
Last Updated May 11, 2026
Model evaluation and performance metrics are the disciplines through which analysts determine whether a predictive system is actually good at the task it is meant to perform. A model is not validated merely because it can be trained, nor is it useful merely because it produces predictions. Its value depends on how well its outputs align with the decision problem, the error structure of the domain, the class balance of the data, the calibration of its probabilities, the stability of its performance over time, and the risks attached to wrong predictions. Evaluation is therefore not a decorative final step. It is one of the central places where analytical claims become operationally meaningful.
This topic matters because predictive systems often enter organizational life as scores, labels, rankings, forecasts, recommendations, alerts, thresholds, triage queues, or automated decisions. A model may appear strong under one metric and weak under another. It may rank cases well but produce misleading probabilities. It may perform well on average while failing on a rare class, a high-risk subgroup, a changing population, or a critical tail of the error distribution. Evaluation should therefore be treated as a substantive analytical discipline rather than a scoreboard. The question is not simply “which model scored highest?” It is “which model behavior is acceptable for this task, under this threshold, with this error cost, for these people, in this operating environment, over time?”
Main Library
Publications
Article Map
Data Systems & Analytics
Related Topic
Artificial Intelligence Systems
Related Topic
Institutions & Governance
Related Topic
Stewardship & Ethics
This article builds on the themes developed in Predictive Analytics and Machine Learning Models, Model Training and Validation, Statistical Modeling and Inference, Data Visualization and Analytical Communication, Reproducible Analytics and Versioned Data Workflows, Data Quality Metrics and Observability, and Data Governance and Stewardship. If training explains how a model is fit, and validation explains how modeling choices are selected and tested, evaluation explains whether the resulting predictive system is good enough for its intended use.
Evaluation as model-quality evidence
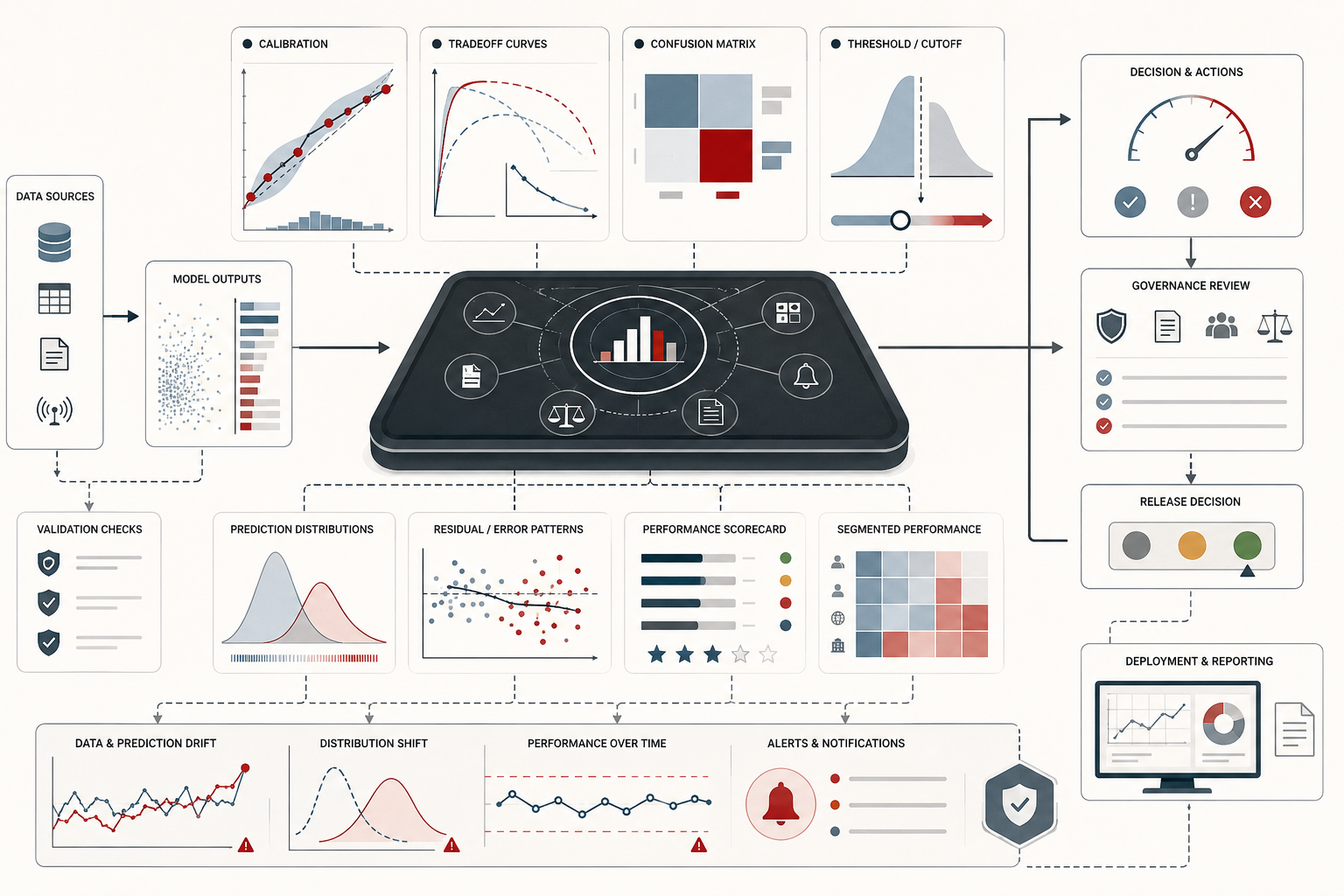
The strongest way to understand model evaluation is as model-quality evidence. Evaluation is not merely a table of scores attached to the end of a modeling workflow. It is the evidentiary system that connects the predictive task, data conditions, model outputs, decision thresholds, error costs, uncertainty, monitoring, and governance limits into an accountable judgment about model use.
This distinction matters because many organizations treat evaluation as a contest. Models are ranked by one metric, the highest score wins, and the chosen model moves toward deployment. That approach may be adequate for a narrow benchmark, but it is insufficient for real systems. A model can win on ROC-AUC and still be poorly calibrated. It can improve accuracy while worsening recall for the rare class. It can reduce mean error while increasing catastrophic tail error. It can perform well in validation and degrade after deployment. Evaluation must therefore ask what kind of evidence is needed to justify use.
Model-quality evidence is multidimensional. It includes discrimination, thresholded decision quality, probability quality, regression error, subgroup behavior, temporal stability, uncertainty, drift, monitoring, and risk limits. It also includes qualitative context: what the model is for, who is affected, what interventions follow, what errors cost, and which failures are unacceptable.
What model evaluation and performance metrics mean
Model evaluation is the process of assessing how well a predictive system performs on data, tasks, populations, and operating conditions that matter for its intended use. Performance metrics are quantitative summaries of that behavior. They may describe classification accuracy, precision, recall, ranking quality, probability calibration, regression error, tail behavior, subgroup error, monitoring drift, or other dimensions of predictive performance.
This means that evaluation is not one procedure. It is a family of measurement practices. A binary classifier, multiclass classifier, risk-ranking model, probability forecaster, demand forecast, anomaly detector, recommender, language model component, and regression model all require different evaluation logic. Even within one task family, metric choice changes the interpretation of performance. A classification score based on class labels does not answer the same question as a probability score. A threshold-free ranking metric does not answer the same question as a threshold-specific operational decision metric. A mean regression error does not answer the same question as a tail error measure.
A model may therefore succeed in one evaluative sense while failing in another. It may separate positives from negatives well but assign overconfident probabilities. It may minimize average error but fail on extreme cases. It may perform well overall but poorly on a subgroup that bears more risk. Metrics are not interchangeable labels for “goodness.” They are windows into different model behaviors.
Why evaluation matters
Evaluation matters because predictive systems are always embedded in contexts of use. A model that looks strong in development but behaves badly under the actual operational decision policy is not merely imperfect; it is misleading. Training tells us that a model can fit. Validation helps select modeling choices and estimate generalization. Evaluation asks what kind of mistakes the model makes, how those mistakes distribute, whether they are acceptable, and whether the model remains trustworthy over time.
This matters especially when predictions are used to allocate attention, resources, scrutiny, credit, benefits, opportunities, services, risk scores, interventions, or human review. A false positive may impose unnecessary burden. A false negative may miss a serious problem. A badly calibrated probability may distort resource allocation. A ranking model may prioritize the wrong cases. A regression forecast may understate demand in a critical tail. A model that drifts after deployment may continue to look authoritative because no one is watching the right metric.
Evaluation is therefore where predictive modeling becomes accountable. It turns “the model predicts” into “the model behaves this way, under this threshold, with this error profile, for this task, and here are the limits of trust.”
Metrics must match the task
The most important principle in model evaluation is that metrics must match the task. Before choosing a metric, the analyst must know what the model is meant to predict and how its output will be used. Is the model estimating a class label, class probability, rank ordering, mean, median, quantile, count, rate, anomaly score, or time-to-event risk? Is the output used for human review, automatic decisioning, screening, prioritization, forecasting, triage, monitoring, or planning?
Metric choice expresses an implicit theory of the model’s purpose. A classifier used for rare-event screening should not be judged mainly by overall accuracy. A model whose probabilities drive resource allocation needs calibration and probability scoring, not only AUC. A demand forecast used for inventory planning may need tail-error review, not only mean error. A ranking model may need average precision or lift at top-k because only the highest-ranked cases are actionable. A system used for thresholded review needs precision, recall, false-positive burden, false-negative risk, and threshold policy.
The wrong metric can make a weak model look strong. It can also make a useful model look weak if the metric does not match the decision problem. Evaluation therefore begins before scoring. It begins with task definition.
Proper scoring rules and honest probability
One of the most important expansions beyond everyday metric talk is the role of proper scoring rules. A scoring rule is proper when it rewards honest probabilistic prediction in expectation. In practical terms, if a model claims that an event has an 80 percent probability, the scoring rule should reward the model when those 80 percent predictions actually occur about 80 percent of the time and should penalize confident mistakes appropriately.
This is why Brier score and log loss matter. They evaluate probability quality rather than only thresholded class labels. Accuracy can ignore whether a model was barely or strongly confident. AUC can reward ranking while remaining indifferent to whether predicted probabilities are numerically trustworthy. Proper scoring rules ask a different question: are the predicted probabilities themselves meaningful?
This matters because many predictive systems do not merely rank cases. They allocate resources based on probability magnitudes, define expected value, trigger interventions, support risk communication, or feed downstream optimization. In those settings, a model that ranks well but is badly calibrated can still be operationally dangerous. Probability quality is a first-class evaluation concern, not a secondary technical detail.
Classification metrics and confusion logic
Classification metrics are often easiest to understand through the confusion matrix. For a binary classifier, predictions can be organized into true positives, false positives, true negatives, and false negatives. These four quantities are the foundation for many familiar metrics.
Accuracy measures the proportion of all cases classified correctly. Precision measures how often predicted positives are actually positive. Recall measures how many actual positives are found. Specificity measures how many actual negatives are correctly excluded. F1 score balances precision and recall through their harmonic mean. False-positive rate and false-negative rate expose the two major failure directions.
These metrics describe different error sensitivities. A high-precision model avoids false alarms but may miss many true cases. A high-recall model catches more true cases but may create more false positives. Accuracy may look strong when most cases belong to the majority class, even if the model performs poorly where it matters most. The confusion matrix is therefore not just a technical table. It is the logic of classification error made visible.
Thresholds, tradeoffs, and decision policy
Many predictive systems do not directly produce decisions. They produce scores or probabilities. A threshold then converts those scores into an action: classify as positive, route to human review, send outreach, escalate risk, trigger inspection, deny a transaction, or request additional information. The model and the threshold together determine operational behavior.
This is crucial. A classifier can appear strong under one threshold and unacceptable under another. Lowering the threshold usually increases recall but may reduce precision. Raising the threshold usually increases precision but may miss more true cases. The correct threshold is not purely a mathematical property of the model. It depends on error costs, intervention capacity, review burden, fairness concerns, risk tolerance, and institutional policy.
Thresholds should therefore be governed like decision rules. A threshold policy should document the positive class, intended action, false-positive cost, false-negative cost, review capacity, expected precision, expected recall, affected population, owner, approval status, and review cadence. Threshold tuning is not merely optimization. It is decision design.
ROC-AUC, PR curves, and ranking quality
Curve-based evaluation is valuable because it summarizes performance across many possible thresholds rather than fixing one operating point. ROC curves plot true positive rate against false positive rate across thresholds. ROC-AUC summarizes ranking quality: how often a randomly chosen positive receives a higher score than a randomly chosen negative. It is useful when rank ordering matters and when analysts want a threshold-independent view of discrimination.
Precision-recall curves offer a different view. They show how precision and recall trade off across thresholds. This is especially important when positive cases are rare or when the cost of false positives and false negatives is asymmetric. In rare-event settings, ROC-AUC may look acceptable even when precision at actionable thresholds is poor. Average precision and PR curves can therefore be more informative for screening, triage, fraud, failure detection, or high-risk review systems.
The deeper lesson is that threshold-free summaries are still contextual. AUC can tell us that the model ranks cases better than chance, but it does not tell us whether the chosen threshold is acceptable, whether probabilities are calibrated, whether the top-ranked cases are actionable, or whether performance is stable across subgroups and time. ROC-AUC is useful, but it is not a deployment decision by itself.
Calibration and probability quality
Discrimination is not the same as calibration. A model may rank cases well while assigning probabilities that are too high or too low. Calibration asks whether predicted probabilities correspond to observed frequencies. If a model assigns 0.8 probability to a group of cases, does the event occur about 80 percent of the time in comparable cases?
This distinction matters because probability estimates often shape decisions. A healthcare triage model, fraud review model, financial risk model, churn model, failure forecast, or intervention-allocation system may use probability magnitudes to allocate scarce attention. A poorly calibrated model can overstate risk, understate risk, distort expected value, or create unjustified confidence.
Calibration should be evaluated through calibration plots, Brier score, log loss, calibration gaps, expected calibration error, subgroup calibration, and temporal calibration drift where appropriate. A model that speaks in probabilities must be evaluated as a probability forecaster. Ranking quality alone is not enough.
Regression metrics and numeric error
Regression evaluation focuses on numeric error rather than thresholded class decisions. Mean absolute error measures typical absolute deviation. Mean squared error and root mean squared error penalize large errors more strongly. Bias measures average overprediction or underprediction. R² summarizes explained variance relative to a baseline, but can obscure practical error magnitude. Quantile or pinball losses evaluate distributional targets such as medians or upper quantiles.
Metric choice should match the target. If the model predicts a conditional mean, squared-error logic may be appropriate. If the model predicts a median-like target, absolute-error logic may be more appropriate. If the application cares about upper-tail demand, service capacity, extreme losses, or safety margins, quantile loss and tail-error measures may matter more than average error.
Good regression evaluation goes beyond one number. Analysts should inspect residuals, heteroskedasticity, subgroup error, temporal drift, tail error, large miss cases, and systematic bias. A model with acceptable average error can still fail if it consistently underpredicts demand for one region, overpredicts capacity during peak periods, or produces large errors in the cases where mistakes are most costly.
Class imbalance, rare events, and metric failure
Class imbalance is one of the clearest reasons evaluation cannot be reduced to accuracy. When positives are rare, a model can achieve high accuracy by predicting almost everything as negative while failing to find the cases that matter. A fraud detector, disease screener, failure predictor, safety monitor, or abuse detector may operate in a setting where the positive class is rare but operationally important.
In these settings, precision, recall, F1, average precision, PR curves, top-k precision, lift, calibration, and threshold policy often become more important than overall accuracy. Analysts should also distinguish between rare-event detection and rare-event action. A model may detect many true positives but produce too many false positives for available review capacity. Or it may generate few false alarms but miss too many serious cases.
Class imbalance also complicates comparison over time. If prevalence changes, some metrics may shift even when model quality does not. Monitoring should therefore track prevalence, score distributions, confusion-matrix elements, and thresholded operating behavior rather than rely only on one aggregate score.
Aggregation, weighting, and multiclass evaluation
Evaluation becomes more complex when there are multiple classes, multiple labels, heterogeneous cohorts, or groups with different error costs. Macro averaging treats classes more equally. Weighted averaging follows class frequency. Micro averaging aggregates individual decisions before computing the metric. Each approach answers a different question.
This is not merely a technical choice. Aggregation can hide weakness. A multiclass model may perform well on frequent classes and poorly on rare classes. A classifier may perform well overall while failing on a group that experiences higher consequences from error. A model may meet an enterprise average while violating local risk limits.
Evaluation should therefore include disaggregated review. Subgroup metrics, cohort metrics, temporal windows, error slices, and worst-case checks help prevent aggregate scores from becoming misleading summaries. The more consequential the model, the less acceptable it is to rely on averages alone.
Metric uncertainty and comparative restraint
Reported metrics are estimates. A difference between two models may not be meaningful if it is within the variability of validation samples, resampling folds, time windows, or subgroup composition. Cross-validation dispersion, confidence intervals, bootstrap estimates, repeated resampling, temporal validation, and cohort-based comparisons can all help analysts understand whether differences are stable enough to matter.
Comparative restraint is essential. A model that wins by a tiny margin on one metric may be worse on calibration, subgroup error, interpretability, deployment cost, or monitoring stability. It may also be less robust under drift. Evaluation should avoid overreading leaderboard differences that do not change operational decisions.
This is especially important in organizational contexts where small metric gains can be used to justify deployment. A rigorous evaluation report should distinguish statistical difference, practical significance, operational acceptability, and governance approval. These are related but not identical.
A mathematical lens for model evaluation
Model evaluation is inherently mathematical, but the mathematics should be connected to decision meaning. The confusion matrix is the simplest place to begin:
\begin{array}{c|cc}
& \hat{y}=1 & \hat{y}=0 \\
\hline
y=1 & TP & FN \\
y=0 & FP & TN
\end{array}
\]
Interpretation: Classification evaluation begins by separating true positives, false positives, true negatives, and false negatives. Each metric emphasizes a different part of this table.
Precision, recall, and F1 score can be expressed as:
Precision = \frac{TP}{TP + FP}, \quad
Recall = \frac{TP}{TP + FN}, \quad
F_1 = \frac{2 \cdot Precision \cdot Recall}{Precision + Recall}
\]
Interpretation: Precision asks whether positive predictions are credible. Recall asks whether actual positives are found. F1 balances the two when both matter, especially under imbalance.
Expected threshold cost can be represented as:
C(t) = c_{FP}FP(t) + c_{FN}FN(t)
\]
Interpretation: Threshold \(t\) should be evaluated as a decision policy. The expected cost depends on how many false positives and false negatives it creates and how costly those errors are in the domain.
Probability quality can be measured with Brier score and log loss:
Brier = \frac{1}{n}\sum_{i=1}^{n}(p_i – y_i)^2
\]
Interpretation: The Brier score measures squared error between predicted probability \(p_i\) and observed outcome \(y_i\). Lower values indicate better probability forecasts.
LogLoss = -\frac{1}{n}\sum_{i=1}^{n}\left[y_i\log(p_i) + (1-y_i)\log(1-p_i)\right]
\]
Interpretation: Log loss penalizes confident wrong probabilities strongly. It is useful when probability quality matters, not only class labels.
Calibration can be expressed by comparing predicted and observed rates within score bins:
CalGap_b = \left|\frac{1}{n_b}\sum_{i \in b}p_i – \frac{1}{n_b}\sum_{i \in b}y_i\right|
\]
Interpretation: Calibration gap compares average predicted probability with observed event rate inside bin \(b\). A calibrated model should have small gaps across bins.
Regression error can be summarized as:
MAE = \frac{1}{n}\sum_{i=1}^{n}|y_i – \hat{y}_i|, \quad
RMSE = \sqrt{\frac{1}{n}\sum_{i=1}^{n}(y_i – \hat{y}_i)^2}
\]
Interpretation: MAE describes typical absolute error. RMSE penalizes large errors more heavily. The right choice depends on whether large misses are especially costly.
A governance-oriented evaluation scorecard can be represented as:
E_m = w_DD_m + w_TT_m + w_PP_m + w_CC_m + w_RR_m + w_SS_m + w_MM_m
\]
Interpretation: Evaluation maturity \(E_m\) for model \(m\) can combine discrimination \(D_m\), threshold policy \(T_m\), probability quality \(P_m\), calibration \(C_m\), regression or ranking error \(R_m\), subgroup stability \(S_m\), and monitoring readiness \(M_m\).
The point of these equations is not to create a false sense of certainty. It is to make evaluation assumptions explicit. Metrics should reveal what the model is being rewarded for and what errors the organization is willing to tolerate.
Python Workflow: Model Evaluation Scorecard
The following Python workflow demonstrates how model evaluation can combine classification metrics, threshold policies, calibration bins, subgroup metrics, regression error, scorecard limits, and monitoring flags. The full GitHub companion repository includes a more complete runnable version with manifests and CSV outputs.
#!/usr/bin/env python3
"""
Python Workflow: Model Evaluation Scorecard
This compact example evaluates model behavior across classification,
threshold, calibration, subgroup, regression, and monitoring dimensions.
"""
from __future__ import annotations
import math
from dataclasses import dataclass
@dataclass
class Confusion:
tp: int
fp: int
tn: int
fn: int
def safe_div(num: float, den: float) -> float:
return num / den if den else 0.0
def confusion_at_threshold(y_true: list[int], scores: list[float], threshold: float) -> Confusion:
y_pred = [1 if score >= threshold else 0 for score in scores]
return Confusion(
tp=sum(1 for y, p in zip(y_true, y_pred) if y == 1 and p == 1),
fp=sum(1 for y, p in zip(y_true, y_pred) if y == 0 and p == 1),
tn=sum(1 for y, p in zip(y_true, y_pred) if y == 0 and p == 0),
fn=sum(1 for y, p in zip(y_true, y_pred) if y == 1 and p == 0),
)
def classification_metrics(conf: Confusion) -> dict[str, float]:
precision = safe_div(conf.tp, conf.tp + conf.fp)
recall = safe_div(conf.tp, conf.tp + conf.fn)
accuracy = safe_div(conf.tp + conf.tn, conf.tp + conf.fp + conf.tn + conf.fn)
f1 = safe_div(2 * precision * recall, precision + recall)
return {
"accuracy": accuracy,
"precision": precision,
"recall": recall,
"f1": f1,
"false_positive_rate": safe_div(conf.fp, conf.fp + conf.tn),
"false_negative_rate": safe_div(conf.fn, conf.fn + conf.tp),
}
def brier_score(y_true: list[int], scores: list[float]) -> float:
return sum((score - y) ** 2 for y, score in zip(y_true, scores)) / len(y_true)
def log_loss(y_true: list[int], scores: list[float], eps: float = 1e-15) -> float:
clipped = [min(max(score, eps), 1 - eps) for score in scores]
return -sum(
y * math.log(score) + (1 - y) * math.log(1 - score)
for y, score in zip(y_true, clipped)
) / len(y_true)
def regression_metrics(y_true: list[float], y_pred: list[float]) -> dict[str, float]:
errors = [pred - actual for actual, pred in zip(y_true, y_pred)]
abs_errors = [abs(error) for error in errors]
sq_errors = [error ** 2 for error in errors]
return {
"mae": sum(abs_errors) / len(abs_errors),
"rmse": math.sqrt(sum(sq_errors) / len(sq_errors)),
"bias": sum(errors) / len(errors),
"max_absolute_error": max(abs_errors),
}
def main() -> None:
y_true = [1, 1, 0, 0, 1, 0, 1, 0]
scores = [0.91, 0.83, 0.72, 0.40, 0.67, 0.62, 0.58, 0.30]
for threshold in [0.50, 0.70]:
conf = confusion_at_threshold(y_true, scores, threshold)
metrics = classification_metrics(conf)
expected_cost = 1.0 * conf.fp + 2.0 * conf.fn
print({
"threshold": threshold,
"confusion": conf,
"metrics": {k: round(v, 3) for k, v in metrics.items()},
"expected_error_cost": expected_cost,
})
print({
"brier_score": round(brier_score(y_true, scores), 3),
"log_loss": round(log_loss(y_true, scores), 3),
})
demand_actual = [120, 132, 141, 90, 95, 110]
demand_predicted = [118, 129, 150, 84, 100, 102]
print({
"regression": {
k: round(v, 3)
for k, v in regression_metrics(demand_actual, demand_predicted).items()
}
})
if __name__ == "__main__":
main()
This workflow shows why model evaluation should not collapse into a single metric. Thresholded classification metrics, probability scores, error costs, and regression metrics each answer different questions. A serious evaluation record should preserve all of the dimensions that matter for use.
R Workflow: Threshold, Calibration, Classification, and Regression Summary
The following R workflow summarizes classification behavior at thresholds, probability calibration, regression error, monitoring drift, and metric scorecard status. It supports a recurring model-review process: which thresholds change behavior, which probabilities are calibrated, which regression errors are acceptable, which monitoring windows need escalation, and which scorecard items remain outside limits?
#!/usr/bin/env Rscript
# R Workflow: Threshold, Calibration, Classification, and Regression Summary
binary <- data.frame(
model_id = c(
"model_churn_v1", "model_churn_v1", "model_churn_v1", "model_churn_v1",
"model_churn_v1", "model_churn_v1", "model_churn_v1", "model_churn_v1"
),
subgroup = c("A", "A", "A", "A", "B", "B", "B", "B"),
y_true = c(1, 1, 0, 0, 1, 0, 1, 0),
y_score = c(0.91, 0.83, 0.72, 0.40, 0.67, 0.62, 0.58, 0.30),
stringsAsFactors = FALSE
)
thresholds <- data.frame(
model_id = c("model_churn_v1", "model_churn_v1"),
threshold = c(0.50, 0.70),
policy_name = c("balanced_retention_outreach", "high_confidence_retention_outreach"),
false_positive_cost = c(1.0, 1.0),
false_negative_cost = c(2.0, 2.0),
stringsAsFactors = FALSE
)
regression <- data.frame(
model_id = rep("model_demand_v1", 6),
y_true = c(120, 132, 141, 90, 95, 110),
y_pred = c(118, 129, 150, 84, 100, 102)
)
safe_div <- function(num, den) {
ifelse(den == 0, 0, num / den)
}
confusion_metrics <- function(y_true, y_score, threshold) {
pred <- ifelse(y_score >= threshold, 1, 0)
tp <- sum(y_true == 1 & pred == 1)
fp <- sum(y_true == 0 & pred == 1)
tn <- sum(y_true == 0 & pred == 0)
fn <- sum(y_true == 1 & pred == 0)
precision <- safe_div(tp, tp + fp)
recall <- safe_div(tp, tp + fn)
accuracy <- safe_div(tp + tn, tp + tn + fp + fn)
f1 <- safe_div(2 * precision * recall, precision + recall)
data.frame(
threshold = threshold,
tp = tp,
fp = fp,
tn = tn,
fn = fn,
accuracy = accuracy,
precision = precision,
recall = recall,
f1 = f1
)
}
threshold_rows <- list()
for (i in seq_len(nrow(thresholds))) {
threshold_rows[[i]] <- cbind(
policy_name = thresholds$policy_name[i],
confusion_metrics(
binary$y_true,
binary$y_score,
thresholds$threshold[i]
)
)
}
threshold_summary <- do.call(rbind, threshold_rows)
calibration_summary <- aggregate(
cbind(y_true, y_score) ~ model_id,
data = binary,
FUN = mean
)
names(calibration_summary) <- c(
"model_id",
"observed_positive_rate",
"mean_predicted_score"
)
calibration_summary$calibration_gap <- abs(
calibration_summary$observed_positive_rate -
calibration_summary$mean_predicted_score
)
regression$absolute_error <- abs(regression$y_pred - regression$y_true)
regression$squared_error <- (regression$y_pred - regression$y_true)^2
regression_summary <- aggregate(
cbind(absolute_error, squared_error) ~ model_id,
data = regression,
FUN = mean
)
names(regression_summary) <- c("model_id", "mae", "mse")
regression_summary$rmse <- sqrt(regression_summary$mse)
dir.create("outputs", showWarnings = FALSE, recursive = TRUE)
write.csv(threshold_summary, "outputs/threshold_summary_r.csv", row.names = FALSE)
write.csv(calibration_summary, "outputs/calibration_summary_r.csv", row.names = FALSE)
write.csv(regression_summary, "outputs/regression_summary_r.csv", row.names = FALSE)
cat("Wrote threshold, calibration, and regression evaluation summaries.\n")
This workflow emphasizes a practical point: evaluation evidence should be structured so that reviewers can compare thresholds, inspect calibration, and evaluate error behavior without treating one metric as the whole truth.
Scorecards, model comparison, and risk limits
Because no single metric is sufficient for many real tasks, model comparison often requires a scorecard rather than a winner-take-all ranking. A useful scorecard might include ranking quality, thresholded precision and recall, calibration, Brier score, log loss, subgroup performance, tail error, monitoring stability, and governance status. The purpose is not to make evaluation more complicated for its own sake. It is to prevent one strong metric from hiding another unacceptable weakness.
A scorecard also makes risk limits explicit. For example, a fraud review model might require recall above a minimum threshold, precision above a review-capacity threshold, calibration within an acceptable range, and no severe subgroup degradation. A demand forecast might require MAE below one limit, tail error below another, and no systematic regional bias. A model used in a high-impact context might require both technical performance and governance review before deployment.
This changes model comparison from “which model won?” to “which model meets the use-case requirements?” That is a more mature and more accountable question.
Monitoring, drift, and ongoing re-evaluation
Evaluation does not end at launch. A model that performed well on historical test data may degrade when the data distribution shifts, labels change, user behavior changes, economic conditions change, instrumentation changes, or the model itself affects the environment it predicts. Monitoring is therefore part of evaluation, not a separate operational afterthought.
Ongoing re-evaluation should track prediction distributions, input drift, label drift, performance drift, calibration drift, subgroup error, threshold suitability, alert volume, false-positive burden, false-negative risk, and stability across time windows. The monitoring metrics should connect to risk limits and escalation rules. If recall falls below an acceptable threshold, if calibration gaps widen, if drift exceeds tolerance, or if subgroup performance deteriorates, the model should trigger review.
This lifecycle perspective is especially important for AI and machine-learning systems because the world does not remain fixed after validation. A model evaluation report is a snapshot. Monitoring asks whether the snapshot still describes present reality.
Governance and institutional accountability
Model evaluation becomes meaningful at organizational scale only when it connects to governance. Metrics should not be isolated notebook outputs. They should connect to owners, stewards, intended use, thresholds, acceptable limits, review status, monitoring windows, deployment gates, and escalation paths. A model that fails a risk limit should not continue to operate simply because no one owns the evaluation result.
Governance also matters because models affect people and institutions differently. A model used for marketing prioritization, inventory planning, fraud review, medical screening, employment screening, credit assessment, public-service triage, or resource allocation carries different risk. Evaluation standards should be proportionate to consequence. High-impact models require stronger documentation, calibration review, subgroup analysis, monitoring, and governance oversight than low-stakes exploratory models.
This does not mean governance should block useful modeling. It means model quality should be connected to accountable decision-making. A performance metric becomes truly meaningful when someone has authority and responsibility to act on it.
Applications across domains
Model evaluation matters across every domain where predictions influence action. In finance, evaluation shapes credit risk, fraud detection, market forecasting, stress testing, and review queues. In healthcare, it affects screening sensitivity, false-alarm burden, triage, resource allocation, and model calibration for risk communication. In operations, it determines whether forecasts, anomaly detectors, and scheduling models can be trusted. In marketing and customer analytics, it affects churn prioritization, propensity scoring, campaign allocation, and personalization. In public systems, it shapes the acceptability of triage, inspection, audit, eligibility support, and prioritization tools.
Across all these domains, the same core questions recur. What does the model output mean? Which metric matches the task? Which threshold converts prediction into action? What kind of error matters most? Is performance stable across groups and time? Are probabilities calibrated? Are limits defined? Who owns monitoring? What happens when performance degrades?
The more consequential the domain, the more evaluation must move beyond leaderboard performance toward accountable model-quality evidence.
Failure modes in model evaluation
Model evaluation fails in recognizable ways. One failure mode is metric opportunism: selecting the metric that makes the model look best rather than the one that matches the task. Another is accuracy fixation, especially in imbalanced classification settings where accuracy hides rare-class failure. A third is AUC overreach, where a ranking metric is treated as proof that a model is ready for a specific thresholded decision.
A fourth failure mode is calibration neglect. A model may produce probabilities that appear precise but do not match observed frequencies. A fifth is threshold invisibility, where decisions are made from scores without documented threshold policy. A sixth is aggregate masking, where average performance hides subgroup error, class imbalance, temporal instability, or tail risk. A seventh is validation overconfidence, where small metric differences are treated as decisive without uncertainty or robustness checks. An eighth is monitoring absence, where deployed models continue operating long after conditions change.
These failures are not merely technical. They are governance failures because they allow predictive systems to be treated as reliable without sufficient evidence.
Implementation principles for high-integrity evaluation
Start with the use case. Define the intended decision, action, or analytical use before choosing metrics.
Name the prediction target. Distinguish class labels, probabilities, ranks, means, medians, quantiles, and scores.
Match metrics to task. Use threshold metrics for thresholded decisions, ranking metrics for ranking tasks, calibration metrics for probabilities, and appropriate loss functions for regression targets.
Evaluate thresholds as policy. Document the threshold, error costs, review capacity, owner, approval status, and expected operating behavior.
Separate discrimination from calibration. A model can rank cases well while assigning misleading probabilities.
Inspect class imbalance and rare events. Do not rely on accuracy when the important class is rare.
Disaggregate performance. Review cohorts, subgroups, time windows, and operational contexts.
Show metric uncertainty. Use cross-validation dispersion, resampling, confidence intervals, or temporal validation when comparison is close.
Monitor after deployment. Track drift, performance, calibration, threshold suitability, and subgroup behavior over time.
Connect evaluation to governance. Define acceptable limits, escalation paths, owners, and model lifecycle actions.
| Control | Purpose | Failure it prevents |
|---|---|---|
| Task-metric alignment | Ensures metrics match prediction target and use case | Metric opportunism and misleading model comparison |
| Confusion-matrix review | Exposes true positives, false positives, true negatives, and false negatives | Accuracy hiding harmful error patterns |
| Threshold policy | Connects scores to action through explicit decision rules | Undocumented conversion of prediction into decision |
| Calibration review | Checks whether predicted probabilities match observed frequencies | Misleading probability magnitudes and overconfident risk scores |
| Regression error distribution | Reviews typical error, bias, and tail misses | Average performance hiding large or systematic errors |
| Subgroup and cohort evaluation | Tests performance across classes, groups, segments, and time windows | Aggregate masking and uneven model behavior |
| Metric uncertainty review | Distinguishes stable improvement from validation noise | Overreading small benchmark differences |
| Monitoring and drift limits | Tracks model behavior after deployment | Static validation being treated as permanent trust |
| Governance scorecard | Links metrics to owners, limits, review status, and escalation | Evaluation results with no accountable action path |
GitHub Repository
This article can be paired with a companion code workflow that models evaluation as model-quality evidence infrastructure. The example includes model registries, binary predictions, regression predictions, threshold policies, metric scorecards, monitoring windows, calibration bins, subgroup metrics, SQL schemas, scorecard scripts, typed contracts, Quarto report templates, evaluation checklists, and multi-language examples across Python, R, Julia, SQL, Go, Rust, C, C++, TypeScript, and Terraform placeholders.
The companion repository provides a vendor-neutral model evaluation and performance metrics scaffold with classification metrics, threshold-policy analysis, calibration review, regression-error summaries, subgroup checks, monitoring flags, SQL evaluation queries, reproducible reporting templates, typed contracts, documentation, and CI smoke-test patterns.
Conclusion
Model evaluation and performance metrics are central to trustworthy analytics because predictive systems are only useful when their behavior is understood in relation to the task they are meant to support. A model is not good in the abstract. It is good for a purpose, under a metric, at a threshold, within an error tolerance, across relevant groups, and over time.
The deeper point is that evaluation turns prediction into accountable evidence. Accuracy, precision, recall, ROC-AUC, average precision, calibration, Brier score, log loss, MAE, RMSE, subgroup metrics, and drift indicators each reveal different parts of model behavior. None is universally sufficient. High-integrity evaluation makes these dimensions explicit, connects them to decision policy and governance limits, and continues measuring after deployment. In data-intensive organizations, that is not merely a machine-learning skill. It is a condition of responsible predictive practice.
Related articles
- Data Systems and Analytics knowledge series
- Predictive Analytics and Machine Learning Models
- Model Training and Validation
- Statistical Modeling and Inference
- Data Visualization and Analytical Communication
- Reproducible Analytics and Versioned Data Workflows
- Data Quality Metrics and Observability
- Data Governance and Stewardship
Further reading
- Fawcett, T. (2006) ‘An introduction to ROC analysis’, Pattern Recognition Letters, 27(8), pp. 861–874.
- Flach, P. (2019) ‘Performance evaluation in machine learning: The good, the bad, the ugly, and the way forward’, Proceedings of the AAAI Conference on Artificial Intelligence, 33(01), pp. 9808–9814.
- Gneiting, T. and Raftery, A.E. (2007) ‘Strictly proper scoring rules, prediction, and estimation’, Journal of the American Statistical Association, 102(477), pp. 359–378.
- Hastie, T., Tibshirani, R. and Friedman, J. (2009) The Elements of Statistical Learning. 2nd edn. New York: Springer.
- James, G., Witten, D., Hastie, T. and Tibshirani, R. (2021) An Introduction to Statistical Learning. 2nd edn. New York: Springer.
- Molnar, C. (2022) Interpretable Machine Learning. 2nd edn. Available at: https://christophm.github.io/interpretable-ml-book/
- NIST (2023) Artificial Intelligence Risk Management Framework (AI RMF 1.0). Gaithersburg, MD: National Institute of Standards and Technology.
References
- scikit-learn developers (n.d.) Metrics and scoring: quantifying the quality of predictions. Available at: https://scikit-learn.org/stable/modules/model_evaluation.html
- scikit-learn developers (n.d.) Probability calibration. Available at: https://scikit-learn.org/stable/modules/calibration.html
- scikit-learn developers (n.d.) roc_auc_score. Available at: https://scikit-learn.org/stable/modules/generated/sklearn.metrics.roc_auc_score.html
- scikit-learn developers (n.d.) Precision-Recall. Available at: https://scikit-learn.org/stable/auto_examples/model_selection/plot_precision_recall.html
- Google for Developers (2026) Classification: Accuracy, recall, precision, and related metrics. Available at: https://developers.google.com/machine-learning/crash-course/classification/accuracy-precision-recall
- Google for Developers (2026) Classification: ROC and AUC. Available at: https://developers.google.com/machine-learning/crash-course/classification/roc-and-auc
- NIST (2023) Artificial Intelligence Risk Management Framework (AI RMF 1.0). Available at: https://nvlpubs.nist.gov/nistpubs/ai/nist.ai.100-1.pdf
- NIST (n.d.) AI RMF Playbook. Available at: https://www.nist.gov/itl/ai-risk-management-framework/nist-ai-rmf-playbook
- Fawcett, T. (2006) ‘An introduction to ROC analysis’, Pattern Recognition Letters, 27(8), pp. 861–874.
- Gneiting, T. and Raftery, A.E. (2007) ‘Strictly proper scoring rules, prediction, and estimation’, Journal of the American Statistical Association, 102(477), pp. 359–378.
- Hastie, T., Tibshirani, R. and Friedman, J. (2009) The Elements of Statistical Learning. 2nd edn. New York: Springer.
- James, G., Witten, D., Hastie, T. and Tibshirani, R. (2021) < ::contentReference[oaicite:2]{index=2} em>An Introduction to Statistical Learning. 2nd edn. New York: Springer.