
Last Updated May 11, 2026
Standards, interoperability, and governance in edge infrastructure determine whether heterogeneous devices, gateways, runtimes, networks, APIs, data models, firmware, accelerators, and control planes can operate as a coherent distributed system rather than a fragile collection of vendor-specific integrations. For engineers, the problem is practical: edge systems become dependable only when interfaces are explicit, schemas are versioned, devices are identifiable, lifecycle states are visible, security expectations are testable, and governance records can prove how the system is supposed to behave.
Edge infrastructure is plural by design. A single deployment may combine sensors, microcontrollers, programmable logic, industrial controllers, gateways, local inference engines, radio access networks, cloud-linked management platforms, cybersecurity controls, telemetry pipelines, AI models, and analytics services from different vendors and different eras. That pluralism is not a temporary inconvenience. It is the normal operating condition of real-world embedded and edge systems.
The architectural question is therefore not only how to connect components. It is how to preserve coherence across interfaces, standards profiles, device identities, security expectations, semantic models, lifecycle states, update policies, and governance responsibilities. Strong edge infrastructure does not merely support communication. It supports stable meaning, controlled change, bounded divergence, conformance evidence, and accountable coordination across a heterogeneous technical estate.
Main Library
Publications
Article Map
Embedded & Edge Systems
Related Topic
Data Systems & Analytics
Related Topic
Artificial Intelligence Systems
Related Topic
Intelligent Infrastructure Systems
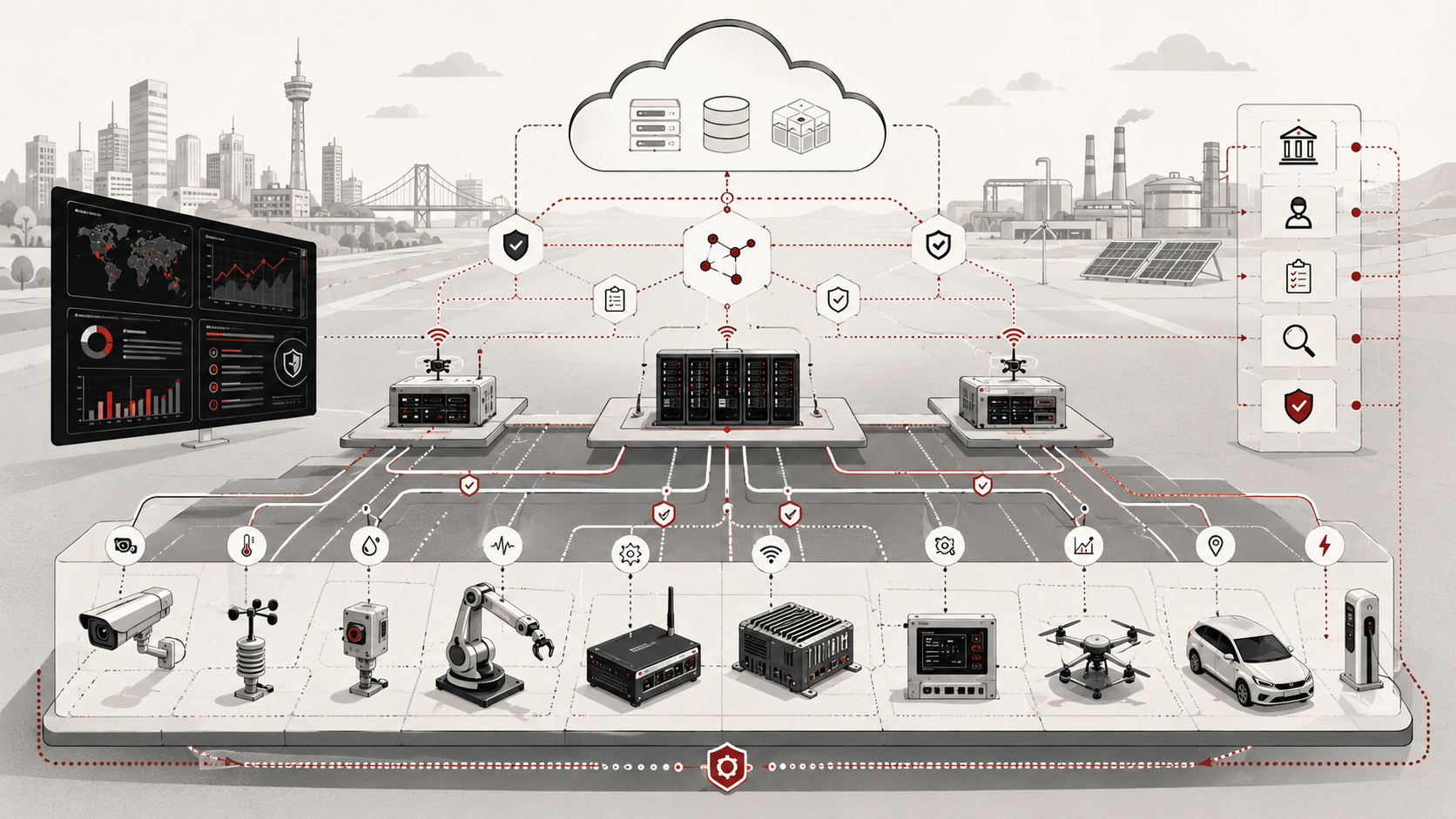
For engineers, interoperability is not a generic standards aspiration. It is a design, implementation, testing, and operations problem. A system that cannot exchange data, interpret device state, validate schema versions, govern firmware and model lifecycles, or maintain shared trust assumptions becomes increasingly expensive and risky as it scales. Standards define common expectations, but engineering practice determines whether those expectations survive deployment, maintenance, procurement, upgrade cycles, vendor transitions, and operational change.
Engineering Problem
The engineering problem is straightforward but difficult: how do you keep a distributed edge estate coherent when the estate includes different device classes, vendors, protocols, runtimes, firmware versions, schema versions, security baselines, update policies, and operational owners?
In small prototypes, engineers can often integrate systems by writing adapters, custom scripts, or one-off data transformations. That approach breaks down when the deployment grows. A production edge environment needs stable interface contracts, versioned data models, device identity records, conformance tests, lifecycle policies, compatibility matrices, support-state inventories, and evidence that each layer still behaves according to the intended profile.
Without that discipline, failures become hard to diagnose. A device may appear online while reporting telemetry under an outdated schema. A gateway may accept an event but interpret a status field differently than the device that produced it. A firmware update may preserve connectivity while breaking a downstream model. A vendor API may remain available while silently changing an error state. In each case, the system is technically connected but operationally incoherent.
For engineers, standards and governance are therefore not abstract management concerns. They are the tools that make distributed systems debuggable, testable, maintainable, replaceable, and auditable.
Reference Architecture
A practical edge interoperability architecture can be understood as a layered system. The exact technologies vary by sector, but the architectural pattern is consistent: devices produce data, gateways normalize and route data, edge runtimes perform local processing, control planes manage lifecycle and policy, and upstream systems consume telemetry, events, alerts, or model outputs.
| Layer | Engineering Role | Interoperability Concern | Governance Evidence |
|---|---|---|---|
| Device and sensor layer | Measures, actuates, infers, or controls close to the physical world | Identity, firmware, data format, timing, units, calibration, support state | Device profile, firmware version, calibration record, support-state record |
| Gateway and aggregation layer | Normalizes device traffic, buffers telemetry, applies local policy, routes events | Protocol translation, schema mapping, identity preservation, failure handling | Gateway profile, interface map, transformation logs, routing policy |
| Edge runtime layer | Runs containers, services, local analytics, inference, or stream processing | Runtime compatibility, dependency state, update behavior, workload isolation | Runtime manifest, service inventory, deployment record, health telemetry |
| Acceleration layer | Uses TinyML, FPGA, PYNQ, or HDL pipelines for local processing | Model version, overlay version, bitstream compatibility, input/output contract | Model manifest, overlay manifest, HDL interface notes, validation result |
| Data and API layer | Defines schemas, events, APIs, contracts, and semantic meaning | Schema drift, API versioning, field semantics, units, timestamps, error states | JSON schema, API profile, compatibility matrix, conformance test |
| Control and governance layer | Manages policy, lifecycle, security, ownership, audit, and escalation | Decision rights, deprecation, exceptions, incident handling, retirement | Lifecycle policy, security baseline, exception record, audit log |
This architecture is useful because it shows where interoperability actually lives. It is not only in protocols. It also lives in manifests, schemas, lifecycle records, policy files, validation scripts, telemetry contracts, model metadata, and operational runbooks.
Implementation Pattern
A production-oriented implementation pattern should begin with explicit contracts. Each device or gateway should have a machine-readable profile that defines its identity, supported protocols, schema versions, firmware version, update status, security baseline, and lifecycle state. Each telemetry stream should have a schema. Each API should have a versioned contract. Each local model or accelerator should have a manifest. Each exception should have an owner and expiration date.
A minimal engineering pattern looks like this:
| Artifact | Purpose | Typical Format |
|---|---|---|
| Device profile | Defines device identity, class, capabilities, firmware, support state, and operational role | JSON or YAML |
| Telemetry schema | Defines required fields, units, timestamps, quality flags, and semantic meaning | JSON Schema, SQL DDL, Avro, Protobuf, or equivalent |
| Interface profile | Defines API behavior, versioning rules, error states, and compatibility requirements | OpenAPI, YAML, Markdown, or formal profile document |
| Compatibility matrix | Maps device classes, firmware versions, schemas, runtime versions, and update eligibility | CSV, SQL table, YAML, or release-management system |
| Lifecycle policy | Defines onboarding, update, rollback, exception, support, and retirement rules | YAML, policy-as-code, or governance record |
| Conformance tests | Checks whether devices, gateways, schemas, and APIs match expected profiles | Python, pytest, SQL checks, CI scripts, Bash |
| Operational dashboard | Shows drift, unsupported devices, schema mismatch, failed updates, and risk bands | BI dashboard, Grafana, notebooks, CSV outputs, R reports |
The key implementation idea is that interoperability should be tested continuously rather than assumed from procurement language or vendor claims. Engineers should be able to run validation checks that answer: Which devices are out of profile? Which schemas are drifting? Which APIs are deprecated? Which firmware versions are unsupported? Which gateways are translating fields incorrectly? Which models or overlays no longer match the expected input contract?
What Standards, Interoperability, and Governance Mean in Edge Infrastructure
Standards provide structured specifications for how systems exchange information, expose functions, describe resources, manage identities, or establish trust. Interoperability is the practical ability of different systems to work together effectively. Governance is the framework of policies, roles, lifecycle rules, evidence practices, and accountability mechanisms through which interoperable systems remain coherent over time.
In embedded and edge infrastructure, these three concepts are tightly linked. A standard without adoption, profiling, testing, or conformance discipline may not produce real interoperability. Interoperability without governance may work briefly and then erode through unmanaged change. Governance without technical standards may become a patchwork of local exceptions that scales poorly and becomes difficult to audit.
Good edge architecture therefore treats these as layered concerns. Standards shape interfaces and expectations. Interoperability ensures usable integration. Governance preserves coherence as technologies, vendors, physical sites, security requirements, model versions, hardware capabilities, and operating conditions change.
This is especially important because edge systems connect digital infrastructure to the physical world. A cloud application can sometimes tolerate abstraction, redundancy, and delayed correction. Edge systems often operate under harder constraints: limited memory, constrained power, intermittent connectivity, low-latency control loops, local safety concerns, and long-lived deployed assets. Standards and governance are therefore not decorative. They are part of how physical-digital systems remain dependable.
Why Interoperability Is a First-Order Edge Problem
Interoperability is a first-order edge problem because edge systems are structurally plural. They span devices, gateways, local compute nodes, cloud-linked services, industrial protocols, telecom infrastructure, analytics platforms, cybersecurity layers, AI models, accelerators, and multiple organizational domains. In practice, no single vendor stack is likely to define the whole environment indefinitely.
This means edge infrastructure must do more than exchange packets. It must coordinate identities, APIs, event formats, data semantics, firmware versions, model versions, overlay versions, update states, security expectations, and operational roles across systems that were not necessarily designed together. ETSI’s Multi-access Edge Computing work is useful here because it treats edge computing as an environment where applications, platforms, management systems, host-level resources, and network-facing entities need a shared architectural frame.
The same issue appears in IoT and embedded systems more generally. RFC 9556 frames IoT edge computing around challenges such as time sensitivity, connectivity cost, intermittent service, privacy, security, and the need for edge functions that cannot always be satisfied by centralized cloud architectures. These constraints make interoperability more than a convenience. They make it part of the basic operating model of distributed infrastructure.
Interoperability failures accumulate. A single undocumented interface may be manageable. A fleet of undocumented interfaces becomes an integration burden. A single unsupported device may be tolerable. A class of unsupported edge devices becomes a lifecycle risk. A single data translation may be harmless. Hundreds of translations across systems can produce semantic drift, duplicated pipelines, avoidable latency, hidden security assumptions, and brittle operational dependencies.
The result is that interoperability is not simply an engineering ideal. It is a cost structure, a risk structure, and a governance structure. Systems that interoperate well are easier to maintain, audit, secure, replace, and extend. Systems that do not interoperate often become more expensive and less governable with every added device, vendor, protocol, model, schema, and site.
Standards Bodies, Profiles, and Layered Edge Architecture
Edge infrastructure is shaped not by one standard, but by overlapping standards bodies and technical domains. ETSI MEC addresses multi-access edge computing environments and application enablement. IETF and IRTF documents provide internet-layer and research-oriented framing for IoT edge challenges. NIST contributes guidance on trust, cybersecurity, lifecycle management, onboarding, and barriers to IoT adoption. W3C Web of Things specifications address web-based abstraction and description of devices and services. oneM2M focuses on interoperable IoT service layers. OPC UA is especially important in industrial contexts where structured information exchange across machines, systems, and enterprise layers is central.
This layered reality matters because infrastructure coherence often depends on profiles rather than raw standards adoption. A standard may be broad while a deployment requires a narrower interoperable subset: a defined API profile, a fixed data model, a credentialing pattern, a transport constraint, a device onboarding process, a model manifest, an overlay compatibility rule, or a lifecycle workflow. Two systems may both claim alignment with a broad standard while still failing to interoperate because they implement different optional features, interpret metadata differently, or use incompatible profile assumptions.
Good architecture therefore does not ask only, “Which standard do we use?” It also asks, “Which subset, profile, conformance expectation, test method, and compatibility boundary will keep this infrastructure coherent in practice?”
This distinction is important for procurement and governance. A procurement document that merely names a standard may not ensure interoperability. A stronger governance approach specifies version, profile, mandatory capabilities, security requirements, data schemas, test evidence, lifecycle commitments, documentation expectations, and exit conditions. That is how standards become operational infrastructure rather than symbolic compliance language.
Interfaces, APIs, and Semantic Interoperability
Technical interoperability begins at interfaces, but it does not end there. Two components may connect successfully and still fail to interoperate meaningfully if APIs are inconsistent, states are underspecified, errors are ambiguous, or data values carry different assumptions in different systems.
This is why semantic interoperability matters. Systems must not only exchange data; they must preserve meaning across the exchange. A health status, policy state, alert, update result, occupancy value, device identity, model version, sensor reading, inference output, or accelerator state should mean sufficiently similar things across participating layers that coordination remains reliable.
Strong edge architecture therefore treats APIs and interfaces as contracts, not just access points. Those contracts should define structure, lifecycle behavior, error states, security expectations, event timing, data units, versioning rules, and assumptions clearly enough that multi-vendor coordination remains stable rather than ad hoc.
Semantic interoperability is especially important when edge systems support automated or semi-automated decisions. If one system classifies a device as “healthy” because it is online, while another expects “healthy” to include secure firmware, current certificates, adequate battery state, valid telemetry schema, and supported software, then a shared label conceals a governance failure. The word is the same; the operational meaning is not.
For this reason, standards work must be joined to data modeling, documentation, testing, and monitoring. Interoperability cannot be inferred from connectivity alone. It has to be verified through evidence that systems exchange, interpret, and act upon information consistently enough for the deployment’s purpose.
Data Models, Portability, and Cross-System Meaning
Data portability and shared meaning are essential in edge systems because information often travels across local devices, gateways, site infrastructure, and upstream platforms. If those systems use incompatible schemas, inconsistent units, weak timestamp practices, or conflicting identity models, then integration becomes fragile even when the transport layer works correctly.
This means governance over data models matters as much as transport interoperability. Systems need clear definitions of entities, timestamps, state transitions, units of measurement, compatibility metadata, provenance fields, quality indicators, model inputs, inference outputs, and lifecycle fields. Without that discipline, every integration becomes a translation exercise, and each translation becomes a new point of ambiguity or failure.
Data portability also affects institutional power. If an operator cannot export device histories, configuration records, telemetry logs, incident histories, firmware versions, model versions, overlay versions, or governance evidence in usable form, then interoperability is incomplete. The system may be technically connected but organizationally locked in. Portability therefore belongs in the same conversation as standards, procurement, lifecycle management, and accountability.
Good infrastructure values stable data models, versioned schemas, and explicit treatment of semantic change. Portability without interpretability is not meaningful interoperability. Export without context is not governance. A data model should make it possible to ask not only what happened, but which device produced the event, under what configuration, with what firmware, through which interface, according to which schema, and under which policy state.
Lifecycle Governance, Versioning, and Controlled Change
Interoperable infrastructures can still fail through unmanaged change. APIs evolve, unsupported devices remain deployed, firmware versions diverge, vendor roadmaps shift, model versions change, accelerators are reconfigured, and security baselines evolve. Lifecycle governance is therefore a core part of interoperability. Systems need version awareness, compatibility boundaries, deprecation policies, change windows, asset inventories, support-state tracking, and explicit handling of what happens when one component can no longer meet the ecosystem’s expectations.
This is where edge infrastructure differs sharply from many purely software environments. Deployed devices can remain in the field for years. They may be difficult to physically access. They may operate in buildings, factories, vehicles, farms, utilities, clinics, public infrastructure, or remote environmental monitoring sites. Their software may age faster than their hardware. Their vendor support may end before the broader system is ready to replace them.
CISA’s emphasis on end-of-support edge devices highlights the governance problem directly. An edge component can become risky not because it suddenly stops functioning, but because it continues functioning after the support, update, monitoring, or assurance model around it has failed.
Strong governance therefore treats change as structured rather than incidental. It defines who can introduce new versions, how compatibility is tested, when older interfaces are retired, how unsupported components are identified, how exceptions are approved, and how transition plans are documented before silent operational debt becomes systemic risk.
Security Baselines and Trust Governance Across Vendors
Security complicates interoperability because systems may connect successfully while carrying inconsistent trust assumptions. Devices may differ in firmware assurance, update cadence, identity strength, cryptographic support, runtime isolation, vulnerability handling, incident reporting, or secure onboarding practices. A weak component can therefore become the path by which an otherwise well-governed edge environment becomes unsafe.
This means edge governance needs shared security baselines, even when full uniformity is impossible. Vendors and operators need agreed expectations around device identity, secure update behavior, support windows, vulnerability disclosure, credential rotation, logging, remote access, incident handling, and trust relationships between devices, gateways, orchestration systems, accelerators, models, and control planes.
Security baselines should not be treated as static checklists. They should be versioned and revisited as threat models, standards, vulnerabilities, and deployment contexts change. A security control that is adequate for a lab prototype may be inadequate for a public infrastructure deployment. A credential practice that works for a small pilot may become dangerous when scaled across thousands of field devices.
Good multi-vendor infrastructure therefore treats security governance as part of interoperability rather than a separate overlay. Systems should not merely interconnect; they should interconnect under conditions of bounded trust, explicit assurance expectations, and documented responsibilities.
Operational Governance and Multi-Stakeholder Coordination
Edge infrastructure is often operationally plural as well as technically plural. Manufacturers, site operators, network providers, cloud providers, integrators, cybersecurity teams, data teams, facilities managers, procurement offices, and internal engineering groups may all influence different layers of the same system. That makes governance not only a technical issue but also a coordination issue among stakeholders with different incentives and different control surfaces.
This matters because operational ambiguity can erode infrastructure coherence even when standards are sound. If no one clearly owns schema changes, credential rotation, lifecycle policy, device retirement, interface deprecation, incident escalation, conformance testing, model update approval, or accelerator validation, then fragmentation emerges through process rather than protocol.
Strong governance therefore defines roles, escalation paths, change authority, review cycles, audit evidence, and accountability boundaries. In heterogeneous edge systems, responsibility mapping is part of infrastructure design. It should be clear who owns the device inventory, who validates firmware state, who maintains API compatibility, who approves schema changes, who responds to incidents, who verifies vendor commitments, and who decides when exceptions expire.
Operational governance also needs records. A governance process that leaves no evidence is difficult to audit, improve, or defend. Edge systems should therefore maintain structured records of device identity, configuration, firmware, interface profile, security state, support status, data model version, policy exceptions, incident history, model version, and accelerator configuration. Those records are not bureaucratic overhead. They are part of what makes a distributed physical-digital estate governable.
Policy, Accountability, and Edge Decision Rights
Governance also concerns who is allowed to decide what. Edge systems increasingly include local analytics, partial autonomy, data transformation, filtering, prioritization, and policy enforcement close to where data are generated. This raises questions of decision rights: what can be decided locally, what must be synchronized centrally, what must conform to external regulation or sectoral standards, and how deviations are reviewed.
This is especially important when edge systems cross privacy, safety, labor, public infrastructure, or compliance boundaries. A technically interoperable system that lacks policy coherence may still become unmanageable or untrustworthy in practice. For example, a local gateway may be technically capable of filtering video, summarizing telemetry, flagging anomalies, or triggering action, but the authority to perform those actions may depend on context, consent, regulation, safety certification, or institutional policy.
Good governance therefore includes decision rights alongside technical standards. It should be clear which layers may enforce local policy, which changes require central approval, how exceptions are documented, which data may be processed locally, which events must be escalated, and how accountability is preserved when decisions are distributed across the infrastructure.
Accountability also requires explainability at the infrastructure level. Operators should be able to reconstruct why a device acted, why a gateway filtered or forwarded data, why an update was applied or withheld, why a model was changed, why an overlay was loaded, why a vendor component remained in service, and who had authority over the relevant policy boundary. Edge governance is therefore not only about control. It is about traceability, responsibility, and the ability to contest or correct system behavior.
Data and Configuration Artifacts
Engineers should represent interoperability assumptions as artifacts, not only as prose. In an edge system, YAML and JSON manifests, SQL schemas, test files, firmware metadata, and notebook outputs become part of the governance layer. They make assumptions machine-readable and reviewable.
| Artifact | What It Captures | Why Engineers Need It |
|---|---|---|
device_profile.json |
Device class, processor, memory, connectivity, firmware version, support state, capabilities | Prevents ambiguous device identity and supports compatibility checks |
telemetry_schema.json |
Required telemetry fields, units, timestamps, quality flags, schema version | Prevents semantic drift across devices, gateways, and upstream systems |
deployment_manifest.yml |
Runtime components, rollout ring, target environment, required validation | Makes deployments repeatable and reviewable |
lifecycle_policy.yml |
Onboarding, update, support, exception, rollback, and decommissioning rules | Connects operational decisions to explicit governance requirements |
model_manifest.json |
TinyML model version, input schema, quantization, fallback behavior | Prevents model updates from breaking edge inference contracts |
overlay_manifest.json |
PYNQ overlay version, bitstream file, interfaces, fallback overlay | Tracks FPGA-backed acceleration as part of lifecycle governance |
schema.sql |
Tables for assets, telemetry, lifecycle events, governance scores, and evidence | Makes governance queryable and auditable |
validate_manifests.sh |
Local validation of JSON/YAML configuration files | Provides repeatable command-line checks for engineering workflows |
The point is not to make every deployment use these exact filenames. The point is to make the system’s assumptions explicit enough that a new engineer, auditor, vendor, or operator can understand what is supposed to interoperate and how that claim is verified.
Mathematical Lens: Interoperability as Governance Capacity
Interoperability can be understood as a governance capacity rather than a binary property. A deployment is not simply interoperable or non-interoperable. It has degrees of protocol conformance, semantic alignment, lifecycle control, security assurance, operational accountability, and unmanaged divergence. A simple scoring model can help make that structure visible.
G_{\mathrm{edge}} = w_pP + w_sS + w_lL + w_tT + w_oO – w_dD
\]
Interpretation: \(G_{\mathrm{edge}}\) represents edge governance capacity. \(P\) is protocol conformance, \(S\) is semantic alignment, \(L\) is lifecycle control, \(T\) is trust and security baseline maturity, \(O\) is operational accountability, and \(D\) is unmanaged divergence. The weights \(w\) reflect the importance of each factor for a particular deployment.
This model is intentionally simple, but it reflects a practical truth: interoperability can be degraded by unmanaged divergence even when several individual components score well. A fleet with strong APIs but weak lifecycle records may still be risky. A system with good security controls but poor semantic alignment may still produce operational confusion. A deployment with standards-compliant devices but no accountable change process may still fragment over time.
The point of the equation is not to reduce governance to a single number. It is to make the components of governance visible enough to compare deployments, identify weak points, and justify remediation. In mature edge infrastructure, standards adoption, data modeling, lifecycle management, security baselines, and operational accountability should be measured together rather than separately.
Python Workflow: Interoperability Risk Scoring Across Edge Device Fleets
The companion Python workflow models an edge estate as a fleet of devices with protocol profiles, schema versions, firmware states, support windows, security baselines, and governance records. It calculates an interoperability governance score for each device and flags devices that create integration, lifecycle, or accountability risk.
This workflow is useful for translating governance concepts into operational evidence. Instead of treating interoperability as a narrative claim, the Python workflow turns device metadata into a repeatable scoring process. It can be adapted for procurement reviews, device inventories, edge-platform audits, migration planning, lifecycle-risk dashboards, and continuous integration checks for manifest changes.
# Python Workflow: Interoperability Risk Scoring Across Edge Device Fleets
score = (
0.20 * protocol_conformance
+ 0.20 * semantic_alignment
+ 0.20 * lifecycle_control
+ 0.20 * security_baseline
+ 0.15 * operational_accountability
- 0.15 * unmanaged_divergence
)The full companion script expands this model with typed records, CSV loading, fleet summaries, risk labels, and exportable governance reports. The emphasis is not prediction for its own sake. The point is to give edge operators a reproducible method for identifying where interoperability is becoming brittle before failures become expensive or unsafe.
For engineers, the important extension is to wire this workflow into real operational data: device inventory exports, gateway telemetry, firmware records, schema registries, vulnerability feeds, support-state records, and deployment manifests. Once the data sources are connected, the same scoring workflow becomes a practical monitoring and review tool.
R Workflow: Standards Adoption and Governance Reporting for Edge Estates
The companion R workflow focuses on reporting. It summarizes standards adoption, support-state distribution, vendor diversity, schema-version drift, risk bands, and governance maturity across an edge estate. Where Python is useful for pipeline logic, scoring, and automation, R is especially useful for statistical summaries, quality reporting, and publication-ready tables.
This workflow can support monthly governance reviews, infrastructure modernization plans, risk committee reporting, public-sector documentation, procurement analysis, or technical assurance reviews. It can also help compare sites, vendors, device classes, and protocol profiles without reducing the analysis to a single compliance checkbox.
# R Workflow: Standards Adoption and Governance Reporting for Edge Estates
governance_summary <- edge_assets |>
dplyr::group_by(site, standard_profile, support_state) |>
dplyr::summarise(
devices = dplyr::n(),
mean_governance_score = mean(governance_score, na.rm = TRUE),
high_risk_devices = sum(risk_band == "high", na.rm = TRUE),
.groups = "drop"
)The R workflow complements the mathematical lens by showing how interoperability governance can be monitored over time. A governance score is only useful if it becomes part of a reporting cycle: reviewed, challenged, updated, and tied to corrective action.
For engineering teams, the reporting layer matters because system risk often hides in distribution. One site may carry all unsupported devices. One vendor class may account for most schema drift. One gateway type may create most integration errors. Reporting makes those patterns visible enough to prioritize remediation.
Systems Code: C, C++, Rust, Go, MicroPython, TinyML, PYNQ, HDL, Bash, and Configuration
The companion repository should be useful to engineers because it connects the article’s architecture to implementation scaffolds. Each language has a distinct role in the embedded and edge systems stack.
| Folder | Engineering Role | Example Use |
|---|---|---|
c/ |
Constrained embedded logic | Device-side conformance watchdog or local validation routine |
cpp/ |
Gateway, firmware, and streaming abstractions | Semantic gateway profile validation or stream-processing policy |
rust/ |
Safe systems validation and policy tooling | Lifecycle-policy validator for support state, firmware, and interface compatibility |
go/ |
Operational services and gateway utilities | Telemetry gateway service that validates fields before forwarding |
micropython/ |
Microcontroller telemetry prototypes | Sensor reading, local preprocessing, and lightweight telemetry publishing |
tinyml/ |
Constrained on-device inference | Model manifest, fallback behavior, event-only inference, and local policy wrapper |
pynq/ |
FPGA-backed edge acceleration | Overlay manifest and compatibility validation for accelerated preprocessing |
hdl/ |
Hardware/software co-design | Verilog/VHDL stream filter for low-latency edge preprocessing |
bash/ |
Repeatable workflow execution | Manifest validation, workflow runs, output generation, cleanup |
config/ |
Machine-readable governance metadata | Device profiles, telemetry schemas, deployment manifests, lifecycle policy |
This stack is intentionally broad because embedded and edge systems are cross-layer systems. A serious engineering reference should not stop at Python notebooks. It should show how the same concept appears in device logic, gateway validation, telemetry schemas, runtime configuration, local inference, hardware acceleration, testing, and operational scripts.
Testing and Validation
Interoperability should be validated at multiple layers. Unit tests can confirm that JSON manifests contain required fields. SQL checks can identify unsupported devices or schema drift. Python tests can validate scoring logic. Gateway tests can verify required telemetry fields. Hardware-facing checks can validate model and overlay manifests before deployment.
A practical validation suite should answer these questions:
- Do all devices have stable identities and valid device profiles?
- Do telemetry events match the expected schema and unit conventions?
- Are firmware versions, model versions, and overlay versions recorded?
- Are unsupported or limited-support devices visible?
- Are deprecated API versions still in use?
- Are gateway transformations documented and testable?
- Do TinyML models declare input schemas and fallback behavior?
- Do PYNQ overlays declare bitstream versions and interface contracts?
- Do HDL modules align with the expected stream interface?
- Are exception records owned, approved, and time-limited?
The goal is not to test everything at once. The goal is to turn interoperability assumptions into checks that can run during development, deployment, and operations. If a standard, profile, schema, or policy matters, it should have some form of validation evidence.
Observability and Operational Signals
Operational observability is what allows engineers to detect interoperability failure before it becomes downtime, safety risk, privacy exposure, or expensive rework. Edge systems should report not only device health, but also interoperability health.
| Signal | What It Reveals | Why It Matters |
|---|---|---|
| Schema version by device and site | Whether telemetry formats are drifting | Prevents silent parsing and semantic failures |
| Firmware and runtime version | Whether devices and gateways remain supportable | Identifies obsolete or vulnerable components |
| API error-state distribution | Whether interface contracts are failing in practice | Surfaces vendor, gateway, or version mismatch |
| Device support state | Whether components are supported, limited, unsupported, or retired | Prevents end-of-support devices from becoming hidden risk |
| Transformation and routing logs | How gateways change data before forwarding | Supports debugging, audit, and semantic traceability |
| Model and overlay compatibility state | Whether local inference or acceleration still matches expected inputs | Prevents edge AI and acceleration drift |
| Governance score trends | Whether overall interoperability capacity is improving or degrading | Helps prioritize remediation and modernization |
Observability should be designed as part of the system, not added after failures. The most important interoperability failures are often not total outages. They are partial mismatches: a unit changes, a field is renamed, a device remains unsupported, an old profile persists, or a gateway transforms data in a way no one documented.
Common Failure Modes
Engineers should design for common interoperability failures explicitly. These failures are predictable because they emerge from heterogeneity, lifecycle change, and unclear ownership.
- Schema drift: devices continue sending telemetry, but field names, units, types, or meanings change.
- Semantic mismatch: two systems use the same label, such as “healthy” or “active,” but assign it different operational meanings.
- Firmware divergence: device behavior differs across firmware versions even though the device class appears identical.
- Unsupported edge devices: components remain deployed after vendor support, security updates, or assurance evidence ends.
- Gateway translation errors: gateways normalize data inconsistently or obscure the original source context.
- API deprecation failure: old clients remain dependent on interfaces that are no longer maintained or tested.
- Model-interface mismatch: an edge model expects one feature schema while the device or gateway produces another.
- Overlay compatibility failure: a PYNQ or FPGA overlay no longer matches the expected stream interface or runtime version.
- Policy ambiguity: no one knows who can approve exceptions, retire devices, update profiles, or change schema versions.
- Audit gap: the system behaves correctly for now, but there is no record proving how or why it is configured that way.
A mature edge architecture does not pretend these failures are unusual. It assumes they will happen and gives engineers the records, tests, dashboards, and decision rights needed to detect and correct them.
Trade-Offs in Standardization and Governance
Standards and governance create trade-offs that cannot all be optimized at once. More standardization can improve portability, reduce integration cost, strengthen procurement discipline, and simplify audit evidence. But it may also slow experimentation, restrict local adaptation, or reduce room for differentiated engineering. More local flexibility can improve contextual fit, but it may weaken cross-system consistency. Richer governance can improve control and accountability, but it may also increase process overhead.
The right balance depends on context. Industrial infrastructure, telecom edge, smart buildings, robotics fleets, logistics systems, environmental monitoring networks, medical edge devices, and public-sector deployments each require different balances of openness, conformance, local autonomy, latency tolerance, lifecycle assurance, and cross-vendor accountability.
Good edge architecture is therefore neither anti-standard nor naively standard-centric. It uses standards where they reduce fragility, profiles them where necessary, and governs change so that interoperability remains operational rather than merely aspirational.
The deeper trade-off is between short-term integration speed and long-term institutional memory. Custom integration can move quickly at first, but it often leaves behind tacit knowledge, fragile scripts, undocumented assumptions, and difficult vendor exits. Standards-based governance may feel slower at the beginning, but it creates a stronger foundation for scale, succession, auditability, and adaptation.
Applications in Embedded and Edge Systems
Telecom and MEC environments. ETSI MEC is one of the clearest examples of standards-driven edge architecture because it treats applications, platforms, host-level resources, network relationships, and system-level management as part of a structured multi-access edge environment.
Industrial and smart manufacturing systems. Industrial environments often require interoperability across legacy control systems, newer edge analytics layers, OPC UA information models, machine data, safety constraints, and service-oriented digital infrastructure. Governance over interfaces and lifecycle change is especially important because downtime, safety, and production continuity are directly affected.
IoT and building platforms. Mixed vendor ecosystems depend on common schemas, identity expectations, lifecycle policies, and structured API behavior if device fleets are to remain governable over time. Building systems are especially vulnerable to fragmentation because sensors, access systems, HVAC controls, occupancy systems, and energy-management platforms often come from different procurement cycles.
Environmental monitoring networks. Distributed sensors for air, water, soil, weather, biodiversity, and infrastructure monitoring require shared data models, calibration records, provenance metadata, and lifecycle documentation. Without those records, measurements may be technically collected but scientifically difficult to compare.
Public infrastructure and civic systems. Edge systems used in transportation, utilities, emergency response, public health, and municipal infrastructure require stronger accountability because technical failure can become public harm. Standards and governance help ensure that interoperability is not dependent on informal vendor knowledge or undocumented local practice.
AI-enabled edge systems. Edge AI adds another layer of governance. Devices may need to track model versions, input schemas, inference logs, confidence thresholds, fallback behavior, and update policies. Interoperability therefore includes not only hardware and telemetry, but also model lifecycle and evidence infrastructure.
Accelerated edge pipelines. PYNQ, FPGA, and HDL-based components need the same governance discipline as software services. Bitstreams, overlays, stream interfaces, timing assumptions, and fallback paths should be versioned and validated rather than treated as invisible hardware details.
Engineer Checklist
- Define device identities, device classes, firmware versions, and support states in machine-readable form.
- Use versioned telemetry schemas with explicit units, timestamps, quality flags, and semantic definitions.
- Document interface profiles, API versions, error states, and compatibility boundaries.
- Create a compatibility matrix across devices, firmware, gateways, runtime versions, models, and overlays.
- Validate JSON, YAML, SQL, model, and overlay manifests before deployment.
- Track unsupported, limited-support, deprecated, or exception-based components explicitly.
- Monitor schema drift, API errors, gateway transformations, and firmware divergence.
- Require lifecycle records for onboarding, update, rollback, exception approval, and decommissioning.
- Treat TinyML models and PYNQ/HDL accelerators as governed lifecycle components, not invisible implementation details.
- Make governance evidence exportable so audits, migrations, vendor transitions, and incident reviews do not depend on informal memory.
This checklist is intentionally practical. The goal is not to make every edge deployment bureaucratic. It is to prevent the most common failure pattern: systems that technically connect but become impossible to understand, test, replace, or govern as they scale.
GitHub Repository
This article is supported by a companion workflow that models standards, interoperability, governance, lifecycle control, and trust baselines in embedded and edge infrastructure using reproducible code, telemetry schemas, device metadata, notebooks, systems programming examples, configuration manifests, and validation workflows.
Where This Fits in the Series
This article extends the foundation established in Device Lifecycle Management and Over-the-Air Updating, Gateways, Aggregation Layers, and Distributed Edge Infrastructure, Cloud-Edge Coordination and Hybrid Architectures, and Security in Embedded and Edge Systems by focusing on the standards, interface discipline, semantic models, lifecycle controls, validation practices, and governance structures that allow heterogeneous edge environments to remain coherent over time.
It also prepares the ground for articles on edge AI governance, observability, telemetry pipelines, device lifecycle evidence, intelligent infrastructure, privacy-preserving local processing, TinyML deployment, hardware acceleration, and the broader question of how distributed technical systems remain accountable when decision-making moves closer to the physical world.
Related articles
- Embedded and Edge Systems: Real-Time Computing in Devices, Sensors, and Infrastructure
- Device Lifecycle Management and Over-the-Air Updating
- Gateways, Aggregation Layers, and Distributed Edge Infrastructure
- Cloud-Edge Coordination and Hybrid Architectures
- Security in Embedded and Edge Systems
- Privacy and Local Data Processing at the Edge
Further reading
- ETSI (n.d.) Multi-access Edge Computing. Available at: https://www.etsi.org/technical-groups/mec/
- ETSI (2024) ETSI GS MEC 003 V3.2.1: Multi-access Edge Computing (MEC); Framework and Reference Architecture. Available at: https://www.etsi.org/deliver/etsi_gs/MEC/001_099/003/03.02.01_60/gs_mec003v030201p.pdf
- IETF Datatracker (2024) RFC 9556: Internet of Things (IoT) Edge Challenges and Functions. Available at: https://datatracker.ietf.org/doc/rfc9556/
- W3C (2023) Web of Things (WoT) Architecture 1.1. Available at: https://www.w3.org/TR/wot-architecture11/
- W3C (2023) Web of Things (WoT) Thing Description 1.1. Available at: https://www.w3.org/TR/wot-thing-description11/
- oneM2M (n.d.) The Global Community That Develops Standards for IoT. Available at: https://www.onem2m.org/
- OPC Foundation (n.d.) OPC Unified Architecture. Available at: https://opcfoundation.org/about/opc-technologies/opc-ua/
- NIST (2024) IoT Assignment Completed! Report on Barriers to U.S. IoT Adoption. Available at: https://www.nist.gov/blogs/cybersecurity-insights/iot-assignment-completed-report-barriers-us-iot-adoption
References
- CISA (2026) BOD 26-02: Mitigating Risk From End-of-Support Edge Devices. Available at: https://www.cisa.gov/news-events/directives/bod-26-02-mitigating-risk-end-support-edge-devices
- CISA (2026) Reducing the Attack Surface for End-of-Support Edge Devices. Available at: https://www.cisa.gov/resources-tools/resources/reducing-attack-surface-end-support-edge-devices
- ETSI (n.d.) Multi-access Edge Computing. Available at: https://www.etsi.org/technical-groups/mec/
- ETSI (2024) ETSI GS MEC 003 V3.2.1: Multi-access Edge Computing (MEC); Framework and Reference Architecture. Available at: https://www.etsi.org/deliver/etsi_gs/MEC/001_099/003/03.02.01_60/gs_mec003v030201p.pdf
- IETF Datatracker (2024) RFC 9556: Internet of Things (IoT) Edge Challenges and Functions. Available at: https://datatracker.ietf.org/doc/rfc9556/
- NIST IoT Advisory Board (2024) The IoT of Things. Available at: https://www.nist.gov/system/files/documents/2024/10/21/The%20IoT%20of%20Things%20Oct%202024%20508%20FINAL_1.pdf
- NIST NCCoE (2024) Trusted IoT Device Network-Layer Onboarding and Lifecycle Management. Available at: https://www.nccoe.nist.gov/sites/default/files/2024-05/nist-sp-1800-36-draft.pdf
- oneM2M (n.d.) The Global Community That Develops Standards for IoT. Available at: https://www.onem2m.org/
- OPC Foundation (n.d.) OPC Unified Architecture. Available at: https://opcfoundation.org/about/opc-technologies/opc-ua/
- W3C (2023) Web of Things (WoT) Architecture 1.1. Available at: https://www.w3.org/TR/wot-architecture11/
- W3C (2023) Web of Things (WoT) Thing Description 1.1. Available at: https://www.w3.org/TR/wot-thing-description11/