
Last Updated May 11, 2026
Relational databases and SQL systems remain one of the central institutional architectures for structured data management. Although contemporary data environments now include document stores, graph systems, time-series databases, vector search infrastructure, object storage, lakehouse tables, and distributed analytical engines, the relational model continues to define the conceptual and operational baseline for how structured information is represented, constrained, queried, shared, and governed. Its durability rests on a powerful combination of formal simplicity and practical utility: entities and events can be modeled as relations, dependencies can be disciplined through schema design, integrity can be enforced through keys and constraints, and data can be queried through a declarative language that separates logical intent from low-level storage execution.
Relational systems matter not because they solve every data problem equally well, but because they solve a wide range of high-value problems exceptionally well. They are especially powerful where data must remain durable, interpretable, auditable, constrained, and shareable across many users, applications, workflows, reports, and institutional contexts. Finance, logistics, healthcare, public administration, science, enterprise operations, education, infrastructure management, and large portions of digital commerce still depend on relational databases because these systems provide a disciplined way to preserve structured state under concurrent use.
Main Library
Publications
Article Map
Data Systems & Analytics
Related Topic
Database Architecture
Related Topic
Warehouses & Lakes
Related Topic
Governance & Security
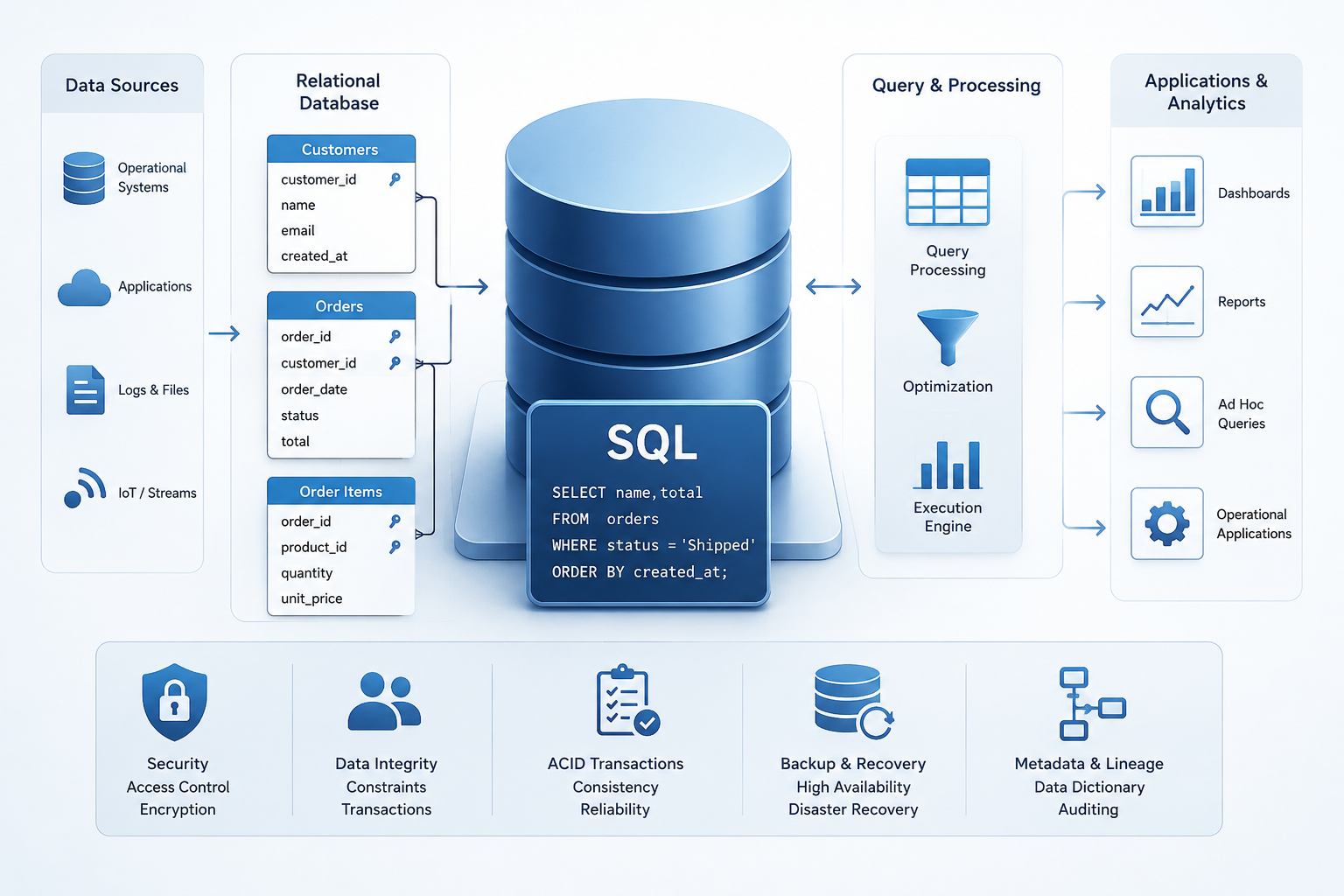
SQL gives relational systems their practical institutional language. It is not merely a syntax for selecting rows from tables. It is a broader language family for defining schemas, declaring data types and constraints, expressing joins and aggregations, controlling permissions, managing transactions, and operating on structured data in a portable declarative form. The SQL standard continues to be maintained through the ISO/IEC 9075 series, while mature implementations such as PostgreSQL provide current, living examples of how the language functions in real systems.
This article should be read alongside Data Systems & Analytics, Database Systems and Data Architecture, Data Warehouses and Data Lakes, Data Pipelines and Data Processing Systems, ETL and Data Transformation Systems, Data Cleaning and Data Quality Management, Data Quality Metrics and Observability, Metadata, Data Catalogs, and Lineage, and Reproducible Analytics and Versioned Data Workflows. Relational systems are not isolated from modern data architecture; they remain one of its most durable foundations.
Relational discipline as institutional structure
The strongest way to understand relational databases is as disciplined institutional structure. A relational system does not merely store data in tables. It defines what kinds of entities, events, relationships, and state changes are permitted inside a shared information environment. Tables define the kinds of things the institution recognizes. Primary keys define identity. Foreign keys define governed relationships. Constraints define valid states. Transactions define controlled change. SQL defines a shared declarative language through which people and systems can inspect, update, and summarize structured state.
This matters because institutions depend on shared facts. A customer, patient, order, shipment, invoice, course, facility, permit, sensor, observation, transaction, or case record is not just an isolated row. It is part of a web of meaning and dependency. A customer may place orders. An order may contain lines. Lines may reference products. Payments may reference orders. Shipments may fulfill orders. Reports may aggregate those relationships. Applications may enforce workflows around them. Auditors may later inspect them.
Relational systems remain powerful because they make those dependencies explicit. They turn structured data management into a governed architecture of identity, dependency, constraint, retrieval, and change. That is why relational databases continue to matter even in environments that also use lakes, warehouses, streaming systems, graph stores, document stores, and machine-learning infrastructure.
What relational databases and SQL systems mean
A relational database is a database system organized around relations, which are typically represented in practice as tables composed of rows and columns. Each relation models a set of entities, events, or associations within a domain. Columns represent attributes, while rows represent instances, records, or tuples. What makes the model powerful is not simply its tabular appearance, but the formal discipline through which relations can be linked, constrained, queried, and updated without tying users directly to physical storage paths.
A SQL system is a relational database implementation that uses Structured Query Language as its primary interface for defining schemas, manipulating records, retrieving data, and managing database operations such as permissions, transactions, and administrative commands. In practical environments, SQL functions as the common working language through which relational systems become usable by analysts, developers, administrators, reporting tools, applications, and automated workflows.
The relationship between the two is important. The relational model provides the conceptual foundation. SQL provides the dominant operational language through which that foundation is implemented. The model and the language are not identical. SQL systems include historical compromises, vendor extensions, procedural additions, optimizer behavior, physical storage choices, and performance features. But together they form the most influential architecture in the history of structured data management.
Why the relational model endures
The relational model endures because it solved a foundational problem in shared data systems: how to represent structured information in a way that preserves logical clarity while supporting flexible retrieval and controlled change. Codd’s 1970 paper argued that large shared data banks should be organized through relations rather than navigational access paths tightly coupled to physical storage. That move elevated abstraction, data independence, and declarative access to the center of database design.
The model’s durability also reflects the kinds of problems institutions most often face. Many organizational domains involve entities with persistent identity, interpretable attributes, governed relationships, and strong needs for consistency. Customers place orders. Patients have encounters. Invoices belong to accounts. Shipments move between facilities. Students enroll in courses. Permits belong to agencies and jurisdictions. Observations are tied to time and place. These are domains in which identity, dependency, and valid state transitions matter.
Relational databases remain valuable because they make those features explicit. They require schema, keys, types, relationships, and constraints. That discipline can feel rigid compared with more flexible data stores, but it is often precisely what makes large systems governable over time. Structure is not merely a limitation. It is a form of accountability.
Relations, tuples, attributes, and keys
At the heart of the relational model lies a deceptively simple set of concepts. A relation represents a set of tuples sharing a common structure. In practical systems, this is usually realized as a table. A tuple corresponds to a row or record. An attribute corresponds to a column or field. These practical analogies are useful, but they should not obscure the deeper point: the relational model is grounded in formal representation, not merely spreadsheet-like display.
Keys are central because they establish identity and relational linkage. A primary key uniquely identifies each tuple within a relation. A foreign key references the primary key of another relation, thereby expressing a governed relationship between tables. Together, these structures allow the database to model one-to-one, one-to-many, and many-to-many relationships in controlled ways.
Without keys, relational systems quickly degrade into loosely structured tables that resemble files rather than coherent databases. Keys make joins meaningful, constraints enforceable, and duplication diagnosable. They are not just technical devices for retrieval. They are architectural commitments about what counts as identity in the domain being modeled.
| Concept | Technical meaning | Institutional function |
|---|---|---|
| Relation / table | A structured set of tuples sharing attributes | Defines a recognized entity, event, or association type |
| Tuple / row | One instance in a relation | Asserts that a particular entity, event, or relationship exists |
| Attribute / column | A named property with a type or domain | Defines what qualities the institution records and governs |
| Primary key | A unique identifier for each tuple | Defines identity and prevents duplicate institutional state |
| Foreign key | A governed reference to another relation | Defines accountable relationships across tables |
| Constraint | A rule that limits valid database states | Embeds institutional rules inside the data system |
The relational model as logical discipline
The relational model is often introduced through tables, but its real importance lies in the logical discipline beneath the tables. Codd’s work grounded database management in relation theory and predicate logic, giving data design a more formal basis than earlier navigational systems. The value of that move was not academic elegance alone. It made it possible to reason more clearly about dependencies, redundancy, constraints, and data independence.
A relational database is not just a collection of records. It is a representation of structured propositions about the world. A row in a table asserts that a certain entity or event exists with certain properties. A foreign key asserts that one record depends on another recognized record. A constraint asserts that only some states are valid. A query asks for a logical result set derived from these structured assertions.
Seen in this light, relational databases are not merely storage technologies. They are structured systems of representation. Their discipline helps organizations distinguish durable information design from ad hoc record accumulation. This is why relational systems remain so important to governance, auditing, analytics, and transactional applications: they provide a shared logic for what the institution claims to know.
What SQL actually is
SQL is often described simply as a language for querying databases, but that description is incomplete. SQL is a broader language family for defining structure, manipulating data, expressing relational logic, controlling access, and participating in transaction-oriented system management. The ISO/IEC 9075 series specifies the formal SQL standard, while individual database systems implement the language with varying degrees of compatibility and extension.
The power of SQL lies in its declarative nature. In SQL, users specify what data they want or what structural outcome they intend, rather than describing step by step how the machine should traverse storage to achieve it. The query planner and optimizer are responsible for determining an efficient execution path. This separation between logical intent and physical execution is one of SQL’s greatest achievements.
In practice, SQL is both standardized and plural. PostgreSQL, SQL Server, Oracle, MySQL, SQLite, DuckDB, and cloud data warehouses all expose SQL, but each implements extensions, data types, functions, administrative commands, optimizers, and performance behavior differently. This combination of shared foundation and implementation diversity is one reason SQL remains portable enough to be broadly useful while flexible enough to evolve in real systems.
DDL, DML, queries, and administrative control
One reason SQL remains central is that it spans multiple categories of database work rather than serving a single narrow function.
Data Definition Language, or DDL, includes statements used to define and alter schema structure: creating tables, defining columns and types, establishing constraints, creating indexes, and modifying database objects. This is where structure becomes formal.
Data Manipulation Language, or DML, includes inserting, updating, and deleting records. This is where database state changes over time through controlled operations.
Query operations retrieve, filter, sort, group, join, and aggregate data. This is the part of SQL most familiar to analysts, but it depends on the stability and logic created by the other parts of the language.
Control and administration include commands and capabilities related to permissions, sessions, transactions, roles, views, stored routines, security policies, and system objects. Although these are sometimes treated as administrative rather than analytical concerns, they are essential to how shared relational systems remain governable.
The breadth of SQL matters because it unifies structure, state change, retrieval, and governance within a common relational language. This makes relational systems unusually powerful as shared institutional infrastructure.
Joins, aggregation, and declarative retrieval
One of SQL’s greatest strengths is its ability to express complex retrieval logic through concise declarative syntax. The join is especially important because it allows related data stored in separate normalized relations to be recombined when needed. Customers can be joined to orders, orders to order lines, products to sales, students to enrollments, facilities to inspections, and devices to measurements. In a properly designed schema, these joins do not create arbitrary linkages. They traverse governed relationships defined through keys and constraints.
SQL also excels at aggregation. Counts, sums, averages, minima, maxima, grouped summaries, window functions, and analytical expressions allow relational systems to support reporting, monitoring, and operational intelligence. This is one reason relational databases remain central even as analytical ecosystems have expanded. They can serve both as operational record-keepers and as engines for structured summarization.
The declarative nature of joins and aggregation is crucial. Users specify the logical conditions of combination and summarization, while the database determines efficient execution. This is a major reason relational systems proved more scalable and maintainable than earlier navigational approaches that tied retrieval more directly to storage pathways.
Constraints, integrity, and valid state
Relational systems are strong not only because they can retrieve data flexibly, but because they can constrain data meaningfully. Constraints define what kinds of states are allowed in the database. Primary keys prevent duplicate identity within a relation. Foreign keys preserve referential integrity across relations. Unique constraints prevent repeated values where uniqueness matters. Check constraints limit acceptable values. Nullability rules express whether absence is permitted. Data types distinguish dates from numbers, booleans from text, and structured domains from arbitrary strings.
These mechanisms matter because shared systems require more than storage; they require trustworthy state. A database that permits invalid linkages, duplicate identities, contradictory values, uncontrolled updates, or impossible records may still be queryable, but it will not remain reliable. Constraints therefore operate as institutional safeguards embedded in schema.
This is one of the reasons relational databases remain useful in high-stakes environments. A check constraint that prevents negative payment amounts, a foreign key that prevents orphaned order lines, or a unique constraint that protects customer identity is not merely technical neatness. It is a rule about institutional reality.
Transactions, concurrency, and trustworthy change
Relational systems also matter because they support controlled change under concurrent use. In a shared database, many users and applications may try to read and write at the same time. Without transaction discipline, one workflow could see partial results from another, conflicting updates could corrupt state, and multi-step operations could leave the database in an inconsistent intermediate condition.
A transaction defines a boundary around a set of operations that should succeed or fail together. Classical transaction-processing theory describes these properties through the familiar ACID frame: atomicity, consistency, isolation, and durability. The practical point is that a database should protect shared state while many operations proceed concurrently.
Different isolation levels involve different tradeoffs. Stronger isolation can reduce anomalies but may increase contention or reduce throughput. Weaker isolation can improve performance but may permit phenomena such as non-repeatable reads or phantom reads depending on the database and workload. Mature relational design therefore requires clarity about transaction boundaries, expected isolation, rollback behavior, deadlock handling, retry logic, and audit evidence.
Normalization and schema design
Relational database design is inseparable from the problem of redundancy. Normalization is the process of organizing schema so that facts are represented in relations whose dependency structure minimizes update anomalies and semantic confusion. In well-normalized systems, the same fact does not need to be maintained in multiple places unnecessarily, and dependencies are expressed more cleanly through keys and relation structure.
The logic behind normalization is not merely aesthetic. It emerges from the need to align schema with the underlying dependency structure of the domain. When a table combines several independent fact patterns in unstable ways, insertions, deletions, and updates can create anomalies. A normalized relational schema seeks to reduce those problems while preserving meaning and consistency.
At the same time, schema design is contextual. Highly normalized schemas are often well suited to transactional systems, but analytical workloads may later introduce denormalized views, materialized tables, dimensional marts, and reporting structures that prioritize query efficiency over minimal redundancy. This is not a betrayal of the relational model. It is an architectural response to different workloads. What matters is clarity about which layer serves which purpose.
| Concern | Question | Risk if ignored |
|---|---|---|
| Grain | What does one row represent? | Ambiguous aggregation, duplicated facts, unclear joins |
| Primary key | What uniquely identifies a row? | Duplicate identity and unstable relationships |
| Foreign key | What governed relationship links this table to another? | Orphaned records and broken referential integrity |
| Functional dependency | Which attributes depend on which keys? | Update anomalies and hidden redundancy |
| Normalization | Are independent facts separated appropriately? | Mixed fact patterns and semantic instability |
| Analytical denormalization | Which structures are intentionally optimized for reporting? | Unclear distinction between transactional truth and reporting convenience |
Query planning, indexes, and performance
SQL is declarative, but its performance depends on the machinery beneath the language. Modern relational systems include query planners and optimizers that interpret SQL statements and choose execution strategies based on indexes, statistics, access paths, join orders, costs, and expected cardinalities. This is one reason relational systems are more than logical abstractions; they are highly engineered execution environments.
Indexes play a major role by providing more efficient access paths for search, filtering, sorting, and join operations. But indexing is always a tradeoff. Indexes improve many reads while imposing storage cost and write overhead. A heavily indexed table may serve lookup and reporting workloads well but slow down insert-heavy transactional workloads. Good relational design therefore requires both logical clarity and workload awareness.
This interaction between declarative SQL and physical optimization is one of the model’s enduring achievements. Users express intent at a high level; the system works to make that intent executable efficiently. But performance does not happen by magic. It depends on schema design, statistics, indexes, partitioning, query patterns, concurrency, hardware, configuration, and the maturity of the database engine.
Modern relational systems in practice
Modern relational systems are no longer limited to simple table stores sitting behind monolithic applications. They now operate across on-premises deployments, managed cloud services, replicated systems, distributed SQL databases, analytical extensions, JSON-capable relational environments, embedded systems, and hybrid architectures that combine transactional workloads with analytical features. Yet the underlying relational logic remains recognizable: schema, keys, constraints, transactions, SQL, and optimizer-driven execution.
PostgreSQL is one important contemporary example because it combines a mature SQL implementation with extensive support for data types, indexes, functions, transactions, views, constraints, administrative commands, procedural extensions, and performance tuning. Other relational systems make different implementation choices, but the broader architectural pattern remains stable.
The persistence of relational systems shows that they have not stood still. They have evolved while preserving their core commitments to structured representation, declarative access, transactional control, and governed state. In many modern architectures, relational databases coexist with data lakes, warehouses, streaming systems, document stores, search systems, and feature platforms. The relational layer remains central where structured identity, consistency, and auditable state matter.
Limits of relational systems
Relational systems are foundational, but they are not universal solutions. Some workloads strain the model or expose its limits. Highly irregular semi-structured documents may fit awkwardly into rigid schemas. Rich graph traversals may become cumbersome through repeated joins. High-velocity time-series ingestion may require specialized storage, compression, and retention strategies. Embedding-based similarity search introduces retrieval problems that classical relational operators were not designed to solve directly. Massive object storage and raw evidence retention often require lake-style architecture outside the relational core.
These limits do not diminish the importance of relational databases. They clarify the kinds of problem structures for which alternative architectures arise. In many real systems, relational databases coexist with other storage forms rather than being displaced by them. The relational layer continues to handle core structured records, governed identity, transactions, and reporting, while adjacent systems address specialized workloads.
For that reason, the right question is rarely whether relational databases are obsolete. The better question is which part of the information environment benefits from relational discipline and which part requires complementary architectural forms.
A mathematical lens for relational systems
A relation can be represented as a set of tuples over named attributes:
R(A_1, A_2, \ldots, A_n) = \{t_1, t_2, \ldots, t_m\}
\]
Interpretation: Relation \(R\) has attributes \(A_1,\ldots,A_n\) and tuples \(t_1,\ldots,t_m\). In practical SQL systems, this is usually represented as a table with columns and rows.
A primary key is a set of attributes that uniquely identifies tuples:
\forall t_i, t_j \in R,\; t_i[K] = t_j[K] \Rightarrow t_i = t_j
\]
Interpretation: If two tuples have the same key value \(K\), they must be the same tuple. This is the formal intuition behind unique identity.
A foreign key expresses a referential relationship between relations:
R[F] \subseteq S[K]
\]
Interpretation: Every foreign-key value \(F\) in relation \(R\) must correspond to an existing key value \(K\) in relation \(S\). This protects referential integrity.
A join combines relations according to a predicate:
R \bowtie_{\theta} S = \{(r,s) : r \in R,\; s \in S,\; \theta(r,s)\}
\]
Interpretation: A join returns paired tuples from relations \(R\) and \(S\) when predicate \(\theta\) is satisfied, such as matching a customer key in an orders table.
A functional dependency states that one set of attributes determines another:
X \rightarrow Y
\]
Interpretation: Attribute set \(X\) functionally determines \(Y\) when each value of \(X\) is associated with one value of \(Y\). Functional dependencies are central to normalization.
A transaction can be represented as a sequence of operations that commits or rolls back as a unit:
T = (o_1, o_2, \ldots, o_k) \Rightarrow \mathrm{COMMIT} \;\text{or}\; \mathrm{ROLLBACK}
\]
Interpretation: Transaction \(T\) contains operations \(o_1,\ldots,o_k\). The database should not leave the institution with a partially applied state change.
A relational-readiness score can combine schema, constraints, query workload fit, transaction health, access controls, and incident resolution:
Q_r = w_SS_r + w_CC_r + w_QQ_r + w_TT_r + w_AA_r + w_II_r
\]
Interpretation: Relational readiness \(Q_r\) can combine schema readiness \(S_r\), constraint strength \(C_r\), query workload fit \(Q_r\), transaction health \(T_r\), access control maturity \(A_r\), and integrity incident resolution \(I_r\).
The point of this mathematical lens is not to reduce databases to formulas. It is to make relational discipline visible: identity, reference, dependency, valid state, query composition, and controlled change all have formal structure.
Python Workflow: Relational Schema, SQL Workload, Integrity, and Readiness Scorecard
The following Python workflow demonstrates how a relational database review can evaluate table grains, primary keys, foreign keys, constraints, normalization checks, query workload fit, transaction evidence, access controls, integrity incidents, and relational-readiness scoring.
#!/usr/bin/env python3
"""
Python Workflow: Relational Schema, SQL Workload,
Integrity, and Readiness Scorecard
This compact example treats a relational database as structured evidence:
tables, grains, keys, constraints, indexes, query workloads, transactions,
access controls, integrity incidents, and readiness scoring.
"""
from __future__ import annotations
from statistics import mean
def status_score(value: str) -> float:
return {
"certified": 1.0,
"approved": 1.0,
"pass": 1.0,
"good": 1.0,
"committed": 1.0,
"resolved": 0.9,
"registered": 0.75,
"in_review": 0.60,
"watch": 0.45,
"warn": 0.40,
"planned": 0.35,
"rolled_back": 0.25,
"missing": 0.10,
"failed": 0.0,
}.get(value, 0.5)
def severity_weight(value: str) -> float:
return {
"low": 0.05,
"medium": 0.15,
"high": 0.30,
"critical": 0.50,
}.get(value, 0.15)
def relational_readiness_score(
schema: float,
constraints: float,
workload_fit: float,
transactions: float,
access_controls: float,
integrity_incidents: float,
) -> float:
return round(
0.24 * schema
+ 0.18 * constraints
+ 0.18 * workload_fit
+ 0.14 * transactions
+ 0.14 * access_controls
+ 0.12 * integrity_incidents,
3,
)
def main() -> None:
tables = [
{
"table": "customers",
"entity_type": "entity",
"grain": "one row per customer",
"primary_key": "customer_id",
"certification": "certified",
"incident_count": 0,
},
{
"table": "orders",
"entity_type": "event",
"grain": "one row per customer order",
"primary_key": "order_id",
"certification": "certified",
"incident_count": 0,
},
{
"table": "order_lines",
"entity_type": "event",
"grain": "one row per ordered product line",
"primary_key": "order_line_id",
"certification": "certified",
"incident_count": 0,
},
{
"table": "shipments",
"entity_type": "event",
"grain": "one row per shipment",
"primary_key": "shipment_id",
"certification": "in_review",
"incident_count": 1,
},
]
constraints = [
{"table": "customers", "type": "primary_key", "severity": "critical", "status": "approved"},
{"table": "customers", "type": "unique", "severity": "high", "status": "approved"},
{"table": "orders", "type": "primary_key", "severity": "critical", "status": "approved"},
{"table": "orders", "type": "foreign_key", "severity": "critical", "status": "approved"},
{"table": "orders", "type": "check", "severity": "high", "status": "approved"},
{"table": "order_lines", "type": "foreign_key", "severity": "critical", "status": "approved"},
{"table": "order_lines", "type": "check", "severity": "high", "status": "approved"},
{"table": "shipments", "type": "foreign_key", "severity": "critical", "status": "in_review"},
]
table_scores = []
for table in tables:
table_constraints = [
constraint for constraint in constraints
if constraint["table"] == table["table"]
]
has_pk = bool(table["primary_key"])
approved_constraint_share = mean([
status_score(constraint["status"])
for constraint in table_constraints
])
incident_penalty = min(0.4, table["incident_count"] * 0.20)
table_scores.append(
max(
0.0,
0.30 * float(has_pk)
+ 0.30 * approved_constraint_share
+ 0.20 * status_score(table["certification"])
+ 0.20 * float(bool(table["grain"]))
- incident_penalty,
)
)
constraint_scores = [
0.50 * status_score(constraint["status"])
+ 0.25 * (1.0 - severity_weight(constraint["severity"]))
+ 0.25 * (1.0 if constraint["type"] in {"primary_key", "foreign_key", "unique", "check"} else 0.5)
for constraint in constraints
]
query_workloads = [
{
"query": "customer_order_history",
"expected_latency_ms": 150,
"p95_latency_ms": 120,
"index_fit": 1.0,
"status": "good",
},
{
"query": "daily_revenue_report",
"expected_latency_ms": 600,
"p95_latency_ms": 720,
"index_fit": 0.75,
"status": "watch",
},
{
"query": "payment_exception_review",
"expected_latency_ms": 200,
"p95_latency_ms": 350,
"index_fit": 0.70,
"status": "watch",
},
]
query_scores = []
for query in query_workloads:
latency_score = min(1.0, query["expected_latency_ms"] / query["p95_latency_ms"])
query_scores.append(
0.40 * query["index_fit"]
+ 0.35 * latency_score
+ 0.25 * status_score(query["status"])
)
transactions = [
{"result": "committed", "latency_ms": 90, "rollback": False, "deadlock_retries": 0},
{"result": "committed", "latency_ms": 650, "rollback": False, "deadlock_retries": 1},
{"result": "rolled_back", "latency_ms": 920, "rollback": True, "deadlock_retries": 2},
]
transaction_scores = []
for txn in transactions:
latency_score = max(0.0, 1.0 - min(txn["latency_ms"] / 1000.0, 1.0))
retry_penalty = min(0.4, txn["deadlock_retries"] * 0.15)
transaction_scores.append(
max(
0.0,
0.45 * status_score(txn["result"])
+ 0.25 * latency_score
+ 0.20 * (0.0 if txn["rollback"] else 1.0)
+ 0.10 * (1.0 - retry_penalty),
)
)
access_controls = [
{"role": "analyst_readonly", "least_privilege": "pass", "status": "approved"},
{"role": "finance_analyst", "least_privilege": "pass", "status": "approved"},
{"role": "app_service", "least_privilege": "watch", "status": "in_review"},
]
access_scores = [
0.60 * status_score(item["least_privilege"])
+ 0.40 * status_score(item["status"])
for item in access_controls
]
incidents = [
{"severity": "high", "status": "in_review"},
{"severity": "critical", "status": "resolved"},
]
incident_scores = [
status_score(item["status"]) * (1.0 - severity_weight(item["severity"]) / 2.0)
for item in incidents
]
print({
"schema_score": round(mean(table_scores), 3),
"constraint_score": round(mean(constraint_scores), 3),
"query_workload_score": round(mean(query_scores), 3),
"transaction_score": round(mean(transaction_scores), 3),
"access_control_score": round(mean(access_scores), 3),
"incident_resolution_score": round(mean(incident_scores), 3),
"relational_sql_readiness": relational_readiness_score(
schema=mean(table_scores),
constraints=mean(constraint_scores),
workload_fit=mean(query_scores),
transactions=mean(transaction_scores),
access_controls=mean(access_scores),
integrity_incidents=mean(incident_scores),
),
})
if __name__ == "__main__":
main()
This workflow treats relational systems as structured governance evidence. It evaluates not only whether tables exist, but whether their grains, keys, constraints, indexes, transactions, access controls, and integrity incidents support trustworthy institutional state.
R Workflow: Relational Schema, Constraints, Workloads, Transactions, and Governance Summary
The following R workflow summarizes relational schema structure, constraint coverage, query workload latency, index status, normalization checks, transaction behavior, access controls, and integrity incidents.
#!/usr/bin/env Rscript
# R Workflow: Relational Schema, Constraints, Workloads,
# Transactions, and Governance Summary
schema <- data.frame(
table_name = c(
"customers",
"products",
"orders",
"order_lines",
"payments",
"shipments",
"audit_log"
),
entity_type = c(
"entity",
"entity",
"event",
"event",
"event",
"event",
"event"
),
normalization_target = c(
"3NF",
"3NF",
"3NF",
"3NF",
"3NF",
"3NF",
"append_only"
),
row_count = c(120000, 55000, 850000, 4200000, 970000, 810000, 2500000),
certification_status = c(
"certified",
"certified",
"certified",
"certified",
"certified",
"in_review",
"registered"
),
stringsAsFactors = FALSE
)
constraints <- data.frame(
table_name = c(
"customers",
"customers",
"orders",
"orders",
"orders",
"order_lines",
"order_lines",
"payments",
"payments",
"shipments"
),
constraint_type = c(
"primary_key",
"unique",
"primary_key",
"foreign_key",
"check",
"primary_key",
"foreign_key",
"primary_key",
"check",
"foreign_key"
),
severity = c(
"critical",
"high",
"critical",
"critical",
"high",
"critical",
"critical",
"critical",
"critical",
"critical"
),
status = c(
"approved",
"approved",
"approved",
"approved",
"approved",
"approved",
"approved",
"approved",
"approved",
"in_review"
),
stringsAsFactors = FALSE
)
workloads <- data.frame(
workload_name = c(
"customer_order_history",
"daily_revenue_report",
"product_sales_rank",
"payment_exception_review",
"shipment_delay_monitor",
"audit_access_review"
),
query_type = c(
"lookup",
"aggregation",
"aggregation",
"lookup",
"operational",
"governance"
),
join_count = c(2, 2, 1, 1, 1, 0),
expected_latency_ms = c(150, 600, 450, 200, 300, 900),
p95_latency_ms = c(120, 720, 410, 350, 520, 1100),
execution_count_per_day = c(5000, 240, 360, 1500, 2000, 30),
criticality = c("high", "critical", "medium", "high", "high", "medium"),
status = c("good", "watch", "good", "watch", "watch", "watch"),
stringsAsFactors = FALSE
)
indexes <- data.frame(
table_name = c(
"customers",
"orders",
"orders",
"order_lines",
"payments",
"shipments",
"audit_log"
),
index_type = c("btree", "btree", "btree", "btree", "btree", "btree", "btree"),
unique_index = c(1, 1, 0, 1, 0, 0, 0),
covering_index = c(1, 1, 1, 1, 1, 1, 0),
write_overhead_score = c(0.10, 0.12, 0.22, 0.12, 0.22, 0.25, 0.18),
status = c("approved", "approved", "approved", "approved", "in_review", "in_review", "in_review"),
stringsAsFactors = FALSE
)
normalization <- data.frame(
table_name = c("customers", "orders", "order_lines", "shipments", "audit_log"),
normal_form = c("3NF", "3NF", "3NF", "2NF", "append_only"),
duplication_risk = c("low", "low", "low", "medium", "low"),
update_anomaly_risk = c("low", "low", "low", "medium", "low"),
status = c("pass", "pass", "pass", "warn", "pass"),
stringsAsFactors = FALSE
)
transactions <- data.frame(
isolation_level = c(
"read_committed",
"read_committed",
"repeatable_read",
"read_committed",
"serializable"
),
result = c("committed", "committed", "committed", "committed", "rolled_back"),
operation_count = c(3, 2, 4, 1, 5),
rollback_flag = c(0, 0, 0, 0, 1),
deadlock_retry_count = c(0, 0, 1, 0, 2),
latency_ms = c(90, 130, 650, 30, 920),
stringsAsFactors = FALSE
)
access <- data.frame(
role_name = c("analyst_readonly", "finance_analyst", "etl_service", "app_service", "dba_admin"),
privilege = c("SELECT", "SELECT", "SELECT;INSERT;UPDATE", "SELECT;INSERT;UPDATE", "ALL"),
least_privilege_status = c("pass", "pass", "pass", "watch", "pass"),
row_level_security = c(1, 1, 0, 1, 0),
masking_required = c(1, 1, 0, 1, 0),
status = c("approved", "approved", "approved", "in_review", "approved"),
stringsAsFactors = FALSE
)
incidents <- data.frame(
table_name = c("shipments", "customer_segments", "payments", "audit_log"),
incident_type = c(
"foreign_key_orphan_candidate",
"reference_table_missing",
"negative_amount_rejected",
"query_latency_above_target"
),
affected_rows = c(12, 120, 3, 0),
severity = c("high", "medium", "critical", "medium"),
status = c("in_review", "planned", "resolved", "in_review"),
stringsAsFactors = FALSE
)
schema_summary <- aggregate(
row_count ~ entity_type + normalization_target + certification_status,
data = schema,
FUN = function(x) c(table_count = length(x), total_rows = sum(x), mean_rows = mean(x))
)
schema_summary <- do.call(data.frame, schema_summary)
constraint_summary <- aggregate(
table_name ~ constraint_type + severity + status,
data = constraints,
FUN = length
)
names(constraint_summary) <- c(
"constraint_type",
"severity",
"status",
"constraint_count"
)
workloads$p95_to_expected_ratio <- workloads$p95_latency_ms / workloads$expected_latency_ms
workload_summary <- aggregate(
cbind(expected_latency_ms, p95_latency_ms, p95_to_expected_ratio, execution_count_per_day) ~ query_type + criticality + status,
data = workloads,
FUN = mean
)
index_summary <- aggregate(
write_overhead_score ~ table_name + index_type + unique_index + covering_index + status,
data = indexes,
FUN = function(x) c(index_count = length(x), mean_write_overhead = mean(x))
)
index_summary <- do.call(data.frame, index_summary)
normalization_summary <- aggregate(
table_name ~ normal_form + duplication_risk + update_anomaly_risk + status,
data = normalization,
FUN = length
)
names(normalization_summary) <- c(
"normal_form",
"duplication_risk",
"update_anomaly_risk",
"status",
"check_count"
)
transaction_summary <- aggregate(
cbind(operation_count, rollback_flag, deadlock_retry_count, latency_ms) ~ isolation_level + result,
data = transactions,
FUN = mean
)
access_summary <- aggregate(
role_name ~ privilege + least_privilege_status + row_level_security + masking_required + status,
data = access,
FUN = length
)
names(access_summary) <- c(
"privilege",
"least_privilege_status",
"row_level_security",
"masking_required",
"status",
"grant_count"
)
incident_summary <- aggregate(
affected_rows ~ table_name + incident_type + severity + status,
data = incidents,
FUN = sum
)
dir.create("outputs", showWarnings = FALSE, recursive = TRUE)
write.csv(schema_summary, "outputs/schema_summary_r.csv", row.names = FALSE)
write.csv(constraint_summary, "outputs/constraint_summary_r.csv", row.names = FALSE)
write.csv(workload_summary, "outputs/query_workload_summary_r.csv", row.names = FALSE)
write.csv(index_summary, "outputs/index_summary_r.csv", row.names = FALSE)
write.csv(normalization_summary, "outputs/normalization_summary_r.csv", row.names = FALSE)
write.csv(transaction_summary, "outputs/transaction_summary_r.csv", row.names = FALSE)
write.csv(access_summary, "outputs/access_control_summary_r.csv", row.names = FALSE)
write.csv(incident_summary, "outputs/integrity_incident_summary_r.csv", row.names = FALSE)
cat("Wrote relational schema, constraint, workload, index, normalization, transaction, access, and incident summaries.\n")
This workflow treats relational design as a structured review problem. It shows how schema structure, constraints, query workload, indexes, normalization, transactions, permissions, and integrity incidents can be summarized together rather than reviewed in isolation.
Applications across domains
Relational databases and SQL systems remain central across domains where structured identity, governed relationships, and auditable state matter. Banking systems depend on relational records for accounts, customers, transactions, ledgers, and compliance evidence. Hospitals and clinics rely on relational structures for patients, encounters, orders, medications, claims, and administrative workflows. Universities use them for students, courses, enrollments, credentials, and institutional reporting. Governments use them for registries, taxation, licensing, case systems, benefits, inspections, and public accountability. Commerce platforms use them for customers, products, orders, inventory, payments, fulfillment, and returns.
In each case, the value of the relational model lies not only in storage efficiency but in the preservation of interpretable institutional state. SQL then becomes the working language through which that state can be queried, summarized, updated, and governed across human and machine actors alike.
Relational systems also remain crucial in analytical architecture. Warehouses, marts, semantic layers, reporting datasets, governance catalogs, and many machine-learning feature workflows continue to depend on relational thinking: defined grain, keys, constraints, joins, aggregations, and stable definitions. Even when data ultimately lands in a lakehouse or distributed analytical engine, the relational logic of structure and query remains deeply influential.
Implementation principles for high-integrity relational systems
Define the grain of every table. Each table should make clear what one row represents.
Use primary keys deliberately. Identity should be stable, unique, and documented.
Use foreign keys where relationships matter. Referential integrity should be enforced when orphaned records would undermine trust.
Constrain valid state. Nullability, uniqueness, check constraints, domains, and types should reflect real institutional rules.
Normalize transactional schemas where anomalies matter. Redundancy should be minimized where it creates update, deletion, or insertion anomalies.
Denormalize analytically only with intent. Views, materialized tables, dimensional marts, and reporting layers should be documented as analytical structures.
Design indexes from workload evidence. Indexes should support observed query patterns while accounting for write overhead.
Measure transaction health. Rollbacks, deadlocks, retries, isolation levels, and latency should be visible.
Govern access through least privilege. Roles, grants, row-level security, and masking should match data sensitivity and user purpose.
Treat SQL as institutional language. Queries, schema definitions, and constraints are not merely technical artifacts; they are how structured institutional claims are expressed.
| Control | Purpose | Failure it prevents |
|---|---|---|
| Table grain | Defines what one row means | Ambiguous records, double counting, and unstable joins |
| Primary key | Defines unique identity | Duplicate institutional state |
| Foreign key | Protects governed relationships | Orphaned records and broken referential integrity |
| Check and domain constraints | Restrict valid values | Impossible, invalid, or contradictory state |
| Normalization review | Aligns schema with dependency structure | Update anomalies and hidden redundancy |
| Index design | Supports query performance | Slow joins, scans, filters, and reporting workloads |
| Transaction monitoring | Tracks controlled state change | Unexplained rollbacks, deadlocks, and partial operations |
| Access governance | Controls who can see or change structured state | Overbroad permissions and weak accountability |
GitHub Repository
This article can be paired with a companion code workflow that models relational databases and SQL systems as structured-data governance infrastructure. The example includes relational schema inventories, constraint inventories, query workloads, index inventories, normalization checks, transaction logs, access controls, integrity incidents, SQL schemas, SQLite examples, Python and R workflows, Julia scoring, typed contracts, Quarto report templates, and multi-language examples across Python, R, Julia, SQL, Go, Rust, C, C++, TypeScript, and Terraform placeholders.
The companion repository provides a vendor-neutral relational databases and SQL systems scaffold with table-grain inventories, primary-key and foreign-key checks, constraint scorecards, query-workload and index-fit analysis, normalization review, transaction evidence, access-control summaries, integrity-incident tracking, SQL examples, reproducible reporting templates, typed contracts, documentation, and CI smoke-test patterns.
Conclusion
Relational databases and SQL systems remain foundational because they provide a disciplined architecture for structured institutional state. They define relations, keys, constraints, transactions, and declarative queries in ways that make data durable, interpretable, auditable, and governable. In a world of increasingly diverse data architectures, the relational model continues to matter because many of the most important institutional problems still involve identity, dependency, valid state, controlled change, and shared interpretation.
The deeper point is that relational databases are not merely legacy infrastructure. They are one of the most enduring forms of information discipline. They force clarity about what exists, what relates to what, what is allowed, what changed, who can act, and what can be queried. Modern data systems may extend far beyond the relational model, but they still repeatedly return to relational ideas whenever structured trust, governed state, and analytical clarity are required.
Related articles
- Data Systems & Analytics
- Database Systems and Data Architecture
- Data Warehouses and Data Lakes
- Cloud Data Platforms and Modern Data Stack Architecture
- Data Pipelines and Data Processing Systems
- ETL and Data Transformation Systems
- Data Cleaning and Data Quality Management
- Reproducible Analytics and Versioned Data Workflows
Further reading
- Codd, E.F. (1990) The Relational Model for Database Management: Version 2. Reading, MA: Addison-Wesley.
- Date, C.J. (2003) An Introduction to Database Systems. 8th edn. Boston: Addison-Wesley.
- Elmasri, R. and Navathe, S.B. (2016) Fundamentals of Database Systems. 7th edn. Boston: Pearson.
- Garcia-Molina, H., Ullman, J.D. and Widom, J. (2008) Database Systems: The Complete Book. 2nd edn. Upper Saddle River, NJ: Pearson.
- Gray, J. and Reuter, A. (1992) Transaction Processing: Concepts and Techniques. San Francisco: Morgan Kaufmann.
- Silberschatz, A., Korth, H.F. and Sudarshan, S. (2019) Database System Concepts. 7th edn. New York: McGraw-Hill.
References
- Codd, E.F. (1970) ‘A relational model of data for large shared data banks’, Communications of the ACM, 13(6), pp. 377–387. Available at: https://dl.acm.org/doi/10.1145/362384.362685
- IBM (n.d.) Edgar F. Codd: The inventor made relational databases possible. Available at: https://www.ibm.com/history/edgar-codd
- International Organization for Standardization (2023) ISO/IEC 9075-1:2023 Database languages SQL — Part 1: Framework (SQL/Framework). Available at: https://www.iso.org/standard/76583.html
- International Organization for Standardization (2023) ISO/IEC 9075-2:2023 Database languages SQL — Part 2: Foundation (SQL/Foundation). Available at: https://www.iso.org/standard/76584.html
- PostgreSQL Global Development Group (2026) PostgreSQL 18 Documentation: Part II. The SQL Language. Available at: https://www.postgresql.org/docs/current/sql.html
- PostgreSQL Global Development Group (2026) PostgreSQL 18 Documentation: SQL Commands. Available at: https://www.postgresql.org/docs/current/sql-commands.html
- PostgreSQL Global Development Group (2026) PostgreSQL 18 Documentation: Constraints. Available at: https://www.postgresql.org/docs/current/ddl-constraints.html
- PostgreSQL Global Development Group (2026) PostgreSQL 18 Documentation: Indexes. Available at: https://www.postgresql.org/docs/current/indexes.html
- PostgreSQL Global Development Group (2026) PostgreSQL 18 Documentation: Transactions. Available at: https://www.postgresql.org/docs/current/tutorial-transactions.html
- Gray, J. and Reuter, A. (1992) Transaction Processing: Concepts and Techniques. San Francisco: Morgan Kaufmann.