
Last Updated May 11, 2026
Time series analysis and forecasting are the disciplines through which analysts study data that unfolds through time and make disciplined judgments about how it may evolve. Unlike cross-sectional analysis, where observations are often treated as exchangeable units, time series analysis must confront temporal dependence directly. Observations collected in sequence may exhibit trend, seasonality, autocorrelation, delayed response, volatility shifts, structural breaks, regime change, or changing uncertainty across horizons. A time series is therefore not simply a dataset with a date column. It is an ordered record of a process whose past may contain information about its future.
Forecasting matters because institutions often have to act before the future is observed. Inventory systems, electricity demand planning, staffing models, maintenance schedules, revenue expectations, climate monitoring, public budgets, operational risk systems, and policy preparation all depend on judgments about what is likely to happen next. But forecasting is not prophecy, and it is not merely extrapolation with a smoother line. It depends on how the past is represented, whether temporal structure is stable enough to support projection, how uncertainty grows with horizon, and whether forecasts are evaluated against unseen future periods rather than merely fitted to history.
Main Library
Publications
Article Map
Data Systems & Analytics
Related Topic
Risk & Resilience
Related Topic
Environmental Monitoring Systems
Related Topic
Intelligent Infrastructure Systems
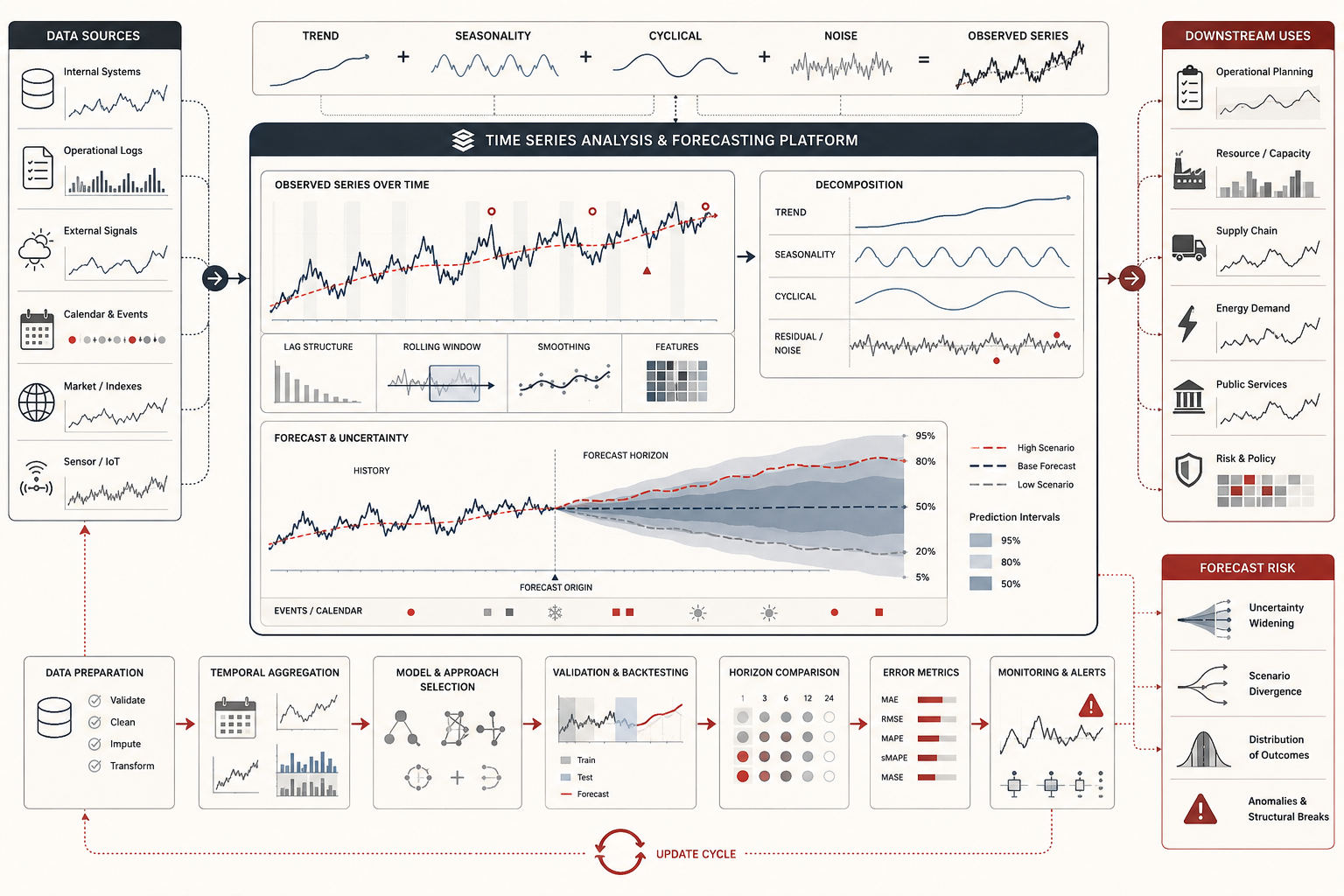
This article builds on the themes developed in Descriptive Analytics and Data Exploration, Statistical Modeling and Inference, Experimental Design and Causal Inference, Predictive Analytics and Machine Learning Models, Model Training and Validation, Model Evaluation and Performance Metrics, Streaming Data and Real-Time Analytics, and Reproducible Analytics and Versioned Data Workflows. If predictive analytics asks how well unseen outcomes can be estimated, time series forecasting asks how well future values can be projected from temporally ordered evidence.
Forecasting as temporal evidence
The strongest way to understand time series forecasting is as temporal evidence under uncertainty. A forecast is not a detached prediction produced by a model in isolation. It is a conditional statement about a future path, grounded in assumptions about temporal structure: whether trend persists, whether seasonality remains stable, whether autocorrelation continues, whether external predictors retain their relationship to the series, and whether the underlying process has not shifted into a new regime.
This distinction matters because time series models are often presented as if they simply “discover the future” from historical data. In reality, they project forward from patterns that may or may not remain relevant. A forecast is only as credible as the temporal structure it depends on. When that structure is stable, forecasting can be extremely useful. When that structure breaks, even a technically sophisticated model may fail.
Forecasting therefore requires both statistical skill and epistemic humility. The analyst must ask what the series has done, what parts of its movement appear persistent, how much uncertainty grows with horizon, how errors behaved in backtests, and whether new observations suggest that the process has changed. Forecasts are not final answers. They are disciplined inputs into planning, risk management, and decision support.
What time series analysis and forecasting mean
A time series is a sequence of observations indexed by time. Time series analysis studies the structure of those observations, especially the ways current values depend on past values, recurring temporal patterns, external drivers, and changing variance. Forecasting uses that structure to estimate future observations and the uncertainty around them.
This distinction matters because time is not just another variable. It imposes order, persistence, and irreversibility. Yesterday can affect today, but tomorrow cannot affect yesterday. A series may drift, repeat, decay, oscillate, spike, collapse, or change regime. Forecasting therefore depends on recognizing which features of the temporal record are signal, which are noise, and which are unstable enough to undermine projection.
Good time series analysis does not begin with model selection. It begins with the series itself: its frequency, time index, missing periods, measurement process, unit of observation, calendar structure, structural breaks, and intended forecast horizon. Without that foundation, modeling becomes a technical exercise disconnected from the process being forecast.
Why temporal data requires special treatment
Temporal data requires special treatment because observations collected over time are usually dependent rather than exchangeable. If monthly sales rise during holidays, hourly electricity load depends on prior demand, industrial measurements remain elevated after a process shift, or disease counts follow seasonal cycles, then the order of observations contains information that would be destroyed by treating the data as an unordered sample.
This also means that familiar inferential intuitions can weaken. Repeated observations do not automatically provide the same amount of new information when nearby observations resemble one another. A run of similar values may reflect persistence rather than repeated independent confirmation. Trends can make an average misleading. Seasonality can make recurring patterns look causal. Autocorrelation can make uncertainty look smaller than it really is if independence is assumed incorrectly.
Time series analysis exists because temporal order changes what counts as evidence. Analysts need methods that preserve sequence, respect forecast origin, and evaluate models using only information that would have been available at the time the forecast was made.
Trend, seasonality, cycles, and remainder
One of the most useful ways to begin time-series reasoning is by thinking in components. A series may contain a trend-cycle component, a seasonal component, and a remainder. In an additive view, the observed value is the sum of those components. In a multiplicative view, the components interact proportionally. The right representation depends on whether seasonal variation appears roughly constant in magnitude or grows with the level of the series.
This component view matters because it helps distinguish different kinds of temporal regularity. A trend reflects long-run directional movement. Seasonality reflects recurring periodic patterns tied to clock or calendar structure. Cycles may reflect longer, less rigid oscillations. The remainder captures what is left after systematic temporal structure has been accounted for.
Forecasting depends on deciding which of these structures are present, which are stable, and which are already breaking down. A model that treats trend as permanent may overproject. A model that ignores seasonality may miss predictable recurrence. A model that treats a structural break as noise may keep forecasting a world that no longer exists.
Autocorrelation, lags, and temporal memory
Perhaps the defining concept in time series analysis is autocorrelation: the correlation of a series with lagged versions of itself. Lag structure matters because it reveals persistence and memory. If values at time \(t\) are strongly related to values at \(t-1\), \(t-2\), or seasonal lags, then the past contains predictive information about the future.
Autocorrelation tells analysts how long the past remains relevant. Some processes decay quickly: only the recent past matters. Others retain longer memory or oscillatory structure. Seasonal autocorrelation can reveal yearly, weekly, or daily recurrences that a plain trend line would miss. In substantive terms, autocorrelation expresses continuity in the process. A highly autocorrelated series is not just noisy data arranged over time; it is evidence that the process carries state from one period into the next.
This is why lag choice is not a trivial tuning decision. Different lags correspond to different plausible process memories: immediate carryover, delayed response, or periodic repetition. Time series analysis becomes richer when analysts ask not only whether the series depends on its past, but which past and over what horizon.
Stationarity and the problem of stability
Many classical time-series methods depend on some version of stationarity: the idea that the process has stable statistical properties over time, often approximated as constant mean, constant variance, and stable autocorrelation structure. Stationarity matters because many models learn from the assumption that the statistical logic of the past remains relevant to the near future.
The intuitive point is simple: forecasting works best when the future resembles the past in the right structural sense. If the underlying process keeps changing its level, variance, dependence structure, or seasonal pattern, then historical data becomes a weaker guide. Stationarity is therefore less a metaphysical property than a working condition of forecastability. A stationary process is not “unchanging” in the everyday sense. It is stable enough that past behavior can teach us something reliable about future behavior.
Many practical series are only approximately stationary, or only after transformation. Differencing, detrending, seasonal adjustment, logarithmic transformation, or variance-stabilizing transformations may be used to make a series more modelable. The need for such transformations is itself a warning: the raw series may not be suitable for direct forecasting without first separating trend, drift, changing scale, or seasonality from the dependence structure of interest.
Time plots, seasonal plots, and lag structure
Graphics are indispensable in time series analysis. A time plot can reveal slow drift, sudden change, changing variance, outliers, or missing periods. A seasonal plot can expose recurring within-year, within-week, or within-day patterns. A lag plot can reveal dependence, clustering, nonlinear association, or delayed response. An autocorrelation plot helps show whether persistence dies out quickly, oscillates, or remains strong across many lags.
Visual inspection is not ornamental. It is often the first serious diagnostic. Summary statistics alone can hide temporal structure because they collapse sequence. A mean may obscure trend. A variance may hide volatility clustering. A correlation may ignore lag timing. A model selected before visual diagnosis may fit a pattern that was obvious but misunderstood.
Time series graphics also help communicate forecasts to decision-makers. Showing observed history, fitted values, forecast paths, prediction intervals, and recent errors helps prevent false precision. It makes the forecast visible as a conditional projection rather than as an isolated number.
Decomposition and structural interpretation
Decomposition methods attempt to separate a series into interpretable components such as trend, seasonality, and remainder. This is valuable for explanation, preprocessing, model selection, and forecast communication. Decomposition allows analysts to ask whether the main forecast signal comes from persistent level, long-run trend, recurring seasonality, lagged dependence, or external drivers.
Conceptually, decomposition reinforces that forecasting is not only about fitting a black-box model. It is often about understanding what temporal structure is doing the work. Is the model projecting summer peaks because seasonality is stable? Is it extrapolating a rising trend? Is it relying on recent persistence? Is it smoothing away a regime change? These are not cosmetic questions. They affect whether the forecast should be trusted and how it should be used.
Decomposition is also useful because it exposes the remainder. The remainder is not merely leftover noise. It may contain outliers, structural breaks, unmodeled cycles, exogenous shocks, or measurement changes. A responsible forecasting workflow inspects what remains after modeled structure has been removed.
Smoothing, ARIMA, and time series regression
The field includes several major modeling families. Smoothing methods are often useful when the goal is to capture level, trend, and seasonality without overfitting short-run noise. Exponential smoothing models update forecasts by weighting recent observations more heavily than older ones, with variants for trend and seasonality. These methods can be strong baselines because they are interpretable, operationally simple, and often competitive.
ARIMA-style models focus on autoregressive and moving-average dependence, often after differencing has made a series more stationary. They are useful when the structure of lagged dependence is central. Seasonal ARIMA extensions add seasonal autoregressive, differencing, and moving-average terms. These models can be powerful, but they require diagnostic discipline: stationarity, residual behavior, differencing choices, and order selection all matter.
Time series regression adds external predictors. A series of interest may be forecast using temperature, calendar effects, promotions, policy indicators, lagged explanatory variables, or other time-indexed covariates. This creates a bridge between purely endogenous forecasting and broader explanatory modeling. It also adds responsibility: external predictors must be available at forecast origin, not only known after the fact.
Forecast horizons, prediction intervals, and recursive uncertainty
A forecast is not only a point estimate. It should also communicate uncertainty. Prediction intervals matter because future values are never known with certainty, and uncertainty usually grows with the forecast horizon. A one-step-ahead forecast can lean heavily on the most recent observed state. A multi-step forecast must increasingly rely on earlier forecasts, stable structure, or assumptions holding further into the future.
This horizon effect is fundamental. Forecast uncertainty is often recursive: uncertainty at one horizon propagates into later horizons. Prediction intervals widen not because forecasters are being timid, but because farther futures are genuinely less constrained by available information. A central forecast path without intervals can create false precision and brittle planning.
This matters for decision-making because many practical uses of forecasting care less about one exact number than about plausible ranges. Inventory planning, staffing, grid balancing, maintenance scheduling, and public budgeting all require awareness of how wrong a forecast might reasonably be at different horizons. A forecast that does not communicate uncertainty is only half a forecast.
Forecast evaluation, backtesting, and rolling origin
Forecasts should be judged by how they perform on unseen future periods, not only by how well they fit historical data. Ordinary random cross-validation is usually inappropriate for forecasting because it breaks temporal order. It can allow a model to learn from future information and then appear to predict the past. A time-aware validation design must preserve forecast origin.
Rolling-origin evaluation is one of the most important methods for this purpose. The model is repeatedly trained using data available up to a given time, then asked to forecast subsequent observations. The forecast origin rolls forward, producing multiple out-of-sample errors. This approximates the operational setting: at each point, the model forecasts the future using only the past available at that point.
Evaluation should also be horizon-specific. A model that performs well one month ahead may fail six months ahead. Another may be weaker in the immediate term but more stable at longer horizons. Forecast evaluation is therefore not one accuracy number. It is an error profile across horizons, regimes, seasons, and operating conditions.
Structural breaks, regime change, and forecasting limits
Time series forecasting fails in recognizable ways. Structural breaks can invalidate previously stable patterns. Seasonal patterns can change. External shocks can overwhelm autoregressive history. A process may become nonstationary in ways that differencing or smoothing cannot adequately repair. A measurement system may change, making old values incomparable with new ones. A model trained on one regime may continue forecasting a world that no longer exists.
This is not just a technical caution. It is a warning about model fragility. Forecasts are conditional statements: if the structural relations of the recent past remain relevant, then these future paths are plausible. But when institutions face regime change—policy shifts, technological transitions, demand shocks, climate anomalies, market disruptions, conflict, regulation, platform redesign, or measurement redesign—the historical record may become a weak guide.
That is why forecasting should be practiced with statistical humility. A forecast is not a promise. It is a disciplined conditional projection. The farther the horizon, the more unstable the process, and the higher the consequence of being wrong, the more decision-makers need to treat forecasts as one input into risk-aware planning rather than as fixed future fact.
A mathematical lens for time series forecasting
A time series can be represented as an ordered sequence:
\{y_t\}_{t=1}^{T}
\]
Interpretation: The observation \(y_t\) is indexed by time \(t\). The order of the sequence is part of the evidence, not incidental metadata.
A common additive decomposition represents a series as trend, seasonal structure, and remainder:
y_t = T_t + S_t + R_t
\]
Interpretation: The observed value \(y_t\) can be decomposed into trend-cycle \(T_t\), seasonality \(S_t\), and remainder \(R_t\). Forecasting depends on which components are stable enough to project.
Autocorrelation summarizes dependence between a series and its lagged values:
\rho_k = \frac{\operatorname{Cov}(y_t, y_{t-k})}{\operatorname{Var}(y_t)}
\]
Interpretation: The autocorrelation \(\rho_k\) at lag \(k\) measures how strongly the series is related to its own past. Large values suggest temporal memory.
A basic autoregressive model uses lagged values as predictors:
y_t = c + \phi_1 y_{t-1} + \phi_2 y_{t-2} + \cdots + \phi_p y_{t-p} + \varepsilon_t
\]
Interpretation: An autoregressive model predicts the current value using prior values. The coefficients \(\phi_1, \ldots, \phi_p\) describe how past states carry forward.
Differencing is often used to reduce trend and approximate stationarity:
\nabla y_t = y_t – y_{t-1}
\]
Interpretation: First differencing models changes rather than levels. This can help when the raw series has a shifting mean or trend.
Forecast error at horizon \(h\) can be written as:
e_{t+h|t} = y_{t+h} – \hat{y}_{t+h|t}
\]
Interpretation: Forecast error compares the observed future value \(y_{t+h}\) with the forecast made at time \(t\) for horizon \(h\).
Rolling-origin forecast accuracy can be summarized by mean absolute error:
MAE_h = \frac{1}{N}\sum_{i=1}^{N}\left|y_{t_i+h} – \hat{y}_{t_i+h|t_i}\right|
\]
Interpretation: Horizon-specific MAE evaluates forecast error across multiple forecast origins while preserving temporal order.
A forecast-readiness score can combine validation design, error behavior, interval coverage, diagnostic status, and governance review:
F_m = w_VV_m + w_EE_m + w_II_m + w_DD_m + w_GG_m
\]
Interpretation: Forecast readiness \(F_m\) for model \(m\) can combine validation design \(V_m\), error evidence \(E_m\), interval behavior \(I_m\), diagnostic status \(D_m\), and governance review \(G_m\).
The point of this mathematical lens is not to make forecasting appear mechanical. It is to make the assumptions explicit: what temporal structure is being modeled, how errors are measured, how uncertainty grows, and why the forecast should or should not be trusted.
Python Workflow: Time Series Forecasting Scorecard
The following Python workflow demonstrates how a forecasting review can inspect autocorrelation, year-level trend, rolling-origin forecast errors, horizon-specific uncertainty, diagnostic checks, and forecast-readiness scoring.
#!/usr/bin/env python3
"""
Python Workflow: Time Series Forecasting Scorecard
This compact example evaluates temporal diagnostics, rolling-origin
errors, interval coverage, and forecast readiness.
"""
from __future__ import annotations
import math
from dataclasses import dataclass
@dataclass
class ForecastPoint:
actual: float
forecast: float
lower_80: float
upper_80: float
def mean(values: list[float]) -> float:
return sum(values) / len(values) if values else 0.0
def autocorrelation(values: list[float], lag: int) -> float:
x = values[lag:]
y = values[:-lag]
x_mean = mean(x)
y_mean = mean(y)
numerator = sum((a - x_mean) * (b - y_mean) for a, b in zip(x, y))
denominator = math.sqrt(
sum((a - x_mean) ** 2 for a in x) *
sum((b - y_mean) ** 2 for b in y)
)
return numerator / denominator if denominator else 0.0
def rolling_seasonal_naive(values: list[float], season: int = 12, min_train: int = 18) -> list[dict[str, float]]:
rows = []
for target_index in range(min_train, len(values)):
forecast = values[target_index - season]
actual = values[target_index]
error = actual - forecast
rows.append({
"target_index": target_index,
"actual": actual,
"forecast": forecast,
"error": error,
"absolute_error": abs(error),
"squared_error": error ** 2,
})
return rows
def forecast_error_summary(errors: list[dict[str, float]]) -> dict[str, float]:
mae = mean([row["absolute_error"] for row in errors])
rmse = math.sqrt(mean([row["squared_error"] for row in errors]))
bias = mean([row["error"] for row in errors])
return {
"mae": mae,
"rmse": rmse,
"bias": bias,
}
def interval_coverage(points: list[ForecastPoint]) -> float:
hits = [
1 if point.lower_80 <= point.actual <= point.upper_80 else 0
for point in points
]
return mean(hits)
def forecast_readiness_score(
validation_design: float,
error_evidence: float,
interval_quality: float,
diagnostic_status: float,
governance_review: float,
) -> float:
return round(
0.30 * validation_design
+ 0.25 * error_evidence
+ 0.20 * interval_quality
+ 0.15 * diagnostic_status
+ 0.10 * governance_review,
3,
)
def main() -> None:
monthly_values = [
105, 108, 115, 121, 130, 146, 155, 151, 139, 128, 119, 136,
111, 114, 122, 129, 140, 158, 169, 164, 150, 137, 128, 147,
120, 124, 133, 141, 153, 172,
]
print({
"acf_lag_1": round(autocorrelation(monthly_values, 1), 3),
"acf_lag_12": round(autocorrelation(monthly_values, 12), 3),
})
errors = rolling_seasonal_naive(monthly_values)
print({
key: round(value, 3)
for key, value in forecast_error_summary(errors).items()
})
released_points = [
ForecastPoint(actual=169, forecast=155, lower_80=145, upper_80=165),
ForecastPoint(actual=164, forecast=151, lower_80=141, upper_80=161),
ForecastPoint(actual=150, forecast=139, lower_80=129, upper_80=149),
ForecastPoint(actual=137, forecast=128, lower_80=118, upper_80=138),
]
coverage = interval_coverage(released_points)
print({
"interval_coverage_80": round(coverage, 3),
"forecast_readiness_score": forecast_readiness_score(
validation_design=1.00,
error_evidence=0.78,
interval_quality=coverage,
diagnostic_status=0.70,
governance_review=0.85,
)
})
if __name__ == "__main__":
main()
This workflow treats forecasting as a controlled evidence process. It does not only produce a future number. It evaluates lag structure, backtested error, interval behavior, diagnostic status, and release readiness.
R Workflow: Time Series Diagnostics, Backtesting, and Forecast Governance Summary
The following R workflow summarizes forecast model families, validation designs, backtest errors, interval coverage, diagnostic checks, forecast horizon widths, and year-level trend evidence.
#!/usr/bin/env Rscript
# R Workflow: Time Series Diagnostics, Backtesting,
# and Forecast Governance Summary
observations <- data.frame(
date = seq(as.Date("2024-01-01"), by = "month", length.out = 30),
series_id = rep("demand", 30),
value = c(
105, 108, 115, 121, 130, 146, 155, 151, 139, 128, 119, 136,
111, 114, 122, 129, 140, 158, 169, 164, 150, 137, 128, 147,
120, 124, 133, 141, 153, 172
)
)
registry <- data.frame(
model_id = c("ts001", "ts002", "ts003", "ts004", "ts005"),
model_family = c(
"seasonal_naive",
"moving_average",
"time_series_regression",
"sarima",
"linear_trend"
),
validation_design = c(
"rolling_origin",
"rolling_origin",
"rolling_origin",
"rolling_origin",
"static_holdout"
),
status = c("approved", "in_review", "in_review", "planned", "needs_revision"),
risk_level = c("low", "medium", "medium", "medium", "medium"),
stringsAsFactors = FALSE
)
backtests <- data.frame(
model_id = c(
"ts001", "ts001", "ts001", "ts001",
"ts002", "ts002", "ts002", "ts002",
"ts003", "ts003", "ts003", "ts003"
),
horizon = rep(1, 12),
actual = c(169, 164, 150, 137, 169, 164, 150, 137, 169, 164, 150, 137),
forecast = c(155, 151, 139, 128, 142, 155, 162, 161, 160, 170, 162, 145),
lower_80 = c(145, 141, 129, 118, 130, 143, 150, 149, 150, 160, 152, 135),
upper_80 = c(165, 161, 149, 138, 154, 167, 174, 173, 170, 180, 172, 155),
status = c("watch", "watch", "watch", "pass", "fail", "pass", "watch", "fail", "pass", "pass", "watch", "pass"),
stringsAsFactors = FALSE
)
checks <- data.frame(
check_type = c(
"time_index_regular",
"missing_periods",
"seasonality_present",
"trend_present",
"stationarity",
"structural_break"
),
status = c("pass", "pass", "pass", "warn", "watch", "watch"),
severity = c("high", "high", "medium", "medium", "high", "high"),
stringsAsFactors = FALSE
)
horizons <- data.frame(
model_id = c("ts001", "ts001", "ts001", "ts003", "ts003", "ts003"),
horizon = c(1, 2, 3, 1, 2, 3),
forecast = c(169, 164, 150, 174, 166, 153),
lower_80 = c(157, 148, 130, 164, 152, 135),
upper_80 = c(181, 180, 170, 184, 180, 171),
lower_95 = c(150, 139, 119, 158, 144, 125),
upper_95 = c(188, 189, 181, 190, 188, 181),
release_status = c("approved", "approved", "approved", "in_review", "in_review", "in_review"),
stringsAsFactors = FALSE
)
model_summary <- aggregate(
model_id ~ model_family + validation_design + status + risk_level,
data = registry,
FUN = length
)
names(model_summary) <- c(
"model_family",
"validation_design",
"status",
"risk_level",
"model_count"
)
backtests$error <- backtests$actual - backtests$forecast
backtests$absolute_error <- abs(backtests$error)
backtests$squared_error <- backtests$error ^ 2
backtests$interval_hit_80 <- ifelse(
backtests$actual >= backtests$lower_80 &
backtests$actual <= backtests$upper_80,
1,
0
)
backtest_summary <- aggregate(
cbind(absolute_error, squared_error, interval_hit_80) ~ model_id + horizon,
data = backtests,
FUN = mean
)
names(backtest_summary) <- c(
"model_id",
"horizon",
"mae",
"mean_squared_error",
"interval_coverage_80"
)
backtest_summary$rmse <- sqrt(backtest_summary$mean_squared_error)
check_summary <- aggregate(
check_type ~ status + severity,
data = checks,
FUN = length
)
names(check_summary) <- c("status", "severity", "check_count")
horizons$width_80 <- horizons$upper_80 - horizons$lower_80
horizons$width_95 <- horizons$upper_95 - horizons$lower_95
horizon_summary <- aggregate(
cbind(width_80, width_95) ~ model_id + horizon + release_status,
data = horizons,
FUN = mean
)
observations$year <- format(observations$date, "%Y")
year_summary <- aggregate(
value ~ series_id + year,
data = observations,
FUN = mean
)
names(year_summary) <- c("series_id", "year", "mean_value")
dir.create("outputs", showWarnings = FALSE, recursive = TRUE)
write.csv(model_summary, "outputs/model_summary_r.csv", row.names = FALSE)
write.csv(backtest_summary, "outputs/backtest_summary_r.csv", row.names = FALSE)
write.csv(check_summary, "outputs/diagnostic_check_summary_r.csv", row.names = FALSE)
write.csv(horizon_summary, "outputs/horizon_interval_summary_r.csv", row.names = FALSE)
write.csv(year_summary, "outputs/year_summary_r.csv", row.names = FALSE)
cat("Wrote time-series model, backtest, diagnostic, horizon, and year summaries.\n")
This workflow treats forecast evidence as a lifecycle record. It asks which model family is being used, whether validation preserves temporal order, how error behaves in backtesting, whether intervals are wide enough, and which diagnostics require review.
Time series analysis in analytical workflow
In a mature analytical workflow, time series analysis sits between descriptive exploration and forward-looking decision support. Analysts begin with time plots, seasonal plots, lag structure, and decomposition to understand the observed process. They then select or compare models suited to the structure they see. Forecasts are evaluated on held-out future periods or rolling origins, and uncertainty is communicated alongside point forecasts.
Time series reasoning also recurs after deployment. Forecasts must be revisited as new observations arrive. Analysts inspect residuals, monitor drift, assess whether old seasonality still holds, and recalibrate models when new regimes emerge. Forecasting is therefore not a one-off technical step. It is an ongoing practice of temporal vigilance.
This workflow also connects directly to reproducibility. Forecast origins, training windows, model versions, exogenous inputs, released forecasts, intervals, and realized errors should be recorded. Without those records, an organization cannot easily tell whether a forecast failed because the model was wrong, the data changed, an exogenous assumption failed, or the process shifted.
Forecast governance and institutional accountability
Forecasts influence decisions. They can shape staffing, procurement, public budgets, infrastructure planning, inventory, energy dispatch, safety preparation, and risk posture. This means forecast governance matters. A forecast should not be treated as a neutral number detached from assumptions, uncertainty, and decision consequences.
Forecast governance includes model ownership, forecast release status, horizon definition, interval reporting, backtest evidence, diagnostic review, monitoring cadence, revision history, and escalation triggers. High-consequence forecasts should include uncertainty intervals and decision-risk framing. A point forecast alone can invite overconfidence.
Governance also requires clarity about what the forecast is not. A forecast is not a causal explanation. It may project demand but not explain why demand changed. It may anticipate a risk window but not identify an intervention. It may show plausible future paths but not eliminate uncertainty. Forecasts should support judgment, not replace it.
Applications across domains
Time series analysis and forecasting appear across nearly every empirical domain where change over time matters. Energy systems use them for load forecasting, grid balancing, and renewable generation planning. Economics uses them for inflation, employment, production, and macro indicators. Finance uses them for prices, returns, volatility, liquidity, and risk monitoring. Public administration uses them for budgeting, demand forecasting, service planning, and emergency preparedness.
Engineering and infrastructure systems use time series for process monitoring, predictive maintenance, anomaly detection, and sensor interpretation. Environmental systems use them for climate indicators, air quality, water levels, biodiversity monitoring, and hazard detection. Business systems use them for sales, staffing, inventory, subscription behavior, and operational capacity.
Across all these settings, the central question is the same: given the temporal structure observed in the record, what future states are plausible, how rapidly does uncertainty grow, and what decision risk follows from being wrong?
Implementation principles for high-integrity forecasting
Preserve temporal order. Do not randomly split time-ordered forecasting data when the goal is to forecast future periods.
Define the forecast origin. Every forecast should specify the time at which it was made and the information available at that time.
Inspect trend, seasonality, and lag structure. Model choice should follow temporal diagnostics, not precede them.
Assess stationarity and transformation needs. Trend, changing variance, and seasonal structure may require differencing, detrending, or transformation.
Use sensible baselines. Naive, seasonal naive, moving average, and simple smoothing methods are important reference points.
Evaluate with rolling origin where possible. Backtesting should simulate the operational forecasting problem.
Report error by horizon. One-step performance does not necessarily describe longer-horizon performance.
Publish intervals, not only point forecasts. Forecasts without uncertainty can create false precision.
Monitor structural breaks and drift. Forecast validity depends on whether temporal structure remains relevant.
Connect forecasts to decision risk. Forecast quality should be judged in relation to the decisions it supports.
| Control | Purpose | Failure it prevents |
|---|---|---|
| Regular time-index review | Confirms frequency, missing periods, and timestamp integrity | Forecasts built on irregular or misunderstood time structure |
| Trend and seasonality diagnostics | Identifies persistent temporal components | Models that ignore recurring or directional structure |
| Autocorrelation review | Measures temporal memory and lag dependence | Treating dependent observations as independent |
| Stationarity assessment | Checks whether mean, variance, and dependence structure are stable enough for modeling | Applying classical models to unstable processes without transformation |
| Rolling-origin backtesting | Evaluates forecasts using past data to predict later observations | Future leakage and random-split optimism |
| Horizon-specific error reporting | Shows how error changes as the forecast horizon grows | Hiding long-horizon failure behind one aggregate metric |
| Prediction interval reporting | Communicates uncertainty around forecast paths | False precision and brittle planning |
| Structural-break monitoring | Detects when historical patterns no longer hold | Models forecasting an obsolete regime |
GitHub Repository
This article can be paired with a companion code workflow that models forecasting as temporal-evidence infrastructure. The example includes monthly series data, forecast model registries, rolling-origin backtests, diagnostic checks, forecast horizons, prediction intervals, SQL schemas, Python and R workflows, Julia scoring, typed contracts, governance checklists, Quarto report templates, and multi-language examples across Python, R, Julia, SQL, Go, Rust, C, C++, TypeScript, and Terraform placeholders.
The companion repository provides a vendor-neutral time series analysis and forecasting scaffold with temporal diagnostics, autocorrelation checks, baseline forecasts, rolling-origin backtests, horizon-specific error summaries, prediction interval review, diagnostic monitoring, SQL governance queries, reproducible reporting templates, typed contracts, documentation, and CI smoke-test patterns.
Conclusion
Time series analysis and forecasting are central to trustworthy analytics because many systems unfold through time and require decisions before the future is observed. Temporal data is not an unordered sample. It may carry trend, seasonality, lag dependence, changing variance, structural breaks, and delayed response. Forecasting becomes credible only when those structures are diagnosed, modeled, validated, and monitored with care.
The deeper point is that forecasting is a disciplined conditional projection. It asks what future paths are plausible if the relevant structure of the past remains informative. That conditional logic requires humility. Forecasts should be evaluated against unseen future periods, reported with uncertainty, revised when regimes change, and governed when they shape consequential decisions. In data-intensive organizations, forecasting is therefore not only a modeling technique. It is a system of temporal evidence, uncertainty communication, and risk-aware decision support.
Related articles
- Data Systems and Analytics knowledge series
- Descriptive Analytics and Data Exploration
- Statistical Modeling and Inference
- Experimental Design and Causal Inference
- Predictive Analytics and Machine Learning Models
- Model Training and Validation
- Model Evaluation and Performance Metrics
- Streaming Data and Real-Time Analytics
Further reading
- Box, G.E.P., Jenkins, G.M., Reinsel, G.C. and Ljung, G.M. (2015) Time Series Analysis: Forecasting and Control. 5th edn. Hoboken, NJ: Wiley.
- Chatfield, C. (2000) Time-Series Forecasting. Boca Raton, FL: CRC Press.
- Hamilton, J.D. (1994) Time Series Analysis. Princeton, NJ: Princeton University Press.
- Hyndman, R.J. and Athanasopoulos, G. (2021) Forecasting: Principles and Practice. 3rd edn. Melbourne: OTexts. Available at: https://otexts.com/fpp3/
- Shumway, R.H. and Stoffer, D.S. (2017) Time Series Analysis and Its Applications. 4th edn. Cham: Springer.
- Hyndman, R.J. and Athanasopoulos, G. (2021) Time series cross-validation. Available at: https://otexts.com/fpp3/tscv.html
References
- Hyndman, R.J. and Athanasopoulos, G. (2021) Forecasting: Principles and Practice. 3rd edn. Melbourne: OTexts. Available at: https://otexts.com/fpp3/
- Hyndman, R.J. and Athanasopoulos, G. (2021) Time series cross-validation. Available at: https://otexts.com/fpp3/tscv.html
- National Institute of Standards and Technology and SEMATECH (2012) Introduction to Time Series Analysis. Available at: https://www.itl.nist.gov/div898/handbook/pmc/section4/pmc4.htm
- National Institute of Standards and Technology and SEMATECH (2012) Stationarity. Available at: https://www.itl.nist.gov/div898/handbook/pmc/section4/pmc442.htm
- National Institute of Standards and Technology and SEMATECH (2012) Seasonality. Available at: https://www.itl.nist.gov/div898/handbook/pmc/section4/pmc443.htm
- scikit-learn developers (2026) TimeSeriesSplit. Available at: https://scikit-learn.org/stable/modules/generated/sklearn.model_selection.TimeSeriesSplit.html
- statsmodels developers (2025) statsmodels.tsa.arima.model.ARIMA. Available at: https://www.statsmodels.org/stable/generated/statsmodels.tsa.arima.model.ARIMA.html
- statsmodels developers (2025) Time Series analysis tsa. Available at: https://www.statsmodels.org/stable/tsa.html