
Last Updated May 14, 2026
Edge computing in environmental monitoring is a distributed computational architecture through which environmental signals are processed, filtered, interpreted, prioritized, and sometimes operationally acted upon near the point of observation rather than only after transfer to distant centralized systems. It relocates part of environmental intelligence from the cloud, laboratory, or operations center to field devices, local gateways, embedded processors, rugged edge nodes, and near-site servers that sit close to the sensor and close to the phenomenon being measured. In this sense, edge computing is not merely the use of small computers in the field. It is a reorganization of environmental judgment: a decision about which parts of measurement, inference, compression, classification, thresholding, buffering, and response should occur at the observational frontier and which should remain centralized.
Environmental monitoring creates a distinctive computational problem because field data are often high-volume, time-sensitive, bandwidth-constrained, power-limited, and only partially meaningful in raw form. Camera systems generate streams too large to transmit continuously. Acoustic recorders may produce vast archives in which ecologically relevant events are rare. Multiparameter sondes, air-sensor pods, autonomous platforms, smart water devices, infrastructure-linked sensors, and ecological field systems can produce data faster than centralized systems can ingest, interpret, and route into meaningful action when latency matters. Edge computing addresses this by moving selected computation outward, closer to the sensor and closer to the environment, so that data can be screened, compressed, prioritized, classified, quality-checked, or acted upon while the environmental process is still unfolding.
The deeper significance of edge computing lies in the fact that it changes the temporal and epistemic structure of environmental evidence. A conventional monitoring system often measures first and interprets later. An edge system can begin interpreting during measurement itself. That shift matters for hazard detection, threshold exceedance, autonomous event capture, adaptive sampling, resilience under communications loss, and field-level responsiveness. But it also introduces harder problems. What exactly is being decided locally: a raw anomaly, a proxy threshold, a model output, a prediction, a sensor-fault state, or an operational trigger? What information is discarded before it ever reaches a central archive? When does edge intelligence improve environmental awareness, and when does it make the evidence chain more opaque by embedding interpretation inside firmware, device logic, or low-visibility models? Edge computing is therefore not only an engineering pattern. It is a theory of where environmental reasoning belongs and how much interpretation should happen before human review.
Main Library
Publications
Article Map
Environmental Monitoring
Related Topic
Embedded & Edge
Related Topic
Data Systems
Related Topic
Artificial Intelligence
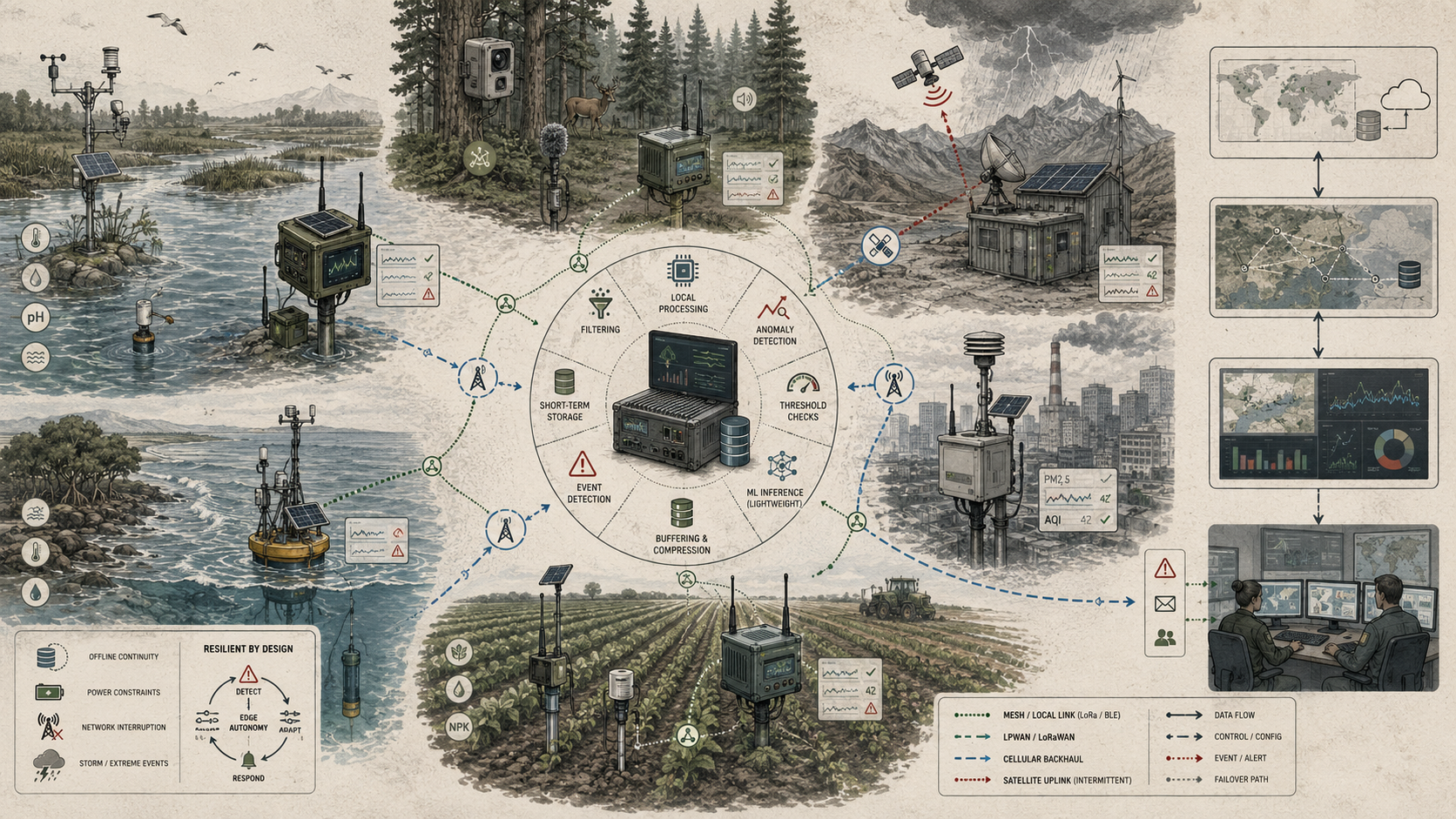
Environmental edge computing is where monitoring becomes locally intelligent evidence infrastructure. It makes it possible for rivers, air sheds, wetlands, coastlines, forests, farms, infrastructure systems, and field stations to be observed not only by distant platforms, but by computational systems that can respond to local conditions as they occur. Yet edge computing is never simply faster processing. It is a redistribution of evidentiary responsibility across the monitoring stack. The central question is not only whether computation happens near the sensor, but whether local computation preserves enough context, uncertainty, traceability, and auditability for edge-derived outputs to remain trustworthy.
Engineering Problem
The engineering problem is how to design environmental edge-computing systems that can reduce latency, bandwidth demand, and central-system dependence while preserving evidence quality, uncertainty visibility, auditability, and decision accountability. Edge computing moves computation closer to the environmental signal, but every local transformation changes what the central system later receives. A field gateway that transmits only anomalies, a camera that saves only high-confidence detections, or a water-quality node that compresses raw observations into summaries may improve responsiveness while weakening later reconstruction if the architecture does not preserve traceability.
This problem is difficult because environmental edge systems are usually deployed where the operating context is harsh and uneven. Field devices may be power-limited, weather-exposed, maintenance-constrained, bandwidth-constrained, physically inaccessible, or intermittently connected. The edge node must often decide what to measure, when to sample, what to buffer, what to transmit, what to discard, what to flag, and what to escalate under imperfect conditions. It must do this while managing battery life, sensor drift, local storage limits, communications failure, model uncertainty, firmware constraints, and operational urgency.
Weak edge architectures treat local computation as a performance optimization. Strong edge architectures treat local computation as an evidentiary design decision. They ask what local rules are doing, what data are lost, which outputs are measured and which are inferred, how models are versioned, how raw context is retained, how uncertainty is transmitted, how latency is measured, how failures degrade, and how local actions remain accountable. The architecture succeeds only when the gain in responsiveness does not silently erode the ability to understand, validate, or explain the environmental evidence later.
| Engineering Tension | Why It Matters | Required Evidence |
|---|---|---|
| Latency reduction versus evidentiary depth | Faster local decisions may occur before full context, validation, or human review is available. | Latency class, confidence flag, local-rule ID, review pathway |
| Bandwidth savings versus information loss | Compression and selective transmission reduce cost but may remove context needed for later interpretation. | Retention policy, compression manifest, raw/summary distinction, loss statement |
| Edge autonomy versus accountability | Local action can improve responsiveness while making decision provenance harder to reconstruct. | Edge action log, rule version, escalation policy, audit trail |
| Adaptive sampling versus comparability | Changing sampling rates can capture events but complicate time-series comparison. | Sampling-mode log, trigger reason, baseline cadence, comparability note |
| Local inference versus model drift | Models deployed at the edge may degrade as environmental conditions, seasons, or sensor states change. | Model card, training domain, drift checks, retraining policy |
| Local resilience versus local opacity | Offline-capable systems may continue operating while central observers cannot inspect what happened. | Buffer log, outage log, synchronization record, replayable event trace |
| Field constraints versus governance expectations | Low-power devices may lack storage or compute for full audit trails unless designed deliberately. | Power budget, storage budget, audit-retention policy, firmware manifest |
The practical question is therefore: can edge computing make environmental monitoring faster, more resilient, and more selective without turning local interpretation into an unreviewable black box?
Reference Architecture
A practical edge-computing architecture for environmental monitoring can be understood as a layered system in which computation is intentionally distributed across the sensor, embedded controller, gateway, local server, cloud platform, analytics service, and decision workflow. The exact implementation may use microcontrollers, embedded Linux gateways, single-board computers, field-deployed GPUs, low-power radios, local time-series buffers, MQTT brokers, SensorThings-style APIs, edge-inference runtimes, quality-control engines, and cloud archives. The responsibilities remain consistent: sense, preprocess, filter, infer, buffer, prioritize, transmit, store, validate, alert, review, and learn.
| Layer | Engineering Role | Primary Risk | Evidence Artifact |
|---|---|---|---|
| Observation objective layer | Defines monitored variables, decision horizons, latency needs, data-retention requirements, and acceptable local autonomy. | Edge functions added for efficiency without connection to monitoring purpose. | Edge objective manifest, decision-use statement, local autonomy policy |
| Sensor and signal layer | Captures environmental signals such as water level, chemical concentration, sound, image, temperature, flow, or biological activity. | Sensor drift, fouling, noise, calibration failure, or weak proxy relation. | Device registry, calibration log, signal metadata, observed-property definition |
| Embedded preprocessing layer | Performs timestamping, range checks, filtering, local storage, basic quality flags, and power-aware sampling. | Firmware silently transforms or suppresses evidence. | Firmware manifest, preprocessing rules, local QC log, sampling-mode record |
| Edge inference and event layer | Runs anomaly detection, threshold logic, classification, trigger rules, adaptive sampling, and local prioritization. | Inferred outputs mistaken for measured facts; model drift or threshold brittleness. | Edge-rule registry, model card, trigger log, confidence score, inference label |
| Buffer and resilience layer | Stores records locally during connectivity gaps, queues events, manages replay, and preserves delayed observations. | Data loss, incomplete replay, unmarked delayed records, buffer overflow. | Buffer policy, outage log, replay log, delayed-record flag |
| Transport and synchronization layer | Moves selected raw, processed, summarized, or event data to central systems through constrained networks. | Packet loss, late data, reordered records, missing raw context. | Connectivity manifest, transmission log, latency report, acknowledgment record |
| Platform and archive layer | Stores raw and processed records, metadata, model outputs, rules, quality flags, and event history. | Central systems receive outputs without enough context to audit them. | Data model, metadata catalog, archive policy, raw/processed lineage |
| Analytics and review layer | Compares edge output with broader context, validates alerts, monitors drift, and supports retraining or rule updates. | Edge decisions remain untested against later evidence. | Review notebook, validation report, drift signal, retraining record |
| Decision and governance layer | Connects edge outputs to operations, science, maintenance, public communication, and accountability. | Local alerts produce action without adequate explanation or ownership. | Escalation policy, governance log, action record, public evidence package |
This architecture makes edge computing visible as a governed distribution of responsibility. The edge is not simply a hardware location. It is where local computational authority is granted, bounded, logged, and reviewed.
Implementation Pattern
A rigorous implementation begins by deciding which environmental tasks genuinely require local processing. Edge computing is most defensible when latency, bandwidth, energy, connectivity, resilience, or local autonomy materially affect monitoring quality. It is less defensible when local computation is added without clear evidentiary, operational, or resilience purpose. The architecture should specify which transformations happen locally, which records remain raw, which records are summarized, which records are transmitted immediately, which are delayed, and which outputs are only preliminary until central review.
| Artifact | Purpose | Suggested Format |
|---|---|---|
| Edge objective manifest | Defines monitored process, latency target, bandwidth constraints, local autonomy, and retention requirements. | YAML, Markdown, architecture decision record |
| Edge device registry | Lists devices, sensors, processors, firmware, deployment locations, observed properties, and calibration state. | CSV, SQL table, asset registry |
| Edge-rule registry | Documents thresholds, filters, compression rules, event triggers, adaptive sampling, and local action logic. | CSV, YAML, rule catalog |
| Edge model card | Documents local inference models, training domain, input features, confidence logic, drift risks, and fallback behavior. | Markdown, model card, MLOps registry record |
| Raw and processed retention policy | Defines what raw records are retained, what is summarized, what is discarded, and when audit samples are preserved. | YAML, governance policy, data-management plan |
| Buffer and replay policy | Defines local storage, outage handling, delayed-record marking, replay order, and overflow behavior. | YAML, runbook, gateway configuration |
| Latency and transport manifest | Defines target latency, transport mode, retry policy, priority classes, and acknowledgment expectations. | YAML, network design record |
| Quality-control policy | Defines local and central QC rules, suspect-data handling, calibration checks, and model-output confidence thresholds. | YAML, QARTOD-style rules, validation code |
| Edge observability plan | Tracks device health, power state, storage use, model version, trigger count, dropped records, latency, and buffer depth. | Dashboard, log schema, metrics specification |
| Governance and review log | Records rule updates, model changes, firmware changes, alert reviews, drift events, and public caveats. | CSV, SQL table, governance register, release notes |
The implementation goal is to make edge intelligence reconstructable. Users should be able to move from a dashboard alert back to the local trigger, from the trigger back to the edge rule or model, from the rule back to the raw or retained context, and from the retained context back to the sensor, deployment, and environmental phenomenon.
Research-Grade Framing: Edge Computing as Distributed Environmental Judgment
A research-grade treatment of edge computing begins by recognizing that it is not merely a distributed IT pattern. It is a reorganization of environmental intelligence. Traditional monitoring pipelines often imply a linear order: sense, transmit, store, analyze, decide. Edge computing destabilizes that order by inserting analysis, prioritization, filtering, and conditional judgment closer to the point where environmental reality is first converted into data.
This means the fact that later appears in a dashboard, alert, or archive may already have been shaped at the edge. Sampling intervals may have been adapted locally. Images may have been screened by motion or model confidence. Acoustic streams may have been compressed into detections. Threshold logic may have decided that one event deserved urgent transmission while another did not. A local gateway may have buffered a flood-stage event, suppressed a duplicate alert, or retained a high-resolution segment while discarding routine data. The edge therefore becomes a site of pre-interpretation rather than a neutral waystation for raw signal.
This redistribution of intelligence is epistemically consequential. Some environmental realities become more visible because they can be identified and prioritized in time. Others may become less visible because local filters suppress weak signals, ambiguous events, subtle precursors, or contextual detail in the name of efficiency. Edge computing therefore offers both gain and risk: more responsiveness, but potentially less transparency; more local intelligence, but also more local opacity. Exceptional edge architectures acknowledge that tradeoff explicitly rather than hiding it behind the rhetoric of real-time analytics.
| Limited Pattern | Stronger Pattern | Why the Shift Matters |
|---|---|---|
| Use edge devices to reduce bandwidth | Design edge rules as auditable environmental relevance decisions | Prevents data reduction from silently becoming evidence loss. |
| Transmit only alerts | Preserve enough context to reconstruct why an alert was generated | Makes urgent signals reviewable after the event. |
| Run local AI models | Version, validate, monitor, and bound edge inference | Prevents opaque local models from weakening evidentiary credibility. |
| Optimize for speed | Balance latency, confidence, uncertainty, and oversight | Prevents rapid misinterpretation from becoming operational action. |
| Buffer during outages | Mark delayed records and preserve replayable event traces | Protects temporal interpretation after connectivity loss. |
| Deploy edge autonomy | Define graduated autonomy, fallback states, and escalation thresholds | Keeps local action within accountable limits. |
The central research question is not “Can this computation run at the edge?” but “What kinds of environmental judgment should be allowed to happen locally, under what evidence standard, and with what traceability afterward?”
Formal Model: Latency, Bandwidth, Edge Traceability, and Evidence Quality
A useful formal model separates latency, bandwidth reduction, edge transformation, retained context, model confidence, quality-control readiness, and decision fit. Let \(L\) represent end-to-end latency, \(B\) bandwidth demand, \(R_e\) edge traceability, \(C_r\) retained raw context, \(Q_c\) quality-control readiness, \(M_d\) model-drift readiness, and \(F_d\) decision fit. Edge evidence quality depends not only on speed, but on how local computation preserves or destroys reviewable meaning.
L_{\mathrm{end\ to\ end}} = t_{\mathrm{decision\ available}} – t_{\mathrm{phenomenon}}
\]
Interpretation: End-to-end latency measures how long it takes an environmental event or condition to become decision-ready evidence.
B_{\mathrm{reduction}} = 1 – \frac{D_{\mathrm{transmitted}}}{D_{\mathrm{raw}}}
\]
Interpretation: Bandwidth reduction measures how much data transmission is reduced by local filtering, compression, summarization, or event selection.
R_{\mathrm{edge}} = \frac{N_{\mathrm{logged\ edge\ transformations}}}{N_{\mathrm{edge\ transformations}}}
\]
Interpretation: Edge traceability measures whether local filters, thresholds, aggregations, model outputs, adaptive sampling changes, and local actions are logged.
C_{\mathrm{retained}} = \frac{D_{\mathrm{raw\ or\ audit\ retained}}}{D_{\mathrm{raw}}}
\]
Interpretation: Retained context measures how much raw or audit-sample information remains available for validation, retraining, and later interpretation.
P_{\mathrm{inference}} = \frac{N_{\mathrm{edge\ outputs\ labeled\ as\ inferred}}}{N_{\mathrm{edge\ inferred\ outputs}}}
\]
Interpretation: Inference transparency measures whether local classifications, anomaly labels, model outputs, and predictions are clearly distinguished from measured values.
Q_{\mathrm{edge\ evidence}} = w_1L_{\mathrm{readiness}} + w_2R_{\mathrm{edge}} + w_3C_{\mathrm{retained}} + w_4Q_{\mathrm{qc}} + w_5P_{\mathrm{inference}} + w_6F_{\mathrm{decision}} – w_7D_{\mathrm{loss}}
\]
Interpretation: Edge evidence quality depends on latency readiness, traceability, retained context, quality control, inference transparency, decision fit, and loss penalty.
This formal structure protects against simplistic edge-computing claims. A system that reduces bandwidth and latency may still be weak as environmental evidence if it discards too much context, hides local inference, fails to track model drift, or cannot explain why a local decision occurred.
What Is Edge Computing in Environmental Monitoring?
Edge computing in environmental monitoring refers to the use of local computational resources—embedded processors, rugged field computers, smart instruments, gateways, single-board computers, local servers, and nearby edge platforms—to perform data handling and analysis close to where environmental measurements are generated. These computations may include quality checks, timestamp alignment, filtering, anomaly detection, threshold logic, compression, local classification, adaptive sampling, event triggering, prioritization of transmissions, preliminary model execution, local buffering, or limited operational response.
Such systems may include smart sensor nodes performing local thresholding, filtering, or quality checks; field gateways aggregating multiple instruments and managing telemetry decisions; camera or acoustic devices using onboard event detection or classification; water, air, or utility systems running local alarm logic or adaptive operating rules; mobile or autonomous platforms that preprocess data before transmission; and hybrid architectures in which edge devices and centralized platforms share analytical tasks.
The defining feature of edge computing is not simply physical location but functional relocation. Computation that would otherwise occur only after transmission to a distant server is moved outward toward the device, gateway, or near-field platform at the edge of the monitoring system. This does not abolish centralized analysis. Instead, it redistributes environmental intelligence across the architecture of observation. The monitoring system no longer has one interpretive center. It becomes a layered computational ecology in which some judgments are made close to the field signal and others remain upstream.
| Function | Local Role | Evidence Requirement |
|---|---|---|
| Local quality control | Detects impossible values, spikes, flatlines, missing records, or sensor-health problems before transmission. | QC rule ID, quality flag, calibration status, suspect-data reason |
| Compression and summarization | Reduces bandwidth by summarizing streams, downsampling, or encoding event segments. | Compression method, retained raw sample, loss statement, summary window |
| Event detection | Identifies threshold exceedance, anomaly, motion, acoustic signal, bloom signature, or environmental event. | Trigger rule, confidence score, pre/post-event buffer, timestamp |
| Adaptive sampling | Changes sampling rate or sensor mode in response to local conditions. | Sampling-mode log, trigger reason, baseline cadence, changed cadence |
| Local inference | Classifies images, sounds, patterns, or sensor states using local rules or models. | Model ID, version, confidence, training-domain note, inferred-state label |
| Buffering and replay | Stores records during connectivity loss and transmits them when transport returns. | Buffer policy, outage window, replay log, delayed-record flag |
| Local action | Triggers alarms, local capture, device-mode shifts, or limited control responses. | Action log, escalation path, autonomy level, override policy |
Edge computing is therefore not a single technology. It is a family of architectural choices about where environmental computation should occur and what evidence must be preserved when it occurs locally.
Why Edge Computing Matters
Edge computing matters because environmental monitoring often operates under hard constraints of bandwidth, latency, power, storage, and connectivity. A field imager may produce far more data than can be transmitted economically. A remote buoy or watershed node may experience intermittent communications and strict energy budgets. A contamination, harmful algal bloom, wildfire-smoke, stormwater, or flood-warning system may need to detect threshold exceedance quickly enough that centralized batch processing is too slow. Under these conditions, a raw-data-first architecture can become not just inefficient, but operationally inadequate.
It also matters because many environmental decisions are time-sensitive in a highly uneven way. Long-term climate trend analysis can absorb slower data movement more easily than smoke alerts, infrastructure alarms, harmful bloom signatures, flood-stage exceedances, contamination triggers, or short-lived ecological events. Edge computing lets systems begin to separate routine conditions from operationally urgent conditions at the source, rather than waiting for all observations to arrive centrally before significance is assigned.
Most importantly, edge computing matters because it changes what monitoring systems are capable of noticing in time. A passive field logger and an edge-aware field node may occupy the same site but inhabit different epistemic worlds. One records. The other screens, ranks, adapts, buffers, and sometimes reacts. That difference is not merely computational convenience. It changes the form of environmental observability available to the institution using the system.
| Need | Edge Contribution | Risk Without Edge Processing |
|---|---|---|
| Low-latency response | Detects urgent environmental conditions near the point of measurement. | Events are recognized only after delayed transmission and central processing. |
| Bandwidth management | Filters, compresses, summarizes, or prioritizes high-value records. | Systems become too costly, slow, or incomplete to transmit useful data. |
| Power conservation | Uses adaptive sampling and selective communication to extend field deployment life. | Devices drain power through unnecessary sensing or communication. |
| Connectivity resilience | Buffers, stores, and locally evaluates observations during outages. | Monitoring stops or loses context whenever communication fails. |
| Event capture | Triggers high-resolution capture only when local conditions warrant it. | Rare or brief events are missed, or routine data overwhelm archives. |
| Operational focus | Separates routine background from actionable signals closer to the field. | Human and platform attention is diluted by undifferentiated telemetry. |
Edge computing matters because environmental intelligence is often valuable only if it arrives within the time window in which action is still possible. But that speed must be designed with evidence discipline. A rapid local inference is useful only when it remains interpretable, validated, and accountable.
Edge Computing as a Reorganization of Environmental Intelligence
Edge computing changes environmental monitoring because it changes where interpretation begins. In traditional architectures, field devices often function as measurement endpoints: they produce signals, transmit records, and leave analysis to a central database, laboratory, or operations center. Edge computing pushes part of that interpretation back toward the field. A device or gateway may decide whether a value is plausible, whether a signal is anomalous, whether a camera frame contains relevant activity, whether a sound deserves retention, whether a flood threshold has been crossed, or whether a higher sampling rate is warranted.
This redistribution gives environmental monitoring systems a more immediate relationship to change. The edge can evaluate a signal while it is still temporally close to the phenomenon, potentially preserving event context that would otherwise be lost. It can also prioritize scarce communication resources in ways that make monitoring more resilient and operationally useful. For remote, hazardous, or fast-changing conditions, this can be transformative.
Yet the same redistribution can narrow what later analysts are able to know. If weak signals are filtered out, ambiguous detections discarded, or raw traces compressed into event labels, then central systems inherit a shaped version of environmental reality. Edge computing therefore changes not only the timing of interpretation, but also the evidentiary inheritance of the monitoring system. The archive may contain not the environment as measured, but the environment as locally selected, summarized, and preinterpreted.
| Monitoring Question | Centralized Pattern | Edge-Enabled Pattern | Evidence Risk |
|---|---|---|---|
| What is routine? | All data are transmitted and classified centrally. | Routine data may be summarized locally. | Baseline variability may be under-retained. |
| What is urgent? | Urgency is determined after central ingestion. | Thresholds or anomalies are detected locally. | Local thresholds may be brittle or poorly contextualized. |
| What is worth retaining? | Storage policy is central and archive-driven. | Devices retain event segments or high-confidence detections. | Ambiguous or low-confidence evidence may disappear. |
| What is inferred? | Models run centrally with more metadata and compute. | Models may run on-device or gateway for speed. | Model version and uncertainty may be hidden. |
| What is acted upon? | Actions follow central review or operations workflow. | Local alarms or adaptive responses can occur immediately. | Action may precede adequate oversight. |
The edge is therefore a site of environmental meaning-making. It determines which signals become urgent, which become summaries, which become alerts, and which may never become central records at all.
Core Functions of Edge Computing at the Environmental Frontier
Edge computing in environmental monitoring commonly performs six interrelated functions: filtering, compression, event detection, adaptive operation, local classification, and operational continuity. These functions are important not just because they save bandwidth or power, but because they shape temporal relevance. The edge decides which parts of environmental variation deserve immediate transmission, durable retention, local escalation, or routine summarization.
| Edge Function | Technical Role | Environmental Value | Evidence Risk |
|---|---|---|---|
| Filtering | Removes implausible readings, artifacts, duplicates, or low-priority records. | Improves signal quality and reduces processing load. | Weak or rare environmental signals may be mistakenly suppressed. |
| Compression and summarization | Transforms raw streams into summaries, aggregates, or compressed records. | Reduces bandwidth, storage, and energy use. | Raw structure needed for later reinterpretation may be lost. |
| Event detection | Identifies threshold exceedance, anomaly, target object, sound, motion, or pattern. | Enables rapid attention to meaningful environmental events. | False positives, false negatives, and threshold brittleness can distort response. |
| Adaptive sampling | Changes measurement frequency or sensor mode based on local conditions. | Captures events at higher fidelity and conserves energy during routine periods. | Uneven sampling may complicate trend analysis and comparability. |
| Local classification | Assigns labels using rules or models for images, sounds, sensor patterns, or device states. | Allows field systems to identify likely conditions before central review. | Inferred labels may be mistaken for direct observations. |
| Operational continuity | Maintains local monitoring, buffering, and limited response when central systems are unavailable. | Improves resilience during connectivity loss or platform outage. | Local actions may occur without immediate central visibility. |
Edge logic embodies a theory of relevance: a practical answer to the question of what environmental change is important enough to treat as an event rather than as background. That theory should be documented, tested, and revisited as conditions change.
Key Analytical Distinctions
Edge computing is not the same as embedded sensing. A field device may sense and log without performing meaningful local computation. Edge computing begins when filtering, inference, prioritization, adaptation, or decision logic is moved outward from the centralized system toward the sensor or gateway.
Local processing is not the same as local understanding. An edge node can execute thresholding, compression, or classification without possessing a full understanding of the environmental process. Its logic remains conditional on model design, proxy validity, calibration state, and deployment context.
Lower latency is not the same as better evidence. Speed can improve actionability, but only if local inference is trustworthy enough that rapid response is not merely rapid misinterpretation.
Bandwidth reduction is not the same as intelligent prioritization. Data compression and selective transmission can preserve resources, but they can also erase ambiguity, context, baseline variability, or precursor signals that later prove important.
Autonomy is not the same as accountability. A system can act or prioritize automatically while still being difficult for operators to inspect, explain, or audit.
Edge-cloud integration is not the same as decentralization. Many edge systems still depend heavily on central archives, retraining pipelines, cross-site synthesis, and governance review. The relevant issue is how interpretive authority is distributed, not whether the cloud disappears.
| Distinction | Why It Matters | Design Implication |
|---|---|---|
| Local computation versus local evidence | Running code near the sensor does not guarantee reliable environmental interpretation. | Validate edge rules and preserve uncertainty, provenance, and context. |
| Signal filtering versus evidence selection | Filtering can shape what later counts as environmental reality. | Document filters, retain audit samples, and expose discarded-data logic. |
| Fast alert versus actionable alert | Speed helps only if alerts are trustworthy, prioritized, and tied to response. | Define severity, owner, escalation, suppression, and review rules. |
| Edge inference versus measured value | Model outputs and classifications are not raw observations. | Label inferred states distinctly from measured sensor records. |
| Adaptive sampling versus stable sampling | Changing cadence improves event capture but complicates statistical comparison. | Log sampling-mode transitions and trigger reasons. |
| Resilience versus opacity | Offline operation is valuable only if post-event reconstruction remains possible. | Preserve buffer logs, replay logs, and delayed-record markers. |
These distinctions prevent edge computing from becoming a story about speed alone. In environmental monitoring, the edge is valuable only when local responsiveness remains connected to evidentiary accountability.
System Architecture: Sensor, Edge, Cloud, and Decision Layer
Edge computing systems in environmental monitoring typically operate as layered architectures. The sensor layer produces raw measurements or environmental signals. The edge layer performs local filtering, threshold logic, anomaly detection, adaptive control, buffering, or preliminary inference. The communications layer moves selected or processed data through radio, cellular, wired, satellite, mesh, or hybrid telemetry pathways. The cloud or central layer performs broader storage, harmonization, archival analysis, retraining, and cross-site interpretation. The decision layer connects outputs to operators, agencies, automated workflows, dashboards, communities, or public communication.
| Layer | Typical Function | Evidence Question |
|---|---|---|
| Physical environment | Environmental condition exists as flow, sound, image, concentration, temperature, height, motion, or biological activity. | What aspect of the environment is actually being represented? |
| Sensor layer | Converts environmental condition into electrical, optical, acoustic, chemical, or digital signal. | Is the sensor calibrated, valid, and suitable for the observed property? |
| Embedded preprocessing | Applies timestamping, basic filtering, local QC, sampling control, and device-state monitoring. | What transformations occur before records leave the device? |
| Edge inference | Runs thresholds, anomaly rules, classification, adaptive sampling, and local event detection. | Which outputs are inferred rather than directly measured? |
| Buffer and replay | Stores records during outages and forwards them later. | Can delayed data be distinguished from real-time data? |
| Transport layer | Moves prioritized records, events, summaries, or raw samples upstream. | What was transmitted, delayed, dropped, compressed, or acknowledged? |
| Central platform | Stores, harmonizes, validates, compares, and exposes edge outputs and retained context. | Does central storage preserve enough metadata and lineage? |
| Decision layer | Turns outputs into alerts, maintenance actions, scientific review, public warnings, or governance records. | Who acts, under what confidence, and with what review trail? |
This architecture matters because edge computing is fundamentally about distribution of tasks across layers. What remains raw? What is transformed locally? What is retained for audit? What is deferred to central systems? A monitoring network becomes trustworthy when this distribution is explicit and fit to purpose rather than accidental.
Latency, Bandwidth, and the Geography of Computation
Environmental monitoring is constrained by the geography of computation. Remote coasts, mountain catchments, agricultural fields, buried infrastructure, wildfire-prone regions, offshore buoys, autonomous platforms, wetlands, and restoration sites operate under uneven communications conditions. Some sites have stable broadband backhaul; others depend on sparse cellular service, scheduled bursts, satellite links, mesh relays, or low-bandwidth radio. Edge computing emerges partly because this geography makes the fantasy of universal continuous cloud dependence unrealistic.
Latency is equally geographical. A delay that is tolerable for long-horizon ecological archiving may be intolerable for flood alarms, contamination response, threshold-triggered imagery, harmful bloom detection, infrastructure alarms, or event-driven operational shifts. Edge computing becomes most defensible where the location of processing alters the decision horizon in materially important ways. The issue is not whether the system can eventually know what happened. The issue is whether it can know soon enough for the knowledge to matter.
Computation is therefore not placeless. Where data are processed affects how quickly the system can notice, classify, and respond to environmental change. The geography of the environment and the geography of computation are entangled, and good architecture recognizes that rather than assuming all interpretation can be centralized without loss.
| Constraint | Edge Pattern | Evidence Risk | Design Response |
|---|---|---|---|
| Low bandwidth | Transmit summaries, anomalies, or event clips rather than full streams. | Routine context and low-confidence signals may be lost. | Retain raw audit samples and document compression logic. |
| Intermittent connectivity | Buffer locally and replay when network returns. | Delayed data may be mistaken for real-time evidence. | Mark outage window, result time, ingestion time, and replay status. |
| Urgent hazard detection | Run local thresholds or anomaly rules at the gateway. | Fast false positives or false negatives may shape response. | Use severity levels, confidence flags, and reviewable alert rules. |
| Power limitation | Use duty cycling, adaptive sampling, and event-triggered communication. | Reduced sampling may miss subtle change. | Log sampling mode and trigger reason. |
| High-volume media | Classify or filter images and sound locally. | Rare events may be discarded by conservative confidence thresholds. | Preserve low-confidence samples for review and retraining. |
Latency and bandwidth are not merely engineering constraints. They influence what environmental conditions become visible in time, what is archived, and what is forgotten.
Filtering, Event Detection, Compression, and Loss
Edge computing often begins with filtering because field systems produce more data than can be transmitted, reviewed, or stored at full fidelity. Images may be screened for motion or target features. Acoustic streams may be summarized into candidate detections. Water or air measurements may be checked against plausibility windows or trigger thresholds. Time-series devices may increase resolution during anomalies and reduce it during routine periods.
These operations are powerful because they preserve bandwidth, extend battery life, and focus human attention. But they also formalize loss. Every filter, compression rule, trigger threshold, or model confidence gate is a decision about what will be retained in full, what will be summarized, what will be transmitted, and what will disappear before broader interpretation ever begins.
Data reduction is therefore never merely technical housekeeping. It is an epistemic act. A system that prioritizes only large excursions may miss subtle precursors. A model that retains only high-confidence classifications may erase rare but important events. A compression strategy that keeps summary statistics may discard the structure needed to reinterpret the signal later. Edge filtering always embodies a theory of what counts as relevant environmental evidence.
| Edge Operation | What It Saves | What It May Lose | Audit Strategy |
|---|---|---|---|
| Range filtering | Reduces impossible or clearly faulty values. | Extreme but real environmental conditions if thresholds are poorly set. | Log rejected values and threshold version. |
| Spike filtering | Suppresses noise and transient sensor artifacts. | Short-lived real events or sudden threshold crossings. | Retain spike windows for later review. |
| Media classification | Reduces images, video, or sound to detections. | Ambiguous examples, rare events, or context around detections. | Store low-confidence samples and model confidence. |
| Event-triggered sampling | Conserves power and storage during routine conditions. | Background variability and early precursors. | Maintain baseline sampling and trigger records. |
| Summary aggregation | Reduces transmission volume through statistics. | Temporal structure, outliers, sequence, and event shape. | Retain periodic raw windows and aggregation formula. |
| Priority transmission | Moves urgent records quickly under bandwidth constraints. | Lower-priority records may arrive late or not at all. | Mark priority class, backlog, and dropped-record count. |
Strong edge systems do not pretend loss is absent. They govern loss. They specify what may be compressed, what must be retained, what can be discarded, and what must remain available for audit, validation, or future reinterpretation.
Edge Autonomy, Local Action, and Human Oversight
Edge computing can make environmental monitoring more autonomous by allowing local systems to react without waiting for centralized confirmation. A field gateway may trigger a higher-frequency mode, open a shorter telemetry interval, preserve a local buffer, escalate an alert, activate a camera, switch sensor mode, or initiate a local alarm. A utility edge node may support local warning logic. A wildlife or habitat system may switch into event mode. In some systems, edge logic can support limited control as well as measurement.
But autonomy introduces a profound design tension. Local response can be fast while remaining hard to inspect. Threshold logic may be brittle under novel conditions. A model deployed at the edge may drift away from the contexts in which it was trained. Human oversight can preserve accountability and contextual judgment, but may reduce the practical value of low-latency field computation. The architecture must therefore define not only what the edge can do, but how much authority it has and under what review conditions.
The strongest edge systems treat autonomy as graduated rather than absolute. Some tasks belong naturally at the edge: buffering, plausibility checks, local triggers, adaptive duty cycling, event capture, and preliminary severity classification. Other tasks, especially those with public, regulatory, safety, or infrastructure consequences, may require confirmation or audit beyond the field device. Exceptional design keeps speed and accountability in productive tension instead of sacrificing one for the other.
| Autonomy Level | Edge Capability | Appropriate Use | Oversight Requirement |
|---|---|---|---|
| Observe | Collects and timestamps records locally. | Routine field monitoring and archival sensing. | Device health and calibration review. |
| Filter | Flags or suppresses implausible values and artifacts. | Noise reduction and quality control. | Rule versioning and rejected-record log. |
| Prioritize | Ranks records for transmission or storage. | Bandwidth-constrained environments. | Priority logic and dropped-record accounting. |
| Infer | Classifies events or anomalies using local rules or models. | Camera traps, acoustic sensors, hazard signals, water-quality triggers. | Model card, confidence score, validation and drift monitoring. |
| Alert | Issues local or upstream warnings. | Flood, contamination, smoke, infrastructure alarms. | Severity, owner, escalation, suppression, and review logs. |
| Act | Initiates local control or operational response. | Limited safety actions or field-system protection. | Strict autonomy policy, fail-safe design, and post-action audit. |
Edge autonomy should be designed as a controlled delegation of environmental judgment, not as uncontrolled automation. The more consequential the local action, the stronger the need for traceability, confidence, and review.
Uncertainty, Drift, and the Risk of Opaque Edge Inference
Edge computing does not remove uncertainty; it can relocate it into places that are harder to inspect. Sensors drift. Field contexts change. Embedded models degrade outside the regimes in which they were developed. Thresholds that were sensible in one season become weak in another. Compression and filtering can remove the raw context needed to determine later whether an edge decision was justified.
This creates a distinctive problem: opaque edge inference. A central platform may receive an alert, summary, label, or compressed trace without retaining the full local conditions under which that output was generated. The result can be environmental intelligence that is faster but also less auditable. Systems become responsive precisely by shifting interpretation into places where later scrutiny may be limited.
Trustworthy edge architectures confront this problem directly. They preserve metadata about local processing, distinguish measured values from inferred states, retain raw data strategically for audit or retraining, and make the edge role legible rather than invisible. The goal is not to eliminate edge inference, which is often impossible or undesirable, but to prevent it from becoming a black box that weakens the evidentiary status of the monitoring system.
| Risk | How It Appears | Why It Matters | Mitigation |
|---|---|---|---|
| Sensor drift | Edge logic receives biased inputs while the device still appears operational. | Local thresholds and models may produce false confidence. | Calibration monitoring, drift checks, cross-device comparison. |
| Model drift | Edge model performance changes as environmental conditions shift. | Classifications become less reliable outside training domain. | Model versioning, drift metrics, retraining schedule, fallback rules. |
| Context loss | Central systems receive summary or label without raw signal context. | Analysts cannot verify why the edge made a decision. | Audit windows, retained raw samples, trigger context bundles. |
| Threshold brittleness | Fixed thresholds perform poorly across seasons, sites, or sensor states. | Alerts may become noisy or miss important events. | Seasonal thresholds, site-specific calibration, rule review. |
| Firmware opacity | Local processing changes through updates without clear record. | Time-series changes may reflect firmware rather than environment. | Firmware manifest, release notes, processing-version field. |
| Confidence erasure | Inferred outputs are transmitted without uncertainty or confidence. | Users may treat weak inference as strong evidence. | Confidence score, inference label, uncertainty flag. |
Edge inference is most trustworthy when it is not invisible. Every local model, threshold, filter, or transformation should leave an evidence trail proportionate to the decision it supports.
Tradeoffs Between Edge and Centralized Processing
Edge and centralized processing are not enemies. They are alternative locations for different forms of environmental intelligence. Centralized systems remain strong at long-term storage, cross-site harmonization, retrospective analysis, larger models, retraining, and broader explanatory synthesis. Edge systems remain strong at low-latency filtering, event detection, adaptive sampling, resilience under connectivity loss, and field-level responsiveness.
Some tasks are especially well suited to the edge: local quality checks, thresholding, anomaly screening, adaptive duty cycling, event triggers, bandwidth-aware prioritization, and local buffering. Other tasks remain better suited to central platforms: historical comparison across sites, integration with external datasets, model improvement, retrospective causal analysis, archival interpretation, and public evidence review. Problems emerge when too much intelligence is pushed outward without auditability, or when too much is kept central and the system becomes slow, costly, and operationally fragile.
The best architecture is therefore layered. It aligns the computational geography of the system with the temporal geography of the environmental process and the institutional geography of response. Edge computing succeeds when it does not try to replace central systems wholesale, but instead relocates the right forms of judgment to the right places in the chain.
| Task | Edge Strength | Central Strength | Recommended Pattern |
|---|---|---|---|
| Basic quality checks | Immediate flagging of implausible values. | Cross-site review and calibration analysis. | Run basic checks locally and review patterns centrally. |
| Hazard thresholding | Low-latency detection and local escalation. | Contextual confirmation and public communication. | Use edge alert with central confirmation and review. |
| High-volume media analysis | Local event selection and bandwidth reduction. | Model retraining, error analysis, and archival science. | Classify locally while retaining audit samples centrally. |
| Adaptive sampling | Responds immediately to local conditions. | Evaluates comparability and sampling bias. | Allow local adaptation with sampling-mode logs. |
| Long-term trend analysis | Can preserve local detail when designed well. | Better suited for cross-site harmonization and retrospective interpretation. | Use edge for capture, central systems for trend analysis. |
| Model governance | Enables on-site inference. | Supports validation, drift review, retraining, and documentation. | Deploy model locally, govern model centrally. |
The question is not edge versus cloud. The question is which environmental judgments need to be local, which need to be central, and which need both.
Governance, Auditability, and Evidentiary Accountability
Edge computing has a governance dimension because it redistributes where environmental evidence is formed. Standards, metadata, quality-control rules, and interoperability matter more—not less—when local devices are doing more interpretation. The more computation occurs at the edge, the more important it becomes to document which values were measured directly, which were inferred, which were compressed, which were delayed, and which were discarded.
This matters because edge outputs often feed larger monitoring enterprises, warning systems, compliance workflows, scientific archives, and public dashboards. Their credibility depends on whether the local logic that produced them is interpretable, maintainable, and auditable. A fast alert that cannot later be explained may be operationally useful in the moment and institutionally weak in the long run. Real-time quality-control traditions such as NOAA IOOS QARTOD, observing-system frameworks such as WMO WIGOS, and interoperable sensor-data approaches such as OGC SensorThings API all point toward the same broader requirement: environmental observations must remain usable beyond the device that produced them.
Edge computing therefore becomes an issue of evidentiary accountability. A threshold alert, anomaly label, compressed stream, or local classification is only as credible as the documented logic beneath it. Where edge systems are well designed, they strengthen monitoring by making environmental intelligence faster and more resilient. Where they are poorly documented or weakly validated, they risk trading central delay for local opacity. The crucial question is not whether edge systems are intelligent, but whether their intelligence remains accountable.
| Governance Responsibility | Question | Evidence |
|---|---|---|
| Rule governance | Who defines, reviews, versions, and retires local thresholds, filters, and triggers? | Edge-rule registry, rule owner, version history, review record |
| Model governance | How are edge models trained, deployed, monitored, updated, and retired? | Model card, training-domain note, drift metric, retraining log |
| Data-retention governance | What raw data, audit samples, summaries, and discarded-record logs must be preserved? | Retention policy, raw/processed lineage, audit-sample registry |
| Quality-control governance | How are local and central quality flags coordinated? | QC policy, flag definitions, suspect-data log, calibration record |
| Autonomy governance | What can the edge do without human or central confirmation? | Autonomy level, escalation path, override rule, action log |
| Security governance | How are edge devices provisioned, authenticated, updated, and protected? | Credential policy, firmware update record, access matrix, incident log |
| Public accountability | Can affected publics or external reviewers understand evidence behind edge-derived claims? | Public evidence package, caveats, method notes, source links |
Governance is not an administrative afterthought. It is how edge intelligence remains trustworthy after computation moves away from the center.
Failure Modes, Model Drift, and Edge Architecture Fragility
Environmental edge systems can fail in ways that remain hidden because the central platform continues receiving outputs. A camera may keep transmitting detections while the model fails under new seasonal conditions. A water-quality edge node may keep sending summaries while the raw signal becomes noisy. A gateway may keep generating alerts while its thresholds no longer fit local hydrology. A device may adapt its sampling cadence while later analysts forget that the time series is no longer uniform. This is edge architecture fragility: the system appears responsive while the evidence chain quietly weakens.
Model drift is especially important because local inference often operates under deployment conditions that differ from training conditions. Seasonal change, sensor aging, site-specific conditions, new species, changing turbidity, novel weather patterns, infrastructure modification, or background noise can reduce model reliability. If the edge output arrives as a label without confidence, version, or raw context, drift may remain invisible until decisions have already been affected.
| Failure Mode | Consequence | Prevention |
|---|---|---|
| Hidden filtering loss | Important weak or ambiguous signals are discarded before central review. | Discard logs, retained audit samples, filter review. |
| Model drift | Local classifications degrade under changing field conditions. | Confidence monitoring, validation samples, retraining policy. |
| Threshold brittleness | Fixed local rules fail under new seasons, sensor states, or environmental regimes. | Seasonal review, site-specific thresholds, rule versioning. |
| Adaptive sampling bias | Time series become difficult to compare because sampling changes during events. | Sampling-mode logs, trigger records, statistical adjustment. |
| Buffer overflow | Records are lost during extended outages or storage saturation. | Buffer monitoring, priority queues, overflow policy. |
| Delayed-data confusion | Late records are interpreted as current observations. | Phenomenon time, result time, ingestion time, delayed-record flag. |
| Firmware drift | Device behavior changes without central awareness. | Firmware manifests, release notes, deployment records. |
| Alert fatigue | Too many local alerts reduce attention and trust. | Severity levels, suppression windows, alert-review cadence. |
Strong edge systems assume failure will occur and design systems so that failure is observable, recoverable, and reviewable. The goal is not perfect local intelligence. The goal is accountable local intelligence that degrades transparently.
Future Directions
The future of edge computing in environmental monitoring lies in tighter integration among embedded devices, field gateways, interoperable telemetry, low-power inference, adaptive sampling, local buffering, and central analytical platforms. The most important advances are likely to come not only from faster processors, but from more explicit architectures of distributed intelligence—architectures that specify what should be sensed, filtered, inferred, stored, transmitted, reviewed, and audited at each layer.
Artificial intelligence will expand edge computing through local anomaly detection, image classification, acoustic event detection, adaptive sampling, sensor-fault detection, predictive maintenance, event summarization, and low-latency decision support. But AI will also increase the need for stronger edge governance. If models run at the edge, their versions, training domains, input assumptions, confidence levels, fallback behavior, and drift signals must be logged. If AI summarizes sensor streams, uncertainty and provenance must remain visible. If automated systems issue local alerts, action pathways and human review must be preserved.
The deeper challenge is not simply making field systems smarter. It is making them more trustworthy, inspectable, and fit for purpose under real deployment constraints. Future systems will need stronger support for model updating, clearer preservation of raw context for audit and retraining, better metadata around local processing, sharper distinctions between measured values and edge-derived interpretations, and more robust monitoring of the edge system itself.
Environmental systems are dynamic enough that waiting for centralized judgment is often too slow, yet complex enough that local judgment is never neutral. Edge computing exists inside that tension. Where it is well designed, it extends environmental intelligence into the very moment and place where change is occurring. Where it is weakly designed, it can replace central delay with local opacity. In that sense, edge computing in environmental monitoring is not simply a faster architecture. It is an infrastructure for deciding where environmental judgment belongs, what environmental evidence should look like, and how much interpretation can responsibly occur before human review.
Deployment Readiness Gate
Before an edge-computing system is used for public communication, operational response, hazard alerting, infrastructure monitoring, ecological assessment, water-quality review, regulatory reporting, or accountability, it should pass a deployment readiness gate. This gate should test whether local computation is technically reliable, semantically coherent, quality-controlled, latency-appropriate, auditable, and fit for its decision role.
| Readiness Area | Required Question | Pass Evidence |
|---|---|---|
| Purpose readiness | Does the edge function match the environmental question, latency need, bandwidth constraint, and decision use? | Edge objective manifest, decision-use statement, latency class |
| Device readiness | Are sensors, processors, firmware, storage, power, calibration, and deployment context documented? | Device registry, firmware manifest, calibration log, power budget |
| Rule readiness | Are local thresholds, filters, triggers, compression rules, and adaptive sampling rules versioned? | Edge-rule registry, rule owner, version history, test result |
| Model readiness | Are local models documented, validated, versioned, confidence-aware, and monitored for drift? | Model card, validation report, confidence output, drift metric |
| Retention readiness | Is enough raw or audit context preserved to support later validation, retraining, and explanation? | Retention policy, raw/processed lineage, audit-sample plan |
| Latency readiness | Does end-to-end latency meet the operational decision horizon? | Latency report, phenomenon/result/ingestion time fields, delay flags |
| Resilience readiness | Can the edge system buffer, replay, fail over, and mark delayed records during outages? | Buffer policy, outage simulation, replay log, overflow rule |
| Quality-control readiness | Are local and central QC rules coordinated for range, spike, flatline, drift, missingness, and suspect data? | QC policy, quality flags, suspect-data rules, calibration checks |
| Governance readiness | Are local autonomy, security, model updates, firmware changes, public caveats, and review responsibilities defined? | Governance policy, access matrix, update log, review cadence, public evidence package |
This readiness gate prevents edge systems from being deployed merely because they can process data locally. The stronger standard is whether local computation improves environmental monitoring without weakening the ability to explain and validate the evidence it produces.
Data and Configuration Artifacts
A reproducible edge-computing workflow should include explicit artifacts for edge objectives, devices, rules, models, retention, latency, quality control, buffering, alerts, observability, security, and governance. These artifacts make edge intelligence auditable rather than hidden inside device firmware or gateway configuration.
| Artifact | Purpose | Suggested Path |
|---|---|---|
| Edge objective manifest | Defines monitored process, local processing purpose, latency target, bandwidth constraint, and decision use. | config/edge_objective.yml |
| Edge device registry | Lists devices, sensors, processors, firmware, observed properties, deployment context, and calibration status. | data/edge_device_registry.csv |
| Edge-rule registry | Documents thresholds, filters, compression logic, adaptive sampling, triggers, and local action rules. | data/edge_rule_registry.csv |
| Edge model cards | Documents on-device or gateway models, training domain, inputs, outputs, confidence, and drift risks. | model_cards/edge_model_card.md |
| Retention and loss policy | Defines what raw data, event clips, audit samples, summaries, and discarded-record logs are retained. | config/retention_loss_policy.yml |
| Buffer and replay manifest | Defines local storage, queue policy, outage handling, replay order, delayed-record labels, and overflow rules. | config/buffer_replay_manifest.yml |
| Edge readiness scores | Stores latency readiness, bandwidth reduction, traceability, retained context, QC readiness, and decision fit. | data/edge_readiness_scores.csv |
| Edge event records | Stores local trigger events, anomaly detections, sampling-mode changes, alerts, and local actions. | data/edge_event_records.csv |
| Governance log | Tracks rule updates, model changes, firmware changes, drift events, alert reviews, and public caveats. | data/edge_governance_log.csv |
These artifacts turn edge computing from a hidden implementation choice into an explicit evidence architecture that can be reviewed, improved, and trusted over time.
Mathematical Lens: Latency, Bandwidth, Loss, Traceability, and Readiness
Several simple metrics can help evaluate edge-computing readiness. These metrics are not substitutes for domain review, engineering validation, or governance oversight, but they make the evidence chain more inspectable.
L_{\mathrm{readiness}} = 1 – \min\left(\frac{L_{\mathrm{observed}}}{L_{\mathrm{target}}}, 1\right)
\]
Interpretation: Latency readiness is higher when observed latency remains below the target decision horizon.
B_{\mathrm{reduction}} = 1 – \frac{D_{\mathrm{transmitted}}}{D_{\mathrm{raw}}}
\]
Interpretation: Bandwidth reduction measures how much local processing reduces data transmission compared with raw streams.
D_{\mathrm{loss}} = \frac{D_{\mathrm{discarded\ without\ audit}}}{D_{\mathrm{raw}}}
\]
Interpretation: Loss penalty increases when raw data are discarded without an audit trail or retained sample.
R_{\mathrm{edge}} = \frac{N_{\mathrm{logged\ edge\ transformations}}}{N_{\mathrm{edge\ transformations}}}
\]
Interpretation: Edge traceability measures how many local transformations are logged with rule ID, version, timestamp, and reason.
P_{\mathrm{inference}} = \frac{N_{\mathrm{inferred\ outputs\ with\ confidence}}}{N_{\mathrm{inferred\ outputs}}}
\]
Interpretation: Inference transparency measures whether local model outputs include confidence, version, and evidence-status labels.
Q_{\mathrm{edge\ evidence}} = w_1L_{\mathrm{readiness}} + w_2R_{\mathrm{edge}} + w_3C_{\mathrm{retained}} + w_4Q_{\mathrm{qc}} + w_5P_{\mathrm{inference}} + w_6F_{\mathrm{decision}} – w_7D_{\mathrm{loss}}
\]
Interpretation: Edge evidence quality depends on latency readiness, traceability, retained context, quality control, inference transparency, decision fit, and loss penalty.
These measures evaluate edge computing as an evidence system rather than a performance feature. They ask whether local computation is fast, traceable, context-preserving, quality-controlled, transparent, and decision-ready.
Python Workflow: Edge Readiness and Evidence Quality
A Python workflow can demonstrate how edge components might be evaluated for latency readiness, bandwidth reduction, retained context, edge traceability, quality-control readiness, inference transparency, and decision fit. The purpose is not to create a universal score, but to make edge-readiness dimensions visible.
from dataclasses import dataclass
from typing import List
import pandas as pd
@dataclass
class EdgeComponent:
component_id: str
domain: str
component_type: str
observed_latency_seconds: float
target_latency_seconds: float
raw_data_mb: float
transmitted_data_mb: float
discarded_without_audit_mb: float
retained_context_score: float
edge_traceability: float
qc_readiness: float
inference_transparency: float
decision_fit: float
high_stakes_use: bool
def latency_readiness(component: EdgeComponent) -> float:
if component.target_latency_seconds <= 0:
return 0.0
ratio = component.observed_latency_seconds / component.target_latency_seconds
return max(0.0, 1.0 - min(ratio, 1.0))
def bandwidth_reduction(component: EdgeComponent) -> float:
if component.raw_data_mb <= 0:
return 0.0
return max(0.0, min(1.0, 1.0 - component.transmitted_data_mb / component.raw_data_mb))
def loss_penalty(component: EdgeComponent) -> float:
if component.raw_data_mb <= 0:
return 0.0
return max(0.0, min(1.0, component.discarded_without_audit_mb / component.raw_data_mb))
def edge_evidence_quality(component: EdgeComponent) -> float:
return (
0.16 * latency_readiness(component) +
0.16 * component.edge_traceability +
0.16 * component.retained_context_score +
0.16 * component.qc_readiness +
0.14 * component.inference_transparency +
0.14 * component.decision_fit +
0.08 * bandwidth_reduction(component) -
0.12 * loss_penalty(component)
)
def classify_review_priority(component: EdgeComponent, score: float) -> str:
if component.high_stakes_use and component.qc_readiness < 0.80:
return "high_stakes_qc_review"
if latency_readiness(component) < 0.20:
return "latency_readiness_review"
if component.edge_traceability < 0.75:
return "edge_traceability_review"
if component.retained_context_score < 0.70:
return "retained_context_review"
if component.inference_transparency < 0.75:
return "inference_transparency_review"
if loss_penalty(component) > 0.30:
return "loss_policy_review"
if component.decision_fit < 0.75:
return "decision_fit_review"
if score < 0.75:
return "edge_quality_review"
return "routine_monitoring"
components: List[EdgeComponent] = [
EdgeComponent(
"flood-threshold-gateway",
"water",
"gateway_threshold_engine",
8,
15,
120,
22,
6,
0.84,
0.82,
0.86,
0.80,
0.90,
True,
),
EdgeComponent(
"acoustic-biodiversity-node",
"biodiversity",
"edge_audio_classifier",
45,
60,
850,
40,
320,
0.62,
0.70,
0.76,
0.68,
0.72,
False,
),
EdgeComponent(
"water-quality-edge-sonde",
"water_quality",
"local_qc_and_alert_node",
18,
20,
75,
28,
4,
0.88,
0.78,
0.82,
0.76,
0.86,
True,
),
EdgeComponent(
"wildfire-smoke-camera-edge",
"air_quality",
"image_event_detector",
20,
30,
1500,
60,
260,
0.72,
0.76,
0.80,
0.78,
0.84,
True,
),
]
records = []
for component in components:
score = edge_evidence_quality(component)
records.append({
"component_id": component.component_id,
"domain": component.domain,
"component_type": component.component_type,
"latency_readiness": round(latency_readiness(component), 3),
"bandwidth_reduction": round(bandwidth_reduction(component), 3),
"loss_penalty": round(loss_penalty(component), 3),
"retained_context_score": component.retained_context_score,
"edge_traceability": component.edge_traceability,
"qc_readiness": component.qc_readiness,
"inference_transparency": component.inference_transparency,
"decision_fit": component.decision_fit,
"edge_evidence_quality": round(score, 3),
"review_priority": classify_review_priority(component, score),
})
df = pd.DataFrame(records)
print(df.sort_values(["review_priority", "edge_evidence_quality"]))
This workflow treats edge components as evidence-chain components. A component is not ready merely because it runs locally or reduces bandwidth. It must meet latency needs, preserve traceability, retain enough context, support quality control, distinguish inference from measurement, and fit the decision context.
R Workflow: Edge Node, Gateway, Model, and Alert Reporting
An R workflow can support edge governance by summarizing readiness across component types, domains, and review priorities. This is useful for edge-node audits, gateway review, alert governance, local-inference assessment, and environmental evidence-quality reporting.
library(dplyr)
library(readr)
edge_components <- tribble(
~component_id, ~domain, ~component_type, ~observed_latency_seconds, ~target_latency_seconds, ~raw_data_mb, ~transmitted_data_mb, ~discarded_without_audit_mb, ~retained_context_score, ~edge_traceability, ~qc_readiness, ~inference_transparency, ~decision_fit, ~high_stakes_use,
"flood-threshold-gateway", "water", "gateway_threshold_engine", 8, 15, 120, 22, 6, 0.84, 0.82, 0.86, 0.80, 0.90, TRUE,
"acoustic-biodiversity-node", "biodiversity", "edge_audio_classifier", 45, 60, 850, 40, 320, 0.62, 0.70, 0.76, 0.68, 0.72, FALSE,
"water-quality-edge-sonde", "water_quality", "local_qc_and_alert_node", 18, 20, 75, 28, 4, 0.88, 0.78, 0.82, 0.76, 0.86, TRUE,
"wildfire-smoke-camera-edge", "air_quality", "image_event_detector", 20, 30, 1500, 60, 260, 0.72, 0.76, 0.80, 0.78, 0.84, TRUE
)
edge_summary <- edge_components %>%
mutate(
latency_readiness = pmax(0, 1 - pmin(observed_latency_seconds / target_latency_seconds, 1)),
bandwidth_reduction = pmax(0, pmin(1, 1 - transmitted_data_mb / raw_data_mb)),
loss_penalty = pmax(0, pmin(1, discarded_without_audit_mb / raw_data_mb)),
edge_evidence_quality = round(
0.16 * latency_readiness +
0.16 * edge_traceability +
0.16 * retained_context_score +
0.16 * qc_readiness +
0.14 * inference_transparency +
0.14 * decision_fit +
0.08 * bandwidth_reduction -
0.12 * loss_penalty,
3
),
review_priority = case_when(
high_stakes_use & qc_readiness < 0.80 ~ "high_stakes_qc_review",
latency_readiness < 0.20 ~ "latency_readiness_review",
edge_traceability < 0.75 ~ "edge_traceability_review",
retained_context_score < 0.70 ~ "retained_context_review",
inference_transparency < 0.75 ~ "inference_transparency_review", loss_penalty > 0.30 ~ "loss_policy_review",
decision_fit < 0.75 ~ "decision_fit_review",
edge_evidence_quality < 0.75 ~ "edge_quality_review", TRUE ~ "routine_monitoring" ) ) %>%
arrange(review_priority, edge_evidence_quality)
print(edge_summary)
write_csv(
edge_summary,
"outputs/edge_readiness_summary.csv"
)
The R workflow emphasizes that edge-system review should account for latency readiness, bandwidth reduction, evidence loss, retained context, edge traceability, quality-control readiness, inference transparency, and decision fit. These dimensions help prevent edge systems from being judged by speed or bandwidth reduction alone.
Systems Code: Edge Nodes, Gateways, Rules, Buffers, and Local Inference
Environmental edge computing depends on full-stack systems code. The stack includes embedded firmware, local buffers, gateway event queues, low-power telemetry, edge-rule registries, threshold engines, local inference runtimes, time synchronization, schema validation, replay services, central APIs, observability dashboards, and governance logs. A serious companion repository should therefore include both analytical workflows and systems-code scaffolding.
| Language / Tool | Role in Companion Repository | Example Use |
|---|---|---|
| Python | Edge readiness scoring, latency review, retention analysis, local-inference audit | Edge evidence-quality scoring and review triage |
| R | Edge node, gateway, model, and alert reporting | Governance summaries and readiness tables |
| SQL | Edge device registry, edge-rule registry, event records, retention logs, governance records | Auditable edge architecture database schema |
| C | Embedded edge-rule and threshold scaffolding | Local sensor threshold and quality flag construction |
| C++ | Gateway buffering, priority queues, and event replay simulation | Outage buffer and replayable event trace |
| MicroPython | Low-power edge node example | Adaptive sampling and local thresholding on a field node |
| Go | Lightweight edge health endpoint or platform ingestion service | Expose edge status, buffer depth, and rule version |
| Rust | Safe validation CLI for edge records, rules, and event logs | Validate edge event schemas and transformation manifests |
| TypeScript | Dashboard and platform data models | Edge node cards, event panels, latency views, inference labels |
| TinyML | On-device anomaly or classification placeholder | Local inference with model version and confidence metadata |
| PYNQ / HDL | Streaming threshold, filtering, and quality-flag placeholders | Hardware-assisted local event detection and signal filtering |
This breadth is appropriate because edge computing is not only a software pattern. It is an evidence infrastructure problem spanning hardware, firmware, local models, constrained networks, central systems, observability, and governance.
GitHub Repository
A companion repository for this article should translate the edge-computing framework into reproducible technical scaffolding. The repository should include edge objective manifests, device registries, edge-rule registries, model cards, retention and loss policies, buffer and replay manifests, readiness scoring workflows, SQL schemas, embedded and gateway examples, local inference placeholders, edge observability examples, and governance logs.
Testing and Validation
Testing environmental edge-computing systems requires more than confirming that local code runs or that alerts appear. It requires validating sensor inputs, firmware behavior, local rules, model outputs, raw-data retention, compression and loss, latency, buffer replay, delayed-record labeling, edge-to-cloud lineage, quality-control coordination, model drift, alert actionability, and security controls.
| Test Type | Purpose | Example Test |
|---|---|---|
| Device input test | Ensure edge logic receives valid, calibrated, timestamped sensor inputs. | Validate device ID, calibration status, phenomenon time, and input range. |
| Local rule test | Ensure thresholds, filters, and adaptive sampling rules behave as intended. | Run synthetic edge records through rule test cases. |
| Model inference test | Ensure edge model outputs include version, confidence, and valid-use context. | Evaluate known labeled examples and record inference confidence. |
| Loss and retention test | Ensure compression and filtering preserve required audit context. | Compare raw, transmitted, discarded, and retained audit data volumes. |
| Latency test | Ensure edge outputs arrive within required decision horizon. | Measure phenomenon time to decision-available time under normal and degraded transport. |
| Buffer and replay test | Ensure records survive connectivity loss and remain correctly labeled after replay. | Simulate outage and validate replay order, delayed flags, and missing-record count. |
| Edge traceability test | Ensure every local transformation can be reconstructed. | Audit event record for rule ID, version, input window, output, and timestamp. |
| QC coordination test | Ensure local and central quality-control flags do not conflict silently. | Compare edge QC flags with central validation results. |
| Alert test | Ensure local alerts are actionable, prioritized, owned, and reviewable. | Replay known events and compare expected severity and escalation path. |
| Security test | Ensure edge devices, gateways, and update processes are authenticated and protected. | Test provisioning, firmware-signature checks, access rules, and invalid-message rejection. |
Validation should test the edge system as a chain of evidence. The decisive question is not only whether local computation works, but whether the resulting local judgment can support the claim or action attached to it.
Operational Signals and Edge-System Observability
Edge systems must observe themselves. A system that locally processes environmental signals but cannot report its own rule versions, model versions, buffer depth, latency, dropped records, confidence scores, power state, storage saturation, firmware state, and connectivity status is operationally fragile. Edge observability should track both technical health and evidence health.
| Signal | Why It Matters | Failure Indicator |
|---|---|---|
| Device uptime | Determines whether local computation is active and connected to valid sensing. | Missing heartbeat, repeated reboot, local process crash. |
| Power state | Determines whether edge processing and communication can continue. | Battery decline, thermal throttling, degraded sampling mode. |
| Storage and buffer depth | Determines whether records are accumulating during outages or high-volume events. | Buffer near capacity, dropped records, old unsent records. |
| Rule version | Determines which local logic produced an event or alert. | Untracked rule update, inconsistent behavior across devices. |
| Model version | Determines which local model produced an inference. | Untracked model update, stale model, unsupported deployment domain. |
| Inference confidence | Determines whether local classifications are strong enough for action. | Confidence decline, high uncertainty, rising ambiguous classifications. |
| Latency distribution | Determines whether edge processing meets the decision horizon. | Late alerts, delayed replay, long tail latency. |
| Dropped-record count | Determines whether loss is increasing beyond policy. | Record loss during events, discarded audit context. |
| QC failure rate | Determines whether local data quality is degrading. | Spike, flatline, range, missingness, drift, or calibration warnings. |
| Alert burden | Determines whether local alerts are actionable or overwhelming. | Duplicate alerts, non-actionable alert surge, unresolved events. |
Operational observability protects edge systems from silent degradation. It helps ensure that the appearance of real-time environmental intelligence does not outlast the quality of the local evidence chain beneath it.
Engineer and Researcher Checklist
- Define the environmental decision horizon before deciding what computation belongs at the edge.
- Use edge processing where latency, bandwidth, energy, resilience, or event capture materially improves monitoring.
- Document every local threshold, filter, compression rule, adaptive sampling rule, and model inference pathway.
- Distinguish measured values from inferred labels, anomaly scores, predictions, and local alerts.
- Preserve raw records or audit samples where local filtering, compression, or model inference affects important decisions.
- Log sampling-mode changes, trigger reasons, event windows, confidence scores, rule IDs, and model versions.
- Track phenomenon time, result time, ingestion time, and decision-available time separately.
- Mark delayed records clearly after outages, buffering, or replay.
- Monitor edge health, storage, buffer depth, dropped records, power, firmware version, model version, and connectivity.
- Use graduated autonomy: observe, filter, prioritize, infer, alert, and act under increasingly strict governance requirements.
- Coordinate local and central quality-control rules so suspect data are not silently normalized.
- Maintain governance records for firmware changes, model changes, rule updates, alert reviews, drift events, and public caveats.
Where This Fits in the Series
This article connects Environmental Monitoring Systems to IoT architectures, embedded field devices, environmental sensor networks, data platforms, artificial intelligence, smart water systems, dashboards, intelligent infrastructure, and risk and resilience. It sits at the local-processing layer of the series: the point where environmental observation becomes computationally selective, latency-aware, and resilient under field constraints.
Within the broader series, this article provides the edge-computing framework that supports IoT architectures for environmental monitoring, embedded monitoring devices for field observation, smart water systems and environmental sensing, environmental sensor networks, environmental analytics dashboards, environmental data platforms, and future environmental monitoring systems. Its role is to show that local processing is not merely a technical convenience. It is a consequential design choice about where environmental evidence is shaped, what is preserved, what is lost, and how quickly monitoring can become action.
Related articles
- IoT Architectures for Environmental Monitoring
- Embedded Monitoring Devices for Field Observation
- Environmental Sensor Networks
- Smart Water Systems and Environmental Sensing
- Environmental Data Platforms and Decision Support Systems
- Environmental Analytics and Monitoring Dashboards
- Remote Sensing Systems in Environmental Monitoring
- Monitoring Environmental Risk and Resilience
- Environmental Monitoring Systems
Further reading
- National Oceanic and Atmospheric Administration, Integrated Ocean Observing System (2026) QARTOD. Available at: https://ioos.noaa.gov/project/qartod/
- National Oceanic and Atmospheric Administration, Integrated Ocean Observing System (2022) QARTOD Project Plan Update 2022–2026. Available at: https://cdn.ioos.noaa.gov/media/2022/05/QARTOD-Project-Plan-Update-2022-2026_Final.pdf
- National Oceanic and Atmospheric Administration, Integrated Ocean Observing System (2026) Access IOOS Data. Available at: https://ioos.noaa.gov/data/access-ioos-data/
- National Oceanic and Atmospheric Administration, Integrated Ocean Observing System (2026) Open Data Sharing. Available at: https://ioos.noaa.gov/data/data-standards/open-data-sharing/
- Open Geospatial Consortium (2026) OGC SensorThings API Standard. Available at: https://www.ogc.org/standards/sensorthings/
- Open Geospatial Consortium (2026) OGC SensorThings API Overview. Available at: https://ogcapi.ogc.org/sensorthings/overview.html
- U.S. Environmental Protection Agency (2026) Water Sensors Toolbox. Available at: https://www.epa.gov/water-research/water-sensors-toolbox
- U.S. Environmental Protection Agency (2026) Water Sensors Presentations and Publications. Available at: https://www.epa.gov/water-research/water-sensors-presentations-and-publications
- U.S. Environmental Protection Agency (2024) Intelligent Water Systems. Available at: https://www.epa.gov/system/files/documents/2024-04/cwsrf-intelligent-water-systems.pdf
- U.S. Geological Survey (2026) Artificial Intelligence in the USGS Ecosystems Mission Area. Available at: https://www.usgs.gov/mission-areas/ecosystems/science/artificial-intelligence-usgs-ecosystems-mission-area
- U.S. Geological Survey (2026) Artificial Intelligence Strategy for the U.S. Geological Survey. Available at: https://www.usgs.gov/publications/artificial-intelligence-strategy-us-geological-survey
- World Meteorological Organization (2026) WMO Integrated Global Observing System (WIGOS). Available at: https://wmo.int/activities/wmo-integrated-global-observing-system-wigos
- World Meteorological Organization (2026) WMO Integrated Global Observing System. Available at: https://wmo.int/activities/wmo-integrated-global-observing-system-wigos/wmo-integrated-global-observing-system
References
- National Oceanic and Atmospheric Administration, Integrated Ocean Observing System (2022) QARTOD Project Plan Update 2022–2026. Available at: https://cdn.ioos.noaa.gov/media/2022/05/QARTOD-Project-Plan-Update-2022-2026_Final.pdf (Accessed: 14 May 2026).
- National Oceanic and Atmospheric Administration, Integrated Ocean Observing System (2026) Access IOOS Data. Available at: https://ioos.noaa.gov/data/access-ioos-data/ (Accessed: 14 May 2026).
- National Oceanic and Atmospheric Administration, Integrated Ocean Observing System (2026) Open Data Sharing. Available at: https://ioos.noaa.gov/data/data-standards/open-data-sharing/ (Accessed: 14 May 2026).
- National Oceanic and Atmospheric Administration, Integrated Ocean Observing System (2026) QARTOD. Available at: https://ioos.noaa.gov/project/qartod/ (Accessed: 14 May 2026).
- Open Geospatial Consortium (2026) OGC SensorThings API Standard. Available at: https://www.ogc.org/standards/sensorthings/ (Accessed: 14 May 2026).
- Open Geospatial Consortium (2026) OGC SensorThings API Overview. Available at: https://ogcapi.ogc.org/sensorthings/overview.html (Accessed: 14 May 2026).
- U.S. Environmental Protection Agency (2024) Intelligent Water Systems. Available at: https://www.epa.gov/system/files/documents/2024-04/cwsrf-intelligent-water-systems.pdf (Accessed: 14 May 2026).
- U.S. Environmental Protection Agency (2026) Water Sensors Presentations and Publications. Available at: https://www.epa.gov/water-research/water-sensors-presentations-and-publications (Accessed: 14 May 2026).
- U.S. Environmental Protection Agency (2026) Water Sensors Toolbox. Available at: https://www.epa.gov/water-research/water-sensors-toolbox (Accessed: 14 May 2026).
- U.S. Geological Survey (2026) Artificial Intelligence in the USGS Ecosystems Mission Area. Available at: https://www.usgs.gov/mission-areas/ecosystems/science/artificial-intelligence-usgs-ecosystems-mission-area (Accessed: 14 May 2026).
- U.S. Geological Survey (2026) Artificial Intelligence Strategy for the U.S. Geological Survey. Available at: https://www.usgs.gov/publications/artificial-intelligence-strategy-us-geological-survey (Accessed: 14 May 2026).
- World Meteorological Organization (2026) WMO Integrated Global Observing System (WIGOS). Available at: https://wmo.int/activities/wmo-integrated-global-observing-system-wigos (Accessed: 14 May 2026).
- World Meteorological Organization (2026) WMO Integrated Global Observing System. Available at: https://wmo.int/activities/wmo-integrated-global-observing-system-wigos/wmo-integrated-global-observing-system (Accessed: 14 May 2026).