
Last Updated May 10, 2026
Computer vision and machine perception study how artificial systems transform high-dimensional visual signals into structured representations that support recognition, localization, segmentation, reasoning, prediction, interaction, and action. Unlike language, which is already partly discrete and symbolic, visual data is continuous, spatially structured, high-dimensional, context-dependent, and often ambiguous. A computer vision system must convert pixels, frames, depth maps, satellite scenes, medical images, sensor streams, or multimodal visual inputs into representations that can identify objects, infer relationships, detect anomalies, guide robots, support interpretation, or assist decision-making under uncertainty.
The central argument of this article is that computer vision should be understood as a form of governed machine perception infrastructure. A vision model does not merely “see.” It samples visual signals, transforms them into features, learns representations, produces structured outputs, routes those outputs into downstream workflows, and shapes how people, institutions, platforms, and machines interpret visual evidence. Its value depends not only on accuracy, but also on robustness, calibration, uncertainty, subgroup performance, sensor awareness, domain fitness, privacy, contestability, and accountable use.
Main Library
Publications
Article Map
Artificial Intelligence Systems
Related Topic
Data Systems & Analytics
Related Topic
Embedded & Edge Systems
Related Topic
Intelligent Infrastructure Systems
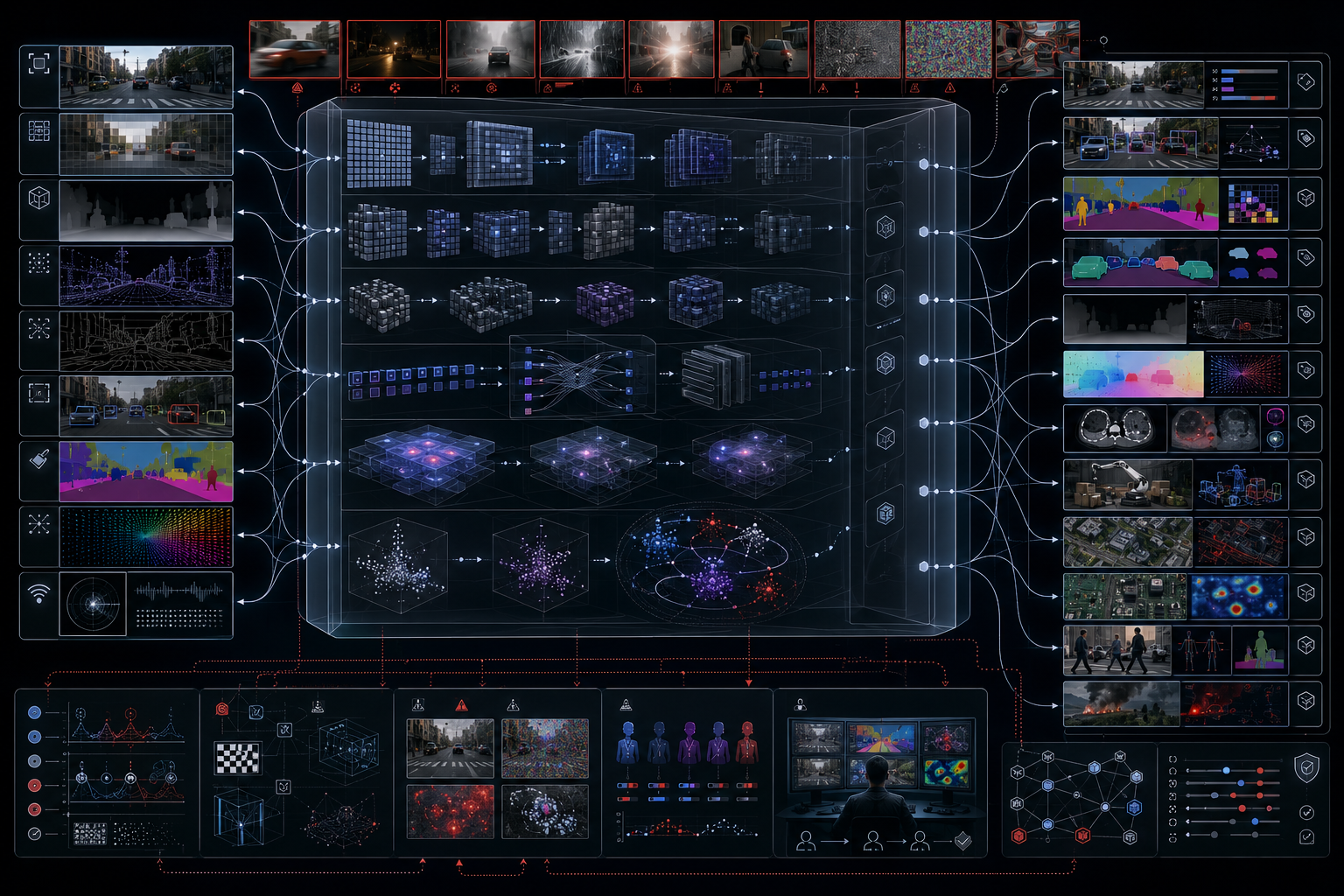
Modern computer vision sits at the intersection of machine learning, geometry, signal processing, representation learning, neural networks, statistical inference, optimization, human perception, robotics, scientific imaging, remote sensing, and systems engineering. Its recent progress has been driven by convolutional neural networks, residual networks, large annotated datasets, self-supervised learning, vision transformers, multimodal image-text models, segmentation systems, diffusion models, and visual foundation models. Yet perception is not reducible to pattern recognition alone. It also requires invariance, equivariance, spatial reasoning, causal context, sensor calibration, distribution-shift awareness, and governance.
A perception system can classify an image, detect objects, segment regions, track motion, estimate depth, retrieve related images, answer questions about scenes, generate synthetic visuals, or guide action. But each of those outputs becomes consequential only when placed inside a larger system. A detection model in an autonomous vehicle is not simply a classifier; it is part of a safety-critical control stack. A medical imaging model is not only a segmentation tool; it is part of a clinical evidence workflow. A satellite model is not merely a land-cover classifier; it can affect environmental reporting, infrastructure planning, agriculture, conservation, or enforcement. Computer vision therefore belongs at the center of artificial intelligence systems thinking.
This article develops Computer Vision and Machine Perception as an advanced article within the Artificial Intelligence Systems knowledge series. It explains vision as an inverse problem, image representation, convolution, feature hierarchies, CNNs, residual learning, detection, segmentation, vision transformers, attention, multimodal image-text alignment, robustness, adversarial examples, distribution shift, real-world perception infrastructure, evaluation metrics, bias, uncertainty, and governance. Selected Python and R examples appear here, while the full GitHub repository contains expanded computational scaffolding for synthetic images, convolution demonstrations, edge detection, feature extraction, image-classification baselines, segmentation masks, robustness tests, grouped error diagnostics, SQL metadata, model-card notes, and advanced Jupyter notebooks.
Why Computer Vision Matters
Computer vision matters because visual interpretation is one of the most consequential forms of machine perception. Images and video now mediate medical diagnosis, industrial inspection, autonomous vehicles, satellite monitoring, robotics, accessibility tools, agricultural sensing, security systems, scientific imaging, content moderation, environmental observation, infrastructure monitoring, and creative production. A vision system does not merely process pixels. It transforms visual signals into representations that can be classified, searched, measured, segmented, tracked, acted upon, or used as evidence.
The field is powerful because visual data is rich. A single image can contain objects, spatial relations, material properties, motion cues, lighting conditions, text, human activity, environmental context, and latent social meaning. But this richness also creates risk. Visual signals are ambiguous. A two-dimensional image is a projection of a three-dimensional world. Lighting can change appearance. Objects can occlude one another. Background correlations can mislead a model. Training datasets can encode social bias. A system may perform well on benchmarks while failing in real-world conditions.
Computer vision therefore belongs at the center of artificial intelligence systems thinking. It connects deep learning to physical sensors, perception to decision-making, and representation learning to safety. A perception error can propagate into an autonomous vehicle control system, a medical workflow, a surveillance decision, a search result, a robotics action, or an environmental monitoring dashboard. For that reason, machine perception must be evaluated not only by accuracy, but by robustness, calibration, fairness, uncertainty, interpretability, domain fitness, and accountable deployment.
Visual\ Output \neq Visual\ Truth
\]
Interpretation: A computer vision output is an inference produced by data, sensors, models, labels, and deployment context. It should not be treated as direct or neutral visual truth.
| Use Context | Vision Capability | Potential Value | Governance Concern |
|---|---|---|---|
| Medical imaging | Classification, segmentation, anomaly detection, measurement. | Supports diagnosis, triage, and clinical review. | False positives, false negatives, scanner shift, clinical overtrust. |
| Autonomous systems | Object detection, tracking, depth estimation, scene understanding. | Supports navigation, planning, and safety. | Failure under weather, occlusion, rare events, or sensor degradation. |
| Satellite and environmental monitoring | Land-cover classification, change detection, segmentation. | Supports climate, agriculture, conservation, and infrastructure analysis. | Regional bias, cloud cover, resolution limits, political misuse. |
| Industrial inspection | Defect detection, quality control, process monitoring. | Improves reliability and safety. | Domain shift, rare defects, and hidden failure modes. |
| Public platforms and media systems | Content moderation, visual search, tagging, synthetic-media detection. | Improves discovery, safety, and organization. | Bias, censorship concerns, authenticity erosion, and weak contestability. |
Note: Computer vision systems become most consequential when visual outputs are used as operational evidence, not merely as model predictions.
Vision as an Inverse Problem
Computer vision can be understood as an inverse problem. The world is three-dimensional, but images are two-dimensional projections produced by a rendering process involving objects, materials, geometry, lighting, viewpoint, motion, occlusion, atmosphere, and sensor characteristics. Recovering meaningful structure from an image therefore requires inferring latent causes from incomplete observations.
A simplified image formation process can be written as:
I = R(S,L,V,C)
\]
Interpretation: An image \(I\) is produced by a rendering process \(R\) involving scene structure \(S\), lighting \(L\), viewpoint \(V\), and camera or sensor characteristics \(C\).
The perception problem is to infer properties of the underlying scene from the observed image:
\hat{S}
=
\arg\max_S P(S \mid I)
\]
Interpretation: Vision estimates the most plausible scene structure \(S\) given an observed image \(I\).
This inversion is ill-posed. Multiple scenes can produce similar images. A small object nearby can resemble a larger object farther away. Lighting can change apparent color. Reflections can create false surfaces. Shadows can resemble objects. Partial occlusion can hide critical information. A machine perception system therefore requires priors, learned representations, geometric assumptions, domain knowledge, and evaluation under uncertainty.
This framing aligns computer vision with broader problems in probabilistic inference, machine learning, and decision-making under incomplete information. Vision is not passive recording. It is structured inference from visual evidence.
| Visual Condition | Why It Creates Ambiguity | Modeling Response | Risk if Mishandled |
|---|---|---|---|
| Lighting variation | Color and contrast change without object identity changing. | Augmentation, normalization, robust feature learning. | Model confuses illumination with object class. |
| Occlusion | Objects may be partly hidden. | Context modeling, detection, segmentation, tracking. | Critical objects are missed or partially misread. |
| Projection | Three-dimensional scenes become two-dimensional images. | Geometry, depth estimation, multi-view learning. | Model misjudges size, distance, or spatial relation. |
| Sensor variation | Cameras, lenses, compression, and resolution alter inputs. | Calibration, metadata, domain adaptation. | Deployment images differ from training images. |
| Context dependence | Visual meaning depends on scene, culture, and task. | Multimodal alignment, human review, domain constraints. | Model overgeneralizes from weak context. |
Note: Machine perception should be treated as probabilistic inference under uncertainty, not as direct extraction of visual truth.
Image Representation and the Geometry of Visual Data
A digital image is commonly represented as a tensor of height, width, and channels:
I \in \mathbb{R}^{H \times W \times C}
\]
Interpretation: An image can be represented as a height-by-width-by-channel array, such as RGB pixel values.
Although this tensor may contain millions of pixel values, meaningful visual structure often lies on lower-dimensional manifolds embedded within pixel space. Natural images are not arbitrary arrays. They contain edges, textures, contours, surfaces, objects, backgrounds, spatial relations, and semantic patterns. Computer vision models learn transformations that reorganize raw pixel geometry into more useful feature spaces.
A representation-learning model can be written as:
f_\theta:
\mathbb{R}^{H \times W \times C}
\rightarrow
\mathbb{R}^{d}
\]
Interpretation: A visual encoder maps an image tensor into a \(d\)-dimensional feature representation.
This transformation is not merely dimensionality reduction. It is a geometric reorganization of visual data so that relevant structures become separable, retrievable, classifiable, or actionable. Early layers may encode edges or local textures. Intermediate layers may encode parts and motifs. Later layers may encode object-level or scene-level structure.
This geometric view is central to modern machine perception. A model’s usefulness depends on whether its representation preserves task-relevant structure while discarding irrelevant variation.
| Representation Level | Visual Structure | Modeling Role | System Concern |
|---|---|---|---|
| Pixels | Raw intensity and color values. | Input signal for image models. | Highly sensitive to lighting, compression, and sensor noise. |
| Edges and textures | Local gradients, boundaries, and repeated patterns. | Early feature extraction. | Texture bias may overpower shape or semantic reasoning. |
| Parts and shapes | Contours, object fragments, surfaces, and geometry. | Intermediate feature learning. | Occlusion and viewpoint variation can disrupt recognition. |
| Objects and scenes | Semantic entities and context. | Classification, detection, segmentation, retrieval. | Spurious background cues can mislead models. |
| Embeddings | Compact learned vector representations. | Search, alignment, clustering, retrieval, downstream modeling. | Embedding similarity may hide bias or weak grounding. |
Note: Visual representations convert pixel geometry into task-relevant structure, but that transformation reflects training data, architecture, and evaluation choices.
Convolution, Filters, and Local Structure
Convolution is one of the foundational operations in computer vision. It applies a small filter or kernel across spatial positions in an image. The same filter is reused across the image, making the operation efficient and translation-aware.
A two-dimensional discrete convolution can be written as:
(I*K)(x,y)
=
\sum_i\sum_j I(x+i,y+j)K(i,j)
\]
Interpretation: A convolution computes local weighted sums by sliding a kernel \(K\) across an image \(I\).
Convolution is useful because natural images have strong local structure. Nearby pixels are often related. Edges, corners, textures, and contours can be detected with local filters. By applying the same filter across the image, a model can detect the same pattern wherever it appears.
This operation encodes two important assumptions. First, visual patterns are local. Second, the same visual feature may occur at many positions. These assumptions are not arbitrary. They reflect the structure of natural images and make convolutional models more efficient than fully connected models applied directly to pixels.
| Convolution Concept | Meaning | Vision Function | Limitation |
|---|---|---|---|
| Kernel | Small matrix of weights applied locally. | Detects edges, corners, textures, or learned features. | Kernel size shapes what local structure can be captured. |
| Parameter sharing | Same filter used across spatial positions. | Improves efficiency and translation awareness. | May be insufficient for location-specific context. |
| Feature map | Output produced by applying a filter. | Highlights where visual patterns occur. | Can be sensitive to noise or preprocessing. |
| Stacked layers | Multiple convolutions build hierarchy. | Supports increasingly abstract features. | Deep systems require careful optimization and validation. |
Note: Convolution gives vision models a useful bias toward locality and repeated structure, but it does not by itself guarantee robust perception.
Convolutional Neural Networks and Inductive Bias
Convolutional neural networks, or CNNs, extend convolution into trainable hierarchical models. Rather than hand-designing every edge detector or texture filter, CNNs learn filters from data. A convolutional layer applies multiple learned kernels, adds nonlinearities, and passes the resulting feature maps to deeper layers.
A simplified convolutional layer can be written as:
h_{\ell+1}
=
\sigma(W_\ell * h_\ell + b_\ell)
\]
Interpretation: A convolutional layer applies learned filters \(W_\ell\), adds bias \(b_\ell\), and passes the result through a nonlinear activation \(\sigma\).
CNNs introduce inductive biases that reflect properties of natural images: locality, translation equivariance, parameter sharing, and hierarchical composition. Pooling and downsampling can reduce sensitivity to small spatial shifts. Deeper layers can build increasingly abstract visual features.
These architectural choices help explain why CNNs transformed computer vision. They did not merely add more parameters. They encoded useful assumptions about image structure while allowing data-driven learning. The result was a model family capable of learning rich visual representations at scale.
Architecture = Capacity + Inductive\ Bias
\]
Interpretation: Model architecture does not only determine how many parameters a system has. It shapes what patterns the system can learn efficiently and what assumptions it brings to visual data.
| Inductive Bias | Meaning | Benefit | Possible Failure |
|---|---|---|---|
| Locality | Nearby pixels are likely related. | Efficiently captures edges, textures, and local patterns. | May miss long-range context without deeper architecture. |
| Translation equivariance | Feature response shifts with the image. | Recognizes patterns across positions. | Location-specific meaning may be underrepresented. |
| Parameter sharing | Same filter applied across image regions. | Reduces parameters and improves generalization. | May assume visual patterns transfer where they do not. |
| Hierarchy | Features build from simple to complex. | Supports object and scene recognition. | High-level features may reflect dataset shortcuts. |
Note: CNNs are powerful because they combine learned representation with visual structure assumptions.
Invariance, Equivariance, and Feature Hierarchies
A central goal in vision is to learn representations that are invariant to irrelevant transformations while remaining sensitive to meaningful variation. Object identity should remain stable under small translation, lighting change, scale variation, or viewpoint change. At the same time, location and orientation may matter for detection, segmentation, robotics, and spatial reasoning.
Invariance can be written as:
f(Tx)=f(x)
\]
Interpretation: A representation is invariant if a transformation \(T\) does not change the output.
Equivariance can be written as:
f(Tx)=T’f(x)
\]
Interpretation: A representation is equivariant if transformation of the input produces a corresponding transformation of the representation.
CNNs achieve approximate translation equivariance through convolution and partial invariance through pooling. More advanced architectures may explicitly model rotation, scale, viewpoint, or group symmetries. Vision transformers handle invariance differently, relying more on data, positional encodings, attention, and scale.
Feature hierarchies are equally important. Early layers learn local patterns. Middle layers combine them into parts. Deeper layers encode higher-level structures. This hierarchy reflects the compositional nature of visual scenes: pixels become edges, edges become shapes, shapes become objects, and objects become scenes.
| Property | Meaning | Useful For | Caution |
|---|---|---|---|
| Translation invariance | Output remains stable when object shifts position. | Image classification. | Not always desirable for localization tasks. |
| Translation equivariance | Feature location shifts with input location. | Detection, segmentation, tracking. | Requires careful handling through downsampling and pooling. |
| Scale robustness | Model handles object size variation. | Detection across distances and resolutions. | Scale assumptions may fail in unfamiliar domains. |
| Viewpoint robustness | Model handles changes in camera angle. | Robotics, vehicles, surveillance, inspection. | Occlusion and perspective can still break recognition. |
| Feature hierarchy | Representations build from local to global structure. | General visual recognition. | High-level abstractions may encode spurious correlations. |
Note: The right balance of invariance and equivariance depends on the task. Classification, detection, segmentation, and control need different visual representations.
Core Vision Tasks and Structured Outputs
Computer vision systems address multiple tasks, each requiring different output structures. Image classification maps an image to one or more labels. Object detection identifies and localizes objects with bounding boxes. Semantic segmentation assigns a class label to each pixel. Instance segmentation separates individual objects of the same class. Keypoint detection identifies important points such as joints, landmarks, or object parts. Depth estimation infers distance or three-dimensional structure from image data. Optical flow estimates motion across frames. Visual question answering combines image interpretation with language reasoning. Image generation produces or edits visual content from learned representations.
These tasks increase in structural complexity. Classification asks what is present. Detection asks what and where. Segmentation asks which pixels belong to which class or object. Tracking asks how objects move through time. Visual reasoning asks how entities relate. Robotics asks how perception should guide action.
A classification model can be written as:
\hat{y}
=
\arg\max_c P(y=c \mid I)
\]
Interpretation: Image classification selects the class \(c\) with highest predicted probability for image \(I\).
A detection model predicts both class and location:
\hat{o}_k=(\hat{c}_k,\hat{b}_k)
\]
Interpretation: Each detected object has a predicted class \(\hat{c}_k\) and bounding box \(\hat{b}_k\).
The output structure matters because evaluation, failure modes, and governance differ by task.
| Task | Output Structure | Example Use | Governance Risk |
|---|---|---|---|
| Classification | Class label or probability distribution. | Image tagging, medical triage, defect detection. | Label may hide uncertainty or ambiguity. |
| Detection | Classes plus bounding boxes. | Vehicles, pedestrians, products, infrastructure assets. | Missed detections can cause downstream harm. |
| Semantic segmentation | Class label per pixel. | Medical imaging, land cover, road scenes. | Boundary errors may affect measurement and decisions. |
| Instance segmentation | Object-specific pixel masks. | Robotics, microscopy, inventory, scene analysis. | Overlapping objects may be miscounted or merged. |
| Depth and 3D perception | Distance, geometry, or point-cloud structure. | Robotics, autonomous vehicles, augmented reality. | Depth errors can create safety failures. |
| Visual question answering | Language response grounded in image evidence. | Assistants, accessibility, search, education. | Fluent answers may hallucinate visual context. |
Note: Vision tasks should be evaluated by their output structure and downstream use, not by a single generic accuracy measure.
Residual Networks and Deep Visual Representation
As neural networks became deeper, optimization became more difficult. Very deep networks can suffer from degradation, vanishing gradients, unstable training, or inefficient representation learning. Residual networks introduced a simple but powerful idea: instead of learning a direct mapping, learn a residual correction added to the input.
A residual block can be written as:
h_{\ell+1}
=
h_\ell + F(h_\ell;\theta_\ell)
\]
Interpretation: A residual block learns a correction \(F\) to the previous representation \(h_\ell\), making very deep networks easier to optimize.
Residual learning helped make very deep visual networks practical and became a major foundation for modern computer vision. It also illustrates a broader principle: architectural design can make optimization easier by changing what the network is asked to learn.
Residual connections now appear far beyond classical CNNs. They are used in transformers, diffusion models, multimodal systems, and many deep architectures. In this sense, residual learning is not only a computer vision technique. It is a general design principle for trainable systems.
Deep\ Learning\ Progress = Architecture + Optimization + Data + Compute
\]
Interpretation: Residual networks show that better model depth depends not only on adding layers, but on making those layers trainable and useful.
Vision Transformers and Global Representation Learning
Vision transformers extend attention-based architectures to images by treating image patches as tokens. An image is divided into fixed-size patches, each patch is embedded into a vector, positional information is added, and transformer layers model relationships among patches.
A patch embedding process can be summarized as:
I \rightarrow \{p_1,p_2,\ldots,p_N\}
\rightarrow
\{z_1,z_2,\ldots,z_N\}
\]
Interpretation: A vision transformer divides an image into patches \(p_i\) and maps them into token embeddings \(z_i\).
Attention then models relationships across the entire image:
\mathrm{Attention}(Q,K,V)
=
\mathrm{softmax}
\left(
\frac{QK^T}{\sqrt{d_k}}
\right)V
\]
Interpretation: Attention allows visual tokens to exchange information globally across the image.
CNNs encode strong local inductive biases. Vision transformers rely more heavily on data, scale, and attention. This creates a tradeoff between structure and flexibility. With enough data and compute, transformers can learn powerful global representations. In smaller-data settings, convolutional inductive bias may still be valuable.
Modern vision systems often combine these ideas: convolution for local structure, attention for global context, self-supervision for representation learning, and multimodal alignment for connecting images to language.
| Model Family | Core Representation Strategy | Strength | Risk or Limitation |
|---|---|---|---|
| CNNs | Local convolutional feature hierarchies. | Efficient, structured, strong visual inductive bias. | May require architectural additions for global context. |
| Vision transformers | Image patches treated as tokens with attention. | Global representation learning and flexible scaling. | Can require large data and compute for strong performance. |
| Hybrid architectures | Combine convolutional and attention-based components. | Balance local structure and global context. | More complex to validate and deploy. |
| Multimodal visual models | Align image representations with language or other modalities. | Supports search, captioning, grounding, and generative interfaces. | May learn spurious image-text associations. |
Note: Vision transformers shifted computer vision toward tokenized visual representation, but local structure, sensor context, and task constraints still matter.
Multimodal Vision and Image-Text Alignment
Computer vision increasingly operates within multimodal AI systems. Images are paired with captions, documents, audio, video, sensor metadata, user prompts, or structured knowledge. Vision-language models learn representations that connect visual and textual information.
A visual encoder and text encoder can be written as:
z_{\mathrm{image}}=f_{\mathrm{image}}(I),
\qquad
z_{\mathrm{text}}=f_{\mathrm{text}}(T)
\]
Interpretation: Image and text encoders map different modalities into embedding spaces that can be compared or aligned.
Cosine similarity can compare visual and textual embeddings:
\mathrm{sim}(z_{\mathrm{image}},z_{\mathrm{text}})
=
\frac{z_{\mathrm{image}}\cdot z_{\mathrm{text}}}
{\|z_{\mathrm{image}}\|\|z_{\mathrm{text}}\|}
\]
Interpretation: Similarity between image and text embeddings supports cross-modal retrieval, captioning, grounding, and visual search.
This shift changes the role of computer vision. Images are no longer only classified or segmented. They are embedded into broader representational systems where they can be searched, described, retrieved, edited, compared, reasoned over, or used in conversation. This connects computer vision directly to speech recognition, multimodal AI, natural language processing, generative AI, and human-AI interaction.
Image\text{-}Text\ Alignment \neq Visual\ Understanding
\]
Interpretation: A model can align images and captions statistically without fully understanding physical context, causality, culture, consent, or downstream use.
| Capability | How It Works | Potential Value | Governance Concern |
|---|---|---|---|
| Image-text retrieval | Compares image and text embeddings. | Searches images using language and retrieves captions. | Ranking may reflect bias in training captions. |
| Captioning | Generates text from visual input. | Accessibility, search, documentation. | Captions may hallucinate context or identity. |
| Visual question answering | Combines image perception with language response. | Interactive explanation and assistive use. | Fluent answers may exceed visual evidence. |
| Text-guided image generation | Uses language to condition visual synthesis. | Creative prototyping and design. | Authenticity, bias, authorship, and consent concerns. |
| Multimodal decision support | Combines images with text, records, sensors, or metadata. | Clinical, environmental, industrial, and infrastructure workflows. | Errors can propagate across modalities and records. |
Note: Multimodal vision expands the power of visual AI, but it also expands the pathways through which error, bias, and uncertainty can spread.
Generalization, Robustness, and Distribution Shift
Vision systems must generalize across changes in viewpoint, lighting, background, scale, sensor type, geography, weather, occlusion, domain, and social context. A model trained on one dataset may fail when deployed in another environment. A medical imaging model may fail on images from a different scanner. An autonomous vehicle perception model may fail under unusual weather. A satellite model may fail across regions with different land-use patterns. A content moderation model may fail across cultural contexts.
Distribution shift can be represented as a difference between training and deployment distributions:
\Delta
=
d(P_{\mathrm{train}}(I),P_{\mathrm{deploy}}(I))
\]
Interpretation: Distribution shift measures how much deployment images differ from the images used during training.
Robustness cannot be assumed from benchmark accuracy alone. Models may rely on spurious correlations, background cues, texture bias, annotation artifacts, or dataset shortcuts. A classifier that recognizes cows may depend more on grass backgrounds than animal shape. A medical model may rely on hospital-specific markers rather than pathology. A face analysis system may show uneven performance across demographic groups.
Responsible machine perception therefore requires evaluation beyond standard test sets: out-of-domain testing, subgroup diagnostics, stress tests, adversarial robustness, calibration, uncertainty, and human-in-the-loop review.
| Shift Type | Example | Evaluation Need | Governance Risk |
|---|---|---|---|
| Lighting shift | Model trained on clear images fails under low light or glare. | Lighting stress tests and calibration review. | Failures appear only after deployment. |
| Sensor shift | Different camera, scanner, satellite, lens, or compression pipeline. | Device-specific evaluation and metadata tracking. | Model appears portable when it is not. |
| Geographic shift | Satellite or street-level model fails in new regions. | Regional validation and local context review. | Underrepresented places are misclassified. |
| Demographic or social shift | Face, gesture, clothing, or activity recognition varies across groups. | Subgroup diagnostics and appropriate-use review. | Machine perception reproduces unequal treatment. |
| Operational shift | Deployment setting differs from benchmark setting. | Field testing, monitoring, and incident review. | Benchmark success becomes false assurance. |
Note: Robustness is a deployment property, not only a benchmark result.
Optimization, Data Scaling, and Benchmarks
Modern vision systems benefit from large-scale datasets, GPUs, distributed training, open-source frameworks, and standardized benchmarks. ImageNet played a major role in accelerating deep visual recognition by providing a large benchmark for classification and detection. AlexNet demonstrated the power of deep convolutional networks at ImageNet scale. ResNet showed that residual learning could make very deep networks easier to optimize. Vision transformers showed that attention-based models could perform strongly on image recognition when trained at scale.
These advances show that computer vision progress has never been only about model architecture. It has depended on datasets, labels, benchmarks, compute, software tooling, evaluation protocols, and research institutions. A computer vision system is therefore both an algorithmic artifact and an infrastructure artifact.
Optimization remains central. Most deep vision systems are trained by minimizing a loss function through stochastic gradient-based methods:
\theta_{t+1}
=
\theta_t
–
\eta \nabla_\theta \mathcal{L}(\theta_t)
\]
Interpretation: Gradient-based optimization updates parameters \(\theta\) to reduce loss, with learning rate \(\eta\).
Scaling can improve performance, but it also increases cost, opacity, energy use, infrastructure dependence, and governance burden. Larger models are not automatically more trustworthy. They must still be evaluated for robustness, fairness, calibration, uncertainty, and domain fitness.
| Infrastructure Element | Role | Contribution | Governance Concern |
|---|---|---|---|
| Datasets | Provide labeled or unlabeled visual examples. | Enable supervised and self-supervised learning. | Data provenance, consent, bias, and missing contexts. |
| Benchmarks | Standardize evaluation tasks. | Accelerate comparison and progress. | Benchmark overfitting and poor deployment transfer. |
| Compute | Supports large-scale training and inference. | Enables deeper models and larger datasets. | Concentrates capability and increases energy burden. |
| Optimization methods | Train models through loss minimization. | Improve representation learning. | Loss functions may misalign with real-world goals. |
| Open-source tooling | Makes workflows reusable and inspectable. | Supports reproducibility and adoption. | Hidden dependencies can affect results and security. |
Note: Computer vision progress is produced by model architecture, data infrastructure, benchmarks, compute, and evaluation culture together.
Perception Systems in Real-World Environments
Computer vision systems are embedded in real-world environments: autonomous vehicles, robotics, surveillance systems, medical imaging workflows, industrial inspection lines, agricultural monitoring, satellite analysis, accessibility tools, augmented reality, scientific instruments, and content platforms. In these settings, perception is part of a larger system that includes sensors, preprocessing, models, user interfaces, decision logic, control systems, feedback loops, and human oversight.
This creates system-level dependencies. A perception error can propagate into planning, control, diagnosis, enforcement, ranking, or resource allocation. A segmentation mistake in medical imaging can affect clinical interpretation. A detection failure in robotics can cause unsafe motion. A satellite classification error can distort environmental reporting. A surveillance model can misidentify people or actions. In each case, the model output becomes part of an operational chain.
Real-world perception also requires sensor awareness. Camera resolution, lens distortion, lighting, depth, motion blur, compression, frame rate, calibration, and environmental conditions all affect model behavior. A robust computer vision system is therefore not merely a trained network. It is a sensor-model-interface-governance system.
| System Layer | Function | Why It Matters | Failure Mode |
|---|---|---|---|
| Sensor layer | Captures visual input through cameras, scanners, satellites, or instruments. | Determines resolution, noise, field of view, and calibration. | Sensor artifacts are mistaken for visual truth. |
| Preprocessing layer | Normalizes, resizes, crops, compresses, or transforms images. | Shapes what the model receives. | Important details are lost or distorted. |
| Model layer | Classifies, detects, segments, tracks, or embeds visual data. | Produces machine perception outputs. | Model fails under shift, occlusion, or ambiguity. |
| Interface layer | Displays labels, boxes, masks, confidence, or explanations. | Shapes human interpretation and trust. | Uncertainty is hidden behind clean visual overlays. |
| Decision layer | Uses visual outputs for action, review, ranking, or control. | Connects perception to consequences. | Perception errors become operational harms. |
| Governance layer | Defines monitoring, audit, escalation, and accountability. | Supports correction and responsible use. | Failures are difficult to contest or reconstruct. |
Note: A deployed vision model should be evaluated as part of a sensor-to-decision system, not as an isolated algorithm.
Failure Modes, Adversarial Inputs, and Uncertainty
Computer vision systems are vulnerable to several types of failure. They may misclassify due to occlusion, unusual viewpoints, poor lighting, blur, low resolution, domain shift, rare objects, or ambiguous scenes. They may rely on spurious background correlations. They may perform unevenly across demographic groups or geographic contexts. They may fail under sensor degradation or environmental stress.
Adversarial perturbations are a particularly striking failure mode. A small input change that is nearly invisible to humans can alter model predictions. A simplified adversarial perturbation can be represented as:
x’ = x + \delta,
\qquad
\|\delta\| \leq \epsilon
\]
Interpretation: An adversarial input \(x’\) differs from the original image \(x\) by a small perturbation \(\delta\), but may produce a different model prediction.
Uncertainty should therefore be explicit. A responsible vision system should not only produce a label or bounding box. It should provide confidence estimates where appropriate, flag low-confidence cases, support human review, document known failure modes, and avoid silent deployment in environments far from training data.
| Failure Mode | Description | Example | Mitigation |
|---|---|---|---|
| Occlusion failure | Model misses or misreads partially hidden objects. | Pedestrian, lesion, defect, or vehicle obscured by another object. | Occlusion tests, tracking, human review. |
| Spurious correlation | Model relies on background or dataset artifact. | Animal classification depends on grass or snow context. | Counterfactual testing and dataset review. |
| Adversarial vulnerability | Small perturbations alter predictions. | Sticker, noise, or pixel shift changes classification. | Robust training, monitoring, and threat modeling. |
| Sensor degradation | Image quality changes due to blur, compression, or calibration drift. | Industrial or vehicle camera degrades over time. | Sensor monitoring and calibration logs. |
| Subgroup performance gap | Error rates differ across people, places, or conditions. | Face, gesture, or activity recognition fails unevenly. | Grouped diagnostics and appropriate-use constraints. |
| Overconfident ambiguity | Model gives confident output for uncertain visual evidence. | Ambiguous medical image or unclear surveillance frame. | Calibration, uncertainty display, escalation paths. |
Note: Vision failures become governance problems when model outputs are treated as authoritative evidence without uncertainty, review, or contestability.
Confidence \neq Correctness
\]
Interpretation: A high-confidence visual prediction can still be wrong, especially under domain shift, adversarial input, occlusion, ambiguity, or dataset bias.
Implications for Safety, Autonomy, and Decision Systems
Because perception systems are used in safety-critical and institutionally consequential settings, reliability is essential. Computer vision can affect who receives medical attention, which vehicle action is taken, what content is removed, what infrastructure is monitored, what land use is detected, which defect is flagged, or which person is identified. These uses raise questions of validation, accountability, privacy, bias, surveillance, contestability, and risk management.
Governance must begin before deployment. Who collected the images? What consent or licensing applies? What populations, environments, and edge cases are missing? How was labeling performed? Which metrics determine success? Are errors evenly distributed? What happens when the system is uncertain? Who reviews failures? Can users contest outputs? How are model updates documented? How are monitoring and incident response handled?
Computer vision systems can expand human capability, but they can also intensify surveillance and automate visual judgment at scale. That makes auditability central. A responsible perception system must document data provenance, model limitations, evaluation coverage, subgroup behavior, failure modes, monitoring plans, and human oversight.
| Governance Area | Question | Evidence Needed | Risk if Ignored |
|---|---|---|---|
| Data provenance | Where did images come from and under what conditions? | Dataset documentation, consent, licensing, collection context. | Unreviewed data becomes institutional evidence. |
| Labeling practices | Who labeled the images and with what assumptions? | Annotation guidelines, inter-rater review, label uncertainty. | Human judgment errors become model ground truth. |
| Domain fitness | Does the system work in the deployment setting? | Field tests, device tests, regional tests, stress tests. | Benchmark performance creates false confidence. |
| Subgroup performance | Are errors unevenly distributed? | Grouped diagnostics where relevant and appropriate. | Perception systems reproduce exclusion or harm. |
| Contestability | Can users challenge or correct visual outputs? | Correction workflows, audit trails, escalation procedures. | Automated visual judgment becomes unchallengeable. |
| Monitoring | Are drift, failures, and incidents tracked after deployment? | Model version logs, drift reports, incident reviews. | System degradation remains invisible. |
Note: Computer vision governance should follow the full chain from image collection to model output, downstream decision, correction, and accountability.
Machine\ Perception + Institutional\ Use \Rightarrow Institutional\ Responsibility
\]
Interpretation: When institutions use computer vision to support decisions, responsibility remains with the institution—not with the model, dataset, vendor, or visual interface alone.
Mathematical Lens: Images, Convolutions, Attention, and Segmentation
A mathematics-first view begins with image representation:
I \in \mathbb{R}^{H \times W \times C}
\]
Interpretation: A digital image is represented as a tensor with height, width, and channels.
A visual encoder maps the image into a feature space:
z=f_\theta(I)
\]
Interpretation: The model produces a learned representation \(z\) from image \(I\).
Convolution extracts local structure:
(I*K)(x,y)
=
\sum_i\sum_j I(x+i,y+j)K(i,j)
\]
Interpretation: A convolutional filter detects local patterns by applying the same kernel across positions.
A convolutional layer applies learned filters and nonlinearities:
h_{\ell+1}
=
\sigma(W_\ell*h_\ell+b_\ell)
\]
Interpretation: CNN layers build hierarchical visual features through learned local transformations.
Image classification estimates class probabilities:
P(y=c\mid I)
=
\mathrm{softmax}_c(g_\phi(f_\theta(I)))
\]
Interpretation: A classifier maps visual representations into class probabilities.
Residual learning improves optimization:
h_{\ell+1}
=
h_\ell+F(h_\ell;\theta_\ell)
\]
Interpretation: Residual connections allow layers to learn corrections rather than full transformations.
Vision transformers use attention over image patches:
\mathrm{Attention}(Q,K,V)
=
\mathrm{softmax}
\left(
\frac{QK^T}{\sqrt{d_k}}
\right)V
\]
Interpretation: Attention lets visual tokens exchange global information across an image.
Segmentation predicts pixel-level labels:
\hat{Y}
\in
\{1,\ldots,C\}^{H \times W}
\]
Interpretation: A segmentation model assigns a class label to each pixel location.
Intersection over Union evaluates overlap:
\mathrm{IoU}
=
\frac{|A\cap B|}{|A\cup B|}
\]
Interpretation: IoU measures overlap between a predicted region \(A\) and reference region \(B\).
A governance-aware visual reliability score can combine model confidence, calibration, domain shift, subgroup risk, and downstream consequence:
Reliability_i =
\alpha C_i
–
\beta E_i
–
\gamma \Delta_i
–
\lambda R_i
\]
Interpretation: Reliability for case \(i\) may combine confidence \(C_i\), expected error \(E_i\), distribution shift \(\Delta_i\), and downstream risk \(R_i\). The weights should be documented and reviewed.
This mathematical lens shows that computer vision is a field of representation, geometry, spatial structure, optimization, uncertainty, and systems-level evaluation.
Variables and System Interpretation
| Symbol or Term | Meaning | Typical Type or Unit | System Interpretation |
|---|---|---|---|
| \(I\) | Image | Tensor in \(\mathbb{R}^{H \times W \times C}\) | Visual input represented as pixels or channels. |
| \(H,W,C\) | Height, width, channels | Dimensions | Spatial and channel structure of an image. |
| \(S\) | Scene structure | Latent world state | Underlying structure inferred from image evidence. |
| \(R\) | Rendering process | Image formation function | Maps world, lighting, viewpoint, and sensor into an image. |
| \(K\) | Convolution kernel | Small matrix or tensor | Local filter applied across an image. |
| \(h_\ell\) | Layer representation | Feature map or token sequence | Intermediate visual representation in a model. |
| \(f_\theta\) | Visual encoder | Parameterized function | Maps images into learned feature spaces. |
| \(z\) | Embedding | Vector in \(\mathbb{R}^d\) | Compact learned visual representation. |
| \(\hat{y}\) | Predicted class | Label | Classification output. |
| \(\hat{b}\) | Bounding box | Coordinates | Object location prediction. |
| \(\hat{Y}\) | Segmentation map | Pixel-level labels | Structured output assigning labels to image regions. |
| \(\mathrm{IoU}\) | Intersection over Union | Ratio | Overlap metric for detection and segmentation. |
| \(\delta\) | Perturbation | Small image change | Potential adversarial, noise, or degradation input. |
Note: Computer vision systems depend on mathematical representation and deployment context. The same visual model may behave differently under lighting changes, camera shifts, domain shifts, demographic differences, sensor degradation, or operational stress.
Worked Example: From Pixels to Visual Representation
A simplified computer vision pipeline begins with an image tensor:
I \in \mathbb{R}^{H \times W \times C}
\]
Interpretation: The input image is a structured array of pixel values.
A convolutional layer extracts local features:
h_1 = \sigma(W_0 * I + b_0)
\]
Interpretation: The first layer detects local visual patterns such as edges, corners, and textures.
Deeper layers build more abstract features:
h_L = f_\theta(I)
\]
Interpretation: The full network maps pixels into a high-level visual representation.
A classifier maps that representation to class probabilities:
\hat{p}=\mathrm{softmax}(Wh_L+b)
\]
Interpretation: The classifier converts visual features into probabilities over classes.
A detection or segmentation system adds spatial structure:
I \rightarrow \{(\hat{c}_k,\hat{b}_k)\}_{k=1}^{K}
\]
Interpretation: Object detection returns classes and bounding boxes for detected objects.
This simplified pipeline captures a major principle: computer vision systems do not simply memorize images. They transform pixel geometry into layered representations that support classification, localization, segmentation, retrieval, or action.
| Review Field | Meaning | Why It Matters | Review Question |
|---|---|---|---|
| Prediction confidence | Model-estimated confidence in visual output. | Helps decide whether human review is needed. | Is confidence calibrated for this domain? |
| Domain similarity | How similar the input is to training and validation data. | Detects possible distribution shift. | Is this image outside the model’s reliable operating range? |
| Sensor metadata | Camera, scanner, resolution, lighting, compression, or acquisition context. | Supports interpretation and debugging. | Could sensor conditions explain the output? |
| Subgroup diagnostic | Error analysis across relevant groups, domains, devices, or regions. | Supports fairness and domain fitness. | Are errors concentrated in specific contexts? |
| Downstream consequence | How the output will be used after prediction. | Determines review burden. | Will this output affect safety, rights, access, or resources? |
Note: A visual output should be reviewed not only as a prediction, but as evidence that may enter a workflow, record, control system, or public decision.
Computational Modeling
Computational modeling makes computer vision more auditable. A convolution workflow can demonstrate how filters detect edges. A synthetic image generator can test how shapes, noise, blur, and lighting affect model behavior. A segmentation workflow can evaluate pixel-level overlap. A robustness workflow can perturb images and test prediction stability. A grouped diagnostics workflow can reveal whether errors differ across synthetic conditions, camera types, regions, lighting settings, or image groups. A SQL metadata schema can document datasets, labels, model versions, evaluation runs, and failure modes.
The selected examples below focus on synthetic image generation, convolution, edge detection, and grouped error diagnostics because these are foundational, readable, and directly reusable. The GitHub repository extends the same logic into advanced Jupyter notebooks, synthetic vision datasets, CNN baselines, patch embeddings, IoU calculations, adversarial perturbation demos, subgroup diagnostics, drift monitoring, metadata schemas, and governance documentation.
| Artifact | Purpose | Governance Value |
|---|---|---|
| Synthetic image dataset | Creates controlled visual examples for testing. | Supports explainable demos and stress testing. |
| Convolution feature maps | Shows how filters transform pixels into structure. | Improves representation transparency. |
| Edge detection outputs | Identifies visual boundaries and local gradients. | Demonstrates foundational perception logic. |
| Segmentation and IoU reports | Measures pixel-level overlap between predictions and references. | Supports structured-output evaluation. |
| Grouped error diagnostics | Compares error rates across visual conditions or groups. | Supports robustness, fairness, and deployment review. |
| Governance memo | Summarizes model limitations, risk areas, and review needs. | Supports auditability and institutional accountability. |
Note: Computer vision workflows should generate evidence for review, not only labels, boxes, masks, or confidence scores.
Python Workflow: Synthetic Image, Convolution, and Edge Detection
Python is useful for image processing, visual model prototyping, and reproducible AI workflows. The following example creates a synthetic image, applies simple convolution filters, calculates edge diagnostics, and exports governance-ready outputs.
"""
Computer Vision and Machine Perception
Python workflow: synthetic image, convolution, and edge detection.
This educational workflow demonstrates:
1. synthetic image generation
2. convolution with simple edge filters
3. basic visual diagnostics
4. governance-ready output records
It does not require private image data.
"""
from __future__ import annotations
from pathlib import Path
import numpy as np
import pandas as pd
from scipy.signal import convolve2d
RANDOM_SEED = 42
rng = np.random.default_rng(RANDOM_SEED)
OUTPUT_DIR = Path("outputs")
OUTPUT_DIR.mkdir(exist_ok=True)
def make_synthetic_image(size: int = 64) -> np.ndarray:
"""
Create a simple synthetic image with a bright square and light noise.
In a real workflow, this function would be replaced by image loading,
preprocessing, and metadata capture from a controlled dataset.
"""
image = np.zeros((size, size), dtype=float)
image[18:46, 18:46] = 1.0
image += 0.05 * rng.normal(size=image.shape)
return np.clip(image, 0.0, 1.0)
def apply_edge_filters(image: np.ndarray) -> dict[str, np.ndarray]:
"""Apply Sobel edge filters to a grayscale image."""
sobel_x = np.array(
[
[-1, 0, 1],
[-2, 0, 2],
[-1, 0, 1],
],
dtype=float,
)
sobel_y = np.array(
[
[-1, -2, -1],
[0, 0, 0],
[1, 2, 1],
],
dtype=float,
)
edge_x = convolve2d(image, sobel_x, mode="same", boundary="symm")
edge_y = convolve2d(image, sobel_y, mode="same", boundary="symm")
edge_magnitude = np.sqrt(edge_x**2 + edge_y**2)
return {
"edge_x": edge_x,
"edge_y": edge_y,
"edge_magnitude": edge_magnitude,
}
def summarize_image(image: np.ndarray, edge_magnitude: np.ndarray) -> pd.DataFrame:
"""Create a compact diagnostic summary for image and edge maps."""
return pd.DataFrame(
[
{
"image_height": image.shape[0],
"image_width": image.shape[1],
"mean_intensity": float(image.mean()),
"std_intensity": float(image.std()),
"max_intensity": float(image.max()),
"min_intensity": float(image.min()),
"max_edge_magnitude": float(edge_magnitude.max()),
"mean_edge_magnitude": float(edge_magnitude.mean()),
"edge_pixels_above_threshold": int((edge_magnitude > 0.75).sum()),
}
]
)
def create_governance_memo(summary: pd.DataFrame) -> str:
"""Create a simple governance memo for the synthetic vision workflow."""
row = summary.iloc[0]
return f"""# Computer Vision Workflow Governance Memo
## Summary
Image size: {int(row["image_height"])} x {int(row["image_width"])}
Mean intensity: {row["mean_intensity"]:.4f}
Mean edge magnitude: {row["mean_edge_magnitude"]:.4f}
Maximum edge magnitude: {row["max_edge_magnitude"]:.4f}
Edge pixels above threshold: {int(row["edge_pixels_above_threshold"])}
## Interpretation
- The synthetic image creates a controlled test case for visual processing.
- Sobel filters demonstrate how local convolution highlights spatial edges.
- Edge magnitude records can be used to inspect basic feature extraction.
- Real-world systems should add metadata for sensor type, lighting, resolution,
compression, acquisition context, and labeling assumptions.
- Visual diagnostics should be reviewed before model outputs are used in
safety-critical or institutionally consequential workflows.
"""
def main() -> None:
"""Run synthetic image, convolution, and edge diagnostics workflow."""
image = make_synthetic_image()
filtered = apply_edge_filters(image)
summary = summarize_image(image, filtered["edge_magnitude"])
memo = create_governance_memo(summary)
image_df = pd.DataFrame(image)
edge_df = pd.DataFrame(filtered["edge_magnitude"])
image_df.to_csv(OUTPUT_DIR / "python_synthetic_image.csv", index=False)
edge_df.to_csv(OUTPUT_DIR / "python_edge_magnitude.csv", index=False)
summary.to_csv(OUTPUT_DIR / "python_vision_diagnostic_summary.csv", index=False)
(OUTPUT_DIR / "python_vision_governance_memo.md").write_text(memo)
print("Vision diagnostic summary")
print(summary.T)
print("\nGovernance memo")
print(memo)
if __name__ == "__main__":
main()
This workflow is intentionally simple, but it exposes the core logic of convolutional perception: local filters transform raw pixels into feature maps that highlight structure. In production settings, the same governance logic should be extended to image provenance, sensor metadata, labeling assumptions, model versions, subgroup diagnostics, and downstream use.
R Workflow: Vision Error Diagnostics by Group
R is useful for evaluation summaries, grouped diagnostics, error analysis, and reporting. The following workflow simulates classification error rates across synthetic image groups and lighting conditions, then writes a governance-ready summary.
# Computer Vision and Machine Perception
# R workflow: vision error diagnostics by group.
#
# This educational workflow simulates classification error rates across
# synthetic image groups and lighting conditions.
set.seed(42)
if (!dir.exists("outputs")) {
dir.create("outputs")
}
n <- 1500
vision_eval <- data.frame(
image_id = paste0("IMG", sprintf("%04d", 1:n)),
image_group = sample(
c("A", "B", "C"),
n,
replace = TRUE,
prob = c(0.5, 0.3, 0.2)
),
lighting_condition = sample(
c("normal", "low_light", "harsh_light"),
n,
replace = TRUE,
prob = c(0.50, 0.30, 0.20)
),
target = rbinom(n, size = 1, prob = 0.4)
)
lighting_error <- ifelse(
vision_eval$lighting_condition == "normal", 0.08,
ifelse(vision_eval$lighting_condition == "low_light", 0.18, 0.14)
)
group_error <- ifelse(
vision_eval$image_group == "A", 1.00,
ifelse(vision_eval$image_group == "B", 1.20, 1.35)
)
error_probability <- pmin(lighting_error * group_error, 0.90)
is_error <- rbinom(n, size = 1, prob = error_probability)
vision_eval$prediction <- ifelse(
is_error == 1,
1 - vision_eval$target,
vision_eval$target
)
vision_eval$error <- vision_eval$prediction != vision_eval$target
group_summary <- aggregate(
error ~ image_group + lighting_condition,
data = vision_eval,
FUN = mean
)
names(group_summary)[3] <- "classification_error_rate"
overall_summary <- data.frame(
images_reviewed = nrow(vision_eval),
mean_error_rate = mean(vision_eval$error),
max_group_condition_error = max(group_summary$classification_error_rate),
min_group_condition_error = min(group_summary$classification_error_rate),
diagnostic_gap = max(group_summary$classification_error_rate) -
min(group_summary$classification_error_rate)
)
review_flags <- group_summary[
group_summary$classification_error_rate >
overall_summary$mean_error_rate + 0.05,
]
write.csv(vision_eval, "outputs/r_vision_error_records.csv", row.names = FALSE)
write.csv(group_summary, "outputs/r_vision_error_diagnostics.csv", row.names = FALSE)
write.csv(overall_summary, "outputs/r_vision_overall_summary.csv", row.names = FALSE)
write.csv(review_flags, "outputs/r_vision_review_flags.csv", row.names = FALSE)
memo <- paste0(
"# Computer Vision Error Diagnostics Memo\n\n",
"Images reviewed: ", nrow(vision_eval), "\n",
"Mean error rate: ", round(mean(vision_eval$error), 3), "\n",
"Maximum group-condition error rate: ",
round(max(group_summary$classification_error_rate), 3), "\n",
"Minimum group-condition error rate: ",
round(min(group_summary$classification_error_rate), 3), "\n",
"Diagnostic gap: ",
round(overall_summary$diagnostic_gap, 3), "\n\n",
"Interpretation:\n",
"- Aggregate accuracy should not be the only evaluation metric.\n",
"- Grouped diagnostics reveal whether error rates differ across image groups ",
"and lighting conditions.\n",
"- Groups with elevated error rates should trigger review before deployment ",
"in high-stakes settings.\n",
"- Real systems should extend this analysis to camera type, geography, ",
"lighting, image source, domain, sensor metadata, and relevant user groups ",
"when those categories are appropriate and ethically justified.\n"
)
writeLines(memo, "outputs/r_vision_error_diagnostics_memo.md")
print("Grouped computer vision diagnostics")
print(group_summary)
print("Overall summary")
print(overall_summary)
print("Review flags")
print(review_flags)
cat(memo)
This workflow is synthetic, but the diagnostic logic is real. Vision systems should not be evaluated only by aggregate accuracy. Error rates should be inspected across lighting conditions, camera types, domains, image sources, geographies, and user groups when those categories are relevant, privacy-preserving, and ethically appropriate.
GitHub Repository
The article body includes selected computational examples so the conceptual and mathematical argument remains readable. The full repository contains expanded computational infrastructure: advanced Jupyter notebooks, synthetic image generation, convolution demonstrations, feature extraction, classification baselines, patch embeddings, IoU calculations, robustness tests, grouped error diagnostics, SQL metadata schemas, model-card notes, governance documentation, and reproducible outputs.
Complete Code Repository
The full code distribution for this article includes Python, R, SQL, Julia, Rust, Go, TypeScript, C++, synthetic image data, convolution demos, edge detection workflows, segmentation diagnostics, IoU calculations, robustness testing, grouped vision diagnostics, SQL metadata, model-card notes, advanced notebooks, reproducible outputs, and audit scaffolding for studying computer vision and machine perception.
From Computer Vision to Auditable Machine Perception
Computer vision and machine perception show how artificial intelligence moves from abstract prediction into visual interpretation, spatial reasoning, and action. These systems transform images and videos into representations that can classify, detect, segment, retrieve, generate, or guide decisions. Their power comes from learned visual structure: convolutional filters, hierarchical features, residual representations, attention across patches, multimodal alignment, and structured prediction.
But machine perception also expands the stakes of AI governance. A visual model can misclassify a medical image, miss a pedestrian, misread a satellite scene, distort accessibility support, intensify surveillance, or automate visual judgment at scale. It can appear objective because it processes images, yet still inherit bias from datasets, sensors, labels, benchmarks, and institutions. Visual evidence can feel authoritative even when model uncertainty is high.
The future of computer vision will therefore depend not only on better models, but on better evaluation and governance. Robust systems must be tested across domains, lighting conditions, cameras, regions, populations, edge cases, and operational settings. They must document data provenance, labeling practices, sensor assumptions, model limitations, error patterns, uncertainty, and human oversight. They must be designed for correction, contestability, and appropriate use. In short, machine perception must become auditable.
Within the Artificial Intelligence Systems knowledge series, this article belongs near Deep Learning Systems: Representation, Scale, and Generalization, Neural Networks and Pattern Recognition, Speech Recognition and Multimodal AI Systems, Natural Language Processing and Computational Language Systems, Model Validation, Benchmarking, and Generalization Theory, Data Quality, Bias, and Measurement in Machine Learning, Human-AI Interaction and Interface Design, and Data Governance, Provenance, and Lineage in AI Systems. It provides the visual-perception bridge between representation learning, spatial inference, multimodal systems, and AI governance.
The final point is institutional. Computer vision systems do not simply interpret images; they help decide which visual evidence becomes legible, searchable, actionable, and authoritative. A responsible machine perception system should make visual interpretation more useful without making automated visual judgment unchallengeable.
Related Articles
- Machine Learning Foundations: How Systems Learn from Data
- Deep Learning Systems: Representation, Scale, and Generalization
- Neural Networks and Pattern Recognition
- Speech Recognition and Multimodal AI Systems
- Natural Language Processing and Computational Language Systems
- Model Validation, Benchmarking, and Generalization Theory
- Data Quality, Bias, and Measurement in Machine Learning
- Human-AI Interaction and Interface Design
- Data Governance, Provenance, and Lineage in AI Systems
Further Reading
- Krizhevsky, A., Sutskever, I. and Hinton, G.E. (2012) ‘ImageNet Classification with Deep Convolutional Neural Networks’, Advances in Neural Information Processing Systems. Available at: https://papers.nips.cc/paper/4824-imagenet-classification-with-deep-convolutional-neural-networks
- He, K., Zhang, X., Ren, S. and Sun, J. (2016) ‘Deep Residual Learning for Image Recognition’, Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. Available at: https://openaccess.thecvf.com/content_cvpr_2016/html/He_Deep_Residual_Learning_CVPR_2016_paper.html
- Dosovitskiy, A. et al. (2021) ‘An Image is Worth 16×16 Words: Transformers for Image Recognition at Scale’, International Conference on Learning Representations. Available at: https://openreview.net/forum?id=YicbFdNTTy
- LeCun, Y., Bengio, Y. and Hinton, G. (2015) ‘Deep learning’, Nature, 521, pp. 436–444. Available at: https://www.nature.com/articles/nature14539
- Russakovsky, O. et al. (2015) ‘ImageNet Large Scale Visual Recognition Challenge’, International Journal of Computer Vision, 115, pp. 211–252. Available at: https://arxiv.org/abs/1409.0575
- Goodfellow, I., Bengio, Y. and Courville, A. (2016) Deep Learning. Cambridge, MA: MIT Press. Available at: https://www.deeplearningbook.org/
- Szeliski, R. (2022) Computer Vision: Algorithms and Applications. 2nd edn. Available at: https://szeliski.org/Book/
- Radford, A. et al. (2021) ‘Learning Transferable Visual Models From Natural Language Supervision’, Proceedings of the 38th International Conference on Machine Learning, PMLR 139, pp. 8748–8763. Available at: https://arxiv.org/abs/2103.00020
References
- Dosovitskiy, A. et al. (2021) ‘An Image is Worth 16×16 Words: Transformers for Image Recognition at Scale’, International Conference on Learning Representations. Available at: https://openreview.net/forum?id=YicbFdNTTy
- Goodfellow, I., Bengio, Y. and Courville, A. (2016) Deep Learning. Cambridge, MA: MIT Press. Available at: https://www.deeplearningbook.org/
- He, K., Zhang, X., Ren, S. and Sun, J. (2016) ‘Deep Residual Learning for Image Recognition’, Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. Available at: https://openaccess.thecvf.com/content_cvpr_2016/html/He_Deep_Residual_Learning_CVPR_2016_paper.html
- Krizhevsky, A., Sutskever, I. and Hinton, G.E. (2012) ‘ImageNet Classification with Deep Convolutional Neural Networks’, Advances in Neural Information Processing Systems. Available at: https://papers.nips.cc/paper/4824-imagenet-classification-with-deep-convolutional-neural-networks
- LeCun, Y., Bengio, Y. and Hinton, G. (2015) ‘Deep learning’, Nature, 521, pp. 436–444. Available at: https://www.nature.com/articles/nature14539
- Radford, A. et al. (2021) ‘Learning Transferable Visual Models From Natural Language Supervision’, Proceedings of the 38th International Conference on Machine Learning, PMLR 139, pp. 8748–8763. Available at: https://arxiv.org/abs/2103.00020
- Russakovsky, O. et al. (2015) ‘ImageNet Large Scale Visual Recognition Challenge’, International Journal of Computer Vision, 115, pp. 211–252. Available at: https://arxiv.org/abs/1409.0575
- Szeliski, R. (2022) Computer Vision: Algorithms and Applications. 2nd edn. Available at: https://szeliski.org/Book/