
Last Updated May 20, 2026
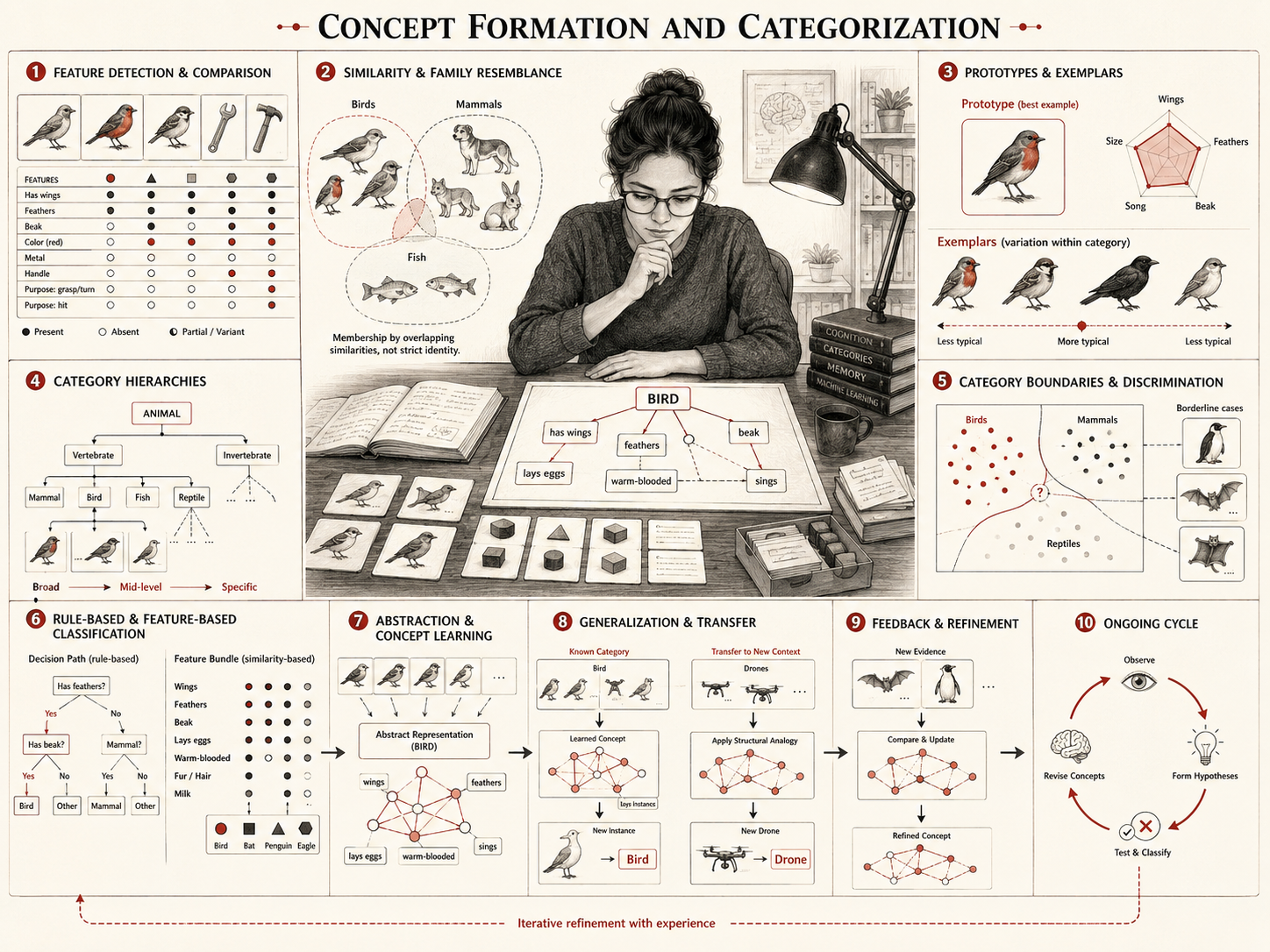
Concept formation refers to the processes through which the mind organizes information into categories, enabling abstraction, generalization, discrimination, prediction, and efficient reasoning. By grouping objects, events, properties, actions, and ideas into meaningful classes, concepts allow individuals to navigate complexity, interpret new information, and make decisions on the basis of prior knowledge. In cognitive psychology, concepts are not incidental labels attached to experience after the fact. They are among the basic structures through which experience becomes thinkable at all.
Concepts function as the building blocks of cognition. They allow individuals to move beyond isolated episodes and reason about general patterns, kinds, relations, roles, functions, and meanings. Without concepts, every new situation would need to be processed from first principles. Learning would be slower, inference would be weaker, language would lose stability, and decision making would be far less efficient.
Concept formation therefore links perception, memory, semantic memory, language processing, learning, mental models, analogical reasoning, and decision making into a more unified system of knowledge representation. Modern theories disagree about what concepts are and how they work, but they converge on one point: concepts are central to thought.
Main Library
Publications
Article Map
Cognitive Psychology
Related Topic
Artificial Intelligence Systems
Related Topic
Data Systems & Analytics
Related Topic
Behavioral Economics
Concepts matter because cognition must preserve what is relevant while ignoring what is incidental. A concept such as “vehicle” allows cars, bicycles, trains, buses, ships, and airplanes to be understood as related despite enormous differences in form. A concept such as “institution” allows courts, universities, agencies, markets, and public offices to be treated as structured social arrangements. A concept such as “risk” allows uncertainty, probability, exposure, consequence, and vulnerability to be organized into a shared frame of reasoning.
The nature of concepts
Concepts are mental representations that group entities together on the basis of shared structure, relevant features, functional roles, relational patterns, or culturally learned meanings. They allow individuals to recognize patterns, classify new information, make predictions, communicate distinctions, and draw inferences about unfamiliar cases.
For example, the concept of “vehicle” allows people to classify cars, trains, bicycles, and airplanes together despite large differences in size, form, speed, and mechanism. The concept of “tool” allows people to group hammers, scalpels, spoons, and software applications together when the relevant frame is functional use. The concept of “democracy” organizes institutions, representation, elections, rights, participation, legitimacy, and public authority into a more abstract political category.
Concepts therefore reduce cognitive complexity by organizing information into structured representations. They preserve what is relevant while filtering what is incidental. That ability is one of the conditions that makes abstraction possible.
Concepts are also flexible. The same object can fall under different concepts depending on context. A hammer may be a tool, a physical object, a household item, a weapon, a lever, a symbol of labor, or evidence in a legal case. A category is not always a fixed container; it is often a context-sensitive cognitive structure that highlights some relations and suppresses others.
This flexibility is central to cognition. Concepts do not merely label what is already obvious. They shape what becomes noticeable, comparable, memorable, and actionable. The concept used to frame a situation helps determine what the mind treats as relevant.
How concepts are formed
Concept formation depends on several related cognitive processes. These processes allow the mind to extract structure from experience rather than treating every encounter as wholly separate.
- Abstraction identifies relevant features while ignoring irrelevant variation.
- Generalization applies a learned concept to new cases or situations.
- Discrimination distinguishes between similar but meaningfully different categories.
- Feature weighting determines which properties matter most for classification.
- Boundary learning identifies where one category ends and another begins.
- Feedback integration uses correction, success, failure, and social response to refine category use.
- Conceptual reorganization revises a concept when new evidence changes the relevant structure.
These processes are visible in ordinary learning. A child learning the concept “dog” must generalize across different sizes, colors, breeds, and behaviors while discriminating dogs from wolves, cats, toys, and pictures. A student learning “democracy” must move beyond a single example and understand institutional structures, political practices, historical variation, and contested meanings. A scientist learning a technical concept must identify the features that are theoretically diagnostic, not merely perceptually obvious.
Concept formation is therefore tied to perception, because sensory input must be organized into meaningful units before categorization can occur. It is tied to semantic memory, because concepts are stored within organized knowledge systems. It is tied to learning, because concepts become more refined as experience accumulates.
Concept formation is not only the creation of a category. It is the gradual construction of a usable representational structure. The concept becomes cognitively valuable when it supports prediction, communication, inference, and transfer.
Prototype, exemplar, and rule-based theories
Different theories explain concept formation in different ways. Some emphasize prototypes, some emphasize stored exemplars, some emphasize rules, and some emphasize theory-like knowledge structures. These accounts are not mutually exclusive. Human categorization often uses several forms of representation depending on task, domain, expertise, and context.
Prototype theories propose that categories are organized around central or typical cases. A robin may be judged a more typical bird than an ostrich because it better matches the usual features associated with birds. Prototype theory helped challenge the view that all categories are defined only by strict necessary and sufficient conditions.
Exemplar theories propose that categorization depends on comparison to stored examples. A person may classify a new animal by comparing it with remembered animals rather than by consulting a single abstract prototype. Exemplar models are especially useful for explaining how people classify unusual, variable, or boundary cases.
Rule-based theories emphasize explicit criteria. A triangle can be classified by a rule: a closed plane figure with three sides. In some domains, especially formal, legal, mathematical, or institutional domains, rules can play a powerful role in category membership.
Theory-based accounts argue that concepts are embedded in broader causal, functional, social, or explanatory structures. A concept such as “disease,” “money,” “species,” or “institution” cannot be fully explained by surface similarity alone. It depends on background knowledge about causes, functions, histories, practices, and relations.
These theories highlight different aspects of concept formation. Prototypes explain graded typicality. Exemplars explain memory for particular cases. Rules explain formal category boundaries. Theory-based accounts explain why concepts often depend on deeper causal or social structure. A research-grade account of concepts should keep all of these possibilities available.
Category boundaries, typicality, and ambiguity
Categories often have boundaries, but those boundaries are not always sharp. Some concepts have formal definitions. Others have graded membership, fuzzy edges, contextual meaning, or contested boundaries. This is why category typicality is different from category membership.
A penguin is a bird, but it may be less typical than a robin. A tomato is botanically a fruit, but it may function as a vegetable in culinary categorization. A person may be legally classified under one category, socially interpreted through another, and institutionally treated through a third. Concepts are not always simple containers; they are often layered systems of meaning.
Boundary cases are especially important because they reveal how concepts work. When an item is clearly central to a category, classification is easy. When an item sits near a boundary, the mind must rely more heavily on context, rules, features, goals, and prior knowledge.
Boundary ambiguity can arise when:
- two categories share many features;
- the diagnostic features are unclear;
- the item resembles stored examples from more than one category;
- the relevant category depends on context;
- formal rules conflict with everyday usage;
- social or institutional meanings are contested.
This matters because many important real-world concepts are boundary-sensitive. “Disability,” “employment,” “citizenship,” “risk,” “harm,” “consent,” “intelligence,” “species,” “public interest,” and “security” are not merely cognitive labels. They shape rights, resources, accountability, and institutional action.
Concept research therefore matters not only because it explains classification, but because classification affects life chances. How a category is defined can determine what is seen, who is included, and what action becomes possible.
Formalizing concept formation: categorization, similarity, and generalization
Concept formation can be described formally as a mapping from instances to category representations. Let an instance be described by a feature vector \(x = (x_1, x_2, \dots, x_n)\). A categorization function assigns the instance to a concept \(C_k\):
f(x) \rightarrow C_k
\]
Interpretation: A categorization function maps an observed item or situation \(x\) into a concept or category \(C_k\).
One common way of modeling categorization is through similarity to a prototype. If prototype \(p_k\) represents the central tendency of category \(C_k\), then a simple similarity-based assignment can be expressed as:
\hat{C}(x) = \arg\min_k d(x, p_k)
\]
Interpretation: The item is assigned to the category whose prototype is closest in feature space.
Exemplar-based models compare a new item to stored examples rather than to a single summary prototype:
S_k(x) = \sum_{i \in C_k} \exp(-\lambda d(x, x_i))
\]
Interpretation: Category support \(S_k(x)\) increases when an item resembles many stored exemplars from category \(C_k\).
Generalization can also be represented probabilistically. If \(P(C_k \mid x)\) is the probability that item \(x\) belongs to category \(C_k\), then concept learning can be viewed as improving that conditional mapping over time:
P_{t+1}(C_k \mid x) = P_t(C_k \mid x) + \alpha \Delta
\]
Interpretation: Category beliefs update through learning, where \(\alpha\) is a learning rate and \(\Delta\) is the evidence- or feedback-driven change.
Boundary ambiguity can be represented by comparing the two strongest category scores:
B(x)=1-\frac{|S_1(x)-S_2(x)|}{S_1(x)+S_2(x)}
\]
Interpretation: Boundary ambiguity is high when two categories offer nearly equal support for the same item.
These formalizations are simplified, but useful. They show that concept formation can be studied as a structured process involving representation, similarity, feedback, boundary learning, and probabilistic generalization.
Concepts and memory systems
Concepts are stored and organized within long-term memory, especially within semantic memory. Semantic memory contains knowledge about objects, categories, properties, relations, meanings, and facts. Concepts are among its central structures.
When individuals encounter new information, they do not usually begin from nothing. They integrate the new material into existing conceptual frameworks, strengthening some distinctions while revising others. This integration is essential for learning, because new knowledge becomes usable largely by being connected to what is already known.
Concepts also influence memory encoding. Information that fits an existing category is often easier to organize and remember. But category structure can also distort memory when expectations override details. A person may remember what was typical rather than what was actually present. This is one reason concepts can both support and bias cognition.
The relationship between concepts and memory works in both directions. Memory stores concepts, but concepts structure memory. What counts as an event, object, role, tool, exception, danger, or opportunity depends on conceptual organization. Category knowledge helps determine what is noticed, how it is encoded, and how it is later retrieved.
Concept formation therefore provides a bridge between memory and reasoning. It explains how repeated experiences become organized knowledge rather than remaining isolated traces.
Concepts and language
Language plays a major role in concept formation by providing labels that help stabilize, communicate, and refine categories. Words allow individuals to share conceptual distinctions, preserve them culturally, and coordinate understanding across groups.
At the same time, concepts are not reducible to words alone. Individuals can form concepts through perception, action, emotion, social interaction, and experience before they possess explicit linguistic labels for them. Infants and non-human animals can classify aspects of the world without having fully developed language. This suggests that concept formation is broader than vocabulary.
Still, language transforms concept formation in powerful ways. A label can help make a category more stable, more shareable, and more available for reflection. Technical vocabulary allows disciplines to build precise concepts that would be difficult to maintain through perception alone. Legal, scientific, medical, mathematical, and political concepts depend heavily on linguistic and institutional stabilization.
Language also shapes category boundaries. The words available in a language influence how distinctions are commonly made, which categories are socially salient, and how experience is interpreted. This does not mean language determines thought completely. But language gives concepts durable public form.
The relationship between language and concepts is therefore reciprocal. Concepts give language meaning, and language helps concepts become communicable, teachable, contestable, and culturally durable.
Concept formation and mental models
Concepts are among the building blocks of mental models. Concepts classify elements. Mental models organize relations among those elements. Together, they allow individuals to reason about systems, predict outcomes, and understand structured environments.
A concept such as “predator,” “market,” “institution,” “feedback loop,” “risk,” or “public good” does not by itself represent a whole system. But such concepts make it possible to build more complex models in which those elements stand in causal, temporal, functional, social, or institutional relation to one another.
This is why concept formation matters for higher-level cognition. Without concepts, there can be no stable materials out of which larger cognitive structures are built. Without mental models, concepts remain isolated and underused.
For example, a learner may know the concepts “interest rate,” “inflation,” “debt,” and “investment” but still lack a coherent mental model of a financial system. A student may know the concepts “ecosystem,” “species,” “habitat,” and “feedback” but still struggle to reason about ecological change. Concept formation supplies the units; model formation supplies the structure.
Strong reasoning requires both. Concepts make the world classifiable. Mental models make it intelligible as a system.
Concept formation and decision making
Concepts influence decision making by shaping how information is interpreted and which distinctions appear relevant. The categories people use affect what counts as similar, what alternatives are compared, and what information is treated as diagnostic.
This becomes especially important under uncertainty, where individuals often rely on conceptual frameworks to simplify complexity. A decision may change depending on whether a case is categorized as a “threat,” an “opportunity,” a “routine exception,” an “anomaly,” a “failure,” a “tradeoff,” or a “systemic pattern.” Conceptual structure therefore helps determine not only what is known, but how choice itself is framed.
Concepts can support decision making by reducing cognitive burden. They allow people to treat different situations as instances of a known type. But categories can also distort judgment when they are too rigid, too coarse, outdated, or poorly matched to the case at hand.
These processes connect directly to cognitive biases. Stereotypes, framing effects, representativeness judgments, availability effects, and category-based assumptions all depend in part on concept structure. A category can make reasoning efficient, but it can also make mistaken assumptions feel obvious.
Good decision making often requires concept discipline: asking whether the category being used is appropriate, whether relevant differences are being ignored, whether a boundary case is being forced into the wrong frame, and whether a better concept would reveal the problem more accurately.
Development, learning, and conceptual change
Concept formation develops over time. Children begin with early perceptual, functional, and social categories, then gradually refine them through language, feedback, comparison, instruction, and experience. Development is not merely the accumulation of more labels. It is the reorganization of conceptual structure.
Learning can add new concepts, refine existing ones, or transform category boundaries. A child’s early concept of “animal” may be based on movement and appearance. Later, the concept may incorporate biological structure, reproduction, taxonomy, ecology, and evolution. A student’s concept of “force” may begin as an intuitive sense of pushing and pulling, then shift through formal physics education into a more precise scientific relation.
Conceptual change is especially important when prior concepts conflict with more accurate models. Misconceptions are not simply missing information. They are often organized knowledge structures that must be revised. Teaching therefore requires more than presenting correct facts. It requires helping learners reconstruct the conceptual frame that makes those facts meaningful.
Expertise also changes concept formation. Experts do not merely know more examples. They often categorize by deeper structure. A novice may classify physics problems by surface features; an expert may classify them by underlying principles. A novice may classify medical cases by visible symptoms; an expert may classify them by causal mechanisms and diagnostic probabilities.
Concept formation is therefore central to development, education, and expertise. It explains how learning becomes organized enough to transfer beyond the original case.
Social categories, power, and institutional meaning
Concepts are cognitive structures, but they are also social and institutional structures. Many of the categories that shape human life are not natural kinds with simple boundaries. They are produced, maintained, contested, and enforced through language, institutions, law, policy, media, education, and power.
This is especially important for social categories. Concepts such as “citizen,” “worker,” “student,” “patient,” “disabled,” “criminal,” “refugee,” “expert,” “risk,” “merit,” and “public interest” do not merely organize perception. They can determine rights, resources, obligations, recognition, exclusion, and institutional treatment.
Concept formation can therefore never be treated as purely neutral when categories carry social consequences. A category may support care, accountability, and coordination. It may also stigmatize, oversimplify, erase difference, or reproduce unequal power. The same cognitive process that helps the mind classify the world can also become a mechanism through which institutions classify people.
For research and public reasoning, this creates an ethical obligation. We should ask not only whether a category is cognitively efficient, but also whether it is accurate, fair, historically aware, and accountable to those affected by it. Concepts are tools of thought, but some tools cut unevenly.
A serious account of concept formation must therefore include marginalized perspectives, contested categories, and the social consequences of classification. Concepts are not only how individuals think. They are also how societies organize meaning.
Concept formation in artificial intelligence
Concept formation is not limited to human cognition. In artificial intelligence, systems are often designed to learn categories and patterns from data through clustering, classification, representation learning, ontology construction, embedding spaces, rule learning, and related methods. These processes parallel, in broad form, the abstraction and generalization mechanisms seen in human cognition.
Machine-learning systems may learn to classify images, detect anomalies, group documents, identify semantic clusters, recommend content, recognize speech, or infer latent structure from data. These tasks depend on representations that function like learned categories, even when they are not human concepts in the full cognitive and social sense.
The comparison is useful because both human and artificial systems confront the problem of grouping diverse instances into more general representational structures that support prediction and action. But the comparison has limits. Human concepts are shaped by embodiment, language, culture, values, action, development, and social use. Machine categories may reflect training data, optimization objectives, feature spaces, and institutional deployment conditions.
This distinction matters because AI systems can reproduce problematic categories when training data or labels encode social bias. A classifier can appear objective while relying on historically produced categories that are incomplete, harmful, or unequally distributed. Concept formation in AI is therefore not only a technical problem; it is also a governance problem.
Concept research provides a useful bridge between cognitive psychology and computational systems because it asks a foundational question: how should experience be organized into categories that support reliable, flexible, and accountable reasoning?
Concept formation in contemporary research
Current research on concept formation integrates cognitive psychology, neuroscience, developmental psychology, philosophy, linguistics, education, artificial intelligence, and computational modeling. Philosophical work continues to debate what concepts are, how they are structured, whether concepts are mental representations, abilities, abstract objects, or something else, and whether one theory of concepts can explain all the roles concepts play in thought.
Psychological research continues to examine how categories are learned, how prototypes and exemplars interact, how feature diagnosticity changes with expertise, how labels influence category learning, how children acquire concepts, and how conceptual structure supports reasoning and communication. Cognitive neuroscience examines how conceptual knowledge is represented across distributed brain systems and how different kinds of concepts depend on perceptual, motor, linguistic, and integrative regions.
Computational research adds models of category learning, clustering, representation learning, Bayesian generalization, neural networks, knowledge graphs, and embedding spaces. These models help clarify what kinds of structure can be learned from examples, how boundary cases are handled, and why generalization sometimes succeeds or fails.
Across these traditions, one point remains stable: concepts are dynamic rather than static. They are refined through experience, reorganized through learning, shaped by language, and continually reshaped by the environments in which they are used.
Concept formation remains central because it sits at the intersection of perception, memory, language, reasoning, social meaning, and action. It explains how the mind moves from the particular to the general — and how the general then shapes every new particular the mind encounters.
R code for concept-formation data
The following R workflow illustrates analyses relevant to concept-formation research, including categorization accuracy, prototype-distance effects, exemplar similarity, generalization, discrimination, abstraction quality, conceptual flexibility, and response time.
# Install packages if needed:
# pak::pak(c("tidyverse", "lme4", "lmerTest", "emmeans", "broom.mixed"))
library(tidyverse)
library(lme4)
library(lmerTest)
library(emmeans)
library(broom.mixed)
# Expected columns:
# participant, condition, stimulus_id, category_label,
# prototype_distance, nearest_competing_distance,
# exemplar_similarity, feature_diagnosticity, feature_overlap,
# boundary_ambiguity, rule_consistency, feedback_available,
# category_accuracy, generalization_score, discrimination_score,
# abstraction_quality, conceptual_flexibility, confidence,
# response_time_ms
dat <- read_csv("concept_formation_trials.csv") %>%
mutate(
participant = factor(participant),
condition = factor(condition),
stimulus_id = factor(stimulus_id),
category_label = factor(category_label),
feedback_available = as.integer(feedback_available),
category_accuracy = as.integer(category_accuracy),
log_response_time = log(response_time_ms)
)
# -----------------------------
# 1. Descriptive profile
# -----------------------------
condition_summary <- dat %>%
group_by(condition) %>%
summarise(
n_trials = n(),
participants = n_distinct(participant),
mean_prototype_distance = mean(prototype_distance, na.rm = TRUE),
mean_competing_distance = mean(nearest_competing_distance, na.rm = TRUE),
mean_exemplar_similarity = mean(exemplar_similarity, na.rm = TRUE),
mean_feature_diagnosticity = mean(feature_diagnosticity, na.rm = TRUE),
mean_boundary_ambiguity = mean(boundary_ambiguity, na.rm = TRUE),
mean_rule_consistency = mean(rule_consistency, na.rm = TRUE),
feedback_rate = mean(feedback_available, na.rm = TRUE),
accuracy_rate = mean(category_accuracy, na.rm = TRUE),
mean_generalization = mean(generalization_score, na.rm = TRUE),
mean_discrimination = mean(discrimination_score, na.rm = TRUE),
mean_abstraction_quality = mean(abstraction_quality, na.rm = TRUE),
mean_conceptual_flexibility = mean(conceptual_flexibility, na.rm = TRUE),
mean_confidence = mean(confidence, na.rm = TRUE),
mean_response_time_ms = mean(response_time_ms, na.rm = TRUE),
.groups = "drop"
)
print(condition_summary)
# -----------------------------
# 2. Categorization accuracy model
# -----------------------------
accuracy_model <- glmer(
category_accuracy ~
condition +
category_label +
prototype_distance +
nearest_competing_distance +
exemplar_similarity +
feature_diagnosticity +
feature_overlap +
boundary_ambiguity +
rule_consistency +
feedback_available +
(1 | participant) +
(1 | stimulus_id),
data = dat,
family = binomial(),
control = glmerControl(optimizer = "bobyqa")
)
summary(accuracy_model)
emmeans(accuracy_model, ~ condition, type = "response")
# -----------------------------
# 3. Generalization model
# -----------------------------
generalization_model <- lmer(
generalization_score ~
condition +
prototype_distance +
exemplar_similarity +
feature_diagnosticity +
boundary_ambiguity +
rule_consistency +
category_accuracy +
abstraction_quality +
conceptual_flexibility +
(1 | participant) +
(1 | stimulus_id),
data = dat,
REML = FALSE
)
summary(generalization_model)
emmeans(generalization_model, ~ condition)
# -----------------------------
# 4. Discrimination model
# -----------------------------
discrimination_model <- lmer(
discrimination_score ~
condition +
prototype_distance +
nearest_competing_distance +
feature_diagnosticity +
boundary_ambiguity +
rule_consistency +
category_accuracy +
(1 | participant) +
(1 | stimulus_id),
data = dat,
REML = FALSE
)
summary(discrimination_model)
emmeans(discrimination_model, ~ condition)
# -----------------------------
# 5. Abstraction-quality model
# -----------------------------
abstraction_model <- lmer(
abstraction_quality ~
condition +
feature_diagnosticity +
rule_consistency +
feedback_available +
category_accuracy +
boundary_ambiguity +
prototype_distance +
(1 | participant) +
(1 | stimulus_id),
data = dat,
REML = FALSE
)
summary(abstraction_model)
# -----------------------------
# 6. Response-time model
# -----------------------------
rt_model <- lmer(
log_response_time ~
condition +
prototype_distance +
boundary_ambiguity +
exemplar_similarity +
feature_diagnosticity +
rule_consistency +
category_accuracy +
(1 | participant) +
(1 | stimulus_id),
data = dat,
REML = FALSE
)
summary(rt_model)
# -----------------------------
# 7. Visualization
# -----------------------------
ggplot(dat, aes(x = prototype_distance, y = generalization_score, color = condition)) +
geom_point(alpha = 0.25) +
geom_smooth(method = "lm", se = FALSE) +
labs(
title = "Prototype distance and conceptual generalization",
x = "Prototype distance",
y = "Generalization score"
) +
theme_minimal()This workflow can be adapted for prototype-distance studies, exemplar-learning experiments, category-boundary tasks, rule-versus-similarity comparisons, feedback-learning studies, conceptual-change interventions, developmental categorization research, or human-AI comparisons of category learning. Researchers should model participant and stimulus effects whenever possible because categorization tasks vary strongly in item difficulty, boundary ambiguity, and prior familiarity.
Python code for concept-formation data
The Python examples below parallel the R workflow and are useful for categorization studies, prototype effects, exemplar similarity, generalization experiments, boundary ambiguity, concept revision, and response-time modeling.
import numpy as np
import pandas as pd
import statsmodels.formula.api as smf
import statsmodels.api as sm
import matplotlib.pyplot as plt
# Expected columns:
# participant, condition, stimulus_id, category_label,
# prototype_distance, nearest_competing_distance,
# exemplar_similarity, feature_diagnosticity, feature_overlap,
# boundary_ambiguity, rule_consistency, feedback_available,
# category_accuracy, generalization_score, discrimination_score,
# abstraction_quality, conceptual_flexibility, confidence,
# response_time_ms
df = pd.read_csv("concept_formation_trials.csv")
categorical_cols = [
"participant",
"condition",
"stimulus_id",
"category_label",
]
for col in categorical_cols:
df[col] = df[col].astype("category")
df["feedback_available"] = df["feedback_available"].astype(int)
df["category_accuracy"] = df["category_accuracy"].astype(int)
df["log_response_time"] = np.log(df["response_time_ms"])
# -----------------------------
# 1. Descriptive profile
# -----------------------------
condition_summary = (
df.groupby("condition")
.agg(
n_trials=("category_accuracy", "size"),
participants=("participant", "nunique"),
mean_prototype_distance=("prototype_distance", "mean"),
mean_competing_distance=("nearest_competing_distance", "mean"),
mean_exemplar_similarity=("exemplar_similarity", "mean"),
mean_feature_diagnosticity=("feature_diagnosticity", "mean"),
mean_boundary_ambiguity=("boundary_ambiguity", "mean"),
mean_rule_consistency=("rule_consistency", "mean"),
feedback_rate=("feedback_available", "mean"),
accuracy_rate=("category_accuracy", "mean"),
mean_generalization=("generalization_score", "mean"),
mean_discrimination=("discrimination_score", "mean"),
mean_abstraction_quality=("abstraction_quality", "mean"),
mean_conceptual_flexibility=("conceptual_flexibility", "mean"),
mean_confidence=("confidence", "mean"),
mean_response_time_ms=("response_time_ms", "mean"),
)
.reset_index()
)
print(condition_summary)
# -----------------------------
# 2. Categorization accuracy model
# -----------------------------
accuracy_model = smf.glm(
"category_accuracy ~ condition + category_label + prototype_distance "
"+ nearest_competing_distance + exemplar_similarity + feature_diagnosticity "
"+ feature_overlap + boundary_ambiguity + rule_consistency + feedback_available",
data=df,
family=sm.families.Binomial(),
)
accuracy_result = accuracy_model.fit(
cov_type="cluster",
cov_kwds={"groups": df["participant"]},
)
print(accuracy_result.summary())
# -----------------------------
# 3. Generalization model
# -----------------------------
generalization_model = smf.ols(
"generalization_score ~ condition + prototype_distance + exemplar_similarity "
"+ feature_diagnosticity + boundary_ambiguity + rule_consistency "
"+ category_accuracy + abstraction_quality + conceptual_flexibility",
data=df,
)
generalization_result = generalization_model.fit(
cov_type="cluster",
cov_kwds={"groups": df["participant"]},
)
print(generalization_result.summary())
# -----------------------------
# 4. Discrimination model
# -----------------------------
discrimination_model = smf.ols(
"discrimination_score ~ condition + prototype_distance "
"+ nearest_competing_distance + feature_diagnosticity "
"+ boundary_ambiguity + rule_consistency + category_accuracy",
data=df,
)
discrimination_result = discrimination_model.fit(
cov_type="cluster",
cov_kwds={"groups": df["participant"]},
)
print(discrimination_result.summary())
# -----------------------------
# 5. Abstraction-quality model
# -----------------------------
abstraction_model = smf.ols(
"abstraction_quality ~ condition + feature_diagnosticity "
"+ rule_consistency + feedback_available + category_accuracy "
"+ boundary_ambiguity + prototype_distance",
data=df,
)
abstraction_result = abstraction_model.fit(
cov_type="cluster",
cov_kwds={"groups": df["participant"]},
)
print(abstraction_result.summary())
# -----------------------------
# 6. Response-time model
# -----------------------------
rt_model = smf.ols(
"log_response_time ~ condition + prototype_distance + boundary_ambiguity "
"+ exemplar_similarity + feature_diagnosticity + rule_consistency "
"+ category_accuracy",
data=df,
)
rt_result = rt_model.fit(
cov_type="cluster",
cov_kwds={"groups": df["participant"]},
)
print(rt_result.summary())
# -----------------------------
# 7. Visualization
# -----------------------------
fig, ax = plt.subplots(figsize=(8, 5))
for condition, group in df.groupby("condition"):
ax.scatter(
group["prototype_distance"],
group["generalization_score"],
alpha=0.35,
label=str(condition),
)
ax.set_xlabel("Prototype distance")
ax.set_ylabel("Generalization score")
ax.set_title("Prototype distance and conceptual generalization")
ax.legend(title="Condition")
plt.tight_layout()
plt.show()The Python workflow is intentionally transparent and extensible. It can be expanded with Bayesian category-learning models, prototype/exemplar model comparison, clustering algorithms, embedding-based concept representations, reinforcement-learning accounts of feedback, developmental category-learning tasks, or human-AI comparisons of abstraction and generalization.
GitHub Repository
The companion repository provides reusable code and research scaffolding for studying concept formation in cognitive psychology, including workflows for categorization accuracy, prototype-distance effects, exemplar similarity, boundary ambiguity, feature diagnosticity, generalization, discrimination, abstraction quality, conceptual flexibility, response-time modeling, and computational category-learning simulation.
Complete Code Repository
Access the full companion repository for this article, including reproducible analysis materials and multi-language code workflows for concept-formation and categorization research.
Applications of concept research
Concept research matters across education, scientific reasoning, design, interface development, machine learning, clinical assessment, public communication, legal reasoning, and institutional governance. It helps explain how people recognize patterns, classify ambiguity, learn categories, and distinguish meaningful structure from superficial variation.
In education, concept research helps explain why examples, contrasts, feedback, and boundary cases are essential for deep learning. Students do not simply need definitions; they need opportunities to see what belongs, what does not belong, what is central, what is peripheral, and what changes when the concept is used in a new context.
In science and engineering, concept formation supports theory building, model construction, classification, diagnosis, and design. New discoveries often require new concepts, because old categories cannot always organize new evidence. In medicine, law, policy, and public administration, category definitions can determine diagnosis, eligibility, liability, protection, and resource allocation.
In artificial intelligence and interface design, concept research helps evaluate whether categories are useful, interpretable, fair, and robust. A system that classifies well on familiar cases may still fail on boundary cases, marginalized cases, or cases that reveal the limits of its learned representation.
These applications matter because concepts are among the most basic tools of thought. They make it possible to move from isolated cases to general knowledge, and from general knowledge to flexible reasoning. But because categories guide action, they must be examined as carefully as they are used.
Conclusion
Concept formation refers to the processes through which the mind groups experience into categories that support abstraction, generalization, discrimination, prediction, communication, and efficient reasoning. Concepts reduce complexity by organizing information into structured classes that make learning, inference, and decision making possible.
Cognitive psychology shows that concepts are not static labels but dynamic representations shaped by abstraction, experience, language, memory, feedback, culture, and context. Understanding concept formation therefore helps explain how minds build general knowledge from particular encounters and how structured thought becomes possible at all.
The central lesson is that concepts do not merely describe the world. They organize the world for thought. To understand cognition, we must understand how categories are formed, how they are used, how they change, and how they sometimes need to be challenged.
Related articles
- Cognitive Psychology
- Semantic Memory in Cognitive Psychology
- Memory in Cognitive Psychology
- Language Processing in Cognitive Psychology
- Perception in Cognitive Psychology
- Cognitive Learning Processes
- Mental Models in Cognitive Psychology
- Analogical Reasoning and Knowledge Transfer
- Decision Making in Cognitive Psychology
Further reading
- American Psychological Association (n.d.) Conceptualization. APA Dictionary of Psychology. Available at: https://dictionary.apa.org/conceptualization.
- Margolis, E. and Laurence, S. (2023) ‘Concepts’, Stanford Encyclopedia of Philosophy. Available at: https://plato.stanford.edu/entries/concepts/.
- Murphy, G.L. (2002) The Big Book of Concepts. Cambridge, MA: MIT Press. Available at: https://mitpress.mit.edu/9780262632997/the-big-book-of-concepts/.
- Rosch, E. (1978) ‘Principles of categorization’, in Rosch, E. and Lloyd, B.B. (eds.) Cognition and Categorization. Hillsdale, NJ: Lawrence Erlbaum, pp. 27–48.
- UC Berkeley Department of Psychology (n.d.) Eleanor H. Rosch. Available at: https://psychology.berkeley.edu/people/eleanor-h-rosch.
- Smith, E.E. and Medin, D.L. (1981) Categories and Concepts. Cambridge, MA: Harvard University Press.
References
- American Psychological Association (n.d.) Conceptualization. APA Dictionary of Psychology. Available at: https://dictionary.apa.org/conceptualization.
- Margolis, E. and Laurence, S. (2023) ‘Concepts’, Stanford Encyclopedia of Philosophy. Available at: https://plato.stanford.edu/entries/concepts/.
- Murphy, G.L. (2002) The Big Book of Concepts. Cambridge, MA: MIT Press. Available at: https://mitpress.mit.edu/9780262632997/the-big-book-of-concepts/.
- Rosch, E. (1978) ‘Principles of categorization’, in Rosch, E. and Lloyd, B.B. (eds.) Cognition and Categorization. Hillsdale, NJ: Lawrence Erlbaum, pp. 27–48.
- Smith, E.E. and Medin, D.L. (1981) Categories and Concepts. Cambridge, MA: Harvard University Press.
- UC Berkeley Department of Psychology (n.d.) Eleanor H. Rosch. Available at: https://psychology.berkeley.edu/people/eleanor-h-rosch.