
Last Updated May 10, 2026
AI security, misuse, and adversarial threats concern the ways artificial intelligence systems can be attacked, manipulated, exploited, abused, or repurposed in ways that create harm. As AI systems become embedded in search, enterprise workflows, software development, cybersecurity, scientific research, education, healthcare, finance, public administration, content moderation, infrastructure operations, and automated decision support, they become both targets and instruments of security risk. The problem is not only that models can fail. It is that adversaries, careless users, vendors, insiders, compromised systems, or automated agents may intentionally or unintentionally push AI systems outside their intended boundaries.
AI security is broader than conventional cybersecurity because AI systems introduce new attack surfaces: training data, fine-tuning data, model weights, prompts, embeddings, retrieval indexes, tool permissions, plugin ecosystems, agent workflows, evaluation pipelines, monitoring logs, and generated outputs. A secure AI system must therefore protect not only servers, networks, credentials, and endpoints, but also model behavior, data provenance, runtime context, downstream actions, and human oversight.
The security challenge is especially serious because AI systems often operate in ambiguous spaces between language, data, instruction, and action. A traditional application may treat code, configuration, credentials, user input, and database records as distinct categories. A language-model system may process instructions, documents, retrieved content, user messages, tool outputs, and operational context through the same representational channel. That creates distinctive risks: untrusted content can shape model behavior, retrieved documents can contain malicious instructions, agents can misinterpret tool outputs, and generated text can influence human decisions.
Main Library
Publications
Article Map
Artificial Intelligence Systems
Related Topic
Data Systems & Analytics
Related Topic
Embedded & Edge Systems
Related Topic
Intelligent Infrastructure Systems
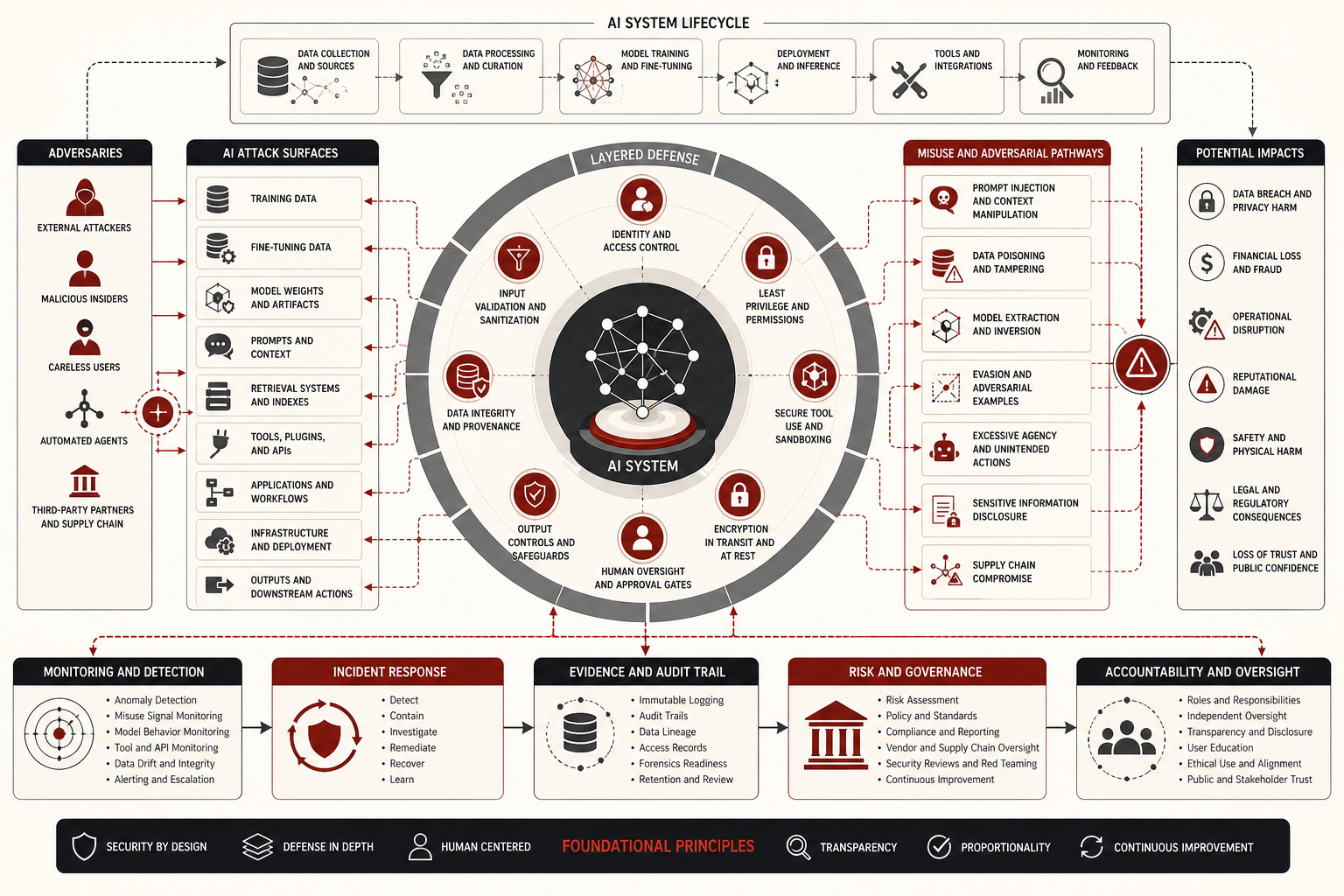
This article develops AI Security, Misuse, and Adversarial Threats as an advanced article within the Artificial Intelligence Systems knowledge series. It explains adversarial machine learning, prompt injection, data poisoning, model extraction, model inversion, evasion, misuse, insecure tool use, supply-chain exposure, sensitive information disclosure, excessive agency, monitoring, incident response, red teaming, governance, and secure-by-design AI architecture. Selected Python and R examples appear here, while the full GitHub repository contains expanded defensive scaffolding for AI security risk scoring, misuse monitoring, SQL governance schemas, incident templates, safe evaluation workflows, and reproducible notebooks.
Why AI Security Matters
AI security matters because AI systems are increasingly connected to real workflows. A model that only classifies images in a sandbox has a limited attack surface. A model connected to documents, code repositories, calendars, customer records, financial systems, databases, APIs, cloud tools, autonomous agents, or operational infrastructure has a much larger security boundary. In these environments, an AI failure may not remain a bad answer. It may become an unauthorized action, leaked information, poisoned record, corrupted workflow, reputational crisis, or institutional decision error.
Traditional security focuses heavily on confidentiality, integrity, and availability. AI security must preserve those properties while also protecting model behavior, data lineage, decision context, alignment boundaries, evaluation integrity, and downstream action safety. A system can be cryptographically secure and still vulnerable if malicious or untrusted content can alter model behavior, poison retrieval results, trigger unsafe tool calls, or manipulate human users through generated output.
AI security also matters because misuse does not always require sophisticated adversarial machine learning. Some harms arise from ordinary users over-trusting generated content, staff pasting sensitive data into tools, applications granting excessive permissions, or organizations deploying AI without logging, access control, review, and incident response. The security problem is therefore sociotechnical: it includes models, infrastructure, people, policies, incentives, and operational context.
The practical implication is that AI security cannot be added at the end of deployment. It must be designed into the architecture from the beginning. The security team must understand how the model receives context, how retrieval works, which tools can be called, what data can be accessed, what outputs can trigger actions, how logs are preserved, and who is responsible when something goes wrong. AI systems should be treated as operational systems, not merely as prediction engines.
Foundations of AI Security
AI security refers to the protection of AI systems from attacks, misuse, unauthorized access, data compromise, behavioral manipulation, and unsafe downstream effects. It includes the security of training data, model weights, prompts, retrieval systems, fine-tuning pipelines, deployment infrastructure, interfaces, tool permissions, monitoring systems, and outputs.
Security_{\mathrm{AI}} \neq Security_{\mathrm{IT}}
\]
Interpretation: AI security includes ordinary information security, but also model behavior, adversarial inputs, data poisoning, misuse pathways, retrieval integrity, tool access, and output handling.
AI systems introduce several security layers:
- Data security: protects training, validation, fine-tuning, retrieval, and operational data.
- Model security: protects weights, architecture, checkpoints, adapters, prompts, and inference behavior.
- Application security: protects APIs, interfaces, plugins, agents, and downstream services.
- Operational security: protects deployment, monitoring, incident response, logging, access control, and recovery.
- Governance security: defines acceptable use, misuse monitoring, escalation, accountability, and review.
AI security therefore cannot be delegated only to the model provider or only to the cybersecurity team. It requires coordination among machine learning engineers, application developers, security teams, legal teams, risk officers, product owners, domain experts, and governance leaders.
The central principle is defense in depth. No single safeguard is sufficient. Content filtering cannot replace access control. Prompt engineering cannot replace permission design. Model alignment cannot replace monitoring. Red teaming cannot replace incident response. Vendor assurances cannot replace internal governance. Secure AI systems require layered controls that reduce the probability of failure, limit impact when failure occurs, preserve evidence for investigation, and support recovery.
Security Properties for AI Systems
AI systems require familiar security properties and AI-specific extensions. Confidentiality, integrity, and availability remain essential, but they do not capture the full risk landscape. A secure AI system must also protect behavioral integrity, provenance, authorization boundaries, explainability of actions, and misuse resistance.
Important AI security properties include:
- Confidentiality: sensitive data, prompts, credentials, records, and outputs are protected from unauthorized disclosure.
- Integrity: data, models, retrieval indexes, prompts, tools, and outputs are protected from unauthorized modification or manipulation.
- Availability: AI services remain usable and resilient under load, failure, disruption, or attack.
- Behavioral reliability: the system resists manipulation that would cause it to violate intended boundaries.
- Provenance: data, model artifacts, retrieved sources, tool calls, and outputs remain traceable.
- Least privilege: models, agents, users, and tools receive only the permissions required for their tasks.
- Action safety: high-impact actions are validated, constrained, logged, and reviewed.
- Monitoring and accountability: suspicious behavior, misuse, policy violations, and incidents can be detected and investigated.
These properties are interdependent. A retrieval system with weak provenance may undermine output integrity. A tool-enabled agent with excessive permissions may undermine confidentiality and action safety. A monitoring system that fails to preserve logs may undermine accountability. A model that produces plausible but unverified outputs may undermine institutional decision integrity.
A secure AI architecture should therefore ask: What can the model see? What can it infer? What can it reveal? What can it cause? What can it modify? What can it call? What can it remember? What can it log? What can humans review? What can be rolled back?
Threat Modeling for AI Systems
Threat modeling asks what must be protected, who may try to compromise it, what capabilities they may have, what pathways they may use, what harms could result, and what controls are needed. In AI systems, threat modeling must cover the full lifecycle.
Important AI threat-modeling questions include:
- What data are used for training, fine-tuning, retrieval, and runtime inference?
- Can untrusted content enter prompts, context windows, retrieval indexes, or tool arguments?
- What tools, APIs, databases, or workflows can the AI system access?
- What permissions does the system have?
- Can outputs trigger downstream actions?
- Can users or adversaries extract sensitive information?
- Can the model be manipulated, copied, reverse-engineered, or probed?
- Can poisoned data influence future behavior?
- Can monitoring detect misuse, drift, policy violations, or anomalous behavior?
T = \{A, C, S, V, I, M\}
\]
Interpretation: A threat model \(T\) includes adversaries \(A\), capabilities \(C\), system assets \(S\), vulnerabilities \(V\), impacts \(I\), and mitigations \(M\).
Threat modeling should be repeated as the system changes. A chatbot without tools has one risk profile. The same model connected to email, code execution, payments, customer records, or external APIs has a different risk profile.
Threat models should also distinguish between external attackers, malicious insiders, negligent users, compromised vendors, automated bots, and accidental misuse. Each actor has different capabilities and pathways. A malicious external actor may probe a public interface. A careless employee may paste confidential records into a tool. A compromised dependency may tamper with the application layer. A poisoned retrieval document may influence the model’s context. A poorly configured agent may trigger actions beyond its intended scope.
A practical AI threat model should therefore include assets, actors, entry points, trust boundaries, permissions, expected actions, prohibited actions, logs, response plans, and fallback procedures.
Adversarial Machine Learning
Adversarial machine learning studies attacks and defenses involving machine learning systems. Common categories include evasion, poisoning, extraction, inversion, and privacy attacks. These categories should be understood at a high level for governance and defense, not as instructions for attack.
- Evasion: attempts to alter inputs so a deployed model misclassifies or behaves incorrectly.
- Poisoning: attempts to corrupt training, fine-tuning, or retrieval data so future behavior is degraded or manipulated.
- Model extraction: attempts to infer or copy model behavior through repeated queries or access patterns.
- Model inversion: attempts to infer sensitive properties of training data from model behavior.
- Membership inference: attempts to determine whether a particular record was included in training data.
- Backdoor behavior: hidden behavior that appears only under specific triggers or contexts.
The defensive lesson is that model performance under clean evaluation is not enough. Security evaluation must consider adversarial pressure, abnormal inputs, malicious context, suspicious query patterns, and data-integrity failures.
R_{\mathrm{adv}} = P(A_{\mathrm{success}} \mid C,V,D) \times I(A_{\mathrm{success}})
\]
Interpretation: Adversarial risk depends on the probability that an attack succeeds given attacker capability \(C\), vulnerability \(V\), and defenses \(D\), multiplied by the impact of success.
The goal of AI security is not to make attacks impossible in the abstract. The goal is to reduce likelihood, reduce impact, improve detection, preserve evidence, limit permissions, and enable recovery.
Security evaluation should therefore include both model-level and system-level testing. Model-level testing asks how the model behaves under unusual, adversarial, ambiguous, or out-of-distribution inputs. System-level testing asks what happens when model behavior interacts with retrieval systems, permissions, user interfaces, APIs, logs, and downstream workflows. A model that is relatively robust in isolation may still be unsafe when connected to tools without appropriate boundaries.
Generative AI, Prompt Injection, and Tool Risk
Generative AI systems introduce distinctive security problems because they process instructions, data, retrieved context, and user input through the same language channel. When untrusted content is placed into a model’s context, the model may not reliably distinguish system instructions from malicious or manipulative content.
Prompt injection is one of the most important generative AI risks. It occurs when user-provided or retrieved content attempts to alter model behavior in ways contrary to the system’s intended instructions. This may affect confidentiality, integrity, authorization, tool use, or downstream decisions.
\mathrm{Untrusted\ Content} \neq \mathrm{Trusted\ Instruction}
\]
Interpretation: Retrieved documents, user messages, web pages, files, and tool outputs should not be treated as trusted instructions for the system.
Tool use increases risk. An AI system that can only answer questions has limited operational effect. An AI system that can send messages, modify files, run code, query databases, issue refunds, update tickets, or trigger workflows can produce real-world consequences. Security design must therefore limit permissions, require confirmation for high-impact actions, validate tool arguments, sandbox execution, log activity, and separate reading from acting.
Important controls include:
- least-privilege tool permissions;
- separation of trusted instructions from untrusted content;
- input and output validation;
- tool-call allowlists;
- human approval for high-risk actions;
- retrieval-source trust scoring;
- secret and credential filtering;
- audit logging;
- runtime anomaly detection;
- incident response and rollback.
Prompt injection should not be treated as a problem that can be solved by a single clever instruction. It is a system problem. The safer approach is architectural: reduce what untrusted content can influence, constrain tools, separate privileges, verify actions, and log the path from input to output to tool call.
A secure generative AI system should also distinguish between answer generation and action authorization. The model may help draft, summarize, reason, or recommend, but authorization for consequential actions should come from trusted policy, validated user permissions, and appropriate human confirmation.
Agentic AI and Excessive Agency
Agentic AI systems introduce additional security concerns because they can plan, call tools, execute steps, observe results, and continue acting over time. The more autonomy an AI system has, the more important it becomes to define boundaries, permissions, termination conditions, and review requirements.
Excessive agency occurs when an AI system has more operational authority than the task requires. For example, an assistant that needs to draft an email may not need permission to send it. A system that needs to query a database may not need permission to modify records. A tool that summarizes tickets may not need permission to close them. A code assistant may need a sandbox rather than direct production access.
Risk_{\mathrm{agency}} \uparrow \quad \mathrm{as} \quad Permission_{\mathrm{scope}} \uparrow
\]
Interpretation: Agency risk increases as the scope of actions available to the AI system expands.
Agentic systems should therefore be designed with:
- bounded goals: the system should know what task it is allowed to perform and what tasks are out of scope;
- least-privilege permissions: tools should provide only the minimum necessary access;
- step-level validation: planned actions should be checked before execution;
- human approval gates: high-impact actions should require explicit confirmation;
- safe termination: the system should stop when uncertainty, errors, or policy boundaries are encountered;
- audit trails: each tool call, observation, and decision should be logged;
- rollback paths: reversible actions should be preferred, and recovery procedures should be defined.
The governance question is not simply whether an AI agent works. It is whether the organization can explain, constrain, monitor, and recover from what the agent does.
Data, Model, and Supply-Chain Security
AI systems depend on supply chains. Data may come from internal systems, vendors, public datasets, scraping pipelines, user submissions, synthetic generation, human labeling, third-party APIs, or retrieval sources. Models may depend on base models, checkpoints, adapters, embeddings, libraries, deployment services, hardware, and cloud infrastructure.
Supply-chain exposure matters because compromised components can undermine system integrity. A poisoned dataset, tampered model artifact, unsafe dependency, compromised retrieval source, or unverified fine-tuning adapter may introduce hidden security risk.
Integrity_{\mathrm{system}} = f(I_{\mathrm{data}}, I_{\mathrm{model}}, I_{\mathrm{code}}, I_{\mathrm{infra}}, I_{\mathrm{process}})
\]
Interpretation: System integrity depends on the integrity of data, model artifacts, code, infrastructure, and governance processes.
Practical controls include dataset provenance, artifact signing, dependency scanning, model cards, software bills of materials, access control, secure evaluation environments, vulnerability management, reproducible training records, and rollback capability.
Retrieval-augmented generation adds a distinctive supply-chain problem: the retrieval corpus becomes part of the model’s effective operating context. If a retrieval source is stale, manipulated, poorly permissioned, or insufficiently trusted, the model may generate misleading or unsafe outputs even when the base model itself has not changed. Retrieval security should therefore include source validation, document-level trust scoring, access-aware retrieval, versioning, content sanitation, and monitoring for unusual retrieval patterns.
Model supply chains also require lifecycle management. Organizations should know which model version is deployed, what evaluations were performed, what data or adapters were used, what limitations are documented, what vendor obligations apply, and how the system can be rolled back if a new release introduces unacceptable behavior.
Misuse, Dual Use, and Abuse Pathways
AI misuse occurs when systems are used for harmful, deceptive, illegal, unsafe, or unauthorized purposes. Misuse may be intentional or negligent. A system can be misused even when it is not technically compromised.
Misuse categories include:
- Information misuse: generating deceptive, manipulative, or harmful content.
- Cyber misuse: using AI to accelerate reconnaissance, social engineering, or unsafe automation.
- Privacy misuse: extracting, inferring, or exposing sensitive information.
- Operational misuse: granting systems excessive autonomy or permissions.
- Decision misuse: using AI outputs outside their validated context.
- Scientific or technical misuse: applying models to high-risk domains without appropriate safeguards.
R_{\mathrm{misuse}} = Capability \times Accessibility \times Intent \times Impact \times (1-Control)
\]
Interpretation: Misuse risk increases with capability, accessibility, malicious or negligent intent, and potential impact, and decreases with effective controls.
Responsible AI security must therefore combine technical safeguards with policy, monitoring, user education, access management, and enforcement.
Dual-use risk is especially difficult because the same capability may be beneficial or harmful depending on context. A model that summarizes scientific literature may support legitimate research or irresponsible technical application. A system that helps analyze logs may support defensive security or unsafe probing. A tool that drafts persuasive messages may support customer service or manipulation. Governance must therefore consider user roles, use context, permission levels, monitoring signals, and escalation thresholds.
Misuse governance should avoid two extremes. One extreme is assuming that acceptable-use policies alone are enough. The other is assuming that every possible misuse can be eliminated technically. The better approach is layered: restrict high-risk access, monitor suspicious behavior, require human review for sensitive use cases, preserve logs, update policies, and create response procedures when misuse occurs.
Monitoring, Detection, and Incident Response
AI security monitoring must watch both conventional and AI-specific signals. Conventional signals include authentication anomalies, suspicious API usage, privilege escalation, network events, and data exfiltration indicators. AI-specific signals include abnormal prompts, unusual tool calls, repeated probing, retrieval anomalies, output policy violations, unexpected model behavior, sudden performance degradation, and suspicious fine-tuning or embedding changes.
Monitoring should include:
- prompt and interaction metadata;
- tool-call frequency and arguments;
- retrieval-source anomalies;
- data-ingestion integrity checks;
- model-output policy violations;
- rate-limit and cost anomalies;
- sensitive-data exposure signals;
- model drift and behavior regression;
- user, role, and permission anomalies;
- incident escalation and remediation records.
Detect \rightarrow Contain \rightarrow Investigate \rightarrow Remediate \rightarrow Learn
\]
Interpretation: AI security incidents require detection, containment, investigation, remediation, and system learning.
Incident response should include the ability to disable tools, rotate credentials, quarantine data, roll back models, revoke access, preserve logs, notify stakeholders, and update safeguards.
AI incident response should also distinguish among model incidents, data incidents, tool incidents, user incidents, and governance incidents. A model incident may involve unexpected behavior. A data incident may involve leakage or poisoning. A tool incident may involve an unauthorized action. A user incident may involve misuse or policy violation. A governance incident may involve missing review, weak permissions, or inadequate monitoring. Classifying incidents correctly matters because different root causes require different remedies.
Governance, Red Teaming, and Accountability
AI security governance defines who is responsible for AI security risk, what standards apply, how systems are tested, how incidents are reported, and how deployment decisions are approved. Governance must include red teaming, misuse review, secure deployment criteria, vendor assessment, and ongoing monitoring.
Red teaming should be defensive and controlled. Its purpose is to identify weaknesses before adversaries exploit them. For AI systems, red teaming may examine whether the system leaks sensitive information, follows untrusted instructions, grants excessive tool access, fails under unusual inputs, mishandles retrieved content, or produces unsafe outputs.
Governance questions include:
- Has the AI system been threat-modeled?
- Are data and model artifacts traceable?
- Are tool permissions limited by least privilege?
- Are high-impact actions gated by human review?
- Are logs sufficient for investigation?
- Are prompt injection and retrieval risks tested?
- Are misuse scenarios reviewed before release?
- Are incidents classified and escalated?
- Are vendors required to disclose security practices?
- Can the system be paused, rolled back, or isolated?
Accountability is essential because AI security failures often occur across organizational boundaries. A vendor may supply the model. An internal team may build the application. A product team may define the workflow. A security team may monitor infrastructure. A governance team may approve deployment. A user may trigger a risky action. Without clear accountability, each actor can treat the failure as someone else’s responsibility.
A mature governance process should define system ownership, security review requirements, risk acceptance authority, incident escalation pathways, vendor obligations, and decommissioning authority. It should also require post-incident learning. The goal is not only to fix a specific failure, but to improve architecture, monitoring, training, and policy.
Common Failure Modes
AI security failures often arise from ordinary design weaknesses rather than exotic attacks. A system may be vulnerable because permissions are too broad, logs are incomplete, retrieval is poorly controlled, sensitive data are handled casually, or users misunderstand the tool’s authority.
| Failure Mode | Description | Likely Consequence | Defensive Response |
|---|---|---|---|
| Untrusted content treated as instruction | Retrieved documents or user content can influence system behavior as if they were trusted commands. | Prompt injection, unsafe tool use, or confidentiality failure. | Separate trusted instructions from untrusted content and constrain downstream actions. |
| Excessive tool permissions | The AI system can perform more actions than the task requires. | Unauthorized changes, data exposure, workflow corruption, or financial harm. | Apply least privilege, allowlists, confirmation gates, and sandboxing. |
| Weak retrieval governance | Retrieval sources are stale, manipulated, overbroad, or poorly permissioned. | Misleading outputs, data leakage, or poisoned context. | Use access-aware retrieval, provenance, trust scoring, and source validation. |
| Inadequate logging | Prompts, tool calls, retrieval events, or model versions are not recorded sufficiently. | Incidents cannot be investigated or corrected. | Preserve audit trails with privacy-aware logging and retention rules. |
| Overreliance on content filters | Filters are treated as the main security layer. | Unsafe actions remain possible through other pathways. | Use defense in depth across permissions, tools, monitoring, and governance. |
| Supply-chain opacity | Data, models, adapters, dependencies, or vendors are insufficiently traceable. | Hidden vulnerabilities or compromised components persist. | Require provenance, artifact controls, vendor review, and rollback capability. |
| No incident playbook | The organization has no defined response when AI misuse or compromise occurs. | Slow containment, evidence loss, recurring harm, and unclear accountability. | Create AI-specific incident response procedures and escalation paths. |
Note: Most AI security failures are architectural and operational. They cannot be solved by model behavior alone.
Limits and Open Problems
AI security remains an evolving field. Many systems are deployed faster than organizations can develop robust controls. Generative AI complicates traditional security assumptions because language models blur boundaries between instruction, data, context, and output. Agentic AI adds further risk by connecting models to tools and workflows. Open-source models, third-party adapters, cloud APIs, and retrieval systems create supply-chain complexity.
There are also measurement problems. It is difficult to know whether a model is secure against unknown adversarial strategies. Red-team results are useful but incomplete. Benchmark safety may not generalize to deployed environments. Prompt injection, retrieval manipulation, and misuse patterns may evolve quickly.
Another open problem is security usability. If safeguards are too burdensome, users may route around them. If safeguards are invisible, users may overtrust the system. If permissions are too restrictive, legitimate work may be blocked. If permissions are too broad, the system becomes dangerous. AI security must therefore balance usability, risk, explainability, and operational control.
The practical conclusion is that AI security should be treated as an ongoing lifecycle discipline rather than a one-time evaluation. Secure AI systems require defense in depth, continuous monitoring, controlled permissions, human oversight, incident response, and governance that evolves with the system.
Mathematical Lens
A deployed AI system can be represented as:
\hat{y}=f_{\theta}(x,c,t)
\]
Interpretation: The model \(f_{\theta}\) produces output \(\hat{y}\) from input \(x\), context \(c\), and tool or runtime environment \(t\).
Attack surface can be represented as:
S_{\mathrm{attack}} = S_{\mathrm{data}} \cup S_{\mathrm{model}} \cup S_{\mathrm{prompt}} \cup S_{\mathrm{retrieval}} \cup S_{\mathrm{tool}} \cup S_{\mathrm{infra}}
\]
Interpretation: The AI attack surface includes data, model, prompt, retrieval, tool, and infrastructure layers.
Adversarial risk can be represented as:
R_{\mathrm{adv}} = P(A_{\mathrm{success}}) \times I(A_{\mathrm{success}})
\]
Interpretation: Adversarial risk combines the probability of successful compromise with the impact of compromise.
Defensive control effectiveness can be represented as:
D_{\mathrm{eff}} = 1 – \prod_{i=1}^{n}(1-d_i)
\]
Interpretation: Defense effectiveness increases when multiple independent controls \(d_i\) reduce risk through defense in depth.
Residual risk can be represented as:
R_{\mathrm{residual}} = R_{\mathrm{inherent}}(1-D_{\mathrm{eff}})
\]
Interpretation: Residual risk is the remaining risk after controls reduce inherent risk.
Misuse monitoring can be represented as:
M_t = h(q_t,o_t,a_t,p_t)
\]
Interpretation: Misuse signal \(M_t\) may depend on query pattern \(q_t\), output pattern \(o_t\), action pattern \(a_t\), and permission context \(p_t\).
A least-privilege condition can be represented as:
P_{\mathrm{granted}} \leq P_{\mathrm{required}}
\]
Interpretation: The permissions granted to an AI system should not exceed the permissions required for its authorized task.
Variables and System Interpretation
| Symbol or Term | Meaning | Typical Type | System Interpretation |
|---|---|---|---|
| \(f_{\theta}\) | AI model | learned function | System that produces predictions, classifications, rankings, or generated outputs |
| \(x\) | Input | prompt, record, file, document, image, request | User or system-provided input processed by the AI model |
| \(c\) | Context | retrieved content, conversation state, metadata | Additional information that shapes model behavior |
| \(t\) | Tool environment | APIs, plugins, databases, code runners, services | External capabilities available to the AI system |
| \(S_{\mathrm{attack}}\) | Attack surface | set of exposed components | All system areas where adversarial pressure may enter |
| \(R_{\mathrm{adv}}\) | Adversarial risk | risk score | Expected risk from intentional attack or manipulation |
| \(R_{\mathrm{misuse}}\) | Misuse risk | risk score | Expected risk from harmful or unauthorized use |
| \(D_{\mathrm{eff}}\) | Defense effectiveness | control effectiveness measure | Risk reduction achieved through layered safeguards |
| \(R_{\mathrm{residual}}\) | Residual risk | remaining risk | Risk that remains after mitigation |
| \(M_t\) | Misuse signal | monitoring indicator | Evidence of suspicious, unsafe, or unauthorized behavior over time |
| \(P_{\mathrm{granted}}\) | Granted permissions | permission set or access level | What the AI system is allowed to access or do |
| \(P_{\mathrm{required}}\) | Required permissions | permission set or access level | What the task actually requires |
Note: AI security must be assessed across data, model, prompt, retrieval, tool, infrastructure, monitoring, and governance layers.
Worked Example: Securing an AI Assistant with Tool Access
Suppose an enterprise deploys an AI assistant that can search internal documents, summarize customer records, draft emails, and create support tickets. At first glance, the system appears to be a productivity tool. From a security perspective, however, it has several risk layers: document access, sensitive information, retrieval integrity, user permissions, generated outputs, and workflow actions.
A weak deployment may allow the assistant to retrieve broad internal content, follow instructions embedded in documents, draft external messages, and create tickets without review. In that configuration, untrusted content may influence trusted actions.
A stronger deployment separates reading from acting:
Permission_{\mathrm{read}} \neq Permission_{\mathrm{act}}
\]
Interpretation: The ability to read information should not automatically grant the ability to modify systems or trigger external actions.
The organization should define tool permissions, classify sensitive data, apply retrieval trust scores, require human confirmation for high-impact actions, log all tool calls, and monitor anomalies.
For high-risk actions:
Action_{\mathrm{high\ impact}} \rightarrow Human\ Approval
\]
Interpretation: High-impact actions should require review, confirmation, or escalation before execution.
This example shows that AI security is not only about preventing bad outputs. It is about controlling what outputs can do.
A secure version of this assistant would use role-based access control, access-aware retrieval, source provenance, tool-call allowlists, secret filtering, human approval for external communication, and incident logging. It would also restrict what retrieved documents can instruct the model to do. A document should be treated as information, not as authority. The model may summarize it, but it should not obey hidden instructions inside it.
Computational Modeling
Computational modeling can make AI security governance more concrete. A defensive risk-scoring workflow can evaluate threat likelihood, impact, exposure, and control strength. A monitoring workflow can track suspicious usage patterns. A governance schema can preserve incident records, model versions, tool permissions, and remediation history. A sensitivity analysis can show which controls most reduce residual risk.
The examples below are intentionally lightweight so the article remains readable and WordPress-friendly. The GitHub repository extends the same logic into SQL schemas, documentation templates, defensive monitoring workflows, incident response templates, red-team tracking, and reproducible outputs.
These examples do not implement attack techniques. They are governance and defensive-analysis examples. Their purpose is to help organizations inventory assets, estimate risk, prioritize controls, monitor misuse signals, and maintain accountability.
Python Workflow: Defensive AI Security Risk Scoring
"""
AI Security, Misuse, and Adversarial Threats Mini-Workflow
This defensive example demonstrates:
1. AI system asset inventory
2. high-level risk scoring
3. control effectiveness scoring
4. residual risk estimation
5. governance-oriented prioritization
It is educational and uses synthetic data.
It does not implement attack techniques.
"""
from __future__ import annotations
import pandas as pd
assets = pd.DataFrame({
"asset": [
"training_data",
"fine_tuning_pipeline",
"retrieval_index",
"system_prompt",
"model_endpoint",
"tool_api_gateway",
"audit_logs",
"monitoring_pipeline"
],
"exposure": [0.50, 0.45, 0.75, 0.65, 0.80, 0.90, 0.40, 0.55],
"impact": [0.85, 0.80, 0.75, 0.70, 0.90, 0.95, 0.65, 0.70],
"threat_likelihood": [0.40, 0.35, 0.60, 0.55, 0.65, 0.70, 0.30, 0.45],
"control_strength": [0.60, 0.55, 0.50, 0.45, 0.65, 0.55, 0.70, 0.60]
})
assets["inherent_risk"] = (
assets["exposure"] *
assets["impact"] *
assets["threat_likelihood"]
)
assets["residual_risk"] = (
assets["inherent_risk"] *
(1 - assets["control_strength"])
)
assets["risk_band"] = pd.cut(
assets["residual_risk"],
bins=[0, 0.10, 0.20, 1.00],
labels=["low", "moderate", "high"],
include_lowest=True
)
priority = assets.sort_values("residual_risk", ascending=False)
print(priority)This workflow treats AI security as an asset and control problem. The highest priority is not simply the most exposed component or the most valuable component. It is the component where exposure, impact, threat likelihood, and control weakness combine to produce high residual risk.
R Workflow: Misuse Monitoring and Security-Risk Summary
# AI Security, Misuse, and Adversarial Threats Diagnostics
#
# This defensive workflow simulates high-level monitoring indicators:
# - unusual query rate
# - tool-call intensity
# - sensitive-output flags
# - permission-risk level
# - residual security risk
#
# It does not implement attack techniques.
set.seed(42)
n <- 500
events <- data.frame(
event_id = 1:n,
unusual_query_score = runif(n, 0, 1),
tool_call_intensity = runif(n, 0, 1),
sensitive_output_signal = runif(n, 0, 1),
permission_risk = runif(n, 0, 1),
control_strength = runif(n, 0.30, 0.90)
)
events$misuse_signal <-
0.30 * events$unusual_query_score +
0.25 * events$tool_call_intensity +
0.25 * events$sensitive_output_signal +
0.20 * events$permission_risk
events$residual_risk <- events$misuse_signal * (1 - events$control_strength)
events$risk_band <- ifelse(
events$residual_risk < 0.15,
"low",
ifelse(events$residual_risk < 0.30, "moderate", "high")
)
summary_table <- aggregate(
cbind(misuse_signal, residual_risk) ~ risk_band,
data = events,
FUN = mean
)
print(summary_table)This workflow models misuse monitoring as a signal-detection problem. A single unusual event may not indicate misuse, but a pattern of unusual queries, intense tool use, sensitive-output signals, and high permission risk should trigger closer review.
GitHub Repository
The article body includes selected computational examples so the conceptual and mathematical argument remains readable. The full repository contains expanded computational infrastructure for defensive AI security risk scoring, misuse monitoring, incident logging schemas, SQL governance tables, Rust and Go examples, Julia sensitivity analysis, TypeScript validation, C++ scoring, documentation templates, and reproducible notebooks.
From Model Safety to Security Architecture
AI security, misuse, and adversarial threats show why responsible AI cannot rely only on model alignment, content filters, or acceptable-use policies. Security must be designed into the architecture: data provenance, access control, retrieval integrity, prompt isolation, tool permissions, output validation, monitoring, incident response, and governance.
The central lesson is that AI systems are not only reasoning systems. They are operational systems. Once connected to tools, data, and workflows, they become part of an organization’s security boundary. Misuse and adversarial threats therefore have to be managed through defense in depth, not through any single safeguard.
This shift changes the meaning of responsible AI. A responsible model is not enough if the surrounding application grants excessive permissions, fails to log tool calls, retrieves untrusted content without controls, or lacks a response plan. Likewise, a secure infrastructure perimeter is not enough if the model can be manipulated through context, retrieval, or generated instructions. AI security requires the integration of model evaluation, application security, data governance, operational monitoring, and institutional accountability.
Within the Artificial Intelligence Systems knowledge series, this article belongs near Robustness and Adversarial Resilience in Machine Learning, Human Oversight, Contestability, and AI Accountability, AI Agents, Tool Use, and Workflow Automation, Retrieval-Augmented Generation and AI Knowledge Systems, Model Monitoring, Drift, and AI Observability, and AI Governance and Regulatory Systems. It provides the security layer for understanding how AI systems should be protected, monitored, constrained, and governed.
Related Articles
- Artificial Intelligence Systems
- Robustness and Adversarial Resilience in Machine Learning
- Human Oversight, Contestability, and AI Accountability
- AI Agents, Tool Use, and Workflow Automation
- Retrieval-Augmented Generation and AI Knowledge Systems
- Model Monitoring, Drift, and AI Observability
- AI Governance and Regulatory Systems
Further Reading
- NIST (2025) Adversarial Machine Learning: A Taxonomy and Terminology of Attacks and Mitigations. Available at: https://csrc.nist.gov/pubs/ai/100/2/e2025/final
- NIST (2023) Artificial Intelligence Risk Management Framework. Available at: https://www.nist.gov/itl/ai-risk-management-framework
- OWASP (2025) OWASP Top 10 for Large Language Model Applications. Available at: https://owasp.org/www-project-top-10-for-large-language-model-applications/
- OWASP Gen AI Security Project (2025) LLM01: Prompt Injection. Available at: https://genai.owasp.org/llmrisk/llm01-prompt-injection/
- MITRE (ongoing) MITRE ATLAS: Adversarial Threat Landscape for Artificial-Intelligence Systems. Available at: https://atlas.mitre.org/
- ISO (2023) ISO/IEC 42001:2023 Artificial Intelligence Management System. Available at: https://www.iso.org/standard/42001
- Goodfellow, I.J., Shlens, J. and Szegedy, C. (2015) ‘Explaining and Harnessing Adversarial Examples’. Available at: https://arxiv.org/abs/1412.6572
References
- Goodfellow, I.J., Shlens, J. and Szegedy, C. (2015) ‘Explaining and Harnessing Adversarial Examples’. Available at: https://arxiv.org/abs/1412.6572
- ISO (2023) ISO/IEC 42001:2023: Information Technology — Artificial Intelligence — Management System. International Organization for Standardization. Available at: https://www.iso.org/standard/42001
- MITRE (ongoing) MITRE ATLAS: Adversarial Threat Landscape for Artificial-Intelligence Systems. Available at: https://atlas.mitre.org/
- NIST (2023) Artificial Intelligence Risk Management Framework (AI RMF 1.0). National Institute of Standards and Technology. Available at: https://www.nist.gov/itl/ai-risk-management-framework
- NIST (2025) Adversarial Machine Learning: A Taxonomy and Terminology of Attacks and Mitigations. National Institute of Standards and Technology. Available at: https://csrc.nist.gov/pubs/ai/100/2/e2025/final
- OWASP (2025) OWASP Top 10 for Large Language Model Applications. OWASP Foundation. Available at: https://owasp.org/www-project-top-10-for-large-language-model-applications/
- OWASP Gen AI Security Project (2025) LLM01: Prompt Injection. OWASP Foundation. Available at: https://genai.owasp.org/llmrisk/llm01-prompt-injection/