change, and PCA scaffold
# ------------------------------------------------------------
set.seed(42)
genes <- paste0("gene_", 1:150)
samples <- paste0("sample_", 1:8)
group <- c(rep("control", 4), rep("treated", 4))
expr_mat <- matrix(
rpois(150 * 8, lambda = 80),
nrow = 150,
ncol = 8,
dimnames = list(genes, samples)
)
# Add synthetic treatment-responsive structure.
expr_mat[1:12, 5:8] <- expr_mat[1:12, 5:8] + 45
expr_mat[13:24, 5:8] <- pmax(expr_mat[13:24, 5:8] - 20, 1)
expr_df <- as.data.frame(expr_mat) %>%
tibble::rownames_to_column("gene")
meta_df <- tibble(sample = samples, group = group)
long_expr_df <- expr_df %>%
pivot_longer(-gene, names_to = "sample", values_to = "count") %>%
left_join(meta_df, by = "sample")
gene_summary_df <- long_expr_df %>%
group_by(gene, group) %>%
summarise(mean_count = mean(count), .groups = "drop") %>%
pivot_wider(names_from = group, values_from = mean_count) %>%
mutate(
log2_fc = log2((treated + 1) / (control + 1)),
mean_expression = (treated + control) / 2
) %>%
arrange(desc(abs(log2_fc)))
log_expr <- log2(expr_mat + 1)
pca <- prcomp(t(log_expr), center = TRUE, scale. = TRUE)
pca_df <- as.data.frame(pca$x[, 1:2]) %>%
tibble::rownames_to_column("sample") %>%
left_join(meta_df, by = "sample")
# ------------------------------------------------------------
# 4. Codon usage and GC content
# ------------------------------------------------------------
coding_seq <- "ATGGCCGCCGAACTGATCGTCAAGGGTAAACCCGGGTTTAA"
codons <- str_sub(
coding_seq,
seq(1, nchar(coding_seq), by = 3),
seq(3, nchar(coding_seq), by = 3)
)
codons <- codons[codons != ""]
codon_df <- tibble(codon = codons) %>%
count(codon, sort = TRUE) %>%
mutate(fraction = n / sum(n))
bases <- str_split(coding_seq, "", simplify = TRUE)
gc_summary <- tibble(
sequence_length = nchar(coding_seq),
gc_fraction = mean(bases %in% c("G", "C"))
)
print(round(decay_summary, 4))
print(round(decay_result, 4))
print(production_decay_df %>% slice_head(n = 12) %>% mutate(expression = round(expression, 4)))
print(production_decay_df %>% slice_tail(n = 12) %>% mutate(expression = round(expression, 4)))
print(gene_summary_df %>% slice_head(n = 20))
print(pca_df)
print(codon_df)
print(gc_summary)This R workflow is useful because molecular biology increasingly studies expression programs rather than one transcript at a time. It also keeps sequence-level features connected to reproducible data summaries and interpretable biological context.
Python Workflow: Sequence Distance, Transcript Half-Life, Expression Matrix, Translation, and Codon Usage
Python is useful for DNA-RNA biology because it supports sequence parsing, numerical modeling, matrix operations, pipeline design, and reproducible computational analysis. The following workflow calculates sequence distance and Jukes-Cantor correction, builds a pairwise distance matrix, estimates transcript half-life and expression area under the curve, summarizes an expression matrix with log2 fold change and PCA-style ordination, and translates a short coding sequence while reporting codon usage and GC content.
"""
DNA, RNA, and the Molecular Logic of Life Workflow
This workflow demonstrates five quantitative DNA-RNA biology tasks:
1. Calculate observed sequence distance and Jukes-Cantor correction.
2. Build a pairwise sequence-distance matrix across multiple samples.
3. Estimate transcript half-life and expression area under the curve.
4. Summarize an expression matrix with log2 fold change and PCA-style ordination.
5. Translate a coding sequence and summarize codon usage and GC content.
The examples are compact, but the same structures can be extended to
transcriptomics, molecular ecology, microbial gene-expression studies,
plant stress biology, diagnostics, biotechnology, and computational biology.
"""
from __future__ import annotations
from collections import Counter
from itertools import combinations
import numpy as np
import pandas as pd
def jukes_cantor_distance(p_distance: float) -> float:
"""
Calculate Jukes-Cantor corrected distance from observed p-distance.
"""
if p_distance >= 0.75:
return float("nan")
return float(-(3.0 / 4.0) * np.log(1.0 - (4.0 / 3.0) * p_distance))
def pairwise_distance(seq1: str, seq2: str) -> tuple[int, float, float]:
"""
Return mismatch count, p-distance, and Jukes-Cantor distance.
"""
if len(seq1) != len(seq2):
raise ValueError("Sequences must be equal length for this simple example.")
mismatches = sum(a != b for a, b in zip(seq1, seq2))
length = len(seq1)
p_distance = mismatches / length
jc_distance = jukes_cantor_distance(p_distance)
return mismatches, p_distance, jc_distance
def sequence_distance_example() -> pd.DataFrame:
"""
Calculate distance between two DNA sequences.
"""
seq1 = "ATGCTAGCTAACGGTACCTA"
seq2 = "ATGCTGGCTATCGGTACCTA"
mismatches, p_distance, jc_distance = pairwise_distance(seq1, seq2)
return pd.DataFrame(
{
"sequence_1": [seq1],
"sequence_2": [seq2],
"length": [len(seq1)],
"mismatches": [mismatches],
"p_distance": [p_distance],
"jukes_cantor_distance": [jc_distance],
}
)
def pairwise_distance_matrix_example() -> tuple[pd.DataFrame, pd.DataFrame]:
"""
Build a pairwise sequence-distance table and matrix.
"""
sequences = {
"sample_A": "ATGCTAGCTAACGGTACCTA",
"sample_B": "ATGCTGGCTATCGGTACCTA",
"sample_C": "ATGATGGCTATCGGTTCCTA",
"sample_D": "ATGCTAGTTAACGGAACCTG",
}
rows = []
for sample_a, sample_b in combinations(sequences.keys(), 2):
mismatches, p_distance, jc_distance = pairwise_distance(
sequences[sample_a],
sequences[sample_b],
)
rows.append(
{
"seq_1": sample_a,
"seq_2": sample_b,
"mismatches": mismatches,
"p_distance": p_distance,
"jukes_cantor": jc_distance,
}
)
distance_table = pd.DataFrame(rows)
taxa = list(sequences.keys())
distance_matrix = pd.DataFrame(
np.zeros((len(taxa), len(taxa))),
index=taxa,
columns=taxa,
)
for _, row in distance_table.iterrows():
distance_matrix.loc[row["seq_1"], row["seq_2"]] = row["jukes_cantor"]
distance_matrix.loc[row["seq_2"], row["seq_1"]] = row["jukes_cantor"]
return distance_table, distance_matrix
def transcript_half_life_example() -> tuple[pd.DataFrame, pd.DataFrame]:
"""
Estimate transcript half-life and expression area under the curve.
"""
time_h = np.array([0, 1, 2, 3, 4, 5, 6], dtype=float)
expr = np.array([100, 76, 59, 42, 25, 19, 14], dtype=float)
slope, intercept = np.polyfit(time_h, np.log(expr), 1)
k_est = -slope
m0_est = np.exp(intercept)
half_life_h = np.log(2.0) / k_est
auc = np.trapz(expr, time_h)
predicted = np.exp(intercept + slope * time_h)
summary = pd.DataFrame(
{
"k_est": [k_est],
"m0_est": [m0_est],
"half_life_h": [half_life_h],
"AUC": [auc],
}
)
trace = pd.DataFrame(
{
"time_h": time_h,
"expr_observed": expr,
"expr_predicted": predicted,
"residual": expr - predicted,
}
)
return summary, trace
def expression_matrix_example() -> tuple[pd.DataFrame, pd.DataFrame]:
"""
Create an expression matrix, summarize log2 fold change, and build PCA-style scores.
"""
rng = np.random.default_rng(7)
n_genes = 180
n_samples = 10
groups = np.array(["control"] * 5 + ["treated"] * 5)
expr = rng.poisson(lam=90, size=(n_genes, n_samples)).astype(float)
# Add synthetic treatment-responsive structure.
expr[:15, 5:] += 40
expr[15:30, 5:] = np.maximum(expr[15:30, 5:] - 25, 1)
sample_names = [f"sample_{i + 1}" for i in range(n_samples)]
gene_names = [f"gene_{i + 1}" for i in range(n_genes)]
expr_df = pd.DataFrame(expr, index=gene_names, columns=sample_names)
control_mean = expr_df.iloc[:, :5].mean(axis=1)
treated_mean = expr_df.iloc[:, 5:].mean(axis=1)
gene_summary = pd.DataFrame(
{
"gene": gene_names,
"control_mean": control_mean.values,
"treated_mean": treated_mean.values,
"log2_fc": np.log2((treated_mean.values + 1.0) / (control_mean.values + 1.0)),
}
).sort_values("log2_fc", ascending=False)
log_expr = np.log2(expr_df + 1.0)
# PCA-style ordination using singular value decomposition.
centered_by_gene = log_expr.sub(log_expr.mean(axis=1), axis=0)
x = centered_by_gene.T.values
x_centered = x - x.mean(axis=0, keepdims=True)
u, singular_values, _ = np.linalg.svd(x_centered, full_matrices=False)
scores = u[:, :2] * singular_values[:2]
pca_df = pd.DataFrame(
{
"sample": sample_names,
"group": groups,
"PC1": scores[:, 0],
"PC2": scores[:, 1],
}
)
return gene_summary, pca_df
def translation_and_codon_usage_example() -> tuple[pd.DataFrame, pd.DataFrame]:
"""
Translate a short coding sequence and summarize codon usage and GC content.
"""
coding_seq = "ATGGCCGCCGAACTGATCGTCAAGGGTAAACCCGGGTTTAA"
codon_table = {
"ATG": "M",
"GCC": "A",
"GAA": "E",
"CTG": "L",
"ATC": "I",
"GTC": "V",
"AAG": "K",
"GGT": "G",
"AAA": "K",
"CCC": "P",
"GGG": "G",
"TTT": "F",
"TAA": "*",
}
codons = [
coding_seq[i : i + 3]
for i in range(0, len(coding_seq) - 2, 3)
]
protein = "".join(codon_table.get(codon, "X") for codon in codons)
codon_counts = Counter(codons)
codon_df = pd.DataFrame(
{
"codon": list(codon_counts.keys()),
"count": list(codon_counts.values()),
}
).sort_values("count", ascending=False)
codon_df["fraction"] = codon_df["count"] / codon_df["count"].sum()
gc_fraction = sum(base in {"G", "C"} for base in coding_seq) / len(coding_seq)
sequence_summary = pd.DataFrame(
{
"coding_sequence": [coding_seq],
"protein": [protein],
"sequence_length_nt": [len(coding_seq)],
"codon_count": [len(codons)],
"gc_fraction": [gc_fraction],
}
)
return sequence_summary, codon_df
def main() -> None:
"""
Run compact DNA-RNA biology workflows.
"""
sequence_distance = sequence_distance_example()
distance_table, distance_matrix = pairwise_distance_matrix_example()
decay_summary, decay_trace = transcript_half_life_example()
gene_summary, pca_df = expression_matrix_example()
sequence_summary, codon_df = translation_and_codon_usage_example()
print("Sequence distance:")
print(sequence_distance.round(4).to_string(index=False))
print("\nPairwise sequence-distance table:")
print(distance_table.round(4).to_string(index=False))
print("\nJukes-Cantor distance matrix:")
print(distance_matrix.round(4).to_string())
print("\nTranscript half-life summary:")
print(decay_summary.round(4).to_string(index=False))
print(decay_trace.round(4).to_string(index=False))
print("\nTop expression changes:")
print(gene_summary.head(20).round(4).to_string(index=False))
print("\nPCA-style ordination:")
print(pca_df.round(4).to_string(index=False))
print("\nTranslation and sequence summary:")
print(sequence_summary.round(4).to_string(index=False))
print("\nCodon usage:")
print(codon_df.round(4).to_string(index=False))
if __name__ == "__main__":
main()This Python workflow is useful because it connects sequence comparison, transcript dynamics, condition comparison, ordination, translation, composition, and codon usage in one reproducible scaffold. The examples are compact, but the same logic can scale to transcriptomics, genomics, molecular ecology, diagnostics, biotechnology, and bioinformatics pipelines.
GitHub Repository
The article body includes compact R and Python examples so the biological and scientific argument remains readable. The full repository expands those examples into a broader computational DNA-RNA biology workflow, including transcript-decay fitting, production-decay simulation, half-life estimation, sequence-distance matrices, Jukes-Cantor correction, GC-content calculation, codon-usage summaries, DNA-to-protein translation scaffolds, expression matrices, log2 fold change, PCA-style ordination, molecular condition scoring, SQL provenance structures, validation notes, reproducible data files, and full-stack scientific-computing examples across Python, R, Julia, Fortran, Rust, Go, C, C++, SQL, and notebooks.
Complete Code Repository
The full code distribution for this article, including selected article examples, expanded computational workflows, reproducible data structures, provenance documentation, validation notes, and full-stack scientific-computing scaffolding, is available on GitHub.
Limits, Complexity, and Modern Molecular Logic
DNA and RNA are foundational, but molecular logic is not adequately captured by overly simple formulas. Not every gene encodes a protein. Not every biological outcome is predictable from sequence alone. Expression depends on regulation, chromatin accessibility, RNA processing, degradation, cellular state, developmental timing, environmental context, and evolutionary history.
This is why modern molecular thinking increasingly emphasizes integration rather than reduction. Molecular biology is strongest when connected to cell biology, genetics, physiology, development, ecology, and evolution. Sequence matters profoundly, but biological meaning arises through organized systems of interpretation and interaction.
Models and workflows are useful because they clarify assumptions, expose mechanisms, and make comparison possible. But a half-life estimate is not a complete expression system, a GC fraction is not a full genome interpretation, and a codon-usage table is not a theory of translation efficiency by itself. Quantitative DNA-RNA biology is strongest when it supports biological interpretation rather than replacing it.
In that sense, DNA and RNA provide a model case of modern biology itself: materially precise, information-rich, experimentally tractable, historically consequential, computationally analyzable, and always embedded in broader living systems.
This caution is especially important in high-throughput molecular work. A statistically significant expression change may not imply a meaningful phenotype. A sequence variant may not alter function. A transcript may be abundant but poorly translated. A reference genome may bias interpretation. Molecular data are powerful, but they require biological context, experimental provenance, and careful interpretation across scale.
Why This Matters for Scientific Work
For working scientists, DNA and RNA matter because many biological questions are misread when sequence and expression are treated as black boxes beneath organismal phenomena. A conservation problem may hinge on stress-response regulation. A disease problem may depend on transcript abundance rather than obvious structural mutation alone. A microbiology problem may turn on sequence variation, horizontal transfer, or transcriptional switching. A plant or marine systems problem may require distinguishing constitutive sequence differences from context-dependent expression response.
This means DNA-RNA biology should often be treated as explanatory infrastructure rather than as a narrow molecular specialty. Ecologists need it because environmental response has a molecular basis. Evolutionary biologists need it because heredity, variation, and selection depend on sequence systems. Biomedical scientists need it because diagnosis and mechanism increasingly rely on sequence and transcript information. Computational biologists need it because nucleic acids are among the core analyzable data types of modern life science.
The scientific importance of DNA and RNA lies partly in this breadth. They are among the principal ways biology explains how life remains continuous, adaptive, regulated, and experimentally intelligible.
DNA-RNA biology is also practically actionable. Sequences can be compared. Expression can be measured. Mutations can be detected. Transcripts can be quantified. Codon usage can be summarized. Molecular distances can be estimated. Expression matrices can be explored. These tools connect molecular theory to diagnostics, ecological monitoring, pathogen tracking, conservation genetics, plant breeding, biotechnology, and reproducible computational biology.
Conclusion
DNA, RNA, and the molecular logic of life show that living systems depend on the material storage, regulated transmission, and context-sensitive interpretation of hereditary information. DNA helps preserve continuity. RNA helps mobilize, regulate, and diversify expression. Together with translation and protein synthesis, they form one of the major molecular frameworks through which life becomes organized, functional, and historically persistent.
To understand DNA and RNA is therefore to understand one of the deepest conditions of biological possibility: that information in living systems is materially embodied, copied with high fidelity, expressed selectively, altered through time, and made functional through regulated molecular processes. That is why DNA-RNA biology remains central not only to molecular and cell biology, but also to ecology, conservation, microbiology, plant science, marine and freshwater biology, disease ecology, medicine, and biotechnology.
DNA and RNA are thus more than molecules within cells. They are among the principal ways biology explains how life remains continuous, adaptive, and scientifically intelligible. Modern quantitative and computational workflows deepen that understanding by making sequence comparison, transcript dynamics, expression change, codon usage, and molecular provenance more transparent, reproducible, and biologically interpretable.
Related articles
- Biology
- Molecular Biology and the Flow of Genetic Information
- Genes, Inheritance, and the Principles of Heredity
- Cell Theory and the Basic Unit of Life
- Mutation, Variation, and the Sources of Novelty
- Epigenetics, Regulation, and Gene Expression
- Enzymes, Regulation, and Biochemical Pathways
- Genomics and the Expansion of Biological Knowledge
- Cell Signaling, Communication, and Biological Coordination
- Development, Differentiation, and the Making of Organisms
- Systems Biology and the Logic of Biological Integration
Further reading
- Alberts, B. et al. (2002) Molecular Biology of the Cell. 4th edn. New York: Garland Science. Available at: https://www.ncbi.nlm.nih.gov/books/NBK21054/
- Alberts, B. et al. (2002) ‘How cells read the genome: From DNA to protein’, in Molecular Biology of the Cell. 4th edn. New York: Garland Science. Available at: https://www.ncbi.nlm.nih.gov/books/NBK21050/
- Alberts, B. et al. (2002) ‘From DNA to RNA’, in Molecular Biology of the Cell. 4th edn. New York: Garland Science. Available at: https://www.ncbi.nlm.nih.gov/books/NBK26887/
- Alberts, B. et al. (2002) ‘From RNA to protein’, in Molecular Biology of the Cell. 4th edn. New York: Garland Science. Available at: https://www.ncbi.nlm.nih.gov/books/NBK26829/
- Brown, T.A. (2002) ‘Genome replication’, in Genomes. 2nd edn. Oxford: Wiley-Liss. Available at: https://www.ncbi.nlm.nih.gov/books/NBK21113/
- Brown, T.A. (2002) ‘Mutation, repair and recombination’, in Genomes. 2nd edn. Oxford: Wiley-Liss. Available at: https://www.ncbi.nlm.nih.gov/books/NBK21114/
- Koonin, E.V. and Galperin, M.Y. (2003) ‘Principles and methods of sequence analysis’, in Sequence – Evolution – Function: Computational Approaches in Comparative Genomics. Boston: Kluwer Academic. Available at: https://www.ncbi.nlm.nih.gov/books/NBK20261/
- Mercadante, A.A. and Honda, B.M. (2023) ‘Biochemistry, replication and transcription’, in StatPearls. Treasure Island, FL: StatPearls Publishing. Available at: https://www.ncbi.nlm.nih.gov/books/NBK540152/
- National Human Genome Research Institute (2024) Ribonucleic Acid (RNA) Fact Sheet. Available at: https://www.genome.gov/about-genomics/educational-resources/fact-sheets/ribonucleic-acid-fact-sheet
- National Human Genome Research Institute (n.d.) Gene Expression. Available at: https://www.genome.gov/genetics-glossary/Gene-Expression
- National Human Genome Research Institute (n.d.) Gene Regulation. Available at: https://www.genome.gov/genetics-glossary/Gene-Regulation
- National Human Genome Research Institute (n.d.) Genetic Code. Available at: https://www.genome.gov/genetics-glossary/Genetic-Code
- National Human Genome Research Institute (n.d.) Recombinant DNA Technology. Available at: https://www.genome.gov/genetics-glossary/Recombinant-DNA-Technology
- National Human Genome Research Institute (n.d.) Ribosome. Available at: https://www.genome.gov/genetics-glossary/Ribosome
- Saeed, U. and Abbasi, B.A. (2019) ‘Biological sequence analysis’, in StatPearls. Treasure Island, FL: StatPearls Publishing. Available at: https://www.ncbi.nlm.nih.gov/books/NBK550342/
References
- Alberts, B. et al. (2002) Molecular Biology of the Cell. 4th edn. New York: Garland Science. NCBI Bookshelf edition Available at: https://www.ncbi.nlm.nih.gov/books/NBK21054/
- Alberts, B. et al. (2002) ‘How cells read the genome: From DNA to protein’, in Molecular Biology of the Cell. 4th edn. Available at: https://www.ncbi.nlm.nih.gov/books/NBK21050/
- Alberts, B. et al. (2002) ‘From DNA to RNA’, in Molecular Biology of the Cell. 4th edn. Available at: https://www.ncbi.nlm.nih.gov/books/NBK26887/
- Alberts, B. et al. (2002) ‘From RNA to protein’, in Molecular Biology of the Cell. 4th edn. Available at: https://www.ncbi.nlm.nih.gov/books/NBK26829/
- Brown, T.A. (2002) ‘Genome replication’, in Genomes. 2nd edn. Oxford: Wiley-Liss. Available at: https://www.ncbi.nlm.nih.gov/books/NBK21113/
- Brown, T.A. (2002) ‘Mutation, repair and recombination’, in Genomes. 2nd edn. Oxford: Wiley-Liss. Available at: https://www.ncbi.nlm.nih.gov/books/NBK21114/
- Koonin, E.V. and Galperin, M.Y. (2003) ‘Principles and methods of sequence analysis’, in Sequence – Evolution – Function: Computational Approaches in Comparative Genomics. Boston: Kluwer Academic. Available at: https://www.ncbi.nlm.nih.gov/books/NBK20261/
- Mercadante, A.A. and Honda, B.M. (2023) ‘Biochemistry, replication and transcription’, in StatPearls. Treasure Island, FL: StatPearls Publishing. Available at: https://www.ncbi.nlm.nih.gov/books/NBK540152/
- National Human Genome Research Institute (2024) Ribonucleic Acid (RNA) Fact Sheet. Available at: https://www.genome.gov/about-genomics/educational-resources/fact-sheets/ribonucleic-acid-fact-sheet
- National Human Genome Research Institute (n.d.) Gene Expression. Available at: https://www.genome.gov/genetics-glossary/Gene-Expression
- National Human Genome Research Institute (n.d.) Gene Regulation. Available at: https://www.genome.gov/genetics-glossary/Gene-Regulation
- National Human Genome Research Institute (n.d.) Genetic Code. Available at: https://www.genome.gov/genetics-glossary/Genetic-Code
- National Human Genome Research Institute (n.d.) Recombinant DNA Technology. Available at: https://www.genome.gov/genetics-glossary/Recombinant-DNA-Technology
- National Human Genome Research Institute (n.d.) Ribosome. Available at: https://www.genome.gov/genetics-glossary/Ribosome
- Saeed, U. and Abbasi, B.A. (2019) ‘Biological sequence analysis’, in StatPearls. Treasure Island, FL: StatPearls Publishing. Available at: https://www.ncbi.nlm.nih.gov/books/NBK550342/