
Last Updated May 12, 2026
Real-time operating systems in embedded computing provide structured task scheduling, interrupt coordination, timing control, synchronization, and resource management for devices that must respond to events within defined temporal bounds. In embedded systems, an RTOS is not simply a smaller operating system. It is a control framework for making concurrency, latency, determinism, and temporal correctness manageable under real-world constraints.
Embedded systems frequently operate in environments where correctness depends not only on what the software does, but on when it does it. A control loop must execute before the next physical state changes. A sensor reading must be sampled on schedule. A communications buffer must be serviced before it overruns. An actuator command must arrive with bounded latency. A watchdog must be serviced only when meaningful progress has occurred. In such contexts, timing is not a secondary performance issue. It is part of the architecture of dependable operation.
This is the context in which real-time operating systems matter. An RTOS helps embedded designers coordinate multiple activities that would otherwise compete for processor time, memory, peripherals, shared buses, interrupt attention, and power-state transitions in ways that quickly become brittle. By structuring execution into tasks, priorities, timing services, synchronization mechanisms, event queues, and defined scheduling behavior, the RTOS makes it possible to reason more clearly about responsiveness, latency, jitter, and bounded execution.
Yet an RTOS is not automatically necessary in every embedded device. Many small systems remain well served by superloops, event-driven control, cooperative scheduling, or bare-metal firmware. The architectural question is not whether an RTOS is inherently better, but whether the system’s concurrency, timing, safety, observability, power, and maintainability requirements justify the overhead and discipline of an operating kernel. That proportional view is essential, because RTOS adoption is a design choice about system structure, not a badge of technical seriousness.
A strong RTOS design is therefore not defined by the presence of tasks alone. It is defined by whether the system has clear timing requirements, justified priorities, bounded interrupt work, disciplined synchronization, stack and memory evidence, latency measurements, scheduling assumptions, overload behavior, and diagnostic telemetry. The kernel provides mechanisms. The architecture determines whether those mechanisms produce temporal control or merely more complicated failure modes.
Main Library
Publications
Article Map
Embedded & Edge Systems
Related Topic
Firmware & Device Control
Related Topic
Low-Power Embedded Design
Related Topic
Reliability & Fault Tolerance
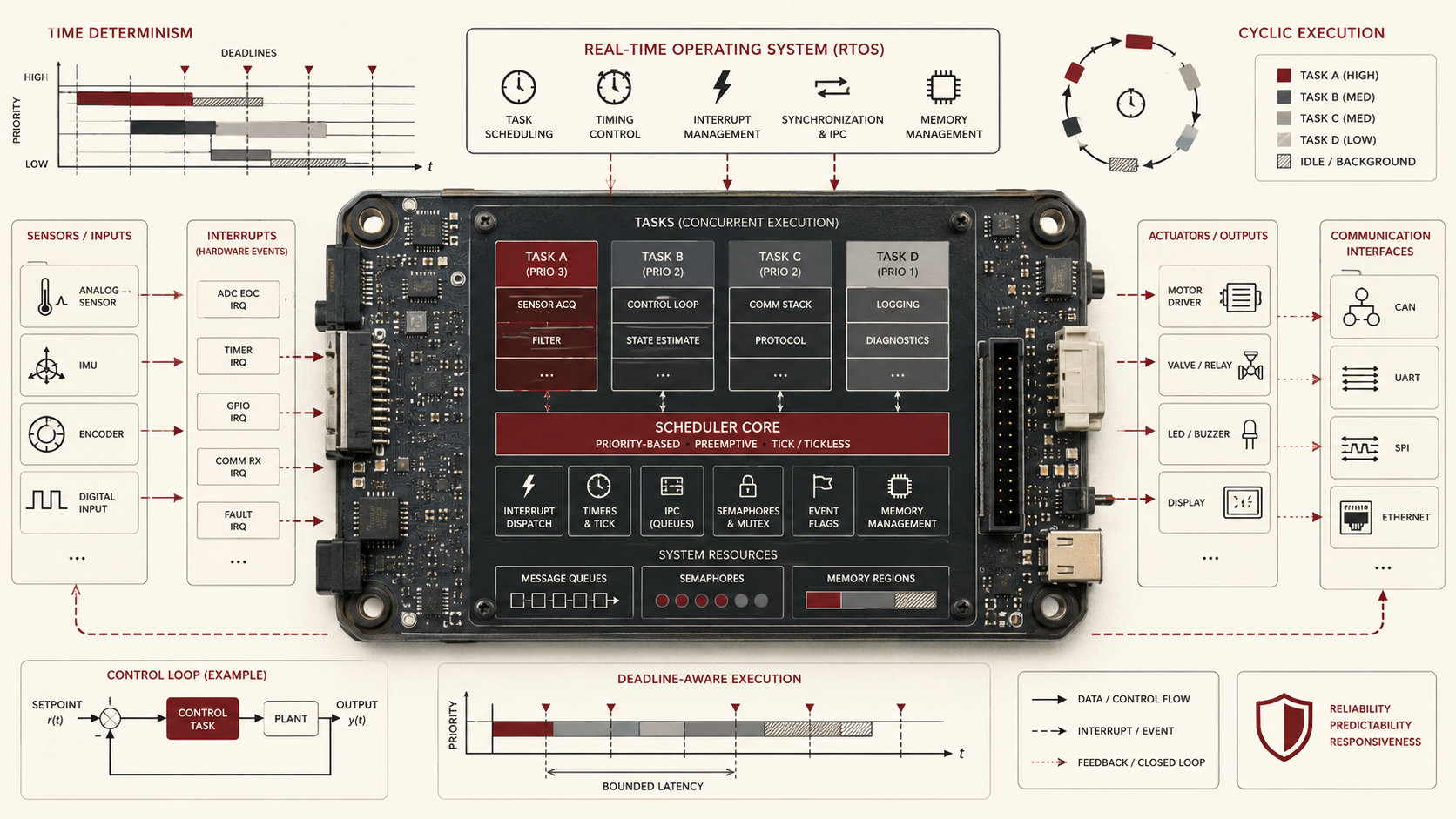
The engineering question is therefore not merely whether a device uses an RTOS. It is whether the execution model makes timing behavior explicit enough to analyze, measure, test, and maintain. A kernel can improve architectural clarity, but only when priorities, deadlines, synchronization, memory, interrupt behavior, power-state behavior, and field diagnostics are designed with discipline.
Engineering Problem
The engineering problem is how to coordinate multiple time-sensitive activities on constrained hardware without losing control over latency, ordering, memory, shared resources, interrupt interference, or power behavior. Embedded software must often handle periodic control loops, asynchronous interrupts, communications stacks, sensor acquisition, local processing, diagnostics, logging, watchdog supervision, and power management within one device. As these responsibilities grow, a simple execution loop may no longer make the timing architecture visible enough to reason about.
A weak design can fail in several ways. A high-priority task may miss a deadline because a lower-priority task holds a mutex. A communication task may fill a queue faster than another task can consume it. An interrupt handler may run too long and inject jitter into control timing. A stack may overflow under an uncommon call path. A driver may block inside a task that was expected to be periodic. A tick configuration may create more wakeups than the low-power budget can tolerate. A task may appear alive while silently processing stale data.
A rigorous RTOS design should be able to answer several questions. What are the critical tasks? What are their periods, deadlines, and worst-case execution times? Which tasks are hard real-time, soft real-time, firm real-time, or best-effort? What are the priority assignments? What blocking is possible? What queues can overflow? Which work happens in interrupt context and which is deferred? How large are task stacks under worst-case conditions? What timing evidence exists from trace logs or field telemetry? How does the scheduler interact with low-power states?
The central challenge is not merely adding concurrency. It is designing concurrency so that temporal behavior remains bounded, observable, power-aware, and proportional to the system’s physical responsibilities.
Reference Architecture
A practical RTOS-based embedded architecture can be understood as a layered timing-control stack. The exact implementation may use FreeRTOS, Zephyr, CMSIS-RTOS2, ThreadX, RTEMS, NuttX, or a vendor-specific kernel, but the architectural responsibilities remain consistent.
| Layer | Engineering Role | Timing Concern | Evidence Artifact |
|---|---|---|---|
| Requirements layer | Defines timing, responsiveness, safety, and service requirements | Periods, deadlines, latency limits, jitter tolerance, loss tolerance | Timing requirements table, criticality classification, deadline map |
| Task model layer | Maps system responsibilities into tasks or threads | Task decomposition, priority discipline, stack footprint, lifecycle | Task manifest, stack budget, priority table |
| Scheduler layer | Chooses which task runs at each reschedule point | Preemption, cooperative behavior, time slicing, priority ordering | Scheduling policy, trace log, utilization model |
| Interrupt layer | Handles urgent hardware events and signals deferred work | ISR latency, ISR duration, interrupt nesting, scheduler interaction | Interrupt map, latency measurement, ISR budget |
| Deferred-work layer | Moves non-urgent processing out of ISR context | Work queues, task notifications, event flags, queue latency | Deferred-work policy, queue-depth report, event trace |
| Synchronization layer | Coordinates shared resources and task communication | Mutexes, semaphores, queues, priority inversion, blocking time | Resource graph, blocking analysis, lock-order policy |
| Memory layer | Controls task stacks, kernel objects, buffers, heaps, and static allocation | Stack overflow, fragmentation, queue footprint, bounded allocation | Stack watermark report, memory budget, heap policy |
| Power layer | Coordinates idle time, tickless behavior, device sleep, and wake events | Sleep eligibility, timer wakeups, retained state, wake latency | Power-state trace, idle residency report, wake-source log |
| Observability layer | Records runtime timing evidence | Deadline misses, task runtime, jitter, queue depth, ISR load, resets | Trace data, telemetry schema, runtime counters, fleet report |
| Verification layer | Tests whether timing assumptions hold under realistic load | Worst-case execution time, deadline adherence, overload behavior, recovery | HIL test, scheduling simulation, trace review, regression report |
This architecture separates kernel mechanisms from temporal assurance. A system is not temporally controlled merely because it has a scheduler. It becomes temporally controlled when tasks, priorities, interrupts, synchronization, memory, power, and observability are designed as one timing architecture.
Implementation Pattern
A rigorous RTOS implementation begins with a task and timing model rather than a pile of threads. The system should identify which responsibilities are periodic, which are event-driven, which are urgent, which are background, which may block, and which must never miss deadlines.
| Artifact | Purpose | Typical Format |
|---|---|---|
| Task manifest | Defines each task, priority, period, deadline, stack size, and responsibility | YAML, CSV, design table, RTOS configuration note |
| Criticality map | Classifies tasks as hard real-time, firm real-time, soft real-time, best-effort, or maintenance | Markdown, risk table, timing requirements matrix |
| Priority assignment | Documents why each priority is chosen | Priority table, rate-monotonic/deadline-monotonic rationale, review note |
| Interrupt budget | Defines ISR responsibilities, maximum ISR duration, and deferred-work mechanism | Interrupt map, latency table, trace report |
| Synchronization policy | Defines queues, mutexes, semaphores, event flags, notifications, lock ordering, and priority-inheritance assumptions | Resource graph, lock policy, blocking analysis |
| Queue and buffer sizing plan | Defines burst tolerance, producer/consumer relationships, stale-data behavior, and overflow policy | Queue-depth budget, overload policy, trace counters |
| Stack and memory budget | Defines task stacks, heap usage, kernel-object footprint, and allocation policy | Stack watermark report, memory map, static allocation plan |
| Timing verification plan | Tests deadline adherence, jitter, latency, overload behavior, and watchdog progress | Trace script, HIL test, Python simulation, timing report |
| Power coordination policy | Defines idle task behavior, tickless mode assumptions, sleep eligibility, timer wakeups, and wake sources | Power-state manifest, idle-residency report, wake log |
| Runtime telemetry schema | Defines task runtime, deadline misses, queue high-water marks, stack watermarks, ISR load, and resets | SQL, CSV, JSON Schema, R fleet report |
The implementation goal is to make concurrency accountable. Engineers should be able to determine why a task exists, how urgent it is, what can block it, how much stack it consumes, what evidence proves it meets its timing budget, and what happens when the system is overloaded.
Research-Grade Framing: RTOS as Temporal Control Architecture
An RTOS should be framed as a temporal control architecture. It is not merely a convenience library for multitasking, nor is it a guarantee of real-time correctness. It is a kernel-level structure for expressing which work is urgent, which work can wait, which events must preempt other events, how shared resources are coordinated, and how execution evidence is captured.
This framing matters because RTOS failures are often failures of design discipline rather than kernel mechanics. Tasks may be added without a timing model. Priorities may be assigned by intuition rather than consequence. Mutexes may conceal priority inversion. Queues may hide overload. Interrupts may contain too much work. Dynamic allocation may introduce uncertainty. Low-power features may be undermined by timer wakeups. Trace data may be absent, leaving deadline misses invisible.
| Temporal Dimension | Question | Required Evidence |
|---|---|---|
| Task purpose | Does each task represent a clear timing or architectural responsibility? | Task manifest, responsibility map, priority rationale |
| Schedulability | Can the task set meet its periods and deadlines under expected load? | Utilization analysis, response-time analysis, simulation, trace data |
| Latency control | Are interrupt, scheduling, queue, and task response times bounded? | Latency budget, ISR trace, runtime timing counters |
| Blocking discipline | Are shared-resource delays known and minimized? | Resource graph, lock-order policy, blocking-time estimate |
| Memory discipline | Are task stacks and kernel-object footprints sized and observed? | Stack watermark report, heap policy, memory budget |
| Overload behavior | Does the system degrade predictably under burst load or missed deadlines? | Queue overflow policy, stale-data policy, overload test |
| Power coherence | Does the RTOS timing model cooperate with sleep and wake behavior? | Idle residency report, tickless test, wake-source log |
| Operational evidence | Can field systems report timing failures and runtime pressure? | Trace records, telemetry schema, fleet report |
In this framing, an RTOS is not a shortcut around systems thinking. It is a demand for more explicit systems thinking, because concurrency that was once hidden in loops and interrupts becomes visible as a schedulable, measurable, and testable structure.
Formal Model: Tasks, Deadlines, Blocking, and Schedulability
A useful formal model separates tasks, execution time, periods, deadlines, blocking, interrupt interference, and jitter. Let each task \(\tau_i\) have worst-case execution time \(C_i\), period \(T_i\), deadline \(D_i\), blocking time \(B_i\), release jitter \(J_i\), and priority \(P_i\).
\tau_i = (C_i, T_i, D_i, B_i, J_i, P_i)
\]
Interpretation: A real-time task is not just a function or thread. It is a timing contract: how long it may execute, how often it runs, when it must finish, what can block it, and how it is prioritized.
U = \sum_{i=1}^{n} \frac{C_i}{T_i}
\]
Interpretation: Processor utilization estimates how much CPU time the periodic task set requires. Utilization alone does not prove correctness, but it is an early warning when load approaches unsafe levels.
R_i = C_i + B_i + I_i
\]
Interpretation: Task response time includes execution time, blocking time, and interference from higher-priority work. A task meets its deadline only when \(R_i \leq D_i\).
J_i = \max(r_i) – \min(r_i)
\]
Interpretation: Jitter measures variation in activation or response timing. Low average latency is not enough when variation itself can harm control, sampling, or communications behavior.
Q_{\mathrm{risk}} = \frac{\lambda_{\mathrm{producer}}}{\mu_{\mathrm{consumer}}}
\]
Interpretation: Queue risk increases when the producer rate approaches or exceeds the consumer service rate. RTOS queues decouple tasks, but they do not eliminate overload.
This model makes a key point: RTOS correctness is not equivalent to kernel correctness. The kernel may work perfectly while the task set remains unschedulable, blocked, overloaded, or unobservable.
What Is a Real-Time Operating System?
A real-time operating system is an operating environment designed to support predictable execution in systems where timing matters. Unlike general-purpose operating systems, which are typically optimized for throughput, flexibility, fairness, or user responsiveness across varied workloads, an RTOS is organized around bounded behavior. It provides mechanisms for multitasking, scheduling, interrupt integration, synchronization, memory discipline, and timing services in ways that help embedded applications meet defined temporal requirements.
The phrase real time is often misunderstood. It does not necessarily mean “extremely fast.” It means that the system must respond within time bounds that are meaningful for the application. Some systems require microsecond-scale responsiveness. Others operate on slower cycles but still depend on predictable deadlines. What matters is not speed in the abstract, but temporal correctness relative to the system’s physical or logical environment.
RTOSes therefore sit in a distinct architectural position. They help transform a processor from a sequential executor of firmware into a managed execution environment where multiple time-sensitive activities can coexist with explicit control over scheduling, synchronization, timers, and resource access.
A useful distinction is between hard real-time, firm real-time, and soft real-time behavior. In hard real-time systems, missing a deadline may be considered system failure. In firm real-time systems, late results may have no value even if occasional misses are tolerable. In soft real-time systems, lateness degrades quality but does not necessarily constitute immediate failure. A serious RTOS design identifies which category applies to each function rather than treating all tasks as equally urgent.
Why RTOSes Matter in Embedded Systems
Embedded systems often begin simply. One routine reads sensors, another updates outputs, another handles communication, and a timer triggers periodic work. In very small devices, these responsibilities can sometimes be serialized in a loop. But as systems grow in complexity, simple control flow becomes harder to maintain. Communication stacks, periodic sampling, error logging, user interfaces, power management, diagnostics, watchdog supervision, and control logic begin to compete for execution time. A design that was once understandable can become a fragile web of interrupts, flags, and implicit assumptions.
An RTOS matters because it provides explicit structure for this complexity. It allows software activities to be separated into tasks with defined priorities and responsibilities. It provides timers, queues, semaphores, mutexes, event flags, task notifications, and scheduling services that make coordination more legible. The result is not magical correctness, but a better architecture for reasoning about concurrency and responsiveness.
This matters especially in devices that interact with the physical world. Cyber-physical systems do not tolerate timing failure gracefully. A delayed control loop can destabilize behavior. A sensor buffer overrun can corrupt interpretation. A blocked safety task can create material risk. A communications path that misses receive windows can drain power through retries. In such contexts, software architecture and timing architecture cannot be separated. They are part of the same system design problem.
The RTOS therefore matters most when concurrency has become a first-order system property. When several activities must coexist with bounded response times, the kernel can make concurrency explicit enough to analyze, test, and maintain.
Tasks, Threads, and Units of Execution
Most RTOSes organize execution around tasks or threads. These are independent units of work that the scheduler can activate, suspend, preempt, block, delay, or resume according to system rules. One task might handle communications, another might process sensor data, another might manage user input, another might run a control algorithm at fixed intervals, and another might perform lower-priority diagnostics.
This task-based model is powerful because it encourages architectural separation. Instead of building one monolithic control loop that must manually multiplex every responsibility, designers can decompose the system into smaller units with clearer boundaries. This improves readability and often improves maintainability. But it also introduces new obligations. Each task consumes stack space. Each interaction between tasks creates possible coordination or timing problems. Each priority choice becomes a design commitment.
Well-designed RTOS applications use tasks to clarify function, not to hide poor architecture. A system with dozens of poorly bounded tasks can be harder to reason about than a smaller bare-metal design. A task that exists only because a developer wanted another place to put code may add stack cost, scheduling overhead, synchronization complexity, and priority confusion without improving temporal control.
A strong task model defines responsibility, period, deadline, priority, stack size, blocking behavior, data ownership, queue relationships, watchdog progress criteria, shutdown behavior, and recovery behavior. Without those details, tasks are merely named concurrency rather than engineered concurrency.
Scheduling Models, Priorities, and Determinism
Scheduling is the core architectural function of an RTOS. The scheduler decides which task runs, when, and under what priority rules. In many embedded RTOSes, scheduling is priority-based and preemptive, allowing a higher-priority task to interrupt a lower-priority one when it becomes ready. Some kernels also support cooperative threads, round-robin time slicing among equal-priority tasks, symmetric multiprocessing, and, in richer implementations, deadline-aware or mixed scheduling policies. Those choices are not minor configuration details. They define how the system expresses urgency.
A sound RTOS design begins with priority discipline. High priority should be reserved for work whose lateness has the most serious consequences. But priority alone does not create determinism. A task that appears urgent on paper may still miss deadlines if it depends on a queue filled too late, waits on a locked resource, is delayed by interrupt load, or contends for a slow bus. Real-time design therefore requires systems thinking, not merely priority assignment.
Scheduling policy also changes how engineers reason about fairness, starvation, and jitter. Time slicing may improve responsiveness among equal-priority threads, but it can also introduce context-switch overhead and timing variation. Cooperative scheduling can simplify reasoning in selected domains, but it assumes disciplined yielding. Preemption improves latency for urgent work, but it makes synchronization and shared-state design more delicate.
The scheduler is therefore not just a kernel service. It is an architectural statement about what kinds of lateness the system will and will not tolerate. A timing-critical task should not merely be “high priority.” It should have a documented deadline, measured response time, known blocking paths, and trace evidence under realistic load.
Interrupts, Deferred Work, and Latency Control
Interrupts remain essential in embedded systems because they provide immediate response to external or internal events. A timer expires, a sensor completes a conversion, a communications peripheral receives data, a DMA transfer completes, or a fault condition is detected. The processor must react quickly. Yet raw interrupt-driven design becomes unstable when too much logic is placed directly inside interrupt service routines.
One of the most important architectural contributions of an RTOS is support for deferred work. Instead of doing all processing inside the ISR, the interrupt can perform the minimum urgent actions: capture a timestamp, acknowledge hardware state, move data into a safe buffer, signal a task, release a semaphore, or place an event in a queue. A higher-level task then completes the heavier work. This preserves responsiveness while reducing interrupt latency and keeping ISR execution bounded.
That separation matters because ISR time is one of the most expensive temporal resources in an embedded system. A long-running ISR can block lower-priority interrupts, delay scheduler activity, and inject jitter into tasks that were otherwise well designed. Good RTOS architecture therefore treats interrupts as the site of minimal urgent reaction, not as a place to hide whole application subsystems.
A rigorous interrupt design should specify ISR responsibilities, maximum ISR duration, shared-state rules, deferred-work mechanism, interrupt priority, nesting assumptions, and trace evidence. Interrupts are not outside the scheduler’s timing architecture. They are one of its most important sources of interference.
Synchronization, Shared Resources, and Coordination Hazards
Once a system contains multiple concurrent tasks, coordination becomes unavoidable. Tasks may need to exchange data, wait on events, signal completion, or share access to peripherals and buffers. RTOSes provide mechanisms such as queues, semaphores, mutexes, event flags, and task notifications to support this coordination. These primitives transform concurrency from a set of ad hoc conventions into explicit architectural relationships.
But synchronization primitives are double-edged. Used well, they preserve correctness and clarify communication paths. Used poorly, they create deadlocks, hidden latency, unnecessary contention, stale data, or priority inversion, in which a high-priority task is blocked by a lower-priority task holding a resource. In such cases, the formal priority model no longer reflects the actual execution order of the system. Some kernels address this partly through priority inheritance or related mechanisms, but the deeper solution is architectural restraint: keep critical sections short, reduce shared mutable state, and avoid unnecessary locking around slow operations.
Queues and mailboxes create a different class of risk. They decouple producers and consumers in useful ways, but they can also conceal overload until buffers fill or stale data accumulates. A full queue is not just a memory condition. It is evidence that the system’s temporal assumptions are failing. The producer is generating work faster than the consumer can safely process it, or the consumer is being delayed by priority, blocking, bus contention, or ISR load.
Synchronization is therefore never just about thread safety. It is about preserving logical clarity and temporal integrity at the same time.
Memory Management, Stack Discipline, and Footprint Control
Embedded RTOS design is always constrained by memory. Each task usually requires its own stack. Kernel objects consume memory. Queues, timers, buffers, mutexes, semaphores, event flags, and synchronization structures all have footprint costs. In a general-purpose system, these costs may seem modest. In a resource-constrained embedded device, they are central architectural decisions.
This is why many RTOS applications favor static or carefully bounded allocation strategies. Dynamic allocation is not impossible, but it introduces risks around fragmentation, exhaustion, allocation latency, and less predictable behavior over long lifecycles. In timing-sensitive systems, such uncertainty may be unacceptable. A kernel can support disciplined memory management, but it cannot rescue a design whose memory budget is fundamentally mismatched to its concurrency model.
Stack discipline is especially important. Every task’s stack must be large enough for worst-case call depth, interrupt interaction, library usage, local buffers, and error paths, yet small enough that total footprint remains realistic. Stack overflow protection and memory isolation features can help, but architecture still depends on honest sizing and observation.
Good RTOS design therefore treats memory as part of temporal design. Stack sizing affects stability. Queue sizing affects burst tolerance. Buffer placement affects latency. Heap policy affects predictability. Every additional task and abstraction carries a cost that must be justified.
Deadlines, Jitter, and Temporal Correctness
The defining promise of a real-time system is not high speed but temporal reliability. A task that usually runs on time but occasionally misses its deadline may still represent system failure. For that reason, RTOS design is deeply concerned with deadlines, response time, and jitter, the variation in timing from one activation to the next.
Jitter can arise from many sources: interrupt nesting, resource contention, poorly chosen priorities, bus delays, long critical sections, blocking calls, scheduler overhead, context switching, clock drift, timer granularity, cache effects in richer processors, or memory effects in complex platforms. The role of the RTOS is not to make these disappear automatically. It is to provide enough structure that they can be analyzed, bounded, and reduced.
Temporal correctness therefore involves more than configuring a scheduler. It requires alignment between application requirements, hardware behavior, interrupt strategy, synchronization design, memory discipline, and power-state behavior. A task that meets its deadline in a lab demo may still miss it under radio traffic, sensor bursts, storage writes, power transitions, or fault recovery.
This is why real-time analysis belongs at the systems level. Timing and latency are not merely software-performance concerns. They are properties of interacting components across the device: clocks, buses, peripherals, firmware, and control logic. An RTOS becomes valuable precisely because it gives that interaction a more explicit form.
RTOS Power Management, Tickless Idle, and Sleep Coordination
RTOS design is closely connected to low-power behavior. A scheduler creates idle time by allowing the system to know when no runnable tasks require the CPU. That idle time can be used to enter low-power states, suspend devices, or coordinate tickless idle modes in which periodic timer ticks are reduced or suppressed during sleep intervals. But this only works when timers, tasks, drivers, and wake sources are aligned.
A poorly designed RTOS application can defeat low-power goals. Tasks may wake too frequently. Timers may be configured at unnecessarily fine granularity. A polling task may prevent idle residency. A driver may hold a device active. A queue may wake a task repeatedly for low-value work. A kernel tick may create wakeups that are incompatible with the power budget. The result is a system that uses an RTOS but never realizes the energy benefits of structured idleness.
Runtime power management requires coordination between task state, device state, and wake-source state. A device can sleep only when no task needs it, no transaction is pending, no wake deadline will be missed, and retained state is sufficient for recovery. In richer embedded environments, device power management may include dependencies among devices, such as buses, regulators, sensors, radios, and storage components.
The RTOS therefore participates in power architecture. It helps reveal idle windows, but it can also destroy them if task structure, timers, and driver behavior are not disciplined.
RTOS Observability, Tracing, and Runtime Evidence
RTOS-based systems need runtime evidence. Without tracing or telemetry, timing problems can remain invisible until they appear as field failures: missed samples, communication drops, watchdog resets, buffer overruns, stale data, or power drain. A system that uses an RTOS but produces no scheduling evidence is difficult to verify beyond intuition.
Useful runtime signals include task runtime, deadline misses, task activation jitter, context-switch counts, queue depth high-water marks, stack watermarks, mutex contention, semaphore wait time, ISR counts, ISR duration, timer callbacks, idle residency, watchdog resets, and low-power wake causes. These signals support both bench validation and field maintenance.
Tracing is especially useful because many RTOS failures are relational. The problem is not that one task exists, but that one task blocks another, one queue backs up, one interrupt arrives too frequently, one stack grows unexpectedly, or one lower-priority resource holder delays a critical path. Trace data can make these relationships visible.
Observability should not be treated as optional polish. In a real-time system, runtime evidence is part of the assurance case. The system should not only attempt to meet deadlines. It should show whether it is meeting them.
RTOS vs Bare-Metal Approaches
Not every embedded system needs an RTOS. Simple devices with one dominant control loop, minimal concurrency, tight footprint limits, or extremely transparent timing paths may be better served by bare-metal firmware, a superloop, cooperative scheduling, or an event-driven design. In such cases, a kernel may add complexity without providing enough architectural benefit.
On the other hand, once a device must coordinate several concurrent activities with bounded responsiveness, a kernel can improve clarity and maintainability significantly. The transition point is usually not raw size, but complexity of interaction: multiple periodic tasks, asynchronous communications, deferred processing, modularized software teams, richer diagnostics, formal timing requirements, or runtime power management all increase the value of an RTOS.
The right comparison is therefore not “modern” versus “old-fashioned.” It is whether the system’s concurrency and timing demands justify the overhead and discipline of a kernel. A small but safety-critical device may need an RTOS. A larger but straightforward device may not. Good embedded architecture remains proportional.
The strongest designs are honest about trade-offs. RTOS adoption adds stack cost, kernel-object memory, scheduling overhead, synchronization complexity, and configuration burden. It also adds structure, modularity, scheduling services, synchronization primitives, and observability opportunities. Whether that exchange is worthwhile depends on the device’s timing architecture.
Contemporary RTOS Platforms
Several RTOS platforms are especially influential in embedded systems today. FreeRTOS remains widely used because it provides a compact real-time kernel and a familiar set of multitasking primitives across many architectures. It is often attractive for microcontroller-based products that need tasks, queues, semaphores, mutexes, timers, and predictable kernel behavior without a large embedded operating environment.
Zephyr has evolved into a broader embedded operating environment built around a small-footprint kernel, configurable subsystems, scheduling services, synchronization services, a device model, networking capabilities, logging, filesystems, and power-management features for resource-constrained and embedded systems. It is often useful when a product benefits from a more integrated embedded software ecosystem rather than only a minimal kernel.
CMSIS-RTOS2 occupies a different architectural role. It provides a standardized RTOS API for Arm Cortex-based devices so software components can be written against a common interface rather than a single kernel-specific API. This can improve reuse and integration, though it does not remove the need to understand the underlying kernel’s timing behavior, configuration, and limitations.
Those differences matter. A very small MCU-based control device may favor a minimal kernel with few abstractions. A more feature-rich embedded product may benefit from an RTOS ecosystem that includes device models, networking stacks, userspace or memory-domain support, logging, filesystems, and configuration control. The architectural point is not that one platform is universally superior. It is that contemporary RTOSes occupy different positions along the spectrum between minimal temporal kernel and fuller embedded operating framework.
Mathematical Lens: Utilization, Response Time, Blocking, and Jitter
A mathematical lens helps connect RTOS architecture to measurable timing behavior. Let each periodic task have worst-case execution time \(C_i\), period \(T_i\), deadline \(D_i\), blocking time \(B_i\), and response time \(R_i\).
U = \sum_{i=1}^{n} \frac{C_i}{T_i}
\]
Interpretation: Utilization estimates how much processor capacity is consumed by periodic work. A system can still fail with low utilization if blocking, interrupts, jitter, or priority assignment are poorly designed.
R_i = C_i + B_i + \sum_{j \in hp(i)} \left\lceil \frac{R_i}{T_j} \right\rceil C_j
\]
Interpretation: A fixed-priority response-time estimate includes the task’s own execution, blocking from lower-priority resource holders, and interference from higher-priority tasks. The task is schedulable when \(R_i \leq D_i\).
J_i = \max(t_{i,k+1} – t_{i,k}) – \min(t_{i,k+1} – t_{i,k})
\]
Interpretation: Jitter measures variation between activations or completions. In control and sampling systems, consistent timing can matter as much as low average latency.
S_{\mathrm{margin}} = D_i – R_i
\]
Interpretation: Slack margin measures how much timing reserve remains before a task misses its deadline. Small margins may be acceptable only when worst-case assumptions are well validated.
Q_{\mathrm{depth}}(t+1) = Q_{\mathrm{depth}}(t) + A(t) – S(t)
\]
Interpretation: Queue depth grows when arrivals \(A(t)\) exceed service \(S(t)\). A queue is not a cure for overload; it is a buffer that reveals whether the system can keep up.
These equations are intentionally practical. They help engineers ask whether the task set has enough CPU capacity, enough priority discipline, enough blocking control, enough queue headroom, and enough measured slack to remain dependable.
Python Workflow: Scheduling, Deadline, and Jitter Simulation
The companion Python workflow models RTOS behavior through tasks, periods, deadlines, priorities, execution-time ranges, blocking times, interrupt events, queue arrivals, and runtime traces. It can simulate fixed-priority scheduling, deadline checks, queue growth, overload scenarios, jitter, response-time margins, and priority-inversion scenarios.
The workflow is designed to answer practical engineering questions. Which tasks consume the most CPU time? Which deadlines have the smallest slack? Which tasks are vulnerable to blocking? What happens when interrupt load increases? Which queue is most likely to overflow? How sensitive is the system to radio bursts, sensor bursts, or logging spikes? Which priority assignment creates unnecessary inversion risk?
Useful outputs include a task manifest, utilization summary, deadline-risk report, simulated schedule trace, jitter distribution, queue-depth trajectory, priority-inversion scenario, stack-risk review, and plots of response-time margin by task. In a production setting, this workflow could support architecture review before firmware implementation and trace comparison after deployment.
The purpose is not to replace formal verification or hardware measurement. It is to make scheduling assumptions explicit enough that engineers can test, revise, and challenge them before field behavior becomes the first real timing test.
R Workflow: Runtime Trace and Fleet Timing Analysis
The companion R workflow treats RTOS behavior as an observability problem. It summarizes runtime traces, task activations, deadline misses, queue high-water marks, stack watermarks, ISR counts, context switches, idle residency, watchdog resets, and firmware versions across devices.
This matters because timing problems often appear only at fleet scale. One firmware version may create more context switches. One device class may show lower idle residency. One site may experience communication bursts that increase queue depth. One control task may miss deadlines only during storage writes. One board revision may show higher ISR counts because of a noisy wake line.
Useful R outputs include task-runtime distributions, jitter summaries, deadline-miss rates, queue-depth reports, stack-watermark rankings, ISR-load summaries, idle-residency comparisons, firmware-version risk tables, and maintenance-priority reports. These reports support firmware tuning, priority revision, stack resizing, queue resizing, power-policy changes, and rollback decisions.
A mature RTOS system is not only scheduled. It is observed across its operating life.
Systems Code: RTOS Task Contracts, Schedulers, Rust Validation, Go Telemetry, PYNQ, HDL, and Bash
The companion systems stack demonstrates how RTOS concepts appear across embedded and edge implementation layers.
The C example focuses on task contracts: priority, period, deadline, stack size, blocking budget, queue ownership, and watchdog progress criteria. The C++ example models a simplified fixed-priority scheduler and checks whether task activations meet deadlines under simulated load. The Rust example validates RTOS task manifests and ensures that required fields—task name, priority, period, deadline, stack size, criticality, blocking budget, and queue relationships—are present before deployment. The Go example sketches a runtime telemetry aggregator for deadline misses, queue high-water marks, stack watermarks, and ISR load.
MicroPython provides a prototype for cooperative task timing and queue-like event handling on constrained boards. TinyML can support local anomaly screening where runtime telemetry suggests timing degradation, but it should never replace explicit scheduling analysis and watchdog discipline. PYNQ support can demonstrate hardware-assisted timestamp capture, event counting, or interrupt tracing. HDL examples can model interrupt event counters, timer compare logic, deadline monitors, or queue-depth counters.
The Bash scripts tie the workflow together by validating manifests, running Python and R workflows, generating outputs, and checking repository structure. The goal is not to turn the article into a full RTOS implementation. The goal is to provide an engineering scaffold that mirrors real RTOS problems: scheduling, latency, jitter, synchronization, memory, power, and field evidence.
Technical Verification Gates
RTOS-based embedded designs should pass explicit verification gates before deployment and during operation. These gates prevent the system from being judged only by whether it appears responsive under nominal conditions.
| Gate | Verification Question | Evidence Required |
|---|---|---|
| Task-model gate | Does every task have a defined responsibility, priority, period or trigger, deadline, stack budget, and criticality? | Task manifest, priority table, stack budget |
| Schedulability gate | Can critical tasks meet deadlines under expected load and interference? | Utilization model, response-time estimate, scheduling simulation, trace data |
| Interrupt gate | Are ISR responsibilities bounded and deferred work properly structured? | Interrupt map, ISR-duration trace, deferred-work policy |
| Synchronization gate | Are blocking paths, priority inversion risks, and shared resources understood? | Resource graph, lock-order policy, blocking analysis |
| Memory gate | Are task stacks, queues, buffers, heap use, and kernel objects sized and monitored? | Stack watermark report, queue high-water marks, memory budget |
| Overload gate | Does the system degrade predictably under bursts, missed deadlines, queue pressure, or communication failures? | Overload test, queue overflow policy, stale-data policy, watchdog evidence |
| Power gate | Does RTOS timing cooperate with idle states, tickless behavior, device sleep, and wake sources? | Idle-residency trace, tickless test, wake-source log, power-state report |
| Field-evidence gate | Can deployed devices report deadline misses, queue depth, stack watermarks, ISR load, and reset causes? | Telemetry schema, trace counters, fleet report |
These gates reinforce the central principle: an RTOS architecture is not validated by multitasking alone. It is validated when task timing, blocking, interrupts, memory, power behavior, overload response, and field evidence are all testable.
Common Failure Modes
RTOS failures often look like random embedded instability: missed samples, occasional watchdog resets, unexplained latency spikes, buffer overruns, field-only lockups, high power draw, or intermittent communication loss. The underlying cause is often not the kernel itself, but poor timing architecture around the kernel.
Common failure modes include task proliferation without timing justification, priorities assigned by intuition, long-running ISRs, blocking calls inside high-priority tasks, mutexes around slow operations, priority inversion, undersized stacks, unbounded queues, excessive timers, dynamic allocation under long-lived load, and hidden dependency on lucky scheduling order.
Other failures include treating queue size as a substitute for throughput, assuming high priority guarantees deadline adherence, ignoring stack watermarks, failing to measure jitter, using the idle task as a dumping ground for background work, and letting low-priority logging or diagnostics interfere with real-time behavior. Power-related failures include RTOS timer wakeups that prevent sleep, polling tasks that destroy idle residency, and driver dependencies that block low-power entry.
A particularly important failure mode is false determinism. The system appears deterministic during ordinary tests because the workload is light, but misses deadlines under realistic interrupt, communication, sensor, storage, or fault-recovery pressure. Strong RTOS design tests the stressful paths, not only the easy schedule.
Applications in Embedded and Edge Systems
RTOSes appear across industrial control, robotics, automotive subsystems, connected medical devices, communications equipment, wearables, sensor hubs, energy systems, building systems, remote field devices, and intelligent infrastructure. They are especially valuable in systems that must integrate periodic work, asynchronous events, bounded response, power-aware idle behavior, and reliable timing without the overhead of a full general-purpose operating environment.
In edge systems, RTOSes also occupy an important middle layer. They can support local sensing, filtering, communications, and control beneath richer gateway or analytics platforms. This makes them crucial to distributed intelligence, where not all computation belongs in the cloud and not all devices can afford a larger operating system stack.
RTOSes also support environmental monitoring and infrastructure systems where devices need to balance periodic sensing, event-driven alerts, low-power sleep, communications, local storage, and fault diagnostics. In these systems, the RTOS is part of the device’s operational discipline: it determines when the device observes, when it communicates, when it sleeps, and how it responds to abnormal events.
The common thread is temporal coordination. Wherever embedded devices must do multiple things on time, with bounded latency and constrained resources, RTOS architecture becomes a serious design question.
Engineer Checklist
| Question | Why It Matters |
|---|---|
| Does every task have a defined responsibility, priority, period or trigger, deadline, and stack size? | Prevents task proliferation from becoming unstructured concurrency. |
| Are priorities assigned from timing consequence rather than convenience? | Ensures urgent work is prioritized for defensible reasons. |
| Are ISR responsibilities minimal and bounded? | Reduces interrupt latency, scheduling delay, and jitter. |
| Are blocking paths and priority inversion risks understood? | Prevents lower-priority work from silently delaying critical tasks. |
| Are task stacks, queues, and buffers sized from evidence? | Reduces stack overflow, queue overrun, memory exhaustion, and hidden overload. |
| Are deadlines and jitter measured under realistic load? | Prevents a lab-clean schedule from hiding field timing failures. |
| Does the RTOS timing model cooperate with low-power behavior? | Protects idle residency, tickless operation, wake control, and battery life. |
| Can field devices report timing evidence? | Supports maintenance, rollback, redesign, and reliability improvement. |
GitHub Repository
This article is supported by a companion workflow that treats RTOS design as a structured timing architecture: task manifests, priority tables, scheduling simulation, deadline analysis, jitter reporting, queue-depth modeling, stack and memory evidence, runtime trace analysis, SQL telemetry schemas, systems-code examples, tests, manifests, and runbooks.
Complete Code RepositoryThe companion repository includes Python, R, SQL, C, C++, Rust, Go, MicroPython, TinyML, PYNQ, HDL, Bash, YAML/JSON configuration, notebooks, tests, docs, data, outputs, and article-specific engineering workflows.
Where This Fits in the Series
This article follows Embedded Systems Architecture and Microcontrollers and System-on-Chip Design by focusing on how embedded software execution is structured once a device has meaningful concurrency and timing requirements.
It prepares the way for Firmware, Hardware Abstraction, and Device Control, Low-Power Embedded System Design, Reliability and Fault Tolerance in Embedded Devices, Environmental Sensor Networks, Cyber-Physical Systems and Hardware Integration, and Edge Computing Architectures.
Related articles
- Embedded Systems Architecture
- Microcontrollers and System-on-Chip Design
- Firmware, Hardware Abstraction, and Device Control
- Low-Power Embedded System Design
- Reliability and Fault Tolerance in Embedded Devices
- Environmental Sensor Networks
- Edge Computing Architectures
Further reading
- Arm (n.d.) CMSIS-RTOS2 Overview. Available at: https://arm-software.github.io/CMSIS_6/main/RTOS2/index.html.
- Burns, A. and Wellings, A.J. (2009) Real-Time Systems and Programming Languages. 4th edn. Harlow: Addison-Wesley.
- Buttazzo, G.C. (2011) Hard Real-Time Computing Systems: Predictable Scheduling Algorithms and Applications. 3rd edn. New York: Springer.
- FreeRTOS (n.d.) RTOS Fundamentals. Available at: https://www.freertos.org/Documentation/01-FreeRTOS-quick-start/01-Beginners-guide/01-RTOS-fundamentals.
- Lee, E.A. and Seshia, S.A. (2017) Introduction to Embedded Systems: A Cyber-Physical Systems Approach. 2nd edn. Cambridge, MA: MIT Press.
- Wollman, D.A., Weiss, M.A., Li-Baboud, Y., Griffor, E.R. and Burns, M.J. (2017) Framework for Cyber-Physical Systems: Volume 3, Timing Annex. Gaithersburg, MD: National Institute of Standards and Technology. Available at: https://doi.org/10.6028/NIST.SP.1500-203.
- Zephyr Project (n.d.) Scheduling. Available at: https://docs.zephyrproject.org/latest/kernel/services/scheduling/index.html.
- Zephyr Project (n.d.) Interrupts. Available at: https://docs.zephyrproject.org/latest/kernel/services/interrupts.html.
References
- Arm (n.d.) CMSIS-RTOS2 Overview. Available at: https://arm-software.github.io/CMSIS_6/main/RTOS2/index.html.
- Burns, A. and Wellings, A.J. (2009) Real-Time Systems and Programming Languages. 4th edn. Harlow: Addison-Wesley.
- Buttazzo, G.C. (2011) Hard Real-Time Computing Systems: Predictable Scheduling Algorithms and Applications. 3rd edn. New York: Springer.
- FreeRTOS (n.d.) Documentation Overview. Available at: https://www.freertos.org/Documentation/00-Overview.
- FreeRTOS (n.d.) RTOS Fundamentals. Available at: https://www.freertos.org/Documentation/01-FreeRTOS-quick-start/01-Beginners-guide/01-RTOS-fundamentals.
- Lee, E.A. and Seshia, S.A. (2017) Introduction to Embedded Systems: A Cyber-Physical Systems Approach. 2nd edn. Cambridge, MA: MIT Press.
- Wollman, D.A., Weiss, M.A., Li-Baboud, Y., Griffor, E.R. and Burns, M.J. (2017) Framework for Cyber-Physical Systems: Volume 3, Timing Annex. Special Publication (NIST SP) 1500-203. Gaithersburg, MD: National Institute of Standards and Technology. Available at: https://doi.org/10.6028/NIST.SP.1500-203.
- Zephyr Project (n.d.) Device Power Management. Available at: https://docs.zephyrproject.org/latest/services/pm/device.html.
- Zephyr Project (n.d.) Introduction. Available at: https://docs.zephyrproject.org/latest/introduction/index.html.
- Zephyr Project (n.d.) Interrupts. Available at: https://docs.zephyrproject.org/latest/kernel/services/interrupts.html.
- Zephyr Project (n.d.) Scheduling. Available at: https://docs.zephyrproject.org/latest/kernel/services/scheduling/index.html.