
Last Updated May 11, 2026
Autonomous systems and edge intelligence examine how embedded and edge platforms perceive, estimate, decide, plan, control, and act with bounded local authority in physical environments. At a technical level, autonomy is not simply automation with more software, nor is edge intelligence merely AI deployed outside the cloud. It is the engineering of local agency under uncertainty, where sensing, state estimation, belief updates, decision policies, runtime assurance, safety filters, compute constraints, monitoring, and failure containment determine whether a system can act responsibly without continuous remote supervision.
Autonomy has become important because many embedded systems now operate in environments where waiting for centralized computation is too slow, too brittle, too bandwidth-intensive, or too disconnected from physical timing. A mobile robot avoiding an obstacle, an industrial system adapting to a process change, an uncrewed platform maintaining mission continuity, or an intelligent edge node responding to local hazards cannot always rely on cloud round trips. Local intelligence becomes part of the system’s operational survivability.
The deeper architectural question is therefore not whether a system can make decisions locally, but what level of decision authority should be delegated, how uncertainty is represented, how local action is bounded, how unsafe actions are filtered at runtime, how decisions remain observable after deployment, and how autonomy narrows or yields when sensing, timing, confidence, security, or safety assumptions degrade.
Main Library
Publications
Article Map
Embedded & Edge Systems
Related Topic
Artificial Intelligence Systems
Related Topic
Intelligent Infrastructure Systems
Related Topic
Data Systems & Analytics
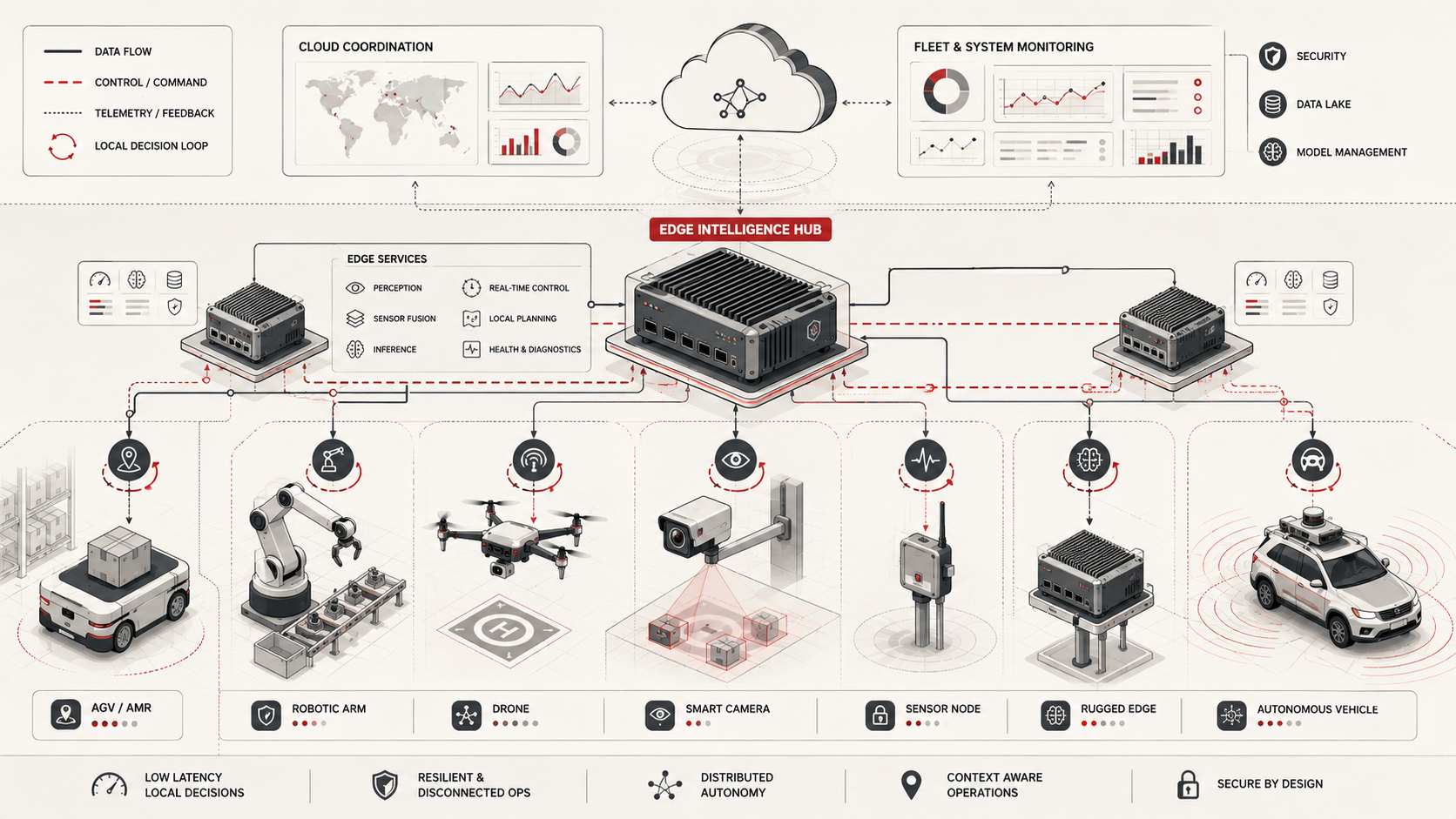
For engineers, autonomous edge systems should be understood as cyber-physical decision systems. They combine local perception, state estimation, decision policies, planning, control, safety constraints, compute scheduling, communications, and post-deployment monitoring. A system becomes trustworthy not because it contains AI, but because its local decisions remain bounded, safety-filtered, explainable enough for operations, observable after deployment, and aligned with the physical consequences it is allowed to create.
Engineering Problem
The engineering problem is how to give a physical system enough local intelligence to act under changing conditions without giving it unbounded authority. An autonomous edge platform must sense its environment, estimate relevant state, maintain a local world model, choose actions, execute control, monitor outcomes, and remain inside safety and mission constraints even when connectivity, sensor quality, timing, compute availability, or model confidence degrade.
In simple automation, engineers can often specify the sequence of actions in advance. In autonomy, the system must interpret context and select among possible actions under uncertainty. That changes the architecture. The design must define what the system may decide, what it may never decide, what requires human or supervisory approval, what happens when confidence is low, and what evidence is logged so behavior can be reviewed after deployment.
Autonomous edge systems are especially challenging because decision-making is tied to local physical conditions. A perception error can become a motion error. A stale state estimate can become a bad plan. A delayed inference can be equivalent to no inference at all. A model that performs well in the lab can drift in the field. A compromised update channel can alter local policy. A local planner can produce actions that are logically coherent but physically unsafe.
For engineers, autonomy should therefore be treated as a bounded decision architecture. It needs explicit state representations, decision policies, safety envelopes, runtime assurance monitors, timing budgets, compute budgets, fallback modes, and authority boundaries.
Reference Architecture
A practical autonomous edge architecture can be understood as a layered decision-control loop. The system observes the world, estimates state, updates a local world model, selects a candidate action, filters that action through safety and authority checks, realizes the action through control, monitors the outcome, and coordinates selectively with edge, fleet, cloud, or human supervisory systems.
| Layer | Engineering Role | Autonomy Concern | Evidence Artifact |
|---|---|---|---|
| Sensor layer | Captures visual, inertial, acoustic, thermal, proximity, force, telemetry, or environmental signals | Noise, calibration, sensor delay, missing observations, adversarial input, sampling rate | Sensor profile, calibration record, sampling policy, telemetry schema |
| Perception layer | Transforms raw input into detected objects, events, features, hazards, or classifications | Model accuracy, confidence, drift, uncertainty, edge inference latency | Model manifest, input schema, confidence log, inference record |
| State-estimation layer | Fuses observations into a local estimate of the system and environment | Belief state, pose, velocity, obstacle state, uncertainty, freshness, observability | Estimator configuration, residual log, state-vector schema |
| World-model layer | Maintains local situational representation for decision-making | Map validity, environmental change, semantic uncertainty, state staleness | World-model manifest, map version, freshness record |
| Decision-policy layer | Selects candidate actions or modes from estimated state, objectives, and constraints | Policy validity, uncertainty handling, action selection, goal alignment | Policy manifest, autonomy-level config, decision log |
| Runtime assurance layer | Checks candidate actions before execution | Safety filtering, authority boundaries, confidence thresholds, fallback action | Safety-filter log, assurance decision, fallback record |
| Planning and control layer | Converts approved decisions into trajectories, setpoints, schedules, or control commands | Feasibility, timing, physical constraints, control stability, safe fallback | Trajectory manifest, controller config, safety-envelope validation |
| Actuation or execution layer | Realizes autonomous decisions through motion, switching, routing, sampling, or process action | Saturation, actuator limits, energy limits, failure containment, safe states | Actuator profile, command log, execution event record |
| Monitoring and governance layer | Records behavior, drift, exceptions, model version, safety events, and authority changes | Post-deployment monitoring, accountability, incident reconstruction, compliance | Autonomy event log, drift report, exception register, review record |
| Coordination layer | Connects autonomous edge nodes to fleets, gateways, cloud services, and human supervisors | Shared state, communication loss, clock drift, coordination delay, handoff rules | Coordination manifest, fleet state record, human-override log |
This architecture makes autonomy inspectable. It separates sensing from perception, perception from state estimation, state estimation from decision policy, candidate action from safety-filtered action, and filtered action from physical execution. That separation matters because failures often occur when those layers are collapsed into one opaque “AI decision.”
Implementation Pattern
A rigorous autonomous edge implementation begins by defining the decision boundary. Engineers should specify what the system may decide locally, what requires coordination, what requires human approval, and what is prohibited. Only after the decision boundary is clear should the team choose models, sensors, compute hardware, or orchestration patterns.
A strong implementation should include:
| Artifact | Purpose | Typical Format |
|---|---|---|
| Autonomy profile | Defines autonomy level, local decision authority, allowed actions, prohibited actions, fallback modes | YAML or JSON |
| Sensor and perception manifest | Defines sensor inputs, model versions, input schemas, confidence thresholds, and inference latency budgets | JSON, YAML, model card, edge AI manifest |
| Belief-state schema | Defines estimated state, uncertainty fields, freshness, confidence, and decision-ready variables | JSON Schema, SQL DDL, Protobuf, Avro |
| Decision-policy manifest | Defines policy version, action space, objective, constraints, authority boundaries, and review status | YAML, JSON, policy-as-code |
| Runtime assurance policy | Defines safety filter, fallback controller, confidence thresholds, and action rejection rules | YAML, JSON, runtime policy |
| Safety envelope | Defines safe state constraints, stop conditions, degraded modes, confidence thresholds, intervention rules | YAML, safety case, runtime policy |
| Compute budget | Defines latency, memory, energy, accelerator, temperature, and scheduling assumptions | YAML, profiling report, runtime manifest |
| Autonomy event log | Records observations, belief state, selected action, filtered action, confidence, authority level, and safety state | SQL, CSV, JSONL, event stream |
| Monitoring and drift report | Tracks confidence drift, input distribution shift, intervention rate, latency violations, safety events, and mission outcomes | Python/R output, dashboard, notebook, governance report |
The implementation goal is to make local decision-making testable. A system should not merely “use AI at the edge.” Engineers should be able to answer: what state did the system believe it was in, what candidate action did it choose, whether that action passed the safety filter, what fallback was available, what authority level applied, and what evidence was retained for review?
The Autonomy Stack: From Observation to Monitored Action
A teachable autonomy stack separates the stages that are often compressed into a single “AI decision.” This separation is useful for engineering, testing, monitoring, and governance.
| Stage | Question Answered | Failure Risk | Engineering Control |
|---|---|---|---|
| Observation | What did the system sense? | Noisy, delayed, missing, or adversarial input | Calibration, sampling policy, sensor freshness, input validation |
| Perception | What did the model detect or classify? | Overconfident or drifted inference | Model manifest, confidence threshold, input drift monitoring |
| Belief state | What does the system believe is true? | Stale or unobservable state | Estimator configuration, uncertainty tracking, residual monitoring |
| Policy | What action would the system prefer? | Policy chooses unsafe or unauthorized action | Decision-policy manifest, action-space limits, validation |
| Safety filter | Is the preferred action allowed now? | Unsafe candidate action reaches execution | Runtime assurance, safety envelope, authority filter |
| Control | Can the approved action be physically realized? | Actuator saturation, timing failure, infeasible trajectory | Controller config, feasibility checks, command bounds |
| Execution | What did the system actually do? | Mismatch between command and physical response | Execution logs, telemetry, actuator monitoring |
| Monitoring | Did deployed autonomy remain trustworthy? | Drift, repeated fallback, safety-event clustering | Drift reports, incident review, rollback, governance loop |
This stack helps prevent a common autonomy failure: treating model output as if it were already a safe, authorized, executable action. In mature autonomous edge systems, candidate actions must pass through safety, authority, timing, and physical feasibility checks before execution.
Formal Model: State, Observation, Belief, Policy, and Action
Autonomous edge systems often operate under partial observability. The system does not know the true state of the world directly. It receives observations, updates an estimate or belief about the state, and selects actions under uncertainty. A useful formal abstraction is the partially observable decision process.
x_{k+1} = f(x_k, u_k, w_k)
\]
Interpretation: \(x_k\) is the true system and environment state, \(u_k\) is the action or control input, and \(w_k\) represents process disturbance. The function \(f\) describes how the world changes after the autonomous system acts.
z_k = h(x_k, v_k)
\]
Interpretation: \(z_k\) is the observation available to the autonomous system, and \(v_k\) represents measurement noise. The system usually acts on observations and estimates, not on perfect state knowledge.
b_k = P(x_k \mid z_{1:k}, u_{1:k-1})
\]
Interpretation: \(b_k\) is the belief state: the system’s probabilistic estimate of the current state given past observations and actions. In autonomous edge systems, the belief state is often the actual basis for decision-making.
Autonomy begins when the system maps this belief state into an action under objectives and constraints.
u_k^\star = \pi(b_k, g_k, c_k)
\]
Interpretation: The decision policy \(\pi\) proposes a candidate action \(u_k^\star\) from belief state \(b_k\), goal \(g_k\), and constraints \(c_k\). This candidate action is not necessarily the action that should be executed.
This distinction between candidate action and executed action is essential. A high-performance autonomy policy may propose useful actions, but a runtime assurance layer should still check safety, authority, timing, confidence, and feasibility before the command reaches the physical system.
Autonomy Levels and Decision Authority
Autonomy is not binary. It is a structured delegation of decision authority. A system can be highly automated but minimally autonomous, or it can be locally autonomous only within a narrow envelope. Engineering clarity improves when autonomy levels are described in relation to what the system may decide.
| Level | Description | Decision Authority | Engineering Requirement |
|---|---|---|---|
| Reactive automation | Executes fixed responses to known conditions | Predefined local response only | Reliable sensing, deterministic logic, bounded outputs |
| Bounded local autonomy | Selects among approved actions under local conditions | Limited local choice inside a defined action set | Action-space limits, safety filter, event logging |
| Supervised autonomy | Acts locally but escalates uncertain or consequential decisions | Local authority with escalation rules | Confidence thresholds, handoff, human-override testing |
| Collaborative or fleet autonomy | Coordinates decisions among multiple agents or infrastructure nodes | Shared local and distributed decision authority | Message freshness, conflict resolution, coordination safety |
| Adaptive autonomy | Changes behavior or authority level based on context, confidence, or mission state | Variable authority under runtime policy | Authority-state machine, drift monitoring, fallback rules |
| Mission-level autonomy | Plans and executes broader mission objectives under bounded supervision | High local authority within a mission envelope | Runtime assurance, governance evidence, robust failure containment |
The higher the autonomy level, the stronger the monitoring and containment requirements become. A low-level threshold system may only need deterministic tests and bounded outputs. A mission-level autonomous system needs state estimation, policy validation, runtime assurance, intervention pathways, post-deployment monitoring, and clear accountability for what the system did in the field.
For engineers, autonomy level should be configurable, versioned, logged, and reducible. A system should be able to step down from mission autonomy to supervised autonomy, bounded local autonomy, degraded mode, safe stop, or human takeover when conditions degrade.
Runtime Assurance and Safety Filtering
Runtime assurance is one of the most important concepts for trustworthy autonomy. The core idea is to separate high-performance decision-making from safety enforcement. A complex planner, learned policy, or edge AI model may propose actions, but a simpler and more verifiable assurance layer checks whether those actions are safe, authorized, timely, and physically feasible before execution.
A practical runtime assurance architecture often looks like this:
| Component | Role | Engineering Question |
|---|---|---|
| Advanced autonomy policy | Proposes high-performance or adaptive actions | What action appears best for the current belief and goal? |
| Safety monitor | Checks constraints, confidence, freshness, and authority | Is this action allowed under current conditions? |
| Fallback policy | Provides conservative behavior when the candidate action fails checks | What safe action should replace or modify the candidate action? |
| Authority manager | Adjusts autonomy level based on state, confidence, mission phase, or operator input | How much local decision authority is permitted now? |
| Assurance log | Records candidate action, filter result, fallback, and reason code | Can engineers reconstruct why an action was allowed or rejected? |
This pattern is powerful because it avoids requiring every autonomy component to be fully interpretable or formally verified. Instead, the system places a more conservative supervisory layer around high-performance autonomy. The advanced policy may be flexible; the safety filter should be simpler, stricter, testable, and easier to audit.
For engineers, runtime assurance should be implemented as an operational control, not only described in architecture diagrams. Candidate actions should have reason codes. Rejected actions should be logged. Fallback actions should be tested. Safety filters should be versioned. Authority boundaries should be machine-readable.
Why Autonomy Pushes Intelligence to the Edge
Autonomy pushes intelligence toward the edge because meaningful local action depends on local interpretation. A robot, uncrewed platform, intelligent camera, industrial node, or autonomous inspection system often cannot wait for centralized inference if hazards, motion constraints, or mission changes unfold quickly.
Bandwidth and privacy matter as well. Raw sensory streams are often too large or too sensitive to transmit continuously upstream. Local edge intelligence allows the system to transform raw input into state estimates, classifications, trajectories, alerts, or bounded actions before only selected information moves outward. That turns the edge into the place where operational meaning is created rather than just where data are produced.
Autonomy also depends on continuity under imperfect connectivity. If a system loses cloud reachability but must continue to navigate, stabilize, inspect, avoid hazards, preserve safety, or maintain task execution, then local intelligence is not optional. It is part of the architecture of survivability.
For engineers, the design principle is not “move everything to the edge.” The principle is to place each function at the level where timing, bandwidth, energy, safety, privacy, and governance requirements can be satisfied. Fast hazard response may need to be local. Fleet-wide learning may be centralized. Mission policy may be supervisory. Runtime execution may be hybrid.
Perception, State Estimation, and Local World Models
Autonomous systems require more than sensing. They require a usable local model of the world. Sensors provide partial, noisy, delayed, and modality-specific observations. The system must fuse, filter, and interpret those observations into a belief or state estimate that can support action.
This means autonomy depends heavily on local world models. A platform may need to estimate position, velocity, obstacles, machine state, terrain conditions, contact state, human proximity, environmental context, or mission-relevant hazards. If that local representation is weak, stale, or poorly calibrated, higher-level autonomy degrades no matter how sophisticated the planning code appears.
Good architecture distinguishes raw measurements, filtered signals, inferred state, belief state, and decision-ready representation. Without that distinction, local intelligence becomes difficult to validate and much harder to trust after deployment.
For engineers, perception and estimation should produce evidence. Confidence scores, residuals, sensor freshness, uncertainty bands, model versions, and input distributions should be logged when they affect autonomous decisions. A system that acts locally but cannot show what it believed locally is difficult to debug, govern, or improve.
Decision Policies, Planning, and Goal-Directed Action
Autonomy becomes operational when local perception leads to goal-directed action. That may involve route selection, obstacle avoidance, task scheduling, inspection prioritization, dynamic replanning, mode switching, local sampling decisions, or control adaptation. The key point is that autonomous behavior is not only prediction. It is the coupling of prediction, decision, and action under constraints.
Decision policies can be rule-based, optimization-based, learned, hybrid, or hierarchical. A small embedded system may use explicit rules and thresholds. A mobile robot may combine local cost maps, planners, and control loops. A more advanced platform may use model predictive control, reinforcement-learning-informed policies, behavior trees, or hybrid supervisory logic.
The engineering requirement is the same across methods: the action space must be bounded, the policy must be versioned, the constraints must be explicit, and the system must know when it is outside the assumptions under which the policy was validated.
For physical systems, planning must remain connected to control and actuation. A local planner that produces elegant trajectories too slowly, or commands that cannot be executed safely, is not practically autonomous. It is algorithmically impressive but physically unreliable.
Control Realization and Physical Feasibility
Autonomous decisions only matter when they can be realized. A selected action must become a trajectory, setpoint, sampling change, route adjustment, actuator command, or operational mode. In embedded and edge systems, this means autonomy must be connected to control, scheduling, energy, communication, and mechanical constraints.
A platform may select a correct high-level action while failing physically because the actuator saturates, the compute task misses its deadline, the battery cannot support the chosen behavior, the local map is stale, or the system enters a region of state space where the policy has not been validated.
Good autonomous architecture therefore uses feasibility checks before execution. The system should ask whether the intended action is allowed, whether it is safe, whether it can be executed within time, whether it exceeds power or thermal constraints, whether the current belief state is reliable enough, and whether human or supervisory approval is required.
For engineers, the decision-action interface should be explicit. It should include command bounds, timing constraints, actuator limits, fallback behavior, logging rules, and authority checks. Autonomy should never be allowed to bypass the physical feasibility layer.
Timing, Reactivity, and Mission-Time Constraints
Autonomous systems are often judged not only by whether they choose the right action, but whether they choose it within the right time horizon. A perception result, route update, obstacle decision, or safety intervention that arrives too late may be equivalent to failure.
This matters because edge intelligence usually sits inside several nested temporal scales at once: fast reactive control, medium-horizon replanning, slower mission logic, and much slower remote synchronization or policy update. A strong autonomous architecture separates these scales clearly rather than allowing all decisions to compete inside one undifferentiated runtime environment.
t_{\mathrm{decision}} = t_{\mathrm{sense}} + t_{\mathrm{infer}} + t_{\mathrm{estimate}} + t_{\mathrm{plan}} + t_{\mathrm{validate}} + t_{\mathrm{act}}
\]
Interpretation: Local decision time includes sensing, inference, estimation, planning, safety validation, and action. Autonomous edge behavior is viable only if this total time remains within the physical and mission-time requirements of the system.
Good design makes explicit which tasks are hard-real-time, which are latency-sensitive but schedulable, which can tolerate asynchronous execution, and which may depend on cloud or supervisory systems. Autonomy without timing discipline quickly becomes brittle.
Compute Platforms, Accelerators, and Energy Budgets
Autonomous edge intelligence is constrained by hardware. Real platforms must allocate CPU, GPU, NPU, DSP, FPGA, memory, storage, sensor I/O, networking, and power across perception, estimation, planning, control, safety checks, telemetry, and monitoring. A model or planner that works on a lab workstation may fail in a fielded system if it exceeds energy limits, thermal limits, memory limits, or real-time scheduling constraints.
This means autonomy is not only an algorithm problem. It is a deployment problem. The compute architecture must match the autonomy architecture. High-rate perception, local inference, sensor fusion, and safety monitoring may need acceleration. Mission planning may tolerate slower execution. Fleet learning may belong upstream. The design must prevent noncritical workloads from starving safety-critical or control-critical processes.
For engineers, compute budgets should be represented explicitly. Latency, memory footprint, energy draw, accelerator availability, thermal behavior, model size, inference rate, and scheduling priority should be part of the autonomy design rather than after-the-fact profiling notes.
Strong edge autonomy treats hardware as part of the trust boundary. If the system cannot guarantee that safety checks and local control remain schedulable under load, then autonomy is not adequately engineered.
Distributed Autonomy and Coordinated Edge Systems
Many autonomous systems are not isolated agents. They operate as coordinated edge systems: fleets of robots, distributed sensors supporting one vehicle, multiple local nodes maintaining situational awareness, or infrastructure platforms that coordinate local autonomy across sites.
Distributed autonomy introduces questions of coordination, shared state, role assignment, clock synchronization, conflict resolution, and fault containment. Communication is therefore part of autonomy rather than a support service. Delayed updates, conflicting local beliefs, inconsistent clocks, or loss of one node can change physical behavior directly.
Good distributed autonomy design limits dependence on perfectly synchronized global knowledge. It defines what each node may decide locally, what must be coordinated, what happens when shared state is stale, and how disagreement is resolved without making the whole system unsafe or unusable.
For engineers, distributed autonomy requires explicit contracts around message freshness, command authority, time synchronization, local fallback, safety precedence, and recovery after partition. A fleet is not simply many autonomous devices. It is a distributed decision system with distributed failure modes.
Monitoring Drift in Autonomous Edge Systems
Autonomy raises the stakes of post-deployment monitoring. A fielded autonomous system should not be judged only by lab accuracy or predeployment validation. The operating environment changes. Input distributions shift. Sensor calibration drifts. Confidence patterns change. Latency changes under thermal or compute load. Human interventions cluster. Fallbacks become more frequent. Safety events appear in locations or task modes that were not represented well during testing.
A strong autonomy monitoring model should track multiple forms of drift:
| Drift Type | What Changes | Why It Matters | Example Signal |
|---|---|---|---|
| Input drift | Sensor inputs differ from validation conditions | Perception models may become less reliable | Feature distribution shift, image brightness shift, new obstacle types |
| Confidence drift | Model confidence changes over time or context | Local decisions may become less certain | Mean confidence, low-confidence rate, entropy trend |
| Latency drift | Inference, planning, or safety validation slows | Correct decisions may arrive too late | Stage latency, missed deadlines, thermal throttling events |
| Fallback drift | Fallback actions become more frequent | Nominal autonomy may no longer fit the field environment | Fallback rate by mission, site, model version, or weather condition |
| Intervention drift | Human supervision or override increases | Autonomy may be less reliable than expected | Manual takeover rate, mission pause rate, operator override log |
| Safety-event drift | Warnings, stops, near-boundary states, or violations cluster | Safety margins may be eroding | Safety-envelope margin, emergency stop events, degraded-mode transitions |
| Mission-outcome drift | Task completion, route quality, sampling success, or inspection quality changes | Autonomy may be technically active but operationally degraded | Completion rate, detour rate, failed inspection rate, energy per mission |
Monitoring should connect field evidence back to lifecycle governance. A drift signal should trigger review, threshold adjustment, policy revision, retraining, rollback, autonomy reduction, hardware inspection, or operational redesign. Otherwise monitoring becomes passive telemetry rather than engineering control.
Failure Containment and Degraded Modes
Autonomous systems should assume that some assumptions will fail. A sensor may drop out. A model may lose confidence. A planner may propose an unsafe action. A network may partition. A compute task may miss a deadline. A local map may become stale. A human supervisor may be unavailable. Failure containment defines how the system narrows behavior when trust weakens.
Containment should be designed as a state machine rather than as an emergency improvisation. Common containment modes include:
| Containment Mode | When It Applies | System Behavior |
|---|---|---|
| Continue nominal autonomy | Confidence, timing, safety, and authority are all valid | Execute safety-filtered local decisions |
| Reduced autonomy | Confidence or environmental fit weakens | Restrict action set and increase conservative margins |
| Degraded mode | Sensing, compute, communication, or model quality is impaired | Use simpler policy, slower motion, narrower workspace, or local-only behavior |
| Safe fallback | Candidate action fails safety filter or timing validation | Execute conservative fallback action |
| Human handoff | Decision exceeds local authority or uncertainty threshold | Request supervision, approval, or teleoperation |
| Mission pause | Mission can safely stop while preserving state | Hold position, stop sampling, wait for recovery or instruction |
| Safe stop | Physical or operational risk becomes unacceptable | Stop actuation or enter predefined safe state |
| Quarantine or isolation | Security, integrity, or severe anomaly concern appears | Disconnect from coordination, restrict communication, preserve evidence |
| Mission abort | Continuing is unsafe, infeasible, or unauthorized | Terminate mission and move to recovery procedure |
Failure containment should be tested. A system that has never exercised degraded mode, human handoff, safe stop, or mission abort may appear autonomous only because it has not yet faced serious field conditions. In strong engineering practice, fallback behavior is not a footnote. It is part of the autonomy design.
Safety, Cybersecurity, and Bounded Behavior
Autonomous systems expand both capability and risk. A compromised or misaligned autonomous system can create physical harm, mission failure, unsafe adaptation, privacy exposure, or operational disruption. Safety and cybersecurity are therefore not separate from autonomy. They are conditions for trustworthy local agency.
Bounded behavior matters because autonomous systems can choose among actions. Good autonomous design does not merely pursue higher performance. It defines operating envelopes, safe fallbacks, degraded modes, intervention boundaries, prohibited actions, and conditions under which autonomy should narrow or yield.
u_k \in \mathcal{U}_{\mathrm{allowed}}(b_k, s_k, a_k)
\]
Interpretation: The executed action \(u_k\) must belong to the allowed action set, which depends on belief state \(b_k\), safety state \(s_k\), and autonomy authority level \(a_k\). As uncertainty rises or safety confidence falls, the allowed action set should shrink.
Cybersecurity is central because autonomy depends on trusted sensing, trusted compute, trusted models, trusted updates, and trusted communication. If any of those layers are compromised, autonomous behavior may remain internally coherent while becoming externally unsafe.
For engineers, safety and security should be represented in runtime policy. The system should not only know how to act, but when not to act, when to degrade, when to stop, when to request help, and when to reject local decision authority altogether.
Human Oversight and Adjustable Autonomy
Most practical autonomous systems do not eliminate human oversight. They redistribute it. Humans may set goals, supervise missions, intervene during exception conditions, approve changes in authority, define operating envelopes, review incidents, and update policies. Autonomy should often be adjustable rather than absolute.
Architecturally, adjustable autonomy means the system should make clear what a human can see, what a human can override, how authority transitions occur, and what information is available when intervention is needed. A system that claims autonomy but cannot explain its state or support meaningful intervention is often less deployable than a more modest system with better oversight structure.
Good design treats human oversight as part of the autonomy architecture, not as a fallback appended after the fact. The strongest systems are not those that remove people from the loop in every circumstance, but those that place people, policy, and local intelligence into a coherent structure of bounded authority.
For engineers, human override should be tested. Authority handoff, command rejection, degraded mode, emergency stop, mission pause, and audit reconstruction should be validated like other autonomy behaviors.
Worked Example: Autonomous Mobile Robot Obstacle Response
Consider an autonomous mobile robot operating inside a warehouse aisle. Its mission is to move a payload from one station to another. During the route, a temporary obstacle appears in the aisle. A weak architecture might treat this as a single perception-to-action event: the robot detects an obstacle and reroutes. A stronger autonomy architecture makes each step explicit.
| Step | System Action | Engineering Evidence |
|---|---|---|
| Observation | Depth camera and proximity sensors detect an object in the planned path | Sensor timestamp, sensor freshness, obstacle measurement, input quality |
| Perception | Local model classifies the obstacle as static and confidence is 0.82 | Model version, confidence score, input schema, inference latency |
| Belief update | Robot updates local map and estimates obstacle position with uncertainty | Belief-state record, map version, uncertainty radius, freshness |
| Candidate policy action | Planner proposes a reroute around the obstacle | Candidate action, objective score, predicted route cost |
| Safety filter | Runtime assurance checks speed, proximity, aisle clearance, and authority level | Safety-filter pass/fail, authority level, constraint margins |
| Execution | Controller reduces speed and follows approved local detour | Command log, trajectory manifest, tracking error, actuator state |
| Fallback condition | If confidence drops below threshold, robot pauses and requests supervision | Fallback reason, human-handoff request, mission-pause record |
| Monitoring | Autonomy log records confidence, latency, reroute, safety margin, and mission impact | Autonomy event log, latency by stage, mission outcome, drift signal |
This example shows why autonomy should not be reduced to local inference. The model classification is only one part of the decision chain. The robot must update belief, select a candidate action, pass the action through safety and authority filters, execute physically feasible control, and retain evidence for later review.
If the obstacle is misclassified, if confidence is low, if the route is too narrow, if the robot is carrying a fragile payload, if latency exceeds the decision budget, or if the robot is outside the autonomy authority granted for that aisle, then the correct behavior may not be rerouting. It may be slowing down, pausing, requesting supervision, or entering a safe fallback state.
This is the practical meaning of bounded autonomy: local intelligence is useful only when local decision authority is matched by runtime assurance, physical feasibility, monitoring, and failure containment.
Data and Configuration Artifacts
Autonomous edge systems become easier to test, govern, and improve when autonomy assumptions are represented as data and configuration artifacts. Engineers should be able to inspect local decision authority, sensor assumptions, model versions, state schemas, compute budgets, safety envelopes, assurance policies, and monitoring policies without relying on undocumented code or operator memory.
| Artifact | What It Captures | Engineering Purpose |
|---|---|---|
autonomy_profile.yml |
Autonomy level, allowed decisions, prohibited actions, escalation rules, fallback modes | Defines local decision authority explicitly |
sensor_manifest.json |
Sensor types, sampling rates, calibration, latency, uncertainty, failure behavior | Clarifies what the system can observe |
model_manifest.json |
Perception model, input schema, output labels, confidence thresholds, drift checks | Tracks edge AI components as governed lifecycle artifacts |
belief_state_schema.json |
Estimated state variables, uncertainty, freshness, confidence, provenance | Separates observations from decision-ready state |
decision_policy.yml |
Policy version, objective, action space, constraints, authority boundaries | Makes local decision-making inspectable |
runtime_assurance.yml |
Safety-filter rules, fallback actions, authority checks, confidence thresholds | Prevents candidate actions from bypassing safety review |
safety_envelope.yml |
Safe sets, stop conditions, confidence thresholds, degraded modes, intervention rules | Constrains autonomous behavior under uncertainty |
compute_budget.yml |
Latency, memory, energy, accelerator, scheduling, and thermal assumptions | Connects autonomy to deployable edge hardware |
autonomy_event_log.csv |
Observation, belief state, candidate action, filtered action, confidence, authority level, safety state | Supports monitoring, debugging, and incident reconstruction |
drift_report.csv |
Input distribution shift, confidence shift, intervention rate, safety events, mission outcomes | Supports post-deployment governance and model review |
The goal is not to force one file format. The goal is to make autonomy reviewable. If local decision-making cannot be represented in artifacts, logs, schemas, policies, and tests, it will be difficult to trust after deployment.
Mathematical Lens: Belief-State Decision-Making, Safety Filtering, and Edge Authority
A technically rigorous lens treats autonomous edge systems as decision systems under uncertainty. The system receives observations, updates a belief state, proposes an action, filters that action through safety and authority constraints, and then executes only the approved behavior.
b_k = \eta \, P(z_k \mid x_k) \sum_{x_{k-1}} P(x_k \mid x_{k-1}, u_{k-1}) b_{k-1}
\]
Interpretation: This belief update combines a prior belief \(b_{k-1}\), transition model, action history, and new observation \(z_k\). The normalizing constant \(\eta\) keeps the belief distribution valid. In engineering terms, the system updates what it thinks is true before deciding what to do.
u_k^\star = \arg\min_{u \in \mathcal{U}} J(b_k, u, g_k)
\]
Interpretation: The autonomous system proposes the action \(u_k^\star\) that minimizes a cost or objective \(J\), given belief state \(b_k), allowed action set \(\mathcal{U}\), and goal \(g_k\). In practice, \(J\) may include task success, energy, risk, latency, safety margin, or mission priority.
u_k = F(u_k^\star, b_k, \mathcal{S}, \mathcal{A})
\]
Interpretation: A safety and authority filter \(F\) converts the candidate action \(u_k^\star\) into the action actually allowed for execution. The filter uses belief state \(b_k\), safety constraints \(\mathcal{S}\), and authority constraints \(\mathcal{A}\) to allow, modify, reject, or replace the action with fallback behavior.
h(x_k) \geq 0,\qquad u_k \in \mathcal{U}_{\mathrm{allowed}}(a_k)
\]
Interpretation: The system must remain inside a safe set \(h(x_k) \geq 0\), and its chosen action must be allowed under the current autonomy authority level \(a_k\). This prevents local intelligence from becoming unbounded local power.
The point is not that every embedded system must implement a full POMDP solver. The point is that all autonomous edge systems face the same structure: partial observation, uncertain state, candidate action, safety filtering, local objective, physical consequence, and authority boundary. A rigorous architecture makes those elements explicit.
Python Workflow: Autonomous Edge Decision Simulation with Belief, Latency, and Safety Bounds
The companion Python workflow should model a simplified autonomous edge decision system. It can simulate observations, belief-state updates, candidate action selection, runtime assurance filtering, confidence thresholds, latency budgets, and safety-envelope validation. The goal is not to replace production autonomy stacks, but to make the system’s decision logic inspectable.
# Python Workflow: Autonomous Edge Decision Simulation with Belief, Latency, and Safety Bounds
belief = update_belief(
previous_belief=belief,
observation=observation,
transition_model=transition_model,
observation_model=observation_model,
previous_action=previous_action
)
candidate_action = policy.select_action(
belief=belief,
goal=mission_goal,
allowed_actions=authority.allowed_actions
)
filtered_action = safety_filter.evaluate(
candidate_action=candidate_action,
belief=belief,
safety_envelope=safety_envelope,
authority=authority,
latency_ms=latency_ms
)
if filtered_action.allowed:
action = filtered_action.action
else:
action = fallback_policy.safe_action(belief)
This workflow is useful because it separates belief, policy, safety, timing, and authority. Engineers can test what happens when confidence drops, latency rises, observations become stale, the model drifts, or the selected action violates the current autonomy boundary.
For production systems, the same logic can be connected to real logs from edge AI models, local planners, mission managers, or robotic middleware. Engineers can then analyze whether local decisions were made with valid state, adequate confidence, acceptable latency, and appropriate authority.
R Workflow: Autonomy Monitoring, Drift, and Mission Reliability Reporting
The companion R workflow should focus on reporting. It can summarize confidence drift, input distribution shift, autonomy-level changes, intervention rate, latency violations, safety events, fallback actions, and mission outcomes across devices, sites, tasks, or fleet segments.
# R Workflow: Autonomy Monitoring, Drift, and Mission Reliability Reporting
autonomy_summary <- autonomy_events |>
dplyr::group_by(device_id, mission_type, autonomy_level) |>
dplyr::summarise(
decisions = dplyr::n(),
mean_confidence = mean(decision_confidence, na.rm = TRUE),
fallback_rate = mean(action_type == "fallback", na.rm = TRUE),
intervention_rate = mean(human_intervention_required, na.rm = TRUE),
latency_violation_rate = mean(latency_ms > latency_budget_ms, na.rm = TRUE),
safety_events = sum(safety_state != "normal", na.rm = TRUE),
input_drift_index = mean(input_drift_score, na.rm = TRUE),
confidence_drift_index = mean(confidence_drift_score, na.rm = TRUE),
.groups = "drop"
)This workflow helps engineering and governance teams distinguish nominal autonomy from fielded autonomy. A system may perform well in controlled tests but show rising fallback rates, declining confidence, increasing interventions, latency violations, or safety-state transitions in deployment.
For autonomous edge fleets, reporting matters because risk is uneven. One environment may create most low-confidence decisions. One model version may produce more fallback behavior. One device class may exceed latency budgets under thermal load. R-style reporting turns those patterns into reviewable evidence.
Systems Code: Firmware, Edge AI, MicroPython, TinyML, PYNQ, HDL, Bash, and Configuration
The companion repository should be useful to engineers because autonomous edge intelligence crosses the full embedded and edge stack. It touches sensing, local inference, belief-state updates, decision policy, runtime assurance, safety validation, telemetry, compute profiling, control handoff, hardware acceleration, and post-deployment monitoring.
| Folder | Engineering Role | Autonomy Use |
|---|---|---|
python/ |
Simulation and workflow automation | Belief-state simulation, policy evaluation, runtime assurance, drift scoring, latency analysis |
r/ |
Reporting and descriptive analytics | Autonomy monitoring, drift summaries, intervention rates, mission reliability |
sql/ |
Queryable engineering evidence | Stores observations, beliefs, candidate actions, filtered actions, safety events, interventions |
c/ |
Constrained embedded autonomy logic | Local mode selection, confidence checks, safe fallback, watchdog behavior |
cpp/ |
Edge autonomy middleware | Decision-state machine, behavior tree, command validation, mission mode control |
rust/ |
Safe systems validation | Authority-bound validation, action-set filtering, safety-envelope enforcement |
go/ |
Operational services and fleet utilities | Autonomy event gateway, decision telemetry router, fleet monitoring service |
micropython/ |
Microcontroller prototypes | Local sensor thresholding, simple mode selection, fallback telemetry |
tinyml/ |
Constrained local inference | On-device classification, anomaly detection, confidence-bounded local decisions |
pynq/ |
FPGA-backed edge acceleration | Low-latency preprocessing, sensor-stream filtering, perception acceleration validation |
hdl/ |
Hardware/software co-design | Stream gates, timing monitors, safety signal handling, preprocessing blocks |
bash/ |
Repeatable workflow execution | Runs simulations, validates manifests, generates monitoring outputs |
config/ |
Machine-readable autonomy metadata | Autonomy profiles, decision policies, runtime assurance rules, safety envelopes, compute budgets |
This stack is intentionally cross-layer. Autonomy is not created by one model or one runtime. It emerges from local inference, state representation, decision authority, runtime assurance, control realization, safety validation, compute scheduling, monitoring, and lifecycle governance.
Testing and Validation
Autonomous edge systems should be validated as decision systems under uncertainty, not merely as model deployments. Engineers should test perception, belief-state quality, policy behavior, safety filtering, action bounds, latency, compute load, fallback behavior, human override, and monitoring evidence.
A practical validation suite should answer these questions:
- Does the system distinguish raw observations, perception outputs, belief state, decision-ready state, candidate action, filtered action, and executed command?
- Are confidence thresholds enforced before consequential local decisions?
- Does the runtime assurance layer reject actions outside safety or authority boundaries?
- Does the selected action satisfy safety-envelope constraints?
- Does local inference meet latency, memory, energy, and thermal budgets?
- Does the system degrade or request supervision when state confidence is low?
- Can the system continue safely under partial connectivity loss?
- Are model versions, policy versions, assurance versions, and autonomy levels logged with each decision?
- Can human override, emergency stop, mission pause, autonomy reduction, and authority handoff be tested?
- Does the monitoring system detect input drift, confidence drift, fallback-rate changes, intervention increases, or safety-event clustering?
- Are TinyML models, PYNQ overlays, and HDL preprocessing blocks versioned and validated?
Testing should include negative cases. Engineers should deliberately test stale observations, low confidence, sensor dropout, adversarial inputs, delayed inference, excessive compute load, model drift, communication loss, unsafe candidate actions, failed safety filters, fallback failure, and authority-bound violations. Autonomy fails most dangerously when the system continues acting confidently after its assumptions have become invalid.
Operational Signals and Autonomy Observability
Autonomy observability is the ability to reconstruct and monitor local decision-making after deployment. It should not be limited to whether the device is online. An autonomous edge system can be online while operating with low confidence, stale observations, excessive latency, frequent fallback behavior, or unsafe autonomy authority.
| Signal | What It Reveals | Why Engineers Need It |
|---|---|---|
| Decision confidence | How strongly the system trusted its local perception or policy output | Detects uncertainty and degraded decision quality |
| Belief-state freshness | How current the estimated state was when the decision occurred | Prevents action based on stale local world models |
| Candidate action | What the autonomy policy wanted to do | Separates policy behavior from safety-filtered behavior |
| Safety-filter result | Whether candidate action was allowed, modified, rejected, or replaced | Supports runtime assurance review |
| Latency by stage | Sensing, inference, estimation, planning, validation, and execution time | Identifies missed mission-time constraints |
| Autonomy level | How much decision authority the system had at the time | Supports authority review and incident reconstruction |
| Fallback rate | How often the system used safe fallback instead of nominal autonomy | Reveals uncertainty, poor policy fit, or environmental mismatch |
| Human intervention rate | How often oversight was required | Shows whether autonomy is reliable under field conditions |
| Safety-envelope margin | Distance from unsafe state or prohibited action boundary | Supports proactive safety review |
| Model, policy, and assurance version | Which deployed components produced and filtered the decision | Supports lifecycle governance and rollback analysis |
| Input distribution shift | Whether field inputs differ from validation conditions | Supports drift monitoring and retraining review |
| Mission outcome | Whether local decisions achieved the intended operational objective | Connects autonomy behavior to real performance |
Engineers should design these signals before deployment. If a system cannot reconstruct what it observed, believed, proposed, filtered, executed, and monitored, then autonomy becomes difficult to debug and harder to govern.
Common Failure Modes
Autonomous edge systems fail in predictable ways because they combine uncertain perception, local decision-making, physical action, distributed coordination, and changing field conditions. Engineers should design the architecture, tests, and observability around these failure modes from the beginning.
- Stale belief state: the system acts on a local world model that no longer matches the environment.
- Overconfident perception: the system treats uncertain or shifted model outputs as reliable.
- Authority creep: local autonomy expands beyond the decisions it was validated to make.
- Safety-filter bypass: candidate actions reach execution without runtime assurance checks.
- Unsafe candidate action: a policy selects an action that violates safety, mission, or physical constraints.
- Timing violation: inference, planning, or validation takes too long for the physical situation.
- Compute contention: noncritical workloads interfere with safety-critical inference or control tasks.
- Fallback failure: degraded mode is unavailable, untested, or unsafe under the actual field condition.
- Monitoring gap: decisions are made locally without enough evidence for review or incident reconstruction.
- Coordination mismatch: distributed nodes act on inconsistent shared state or stale fleet information.
- Model drift: field inputs gradually move away from validation data, reducing decision quality.
- Security compromise: model, sensor, update, or communications trust is weakened, corrupting autonomous behavior.
- Human override failure: authority handoff is unclear, delayed, invisible, or unsupported during exception conditions.
A mature autonomy architecture does not assume these failures can be eliminated. It makes them detectable, bounded, testable, and recoverable.
Trade-Offs in Autonomous Edge Design
Autonomous edge systems are shaped by trade-offs that cannot all be optimized at once. More local intelligence improves reactivity and continuity but increases compute, energy, thermal, monitoring, and validation burden. More central oversight improves fleet visibility but may weaken local responsiveness. Richer models can improve perception or planning but may break real-time budgets or make behavior harder to explain. Stronger safety bounds may reduce performance flexibility but improve trustworthiness.
The right design depends on purpose. Smart manufacturing robots, autonomous mobile robots, uncrewed systems, intelligent cameras, remote monitoring platforms, and infrastructure systems each require different balances of local decision authority, communication dependence, energy budget, safety assurance, and governance.
Good autonomy architecture is therefore proportional. It grants only the autonomy that can be supported responsibly by sensing, compute, control, monitoring, runtime assurance, safety, cybersecurity, and oversight structures.
Engineers should document these trade-offs explicitly. If the system relies on cloud coordination, it needs local fallback. If it relies on local models, it needs drift monitoring. If it increases local action authority, it needs stronger safety validation. If it operates under power constraints, it needs compute budgets tied to mission priorities.
Applications in Embedded and Edge Systems
Smart manufacturing and agile robotics. Manufacturing systems increasingly require local perception, rapid retasking, bounded autonomy, runtime assurance, and safe coordination between robots, machines, and workers.
Autonomous mobile robots. Mobile robots depend on local perception, localization, planning, obstacle handling, and mission-time decisions because navigation cannot be outsourced entirely to the cloud.
Uncrewed and mission-oriented systems. Drones, inspection platforms, and other uncrewed systems require local autonomy for continuity under uncertainty, communications limits, environmental change, and mission constraints.
Intelligent industrial and infrastructure platforms. Edge-intelligent systems in factories, utilities, transportation systems, water systems, and remote infrastructure increasingly combine local sensing, anomaly detection, bounded action, and selective uplink.
Environmental and field monitoring systems. Autonomous edge nodes may adjust sampling, detect anomalies, manage energy, and prioritize uplink based on local environmental conditions.
Edge AI safety and governance systems. Local models increasingly support perception, classification, anomaly detection, and decision support. These systems require model versioning, drift monitoring, confidence thresholds, runtime assurance, and authority boundaries.
The unifying pattern is not one device type. It is the challenge of making local intelligence useful without making local action unbounded, invisible, or unsafe.
Engineer Checklist
- Define the autonomy profile: allowed decisions, prohibited actions, fallback modes, escalation rules, and authority levels.
- Separate raw observations, perception outputs, belief state, decision-ready state, candidate action, filtered action, and executed command.
- Document model versions, input schemas, confidence thresholds, inference latency, and drift-monitoring requirements.
- Define belief-state freshness, uncertainty, and confidence requirements before consequential actions.
- Validate local policies against safety envelopes, mission constraints, and authority boundaries.
- Implement runtime assurance so candidate actions can be allowed, modified, rejected, or replaced by fallback behavior.
- Set timing budgets for sensing, inference, estimation, planning, validation, and execution.
- Track compute budgets: CPU, GPU, NPU, FPGA, memory, energy, thermal headroom, and scheduling priority.
- Design safe fallback for low confidence, stale state, communication loss, sensor failure, compute overload, policy uncertainty, and safety-filter rejection.
- Version TinyML models, PYNQ overlays, HDL preprocessing blocks, decision policies, safety envelopes, runtime assurance rules, and autonomy profiles.
- Log enough evidence to reconstruct what the system observed, believed, proposed, filtered, executed, and monitored.
- Monitor input drift, confidence drift, latency drift, fallback rate, intervention rate, mission outcomes, and safety-event clustering after deployment.
- Test human override, autonomy handoff, emergency stop, mission pause, authority reduction, and degraded-mode transitions under realistic conditions.
This checklist is intentionally practical. Autonomous edge systems become trustworthy when engineers can explain what the system observed, what it believed, what authority it had, what action it proposed, whether the action passed runtime assurance, what physical or operational consequence followed, and how the system behaved when its assumptions weakened.
GitHub Repository
This article is supported by a companion workflow that models autonomous systems and edge intelligence using belief-state simulation, decision-policy validation, runtime assurance, safety filtering, edge AI metadata, latency budgets, safety envelopes, autonomy event logs, drift monitoring, systems-language examples, and hardware/software co-design scaffolds.
Where This Fits in the Series
This article extends the foundation established in Cyber-Physical Systems and Hardware Integration, Embedded Control Systems, Edge AI and On-Device Machine Learning, Robotics, Actuation, and Physical Feedback Loops, and Cloud-Edge Coordination and Hybrid Architectures by focusing on how local perception, decision-making, runtime assurance, and bounded action become operational autonomy at the edge.
It also prepares the ground for deeper work on autonomous robotics, edge AI governance, distributed autonomy, fleet monitoring, cyber-physical safety, runtime assurance, human oversight, intelligent infrastructure, and the monitoring of deployed AI systems in physically situated environments.
Related articles
- Embedded and Edge Systems: Real-Time Computing in Devices, Sensors, and Infrastructure
- Cyber-Physical Systems and Hardware Integration
- Embedded Control Systems
- Edge AI and On-Device Machine Learning
- Robotics, Actuation, and Physical Feedback Loops
- Cloud-Edge Coordination and Hybrid Architectures
- Gateways, Aggregation Layers, and Distributed Edge Infrastructure
Further reading
- Åström, K.J. and Murray, R.M. (2021) Feedback Systems: An Introduction for Scientists and Engineers. Available at: https://fbsbook.org/
- Lee, E.A. and Seshia, S.A. (n.d.) Introduction to Embedded Systems: A Cyber-Physical Systems Approach. Available at: https://ptolemy.berkeley.edu/books/leeseshia/download.html
- Lynch, K.M. and Park, F.C. (2017) Modern Robotics: Mechanics, Planning, and Control. Available at: https://modernrobotics.northwestern.edu/
- NIST (2026) Challenges to the Monitoring of Deployed AI Systems. Available at: https://nvlpubs.nist.gov/nistpubs/ai/NIST.AI.800-4.pdf
- NIST (2024) Autonomous Cybersecurity and AI Risk Management for Uncrewed Systems: Challenges and Opportunities. Available at: https://www.nist.gov/document/autonomous-cybersecurity-and-ai-risk-management-uncrewed-systems-challenges-and
- IETF (2024) RFC 9556: Internet of Things (IoT) Edge Challenges and Functions. Available at: https://datatracker.ietf.org/doc/html/rfc9556
- Intel (n.d.) Edge Insights for Autonomous Mobile Robots. Available at: https://www.intel.com/content/www/us/en/developer/topic-technology/edge-5g/edge-solutions/autonomous-mobile-robots.html
References
- Arm (n.d.) Compute Platforms for Autonomous Machines. Available at: https://www.arm.com/products/autonomous-machines
- Åström, K.J. and Murray, R.M. (2021) Feedback Systems: An Introduction for Scientists and Engineers. Available at: https://fbsbook.org/
- Chen, J. et al. (2022) ‘From unmanned systems to autonomous intelligent systems’, Journal of Bionic Engineering. Available at: https://www.sciencedirect.com/science/article/pii/S2095809921004343
- IETF (2024) RFC 9556: Internet of Things (IoT) Edge Challenges and Functions. Available at: https://datatracker.ietf.org/doc/html/rfc9556
- Intel (n.d.) Edge Insights for Autonomous Mobile Robots. Available at: https://www.intel.com/content/www/us/en/developer/topic-technology/edge-5g/edge-solutions/autonomous-mobile-robots.html
- Lee, E.A. and Seshia, S.A. (n.d.) Introduction to Embedded Systems: A Cyber-Physical Systems Approach. Available at: https://ptolemy.berkeley.edu/books/leeseshia/download.html
- Lynch, K.M. and Park, F.C. (2017) Modern Robotics: Mechanics, Planning, and Control. Available at: https://modernrobotics.northwestern.edu/
- NIST (n.d.) Intelligent Systems Division. Available at: https://www.nist.gov/el/intelligent-systems-division-73500
- NIST (2011) Advanced Manufacturing, Automation, and Autonomous Systems. Available at: https://www.nist.gov/el/goals-programs/advanced-manufacturing-automation-and-autonomous-systems
- NIST (2024) Autonomous Cybersecurity and AI Risk Management for Uncrewed Systems: Challenges and Opportunities. Available at: https://www.nist.gov/document/autonomous-cybersecurity-and-ai-risk-management-uncrewed-systems-challenges-and
- NIST (2026) Challenges to the Monitoring of Deployed AI Systems. Available at: https://nvlpubs.nist.gov/nistpubs/ai/NIST.AI.800-4.pdf