
Last Updated May 14, 2026
Infrastructure monitoring and sensor integration are the systems through which physical infrastructure is rendered observable, measurable, interpretable, and operationally actionable through distributed sensing, communication networks, data integration, analytical review, and governance response. They allow infrastructure institutions to detect changing conditions, identify faults and anomalies, assess performance, evaluate risk, and support more timely intervention across energy systems, transportation networks, water and wastewater systems, buildings, environmental systems, public works, and cyber-physical infrastructure.
Modern infrastructure increasingly depends on observability. Physical systems cannot be managed effectively at scale if their condition is known only through delayed inspection, fragmented reporting, or reactive failure. Monitoring systems address this problem by converting physical conditions into measurable signals. Sensors observe flow, temperature, pressure, vibration, voltage, occupancy, emissions, structural strain, equipment status, water quality, air quality, traffic behavior, and many other variables. Communications networks transmit those signals. Data systems integrate them with operational context. Analytical processes transform raw measurements into usable awareness. Monitoring is therefore not a peripheral technical add-on; it is one of the main mechanisms through which infrastructure becomes governable under contemporary conditions of complexity, interdependence, uncertainty, and risk.
This article develops Infrastructure Monitoring and Sensor Integration: Observability and Resilience as an advanced article within the Intelligent Infrastructure Systems knowledge series. It examines monitoring not as isolated instrumentation, but as a cyber-physical observability system involving sensing, calibration, telemetry, metadata, integration, platform architecture, analytics, risk detection, blind-spot analysis, operational response, cybersecurity, institutional capacity, and public accountability. Selected Python and R examples appear here, while the companion GitHub repository can support reproducible workflows for sensor inventories, telemetry records, calibration review, observability scoring, data-quality review, sensor-health checks, SQL-backed monitoring evidence archives, embedded edge-node validation, hardware stream checks, and multi-language systems-engineering scaffolds.
Main Library
Publications
Article Map
Intelligent Infrastructure
Related Article Map
Data Systems
Related Article Map
Embedded & Edge
Related Article Map
Environmental Monitoring
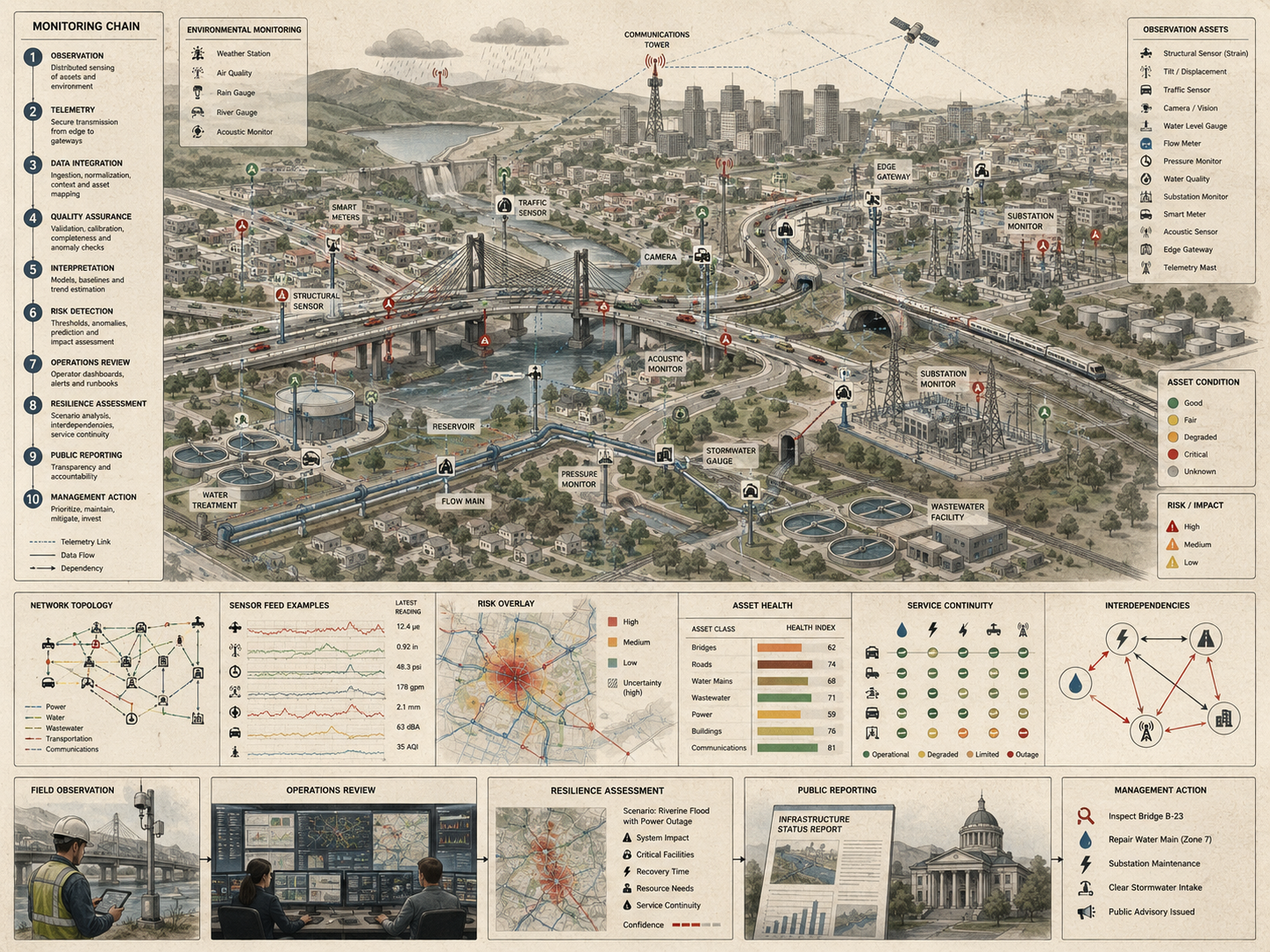
Sensor integration is equally important because infrastructure rarely operates as a collection of isolated devices. Individual sensors only become valuable at system level when their outputs are coordinated, contextualized, validated, secured, and connected to decision processes. A standalone sensor may provide a local reading. An integrated monitoring architecture can support diagnosis, comparison, trend analysis, event detection, predictive maintenance, emergency response, cross-system visibility, and institutional learning. What matters is not data collection in the abstract, but the ability to transform distributed measurements into reliable operational knowledge.
For this reason, infrastructure monitoring and sensor integration sit at the intersection of cyber-physical systems, data systems, embedded and edge systems, control systems, environmental monitoring, security architecture, and governance. Monitoring shapes what operators can see, how quickly they can respond, and how effectively they can distinguish routine variation from meaningful degradation or emerging disruption. It also shapes what remains hidden. The design of monitoring systems therefore has direct implications for resilience, maintenance, accountability, public safety, environmental stewardship, and the distribution of institutional attention across infrastructure systems.
Engineering Problem
The engineering problem is how to convert distributed, noisy, incomplete, heterogeneous, security-sensitive, and context-dependent measurements into trustworthy operational awareness. Infrastructure systems generate signals from physical assets, embedded devices, control systems, meters, cameras, mobile platforms, environmental stations, inspection workflows, and manual reporting channels. These signals may differ in frequency, accuracy, latency, calibration status, unit, ownership, communication pathway, cybersecurity posture, and decision relevance. Monitoring becomes useful only when these signals can be validated, integrated, interpreted, and connected to action.
This problem is difficult because infrastructure monitoring spans both physical and informational uncertainty. A sensor may measure a real condition incorrectly because of drift, fouling, misplacement, damage, poor calibration, or local interference. A communication path may delay or drop the signal. A platform may store the value without enough metadata to interpret it. An alert may fire without a clear response owner. A dashboard may look current while relying on stale readings. A monitoring system may cover highly instrumented assets while leaving vulnerable or marginalized service areas comparatively opaque. In short, measurement alone does not create observability.
A strong monitoring architecture must therefore solve more than instrumentation. It must define what conditions matter, where sensors should be placed, how often measurements are needed, how readings are calibrated, how metadata is preserved, how telemetry is secured, how data quality is assessed, how blind spots are identified, how alerts are prioritized, how field inspection validates digital signals, and how institutional workflows translate monitoring evidence into maintenance, operations, emergency response, investment, public communication, or policy action.
| Engineering Tension | Why It Matters | Required Evidence |
|---|---|---|
| Signal availability versus signal meaning | More sensor readings do not improve infrastructure knowledge unless the readings are contextualized by asset, location, unit, time, threshold, and valid use. | Sensor inventory, metadata dictionary, asset registry, unit register, threshold file |
| Sensor coverage versus blind spots | Monitoring systems often make some assets highly visible while leaving other zones, assets, or communities poorly observed. | Coverage map, service-zone inventory, unmonitored asset register, gap analysis |
| Real-time telemetry versus operational trust | Near-real-time data can still mislead if readings are delayed, uncalibrated, drifting, spoofed, duplicated, or detached from field reality. | Calibration records, latency logs, quality flags, validation reports, field inspection records |
| Integration versus fragmentation | Sensors may be spread across vendors, departments, communications protocols, operational systems, and data platforms. | Interface register, protocol map, data pipeline manifest, source-system inventory |
| Automated detection versus responsible response | Alerts and anomaly scores create value only when linked to inspection, dispatch, maintenance, incident response, or planning authority. | Response protocol, work-order link, escalation matrix, governance action log |
| Observability versus cyber-physical exposure | Monitoring systems expand visibility but can introduce new attack surfaces, data sensitivity, and operational dependency. | Access-control review, device inventory, network segmentation, telemetry integrity checks, incident response plan |
The practical question is therefore: can the monitoring system convert distributed measurements into evidence that is accurate enough to trust, integrated enough to interpret, secure enough to govern, and actionable enough to improve infrastructure resilience?
Reference Architecture
A practical reference architecture for infrastructure monitoring links sensors, embedded devices, communications, data integration, calibration, analytics, governance, cybersecurity, and operational response. The architecture should not begin with a dashboard. It should begin with the infrastructure responsibilities the monitoring system is meant to support: service continuity, safety, environmental quality, asset stewardship, risk detection, operational control, maintenance prioritization, emergency response, resilience planning, and public accountability.
| Layer | Engineering Role | Primary Risk | Evidence Artifact |
|---|---|---|---|
| Monitoring objective layer | Defines what conditions should be observed, why they matter, what decisions they support, and what uses are prohibited. | Sensors are deployed without a clear operational, resilience, or public-accountability purpose. | Monitoring objective manifest, decision-use register, valid-use policy |
| Physical asset and environment layer | Documents assets, facilities, systems, service zones, environmental contexts, and physical conditions being monitored. | Measurements cannot be interpreted in asset, network, service, or environmental context. | Asset registry, service-zone map, topology map, environmental context file |
| Sensing and instrumentation layer | Captures measurements through sensors, meters, cameras, gauges, embedded devices, inspection tools, and remote instruments. | Readings are inaccurate, poorly placed, uncalibrated, or unrepresentative of the system condition. | Sensor inventory, calibration log, placement rationale, maintenance record |
| Telemetry and communications layer | Moves measurements through wired, wireless, cellular, fiber, satellite, industrial, or edge networks. | Signals are delayed, lost, duplicated, insecure, or unavailable during disruptions. | Latency log, communications architecture, message queue status, continuity report |
| Integration and context layer | Links readings to asset identity, location, unit, timestamp, quality flag, threshold, owner, and valid decision use. | Data remains fragmented and difficult to compare across assets, zones, vendors, and systems. | Metadata dictionary, schema registry, entity-resolution table, source-system map |
| Analytics and interpretation layer | Supports threshold alerts, anomaly detection, trend analysis, state estimation, condition assessment, forecasting, and scenario review. | Analytics become overconfident or misleading because assumptions, inputs, limits, or validation status are unclear. | Model card, metric definition file, validation report, analytical notebook |
| Response and governance layer | Connects monitoring outputs to inspection, dispatch, maintenance, incident response, public communication, planning, and accountability. | Monitoring produces awareness without institutional action or public explanation. | Response log, work-order link, governance register, public evidence package |
This architecture makes clear that infrastructure monitoring is not simply the addition of sensors. It is a cyber-physical observability system that translates physical conditions into evidence, and evidence into responsible institutional response.
Implementation Pattern
A rigorous implementation pattern begins with the monitoring question rather than the sensor. A utility, transport agency, public works department, facility owner, environmental agency, infrastructure operator, or resilience office should first identify whether the monitoring need concerns failure detection, degradation, water quality, pressure loss, power quality, congestion, structural stress, air quality, flood exposure, equipment condition, cyber-physical visibility, or service continuity. Only then should the design specify what must be sensed, where it must be sensed, how frequently measurements are required, what accuracy is needed, what latency is acceptable, how calibration will be maintained, and which institutional workflow will respond.
| Artifact | Purpose | Suggested Format |
|---|---|---|
| Monitoring objective manifest | Defines monitoring purpose, decision uses, valid-use limits, public-service goals, and responsible owners. | YAML, Markdown, architecture decision record |
| Sensor inventory | Documents sensor type, asset, location, unit, sampling frequency, communication path, owner, calibration status, and criticality. | CSV, SQL table, asset-management export |
| Asset and service-zone registry | Links sensors to physical assets, service areas, network topology, environmental context, and operating responsibility. | CSV, SQL table, GIS-linked registry, topology file |
| Telemetry record | Stores timestamped readings, units, latency, quality flags, sensor health, and ingestion status. | CSV, time-series table, event stream export, historian extract |
| Calibration and validation log | Tracks calibration date, drift status, field verification, maintenance, sensor replacement, and validation confidence. | CSV, SQL table, maintenance export, inspection record |
| Observability and coverage review | Assesses sensor coverage, blind spots, latency, reliability, calibration, metadata completeness, and monitoring gaps. | Notebook, CSV, SQL view, geospatial layer |
| Alert and response register | Connects readings, thresholds, anomalies, and risk scores to inspection, dispatch, maintenance, incident response, or planning. | CSV, SQL table, work-order export, governance log |
The implementation goal is to make monitoring claims reconstructable. A reader should be able to move from an alert, anomaly, dashboard indicator, risk score, or resilience metric back to the sensor, asset, timestamp, unit, calibration status, metadata, threshold, data-quality flag, validation record, and institutional action that support it.
Research-Grade Framing: Monitoring as Infrastructure Observability
A research-grade account of infrastructure monitoring begins by treating monitoring as observability rather than instrumentation. Instrumentation means placing devices in the world. Observability means creating the conditions under which a complex system can be understood from the signals it produces. This distinction matters because infrastructure systems are dynamic, distributed, interdependent, and often partially hidden. Pipes run underground. Grid stress moves across networks. Transportation bottlenecks emerge across time and space. Structural deterioration can develop slowly. Environmental conditions can shift before institutions notice. Monitoring is the bridge between physical change and institutional awareness.
This framing also foregrounds power and responsibility. Monitoring systems shape what institutions can see, which assets become legible, which risks are prioritized, which communities receive attention, and which failures become explainable. Sensor placement, sampling frequency, calibration practices, metadata rules, alert thresholds, platform access, and response authority are not neutral details. They determine whether monitoring supports public stewardship or produces a partial and uneven view of infrastructure condition.
Mature monitoring systems therefore make uncertainty visible. They do not treat sensor readings as self-evident truth. They document calibration status, drift, missingness, latency, coverage gaps, sensor health, false positives, false negatives, environmental interference, cyber-physical exposure, and field validation. They combine digital telemetry with inspection, engineering judgment, institutional memory, and community-facing accountability. The goal is not sensor density for its own sake, but trustworthy observability connected to responsible action.
| Limited Pattern | Stronger Pattern | Why the Shift Matters |
|---|---|---|
| Deploy more sensors | Build governed observability systems linked to assets, context, quality, and response | Sensor density alone does not produce operational knowledge. |
| Monitor isolated readings | Integrate signals across systems, zones, assets, time, and decision contexts | Infrastructure risk often emerges from relationships among systems. |
| Show dashboards | Preserve calibration, uncertainty, lineage, thresholds, and action pathways | Visual clarity can conceal weak evidence if quality and context are hidden. |
| Automate alerts | Connect alerts to validation, field response, escalation, and governance closure | Detection has little value without accountable response. |
| Assume measured systems are understood | Map blind spots, unmonitored assets, sensor drift, and institutional limits | Observability must include what remains unseen. |
The central research question is therefore: how can monitoring systems strengthen infrastructure observability, resilience, safety, and public accountability without creating false confidence, hidden blind spots, fragile digital dependencies, or unequal visibility across systems and communities?
Formal Model: Sensor Coverage, Signal Quality, Observability, and Resilience
A useful formal model separates sensor coverage, signal quality, calibration confidence, telemetry reliability, metadata completeness, monitoring observability, and resilience contribution. Let \(C_s\) represent sensor coverage, \(Q_s\) signal quality, \(K_c\) calibration confidence, \(T_r\) telemetry reliability, \(M_c\) metadata completeness, \(O_m\) monitoring observability, and \(R_m\) monitoring-enabled resilience.
C_s =
\frac{N_{\mathrm{monitored\ critical\ assets}}}{N_{\mathrm{critical\ assets}}}
\]
Interpretation: Sensor coverage measures the share of critical assets, zones, or conditions that are actually monitored. It should be evaluated by service importance, not only by raw device count.
Q_s =
w_1 A_{\mathrm{accuracy}} +
w_2 P_{\mathrm{precision}} +
w_3 C_{\mathrm{completeness}} +
w_4 V_{\mathrm{validity}} +
w_5 F_{\mathrm{freshness}}
\]
Interpretation: Signal quality depends on accuracy, precision, completeness, validity, and freshness. Weights should reflect the decision context and measurement domain.
K_c =
\exp(-\lambda \Delta t_{\mathrm{since\ calibration}})
\]
Interpretation: Calibration confidence can decay as time since calibration increases. The decay rate should reflect sensor type, operating environment, and failure consequence.
T_r =
1 –
\frac{N_{\mathrm{missing}} + N_{\mathrm{late}} + N_{\mathrm{invalid}}}{N_{\mathrm{expected}}}
\]
Interpretation: Telemetry reliability weakens when expected readings are missing, late, or invalid.
O_m =
\alpha C_s +
\beta Q_s +
\gamma K_c +
\delta T_r +
\theta M_c –
\eta B_g
\]
Interpretation: Monitoring observability improves with coverage, signal quality, calibration confidence, telemetry reliability, and metadata completeness, and weakens when blind spots grow.
R_m =
\lambda_1 O_m +
\lambda_2 A_{\mathrm{action}} +
\lambda_3 B_{\mathrm{backup}} +
\lambda_4 V_{\mathrm{validation}} –
\lambda_5 E_{\mathrm{exposure}}
\]
Interpretation: Monitoring-enabled resilience rises with observability, action linkage, backup capability, and validation, while cyber, physical, organizational, and blind-spot exposure reduce resilience.
This formal structure protects against a common mistake: treating monitoring as device presence. A monitoring system is stronger when coverage, signal quality, calibration, telemetry reliability, metadata, validation, and response pathways work together.
What Is Infrastructure Monitoring?
Infrastructure monitoring is the systematic observation of physical assets, environmental conditions, and operational processes through instruments, sensors, telemetry, inspections, and analytical systems. Its purpose is not merely to collect measurements, but to generate actionable awareness about the current and evolving state of infrastructure. That awareness may support maintenance planning, operational control, incident response, compliance, forecasting, optimization, resilience planning, or long-term asset stewardship.
In more traditional infrastructure environments, monitoring depended heavily on periodic manual inspection, limited instrumentation, and after-the-fact reporting. These practices remain important, but they are often insufficient in systems that are geographically distributed, operationally interdependent, exposed to rapid environmental change, or dependent on tight coordination among physical and digital layers. As infrastructure has become more digitized and more dynamic, monitoring has shifted toward more continuous, networked, and integrated forms of measurement. This is especially visible in smart grids, intelligent transportation systems, building management systems, water networks, industrial facilities, and environmental monitoring platforms.
Monitoring is therefore best understood as an observability function. It provides the informational basis through which infrastructure can be interpreted and managed. Without it, infrastructure remains partly opaque. With it, operators gain a stronger basis for detecting incipient failure, understanding system behavior, and responding before local issues escalate into broader disruption. Monitoring does not eliminate uncertainty, but it can reduce informational darkness and make intervention more timely, targeted, and accountable.
Why Observability Matters in Infrastructure Systems
Infrastructure systems are large, distributed, and often only partially visible to the institutions responsible for operating them. Pipes run underground. Grid conditions shift across complex networks. Buildings contain interacting mechanical and digital systems. Roads, bridges, and transport corridors are affected by traffic, weather, and wear patterns that evolve over time. Environmental conditions such as pollution, moisture, air quality, water chemistry, heat, flood exposure, and ecosystem stress can influence infrastructure performance while remaining difficult to observe directly. Monitoring systems make these conditions more legible.
This matters because infrastructure failure is often preceded by weak signals rather than sudden collapse. Pressure changes may indicate leaks before visible failure appears. Vibration signatures may reveal equipment degradation before breakdown. Changes in load, temperature, or voltage may indicate stress in an energy system. Traffic and occupancy data may reveal bottlenecks, safety risks, or declining service quality. Water-quality indicators may reveal treatment, contamination, or distribution concerns before public-health risk becomes acute. Monitoring is therefore essential not only for real-time control, but also for anticipating deterioration, understanding trends, and managing infrastructure as a dynamic system rather than a static asset inventory.
Observability also affects governance. What institutions can measure influences what they can manage, justify, prioritize, and be held accountable for. Poor monitoring can leave operators reactive, dependent on anecdote, or blind to systemic deterioration. Strong monitoring does not eliminate uncertainty, but it reduces informational opacity and supports more grounded decisions across maintenance, risk management, planning, resilience, environmental protection, and public accountability.
| Infrastructure Need | Monitoring Capability | Failure If Missing |
|---|---|---|
| Failure detection | Identify abnormal conditions before visible breakdown or service interruption. | Maintenance remains reactive and disruption-prone. |
| Condition assessment | Track degradation, wear, drift, stress, and performance trends over time. | Asset stewardship relies on incomplete inspection cycles. |
| Operational control | Provide timely signals for operators, control systems, dispatch, and field response. | Systems cannot adapt to changing conditions quickly enough. |
| Risk and resilience | Detect exposure, vulnerability, cascading risk, and recovery status. | Resilience planning remains abstract or retrospective. |
| Public accountability | Preserve evidence behind interventions, warnings, investments, and claims. | Institutions cannot explain how conclusions were reached. |
Observability is one of the foundations of intelligent infrastructure because it determines whether institutions can see enough of the system to act responsibly under changing conditions.
Sensors as Infrastructure Interfaces
Sensors function as interfaces between the physical world and digital representation. They convert material conditions into signals that can be stored, transmitted, analyzed, and, in cyber-physical settings, linked to operational response. In infrastructure systems, sensors may measure environmental variables, equipment states, structural conditions, system flows, chemical conditions, energy states, or user behaviors depending on the domain and purpose of the monitoring architecture.
These measurement functions vary widely. Energy systems may rely on voltage, current, frequency, phase, temperature, transformer loading, power quality, and breaker status. Water systems may monitor pressure, flow, turbidity, chlorine, pH, conductivity, tank level, pump state, sewer level, and rainfall. Transportation systems may use loop detectors, cameras, radar, GPS-derived data, connected vehicle data, and crowdsourced signals to estimate movement, congestion, incidents, and safety risks. Buildings may monitor temperature, humidity, airflow, occupancy, energy use, alarms, and equipment performance. Environmental systems may track pollutants, meteorological conditions, hydrological variables, atmospheric deposition, water chemistry, soil moisture, biodiversity indicators, or ecosystem stress.
Yet sensing is never entirely neutral. Sensor placement, frequency, accuracy, calibration, sampling design, maintenance, and data access all influence what is visible and what is not. Every monitoring system reflects choices about what matters, what can be measured, what costs are acceptable, and what degree of uncertainty can be tolerated. Sensors therefore shape infrastructure knowledge not only by producing data, but also by defining the boundaries of operational attention.
| Sensor or Signal Type | Infrastructure Condition Observed | Interpretive Risk |
|---|---|---|
| Pressure and flow sensors | Water distribution, pumping, leakage, hydraulic conditions, and service pressure. | Readings may mislead if sensor placement, pipe topology, or calibration is poorly understood. |
| Voltage, current, and frequency sensors | Grid state, power quality, loading, instability, and local electrical stress. | Local readings may not represent broader system behavior without topology context. |
| Vibration and acoustic sensors | Rotating equipment, structural response, leakage, mechanical wear, and anomaly signatures. | Signals may be noisy or environment-dependent without baseline characterization. |
| Cameras, radar, and mobility signals | Traffic flow, incidents, crowding, occupancy, surface conditions, and transport disruption. | Privacy, weather, occlusion, classification errors, and uneven coverage can affect interpretation. |
| Environmental sensors | Air quality, water quality, rainfall, heat, soil moisture, hydrology, and ecological stress. | Sampling design, sensor drift, maintenance, and local microconditions strongly affect reliability. |
| Device-health and telemetry signals | Battery, latency, packet loss, uptime, firmware status, communications path, and sensor condition. | Monitoring systems can appear healthy while individual devices silently degrade. |
Sensors are therefore not merely technical devices. They are epistemic instruments: they define how institutions know the physical systems they are responsible for maintaining.
What Sensor Integration Actually Means
Sensor integration is the process through which measurements from multiple instruments, devices, locations, and subsystems are brought into a coherent operational architecture. In mature infrastructure systems, this involves more than technical connectivity alone. It also includes synchronization, contextualization, validation, metadata management, interoperability, cybersecurity, and the translation of measurements into forms that support decision-making.
This matters because infrastructure systems generate heterogeneous data. Sensors may use different protocols, operate at different frequencies, produce different data types, and exist within different vendor ecosystems or operational domains. Without integration, monitoring remains fragmented. Operators may have many readings but little systemic understanding. Integration turns local signals into a broader picture of infrastructure state by allowing relationships to be observed across space, time, asset class, service zone, and subsystem boundaries.
A mature sensor integration system therefore does several things at once. It collects data from different sources reliably. It aligns that data temporally and operationally. It provides context such as asset identity, location, thresholds, metadata, calibration status, and maintenance history. It supports validation so that spurious readings do not drive poor decisions. And it presents the resulting information through interfaces, analytics, alerts, or operational workflows that connect measurement to action.
| Integration Requirement | Why It Matters | Implementation Pattern |
|---|---|---|
| Stable sensor identity | Readings must be traceable to specific devices, assets, owners, firmware, and calibration records. | Sensor inventory, persistent IDs, device registry |
| Time alignment | Signals from different sources must be comparable across events, systems, and response windows. | Timestamp policy, clock synchronization, timezone handling |
| Unit normalization | Measurements cannot be compared if units, scales, or encoding differ across systems. | Unit registry, validation rules, conversion functions |
| Asset and location context | Sensor readings need physical, geospatial, network, and service meaning. | Asset registry, GIS link, topology map, service-zone table |
| Quality and calibration status | Users must know whether readings are current, valid, calibrated, and trustworthy. | Calibration log, quality flags, validation reports |
| Governed interfaces | Sensor data must move securely and consistently across devices, platforms, teams, and institutions. | API register, protocol map, access-control policy, message schema |
Sensor integration is therefore a form of infrastructure interpretation. It determines whether the institution can reason across the system, or whether it remains trapped in disconnected device-level readings.
Monitoring Architecture and Data Flow
Infrastructure monitoring systems can be understood as layered architectures through which physical conditions are translated into operational awareness. Each layer performs a distinct role, and weaknesses at any layer can undermine the trustworthiness of the full monitoring system.
Sensing Layer
The sensing layer captures signals from infrastructure assets or environments. This includes fixed sensors, embedded devices, meters, cameras, gauges, remote instruments, mobile platforms, connected vehicles, drones, satellite-derived measurements, and inspection devices. Sensing design should define what is measured, why it matters, where the sensor is placed, what unit is used, what sampling interval applies, what calibration is required, and what uncertainty is expected.
Transmission Layer
Measurements must move across communication networks. These may include industrial control networks, fiber systems, cellular links, wireless sensor networks, mesh networks, satellite channels, local gateways, message brokers, or hybrid communications architectures. Reliability, latency, continuity, and security all shape the usefulness of transmitted measurements. Monitoring signals are only operationally useful if they arrive within the time window required by the decision.
Integration Layer
The integration layer ingests data into platforms, brokers, historians, databases, or middleware environments where signals are standardized, timestamped, linked to assets, connected to metadata, and combined with contextual information. This is often the point at which local readings begin to take on systemic meaning. Without integration, a monitoring system may collect data but fail to create shared situational awareness.
Analytics and Interpretation Layer
At this stage, measurements are transformed into operational insight. Analytical functions may include threshold alerts, anomaly detection, trend analysis, state estimation, condition assessment, forecasting, visualization, clustering, event correlation, and decision support. In more advanced environments, these outputs may support digital twins, predictive maintenance, optimization, or scenario analysis. Analytical interpretation should remain tied to data quality, calibration status, uncertainty, and field validation.
Decision and Response Layer
Finally, monitoring outputs feed into decisions. These may involve operator awareness, dispatch, inspection prioritization, maintenance scheduling, incident response, public communication, regulatory reporting, or automated control in tightly coupled cyber-physical systems. Monitoring alone does not improve infrastructure. It must be connected to institutional capacity for interpretation and intervention.
| Stage | Function | Failure Mode |
|---|---|---|
| Physical condition | Infrastructure produces measurable state, stress, flow, movement, quality, or environmental condition. | Important system behavior remains unobserved. |
| Sensing | Devices translate physical conditions into digital or analog signals. | Sensor placement, drift, damage, or uncertainty corrupts interpretation. |
| Telemetry | Signals move through communication networks into platforms or control systems. | Readings arrive late, duplicated, incomplete, insecure, or not at all. |
| Integration | Signals are linked to assets, units, locations, thresholds, metadata, and source identity. | Data cannot be compared or interpreted across systems. |
| Analytics | Signals become indicators, alerts, anomalies, forecasts, trends, or risk scores. | Outputs appear authoritative but lack validation or decision relevance. |
| Response | Outputs inform field inspection, maintenance, control, dispatch, emergency response, or public communication. | Monitoring creates awareness without action. |
This layered model helps explain why infrastructure monitoring is more than instrumentation. It is a system of translation from physical condition to institutional response. Where that translation is weak, measurement can become noise. Where it is strong, monitoring becomes one of the central enabling functions of intelligent infrastructure.
Major Infrastructure Applications
Infrastructure monitoring and sensor integration now shape a wide range of domains. Their value differs by infrastructure sector, but the underlying pattern is consistent: distributed signals become more valuable when integrated with asset context, data quality, analytical interpretation, and governance response.
Energy Systems
Grid monitoring depends on measurements of system state, asset condition, load, voltage, frequency, power quality, equipment temperature, breaker status, distributed energy resource behavior, and outage conditions. In increasingly distributed and dynamic energy environments, monitoring is central to both operational coordination and resilience. A power grid cannot integrate renewable generation, storage, flexible demand, and grid-edge devices responsibly without strong observability.
Transportation Systems
Transportation agencies use cameras, loop detectors, radar, connected vehicle data, crowdsourced signals, weather sensors, pavement condition measurements, and incident reports to understand traffic flow, safety, congestion, travel time, asset conditions, and operational bottlenecks. Transportation observability increasingly depends on blending fixed, mobile, public, private, and environmental data sources rather than relying on a single measurement modality.
Water and Wastewater Systems
Water systems rely on monitoring for flow, pressure, tank level, treatment conditions, pump state, water quality, sewer level, rainfall, overflow risk, and system security. In water networks, monitoring is especially important because many critical conditions remain physically hidden until failure is already advanced. Sensor integration helps connect hydraulic conditions, public-health indicators, maintenance records, and field response.
Buildings and Facilities
Buildings increasingly depend on integrated monitoring for HVAC, lighting, occupancy, indoor air quality, access, alarms, energy use, equipment performance, and comfort. These environments show how sensor integration can support efficiency, maintenance, safety, resilience, indoor environmental quality, and operational continuity within dense cyber-physical settings.
Environmental Monitoring
Environmental infrastructure depends on long-term and distributed monitoring of air quality, water quality, atmospheric deposition, hydrology, soil moisture, heat, biodiversity, and ecological conditions. Sensor networks in these domains provide not only local awareness but also broader visibility into environmental change over time. Monitoring design is especially important because environmental signals can vary across geography, season, scale, and vulnerability.
Cyber-Physical Operations
Modern infrastructure monitoring also includes monitoring of the monitoring system itself: device health, firmware status, packet loss, remote access, credentials, logs, anomalies, network segmentation, and telemetry integrity. As monitoring systems become operationally consequential, their reliability and security become part of infrastructure reliability.
| Domain | Signals | Analytical Uses |
|---|---|---|
| Energy | Voltage, frequency, current, load, power quality, outage status, equipment condition | State awareness, reliability, DER coordination, asset stress, restoration, resilience |
| Water | Pressure, flow, tank level, pump state, turbidity, chlorine, pH, rainfall, sewer level | Leak detection, quality assurance, overflow risk, service continuity, public-health review |
| Transportation | Traffic flow, speed, incidents, vehicle location, signal state, weather, pavement condition | Congestion management, safety analysis, incident response, maintenance planning |
| Buildings | Temperature, humidity, airflow, occupancy, energy use, alarms, equipment condition | Energy performance, fault detection, comfort, safety, maintenance, indoor environmental quality |
| Environmental systems | Air quality, water quality, rainfall, hydrology, soil moisture, heat, ecological indicators | Risk detection, adaptation planning, ecosystem stewardship, public reporting |
| Cyber-physical operations | Device health, telemetry latency, packet loss, firmware, access logs, anomalies | Security monitoring, continuity planning, telemetry trust, incident response |
These applications show that infrastructure monitoring is not isolated device work. It is a cross-domain observability discipline that connects physical systems, digital systems, data systems, and governance systems.
Data Quality, Calibration, and Measurement Limits
Monitoring systems are only as trustworthy as the quality of their measurements and the institutions that sustain them. Sensors drift. Instruments foul. Communications fail. Timestamps misalign. Metadata becomes incomplete. Thresholds are misconfigured. Local conditions distort readings. Batteries weaken. Firmware becomes outdated. Devices are moved without documentation. For this reason, infrastructure monitoring requires calibration, validation, maintenance, redundancy where necessary, and an explicit understanding of measurement uncertainty.
Data quality is not an abstract technical matter. It directly affects whether operators trust the monitoring system, whether alerts are actionable, and whether analytical outputs support sound decisions. Poor-quality data can be worse than no data if it creates false confidence, triggers alert fatigue, or conceals emerging risk. In high-stakes environments, the challenge is not simply collecting more measurements, but ensuring that signals are interpretable, comparable, calibrated, timely, and appropriate to the decisions they inform.
Measurement also has limits. Not everything that matters is easily sensed, and not every important risk is immediately measurable. Monitoring systems always provide partial visibility. Mature infrastructure management therefore combines instrumented measurement with engineering judgment, inspection, domain knowledge, institutional memory, and community-facing feedback rather than assuming that sensing alone can provide complete system understanding.
| Concern | Infrastructure Consequence | Validation Practice |
|---|---|---|
| Sensor drift | Measurements slowly diverge from physical reality. | Calibration schedules, drift detection, field comparison |
| Missing readings | Events or trends may be undercounted or invisible. | Expected-reading counts, missingness alerts, redundancy review |
| Latency | Data arrives too late for operational response. | Latency logs, freshness scores, decision-window requirements |
| Metadata gaps | Readings cannot be interpreted in asset, location, unit, or valid-use context. | Required metadata checks, schema validation, data catalog review |
| False positives and false negatives | Alerts create fatigue or fail to detect real risk. | Alert validation, field verification, threshold tuning |
| Calibration uncertainty | Operators may overtrust values produced by degraded instruments. | Calibration confidence scoring, maintenance logs, sensor replacement rules |
Monitoring quality should be treated as an ongoing operational discipline, not as a one-time commissioning step.
Monitoring Risk, Blind Spots, and System Vulnerability
Monitoring systems create new capabilities, but they also create new vulnerabilities. Heavy dependence on sensors can make infrastructure sensitive to sensor failure, communication outages, spoofing, cyber compromise, corrupted telemetry, cloud outages, platform failures, vendor lock-in, or degraded power supply. If a system is designed around digital observability, loss of that observability can become a serious operational event in its own right. In tightly integrated environments, poor monitoring can distort situational awareness and delay appropriate response.
Blind spots are especially important. Infrastructure monitoring always involves choices about what is measured, where sensors are placed, and which assets receive the most attention. These decisions can create structural asymmetries in awareness. Some forms of deterioration may be highly visible, while others remain poorly instrumented. Some parts of a network may be richly monitored, while others remain effectively opaque. Monitoring architecture therefore shapes not just the quantity of information, but the distribution of visibility across the system.
There is also a governance risk in assuming that more sensing automatically produces better stewardship. Monitoring systems can generate volumes of data that exceed institutional capacity to interpret, maintain, or act on them. In such cases, apparent visibility may conceal organizational overload or fragmented responsibility. Infrastructure intelligence depends on effective measurement, but also on disciplined choices about what to monitor, why it matters, and how institutions will use the results.
| Risk | Failure Mode | Mitigation |
|---|---|---|
| False confidence | Dashboards appear current while readings are stale, incomplete, or uncalibrated. | Freshness indicators, calibration status, quality flags, uncertainty display |
| Blind spots | Unmonitored zones, assets, or communities remain invisible in risk assessment. | Coverage audits, service-zone gap analysis, equity-aware monitoring review |
| Cyber-physical compromise | Telemetry is spoofed, interrupted, manipulated, or used as an entry point. | Segmentation, authentication, telemetry integrity checks, incident response |
| Alert fatigue | Too many low-quality alerts reduce operator trust and response quality. | Threshold review, alert prioritization, field validation, escalation rules |
| Vendor fragmentation | Devices and platforms do not integrate across systems or preserve context. | Open standards, procurement requirements, API governance, portability rules |
| Action gap | Monitoring detects issues but no institution has capacity or authority to respond. | Response protocols, governance logs, owners, work-order integration |
Monitoring systems should therefore be designed not only for visibility, but also for resilience under loss of visibility.
Governance, Standards, and Institutional Capacity
Infrastructure monitoring and sensor integration are governed systems as much as technical systems. Their effectiveness depends on standards, procurement, calibration regimes, maintenance practices, data governance, interoperability frameworks, staffing, cybersecurity, review cycles, and the ability of institutions to coordinate across operators, engineers, IT teams, cybersecurity teams, regulators, vendors, contractors, and public agencies.
Standards matter because monitoring architectures often span devices, communication layers, and software environments from multiple sources. Without interoperability and disciplined metadata practices, integrated visibility becomes difficult to sustain. Monitoring is therefore not a purely local engineering problem. It depends on shared frameworks that allow systems to remain intelligible and operable over time.
Institutional capacity matters just as much. A well-instrumented system can still fail if no one maintains the devices, validates the data, understands the interfaces, responds to alerts, revises thresholds, documents changes, reviews blind spots, or has authority to act on what the system reveals. Monitoring should therefore be understood as part of infrastructure governance. It shapes how institutions know their systems, where they direct attention, and how they justify decisions about risk, maintenance, adaptation, and resilience over time.
| Capability | Purpose | Evidence Artifact |
|---|---|---|
| Monitoring governance | Defines what is monitored, why it matters, who owns it, and what decisions readings support. | Monitoring charter, objective manifest, decision-use register |
| Calibration governance | Ensures sensor readings remain trustworthy over time. | Calibration schedule, drift report, field validation log |
| Data governance | Preserves metadata, source identity, quality flags, valid use, retention, access, and lineage. | Metadata dictionary, data catalog, lineage register, retention policy |
| Interoperability governance | Prevents fragmentation across devices, vendors, protocols, platforms, and teams. | Standards matrix, protocol map, API register, procurement requirements |
| Cybersecurity governance | Protects devices, telemetry, remote access, credentials, firmware, logs, and monitoring platforms. | Security architecture, device inventory, segmentation review, incident response plan |
| Operational governance | Connects alerts and monitoring outputs to inspection, dispatch, maintenance, incident response, or planning. | Response protocol, work-order integration, action log, after-action review |
The governance question is whether monitoring strengthens infrastructure stewardship, resilience, and accountability, or whether it merely adds data streams to already fragmented institutions.
Deployment Readiness Gate
Before infrastructure monitoring workflows are used for operations, public safety, maintenance prioritization, incident response, environmental reporting, water-quality assurance, grid reliability, traffic management, predictive maintenance, regulatory claims, capital planning, or resilience scoring, they should pass a readiness gate. The purpose is not to slow monitoring deployment. It is to confirm that sensor outputs are supported by calibrated devices, reliable telemetry, sufficient metadata, validation, cybersecurity controls, and accountable response pathways.
| Readiness Check | Pass Condition | Evidence |
|---|---|---|
| Monitoring purpose | Decision uses, valid-use limits, responsible institutions, public-service goals, and prohibited uses are defined. | Monitoring objective manifest, decision-use register, governance charter |
| Sensor and asset inventory | Sensors are linked to assets, locations, service zones, source systems, owners, and criticality. | Sensor inventory, asset registry, GIS layer, topology map |
| Calibration and validation | Calibration schedules, drift checks, field validation, and maintenance status are documented. | Calibration log, validation report, inspection records |
| Telemetry quality | Latency, missingness, packet loss, duplication, freshness, device health, and quality flags are measured. | Telemetry record, device-health report, pipeline log |
| Metadata and context | Records include sensor ID, asset ID, location, unit, timestamp source, owner, quality flag, calibration status, and valid use. | Metadata dictionary, schema validation, data catalog |
| Coverage and blind spots | Critical assets, service zones, vulnerable areas, and unmonitored conditions are reviewed. | Coverage map, blind-spot register, service-zone gap analysis |
| Security and continuity | Devices, telemetry, remote access, firmware, credentials, logs, and monitoring platforms are protected and recoverable. | Security architecture, access-control review, incident response plan, backup plan |
| Operational response | Alerts and indicators are connected to inspection, dispatch, maintenance, public communication, emergency response, or planning. | Response protocol, escalation matrix, work-order link, governance action log |
A monitoring system that cannot pass this readiness gate may still be useful for exploration or research, but its outputs should be treated cautiously when used for operational automation, public claims, safety decisions, or infrastructure investment.
Data and Configuration Artifacts
The companion repository can use a data-first structure so infrastructure monitoring claims can be examined rather than merely asserted. Each artifact has a specific role in making the observability chain reconstructable across sensors, assets, telemetry, calibration, coverage, data quality, alerts, response actions, and governance review.
| Artifact | File | Purpose |
|---|---|---|
| Monitoring objective manifest | config/monitoring_objective.yml |
Defines monitoring purpose, decision uses, valid-use limits, governance responsibilities, and public-service aims. |
| Sensor inventory | data/sensor_inventory.csv |
Documents sensor identity, type, measured variable, asset, location, unit, owner, frequency, communication path, and criticality. |
| Infrastructure asset registry | data/monitored_asset_registry.csv |
Links sensors to assets, service zones, systems, facilities, networks, and public-service responsibilities. |
| Telemetry records | data/sensor_telemetry_records.csv |
Stores timestamped readings, units, latency, missingness, device health, quality flags, and ingestion status. |
| Calibration and validation log | data/calibration_validation_log.csv |
Tracks calibration date, drift status, field validation, maintenance, replacement, and confidence. |
| Coverage and blind-spot review | data/coverage_blindspot_review.csv |
Assesses monitored critical assets, unmonitored zones, vulnerable areas, and coverage gaps. |
| Alert and response register | data/monitoring_alert_response_register.csv |
Connects alerts, anomalies, thresholds, and risk signals to field response and governance action. |
| SQL schema | sql/schema.sql |
Creates a local SQLite database for monitoring evidence records. |
These artifacts are designed to make monitoring systems auditable. They can be replaced with institutional data sources later, but the scaffold makes the logic of sensing, calibration, telemetry, coverage, integration, observability, and action explicit from the beginning.
Mathematical Lens: Monitoring Trust, Coverage, and Resilience
A lightweight mathematical lens helps distinguish infrastructure monitoring from simple sensor deployment. The point is not to reduce monitoring performance to a single score, but to make visible the relationships among coverage, signal quality, calibration, telemetry reliability, metadata, blind spots, actionability, and resilience.
C_s =
\frac{N_{\mathrm{monitored\ critical\ assets}}}{N_{\mathrm{critical\ assets}}}
\]
Interpretation: Sensor coverage measures whether critical assets, zones, or conditions are monitored. Coverage should be weighted by service criticality and vulnerability.
Q_s =
w_1 A_{\mathrm{accuracy}} +
w_2 P_{\mathrm{precision}} +
w_3 C_{\mathrm{completeness}} +
w_4 V_{\mathrm{validity}} +
w_5 F_{\mathrm{freshness}}
\]
Interpretation: Signal quality depends on accuracy, precision, completeness, validity, and freshness. These dimensions should be measured rather than assumed.
K_c =
\exp(-\lambda \Delta t_{\mathrm{since\ calibration}})
\]
Interpretation: Calibration confidence declines as time since calibration increases. The decay rate depends on sensor type, environmental stress, and operational consequence.
T_r =
1 –
\frac{N_{\mathrm{missing}} + N_{\mathrm{late}} + N_{\mathrm{invalid}}}{N_{\mathrm{expected}}}
\]
Interpretation: Telemetry reliability measures whether expected readings are arriving on time and in valid form.
O_m =
\alpha C_s +
\beta Q_s +
\gamma K_c +
\delta T_r +
\theta M_c –
\eta B_g
\]
Interpretation: Monitoring observability improves with coverage, signal quality, calibration confidence, telemetry reliability, and metadata completeness, while blind spots reduce observability.
R_m =
\lambda_1 O_m +
\lambda_2 A_{\mathrm{action}} +
\lambda_3 B_{\mathrm{backup}} +
\lambda_4 V_{\mathrm{validation}} –
\lambda_5 E_{\mathrm{exposure}}
\]
Interpretation: Monitoring-enabled resilience rises when observability is connected to action, backup capability, and validation, and falls when cyber, physical, organizational, or coverage exposure grows.
This mathematical framing should be used as a structured diagnostic, not as a substitute for domain engineering, inspection, calibration, cybersecurity review, or institutional judgment.
Python Workflow: Infrastructure Monitoring Review
The Python workflow in the companion repository can read sensor inventories, asset registries, telemetry records, calibration logs, coverage reviews, and alert-response registers; compute coverage, signal quality, calibration confidence, telemetry reliability, metadata completeness, monitoring observability, actionability, and review flags; and export a governance-ready monitoring watchlist.
from pathlib import Path
import numpy as np
import pandas as pd
ARTICLE_DIR = Path("articles/infrastructure-monitoring-and-sensor-integration-observability-and-resilience")
DATA_DIR = ARTICLE_DIR / "data"
OUTPUT_DIR = ARTICLE_DIR / "outputs"
OUTPUT_DIR.mkdir(parents=True, exist_ok=True)
sensors = pd.read_csv(DATA_DIR / "sensor_inventory.csv")
assets = pd.read_csv(DATA_DIR / "monitored_asset_registry.csv")
telemetry = pd.read_csv(DATA_DIR / "sensor_telemetry_records.csv", parse_dates=["timestamp"])
calibration = pd.read_csv(DATA_DIR / "calibration_validation_log.csv", parse_dates=["last_calibration_date"])
coverage = pd.read_csv(DATA_DIR / "coverage_blindspot_review.csv")
alerts = pd.read_csv(DATA_DIR / "monitoring_alert_response_register.csv")
review = (
telemetry
.merge(sensors, on="sensor_id", how="left")
.merge(assets, on="asset_id", how="left")
.merge(calibration, on="sensor_id", how="left")
.merge(coverage, on="service_zone_id", how="left")
)
review["signal_quality_score"] = (
0.25 * review["accuracy_score"] +
0.20 * review["precision_score"] +
0.20 * review["completeness_score"] +
0.20 * review["validity_score"] +
0.15 * review["freshness_score"]
).clip(lower=0, upper=1)
review["days_since_calibration"] = (
pd.Timestamp.utcnow().tz_localize(None) -
review["last_calibration_date"].dt.tz_localize(None)
).dt.days.clip(lower=0)
review["calibration_confidence_score"] = np.exp(
-0.004 * review["days_since_calibration"]
).clip(0, 1)
review["telemetry_reliability_score"] = (
1 -
(
review["missing_readings"] +
review["late_readings"] +
review["invalid_readings"]
) / review["expected_readings"].replace(0, pd.NA)
).fillna(0).clip(lower=0, upper=1)
metadata_fields = [
"has_sensor_id",
"has_asset_id",
"has_location",
"has_unit",
"has_timestamp_source",
"has_owner",
"has_quality_flag",
"has_valid_use"
]
review["metadata_completeness_score"] = (
review[metadata_fields].astype(float).mean(axis=1).clip(lower=0, upper=1)
)
review["sensor_coverage_score"] = (
review["monitored_critical_assets"] /
review["critical_assets"].replace(0, pd.NA)
).fillna(0).clip(lower=0, upper=1)
review["blindspot_penalty"] = (
review["unmonitored_high_risk_zones"] /
review["total_service_zones"].replace(0, pd.NA)
).fillna(0).clip(lower=0, upper=1)
review["monitoring_observability_score"] = (
0.20 * review["sensor_coverage_score"] +
0.20 * review["signal_quality_score"] +
0.20 * review["calibration_confidence_score"] +
0.20 * review["telemetry_reliability_score"] +
0.15 * review["metadata_completeness_score"] -
0.15 * review["blindspot_penalty"]
).clip(lower=0, upper=1)
alert_actions = (
alerts
.assign(has_action=lambda df: df["response_status"].isin(["open", "closed", "in_progress"]))
.groupby("sensor_id", as_index=False)
.agg(actionability_score=("has_action", "mean"))
)
review = review.merge(alert_actions, on="sensor_id", how="left")
review["actionability_score"] = review["actionability_score"].fillna(0).clip(lower=0, upper=1)
review["monitoring_review_flag"] = (
(review["signal_quality_score"] < 0.80) |
(review["calibration_confidence_score"] < 0.70) |
(review["telemetry_reliability_score"] < 0.85) |
(review["metadata_completeness_score"] < 0.85) |
(review["sensor_coverage_score"] < 0.75) |
(review["monitoring_observability_score"] < 0.75) |
(review["actionability_score"] < 0.50) |
(review["quality_flag"].eq("review"))
)
watchlist = (
review[review["monitoring_review_flag"]]
.sort_values(
["monitoring_observability_score", "signal_quality_score", "telemetry_reliability_score"],
ascending=[True, True, True]
)
)
review.to_csv(OUTPUT_DIR / "infrastructure_monitoring_review.csv", index=False)
watchlist.to_csv(OUTPUT_DIR / "infrastructure_monitoring_watchlist.csv", index=False)
print(watchlist[[
"sensor_id",
"asset_id",
"service_zone_id",
"measurement_name",
"signal_quality_score",
"calibration_confidence_score",
"telemetry_reliability_score",
"sensor_coverage_score",
"monitoring_observability_score",
"actionability_score"
]])
This workflow is intentionally transparent. It allows analysts to see whether monitoring concern arises from weak coverage, poor signal quality, calibration decay, telemetry failure, metadata gaps, blind spots, low actionability, or sensor-health issues.
R Workflow: Sensor Integration and Observability Reporting
The R workflow can summarize monitoring performance by infrastructure domain, service zone, asset class, sensor type, owner, or governance concern; identify coverage, quality, calibration, telemetry, metadata, and actionability gaps; and create stewardship-oriented reports for infrastructure owners, utilities, agencies, engineers, operators, analysts, and governance review groups.
library(readr)
library(dplyr)
library(lubridate)
article_dir <- "articles/infrastructure-monitoring-and-sensor-integration-observability-and-resilience"
data_dir <- file.path(article_dir, "data")
output_dir <- file.path(article_dir, "outputs")
dir.create(output_dir, recursive = TRUE, showWarnings = FALSE)
sensors <- read_csv(file.path(data_dir, "sensor_inventory.csv"), show_col_types = FALSE)
assets <- read_csv(file.path(data_dir, "monitored_asset_registry.csv"), show_col_types = FALSE)
telemetry <- read_csv(file.path(data_dir, "sensor_telemetry_records.csv"), show_col_types = FALSE)
calibration <- read_csv(file.path(data_dir, "calibration_validation_log.csv"), show_col_types = FALSE)
coverage <- read_csv(file.path(data_dir, "coverage_blindspot_review.csv"), show_col_types = FALSE)
alerts <- read_csv(file.path(data_dir, "monitoring_alert_response_register.csv"), show_col_types = FALSE)
alert_actions <- alerts %>%
mutate(has_action = response_status %in% c("open", "closed", "in_progress")) %>%
group_by(sensor_id) %>%
summarise(actionability_score = mean(has_action), .groups = "drop")
review <- telemetry %>%
left_join(sensors, by = "sensor_id") %>%
left_join(assets, by = "asset_id") %>%
left_join(calibration, by = "sensor_id") %>%
left_join(coverage, by = "service_zone_id") %>%
left_join(alert_actions, by = "sensor_id") %>%
mutate(
signal_quality_score = pmax(
0,
pmin(
1,
0.25 * accuracy_score +
0.20 * precision_score +
0.20 * completeness_score +
0.20 * validity_score +
0.15 * freshness_score
)
),
days_since_calibration = as.numeric(
as.Date(Sys.time()) - as.Date(last_calibration_date)
),
calibration_confidence_score = pmax(
0,
pmin(1, exp(-0.004 * days_since_calibration))
),
telemetry_reliability_score = if_else(
expected_readings > 0,
pmax(
0,
pmin(
1,
1 - (missing_readings + late_readings + invalid_readings) / expected_readings
)
),
0
),
metadata_completeness_score = rowMeans(
across(
c(
has_sensor_id,
has_asset_id,
has_location,
has_unit,
has_timestamp_source,
has_owner,
has_quality_flag,
has_valid_use
),
as.numeric
),
na.rm = TRUE
),
sensor_coverage_score = if_else(
critical_assets > 0,
pmax(0, pmin(1, monitored_critical_assets / critical_assets)),
0
),
blindspot_penalty = if_else(
total_service_zones > 0,
pmax(0, pmin(1, unmonitored_high_risk_zones / total_service_zones)),
0
),
monitoring_observability_score = pmax(
0,
pmin(
1,
0.20 * sensor_coverage_score +
0.20 * signal_quality_score +
0.20 * calibration_confidence_score +
0.20 * telemetry_reliability_score +
0.15 * metadata_completeness_score -
0.15 * blindspot_penalty
)
),
actionability_score = if_else(is.na(actionability_score), 0, actionability_score),
monitoring_review_flag =
signal_quality_score < 0.80 |
calibration_confidence_score < 0.70 |
telemetry_reliability_score < 0.85 |
metadata_completeness_score < 0.85 |
sensor_coverage_score < 0.75 |
monitoring_observability_score < 0.75 |
actionability_score < 0.50 |
quality_flag == "review"
)
zone_summary <- review %>%
group_by(service_zone_id, infrastructure_domain, owner_operator) %>%
summarise(
sensors = n_distinct(sensor_id),
assets = n_distinct(asset_id),
mean_signal_quality = mean(signal_quality_score, na.rm = TRUE),
mean_calibration_confidence = mean(calibration_confidence_score, na.rm = TRUE),
mean_telemetry_reliability = mean(telemetry_reliability_score, na.rm = TRUE),
mean_metadata_completeness = mean(metadata_completeness_score, na.rm = TRUE),
mean_sensor_coverage = mean(sensor_coverage_score, na.rm = TRUE),
mean_monitoring_observability = mean(monitoring_observability_score, na.rm = TRUE),
mean_actionability = mean(actionability_score, na.rm = TRUE),
review_flags = sum(monitoring_review_flag, na.rm = TRUE),
.groups = "drop"
) %>%
arrange(desc(review_flags), mean_monitoring_observability)
write_csv(review, file.path(output_dir, "infrastructure_monitoring_review_report.csv"))
write_csv(zone_summary, file.path(output_dir, "infrastructure_monitoring_zone_summary.csv"))
print(zone_summary)
The purpose is not to produce a definitive monitoring grade. It is to demonstrate how sensor coverage, signal quality, calibration confidence, telemetry reliability, metadata completeness, blind spots, observability, and actionability can be made reproducible and auditable.
Systems Code: Edge Sensing, Stream Validation, and Monitoring Interfaces
The companion repository can extend the article into a reproducible systems scaffold. Python and R support analytical review; SQL stores evidence; YAML files define objectives and policies; JSON schemas validate records; TypeScript can support interface models; Go can support monitoring-status APIs; Rust can support strict record validation; C can support low-level observability calculations; Fortran can support numerical scoring routines; MicroPython can support low-power edge-node telemetry; PYNQ and HDL can support hardware-assisted stream validation where appropriate.
| Directory | Role | Example Use |
|---|---|---|
python/ |
Monitoring review, sensor coverage scoring, calibration decay, telemetry reliability, observability watchlists | Compute monitoring observability and review flags |
r/ |
Service-zone summaries, sensor integration reports, calibration and quality review | Summarize monitoring performance by domain, zone, owner, and sensor type |
sql/ |
Evidence tables and auditable queries | Join sensors, assets, telemetry, calibration logs, coverage review, and alert response |
schemas/ |
Record validation and interoperability scaffolding | Validate sensor inventories, telemetry records, calibration logs, and response records |
c/ and embedded_c/ |
Low-level monitoring quality and edge checks | Compute signal quality, telemetry reliability, metadata completeness, and edge review flags |
rust/ |
Strict validation and CLI scaffolding | Validate sensor records, units, timestamps, calibration status, and required metadata |
go/ |
Monitoring status API scaffold | Expose sensor, asset, coverage, quality, calibration, and actionability status |
fortran/ |
Numerical monitoring and resilience routines | Prototype observability, calibration decay, and monitoring resilience equations |
micropython/ |
Edge telemetry-node scaffold | Package sensor readings with required metadata, quality flags, and device-health fields |
pynq/ and hdl/ |
Hardware-assisted stream validation | Prototype FPGA checks for metadata, latency, unit validity, missingness, and sensor-health flags |
typescript/ |
Dashboard/interface scaffold | Display monitoring observability, sensor health, calibration confidence, and response status |
The code should be understood as an engineering scaffold for reproducible monitoring and sensor-integration workflows, not as a replacement for certified operations, production data engineering, cybersecurity review, calibration programs, regulatory compliance, field inspection, or domain-specific infrastructure expertise.
GitHub Repository
The companion repository can house the reproducible data, code, schemas, validation tools, and systems-engineering examples that support this article’s infrastructure monitoring and sensor integration framework.
Testing and Validation
Testing infrastructure monitoring systems requires more than confirming that sensors transmit data or dashboards load. Validation should examine whether sensors are placed appropriately, whether measurements are calibrated, whether telemetry arrives on time, whether readings include sufficient metadata, whether units are valid, whether coverage is adequate, whether blind spots are documented, whether alerts are meaningful, whether response workflows exist, and whether monitoring systems remain secure and trustworthy under disruption.
| Validation Area | Test Question | Failure Signal |
|---|---|---|
| Sensor placement | Are sensors located where they can observe the relevant physical condition? | Readings are accurate locally but not representative of the operational question. |
| Calibration | Are sensors calibrated, maintained, and field-validated on a documented schedule? | Values drift from physical reality without visible warning. |
| Telemetry reliability | Are expected readings arriving on time, complete, valid, and non-duplicated? | Dashboards appear stable while missing or stale readings accumulate. |
| Metadata completeness | Do records include sensor ID, asset ID, location, unit, timestamp source, owner, quality flag, and valid use? | Data cannot be responsibly interpreted, joined, or reused. |
| Coverage and blind spots | Are critical assets, high-risk zones, vulnerable communities, and unmonitored conditions documented? | Monitoring creates uneven visibility and false system confidence. |
| Alert validation | Do alerts correspond to meaningful conditions and lead to appropriate response? | Operators experience alert fatigue or miss real events. |
| Security validation | Are devices, telemetry, remote access, credentials, firmware, and monitoring platforms protected? | Monitoring infrastructure becomes a cyber-physical vulnerability. |
| Response validation | Are outputs connected to field inspection, maintenance, dispatch, incident response, planning, or public communication? | Monitoring produces information without institutional action. |
Validation should be repeated after sensor deployments, sensor replacements, platform migrations, communication changes, threshold updates, calibration findings, cybersecurity incidents, major outages, environmental events, or changes in decision use.
Operational Signals and Monitoring-System Observability
Monitoring-system observability means being able to see whether the monitoring system itself is functioning as trustworthy infrastructure. This includes sensor uptime, calibration status, battery state, firmware version, packet loss, latency, missingness, device health, timestamp validity, schema validity, quality flags, telemetry continuity, alert freshness, false-positive rates, false-negative rates, communication pathway status, access anomalies, platform health, backup status, and response closure rates.
| Signal | What It Reveals | Operational Use |
|---|---|---|
| Sensor uptime | Whether monitoring devices are operating and transmitting as expected. | Device maintenance, continuity planning, coverage assurance |
| Calibration status | Whether measurements remain tied to trusted instrument performance. | Quality assurance, drift detection, sensor replacement |
| Telemetry latency | Whether readings arrive within the time window needed for action. | Operational trust, alert reliability, real-time readiness |
| Missingness and invalidity | Whether expected readings are absent, malformed, duplicated, or unusable. | Pipeline maintenance, data-quality governance, blind-spot review |
| Device-health status | Whether battery, firmware, sensor condition, or communication modules are degrading. | Preventive maintenance, edge-device replacement, field dispatch |
| Alert performance | Whether alerts correspond to real events and manageable response needs. | Threshold tuning, false-positive review, escalation design |
| Access and integrity anomalies | Whether telemetry or device access may be compromised or misconfigured. | Cybersecurity response, audit logging, segmentation review |
| Response closure | Whether monitoring outputs lead to responsible institutional action. | Governance accountability and institutional learning |
Monitoring observability is strongest when the institution can monitor not only the physical infrastructure, but also the reliability, security, calibration, quality, and actionability of the monitoring system itself.
Engineer and Researcher Checklist
- Define monitoring purpose, decision uses, valid-use limits, responsible owners, and public-service goals before selecting sensors.
- Document sensor identity, measured variable, asset, location, owner, unit, sampling interval, communication path, firmware, and criticality.
- Link sensors to asset registries, service zones, topology, geospatial context, maintenance records, and operational responsibility.
- Track calibration status, drift, last calibration date, field validation, sensor maintenance, and replacement history.
- Measure telemetry reliability: latency, missingness, packet loss, duplication, invalid readings, timestamp validity, and freshness.
- Preserve metadata: sensor ID, asset ID, location, unit, timestamp source, owner, quality flag, calibration status, and valid use.
- Assess coverage and blind spots across critical assets, high-risk zones, vulnerable areas, and unmonitored conditions.
- Validate alerts against field evidence, operator experience, incident history, false positives, and false negatives.
- Secure devices, telemetry, gateways, remote access, credentials, firmware, logs, and monitoring platforms.
- Connect outputs to inspection, maintenance, dispatch, incident response, planning, reporting, or public communication.
This checklist is intentionally practical. It keeps monitoring focused on observability, trust, calibration, coverage, security, actionability, and public accountability rather than sensor deployment alone.
Where This Fits in the Series
Infrastructure monitoring and sensor integration connect several major threads within the Intelligent Infrastructure Systems knowledge series. They rely on embedded and edge systems to capture local measurements, digital infrastructure to transmit signals, data platforms to integrate and contextualize readings, cyber-physical systems to link sensing with operations, digital twins to simulate monitored state, asset management to prioritize intervention, security systems to protect telemetry, and governance systems to translate evidence into responsible action.
This article therefore functions as a bridge between physical infrastructure, distributed sensing, data systems, operational intelligence, and institutional stewardship. It shows that intelligent infrastructure is not only about automation, optimization, or dashboards. It is also about whether essential systems can become visible enough to maintain, secure, adapt, and explain under changing conditions.
Future Directions
The future of infrastructure monitoring will likely involve denser sensing environments, greater use of edge processing, more fusion of fixed and mobile data sources, wider use of machine learning for anomaly detection, more hardware-assisted stream validation, stronger integration with digital twins, and more operational platforms that combine telemetry with forecasting, simulation, and decision support. Monitoring systems will become less isolated and more embedded within infrastructure governance, resilience planning, cybersecurity, environmental accountability, and public communication.
The deeper challenge, however, is not simply collecting more data. It is building monitoring systems that remain trustworthy, interpretable, maintainable, secure, and institutionally actionable. More sensors do not automatically create better infrastructure if the resulting signals are poorly calibrated, weakly integrated, unevenly distributed, insecure, or disconnected from meaningful response capacity. The future of intelligent infrastructure therefore depends on moving from raw instrumentation to mature observability: measurement systems that are technically sound, operationally integrated, and aligned with the real decisions through which infrastructure is maintained, secured, and adapted.
The long-run goal is not ubiquitous sensing for its own sake, but observability as stewardship: monitoring systems that help institutions know their systems better, detect risk earlier, respond more responsibly, and explain decisions more transparently to the people who depend on essential infrastructure.
Related Articles
- Digital Infrastructure Systems
- Cyber-Physical Infrastructure Systems
- Infrastructure Data Platforms and Analytics
- Digital Twins and Infrastructure Simulation
- Asset Management and Predictive Maintenance Systems
- Infrastructure Security and Cyber Resilience
- Infrastructure Governance and Policy Systems
- Smart Energy Grids and Digital Power Systems
- Intelligent Water Infrastructure Systems
- Intelligent Transportation Networks
These connections are substantive rather than decorative. Monitoring is a bridging function that connects measurement, data quality, cyber-physical coordination, risk detection, maintenance, response, governance, and resilience across complex infrastructure environments.
Further Reading
- Federal Highway Administration (FHWA) (2022) Considerations of Current and Emerging Transportation Data Sources. Available at: https://ops.fhwa.dot.gov/publications/fhwahop18084/fhwahop18084.pdf.
- Federal Highway Administration (FHWA) (2022) Emerging Data Sources. Available at: https://ops.fhwa.dot.gov/publications/fhwahop18084/ch2.htm.
- Greer, C., Burns, M., Wollman, D. and Griffor, E. (2019) Cyber-Physical Systems and Internet of Things. Gaithersburg, MD: National Institute of Standards and Technology. Available at: https://nvlpubs.nist.gov/nistpubs/SpecialPublications/NIST.SP.1900-202.pdf.
- National Institute of Standards and Technology (NIST) (n.d.) Cyber-Physical Systems and Internet of Things Foundations. Available at: https://www.nist.gov/programs-projects/cyber-physical-systems-and-internet-things-foundations.
- National Institute of Standards and Technology (NIST) (n.d.) Cyber Physical Systems and Internet of Things Program. Available at: https://www.nist.gov/programs-projects/cyber-physical-systems-and-internet-things-program.
- U.S. Department of Energy (DOE) (n.d.) Grid Modernization Initiative. Available at: https://www.energy.gov/gmi/grid-modernization-initiative.
- U.S. Department of Energy (DOE) (n.d.) Grid Modernization and the Smart Grid. Available at: https://www.energy.gov/oe/grid-modernization-and-smart-grid.
- World Health Organization (WHO) (2021) WHO global air quality guidelines: particulate matter, ozone, nitrogen dioxide, sulfur dioxide and carbon monoxide. Available at: https://www.who.int/publications/i/item/9789240034228.
- World Health Organization (WHO) (2023) Monitoring air pollution levels is key to adopting and implementing WHO’s Global Air Quality Guidelines. Available at: https://www.who.int/news/item/10-10-2023-monitoring-air-pollution-levels-is-key-to-adopting-and-implementing-who-s-global-air-quality-guidelines.
- World Meteorological Organization (WMO) (n.d.) WMO Integrated Global Observing System (WIGOS). Available at: https://wmo.int/site/knowledge-hub/programmes-and-initiatives/wmo-integrated-global-observing-system-wigos.
- World Meteorological Organization (WMO) (n.d.) Global Observing System (GOS). Available at: https://wmo.int/site/knowledge-hub/programmes-and-initiatives/global-observing-system-gos.
References
- Federal Highway Administration (FHWA) (2022) Considerations of Current and Emerging Transportation Data Sources. Washington, DC: U.S. Department of Transportation. Available at: https://ops.fhwa.dot.gov/publications/fhwahop18084/fhwahop18084.pdf.
- Federal Highway Administration (FHWA) (2022) Emerging Data Sources. Available at: https://ops.fhwa.dot.gov/publications/fhwahop18084/ch2.htm.
- Greer, C., Burns, M., Wollman, D. and Griffor, E. (2019) Cyber-Physical Systems and Internet of Things. Gaithersburg, MD: National Institute of Standards and Technology. Available at: https://nvlpubs.nist.gov/nistpubs/SpecialPublications/NIST.SP.1900-202.pdf.
- National Institute of Standards and Technology (NIST) (n.d.) Cyber-Physical Systems and Internet of Things Foundations. Available at: https://www.nist.gov/programs-projects/cyber-physical-systems-and-internet-things-foundations.
- National Institute of Standards and Technology (NIST) (n.d.) Cyber Physical Systems and Internet of Things Program. Available at: https://www.nist.gov/programs-projects/cyber-physical-systems-and-internet-things-program.
- U.S. Department of Energy (DOE) (n.d.) Grid Modernization Initiative. Available at: https://www.energy.gov/gmi/grid-modernization-initiative.
- U.S. Department of Energy (DOE) (n.d.) Grid Modernization and the Smart Grid. Available at: https://www.energy.gov/oe/grid-modernization-and-smart-grid.
- World Health Organization (WHO) (2021) WHO global air quality guidelines: particulate matter, ozone, nitrogen dioxide, sulfur dioxide and carbon monoxide. Geneva: WHO. Available at: https://www.who.int/publications/i/item/9789240034228.
- World Health Organization (WHO) (2023) Monitoring air pollution levels is key to adopting and implementing WHO’s Global Air Quality Guidelines. Available at: https://www.who.int/news/item/10-10-2023-monitoring-air-pollution-levels-is-key-to-adopting-and-implementing-who-s-global-air-quality-guidelines.
- World Meteorological Organization (WMO) (n.d.) Global Observing System (GOS). Available at: https://wmo.int/site/knowledge-hub/programmes-and-initiatives/global-observing-system-gos.
- World Meteorological Organization (WMO) (n.d.) WMO Integrated Global Observing System (WIGOS). Available at: https://wmo.int/site/knowledge-hub/programmes-and-initiatives/wmo-integrated-global-observing-system-wigos.