
Last Updated May 20, 2026
Decision making is the process through which the mind evaluates alternatives, represents uncertainty, assigns value, accumulates evidence, and selects actions under conditions of constraint. In cognitive psychology, decision making is not treated as a perfectly rational calculation carried out in an unlimited mental space. It is understood instead as a bounded, adaptive, affectively informed, and resource-limited process shaped by attention, perception, memory, working memory, emotion, prior experience, institutional context, and environmental structure. It is one of the central mechanisms through which cognition becomes behavior.
Decision making operates at the intersection of multiple cognitive systems. Attention determines which information is considered. Perception structures incoming data. Memory provides prior experience and learned patterns. Working memory allows alternatives to be held in mind, compared, and manipulated in real time. Emotion gives salience, urgency, and value to possible outcomes. Together, these systems form a decision architecture through which individuals act in uncertain and changing environments.
From this perspective, decision making is not a single isolated faculty. It is a coordination problem. The mind must determine what information matters, how much effort to invest, which outcomes are plausible, what uncertainty remains, which values are at stake, when further search is useful, and when to stop deliberating and act. Research across cognitive psychology, behavioral economics, decision theory, philosophy, neuroscience, human factors, and artificial intelligence has shown that decisions are shaped at least as much by constraints as by preferences. Human choice is not simply what people want. It is what people can represent, compare, value, and act upon under limited time, limited attention, limited memory, incomplete evidence, and unequal environments.
Main Library
Publications
Article Map
Cognitive Psychology
Related Topic
Behavioral Economics
Related Topic
Artificial Intelligence Systems
Related Topic
Data Systems & Analytics
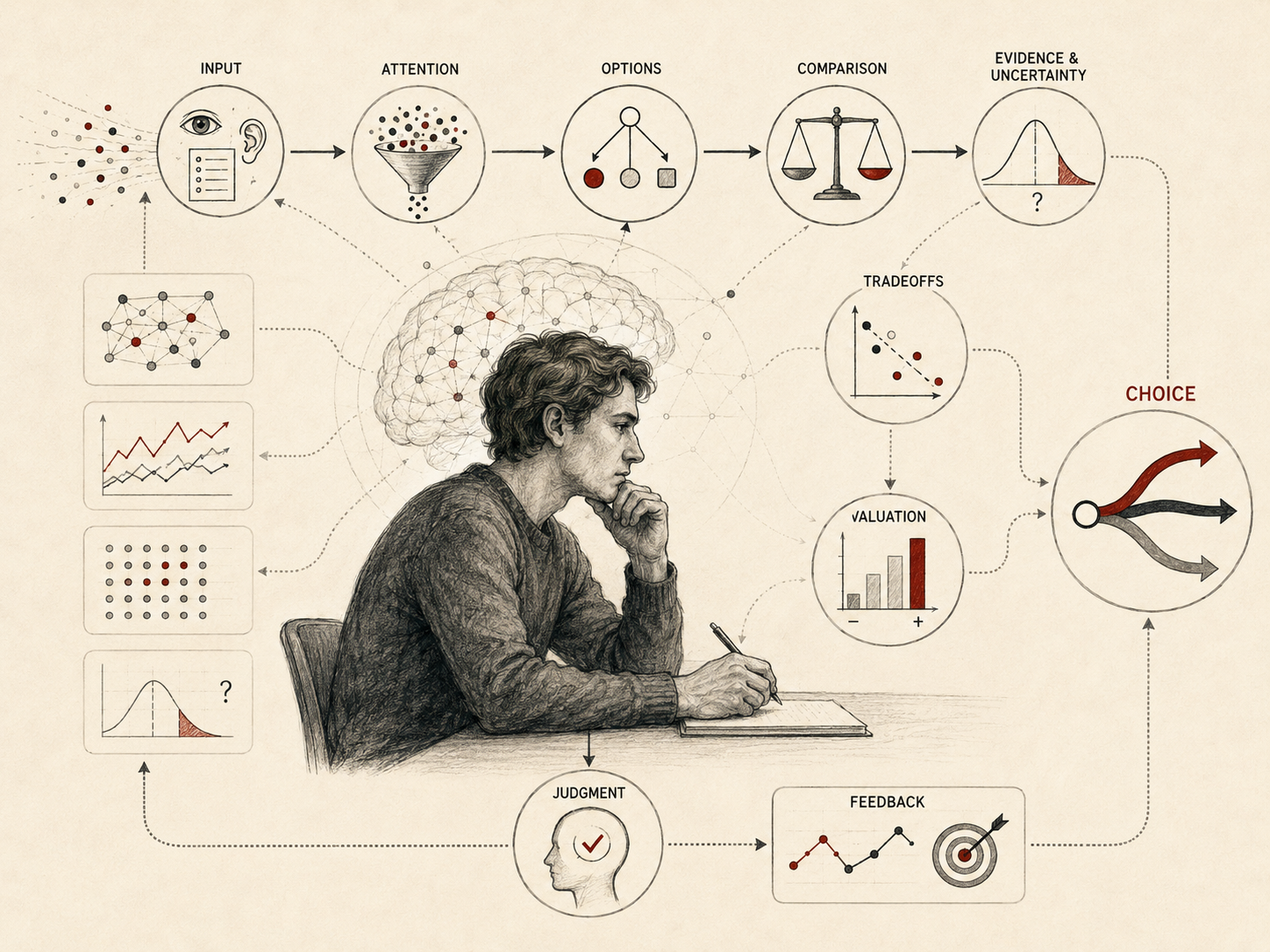
Decision making matters because it is where internal cognition meets consequence. A decision is not merely a thought. It is a commitment to action, delay, avoidance, search, trust, risk, care, investment, diagnosis, policy, or judgment. Every decision rests on a partial representation of the world, and every representation is shaped by cognitive architecture.
What is decision making?
Decision making refers to the processes through which individuals select actions among competing alternatives. At a minimum, this involves identifying possible options, estimating likely outcomes, representing uncertainty and risk, weighing trade-offs, and selecting a course of action. Even this description understates the complexity of the process because real-world decisions rarely involve complete information, unlimited time, or stable preferences.
Most decisions are made under pressure, partial knowledge, shifting goals, incomplete feedback, and finite cognitive capacity. A person may not know all available alternatives. The consequences may be delayed. The relevant probabilities may be uncertain. The available information may be ambiguous, misleading, or socially filtered. Emotional stakes may change what feels salient. Institutional rules may shape which options are possible at all.
For that reason, decision making is better understood not as pure optimization but as adaptive cognition under constraint. The mind tries to make usable choices in environments where full calculation is often impossible. A decision may therefore be rational in a bounded sense even when it does not satisfy idealized standards of complete optimization.
Decision making includes several interlocking subprocesses:
- Problem representation — defining what the decision is about.
- Option generation — identifying possible actions.
- Outcome estimation — imagining what may follow from each option.
- Probability assessment — judging likelihood, risk, ambiguity, or uncertainty.
- Value assignment — determining what outcomes matter and how much.
- Evidence accumulation — gathering and integrating information over time.
- Choice selection — committing to an action or non-action.
- Feedback integration — learning from outcomes after the decision.
These subprocesses do not always occur in sequence. In many real decisions, they are iterative, compressed, interrupted, socially negotiated, or guided by habit. A person may begin with an intuitive preference, search for evidence, revise the problem, imagine consequences, become uncertain, and return to the original option. Decision making is often a dynamic process rather than a single mental event.
Decision making as a cognitive system
Decision making emerges from the interaction of multiple cognitive systems rather than from a single isolated mechanism. Attention filters relevant information. Working memory maintains and compares alternatives. Memory supplies prior knowledge and learned patterns. Problem solving structures how alternatives are generated and evaluated. Emotion assigns salience and urgency. Metacognition evaluates confidence and uncertainty.
This interaction creates a functional architecture in which decisions are constructed rather than merely calculated. The quality of a decision depends not only on the options available, but on how those options are represented, compared, valued, and constrained within the mind.
A choice can fail because of poor information, but it can also fail because attention was misallocated, because memory supplied an unrepresentative comparison, because working memory could not sustain a sufficiently complex evaluation, because emotion made one outcome disproportionately salient, or because the environment framed the decision in a misleading way.
Decision making therefore depends on several forms of constraint:
- Attentional constraint — only some information is selected.
- Memory constraint — prior experience is incomplete and reconstructive.
- Working-memory constraint — only a limited number of elements can be compared at once.
- Time constraint — decisions often must be made before uncertainty is resolved.
- Information constraint — relevant evidence may be unavailable, costly, hidden, or unreliable.
- Affective constraint — fear, hope, anger, trust, anxiety, and regret shape evaluation.
- Institutional constraint — rules, forms, defaults, eligibility systems, and authority structures shape options.
From this perspective, decision making is a systems-level phenomenon. It reflects not only preference, but the structure and limits of cognition itself. A person’s decision may reveal what they value, but it also reveals what they could perceive, remember, compare, trust, imagine, and afford to evaluate.
Classical models of decision making
Many early formal models of decision making came from economics, probability theory, and philosophy. Expected value theory proposed that rational agents should select the option with the highest probability-weighted outcome. Expected utility theory refined this by recognizing that subjective utility need not increase linearly with objective payoff. These frameworks remain important because they provide mathematically explicit accounts of what choice would look like under idealized rational conditions.
Decision theory, in the philosophical sense, is concerned with the reasoning underlying an agent’s choices. It provides normative tools for evaluating how agents ought to decide when probabilities, utilities, preferences, and alternatives are defined. This is valuable because it clarifies what rational consistency, expected utility, dominance, and preference ordering would require under formal assumptions.
However, classical models often assume conditions that are rarely available in real life:
- complete or sufficiently well-defined information;
- substantial computational capacity;
- stable and internally consistent preferences;
- well-formed probabilities;
- clear option sets;
- known outcomes;
- feedback that accurately reveals decision quality.
Cognitive psychology has shown that these assumptions often fail in practice. Human beings rely on approximations, shortcuts, affective signals, satisficing strategies, social cues, and learned patterns that trade strict optimality for speed, tractability, and resource conservation.
This shift — from idealized rational choice to realistic cognition under limitation — marks one of the most important developments in modern decision research. Judgment-and-decision research commonly distinguishes among normative models, which specify how decisions should be made under formal assumptions; descriptive models, which explain how people actually decide; and prescriptive models, which aim to help people and institutions decide better.
The strongest decision research does not discard formal models. It uses them carefully. Normative models provide benchmarks. Descriptive models explain actual behavior. Prescriptive models redesign decision environments so that bounded agents can make better choices under real constraints.
Formalizing choice: utility, uncertainty, and evidence
Several core ideas in decision making can be expressed formally. In a classical expected-value formulation, an option \(i\) with possible outcomes \(x_j\) and associated probabilities \(p_j\) can be evaluated as:
EV_i=\sum_{j=1}^{n}p_jx_j
\]
Interpretation: Expected value \(EV_i\) is the probability-weighted sum of possible outcomes for option \(i\).
Expected utility theory replaces raw outcomes with subjective utility:
EU_i=\sum_{j=1}^{n}p_ju(x_j)
\]
Interpretation: Expected utility \(EU_i\) recognizes that psychological or practical value \(u(x_j)\) may not increase linearly with objective payoff.
Prospect theory further modifies this picture by distinguishing gains from losses and weighting outcomes relative to a reference point. A simplified value function can be written as:
v(x)=
\begin{cases}
x^{\alpha}, & x\geq 0\\
-\lambda(-x)^{\beta}, & x<0
\end{cases}
\]
Interpretation: When \(\lambda>1\), losses carry greater psychological weight than equivalent gains.
Subjective value under risk can be represented as:
SV=\sum_{j=1}^{n}w(p_j)v(x_j-r)
\]
Interpretation: Subjective value \(SV\) depends on psychologically weighted probabilities \(w(p_j)\), subjective value \(v(\cdot)\), and reference point \(r\).
A common probability-weighting function can be written as:
w(p)=\frac{p^{\gamma}}{\left(p^{\gamma}+(1-p)^{\gamma}\right)^{1/\gamma}}
\]
Interpretation: Probability weighting captures the possibility that objective probabilities are not treated linearly in subjective judgment.
Decision processes can also be modeled as evidence accumulation over time. In a drift-diffusion form, a decision variable \(x_t\) evolves as:
dx_t=v\,dt+s\,dW_t
\]
Interpretation: Evidence accumulates with drift rate \(v\), noise scale \(s\), and stochastic fluctuation \(dW_t\) until a decision threshold is reached.
A choice rule can then be expressed as:
\text{choose } A \text{ if } x_t\geq a,\qquad \text{choose } B \text{ if } x_t\leq -a
\]
Interpretation: A response occurs when accumulated evidence crosses a positive or negative threshold.
These formal models are useful because they connect observable behavior — choice, accuracy, confidence, and response time — to latent decision processes such as valuation, probability weighting, evidence strength, uncertainty, and threshold setting.
Bounded rationality
Herbert Simon’s concept of bounded rationality reframed decision making as a process constrained by limited information, limited cognitive capacity, limited time, and limited search. Rather than assuming that people optimize across all possible options, Simon argued that they often satisfice: they seek an option that is good enough relative to current constraints rather than the best imaginable option.
This framework aligns closely with what cognitive psychology has shown about working memory, attention, and information-processing limits. Rationality is not absent, but it is bounded by the architecture of the system that must carry it out.
In practice, bounded rationality explains why people:
- stop searching once acceptable criteria are met;
- use simplifying rules rather than complete comparison;
- prefer familiar or default options under load;
- choose faster when time pressure rises;
- rely on expertise and pattern recognition when available;
- avoid complex comparisons when information costs are high;
- accept locally sufficient solutions rather than globally optimal ones.
Bounded rationality does not imply irrationality. It implies that rational action must be understood relative to the resources available to the agent. A decision can be reasonable under severe uncertainty even if it would not be optimal under full information.
This distinction matters ethically and institutionally. When people make poor choices in overloaded systems, the explanation may not lie only in individual failure. It may lie in the decision environment. A public-benefit form, medical portal, financial product, legal process, or digital interface can impose so much cognitive burden that “choice” becomes formally available but practically constrained.
Bounded rationality therefore connects cognitive psychology to organizational design, public policy, interface design, and institutional justice.
Dual-process accounts
Dual-process accounts distinguish between two broad modes of cognition. Fast, automatic, intuitive processing supports rapid decisions through pattern recognition, learned associations, emotional appraisal, and habit. Slower, more deliberate reasoning supports analysis when novelty, ambiguity, conflict, or complexity requires effortful evaluation.
These systems are often described as:
- System 1 — fast, automatic, intuitive, associative, and often effortless.
- System 2 — slower, more deliberate, more rule-based, and more effortful.
The value of this framework lies less in the exact numbering than in the broader insight that decision making balances speed and effort. Not every choice can be deliberated fully. Not every intuitive judgment is wrong. Not every analytic judgment is correct.
Fast intuitive processes often generate initial impressions that slower reasoning may later evaluate, endorse, modify, or reject. In some domains, fast pattern recognition reflects genuine expertise. In others, it reflects stereotypes, familiarity, availability, or misleading salience. Slow reasoning can correct intuitive error, but it can also rationalize prior preferences or become overloaded by complexity.
A mature decision theory therefore asks not whether intuition or deliberation is superior in the abstract. It asks which mode is appropriate for the task, evidence structure, stakes, uncertainty, feedback environment, and expertise level.
Heuristics and cognitive bias
Because cognitive resources are limited, individuals rely on heuristics: mental shortcuts that simplify decision making. Heuristics allow people to act without exhaustively evaluating every possible outcome, probability, cue, or alternative.
Common heuristics include:
- Availability — judging frequency or probability by ease of recall.
- Representativeness — judging likelihood by similarity to familiar patterns.
- Anchoring — relying heavily on an initial reference point.
- Affect — using emotional response as a cue for risk or benefit.
- Recognition — treating familiar options as more likely, important, or credible.
- Fluency — treating easily processed information as more trustworthy or valuable.
These heuristics can be efficient, but they can also produce cognitive biases. Research by Tversky and Kahneman showed that these errors are not random noise. They are structured by the way cognition simplifies complex judgments under uncertainty. This work helped lay the foundation for behavioral economics and reshaped how economists and psychologists understand real choice.
Heuristics are therefore best understood not simply as flaws, but as adaptive shortcuts whose success depends on the environment, the task, and the cost of further deliberation. A heuristic can be useful when it tracks valid structure. It becomes dangerous when salience, familiarity, framing, or affect substitutes for evidence.
This distinction is essential in applied decision design. The goal should not be to eliminate heuristics. The goal should be to design environments where useful shortcuts are supported and misleading shortcuts are less likely to control high-stakes choices.
Decision making under uncertainty
Most real-world decisions occur under uncertainty. Outcomes cannot be known with certainty, and probabilities are often incomplete, ambiguous, contested, or only loosely estimated. Under these conditions, framing, reference points, emotional salience, prior experience, and trust all become influential.
Uncertainty differs from simple risk. In risk, probabilities may be known or estimable. In uncertainty, probabilities may be unclear. In ambiguity, even the structure of the problem may be unstable or disputed. Many important decisions — medical diagnosis, public policy, climate adaptation, legal judgment, organizational strategy, financial planning, disaster response, AI deployment — involve uncertainty rather than cleanly known probabilities.
Under uncertainty, people may rely on:
- available examples;
- trusted authorities;
- prior experience;
- default options;
- narrative coherence;
- emotional salience;
- social proof;
- institutional rules;
- risk tolerance;
- simple stopping criteria.
Prospect theory showed that individuals evaluate gains and losses asymmetrically. Losses tend to carry greater psychological weight than equivalent gains, and judgments depend heavily on how options are framed relative to a perceived baseline. This insight revealed that decision making is shaped not only by objective outcomes, but by subjective representation.
Current research has also pushed further by asking how decision making operates in natural environments where information is partial, consequences unfold across time, feedback may be delayed, and perfect optimization is unrealistic. Ecologically realistic decision making requires principles that fit real environments rather than idealized laboratory abstraction alone.
Evidence accumulation and response time
Decision making is not only about which option is chosen. It is also about how evidence accumulates over time before a response. Evidence-accumulation models, including drift-diffusion models, connect choices and response times to latent decision dynamics.
In a two-choice decision, evidence may accumulate toward one boundary or another. Stronger evidence generally produces faster and more accurate choices. Higher decision thresholds produce slower but often more cautious decisions. Greater noise produces more variability. Time pressure may lower thresholds and increase speed at the cost of accuracy.
Evidence-accumulation models are useful because they help separate several processes that can look similar in raw behavior:
- Drift rate — how quickly evidence favors one option.
- Threshold — how much evidence is required before responding.
- Noise — variability in evidence accumulation.
- Starting point — prior bias toward one option.
- Nondecision time — perceptual and motor processes outside the decision itself.
Two people may have the same accuracy but different response-time profiles. One may decide quickly because evidence is clear. Another may decide quickly because the threshold is low. One may be slow because evidence is ambiguous. Another may be slow because they are cautious. Evidence-accumulation models help distinguish these possibilities.
This matters in cognitive psychology, neuroscience, human factors, medical decision making, interface design, and AI decision support. Response time is not merely a convenience measure. It is evidence about the temporal structure of cognition.
Emotion, value, and affective appraisal
Decision making is both cognitive and affective. Emotion is not simply noise interfering with rational evaluation. It can distort judgment, but it can also guide adaptive action by encoding salience, urgency, danger, reward, trust, loss, and social meaning.
Emotions shape decisions through several pathways:
- Attention — emotional cues capture focus.
- Valuation — feelings alter perceived benefit and risk.
- Memory — emotionally charged events are often more available.
- Risk perception — fear, anger, hope, and trust alter uncertainty judgments.
- Time horizon — anxiety and urgency can shorten deliberation.
- Social evaluation — shame, guilt, pride, and loyalty influence choices.
- Regret anticipation — imagined future regret can shape present action.
Emotion can improve decisions when it signals genuine importance. A physician’s unease, an engineer’s concern, a parent’s alarm, or a community’s distrust may reflect learned patterns that deserve attention. But emotion can also mislead when fear, anger, familiarity, or vividness substitutes for evidence.
Good decision systems should therefore neither suppress emotion nor surrender to it. They should make room for affective information while requiring structured evidence, uncertainty representation, and reflective review when stakes are high.
Feedback, learning, and regret
Decision making changes through feedback. People learn from outcomes, revise expectations, adjust confidence, and change future strategies. But feedback is often delayed, noisy, incomplete, biased, or absent. This makes decision learning difficult.
A person may make a good decision that produces a bad outcome because uncertainty was unavoidable. Another may make a poor decision that happens to succeed. If feedback is interpreted only through outcomes, decision quality can be mislearned. This is the problem of outcome bias.
Regret also shapes decision learning. Regret can motivate better future decisions, but it can also produce avoidance, excessive caution, or distorted memory. Anticipated regret may influence decisions before outcomes occur, especially in domains involving health, finance, relationships, legal risk, and public responsibility.
Decision learning depends on several conditions:
- clear feedback;
- repeated comparable decisions;
- valid cues;
- timely outcomes;
- ability to distinguish process quality from luck;
- records of pre-decision uncertainty;
- psychological safety to acknowledge error;
- institutional incentives that reward learning rather than blame avoidance.
In many important domains, these conditions are weak. Policy decisions may take years to evaluate. Medical decisions may have ambiguous causes. Organizational decisions may be narrated politically after the fact. AI-assisted decisions may obscure who contributed what. For these reasons, decision research must study not only choice but feedback architecture.
Naturalistic decision making
Naturalistic decision making studies how people make decisions in real environments rather than only in simplified laboratory tasks. This tradition is especially important for understanding firefighters, clinicians, pilots, military personnel, emergency managers, engineers, judges, social workers, infrastructure operators, and other professionals who must decide under pressure, uncertainty, and consequence.
Naturalistic decision environments often involve:
- ill-defined problems;
- changing conditions;
- time pressure;
- high stakes;
- multiple goals;
- organizational constraints;
- uncertain feedback;
- distributed teams;
- expert pattern recognition;
- incomplete or conflicting evidence.
In these settings, decision making often depends on recognition, simulation, and action readiness. Experts may not compare many options explicitly. They may recognize a situation as similar to prior cases, mentally simulate a plausible course of action, and act if it appears workable.
This does not mean naturalistic decisions are automatically good. Expertise depends on valid cues, practice, and feedback. In domains where feedback is poor or cues are misleading, intuition may be overconfident. But naturalistic decision research shows why idealized optimization is often an unrealistic model of high-stakes cognition.
A complete cognitive psychology of decision making must therefore include both laboratory precision and real-world complexity.
Social and institutional decision making
Decision making is often treated as an individual cognitive process, but many decisions are social and institutional. People decide inside families, teams, workplaces, courts, hospitals, schools, agencies, markets, platforms, and public systems. These environments shape what information is available, who is credible, what options are legitimate, and which consequences matter.
Social decision making involves trust, authority, identity, status, norms, persuasion, group membership, and accountability. Institutions create procedures, metrics, categories, defaults, incentives, and review systems. These structures can improve decisions by distributing knowledge and reducing individual error. They can also amplify error by suppressing dissent, rewarding conformity, or embedding biased assumptions into procedure.
Common institutional decision risks include:
- over-reliance on familiar categories;
- failure to include affected communities;
- hidden defaults that shape outcomes;
- metrics that become targets;
- authority bias;
- fragmented responsibility;
- poor appeal mechanisms;
- unequal access to information;
- decision fatigue among people navigating complex systems.
Decision quality therefore depends not only on individual cognition but on decision architecture. A well-designed institution can reduce cognitive burden, preserve dissent, track uncertainty, require justification, and monitor outcomes. A poorly designed institution can make error predictable and then blame individuals for failing to navigate the system.
Decision making and artificial intelligence systems
Artificial intelligence systems increasingly participate in decision environments. They recommend actions, rank options, summarize evidence, estimate risk, classify cases, predict outcomes, and automate parts of institutional judgment. These systems can support human decision making, but they can also create new forms of dependence, opacity, and error.
AI can reduce cognitive burden by:
- retrieving relevant evidence;
- summarizing large information sets;
- identifying patterns;
- estimating probabilities;
- flagging uncertainty;
- supporting comparison across options;
- reducing repetitive search;
- making decision criteria explicit.
AI can also increase or relocate cognitive burden. A system may produce an answer quickly but require extensive verification. A recommendation may anchor human judgment. A fluent explanation may create overconfidence. A risk score may appear objective while concealing biased training data, proxy variables, or institutional assumptions.
Human-AI decision research should therefore measure more than task speed or accuracy. It should measure trust calibration, verification burden, source visibility, uncertainty disclosure, error detection, contestability, and downstream consequences. A decision-support system that saves time while hiding uncertainty may reduce immediate effort but increase systemic risk.
Good AI decision support should preserve human agency, show evidence provenance, disclose uncertainty, support disagreement, make assumptions visible, and allow decisions to be audited. The goal should not be to replace human judgment with machine output. It should be to create accountable decision systems that help bounded humans reason better under constraint.
Neuroscience of decision making
Decision making depends on distributed neural systems rather than a single localized center. The prefrontal cortex is often associated with planning, control, comparison, and rule use. Orbitofrontal and ventromedial prefrontal regions are associated with valuation and reward-related representation. The amygdala contributes to emotional salience and relevance. Striatal systems are involved in reward learning and action selection. Parietal regions are often implicated in evidence accumulation and attention.
These systems interact to integrate cognitive evaluation with affective significance. Contemporary research increasingly rejects the idea that emotion is simply noise in decision making. Emotion can distort, but it can also guide adaptive action by encoding salience, urgency, learned value, and social meaning.
Neuroscience also supports evidence-accumulation accounts by linking decision variables to dynamic neural activity. In perceptual and value-based decisions, neural systems appear to integrate information over time before response thresholds are reached. This helps connect behavioral measures such as accuracy and response time with underlying cognitive and neural mechanisms.
The broader implication is that decision making is neither purely logical nor purely emotional. It is an integrated process involving valuation, attention, memory, control, uncertainty, action readiness, and feedback learning.
Ethics, power, and unequal decision environments
Decision making is not socially neutral. Different people make decisions under different constraints. Some have more time, money, information, institutional support, language access, legal protection, health, safety, and room for error. Others make decisions under scarcity, surveillance, precarity, disability, exclusion, discrimination, administrative burden, or threat.
This matters because cognitive load and decision quality are unequally distributed by environment. A person navigating housing instability, medical debt, immigration paperwork, disability benefits, legal risk, or predatory financial products is not deciding under the same conditions as someone with institutional fluency and professional support.
Ethical decision design should therefore ask:
- Who has access to relevant information?
- Who bears the cost of uncertainty?
- Who is punished for small errors?
- Who can appeal a decision?
- Whose evidence is trusted?
- Who benefits from default settings?
- Who has time to deliberate?
- Who is forced to decide under pressure?
- Whose losses are treated as acceptable?
Decision research has moral significance because choices are never only mental events. They occur within systems that distribute opportunity, risk, dignity, and harm. A serious cognitive psychology of decision making should therefore connect individual cognition with the social conditions under which decisions are made.
R code for decision-making data
The following R workflow illustrates analyses relevant to decision-making experiments, including risky choice, framing effects, subjective value, expected value, evidence strength, response time, confidence, AI agreement, verification burden, and decision quality.
# Install packages if needed:
# pak::pak(c("tidyverse", "lme4", "lmerTest", "emmeans", "broom.mixed"))
library(tidyverse)
library(lme4)
library(lmerTest)
library(emmeans)
library(broom.mixed)
# Expected columns:
# participant, condition, domain, trial, scenario_id, option_count,
# frame, gain_loss, probability, payoff, reference_point,
# expected_value, expected_utility, loss_aversion_lambda,
# probability_weight, subjective_value, evidence_strength,
# drift_rate_proxy, decision_threshold, choice_risky, choice_option,
# optimal_choice, accuracy, confidence, affective_valence,
# cognitive_load, time_pressure, uncertainty, response_time_ms,
# feedback_valence, regret, decision_quality,
# ai_recommendation, ai_agreement, verification_burden
dat <- read_csv("decision_trials.csv") %>%
mutate(
participant = factor(participant),
condition = factor(condition),
domain = factor(domain),
scenario_id = factor(scenario_id),
frame = factor(frame),
gain_loss = factor(gain_loss),
choice_option = factor(choice_option),
choice_risky = as.integer(choice_risky),
optimal_choice = as.integer(optimal_choice),
ai_recommendation = as.integer(ai_recommendation),
ai_agreement = as.integer(ai_agreement),
log_rt = log(response_time_ms)
)
# -----------------------------
# 1. Condition summary
# -----------------------------
condition_summary <- dat %>%
group_by(condition) %>%
summarise(
n_trials = n(),
participants = n_distinct(participant),
risky_choice_rate = mean(choice_risky, na.rm = TRUE),
optimal_choice_rate = mean(optimal_choice, na.rm = TRUE),
mean_accuracy = mean(accuracy, na.rm = TRUE),
mean_confidence = mean(confidence, na.rm = TRUE),
mean_decision_quality = mean(decision_quality, na.rm = TRUE),
mean_response_time_ms = mean(response_time_ms, na.rm = TRUE),
mean_cognitive_load = mean(cognitive_load, na.rm = TRUE),
mean_time_pressure = mean(time_pressure, na.rm = TRUE),
mean_uncertainty = mean(uncertainty, na.rm = TRUE),
mean_regret = mean(regret, na.rm = TRUE),
ai_agreement_rate = mean(ai_agreement, na.rm = TRUE),
mean_verification_burden = mean(verification_burden, na.rm = TRUE),
.groups = "drop"
)
print(condition_summary)
# -----------------------------
# 2. Risky-choice model
# -----------------------------
risky_model <- glmer(
choice_risky ~
condition +
frame * gain_loss +
probability +
payoff +
expected_value +
subjective_value +
probability_weight +
loss_aversion_lambda +
cognitive_load +
time_pressure +
uncertainty +
affective_valence +
ai_recommendation +
ai_agreement +
(1 | participant) +
(1 | scenario_id),
data = dat,
family = binomial(),
control = glmerControl(optimizer = "bobyqa")
)
summary(risky_model)
emmeans(risky_model, ~ frame * gain_loss, type = "response")
# -----------------------------
# 3. Optimal-choice model
# -----------------------------
optimal_model <- glmer(
optimal_choice ~
condition +
domain +
option_count +
expected_value +
subjective_value +
evidence_strength +
drift_rate_proxy +
decision_threshold +
cognitive_load +
time_pressure +
uncertainty +
confidence +
ai_recommendation +
verification_burden +
(1 | participant) +
(1 | scenario_id),
data = dat,
family = binomial(),
control = glmerControl(optimizer = "bobyqa")
)
summary(optimal_model)
# -----------------------------
# 4. Decision-quality model
# -----------------------------
quality_model <- lmer(
decision_quality ~
condition +
domain +
optimal_choice +
accuracy +
confidence +
cognitive_load +
time_pressure +
uncertainty +
regret +
ai_recommendation +
ai_agreement +
verification_burden +
(1 | participant) +
(1 | scenario_id),
data = dat,
REML = FALSE
)
summary(quality_model)
# -----------------------------
# 5. Response-time model
# -----------------------------
rt_model <- lmer(
log_rt ~
condition +
frame +
gain_loss +
option_count +
evidence_strength +
drift_rate_proxy +
decision_threshold +
cognitive_load +
time_pressure +
uncertainty +
optimal_choice +
confidence +
ai_recommendation +
verification_burden +
(1 | participant) +
(1 | scenario_id),
data = dat,
REML = FALSE
)
summary(rt_model)
# -----------------------------
# 6. Confidence model
# -----------------------------
confidence_model <- lmer(
confidence ~
condition +
domain +
accuracy +
optimal_choice +
drift_rate_proxy +
decision_threshold +
uncertainty +
cognitive_load +
ai_recommendation +
ai_agreement +
(1 | participant) +
(1 | scenario_id),
data = dat,
REML = FALSE
)
summary(confidence_model)
# -----------------------------
# 7. AI agreement model
# -----------------------------
ai_dat <- dat %>%
filter(ai_recommendation == 1)
if (nrow(ai_dat) > 25) {
ai_model <- glmer(
ai_agreement ~
domain +
probability +
payoff +
subjective_value +
evidence_strength +
confidence +
uncertainty +
cognitive_load +
verification_burden +
(1 | participant) +
(1 | scenario_id),
data = ai_dat,
family = binomial(),
control = glmerControl(optimizer = "bobyqa")
)
print(summary(ai_model))
}
# -----------------------------
# 8. Visualization
# -----------------------------
ggplot(dat, aes(x = subjective_value, y = choice_risky, color = gain_loss)) +
geom_point(alpha = 0.25) +
geom_smooth(method = "glm", method.args = list(family = "binomial"), se = FALSE) +
labs(
title = "Risky choice by subjective value and gain/loss domain",
x = "Subjective value",
y = "Risky choice"
) +
theme_minimal()This workflow can be adapted for risky-choice experiments, framing studies, evidence-accumulation tasks, prospect-theory parameter estimation, time-pressure manipulations, cognitive-load studies, naturalistic decision-making research, human factors experiments, and human-AI decision-support evaluation. Researchers should model participant and scenario effects whenever possible because decision behavior varies across people, domains, frames, tasks, and decision environments.
Python code for decision-making data
The Python examples below parallel the R workflow and are useful for risky-choice paradigms, gain/loss framing experiments, uncertainty-based decisions, response-time analysis, AI-assisted decision studies, and decision-quality modeling.
import numpy as np
import pandas as pd
import statsmodels.formula.api as smf
import statsmodels.api as sm
import matplotlib.pyplot as plt
# Expected columns:
# participant, condition, domain, trial, scenario_id, option_count,
# frame, gain_loss, probability, payoff, reference_point,
# expected_value, expected_utility, loss_aversion_lambda,
# probability_weight, subjective_value, evidence_strength,
# drift_rate_proxy, decision_threshold, choice_risky, choice_option,
# optimal_choice, accuracy, confidence, affective_valence,
# cognitive_load, time_pressure, uncertainty, response_time_ms,
# feedback_valence, regret, decision_quality,
# ai_recommendation, ai_agreement, verification_burden
df = pd.read_csv("decision_trials.csv")
categorical_cols = [
"participant", "condition", "domain", "scenario_id",
"frame", "gain_loss", "choice_option"
]
for col in categorical_cols:
df[col] = df[col].astype("category")
df["choice_risky"] = df["choice_risky"].astype(int)
df["optimal_choice"] = df["optimal_choice"].astype(int)
df["ai_recommendation"] = df["ai_recommendation"].astype(int)
df["ai_agreement"] = df["ai_agreement"].astype(int)
df["log_rt"] = np.log(df["response_time_ms"])
# -----------------------------
# 1. Condition summary
# -----------------------------
condition_summary = (
df.groupby("condition", observed=True)
.agg(
n_trials=("choice_risky", "size"),
participants=("participant", "nunique"),
risky_choice_rate=("choice_risky", "mean"),
optimal_choice_rate=("optimal_choice", "mean"),
mean_accuracy=("accuracy", "mean"),
mean_confidence=("confidence", "mean"),
mean_decision_quality=("decision_quality", "mean"),
mean_response_time_ms=("response_time_ms", "mean"),
mean_cognitive_load=("cognitive_load", "mean"),
mean_time_pressure=("time_pressure", "mean"),
mean_uncertainty=("uncertainty", "mean"),
mean_regret=("regret", "mean"),
ai_agreement_rate=("ai_agreement", "mean"),
mean_verification_burden=("verification_burden", "mean"),
)
.reset_index()
)
print(condition_summary)
# -----------------------------
# 2. Risky-choice model
# -----------------------------
risky_model = smf.glm(
"choice_risky ~ condition + frame * gain_loss "
"+ probability + payoff + expected_value "
"+ subjective_value + probability_weight + loss_aversion_lambda "
"+ cognitive_load + time_pressure + uncertainty "
"+ affective_valence + ai_recommendation + ai_agreement",
data=df,
family=sm.families.Binomial(),
)
risky_result = risky_model.fit(
cov_type="cluster",
cov_kwds={"groups": df["participant"]},
)
print(risky_result.summary())
# -----------------------------
# 3. Optimal-choice model
# -----------------------------
optimal_model = smf.glm(
"optimal_choice ~ condition + domain + option_count "
"+ expected_value + subjective_value + evidence_strength "
"+ drift_rate_proxy + decision_threshold + cognitive_load "
"+ time_pressure + uncertainty + confidence "
"+ ai_recommendation + verification_burden",
data=df,
family=sm.families.Binomial(),
)
optimal_result = optimal_model.fit(
cov_type="cluster",
cov_kwds={"groups": df["participant"]},
)
print(optimal_result.summary())
# -----------------------------
# 4. Decision-quality model
# -----------------------------
quality_model = smf.ols(
"decision_quality ~ condition + domain + optimal_choice "
"+ accuracy + confidence + cognitive_load + time_pressure "
"+ uncertainty + regret + ai_recommendation + ai_agreement "
"+ verification_burden",
data=df,
)
quality_result = quality_model.fit(
cov_type="cluster",
cov_kwds={"groups": df["participant"]},
)
print(quality_result.summary())
# -----------------------------
# 5. Response-time model
# -----------------------------
rt_model = smf.ols(
"log_rt ~ condition + frame + gain_loss + option_count "
"+ evidence_strength + drift_rate_proxy + decision_threshold "
"+ cognitive_load + time_pressure + uncertainty "
"+ optimal_choice + confidence + ai_recommendation "
"+ verification_burden",
data=df,
)
rt_result = rt_model.fit(
cov_type="cluster",
cov_kwds={"groups": df["participant"]},
)
print(rt_result.summary())
# -----------------------------
# 6. Confidence model
# -----------------------------
confidence_model = smf.ols(
"confidence ~ condition + domain + accuracy + optimal_choice "
"+ drift_rate_proxy + decision_threshold + uncertainty "
"+ cognitive_load + ai_recommendation + ai_agreement",
data=df,
)
confidence_result = confidence_model.fit(
cov_type="cluster",
cov_kwds={"groups": df["participant"]},
)
print(confidence_result.summary())
# -----------------------------
# 7. AI agreement model
# -----------------------------
ai_df = df[df["ai_recommendation"] == 1].copy()
if len(ai_df) > 25:
ai_model = smf.glm(
"ai_agreement ~ domain + probability + payoff "
"+ subjective_value + evidence_strength + confidence "
"+ uncertainty + cognitive_load + verification_burden",
data=ai_df,
family=sm.families.Binomial(),
)
ai_result = ai_model.fit(
cov_type="cluster",
cov_kwds={"groups": ai_df["participant"]},
)
print(ai_result.summary())
# -----------------------------
# 8. Visualization
# -----------------------------
fig, ax = plt.subplots(figsize=(8, 5))
for gain_loss, group in df.groupby("gain_loss", observed=True):
ax.scatter(
group["subjective_value"],
group["choice_risky"],
alpha=0.35,
label=str(gain_loss),
)
ax.set_xlabel("Subjective value")
ax.set_ylabel("Risky choice")
ax.set_title("Risky choice by subjective value and gain/loss domain")
ax.legend(title="Gain/loss")
plt.tight_layout()
plt.show()
# -----------------------------
# 9. Export summaries
# -----------------------------
condition_summary.to_csv("decision_condition_summary.csv", index=False)The Python workflow is intentionally transparent and extensible. It can be expanded with Bayesian hierarchical models, prospect-theory parameter estimation, drift-diffusion modeling, reinforcement learning, dynamic decision tasks, information-search logs, eye-tracking, mouse-tracking, regret learning, calibration curves, naturalistic vignettes, institutional audit workflows, and human-AI decision-support experiments.
GitHub Repository
The companion repository provides reusable code and research scaffolding for studying decision making in cognitive psychology, including workflows for expected value, expected utility, prospect theory, loss aversion, probability weighting, risky choice, gain/loss framing, evidence accumulation, response time, confidence, affect, cognitive load, uncertainty, decision quality, regret, feedback, AI agreement, and verification burden.
Complete Code Repository
Access the full companion repository for this article, including reproducible analysis materials and multi-language code workflows for decision-making research.
Applications of decision research
Decision research has wide applications across domains. In medicine, it informs diagnostic reasoning, triage, treatment choice, risk communication, shared decision making, and safety protocols. In public policy, it helps design interventions that improve the environments in which people choose. In finance and risk analysis, it clarifies how uncertainty, framing, loss sensitivity, and time horizon affect behavior. In technology, it informs interface design, recommendation systems, alerts, automation, and decision-support tools.
In education, decision research helps explain how students choose strategies, allocate effort, respond to feedback, and manage uncertainty. In law, it informs evidence evaluation, sentencing, credibility judgments, negotiation, and hindsight bias. In organizations, it helps explain forecasting errors, escalation of commitment, groupthink, decision fatigue, and the importance of structured review.
In artificial intelligence, decision models influence algorithms that must evaluate alternatives under uncertainty and act with incomplete information. The analogy between human and machine decision processes has limits, but the comparison remains fruitful because both must cope with bounded resources, uncertain environments, incomplete feedback, and trade-offs between speed and accuracy.
The practical importance of decision research lies in its ability to connect mind, method, and institution. It helps ask whether a decision environment supports clear evaluation, calibrated confidence, meaningful choice, responsible action, and correction when error occurs.
Conclusion
Decision making is one of the central functions of cognition because it connects thought to action. Through evaluating alternatives, representing uncertainty, assigning value, accumulating evidence, and selecting outcomes, individuals navigate complex and changing environments.
Cognitive psychology shows that decision making is neither perfectly rational nor simply impulsive. It is an adaptive process shaped by constraints, heuristics, affect, evidence, memory, attention, working memory, feedback, and social context. Understanding decision making therefore provides insight not only into individual behavior, but into how minds operate under limitation, uncertainty, and consequence.
Decision making is also institutional. People decide inside systems that shape what information they can access, what options they can choose, whose evidence is believed, and who bears the cost of error. Good decision design therefore requires more than better individual reasoning. It requires better environments, better feedback, better defaults, better accountability, and better safeguards for those most exposed to harmful decisions.
The central lesson is that decision making is cognition under consequence. To understand it fully, we must study not only preference and choice, but attention, memory, uncertainty, value, emotion, time, evidence, power, and the systems that structure human action.
Related articles
- Cognitive Psychology
- Heuristics in Cognitive Psychology
- Cognitive Biases in Decision Making
- Risk Perception and Uncertainty
- Mental Models in Cognitive Psychology
- Cognitive Load and Information Processing
- Problem Solving in Cognitive Psychology
- Metacognition: Thinking About Thinking
- Behavioral Economics
Further reading
- American Psychological Association (n.d.) Decision making. APA Dictionary of Psychology. Available at: https://dictionary.apa.org/decision-making.
- Fischhoff, B. and Broomell, S.B. (2020) ‘Judgment and decision making’, Annual Review of Psychology, 71, pp. 331–355. Available at: https://www.annualreviews.org/content/journals/10.1146/annurev-psych-010419-050747.
- Gigerenzer, G. (2007) Gut Feelings: The Intelligence of the Unconscious. New York: Viking.
- Kahneman, D. (2011) Thinking, Fast and Slow. New York: Farrar, Straus and Giroux.
- Kahneman, D. and Tversky, A. (1979) ‘Prospect theory: An analysis of decision under risk’, Econometrica, 47(2), pp. 263–291. Available at: https://www.jstor.org/stable/1914185.
- Lerner, J.S., Li, Y., Valdesolo, P. and Kassam, K.S. (2015) ‘Emotion and decision making’, Annual Review of Psychology, 66, pp. 799–823. Available at: https://www.annualreviews.org/doi/10.1146/annurev-psych-010213-115043.
- Payne, J.W., Bettman, J.R. and Johnson, E.J. (1993) The Adaptive Decision Maker. Cambridge: Cambridge University Press. Available at: https://www.cambridge.org/core/books/adaptive-decision-maker/C2F0579B685EC397059F5D386E7B2045.
- Ratcliff, R. and McKoon, G. (2008) ‘The diffusion decision model: Theory and data for two-choice decision tasks’, Neural Computation, 20(4), pp. 873–922. PubMed record available at: https://pubmed.ncbi.nlm.nih.gov/18085991/.
- Simon, H.A. (1957) Models of Man: Social and Rational. New York: Wiley.
- Simon, H.A. (1997) Administrative Behavior. 4th edn. New York: Free Press.
- Steele, K. and Stefánsson, H.O. (2015) ‘Decision theory’, Stanford Encyclopedia of Philosophy. Available at: https://plato.stanford.edu/entries/decision-theory/.
- Summerfield, C. and Parpart, P. (2022) ‘Normative principles for decision-making in natural environments’, Annual Review of Psychology, 73, pp. 53–77. Available at: https://www.annualreviews.org/doi/10.1146/annurev-psych-020821-104057.
- Tversky, A. and Kahneman, D. (1974) ‘Judgment under uncertainty: Heuristics and biases’, Science, 185(4157), pp. 1124–1131. Available at: https://www.science.org/doi/10.1126/science.185.4157.1124.
- Wheeler, G. (2018) ‘Bounded rationality’, Stanford Encyclopedia of Philosophy. Available at: https://plato.stanford.edu/entries/bounded-rationality/.
References
- American Psychological Association (n.d.) Decision making. APA Dictionary of Psychology. Available at: https://dictionary.apa.org/decision-making.
- Fischhoff, B. and Broomell, S.B. (2020) ‘Judgment and decision making’, Annual Review of Psychology, 71, pp. 331–355. Available at: https://www.annualreviews.org/content/journals/10.1146/annurev-psych-010419-050747.
- Gigerenzer, G. (2007) Gut Feelings: The Intelligence of the Unconscious. New York: Viking.
- Kahneman, D. (2011) Thinking, Fast and Slow. New York: Farrar, Straus and Giroux.
- Kahneman, D. and Tversky, A. (1979) ‘Prospect theory: An analysis of decision under risk’, Econometrica, 47(2), pp. 263–291. Available at: https://www.jstor.org/stable/1914185.
- Lerner, J.S., Li, Y., Valdesolo, P. and Kassam, K.S. (2015) ‘Emotion and decision making’, Annual Review of Psychology, 66, pp. 799–823. Available at: https://www.annualreviews.org/doi/10.1146/annurev-psych-010213-115043.
- Payne, J.W., Bettman, J.R. and Johnson, E.J. (1993) The Adaptive Decision Maker. Cambridge: Cambridge University Press. Available at: https://www.cambridge.org/core/books/adaptive-decision-maker/C2F0579B685EC397059F5D386E7B2045.
- Ratcliff, R. and McKoon, G. (2008) ‘The diffusion decision model: Theory and data for two-choice decision tasks’, Neural Computation, 20(4), pp. 873–922. PubMed record available at: https://pubmed.ncbi.nlm.nih.gov/18085991/.
- Simon, H.A. (1957) Models of Man: Social and Rational. New York: Wiley.
- Simon, H.A. (1997) Administrative Behavior. 4th edn. New York: Free Press.
- Steele, K. and Stefánsson, H.O. (2015) ‘Decision theory’, Stanford Encyclopedia of Philosophy. Available at: https://plato.stanford.edu/entries/decision-theory/.
- Summerfield, C. and Parpart, P. (2022) ‘Normative principles for decision-making in natural environments’, Annual Review of Psychology, 73, pp. 53–77. Available at: https://www.annualreviews.org/doi/10.1146/annurev-psych-020821-104057.
- Tversky, A. and Kahneman, D. (1974) ‘Judgment under uncertainty: Heuristics and biases’, Science, 185(4157), pp. 1124–1131. Available at: https://www.science.org/doi/10.1126/science.185.4157.1124.
- Wheeler, G. (2018) ‘Bounded rationality’, Stanford Encyclopedia of Philosophy. Available at: https://plato.stanford.edu/entries/bounded-rationality/.