
Last Updated June 1, 2026
Networked systems make modern life possible. Food moves through supply chains. Electricity moves through grids. Water moves through pipes, pumps, treatment systems, watersheds, and governance institutions. People move through roads, transit, airports, sidewalks, and digital platforms. Information moves through social networks, media systems, organizations, algorithms, and public agencies. Financial obligations move through banks, firms, households, governments, insurers, and markets. Public health depends on networks of care, communication, trust, labor, infrastructure, and social contact.
Networks, Dependencies, and Cascade Risk examines systems whose behavior depends on connection. Networks can create resilience by distributing capacity, sharing resources, and enabling cooperation. But they can also create fragility when failures travel across dependencies. A single supplier failure can disrupt production. A bridge node can spread contagion. A power outage can disable water, communications, healthcare, refrigeration, transit, and emergency response. A rumor can cascade through a platform before correction arrives. A financial shock can propagate through debt, confidence, and liquidity. Network structure determines whether stress is absorbed locally or spreads across the system.
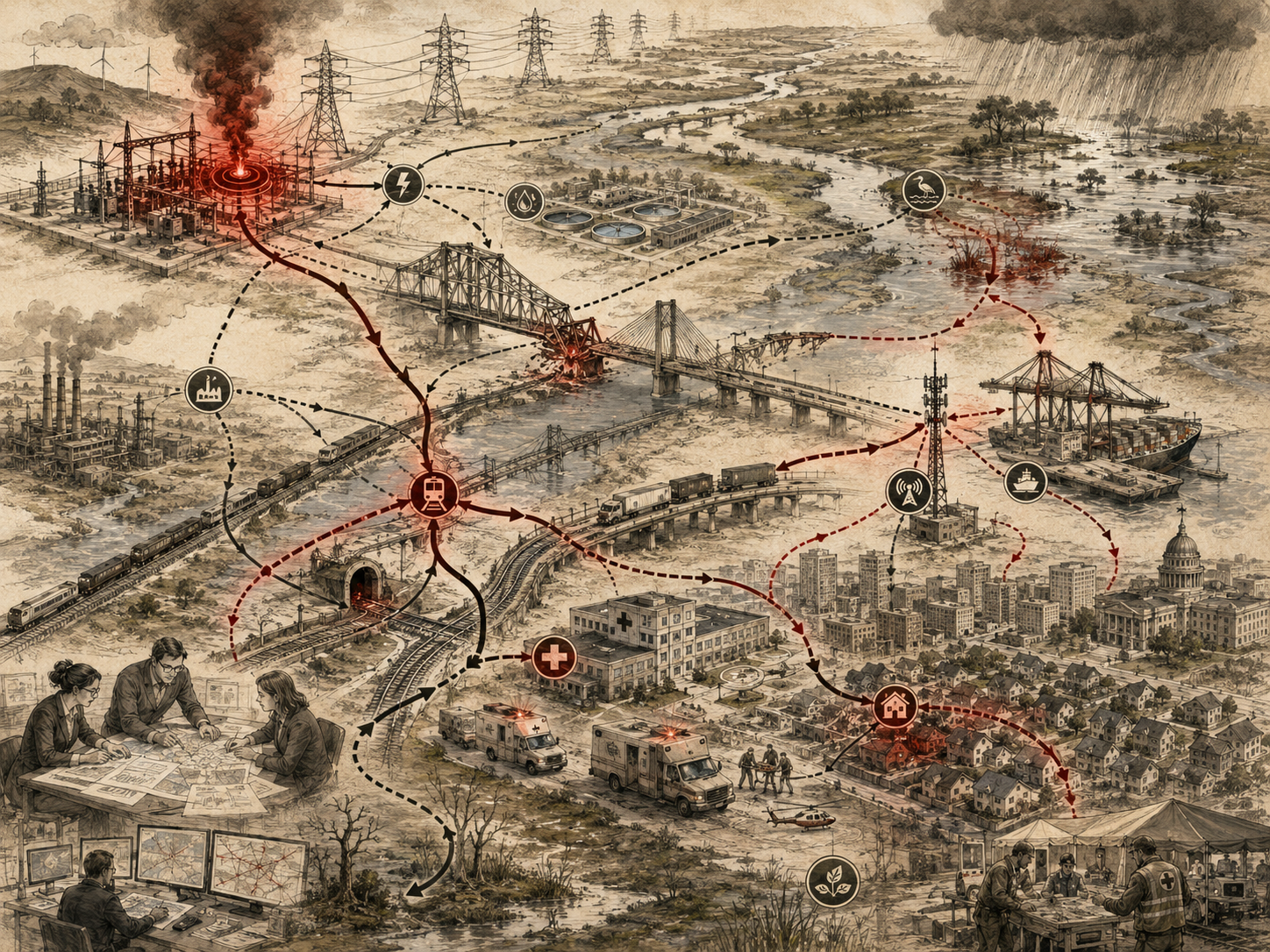
This article explains networks, dependencies, and cascade risk as foundations for systems thinking. It examines nodes, edges, hubs, bridges, dependencies, bottlenecks, redundancy, modularity, coupling, contagion, systemic risk, infrastructure interdependence, digital networks, supply chains, financial systems, public health, and institutional resilience. It shows why highly connected systems can be powerful and fragile at the same time, why efficiency can reduce buffers, why bridge nodes matter, why failures can propagate through hidden dependencies, and why resilient design requires redundancy, transparency, diversity, modularity, monitoring, and accountable governance.
Why Network Thinking Matters
Network thinking matters because many system outcomes depend less on isolated parts than on patterns of connection. A hospital may have beds, staff, medicine, electricity, water, oxygen, supply chains, communications, data systems, and transportation access. Its resilience depends not only on each component, but on how those components depend on one another. A city may have roads, transit, housing, drainage, power, emergency services, schools, and food distribution. Its vulnerability depends on whether one failure can travel through multiple systems. A digital platform may have users, algorithms, advertisers, moderators, data pipelines, incentives, and communities. Its social effect depends on how information, attention, status, and behavior move through the network.
Networks create possibility. They allow coordination, learning, exchange, mobility, care, trade, communication, mutual aid, energy distribution, public services, and collective action. But networks also create exposure. The more a system depends on connection, the more it must ask what happens when a connection fails, overloads, distorts, or transmits harm. Connectivity is not automatically resilience. Sometimes connectivity spreads failure.
Systems thinking often begins with interdependence. Network thinking gives interdependence a structure. It asks which nodes matter most, which links carry critical flows, which hubs concentrate power or risk, which bridges connect otherwise separate systems, which dependencies are hidden, which alternatives exist, and how failure can propagate. Without network thinking, institutions can mistake local stability for system resilience.
| Network question | Why it matters | Example |
|---|---|---|
| Which nodes are critical? | Some components carry disproportionate system importance. | A substation, hospital, supplier, data center, port, bridge, or public agency. |
| Which links are fragile? | Weak connections can interrupt flows or transmit failure. | A single transmission line, logistics route, API, pipeline, or funding channel. |
| Where are bottlenecks? | Flow concentrates where capacity is limited. | Ports, clinics, call centers, rail junctions, court systems, or permitting offices. |
| Where are bridge nodes? | Some nodes connect otherwise separate parts of the system. | Regional hospitals, interconnectors, community health workers, transit hubs, or middleware systems. |
| Where is redundancy missing? | Systems fail when there are no alternative routes or backups. | Single-source suppliers, single roads, single cloud providers, or sole treatment plants. |
| How can failure cascade? | One failure can trigger others across dependencies. | Power outage → water failure → hospital stress → emergency response disruption. |
Network thinking is especially important because modern systems often optimize for efficiency, speed, and cost reduction. Just-in-time supply chains, centralized platforms, thin inventories, concentrated suppliers, automated decision systems, and lean staffing can improve performance under normal conditions. But they can also reduce buffers, obscure dependencies, and increase cascade risk. A system can be efficient and brittle at the same time.
Network systems thinking asks not only whether a system works when conditions are normal. It asks how it fails, where failure spreads, who is exposed, who has backup options, and what kinds of connection make the system more resilient rather than more fragile.
What a Network Is
A network is a set of connected elements. The elements are usually called nodes. The connections are usually called edges, links, ties, or relationships. Nodes can be people, organizations, computers, power plants, hospitals, firms, species, cities, banks, documents, neighborhoods, roads, servers, transformers, public agencies, or ideas. Edges can represent communication, transport, dependency, influence, money, electricity, water, data, infection, trust, trade, ownership, or authority.
A network can be physical, social, ecological, economic, digital, institutional, or conceptual. A road network connects places through streets and highways. A power grid connects generators, substations, transmission lines, distribution lines, and consumers. A social network connects people through relationships. A supply chain connects firms, materials, logistics, finance, and demand. A public-health network connects patients, clinicians, laboratories, agencies, communities, data systems, and communication channels. An ecosystem network connects species through predation, competition, symbiosis, pollination, nutrient cycling, and habitat.
G = (V, E)
\]
Interpretation: A network or graph \(G\) consists of a set of nodes \(V\) and a set of edges \(E\) connecting those nodes.
Networks can be directed or undirected. In an undirected network, a relationship goes both ways: two people know each other, two roads connect, or two organizations collaborate. In a directed network, the relationship has direction: money flows from one institution to another, power flows through a transmission system, information is sent from one account to another, or a supplier provides inputs to a manufacturer. Direction matters because dependency often has direction. A hospital may depend on electricity, but the electricity grid may not depend on that hospital in the same way.
Networks can also be weighted or unweighted. An unweighted edge simply records whether a connection exists. A weighted edge records strength, capacity, frequency, volume, cost, trust, risk, distance, or dependency. A bridge with high traffic volume is not the same as a rarely used road. A supplier that provides 70 percent of a critical input is not the same as a supplier that provides 2 percent. A trusted community messenger is not the same as a weak broadcast channel.
Network thinking makes interdependence visible. It allows us to ask how system structure affects flow, access, vulnerability, power, resilience, and failure. A network is not only a map. It is a way of seeing how systems behave through connection.
Nodes, Edges, Hubs, and Bridges
Not all nodes and edges matter equally. Some nodes are hubs, with many connections. Some are bridges, connecting otherwise separate parts of the network. Some are bottlenecks, where flow is concentrated through limited capacity. Some are peripheral but essential to vulnerable communities. Some nodes are visible because they are large; others are critical because they connect systems quietly.
Hubs can create efficiency and reach. A major airport connects many regions. A cloud provider supports many applications. A regional hospital provides specialized care. A dominant supplier reduces coordination costs. A central data platform standardizes information. But hubs can also concentrate risk. When a hub fails, many dependent nodes may be affected. Hub dominance can also concentrate power, bargaining leverage, surveillance capacity, or political influence.
Bridge nodes connect separate clusters. A bridge may be a transit station linking neighborhoods, a community organization linking residents and government, a data interface linking agencies, a supplier linking industries, a port linking national and global trade, or a transformer linking grid segments. Bridges are often powerful leverage points because they affect coordination across boundaries. They are also points of vulnerability because their failure can isolate parts of the system.
\text{Node Criticality} = f(\text{Connectivity}, \text{Flow}, \text{Substitutability}, \text{Bridge Role})
\]
Interpretation: A node becomes critical when it is highly connected, carries important flow, lacks substitutes, or connects otherwise separate parts of the network.
| Network role | System function | Risk if it fails |
|---|---|---|
| Hub | Concentrates connections, flow, or coordination. | Failure can affect many dependent nodes at once. |
| Bridge | Connects otherwise separate clusters or systems. | Failure can fragment the network or isolate communities. |
| Bottleneck | Controls a limited-capacity passage for critical flow. | Overload or failure can restrict the whole system. |
| Peripheral critical node | May have few links but serve a vulnerable or essential function. | Failure can be severe for specific communities even if system averages look stable. |
| Redundant node | Provides alternative capacity or backup. | Loss may be absorbed if alternatives remain functional. |
Network analysis should not assume that the most connected node is always the most important. A small clinic may be critical for a rural region. A low-volume road may be the only evacuation route. A community organization may be the trusted bridge between public institutions and residents. A small supplier may produce a specialized part that cannot be easily replaced. Criticality depends on function, context, dependency, and substitutability.
Systems thinking therefore asks not only “What is connected?” but “What does the connection do, who depends on it, what alternatives exist, and what happens if it fails?”
Dependency as System Structure
A dependency exists when one part of a system relies on another for function, information, resources, legitimacy, access, capacity, or survival. Dependencies can be technical, social, economic, ecological, institutional, or political. A water system may depend on electricity. A hospital may depend on supply chains, staff, oxygen, pharmaceuticals, data systems, and public trust. A food system may depend on fuel, roads, refrigeration, labor, water, finance, and weather. A digital service may depend on cloud infrastructure, payment systems, software libraries, APIs, identity systems, and network connectivity.
Dependencies are often invisible until something fails. Under normal conditions, the system appears to work. When a dependency breaks, hidden structure becomes visible. A storm reveals that power, communications, water, transportation, fuel, refrigeration, healthcare, and emergency response are intertwined. A supply shock reveals concentrated suppliers. A cyberattack reveals dependence on shared digital infrastructure. A public-health crisis reveals dependence on care workers, data systems, laboratories, trust, and paid leave.
Dependencies can be direct or indirect. A direct dependency links one system to another immediately: a hospital needs electricity. An indirect dependency operates through chains: a hospital needs electricity; electricity needs fuel, transmission, control systems, maintenance workers, communications, and cooling. Indirect dependencies are harder to map and often more dangerous because they hide cascade pathways.
D_{A \rightarrow B} = \text{Degree to which system } A \text{ requires system } B \text{ to function}
\]
Interpretation: Dependency is directional. If system \(A\) depends on system \(B\), failure in \(B\) can disrupt \(A\), even if \(B\) does not depend equally on \(A\).
Dependency is not inherently bad. Systems depend on one another because specialization and connection create capability. A city without dependencies would be impossible. But unmanaged dependency creates fragility when alternatives are missing, information is poor, capacity is thin, or governance is fragmented. The question is not whether dependency exists. The question is whether it is understood, monitored, governed, diversified, and protected.
Network systems thinking treats dependencies as design facts. It asks what must keep functioning for the system to survive, what dependencies are concentrated, what dependencies cross jurisdictions, what dependencies are private but publicly essential, and what dependencies place vulnerable communities at disproportionate risk.
Cascade Risk and Failure Propagation
Cascade risk is the risk that failure in one part of a system will spread to other parts. Cascades occur when nodes or systems depend on one another in ways that transmit stress. A power outage can disrupt water pumps, traffic signals, cell towers, hospitals, elevators, refrigeration, public transit, and payment systems. A supply-chain disruption can affect production, prices, employment, public services, and political stability. A cyberattack can disable municipal services, hospitals, firms, logistics, and communications. A financial shock can spread through credit, confidence, liquidity, and asset values.
Cascades are not always sudden. Some unfold quickly, as with blackouts, cyberattacks, contagion, or social-media information cascades. Others unfold slowly, as with infrastructure maintenance backlogs, ecosystem degradation, institutional distrust, or housing displacement. Cascade risk includes both rapid failure propagation and slow-moving systemic deterioration.
Cascade risk depends on network structure. Highly connected systems can spread stress widely. Tightly coupled systems can transmit failure quickly. Systems with weak buffers have less time to respond. Systems with low redundancy have fewer alternative routes. Systems with poor visibility detect failure late. Systems with fragmented governance struggle to coordinate response.
\text{Cascade Risk} = f(\text{Connectivity}, \text{Dependency}, \text{Coupling}, \text{Buffer}, \text{Redundancy}, \text{Detection})
\]
Interpretation: Cascade risk grows when systems are highly connected, dependent, tightly coupled, poorly buffered, weakly redundant, and slow to detect stress.
| Cascade pathway | Initial disruption | Secondary effects |
|---|---|---|
| Infrastructure cascade | Power outage | Water pumps, hospitals, traffic systems, communications, refrigeration, and emergency response fail. |
| Supply-chain cascade | Supplier shutdown | Production delays, price spikes, inventory shortages, layoffs, and service disruption. |
| Information cascade | False claim spreads | Behavior changes, institutional trust declines, public response weakens, and harm amplifies. |
| Financial cascade | Liquidity shock | Asset sales, credit tightening, firm distress, household insecurity, and public intervention. |
| Public-health cascade | Disease outbreak | Care overload, workforce shortages, school disruption, economic stress, and trust erosion. |
| Climate cascade | Extreme heat or flood | Grid stress, health risk, transport disruption, housing damage, insurance stress, and fiscal burden. |
Cascade risk analysis asks where failure can spread and how to interrupt the pathway. This may involve physical isolation, backup capacity, demand reduction, emergency protocols, local storage, distributed generation, supplier diversification, public communication, cyber segmentation, financial buffers, institutional coordination, or community networks.
The central insight is that preventing cascades is not only about strengthening individual parts. It is about changing the pathways through which failure travels.
Tight Coupling and Hidden Fragility
Tight coupling occurs when parts of a system are linked so closely that changes in one part quickly affect others. Tightly coupled systems can be efficient because they reduce delay, waste, inventory, and slack. But tight coupling can also create fragility because there is little time or space to absorb disruption. When one part fails, others may fail before institutions can understand what is happening.
Modern systems often become tightly coupled through optimization. Just-in-time logistics reduce inventory. Lean staffing reduces labor slack. Automated platforms reduce manual review. Consolidated suppliers reduce procurement complexity. Centralized infrastructure reduces duplication. Integrated data systems improve speed. These improvements can make normal operations faster and cheaper. They can also reduce resilience if backup pathways, human judgment, redundancy, and recovery capacity are removed.
Hidden fragility appears when a system performs well under normal conditions but lacks capacity under stress. A hospital may run efficiently at high occupancy until a surge arrives. A supply chain may keep costs low until a supplier fails. A grid may meet average demand until heat waves increase peak load. A digital platform may scale quickly until a software dependency fails. A public agency may process routine cases until a crisis increases demand.
\text{Fragility} \uparrow \quad \text{when} \quad \text{Coupling} \uparrow \; \text{and} \; \text{Buffer} \downarrow
\]
Interpretation: Systems become more fragile when tight coupling increases while buffers, redundancy, and recovery capacity decline.
Tight coupling can also create moral hazard when private actors benefit from efficiency while public systems absorb failure. A firm may reduce inventory to save cost, but when shortages occur, workers, consumers, public agencies, and vulnerable communities bear the burden. A platform may optimize engagement, while public discourse absorbs misinformation cascades. A utility may defer maintenance, while communities face outage risk. Systems thinking asks who captures efficiency gains and who absorbs fragility costs.
The goal is not to reject efficiency. It is to distinguish healthy efficiency from brittle optimization. A resilient system can be efficient in ordinary conditions while preserving buffers, alternatives, visibility, and recovery capacity for abnormal conditions. This requires design, governance, and investment.
Redundancy, Diversity, and Modularity
Redundancy, diversity, and modularity are three major design principles for reducing cascade risk. Redundancy means having more than one way to perform a critical function. Diversity means alternatives are not all vulnerable to the same failure. Modularity means parts of the system can fail without bringing down the whole. These principles are often criticized as inefficient, but they are central to resilience.
Redundancy provides backup. A hospital may need backup power, oxygen supply, staffing pools, communication systems, and transport routes. A city may need multiple water sources, evacuation routes, cooling centers, and emergency communication channels. A supply chain may need alternative suppliers and inventory buffers. A digital system may need failover capacity and offline continuity plans. Redundancy is not waste when the function is essential.
Diversity prevents common-mode failure. Having multiple suppliers does not create resilience if all suppliers depend on the same rare component, same port, same cloud provider, same region, same labor conditions, or same fragile financing. Diversity means alternatives are genuinely different in geography, technology, governance, ownership, skill, or dependency structure.
Modularity limits spread. Firebreaks, grid segmentation, compartmentalized networks, local food systems, decentralized services, distributed energy, and organizational autonomy can prevent failures from cascading across the whole system. Modularity does not mean isolation. It means connection with boundaries that can absorb failure.
\text{Resilience} = f(\text{Redundancy}, \text{Diversity}, \text{Modularity}, \text{Monitoring}, \text{Recovery Capacity})
\]
Interpretation: Network resilience improves when systems have backup capacity, diverse alternatives, modular boundaries, monitoring, and recovery capacity.
| Design principle | What it does | Example |
|---|---|---|
| Redundancy | Provides backup capacity when one path fails. | Multiple suppliers, backup generators, alternative evacuation routes. |
| Diversity | Prevents all backups from failing for the same reason. | Different energy sources, supplier regions, communication channels, and institutions. |
| Modularity | Limits failure spread across the system. | Grid islands, cyber segmentation, neighborhood-scale resilience hubs. |
| Monitoring | Detects stress before failure cascades. | Infrastructure sensors, public-health surveillance, supply-chain visibility. |
| Recovery capacity | Restores function after disruption. | Repair crews, mutual aid, emergency funds, spare parts, trained personnel. |
Resilience design requires balancing connection and separation. Too little connection reduces coordination and access. Too much unmanaged connection increases cascade risk. The task is to design networks where critical flows can move, but failures can be detected, contained, rerouted, and repaired.
Infrastructure Interdependence
Infrastructure systems are deeply interdependent. Power systems depend on fuel, control systems, communications, water, maintenance workers, finance, roads, and cybersecurity. Water systems depend on electricity, pumps, chemicals, treatment plants, pipes, sensors, watersheds, and public trust. Transportation systems depend on roads, signals, fuel, electricity, maintenance, weather, bridges, finance, and land use. Healthcare systems depend on power, water, transport, staff, data, supply chains, pharmaceuticals, waste management, and communications.
This interdependence means infrastructure resilience cannot be evaluated one sector at a time. A water utility may have strong pipes but weak backup power. A hospital may have equipment but lack reliable supply chains. A transit system may have vehicles but depend on vulnerable power and communication systems. A city may have emergency plans that fail if cell networks, roads, or electricity are down.
Infrastructure interdependence also creates governance challenges. Different systems may be owned, funded, regulated, and managed by different institutions. A privately owned utility may be essential to public health. A regional transportation agency may depend on local land-use decisions. A state highway decision may affect local neighborhoods. A hospital may depend on global supply chains. Cascade risk crosses governance boundaries.
\text{Infrastructure Resilience} = \min(\text{Power}, \text{Water}, \text{Transport}, \text{Communication}, \text{Staffing}, \text{Governance})
\]
Interpretation: The resilience of an infrastructure-dependent service is often constrained by the weakest essential dependency, not by the strongest component.
Interdependent infrastructure requires shared risk mapping. Planners need to know which services depend on which assets, which dependencies are time-sensitive, which assets serve vulnerable populations, which failures can cascade, and which institutions have authority to act. This requires data-sharing, public accountability, emergency coordination, investment planning, and community knowledge.
Infrastructure systems thinking also asks whether infrastructure investment is reducing or increasing dependency risk. Electrification can reduce fossil fuel dependence, but it increases dependence on grid resilience. Digitalization can improve monitoring, but it increases cybersecurity and connectivity dependence. Centralization can improve efficiency, but it may concentrate failure. Distributed systems can increase resilience, but they require coordination and maintenance. The point is not to avoid change. It is to understand the dependency structure that change creates.
Supply Chains and Concentrated Dependency
Supply chains are networks of materials, firms, workers, logistics, finance, energy, water, data, standards, and demand. They connect extraction, production, transport, storage, distribution, retail, maintenance, and disposal. Supply chains create scale and specialization, but they also create dependency. A product that appears simple may depend on hundreds of suppliers, ports, warehouses, software systems, standards, and geopolitical conditions.
Concentrated dependency occurs when many actors depend on the same supplier, region, transport route, material, technology, or platform. Concentration can reduce cost and improve coordination, but it can also create systemic risk. If one supplier produces a specialized component for many industries, its failure can affect multiple sectors. If many firms depend on one cloud provider, outage or cyber risk becomes systemic. If food distribution depends on a small number of processors or logistics firms, disruption can spread widely.
Supply-chain fragility is often hidden by normal performance. When goods arrive on time, dependency is invisible. When disruption occurs, hidden concentration becomes visible. The problem is not merely that something failed. The problem is that the system lacked visibility, substitutes, inventory, flexibility, or governance to absorb the failure.
| Supply-chain risk | System mechanism | Resilience response |
|---|---|---|
| Single-source supplier | One provider controls a critical input. | Supplier diversification, strategic inventory, substitution planning. |
| Geographic concentration | Production is concentrated in one region exposed to shared hazard. | Regional diversification, stress testing, local or regional capacity. |
| Logistics bottleneck | Ports, rail junctions, roads, or warehouses concentrate flow. | Alternative routes, capacity planning, logistics transparency. |
| Digital dependency | Supply-chain coordination depends on shared software or platforms. | Cyber resilience, offline continuity, platform redundancy. |
| Labor vulnerability | Critical flows depend on workers facing unsafe or insecure conditions. | Labor protections, staffing resilience, fair wages, health safeguards. |
Supply-chain resilience also has ethical dimensions. Resilience cannot mean only securing inputs for powerful buyers while shifting risk to workers, communities, or poorer countries. A resilient supply chain should protect labor, communities, ecosystems, and public needs. It should not treat human vulnerability as an external cost.
Network thinking helps supply chains move beyond cost minimization toward responsible dependency design. It asks what is critical, what is concentrated, what is substitutable, what is visible, what is fair, and what must keep functioning during crisis.
Digital Platforms, Information, and Attention Cascades
Digital platforms are networked systems of users, algorithms, advertisers, moderators, creators, data pipelines, recommender systems, rules, incentives, and communities. Information does not simply move through them neutrally. Platform design shapes what is seen, shared, rewarded, monetized, hidden, removed, amplified, or contested. Attention becomes a network flow.
Information cascades occur when people make decisions based partly on what others appear to believe, share, or endorse. A claim can spread because it is emotionally powerful, socially rewarded, algorithmically boosted, or repeated by trusted nodes. The cascade can become self-reinforcing: visibility creates perceived credibility, perceived credibility increases sharing, sharing increases visibility. Corrections often move more slowly because they lack the same emotional, social, or algorithmic reinforcement.
Digital networks can strengthen public knowledge, mutual aid, organizing, education, and accountability. They can also amplify misinformation, harassment, polarization, reputational cascades, financial speculation, public-health confusion, and institutional distrust. The same connectivity that enables rapid coordination can enable rapid harm.
\text{Information Cascade} = f(\text{Visibility}, \text{Trust}, \text{Emotion}, \text{Network Structure}, \text{Algorithmic Amplification})
\]
Interpretation: Information cascades depend on visibility, trust, emotional salience, network pathways, and platform amplification systems.
Attention cascades are not only user behavior. They are shaped by platform business models. If engagement is rewarded, content that provokes reaction may gain advantage. If recommendation systems optimize watch time, sharing, or interaction, they may amplify content that captures attention regardless of public value. If moderation is reactive, harmful cascades may spread before intervention. If transparency is weak, outsiders may not see how the cascade formed.
Network systems thinking asks how platform structure distributes attention and risk. Which nodes are influential? Which communities are targeted? Which algorithms amplify which patterns? Which actors exploit network dynamics? Which groups are exposed to harassment or misinformation? Which safeguards slow harmful cascades without suppressing legitimate speech, organizing, or dissent?
Digital network governance requires more than content removal. It requires attention to incentives, amplification, friction, transparency, auditing, user rights, moderation labor, appeal mechanisms, data access, and public accountability. Information risk is a network design issue.
Financial, Public Health, and Institutional Networks
Financial systems are networked through debt, credit, liquidity, ownership, payment systems, expectations, insurance, collateral, and confidence. A shock can spread when institutions are exposed to one another, when asset sales reduce prices, when liquidity dries up, or when confidence collapses. Financial network risk is not only about individual balance sheets. It is about interconnection, opacity, leverage, and shared exposure.
Public health systems are networked through contact patterns, care systems, laboratories, supply chains, community trust, data reporting, communication channels, schools, workplaces, transportation, and households. Disease spreads through social networks, but response also spreads through institutional networks. Testing, vaccination, care, communication, paid leave, and trust all affect whether health risk cascades or is contained.
Institutional networks connect agencies, laws, budgets, data systems, contractors, communities, courts, schools, hospitals, utilities, and political authorities. Institutional failures can cascade when one agency’s delay creates burden elsewhere. A housing failure becomes a public-health burden. A public-health failure becomes a school and workforce burden. A court backlog becomes a housing, family, and labor-market burden. Fragmented institutions often shift risk rather than resolve it.
| Network type | What flows | Cascade risk |
|---|---|---|
| Financial network | Credit, liquidity, confidence, collateral, obligation | Distress spreads through exposure, leverage, and panic. |
| Public-health network | Disease, information, care, trust, supplies | Outbreaks, misinformation, care overload, and workforce stress spread. |
| Institutional network | Authority, funding, rules, data, referrals, obligations | Silo failure shifts burden across agencies and communities. |
| Community network | Care, trust, support, knowledge, warning signals | Isolation increases vulnerability; trusted bridges can interrupt harm. |
| Legal and regulatory network | Rules, enforcement, rights, responsibilities | Gaps or conflicts create accountability failures and hidden risk. |
These networks show that cascade risk is not only technical. It is social and institutional. A public-health intervention can fail if trust networks are weak. A financial regulation can fail if exposure is hidden. A welfare policy can fail if administrative networks create burden. A climate adaptation plan can fail if institutions cannot coordinate across housing, health, infrastructure, and emergency response.
Network resilience therefore requires public capacity, not just technical redundancy. It requires trusted relationships, accountable institutions, transparent data, legal clarity, community partnership, and the ability to coordinate under stress.
Governing Network Risk
Governing network risk requires seeing beyond individual assets or organizations. A system may appear safe when each component meets its own standard, but still be fragile because dependencies among components are poorly understood. Network governance asks how risk travels, who detects it, who has authority to act, who pays for resilience, and who is harmed when failure spreads.
Network governance often fails because responsibility is fragmented. One agency manages roads, another manages water, another manages emergency response, another regulates utilities, another handles public health, another manages housing, and private firms operate critical digital or logistics systems. Cascades cross these boundaries. Governance must therefore create shared maps, shared scenarios, shared exercises, and shared accountability.
Stress testing is essential. A network should be tested not only for routine performance, but for node loss, hub failure, supplier disruption, cyberattack, extreme weather, disease surge, communication failure, staffing shortage, and simultaneous shocks. Stress testing should include vulnerable communities, not only system averages. A city is not resilient if the system survives while certain neighborhoods lose power, water, housing, or care.
| Governance practice | Purpose | Network-risk question |
|---|---|---|
| Dependency mapping | Identify critical links and hidden dependencies. | What systems must function for this service to survive? |
| Stress testing | Test system behavior under disruption. | Which failures cascade, and how fast? |
| Redundancy planning | Create backup capacity and alternatives. | What routes, suppliers, people, or systems can substitute? |
| Modularity design | Limit failure spread. | Where can the system be segmented without losing essential coordination? |
| Public accountability | Ensure resilience burdens and benefits are fairly distributed. | Who is exposed, who pays, and who decides? |
| Learning systems | Preserve lessons from near misses and failures. | How does the system update after warning signs? |
Network governance should also treat near misses as valuable information. A near miss reveals a pathway that almost produced failure. If institutions ignore near misses because disaster was avoided, they lose learning. In complex networks, repeated near misses often signal that cascade risk is growing.
Strong network governance combines technical analysis with institutional responsibility. It maps dependencies, preserves buffers, funds maintenance, protects vulnerable nodes, creates alternatives, monitors stress, and builds the authority to act before failure spreads.
Ethics: Unequal Exposure, Hidden Dependency, and Shared Responsibility
Network risk is ethical because cascades do not affect everyone equally. People with resources often have backup options: generators, savings, insurance, remote work, private transport, alternative suppliers, political voice, or the ability to relocate. Vulnerable communities may have fewer alternatives and higher exposure to failure. When networks fail, inequality determines who absorbs the shock.
Hidden dependency can also hide responsibility. A platform may depend on moderation workers exposed to trauma. A city may depend on low-wage care workers who cannot afford housing near work. A hospital may depend on global supply chains and local public transit. A food system may depend on migrant labor, water extraction, fossil fuels, and logistics networks. Network maps often show technical dependency while hiding human dependency.
Ethical network analysis asks:
- Who depends on this network for survival, care, income, mobility, information, or rights?
- Who has backup options when the network fails?
- Who is treated as a peripheral node even though their vulnerability is high?
- Which workers, communities, ecosystems, or public systems absorb hidden risk?
- Who benefits from efficiency gains created by reduced buffers?
- Who pays when cascade risk becomes crisis?
- Who has authority to see, question, and redesign dependency structures?
- What near misses have affected marginalized communities before the system recognized a crisis?
- What obligations do private operators of public-essential networks have?
- How should resilience investments be distributed fairly?
Network ethics requires attention to both connection and power. A node may be central because it is powerful, but another node may be ethically central because many vulnerable people depend on it. A resilience plan that protects financial continuity while ignoring household survival is incomplete. A supply-chain plan that protects corporate buyers while ignoring workers is unjust. A smart infrastructure plan that improves system monitoring while increasing surveillance or exclusion is ethically fragile.
Responsible network design should protect essential functions, distribute resilience fairly, preserve public accountability, and make hidden dependencies visible before failure exposes them through harm.
Examples Across Networked Systems
Networks, dependencies, and cascade risk appear across infrastructure, supply chains, finance, public health, technology, ecology, and governance. The examples below show how connection can create both resilience and fragility.
Power grid failure
A grid failure can spread through water systems, hospitals, refrigeration, communications, transport, emergency response, and household safety. The power network is also a dependency platform for many other networks.
Supply-chain bottleneck
A port, supplier, semiconductor plant, warehouse, or logistics route can become a bottleneck. When flow concentrates through a limited node, disruption can spread across industries.
Public-health transmission
Disease spreads through contact networks, but response spreads through care networks, trust networks, laboratories, data systems, schools, workplaces, and public communication.
Digital platform cascade
A false claim or harmful trend can spread through recommendation systems, influencers, peer networks, and attention incentives before slower correction mechanisms respond.
Financial contagion
A liquidity shock can cascade through credit exposure, asset sales, confidence, payment systems, and institutional interdependence, turning local distress into systemic risk.
Urban transit hub disruption
A transit hub failure can affect commuting, school access, healthcare appointments, service workers, local business, traffic congestion, and emergency mobility.
Cloud provider outage
When many services depend on the same digital infrastructure, one outage can disrupt businesses, public agencies, payment systems, communications, and data access.
Ecosystem food web change
Loss of a keystone species or pollinator can propagate through predation, reproduction, vegetation, soil, water, and human livelihoods that depend on ecosystem function.
Across these examples, the central systems question is not only what failed, but how dependency structure allowed failure to spread and what design would have contained it.
Mathematics, Computation, and Modeling
Network systems can be modeled through graph theory, dependency matrices, centrality measures, flow models, cascade simulations, percolation models, robustness tests, agent-based models, infrastructure interdependency models, and scenario analysis. These tools help identify critical nodes, hidden dependencies, bottlenecks, redundancy gaps, and cascade pathways.
A basic network can be represented as:
G = (V, E)
\]
Interpretation: A graph \(G\) consists of nodes \(V\) and edges \(E\). Nodes may represent assets, organizations, people, systems, or places; edges represent relationships, flows, or dependencies.
An adjacency matrix can represent connections:
A_{ij} =
\begin{cases}
1, & \text{if node } i \text{ is connected to node } j \\
0, & \text{otherwise}
\end{cases}
\]
Interpretation: An adjacency matrix records whether nodes are connected. Weighted matrices can record strength, volume, capacity, cost, or dependency.
A dependency matrix can be represented as:
D_{ij} \in [0,1]
\]
Interpretation: \(D_{ij}\) measures how strongly node or system \(i\) depends on node or system \(j\), from no dependency to full dependency.
A simple cascade update rule can be represented as:
F_{i,t+1} =
\begin{cases}
1, & \sum_j D_{ij}F_{j,t} > \theta_i \\
F_{i,t}, & \text{otherwise}
\end{cases}
\]
Interpretation: Node \(i\) fails when dependency-weighted failures among connected nodes exceed its threshold \(\theta_i\).
A network resilience index can be represented conceptually as:
R_n = w_rR + w_dD + w_mM + w_bB + w_vV
\]
Interpretation: Network resilience can combine redundancy, diversity, modularity, buffering, and visibility using transparent weights.
| Modeling task | Network-risk question | Example output |
|---|---|---|
| Centrality analysis | Which nodes are most structurally important? | Degree, betweenness, closeness, and eigenvector centrality scores. |
| Dependency mapping | Which systems rely on which other systems? | Dependency matrix, critical dependency list, interdependency map. |
| Cascade simulation | How does failure spread after node loss? | Failed nodes over time, cascade depth, affected services. |
| Robustness testing | How does the network perform under random or targeted failure? | Connectivity loss, service loss, recovery time, fragility ranking. |
| Modularity analysis | Can the network contain failures within modules? | Cluster structure, bridge nodes, segmentation opportunities. |
| Equity-risk analysis | Who is most exposed when critical nodes fail? | Vulnerability-weighted service disruption and recovery gaps. |
Network models should be used with humility. They depend on what is included, what is excluded, how edges are defined, and how dependency strength is measured. A model may identify technical criticality while missing social vulnerability. It may map infrastructure while ignoring trust, labor, care, disability access, informal networks, or institutional legitimacy. A good network model should make assumptions visible and include affected communities, domain experts, and operational knowledge.
Python Workflow: Network Dependency, Bridge Nodes, and Cascade Risk Scenarios
The Python workflow for this article models a synthetic network of urban, institutional, infrastructure, digital, and supply-chain nodes. It uses only the Python standard library. The workflow calculates simple network centrality measures, identifies bridge-like nodes, simulates targeted and random failures, and exports cascade-risk summaries. It is designed as a professional scaffold for adapting network-risk thinking to infrastructure, public policy, supply chains, public health, and institutional systems.
# network_dependency_cascade_model.py
# Dependency-light professional workflow for network, dependency, and cascade-risk analysis.
# Purpose: model nodes, dependencies, bridge roles, failure propagation, and resilience diagnostics.
# Uses only Python standard library.
from dataclasses import dataclass
import csv
import os
import random
from collections import deque, defaultdict
from statistics import mean
OUTPUT_TABLES = "outputs/tables"
@dataclass
class NetworkNode:
node_id: str
category: str
capacity: float
threshold: float
vulnerability: float
recovery_capacity: float
def ensure_outputs() -> None:
os.makedirs(OUTPUT_TABLES, exist_ok=True)
def build_nodes() -> dict[str, NetworkNode]:
nodes = [
NetworkNode("power_grid", "infrastructure", 0.92, 0.55, 0.42, 0.70),
NetworkNode("water_utility", "infrastructure", 0.88, 0.50, 0.50, 0.62),
NetworkNode("hospital", "public_health", 0.82, 0.48, 0.72, 0.55),
NetworkNode("transit_hub", "transport", 0.78, 0.46, 0.60, 0.50),
NetworkNode("data_center", "digital", 0.86, 0.52, 0.45, 0.68),
NetworkNode("cloud_platform", "digital", 0.90, 0.58, 0.40, 0.72),
NetworkNode("food_distribution", "supply_chain", 0.80, 0.45, 0.68, 0.48),
NetworkNode("fuel_terminal", "supply_chain", 0.76, 0.44, 0.58, 0.46),
NetworkNode("emergency_services", "public_safety", 0.84, 0.50, 0.70, 0.60),
NetworkNode("telecom_network", "digital", 0.87, 0.50, 0.52, 0.64),
NetworkNode("community_clinic", "public_health", 0.70, 0.40, 0.78, 0.44),
NetworkNode("local_government", "institutional", 0.74, 0.42, 0.65, 0.54),
NetworkNode("school_network", "institutional", 0.72, 0.40, 0.62, 0.46),
NetworkNode("housing_services", "institutional", 0.68, 0.38, 0.75, 0.42),
NetworkNode("payment_system", "financial", 0.85, 0.50, 0.48, 0.66),
NetworkNode("regional_supplier", "supply_chain", 0.77, 0.43, 0.55, 0.50)
]
return {node.node_id: node for node in nodes}
def build_dependencies() -> dict[str, dict[str, float]]:
# A depends on B with weight w: dependencies[A][B] = w
return {
"water_utility": {"power_grid": 0.70, "telecom_network": 0.20},
"hospital": {"power_grid": 0.55, "water_utility": 0.35, "telecom_network": 0.30, "regional_supplier": 0.40},
"transit_hub": {"power_grid": 0.45, "telecom_network": 0.25, "fuel_terminal": 0.35},
"data_center": {"power_grid": 0.65, "telecom_network": 0.45, "water_utility": 0.15},
"cloud_platform": {"data_center": 0.65, "telecom_network": 0.45, "power_grid": 0.30},
"food_distribution": {"fuel_terminal": 0.55, "transit_hub": 0.25, "payment_system": 0.25, "regional_supplier": 0.40},
"fuel_terminal": {"power_grid": 0.35, "telecom_network": 0.20},
"emergency_services": {"power_grid": 0.35, "telecom_network": 0.55, "transit_hub": 0.25, "hospital": 0.25},
"telecom_network": {"power_grid": 0.60, "data_center": 0.25},
"community_clinic": {"power_grid": 0.30, "water_utility": 0.25, "hospital": 0.20, "telecom_network": 0.30},
"local_government": {"cloud_platform": 0.35, "telecom_network": 0.35, "payment_system": 0.20},
"school_network": {"power_grid": 0.25, "telecom_network": 0.25, "transit_hub": 0.30, "food_distribution": 0.20},
"housing_services": {"local_government": 0.35, "payment_system": 0.25, "telecom_network": 0.25},
"payment_system": {"cloud_platform": 0.40, "telecom_network": 0.30, "power_grid": 0.20},
"regional_supplier": {"fuel_terminal": 0.30, "payment_system": 0.25, "transit_hub": 0.20}
}
def reverse_dependencies(dependencies: dict[str, dict[str, float]]) -> dict[str, list[str]]:
reverse = defaultdict(list)
for dependent, providers in dependencies.items():
for provider in providers:
reverse[provider].append(dependent)
return dict(reverse)
def degree_scores(nodes: dict[str, NetworkNode], dependencies: dict[str, dict[str, float]]) -> dict[str, int]:
reverse = reverse_dependencies(dependencies)
scores = {}
for node_id in nodes:
outgoing = len(dependencies.get(node_id, {}))
incoming = len(reverse.get(node_id, []))
scores[node_id] = outgoing + incoming
return scores
def dependency_exposure_scores(nodes: dict[str, NetworkNode], dependencies: dict[str, dict[str, float]]) -> dict[str, float]:
reverse = reverse_dependencies(dependencies)
scores = {}
for node_id, node in nodes.items():
exposed_dependents = reverse.get(node_id, [])
exposure = 0.0
for dependent in exposed_dependents:
dependency_weight = dependencies[dependent][node_id]
exposure += dependency_weight * nodes[dependent].vulnerability
scores[node_id] = round(exposure, 4)
return scores
def shortest_path_count(nodes: dict[str, NetworkNode], dependencies: dict[str, dict[str, float]], source: str, target: str) -> int:
# Treat dependencies as undirected for bridge-style path approximation.
neighbors = defaultdict(set)
for a, providers in dependencies.items():
for b in providers:
neighbors[a].add(b)
neighbors[b].add(a)
visited = {source}
queue = deque([(source, 0)])
while queue:
current, distance = queue.popleft()
if current == target:
return distance
for neighbor in neighbors[current]:
if neighbor not in visited:
visited.add(neighbor)
queue.append((neighbor, distance + 1))
return 999
def bridge_approximation(nodes: dict[str, NetworkNode], dependencies: dict[str, dict[str, float]]) -> dict[str, float]:
node_ids = list(nodes.keys())
base_distances = {}
for i, source in enumerate(node_ids):
for target in node_ids[i + 1:]:
base_distances[(source, target)] = shortest_path_count(nodes, dependencies, source, target)
scores = {}
for removed in node_ids:
reduced_nodes = {k: v for k, v in nodes.items() if k != removed}
reduced_dependencies = {
dependent: {provider: weight for provider, weight in providers.items() if provider != removed}
for dependent, providers in dependencies.items()
if dependent != removed
}
disruption = 0
comparisons = 0
reduced_node_ids = list(reduced_nodes.keys())
for i, source in enumerate(reduced_node_ids):
for target in reduced_node_ids[i + 1:]:
old_distance = base_distances.get((source, target), base_distances.get((target, source), 999))
new_distance = shortest_path_count(reduced_nodes, reduced_dependencies, source, target)
if new_distance > old_distance:
disruption += min(new_distance, 20) - min(old_distance, 20)
comparisons += 1
scores[removed] = round(disruption / max(comparisons, 1), 4)
return scores
def simulate_cascade(
nodes: dict[str, NetworkNode],
dependencies: dict[str, dict[str, float]],
initial_failures: set[str],
max_steps: int = 8
) -> list[dict]:
failed = set(initial_failures)
rows = []
for step in range(max_steps + 1):
rows.append({
"step": step,
"failed_nodes": sorted(failed),
"failed_count": len(failed),
"service_loss_index": round(mean(nodes[node_id].vulnerability for node_id in failed), 4) if failed else 0.0
})
new_failures = set()
for node_id, node in nodes.items():
if node_id in failed:
continue
dependency_load = 0.0
for provider, weight in dependencies.get(node_id, {}).items():
if provider in failed:
dependency_load += weight
resilience_buffer = node.capacity * 0.20 + node.recovery_capacity * 0.15
adjusted_threshold = node.threshold + resilience_buffer
if dependency_load > adjusted_threshold:
new_failures.add(node_id)
if not new_failures:
break
failed.update(new_failures)
return rows
def scenario_initial_failures(nodes: dict[str, NetworkNode], mode: str, seed: int = 7) -> set[str]:
if mode == "targeted_power":
return {"power_grid"}
if mode == "targeted_cloud":
return {"cloud_platform"}
if mode == "targeted_transit":
return {"transit_hub"}
if mode == "targeted_supplier":
return {"regional_supplier"}
if mode == "random_two":
rng = random.Random(seed)
return set(rng.sample(list(nodes.keys()), 2))
return set()
def write_csv(path: str, rows: list[dict]) -> None:
if not rows:
return
flat_rows = []
for row in rows:
flat_row = dict(row)
if isinstance(flat_row.get("failed_nodes"), list):
flat_row["failed_nodes"] = ";".join(flat_row["failed_nodes"])
flat_rows.append(flat_row)
with open(path, "w", newline="", encoding="utf-8") as handle:
writer = csv.DictWriter(handle, fieldnames=list(flat_rows[0].keys()))
writer.writeheader()
writer.writerows(flat_rows)
def main() -> None:
ensure_outputs()
nodes = build_nodes()
dependencies = build_dependencies()
degree = degree_scores(nodes, dependencies)
exposure = dependency_exposure_scores(nodes, dependencies)
bridge = bridge_approximation(nodes, dependencies)
node_rows = []
for node_id, node in nodes.items():
node_rows.append({
"node_id": node_id,
"category": node.category,
"capacity": node.capacity,
"threshold": node.threshold,
"vulnerability": node.vulnerability,
"recovery_capacity": node.recovery_capacity,
"degree_score": degree[node_id],
"dependency_exposure_score": exposure[node_id],
"bridge_approximation_score": bridge[node_id],
"criticality_index": round(
degree[node_id] * 0.15
+ exposure[node_id] * 3.0
+ bridge[node_id] * 2.0
+ node.vulnerability * 0.60
- node.recovery_capacity * 0.30,
4
)
})
cascade_rows = []
scenario_modes = ["targeted_power", "targeted_cloud", "targeted_transit", "targeted_supplier", "random_two"]
for mode in scenario_modes:
initial = scenario_initial_failures(nodes, mode)
scenario_rows = simulate_cascade(nodes, dependencies, initial)
for row in scenario_rows:
row["scenario"] = mode
row["initial_failures"] = ";".join(sorted(initial))
cascade_rows.append(row)
summary_rows = []
for mode in scenario_modes:
subset = [row for row in cascade_rows if row["scenario"] == mode]
final = subset[-1]
summary_rows.append({
"scenario": mode,
"initial_failures": final["initial_failures"],
"final_failed_count": final["failed_count"],
"final_service_loss_index": final["service_loss_index"],
"cascade_depth": final["step"],
"diagnostic": (
"high cascade risk" if final["failed_count"] >= 8 else
"moderate cascade risk" if final["failed_count"] >= 4 else
"contained disruption"
)
})
write_csv(os.path.join(OUTPUT_TABLES, "network_node_criticality.csv"), node_rows)
write_csv(os.path.join(OUTPUT_TABLES, "network_cascade_timeseries.csv"), cascade_rows)
write_csv(os.path.join(OUTPUT_TABLES, "network_cascade_summary.csv"), summary_rows)
with open(os.path.join(OUTPUT_TABLES, "validation_report.txt"), "w", encoding="utf-8") as handle:
handle.write("Validation passed.\n")
handle.write("Network node scores, cascade simulations, and summary outputs completed.\n")
print("\nNetwork cascade summary:")
for row in summary_rows:
print(
f"{row['scenario']}: final failed nodes={row['final_failed_count']}, "
f"cascade depth={row['cascade_depth']}, diagnostic={row['diagnostic']}"
)
if __name__ == "__main__":
main()This workflow demonstrates how dependency structure changes system behavior. A targeted failure of a highly connected infrastructure node can produce wider disruption than a random failure. A bridge-like node may matter more than its size suggests. Nodes with high vulnerability and low recovery capacity can increase social risk even when their technical degree is modest. The model is intentionally simplified, but it provides a useful scaffold for professional network-risk thinking.
A fuller repository version can add optional pandas and matplotlib workflows for richer network tables, Excel workbooks, dependency heatmaps, node rankings, cascade plots, and stress-test scenarios while preserving this standard-library script as the default smoke-tested workflow.
R Workflow: Network Indicators, Cascade Tables, and Resilience Visualization
The R workflow for this article uses base R so it can run without additional package dependencies. It reads Python-generated network outputs, creates diagnostic summaries, and produces plots for node criticality, dependency exposure, cascade depth, failed-node counts, and service-loss trajectories.
# network_dependency_cascade_diagnostics.R
# Base R network and cascade-risk workflow.
# Purpose: summarize dependency network outputs and visualize cascade-risk indicators.
tables_dir <- "outputs/tables"
figures_dir <- "outputs/figures"
if (!dir.exists(figures_dir)) {
dir.create(figures_dir, recursive = TRUE)
}
criticality_path <- file.path(tables_dir, "network_node_criticality.csv")
cascade_path <- file.path(tables_dir, "network_cascade_timeseries.csv")
summary_path <- file.path(tables_dir, "network_cascade_summary.csv")
if (!file.exists(criticality_path)) {
stop("Missing network_node_criticality.csv. Run the Python workflow first.")
}
if (!file.exists(cascade_path)) {
stop("Missing network_cascade_timeseries.csv. Run the Python workflow first.")
}
nodes <- read.csv(criticality_path, stringsAsFactors = FALSE)
cascade <- read.csv(cascade_path, stringsAsFactors = FALSE)
node_rank <- nodes[order(-nodes$criticality_index), ]
write.csv(
node_rank,
file.path(tables_dir, "network_node_criticality_ranked.csv"),
row.names = FALSE
)
last_by_scenario <- do.call(
rbind,
lapply(split(cascade, cascade$scenario), function(df) df[nrow(df), ])
)
last_by_scenario$diagnostic <- ifelse(
last_by_scenario$failed_count >= 8,
"high cascade risk",
ifelse(
last_by_scenario$failed_count >= 4,
"moderate cascade risk",
"contained disruption"
)
)
write.csv(last_by_scenario, summary_path, row.names = FALSE)
print(last_by_scenario)
png(file.path(figures_dir, "network_node_criticality_rank.png"), width = 1200, height = 700)
barplot(
height = node_rank$criticality_index,
names.arg = node_rank$node_id,
las = 2,
cex.names = 0.75,
main = "Network Node Criticality",
ylab = "Criticality index"
)
grid()
dev.off()
png(file.path(figures_dir, "dependency_exposure_rank.png"), width = 1200, height = 700)
exposure_rank <- nodes[order(-nodes$dependency_exposure_score), ]
barplot(
height = exposure_rank$dependency_exposure_score,
names.arg = exposure_rank$node_id,
las = 2,
cex.names = 0.75,
main = "Dependency Exposure by Node",
ylab = "Dependency exposure score"
)
grid()
dev.off()
plot_metric <- function(metric, y_label, title, output_name) {
png(file.path(figures_dir, output_name), width = 1200, height = 700)
scenarios <- unique(cascade$scenario)
plot(
NA,
xlim = range(cascade$step),
ylim = range(cascade[[metric]], na.rm = TRUE),
xlab = "Cascade step",
ylab = y_label,
main = title
)
for (scenario_name in scenarios) {
subset_data <- cascade[cascade$scenario == scenario_name, ]
lines(subset_data$step, subset_data[[metric]], lwd = 2)
}
legend("topleft", legend = scenarios, lwd = 2, cex = 0.8, bty = "n")
grid()
dev.off()
}
plot_metric(
metric = "failed_count",
y_label = "Failed node count",
title = "Cascade Failure Count by Scenario",
output_name = "cascade_failed_count_trajectories.png"
)
plot_metric(
metric = "service_loss_index",
y_label = "Service loss index",
title = "Service Loss by Cascade Scenario",
output_name = "cascade_service_loss_trajectories.png"
)
category_summary <- aggregate(
cbind(criticality_index, dependency_exposure_score, bridge_approximation_score) ~ category,
data = nodes,
FUN = mean
)
write.csv(
category_summary,
file.path(tables_dir, "network_category_risk_summary.csv"),
row.names = FALSE
)
print(category_summary)This R workflow helps interpret network risk as both node-level structure and system-level behavior. It ranks critical nodes, summarizes dependency exposure, identifies categories with higher average risk, and visualizes cascade growth across scenarios. The default version is portable and dependency-light, making it suitable for smoke testing and reuse in constrained environments.
A fuller version can add package-based network graphs, heatmaps, community detection, centrality comparisons, geographic overlays, and dashboard exports through an optional advanced analysis environment. The base R workflow remains the stable reproducible layer.
GitHub Repository
The companion repository for this article should help readers model networks, dependencies, bridge nodes, critical infrastructure interdependence, supply-chain concentration, digital platform cascades, service disruption, and resilience strategies using synthetic datasets and reproducible workflows.
articles/networks-dependencies-and-cascade-risk/
├── python/
│ ├── network_dependency_cascade_model.py
│ ├── node_criticality_diagnostics.py
│ ├── bridge_node_analysis.py
│ ├── cascade_scenario_model.py
│ ├── infrastructure_interdependence_model.py
│ ├── dependency_matrix_export.py
│ └── export_network_outputs.py
├── r/
│ ├── network_dependency_cascade_diagnostics.R
│ ├── node_criticality_visualization.R
│ ├── cascade_summary_tables.R
│ ├── dependency_exposure_plots.R
│ ├── network_category_risk_summary.R
│ └── export_network_tables.R
├── julia/
│ ├── nonlinear_cascade_dynamics.jl
│ ├── dependency_threshold_model.jl
│ └── network_resilience_sensitivity.jl
├── sql/
│ ├── schema_nodes.sql
│ ├── schema_edges.sql
│ ├── schema_dependencies.sql
│ ├── schema_cascade_scenarios.sql
│ ├── schema_failure_events.sql
│ ├── schema_resilience_indicators.sql
│ ├── schema_model_runs.sql
│ └── schema_outputs.sql
├── rust/
│ └── network_cascade_validator.rs
├── go/
│ └── network_cascade_runner.go
├── cpp/
│ ├── efficient_cascade_scan.cpp
│ └── bridge_node_solver.cpp
├── fortran/
│ └── recurrence_cascade_model.f90
├── c/
│ └── low_level_network_cascade_kernel.c
├── docs/
│ ├── modeling_principles.md
│ ├── article_notes.md
│ ├── network_dependency_framework.md
│ ├── cascade_risk_guide.md
│ ├── infrastructure_interdependence_notes.md
│ ├── python_workflow.md
│ ├── r_workflow.md
│ ├── diagnostic_questions.md
│ ├── ethics_and_network_responsibility.md
│ ├── assumptions_and_limitations.md
│ └── responsible_use.md
├── data/
│ ├── synthetic_nodes.csv
│ ├── synthetic_edges.csv
│ ├── synthetic_dependencies.csv
│ ├── synthetic_cascade_scenarios.csv
│ ├── synthetic_failure_events.csv
│ ├── synthetic_resilience_indicators.csv
│ ├── synthetic_model_runs.csv
│ └── synthetic_outputs.csv
├── outputs/
│ ├── README.md
│ ├── figures/
│ └── tables/
└── notebooks/
├── python_network_cascade_walkthrough.ipynb
└── r_network_diagnostics_visualization_placeholder.ipynbThis repository structure supports the article’s central argument: networked systems should be analyzed through dependency, criticality, bridge roles, cascading failure, resilience design, and distributional vulnerability. The python/ folder supports dependency-light simulation and diagnostics. The r/ folder supports visualization and interpretive summaries. The julia folder supports nonlinear cascade dynamics. The sql folder defines schemas for network and cascade-risk data. The lower-level language folders provide scaffolds for cascade scanning, bridge-node solving, recurrence modeling, and low-level network simulation.
A Practical Method for Network and Cascade-Risk Diagnosis
Network and cascade-risk diagnosis requires moving from individual components to dependency structure. The method below can support infrastructure planning, public-health preparedness, supply-chain resilience, digital governance, institutional coordination, climate adaptation, and risk management.
1. Define the network boundary
Clarify whether the network includes infrastructure assets, suppliers, institutions, people, data systems, financial obligations, ecological relationships, or multiple connected systems.
2. Identify nodes and edges
List key components and relationships. Define whether edges represent flow, dependency, communication, authority, trust, transport, finance, data, infection, or influence.
3. Measure dependency direction and strength
Ask which nodes depend on which others, how strongly, how quickly failure would matter, and whether dependency is direct or indirect.
4. Identify hubs, bridges, and bottlenecks
Find nodes with high connectivity, high flow, high bridge value, limited capacity, or few substitutes.
5. Map hidden dependencies
Look for dependence on electricity, water, labor, software, cloud platforms, suppliers, data standards, public trust, transport routes, and regulatory approvals.
6. Simulate failure scenarios
Test random failure, targeted hub failure, bridge-node loss, simultaneous shocks, cyber disruption, extreme weather, staffing shortage, and supply interruption.
7. Evaluate redundancy and diversity
Ask whether backups exist, whether backups are genuinely different, and whether alternatives can handle stress when primary nodes fail.
8. Assess modularity and containment
Identify whether failure can be isolated, segmented, rerouted, or contained before it spreads across the system.
9. Analyze distributional exposure
Ask which communities, workers, households, patients, firms, ecosystems, or public services are most exposed when the network fails.
10. Build monitoring, accountability, and learning
Create early-warning indicators, near-miss review, stress tests, public reporting, emergency protocols, and authority to redesign dependency structures.
Common Pitfalls
Network thinking can fail when connection is treated as automatically beneficial or when technical maps hide social vulnerability. Several patterns are especially common.
- Equating connectivity with resilience: more connection can improve coordination, but it can also spread failure faster.
- Ignoring dependency direction: networks are not always symmetrical; one system may depend heavily on another without reciprocal dependence.
- Focusing only on hubs: smaller bridge nodes, bottlenecks, or peripheral critical services may matter more than their size suggests.
- Counting backups without testing diversity: multiple backups do not help if they all depend on the same supplier, platform, route, or power source.
- Optimizing away buffers: lean systems may perform well normally while losing the slack needed to absorb disruption.
- Mapping infrastructure but not people: workers, households, care networks, disability access, and community trust are part of real network resilience.
- Ignoring near misses: near misses reveal cascade pathways before full failure occurs and should be treated as learning signals.
- Separating technical risk from governance: cascade risk crosses ownership, jurisdiction, institutional, and public-private boundaries.
The deeper mistake is treating networks as neutral diagrams rather than living structures of dependency, power, exposure, responsibility, and possible failure propagation.
Why Network Risk Requires Systems Thinking
Network risk requires systems thinking because failures rarely stay where they begin. Modern systems are built through connection. Electricity supports water, healthcare, communications, transport, refrigeration, and data. Supply chains support food, medicine, infrastructure, technology, and public services. Digital networks support finance, government, education, work, communication, and care. Social networks support trust, disease transmission, information, mutual aid, and political mobilization. Institutions depend on one another across boundaries that are often invisible until crisis.
Network thinking reveals that resilience is not only component strength. A strong node can still fail if it depends on weak links. A redundant system can still fail if backups share the same vulnerability. A highly connected network can still be fragile if failure spreads faster than detection and response. A technically efficient system can still be unjust if vulnerable people lack alternatives when networks fail.
Systems thinking changes the question from “What failed?” to “How did failure travel?” It asks what dependencies transmitted stress, what buffers were missing, what bridge nodes mattered, what alternatives failed, what governance boundaries slowed response, and who absorbed the harm. It asks whether systems are designed to contain failure or amplify it.
A responsible networked society needs more than speed, efficiency, and connection. It needs visibility, redundancy, diversity, modularity, maintenance, accountability, and public capacity. It needs institutions that can see hidden dependencies, learn from near misses, protect vulnerable nodes, and redesign networks before cascade risk becomes catastrophe. Networks make collective life possible. Systems thinking helps ensure they do not also make collective failure inevitable.
Related Articles
- What Is Systems Thinking?
- Emergence, Adaptation, and Complexity
- Resilience, Thresholds, and Regime Shifts
- Urban Systems: Congestion, Housing, and Infrastructure
- Climate Systems and Feedback Dynamics
- Public Health as a System
- Systems Thinking in AI and Technology
- Intelligent Infrastructure as a System
Further Reading
- Barabási, Albert-László. Linked: The New Science of Networks. Basic Books.
- Newman, Mark. Networks. Oxford University Press.
- Watts, Duncan J. Six Degrees: The Science of a Connected Age. W.W. Norton.
- Helbing, Dirk. “Globally Networked Risks and How to Respond.” Nature.
- Buldyrev, Sergey V. et al. “Catastrophic Cascade of Failures in Interdependent Networks.” Nature.
- Perrow, Charles. Normal Accidents: Living with High-Risk Technologies. Princeton University Press.
- Hollnagel, Erik, Woods, David D. and Leveson, Nancy. Resilience Engineering: Concepts and Precepts. Ashgate.
- Meadows, Donella H. Thinking in Systems: A Primer. Chelsea Green Publishing.
- Sterman, John D. Business Dynamics: Systems Thinking and Modeling for a Complex World. Irwin/McGraw-Hill.
- National Academies of Sciences, Engineering, and Medicine. Critical Infrastructure Resilience and the Cybersecurity Mission.
References
- Barabási, A.-L. (2002) Linked: The New Science of Networks. New York: Basic Books.
- Buldyrev, S.V. et al. (2010) “Catastrophic Cascade of Failures in Interdependent Networks.” Nature, 464, pp. 1025–1028. Available at: https://doi.org/10.1038/nature08932
- Helbing, D. (2013) “Globally Networked Risks and How to Respond.” Nature, 497, pp. 51–59. Available at: https://doi.org/10.1038/nature12047
- Hollnagel, E., Woods, D.D. and Leveson, N. (eds.) (2006) Resilience Engineering: Concepts and Precepts. Aldershot: Ashgate.
- Meadows, D.H. (2008) Thinking in Systems: A Primer. White River Junction, VT: Chelsea Green Publishing. Available at: https://www.chelseagreen.com/product/thinking-in-systems/
- Newman, M. (2018) Networks. 2nd edn. Oxford: Oxford University Press. Available at: https://global.oup.com/academic/product/networks-9780198805090
- Perrow, C. (1999) Normal Accidents: Living with High-Risk Technologies. Princeton, NJ: Princeton University Press.
- Sterman, J.D. (2000) Business Dynamics: Systems Thinking and Modeling for a Complex World. Boston: Irwin/McGraw-Hill.
- Watts, D.J. (2003) Six Degrees: The Science of a Connected Age. New York: W.W. Norton.
- Watts, D.J. and Strogatz, S.H. (1998) “Collective Dynamics of ‘Small-World’ Networks.” Nature, 393, pp. 440–442. Available at: https://doi.org/10.1038/30918