
Last Updated May 10, 2026
AI in health, medicine, and clinical decision support refers to the use of artificial intelligence systems to assist clinical reasoning, diagnosis, triage, imaging interpretation, risk prediction, treatment planning, documentation, workflow coordination, population health, biomedical research, and patient-facing health services. These systems can identify patterns in images, laboratory data, electronic health records, waveforms, genomics, clinical notes, sensor streams, and patient histories. They can support clinicians by surfacing risks, prioritizing cases, retrieving evidence, summarizing records, recommending next steps, or helping coordinate care. But clinical AI is not merely another software category. It operates in environments where uncertainty, human judgment, patient safety, liability, equity, privacy, and institutional trust are central.
Health AI is powerful because medicine is information-rich, time-constrained, and high-stakes. Clinicians must integrate symptoms, histories, images, labs, guidelines, medications, social context, risks, preferences, and incomplete evidence. AI can help organize this complexity, but it can also create new failure modes: hidden bias, automation bias, overconfident predictions, alert fatigue, workflow disruption, privacy leakage, unsupported recommendations, unsafe generalization, and model drift after deployment. In clinical contexts, the question is not simply whether a model is accurate. The question is whether the system improves care safely, fairly, explainably, and responsibly within a real clinical workflow.
The central argument is that clinical AI should be governed as a medical, technical, organizational, ethical, and regulatory system. A model that performs well in retrospective validation may fail when embedded in an electronic health record, used by different clinicians, applied to a new population, deployed across hospitals, updated over time, or interpreted as a recommendation rather than a signal. Responsible clinical AI therefore requires clinical validation, workflow integration, human oversight, bias analysis, privacy protection, model monitoring, change control, auditability, patient-centered accountability, and careful distinction between assistance, automation, and clinical authority.
Main Library
Publications
Article Map
Artificial Intelligence Systems
Related Topic
Data Systems & Analytics
Related Topic
Risk & Resilience
Related Topic
Institutions & Governance
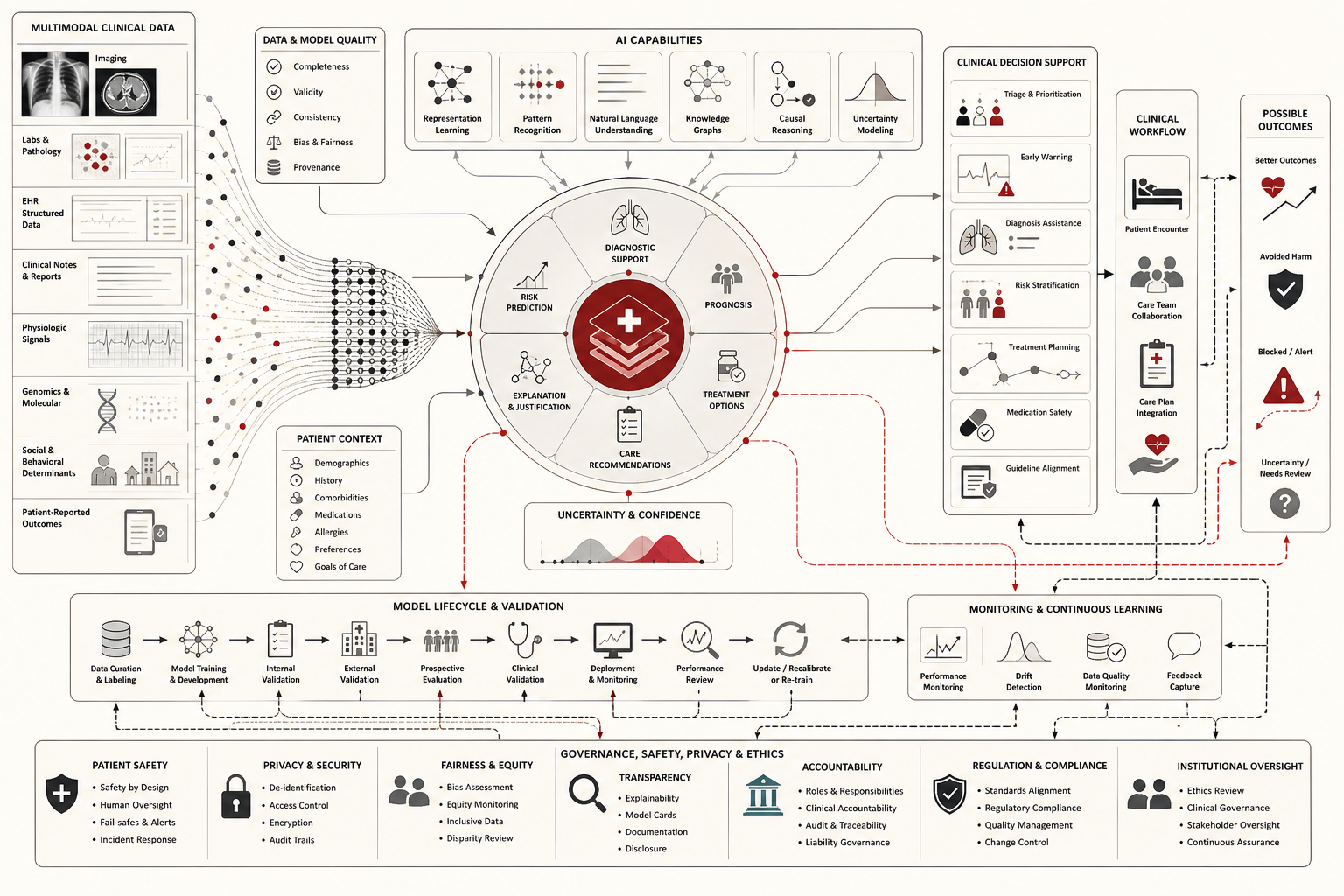
This article develops AI in Health, Medicine, and Clinical Decision Support as an advanced article within the Artificial Intelligence Systems knowledge series. It explains clinical decision support, diagnostic AI, risk prediction, triage, imaging systems, large language models in clinical settings, privacy, health data governance, bias, patient safety, regulatory status, post-deployment monitoring, model drift, change control, institutional accountability, and clinical workflow design. Selected Python and R examples appear here, while the full GitHub repository contains expanded computational scaffolding for clinical validation, calibration review, subgroup analysis, alert-burden monitoring, governance-risk scoring, SQL schemas, documentation templates, incident review, and reproducible notebooks.
Why Clinical AI Matters
Clinical AI matters because medicine is both data-intensive and human-centered. Modern healthcare systems generate enormous volumes of structured and unstructured information: laboratory values, diagnoses, medications, claims, imaging studies, pathology slides, genomics, electrocardiograms, clinician notes, patient messages, bedside monitors, wearables, and operational records. The promise of AI is that it can help clinicians and health systems notice patterns that would otherwise remain hidden, prioritize attention, reduce administrative burden, support early detection, improve documentation, and make care more consistent.
But clinical AI also matters because mistakes can cause harm. A model may miss a diagnosis, overstate risk, reinforce biased care patterns, generate misleading summaries, trigger unnecessary interventions, under-triage a vulnerable patient, or encourage clinicians to rely on a recommendation that is not clinically justified. A model may also perform well in one hospital but poorly in another because disease prevalence, documentation practices, measurement devices, patient populations, workflows, and care pathways differ.
AI in medicine is therefore not simply a question of innovation. It is a question of clinical evidence, patient safety, professional responsibility, and institutional trust. The purpose of clinical AI should not be to replace clinical judgment with opaque automation. It should be to strengthen clinical reasoning, reduce avoidable harm, support equitable care, and make uncertainty visible.
Clinical AI also changes the relationship between data and action. A prediction, alert, or generated summary does not remain inside the model. It enters a care pathway. It may influence which patient is seen first, which image receives priority, which medication is considered, which documentation is trusted, which message is escalated, or which diagnosis remains salient in a clinician’s mind. In clinical settings, model outputs become part of the cognitive and organizational environment of care.
The ethical stakes follow directly from that environment. A model can be mathematically impressive while clinically unsafe. It can be useful in one setting and harmful in another. It can reduce workload while increasing liability. It can improve average performance while harming a subgroup. It can accelerate documentation while introducing factual errors into the medical record. Clinical AI matters because it sits at the boundary between technical inference and human care.
From Prediction to Care
A predictive model does not automatically improve care. A model may estimate risk accurately, but the care system must still decide what to do with that estimate. Does the prediction trigger an alert? Who receives it? How urgent is it? Is the evidence explainable? What action is recommended? Is the clinician able to override it? Does the alert create burden? Does the intervention improve outcomes? Does it affect different patient groups fairly? Is it monitored after deployment?
| Layer | Technical Question | Clinical Question | Governance Question |
|---|---|---|---|
| Data | Are the inputs complete, valid, and representative? | Do the data reflect the patient’s condition? | Are provenance, consent, privacy, and access controls appropriate? |
| Model | Is the model accurate, calibrated, robust, and monitored? | Does the model support clinically meaningful reasoning? | Who approves, validates, updates, and audits the model? |
| Workflow | How is the output delivered? | Does the output help clinicians act at the right time? | Does the system reduce or increase burden, alert fatigue, and risk? |
| Decision | What threshold or policy converts output into action? | What should happen for this patient? | Are authority, accountability, and human review clearly assigned? |
| Outcome | Does the system improve measurable performance? | Does it improve patient care, safety, access, or experience? | Are benefits and harms monitored across populations? |
Note: A technically valid prediction becomes clinically meaningful only when it improves decision-making, workflow, safety, equity, and patient outcomes.
The central challenge is translation. Clinical AI must translate model outputs into safe, timely, and appropriate clinical action. That translation cannot be solved by model accuracy alone. It requires domain expertise, workflow design, outcome evaluation, patient-centered ethics, and governance.
Prediction \neq Care
\]
Interpretation: A model output becomes clinically useful only when it leads to safe, timely, equitable, and appropriate care within a real workflow.
This distinction is especially important for early warning systems, triage tools, diagnostic support, documentation assistants, patient-facing chatbots, and clinical knowledge systems. The same output can be helpful or harmful depending on timing, presentation, clinician workload, patient context, and available resources. A risk score with no clear care pathway may increase anxiety and burden without improving outcomes. An alert delivered to the wrong person at the wrong time may be ignored. A summary that omits uncertainty may create misplaced confidence.
Clinical Decision Support as a Sociotechnical System
Clinical decision support is often described as software that helps clinicians make decisions. But in practice, CDS is a sociotechnical system: it includes data sources, clinical logic, user interfaces, EHR integration, alert timing, clinician interpretation, patient context, organizational policy, regulatory status, monitoring, and accountability.
Traditional CDS may use rules, order sets, medication alerts, guideline reminders, or risk calculators. AI-enabled CDS may use machine learning, natural language processing, computer vision, probabilistic prediction, retrieval-augmented generation, large language models, or multimodal inputs. The technical form may change, but the core responsibility remains: the system must support better clinical decisions without creating hidden harm.
Responsible CDS should make clear:
- what the system is intended to do;
- what population it was trained and validated on;
- what inputs it uses;
- what output it produces;
- what evidence supports its use;
- how clinicians should interpret the output;
- when the system should not be used;
- how performance is monitored;
- how patients and clinicians can report problems;
- who is accountable for deployment and updates.
A sociotechnical view also makes clear why clinical AI cannot be evaluated only in the laboratory. A model may perform well before deployment but fail when placed into a workflow with alert fatigue, staffing constraints, poor interface design, missing data, insufficient training, or unclear responsibility. The system’s safety depends on the interaction among model, clinician, patient, organization, and infrastructure.
Clinical\ AI = Model + Workflow + Human\ Judgment + Monitoring + Governance
\]
Interpretation: Clinical AI is not only a model. It is a deployed care system shaped by workflow, interpretation, monitoring, and institutional responsibility.
Clinical decision support should therefore be designed around human action. What does the clinician need to know? What should happen next? What uncertainty remains? What evidence supports the recommendation? What patient-specific context may change the interpretation? What happens if the clinician disagrees? How will the system learn from errors, overrides, and outcomes?
Major Domains of AI in Health and Medicine
AI appears across multiple clinical and biomedical domains. Each domain has different evidence standards, risks, and governance needs. A single “AI in healthcare” category is too broad. A radiology triage model, ICU deterioration model, documentation assistant, clinical chatbot, pathology image model, oncology trial-matching system, and hospital staffing optimizer require different validation strategies and safeguards.
| Domain | Typical AI Function | Clinical Value | Major Risk |
|---|---|---|---|
| Medical imaging | Detection, segmentation, triage, measurement, quality review. | Prioritizes studies and supports radiology and pathology workflows. | False reassurance, missed findings, dataset shift, device dependence. |
| Clinical risk prediction | Predicts deterioration, readmission, sepsis, mortality, adverse events. | Supports early warning and resource allocation. | Over-alerting, biased risk estimates, poor calibration under drift. |
| Clinical documentation | Summarization, note drafting, coding support, message triage. | Reduces administrative burden. | Hallucinated facts, omitted details, privacy exposure. |
| Decision support | Guideline reminders, diagnostic suggestions, treatment options. | Supports evidence-informed care. | Automation bias, unclear authority, unsafe recommendations. |
| Drug discovery and development | Target discovery, molecule design, trial matching, endpoint analysis. | Accelerates research and prioritization. | Validity gaps, reproducibility issues, biological oversimplification. |
| Population health | Risk stratification, outreach, resource planning. | Supports prevention and care coordination. | Equity harms if social and access factors are mishandled. |
| Patient-facing AI | Symptom guidance, education, navigation, remote monitoring. | Improves access and continuity. | Misinterpretation, unsafe self-management, liability ambiguity. |
| Clinical operations | Scheduling, bed management, staffing, throughput, supply forecasting. | Improves efficiency and resource use. | Optimization may conflict with care quality or fairness. |
Note: Clinical AI governance should be domain-specific because each use case has different evidence needs, risks, workflows, and accountability requirements.
The diversity of clinical AI also means that “human oversight” cannot mean the same thing everywhere. A radiologist reviewing an image triage model, a nurse responding to a deterioration alert, a physician reading an AI-generated note, a care manager using population-health risk scores, and a patient interacting with a symptom checker all require different forms of explanation, training, review, and escalation.
Diagnostics, Imaging, and Pattern Recognition
Some of the most visible clinical AI systems are diagnostic or imaging systems. They may detect lesions, segment organs, prioritize abnormal scans, classify pathology slides, identify retinal disease, analyze ECGs, or flag subtle patterns in medical images. These systems can support clinicians by improving consistency, speed, measurement, triage, or detection sensitivity.
But diagnostic AI must be handled carefully. A high-performing model on retrospective images may fail when imaging devices, acquisition protocols, disease prevalence, patient mix, or clinical workflow change. A model may perform differently across hospitals, scanner types, image quality levels, racial or ethnic groups, age groups, sexes, comorbidity patterns, or rare disease presentations. If the AI output appears authoritative, clinicians may underweight their own judgment or miss contradictory evidence.
Responsible diagnostic AI should be evaluated for:
- clinical sensitivity and specificity;
- false-negative risk for high-harm conditions;
- false-positive burden and downstream testing;
- calibration and uncertainty;
- performance across sites, devices, and patient groups;
- image-quality sensitivity;
- workflow effects and clinician interpretation;
- post-deployment monitoring and incident reporting.
Diagnostic AI also changes attention. A system that highlights a finding may guide the clinician’s eye. A system that fails to highlight a finding may create false reassurance. A triage tool may change which case is read first. A measurement system may affect longitudinal interpretation. These are not merely technical outputs; they are changes to the diagnostic environment.
Diagnostic\ Support \neq Diagnostic\ Authority
\]
Interpretation: Diagnostic AI can support pattern recognition and prioritization, but clinical authority, interpretation, and responsibility must remain clearly assigned.
Risk Prediction, Triage, and Early Warning Systems
Risk prediction systems estimate the probability of future clinical events. Examples include deterioration prediction, sepsis alerts, readmission risk, fall risk, adverse drug event risk, length-of-stay prediction, ICU transfer risk, and mortality risk. These tools can help clinicians prioritize attention, but they also create workflow and equity challenges.
An early warning model may be statistically strong yet clinically ineffective if it alerts too late, alerts too often, targets the wrong clinician, lacks actionable information, or fails to integrate with care pathways. If the system produces many false positives, clinicians may ignore alerts. If it misses high-risk patients, clinicians may develop false reassurance. If it performs worse for certain groups, it may worsen existing inequities.
Risk prediction should therefore be evaluated at multiple levels: model performance, threshold behavior, clinician response, patient outcome, operational burden, and group-level equity. A model that improves AUROC but does not improve clinical workflow or outcomes may not be useful. A model that improves average performance but worsens false-negative rates for a vulnerable group may be unsafe.
Thresholds are especially important. A lower threshold may catch more true cases but increase false positives and alert burden. A higher threshold may reduce workload but miss patients who need attention. Clinical thresholds should reflect harm severity, staffing capacity, intervention availability, equity concerns, and the cost of unnecessary escalation. They should not be chosen by technical performance alone.
Early warning systems also need feedback loops. If clinicians override an alert, why? If alerts are ignored, why? If outcomes worsen despite alerts, what failed: data, model, timing, workflow, staffing, or intervention? If a subgroup experiences more false negatives, is the model miscalibrated, are inputs missing, or is the care pathway unequal? Monitoring should connect predictions to actions and outcomes.
Large Language Models and Clinical Knowledge Systems
Large language models and large multimodal models introduce new possibilities in medicine: summarizing records, drafting notes, answering clinician questions, navigating guidelines, structuring patient messages, supporting prior authorization, extracting information from notes, and synthesizing evidence. Multimodal systems may integrate text, images, audio, video, and structured clinical data.
These systems also introduce distinctive risks. A language model can generate fluent but unsupported statements. It may omit critical details, fabricate citations, misread temporal context, overgeneralize guidelines, fail to distinguish patient-specific evidence from general knowledge, or respond to misleading prompts. In clinical settings, fluency can be dangerous because it may look like expertise.
Clinical LLM systems require controls beyond generic chatbot safety:
- source-grounded retrieval for factual claims;
- clear separation between patient record, retrieved evidence, system instructions, and generated text;
- human review before clinical use;
- traceability of sources and model outputs;
- privacy-preserving logging and access control;
- evaluation for omissions, hallucinations, temporal errors, and unsafe advice;
- deployment boundaries for high-risk clinical decisions;
- monitoring of clinician edits, overrides, complaints, and incidents.
In clinical use, an LLM should not be treated as a clinician. It should be treated as a probabilistic language and knowledge-support system whose output must be constrained, reviewed, and governed according to clinical risk.
Clinical\ Fluency \neq Clinical\ Validity
\]
Interpretation: A fluent clinical answer may still be incomplete, unsupported, outdated, unsafe, or inappropriate for a specific patient.
LLM deployment also raises documentation questions. If a model drafts a note, who verifies it? If it summarizes a record, what was omitted? If it answers a clinical question, what sources were retrieved? If it assists patient messaging, how are tone, safety, escalation, and liability handled? Clinical knowledge systems must preserve source traceability, human review, version history, and boundaries around patient-specific advice.
Privacy, Security, and Health Data Governance
Health AI depends on sensitive data. Patient records contain diagnoses, medications, images, notes, genetics, behavioral information, social context, family history, and identifiers. Clinical AI systems therefore require strong data governance: access control, minimization, de-identification where appropriate, audit logs, consent and authorization frameworks, retention policies, cybersecurity controls, and vendor oversight.
Privacy risk is not limited to raw data exposure. AI systems may leak information through model outputs, memorized text, prompt logs, retrieval systems, embeddings, tool calls, or improperly configured access permissions. Generative systems can also reintroduce sensitive information into summaries or messages. Retrieval-augmented systems can retrieve records the user should not see if permissions are not enforced at retrieval time.
Responsible health AI data governance should address:
- which data are used for training, validation, monitoring, and inference;
- whether data are identifiable, de-identified, limited, or synthetic;
- who has access to raw data, model outputs, prompts, logs, and audit trails;
- whether patient-facing uses are clearly disclosed;
- how third-party vendors handle data;
- how privacy incidents are detected and reported;
- how retrieval permissions are enforced;
- how model updates use new patient data.
Security is inseparable from privacy. Clinical AI systems may connect to EHRs, imaging archives, laboratory systems, scheduling systems, messaging platforms, device streams, cloud services, and third-party APIs. These connections create attack surfaces and access-control challenges. AI systems should be governed through least privilege, audit logs, role-based access, encryption, secure deployment, vendor review, incident response, and careful separation between clinical data and model-development environments.
Bias, Equity, and Patient Safety
Clinical AI can reproduce or amplify inequities in healthcare data. Historical records reflect unequal access, underdiagnosis, undertreatment, biased measurement, insurance differences, structural racism, language barriers, disability-related access barriers, and inconsistent documentation. A model trained on historical outcomes may learn patterns of past care rather than true clinical need.
Bias can appear in many places:
- training data that underrepresent certain populations;
- labels that reflect unequal diagnosis or access;
- features that proxy for socioeconomic status, race, disability, or insurance status;
- missingness patterns that differ across groups;
- devices that measure differently across skin tones or body types;
- thresholds that create unequal alert burden or missed cases;
- deployment contexts that lack resources to act on model outputs.
Fairness in clinical AI is not only a statistical question. A model can have similar error rates across groups but still worsen care if the recommended action is unavailable to some patients. Equity review must therefore examine data, performance, access, workflow, downstream interventions, patient outcomes, and institutional capacity.
Equity_{\mathrm{clinical}} = Performance + Access + Actionability + Outcome
\]
Interpretation: Clinical AI equity requires not only comparable model performance, but also comparable access to follow-up, treatment, explanation, and benefit.
Patient safety and equity should be treated together. A false negative may be especially harmful if it occurs in a population already facing barriers to care. A false positive may be especially burdensome if it triggers unnecessary testing, cost, anxiety, or stigma. A risk score may be inequitable if the intervention it triggers is less available in under-resourced settings. Clinical AI governance should ask who benefits, who is burdened, who is missed, who is over-alerted, and who has practical access to care after the model speaks.
Regulation, Device Status, and Change Control
Clinical AI may or may not be regulated as a medical device, depending on its intended use, function, users, claims, and regulatory jurisdiction. Some AI-enabled tools are software as a medical device. Some clinical decision support functions may fall outside device regulation under specific criteria. Some systems may be operational tools, administrative tools, research tools, or wellness tools. Regulatory classification is therefore not determined by the presence of AI alone.
In the United States, FDA maintains an AI-enabled medical device list and publishes guidance relevant to AI-enabled device software functions, clinical decision support software, software as a medical device, and predetermined change control plans. ONC’s HTI-1 rule also addresses transparency for predictive decision support interventions in certified health IT. Internationally, WHO has emphasized ethics and governance for AI and large multimodal models in health.
Change control is especially important for AI. A clinical model may be updated after deployment because data change, performance drifts, software improves, or the model is retrained. But in healthcare, an update can alter safety, effectiveness, bias, calibration, and workflow. Responsible change control should document what is changing, why it is changing, how it was validated, what risks were assessed, what monitoring is required, and how users will be informed.
Regulatory review should not be treated as the whole of clinical governance. A system may be legally deployable but still require local validation, workflow review, privacy assessment, equity analysis, clinician training, and monitoring. Conversely, an operational AI tool that falls outside device regulation may still create patient-safety, privacy, or equity risks. The institutional question is not only “Is this regulated?” but “What responsibility does this system create in this care environment?”
Monitoring, Drift, and Post-Deployment Surveillance
Clinical AI needs post-deployment monitoring because healthcare changes. New clinical guidelines, coding practices, devices, patient populations, documentation templates, staffing patterns, medications, disease prevalence, and treatment pathways can change model performance. Even if the model does not change, the environment does.
Clinical monitoring should track:
- input data quality and missingness;
- population and site drift;
- model output distribution;
- calibration and threshold behavior;
- sensitivity, specificity, false negatives, and false positives when labels arrive;
- performance by subgroup, site, device, and workflow;
- alert volume and alert fatigue;
- clinician overrides and edits;
- patient outcomes and unintended harms;
- incidents, complaints, and near misses;
- model version and change history.
Monitoring should be tied to action. If calibration worsens, the model may need recalibration. If a subgroup shows degraded performance, deployment may need restriction. If alert burden becomes excessive, thresholds or workflow may need redesign. If incidents occur, the system may need rollback, suspension, or regulatory reporting depending on context.
Monitoring \rightarrow Review \rightarrow Action
\]
Interpretation: Monitoring is only meaningful when performance signals, incidents, drift, and equity gaps trigger review, correction, recalibration, workflow change, or suspension.
Post-deployment surveillance should also include human feedback. Clinicians may notice when alerts are clinically irrelevant, when summaries omit important details, when patient messages are misrouted, or when a model behaves differently in a local context. Patients may notice misunderstanding, delays, confusing communication, or access barriers. Monitoring should preserve these signals as governance evidence, not treat them as anecdotal noise.
Clinical Governance and Institutional Accountability
Clinical AI governance should not be left only to data scientists or vendors. It requires clinicians, patients or patient advocates where appropriate, informaticians, safety officers, privacy officers, compliance teams, ethicists, IT teams, operational leaders, and model owners. Governance should decide which AI systems may be deployed, how they are validated, how they are monitored, and how concerns are escalated.
A responsible clinical AI governance program should document:
- intended use and prohibited use;
- clinical workflow and user group;
- model type, training data, and validation evidence;
- regulatory status and device determination;
- patient population and site applicability;
- performance, calibration, and uncertainty;
- bias and equity analysis;
- privacy and security controls;
- clinician training and user interface design;
- human oversight and override policy;
- monitoring and incident response;
- change control and retirement criteria;
- accountable owners and review cadence.
The purpose of governance is not to block innovation. It is to ensure that clinical AI improves care under real conditions, with evidence, transparency, oversight, and accountability.
Institutional accountability also means that responsibility cannot be outsourced entirely to vendors. A vendor may supply a model, platform, or documentation package, but the deploying institution determines the clinical context, workflow, users, thresholds, training, monitoring, and patient-facing consequences. The hospital, clinic, insurer, public-health agency, or health system remains responsible for how AI functions inside care.
Clinical governance should therefore include authority to approve, restrict, pause, modify, or retire AI systems. A committee that only reviews dashboards but cannot act is not enough. Governance must be connected to operational power: procurement decisions, deployment gates, model inventory, clinician training, incident response, privacy review, bias review, and patient-safety escalation.
Common Failure Modes
Clinical AI often fails not because the model has no signal, but because the surrounding clinical system is weak. A model may be statistically promising while the deployment is unsafe, inequitable, poorly monitored, or poorly integrated into care.
| Failure Mode | Description | Likely Consequence | Governance Response |
|---|---|---|---|
| Retrospective validation only | The system is validated on historical data but not evaluated in prospective workflow. | Model performance does not translate into safer or better care. | Require local validation, workflow testing, and outcome monitoring. |
| Poor calibration | Predicted probabilities do not match observed outcomes in deployment. | Clinicians may over- or under-react to risk estimates. | Monitor calibration, recalibrate where appropriate, and review thresholds. |
| Alert fatigue | The system generates too many low-value alerts. | Clinicians ignore alerts, and high-risk cases may be missed. | Track alert volume, false positives, response rates, and workflow burden. |
| Hidden subgroup harm | Aggregate metrics conceal poor performance for a patient group, site, device, or workflow. | Clinical AI worsens inequity or patient safety for specific populations. | Conduct subgroup review, equity analysis, and site-specific monitoring. |
| Automation bias | Clinicians over-trust AI output because it appears authoritative. | Errors are accepted without sufficient review. | Provide uncertainty, evidence, training, override pathways, and audit review. |
| Documentation hallucination | Generated clinical text includes false, omitted, or unsupported information. | Incorrect information enters the medical record or care plan. | Require clinician verification, source traceability, and documentation audits. |
| Uncontrolled model change | A model update changes behavior without adequate validation or communication. | Safety, fairness, or workflow changes go unnoticed. | Use change control, versioning, validation, user notification, and rollback criteria. |
Note: Clinical AI failures are often sociotechnical. They arise from the interaction of model behavior, workflow, data quality, clinician trust, patient context, governance, and institutional incentives.
Limits and Open Problems
AI in health, medicine, and clinical decision support has important limits. Retrospective validation is not enough: a model may perform well on historical data but fail in prospective clinical use. Accuracy is not clinical utility: performance metrics do not automatically imply improved patient outcomes. Calibration can drift as clinical practice, coding, devices, populations, or workflows change.
Bias can be hidden. Aggregate performance can conceal subgroup harms and unequal alert burden. Workflow can determine safety: a good model can become unsafe if placed in the wrong workflow. Large language models can sound clinically authoritative while being wrong, and fluency should not be confused with evidence. Clinical authority must remain clear because AI outputs should not obscure who is responsible for patient care.
Regulatory status is context-specific. The same algorithmic method may have different oversight requirements depending on intended use and claims. Some systems require formal regulatory review; others may be operational or administrative tools but still affect patient care indirectly. Institutions therefore need risk-based governance even where regulatory classification is uncertain or evolving.
Several open problems remain difficult. How should institutions evaluate adaptive or frequently updated models? How should they monitor foundation-model behavior when vendors update systems outside local control? How should patient consent, transparency, and explanation work for AI-enabled clinical workflows? How should health systems measure equity when race, ethnicity, language, disability, socioeconomic status, and access are recorded inconsistently? How should clinical AI be governed across fragmented care systems where no single institution controls all data, interventions, and outcomes?
The goal is not to reject AI in medicine. The goal is to treat clinical AI with the seriousness that patient care requires. AI can help clinicians see patterns, reduce burden, prioritize attention, and improve care. But it must be validated, monitored, constrained, and governed as part of a clinical system. In medicine, trustworthy AI is not only accurate. It is safe, equitable, accountable, privacy-preserving, clinically useful, and continuously reviewed.
Mathematical Lens
A clinical prediction model maps patient data to a risk estimate.
\hat{p}_i
=
P(Y_i=1 \mid X_i)
\]
Interpretation: For patient \(i\), the model estimates the probability of outcome \(Y_i\) given clinical features \(X_i\). The outcome may be deterioration, disease presence, readmission, adverse event, or another clinically defined endpoint.
Calibration asks whether predicted probabilities match observed outcomes.
P(Y=1 \mid \hat{p}=p) = p
\]
Interpretation: Among patients assigned predicted probability \(p\), the event should occur with frequency \(p\), assuming the validation population and clinical context match the intended use.
A threshold converts risk into action.
a_i
=
\begin{cases}
1, & \hat{p}_i \geq \tau \\
0, & \hat{p}_i < \tau
\end{cases}
\]
Interpretation: If predicted risk exceeds threshold \(\tau\), the system triggers an action such as alert, review, imaging prioritization, outreach, or escalation.
Clinical utility depends on benefits and harms, not only classification accuracy.
U
=
B_{TP}TP
–
C_{FP}FP
–
C_{FN}FN
–
C_{workflow}A
\]
Interpretation: Utility combines benefit from true positives, cost of false positives, cost of false negatives, and workflow cost from alerts or actions \(A\).
Fairness review compares performance across patient groups or clinical contexts.
\Delta_g
=
M_g
–
M_{ref}
\]
Interpretation: \(\Delta_g\) measures the difference between metric \(M_g\) for group \(g\) and a reference group or benchmark. Metrics may include sensitivity, specificity, calibration, false-negative rate, alert burden, or outcome improvement.
Clinical model drift can be represented as changing input, label, or outcome relationships.
D_{drift}
=
d(P_{train}(X,Y),P_{deploy}(X,Y))
\]
Interpretation: Drift measures the difference between training and deployment distributions. In medicine, drift can arise from new devices, documentation changes, treatment changes, coding changes, population shifts, seasonal illness, or workflow changes.
Clinical AI governance risk can combine model risk, clinical impact, uncertainty, equity risk, and workflow burden.
R_{clinical}
=
w_1 E
+
w_2 H
+
w_3 U_c
+
w_4 Q
+
w_5 W
+
w_6 G
\]
Interpretation: Clinical AI risk can combine error \(E\), harm severity \(H\), uncertainty \(U_c\), equity risk \(Q\), workflow burden \(W\), and governance gap \(G\), weighted by institutional priorities.
Variables and Clinical Interpretation
| Symbol or Term | Meaning | Clinical Interpretation | Governance Relevance |
|---|---|---|---|
| \(X_i\) | Patient features | Labs, notes, images, vitals, diagnoses, medications, demographics, device data. | Requires provenance, privacy, missingness review, and clinical validity. |
| \(Y_i\) | Outcome | Disease, deterioration, readmission, adverse event, diagnosis, response. | Must be clinically meaningful and accurately labeled. |
| \(\hat{p}_i\) | Predicted risk | Estimated probability for patient \(i\). | Should be calibrated and interpreted in context. |
| \(\tau\) | Decision threshold | Risk cutoff that triggers action. | Should reflect harm, benefit, capacity, equity, and workflow. |
| \(TP\) | True positives | Correctly identified patients who need action. | Supports benefit estimation. |
| \(FP\) | False positives | Patients incorrectly flagged. | Can create unnecessary testing, anxiety, workload, or intervention. |
| \(FN\) | False negatives | Patients missed by the system. | Can create safety harm if clinicians rely on the model. |
| \(M_g\) | Group-specific metric | Performance for a patient group, site, unit, device, or subgroup. | Supports fairness and local validation. |
| \(D_{drift}\) | Distribution drift | Deployment data differs from validation data. | Requires monitoring and possible recalibration or retraining. |
| \(R_{clinical}\) | Clinical AI governance risk | Composite risk of model use in care. | Guides review, deployment limits, and escalation. |
Note: Clinical AI metrics must be interpreted through patient safety, workflow, equity, uncertainty, clinical usefulness, and institutional accountability.
Worked Example: A Governed Clinical Decision Support System
Consider a hospital deploying an AI system to predict risk of clinical deterioration within the next twelve hours. The model uses vital signs, lab values, medications, nursing documentation, prior diagnoses, and recent clinical events. It generates a risk score and, above a threshold, triggers a review workflow for a rapid response or care team.
A governed deployment would include:
- Define intended use: early warning support, not autonomous diagnosis or treatment.
- Validate model performance on local data before deployment.
- Evaluate calibration and threshold behavior for the hospital’s patient population.
- Assess sensitivity, specificity, false-negative risk, and alert burden.
- Review performance across age, sex, race, ethnicity, language, disability, unit, and comorbidity groups where data are available and appropriate.
- Design the workflow: who receives alerts, what action is expected, and how escalation occurs.
- Train clinicians on interpretation, limitations, and override policy.
- Monitor alerts, overrides, delayed outcomes, model drift, subgroup performance, and incidents.
- Document model version, validation evidence, threshold policy, monitoring plan, and accountable owner.
- Define rollback and suspension criteria if the model creates harm, excessive alert burden, or performance degradation.
This example shows why clinical AI is not just model deployment. It is clinical system design.
If the model generates a risk score but there is no clear response pathway, the output may create ambiguity. If the response team lacks capacity, the alert may produce frustration or unsafe prioritization. If the threshold is set too low, false positives may overwhelm clinicians. If the threshold is set too high, deteriorating patients may be missed. If performance differs across language groups or units, the system may reproduce inequity. A governed system must therefore connect risk prediction to staffing, workflow, thresholds, review, monitoring, and patient outcomes.
Risk\ Score \rightarrow Clinical\ Review \rightarrow Action \rightarrow Outcome \rightarrow Monitoring
\]
Interpretation: A clinical AI system should link prediction to review, action, outcome measurement, and monitoring rather than treating the model score as an endpoint.
Computational Modeling
Computational modeling can make clinical AI governance more concrete. A validation workflow can estimate sensitivity, specificity, predictive value, calibration, alert burden, subgroup performance, and governance risk. A monitoring workflow can track model drift, threshold behavior, false negatives, false positives, clinician overrides, and patient outcomes. A governance workflow can identify cases or subgroups requiring additional review because of missing data, uncertainty, high-risk context, or equity concerns.
The examples below are intentionally educational and synthetic. They are not medical advice, not a clinical validation protocol, and not a substitute for local clinical, regulatory, privacy, safety, or statistical review. Their purpose is to show how clinical AI evaluation can move beyond aggregate accuracy toward calibration, threshold behavior, subgroup review, alert burden, and governance readiness.
A real clinical AI review would require appropriate data governance, expert statistical analysis, clinical validation, regulatory assessment, privacy review, human-factors evaluation, local workflow testing, patient-safety review, and post-deployment monitoring. The code here illustrates the structure of the evaluation problem; it does not validate any real clinical system.
Python Workflow: Clinical AI Validation, Bias, and Monitoring Review
The following Python workflow simulates clinical decision support predictions, computes performance, calibration, threshold utility, subgroup differences, alert burden, and governance risk. It is dependency-light so it can be adapted to validation logs, monitoring tables, and clinical governance review records.
"""
AI in Health, Medicine, and Clinical Decision Support
Python workflow:
- Simulate clinical decision support prediction logs.
- Evaluate model performance, calibration, subgroup differences,
alert burden, clinical utility, and governance risk.
- Produce governance-ready outputs for clinical AI review.
This workflow is educational and systems-focused. It is not medical advice,
not a clinical validation protocol, and not a substitute for local clinical,
regulatory, privacy, safety, or statistical review.
"""
from __future__ import annotations
from pathlib import Path
import numpy as np
import pandas as pd
ARTICLE_DIR = Path(__file__).resolve().parents[1] if "__file__" in globals() else Path(".")
OUTPUT_DIR = ARTICLE_DIR / "outputs"
OUTPUT_DIR.mkdir(parents=True, exist_ok=True)
RANDOM_SEED = 42
rng = np.random.default_rng(RANDOM_SEED)
def sigmoid(values: np.ndarray) -> np.ndarray:
"""Compute logistic sigmoid."""
return 1 / (1 + np.exp(-values))
def simulate_clinical_predictions(n: int = 5000) -> pd.DataFrame:
"""Create synthetic clinical prediction records for governance review."""
site = rng.choice(
["hospital_a", "hospital_b", "hospital_c"],
size=n,
p=[0.50, 0.32, 0.18],
)
unit = rng.choice(
["ward", "icu", "ed"],
size=n,
p=[0.58, 0.22, 0.20],
)
age_band = rng.choice(
["18_44", "45_64", "65_84", "85_plus"],
size=n,
p=[0.22, 0.34, 0.34, 0.10],
)
language_group = rng.choice(
["english", "non_english"],
size=n,
p=[0.82, 0.18],
)
vital_score = rng.normal(0, 1, n)
lab_score = rng.normal(0, 1, n)
comorbidity_score = rng.gamma(shape=2.0, scale=0.6, size=n)
missingness_score = rng.beta(a=1.2, b=6.0, size=n)
unit_shift = np.select(
[unit == "ward", unit == "icu", unit == "ed"],
[0.0, 0.9, 0.35],
default=0.0,
)
age_shift = np.select(
[
age_band == "18_44",
age_band == "45_64",
age_band == "65_84",
age_band == "85_plus",
],
[-0.35, 0.0, 0.45, 0.75],
default=0.0,
)
language_shift = np.where(language_group == "non_english", 0.18, 0.0)
site_shift = np.select(
[site == "hospital_a", site == "hospital_b", site == "hospital_c"],
[0.0, 0.15, -0.10],
default=0.0,
)
true_logit = (
0.90 * vital_score
+ 0.65 * lab_score
+ 0.55 * comorbidity_score
+ unit_shift
+ age_shift
+ language_shift
+ site_shift
- 2.45
)
true_probability = sigmoid(true_logit)
outcome = rng.binomial(1, true_probability)
# The model is imperfect and slightly under-adjusted for some context variables.
model_logit = (
0.82 * vital_score
+ 0.58 * lab_score
+ 0.48 * comorbidity_score
+ 0.72 * unit_shift
+ 0.35 * age_shift
+ 0.03 * language_shift
+ 0.05 * site_shift
- 2.10
+ rng.normal(0, 0.45, n)
)
predicted_probability = sigmoid(model_logit)
return pd.DataFrame(
{
"case_id": [f"CLIN-{i:05d}" for i in range(n)],
"site": site,
"unit": unit,
"age_band": age_band,
"language_group": language_group,
"vital_score": vital_score,
"lab_score": lab_score,
"comorbidity_score": comorbidity_score,
"missingness_score": missingness_score,
"true_probability": true_probability,
"predicted_probability": predicted_probability,
"outcome": outcome,
}
)
def binary_metrics(records: pd.DataFrame, threshold: float = 0.25) -> dict[str, float]:
"""Compute threshold-based clinical decision support metrics."""
y = records["outcome"].to_numpy()
p = records["predicted_probability"].to_numpy()
alerts = p >= threshold
tp = int(np.sum((alerts == 1) & (y == 1)))
fp = int(np.sum((alerts == 1) & (y == 0)))
tn = int(np.sum((alerts == 0) & (y == 0)))
fn = int(np.sum((alerts == 0) & (y == 1)))
sensitivity = tp / max(tp + fn, 1)
specificity = tn / max(tn + fp, 1)
ppv = tp / max(tp + fp, 1)
npv = tn / max(tn + fn, 1)
alert_rate = float(np.mean(alerts))
brier = float(np.mean((p - y) ** 2))
# Clinical utility proxy:
# benefit from true positives, penalties for false positives,
# false negatives, and alert burden.
utility = (
2.0 * tp
- 0.25 * fp
- 4.0 * fn
- 0.05 * np.sum(alerts)
) / len(records)
return {
"cases": len(records),
"threshold": threshold,
"true_positives": tp,
"false_positives": fp,
"true_negatives": tn,
"false_negatives": fn,
"sensitivity": sensitivity,
"specificity": specificity,
"positive_predictive_value": ppv,
"negative_predictive_value": npv,
"alert_rate": alert_rate,
"brier_score": brier,
"clinical_utility_proxy": utility,
}
def calibration_bins(records: pd.DataFrame, bins: int = 10) -> pd.DataFrame:
"""Compute bin-level calibration summary."""
data = records.copy()
data["risk_bin"] = pd.cut(
data["predicted_probability"],
bins=np.linspace(0, 1, bins + 1),
include_lowest=True,
)
grouped = (
data.groupby("risk_bin", observed=True)
.agg(
cases=("case_id", "count"),
mean_predicted_risk=("predicted_probability", "mean"),
observed_event_rate=("outcome", "mean"),
mean_missingness=("missingness_score", "mean"),
)
.reset_index()
)
grouped["absolute_calibration_gap"] = (
grouped["observed_event_rate"] - grouped["mean_predicted_risk"]
).abs()
grouped["weighted_calibration_gap"] = (
grouped["cases"] / grouped["cases"].sum()
) * grouped["absolute_calibration_gap"]
return grouped
def subgroup_review(records: pd.DataFrame, threshold: float = 0.25) -> pd.DataFrame:
"""Compute clinical decision support metrics by subgroup."""
rows = []
for column in ["site", "unit", "age_band", "language_group"]:
for value, subset in records.groupby(column):
metrics = binary_metrics(subset, threshold=threshold)
bins = calibration_bins(subset)
rows.append(
{
"subgroup_type": column,
"subgroup_value": value,
**metrics,
"expected_calibration_error": float(
bins["weighted_calibration_gap"].sum()
),
}
)
summary = pd.DataFrame(rows)
overall = binary_metrics(records, threshold=threshold)
overall_sensitivity = overall["sensitivity"]
overall_alert_rate = overall["alert_rate"]
summary["sensitivity_gap_from_overall"] = (
summary["sensitivity"] - overall_sensitivity
)
summary["alert_rate_gap_from_overall"] = (
summary["alert_rate"] - overall_alert_rate
)
summary["review_required"] = (
(summary["cases"] < 100)
| (summary["sensitivity_gap_from_overall"].abs() > 0.12)
| (summary["alert_rate_gap_from_overall"].abs() > 0.12)
| (summary["expected_calibration_error"] > 0.08)
| (summary["false_negatives"] > 20)
)
return summary.sort_values(
["review_required", "expected_calibration_error"],
ascending=[False, False],
)
def governance_risk(records: pd.DataFrame, threshold: float = 0.25) -> pd.DataFrame:
"""Score case-level governance risk for review routing."""
scored = records.copy()
scored["alert"] = scored["predicted_probability"] >= threshold
scored["uncertainty_zone"] = scored["predicted_probability"].between(
threshold - 0.05,
threshold + 0.05,
)
scored["clinical_ai_governance_risk"] = np.clip(
0.25 * scored["missingness_score"]
+ 0.25 * scored["uncertainty_zone"].astype(float)
+ 0.20 * (scored["unit"] == "icu").astype(float)
+ 0.15 * (scored["age_band"] == "85_plus").astype(float)
+ 0.15 * (scored["language_group"] == "non_english").astype(float),
0,
1,
)
scored["human_review_recommended"] = (
(scored["clinical_ai_governance_risk"] > 0.40)
| (scored["missingness_score"] > 0.35)
| (
scored["uncertainty_zone"]
& scored["unit"].isin(["icu", "ed"])
)
)
return scored.sort_values("clinical_ai_governance_risk", ascending=False)
def main() -> None:
"""Run clinical AI validation and governance review."""
threshold = 0.25
records = simulate_clinical_predictions()
overall_metrics = pd.DataFrame([binary_metrics(records, threshold=threshold)])
bins = calibration_bins(records)
subgroup_summary = subgroup_review(records, threshold=threshold)
scored = governance_risk(records, threshold=threshold)
governance_summary = pd.DataFrame(
[
{
"cases_reviewed": len(records),
"threshold": threshold,
"expected_calibration_error": float(
bins["weighted_calibration_gap"].sum()
),
"subgroups_requiring_review": int(
subgroup_summary["review_required"].sum()
),
"human_review_recommended_cases": int(
scored["human_review_recommended"].sum()
),
"mean_governance_risk": float(
scored["clinical_ai_governance_risk"].mean()
),
"max_governance_risk": float(
scored["clinical_ai_governance_risk"].max()
),
**overall_metrics.iloc[0].to_dict(),
}
]
)
records.to_csv(OUTPUT_DIR / "python_clinical_ai_prediction_logs.csv", index=False)
overall_metrics.to_csv(OUTPUT_DIR / "python_clinical_ai_overall_metrics.csv", index=False)
bins.to_csv(OUTPUT_DIR / "python_clinical_ai_calibration_bins.csv", index=False)
subgroup_summary.to_csv(OUTPUT_DIR / "python_clinical_ai_subgroup_review.csv", index=False)
scored.to_csv(OUTPUT_DIR / "python_clinical_ai_governance_scores.csv", index=False)
governance_summary.to_csv(OUTPUT_DIR / "python_clinical_ai_governance_summary.csv", index=False)
memo = f"""# Clinical AI Governance Memo
Cases reviewed: {int(governance_summary.loc[0, "cases_reviewed"])}
Decision threshold: {governance_summary.loc[0, "threshold"]:.2f}
Sensitivity: {governance_summary.loc[0, "sensitivity"]:.4f}
Specificity: {governance_summary.loc[0, "specificity"]:.4f}
Positive predictive value: {governance_summary.loc[0, "positive_predictive_value"]:.4f}
Negative predictive value: {governance_summary.loc[0, "negative_predictive_value"]:.4f}
Alert rate: {governance_summary.loc[0, "alert_rate"]:.4f}
Brier score: {governance_summary.loc[0, "brier_score"]:.4f}
Expected calibration error: {governance_summary.loc[0, "expected_calibration_error"]:.4f}
Subgroups requiring review: {int(governance_summary.loc[0, "subgroups_requiring_review"])}
Human-review recommended cases: {int(governance_summary.loc[0, "human_review_recommended_cases"])}
Mean governance risk: {governance_summary.loc[0, "mean_governance_risk"]:.4f}
Interpretation:
- Clinical AI should be evaluated beyond aggregate accuracy.
- Thresholds affect sensitivity, false negatives, false positives, and alert burden.
- Calibration and subgroup review are essential before and after deployment.
- Human review should be triggered by uncertainty, missingness, high-impact context, or equity concerns.
- This workflow is for systems analysis and does not provide medical advice.
"""
(OUTPUT_DIR / "python_clinical_ai_governance_memo.md").write_text(memo)
print(governance_summary.T)
print(subgroup_summary.head(20))
print(memo)
if __name__ == "__main__":
main()
This workflow illustrates why clinical AI review should not stop at aggregate performance. It examines threshold behavior, calibration, subgroup differences, alert burden, and governance-risk routing. In practice, the thresholds, weights, and review rules would need clinical, statistical, ethical, regulatory, and institutional review before use.
R Workflow: Clinical Decision Support Evaluation Summary
The following R workflow simulates clinical decision support records and summarizes model performance, alert burden, calibration proxy, subgroup gaps, human-review routing, and governance readiness.
# AI in Health, Medicine, and Clinical Decision Support
# R workflow: clinical decision support evaluation summary.
#
# Educational systems workflow only.
# Not medical advice and not a substitute for local clinical validation.
set.seed(42)
n <- 5000
threshold <- 0.25
site <- sample(
c("hospital_a", "hospital_b", "hospital_c"),
size = n,
replace = TRUE,
prob = c(0.50, 0.32, 0.18)
)
unit <- sample(
c("ward", "icu", "ed"),
size = n,
replace = TRUE,
prob = c(0.58, 0.22, 0.20)
)
age_band <- sample(
c("18_44", "45_64", "65_84", "85_plus"),
size = n,
replace = TRUE,
prob = c(0.22, 0.34, 0.34, 0.10)
)
language_group <- sample(
c("english", "non_english"),
size = n,
replace = TRUE,
prob = c(0.82, 0.18)
)
vital_score <- rnorm(n)
lab_score <- rnorm(n)
comorbidity_score <- rgamma(n, shape = 2.0, scale = 0.6)
missingness_score <- rbeta(n, shape1 = 1.2, shape2 = 6.0)
unit_shift <- ifelse(
unit == "ward",
0.0,
ifelse(unit == "icu", 0.9, 0.35)
)
age_shift <- ifelse(
age_band == "18_44",
-0.35,
ifelse(
age_band == "45_64",
0.0,
ifelse(age_band == "65_84", 0.45, 0.75)
)
)
language_shift <- ifelse(language_group == "non_english", 0.18, 0.0)
site_shift <- ifelse(
site == "hospital_a",
0.0,
ifelse(site == "hospital_b", 0.15, -0.10)
)
sigmoid <- function(x) {
1 / (1 + exp(-x))
}
true_logit <- 0.90 * vital_score +
0.65 * lab_score +
0.55 * comorbidity_score +
unit_shift +
age_shift +
language_shift +
site_shift -
2.45
true_probability <- sigmoid(true_logit)
outcome <- rbinom(n, size = 1, prob = true_probability)
model_logit <- 0.82 * vital_score +
0.58 * lab_score +
0.48 * comorbidity_score +
0.72 * unit_shift +
0.35 * age_shift +
0.03 * language_shift +
0.05 * site_shift -
2.10 +
rnorm(n, mean = 0, sd = 0.45)
predicted_probability <- sigmoid(model_logit)
records <- data.frame(
case_id = paste0("CLIN-", sprintf("%05d", 1:n)),
site = site,
unit = unit,
age_band = age_band,
language_group = language_group,
missingness_score = missingness_score,
true_probability = true_probability,
predicted_probability = predicted_probability,
outcome = outcome
)
records$alert <- records$predicted_probability >= threshold
records$uncertainty_zone <- records$predicted_probability >= (threshold - 0.05) &
records$predicted_probability <= (threshold + 0.05)
tp <- sum(records$alert == TRUE & records$outcome == 1)
fp <- sum(records$alert == TRUE & records$outcome == 0)
tn <- sum(records$alert == FALSE & records$outcome == 0)
fn <- sum(records$alert == FALSE & records$outcome == 1)
overall_metrics <- data.frame(
cases = nrow(records),
threshold = threshold,
true_positives = tp,
false_positives = fp,
true_negatives = tn,
false_negatives = fn,
sensitivity = tp / max(tp + fn, 1),
specificity = tn / max(tn + fp, 1),
positive_predictive_value = tp / max(tp + fp, 1),
negative_predictive_value = tn / max(tn + fn, 1),
alert_rate = mean(records$alert),
brier_score = mean((records$predicted_probability - records$outcome)^2)
)
records$risk_bin <- cut(
records$predicted_probability,
breaks = seq(0, 1, by = 0.1),
include.lowest = TRUE
)
calibration_bins <- aggregate(
cbind(predicted_probability, outcome, missingness_score) ~ risk_bin,
data = records,
FUN = mean
)
bin_counts <- aggregate(case_id ~ risk_bin, data = records, FUN = length)
names(bin_counts)[2] <- "cases"
calibration_bins <- merge(calibration_bins, bin_counts, by = "risk_bin")
names(calibration_bins)[2:4] <- c(
"mean_predicted_risk",
"observed_event_rate",
"mean_missingness"
)
calibration_bins$absolute_calibration_gap <- abs(
calibration_bins$observed_event_rate - calibration_bins$mean_predicted_risk
)
calibration_bins$weighted_calibration_gap <- (
calibration_bins$cases / sum(calibration_bins$cases)
) * calibration_bins$absolute_calibration_gap
expected_calibration_error <- sum(calibration_bins$weighted_calibration_gap)
summarize_group <- function(data, group_name) {
split_data <- split(data, data[[group_name]])
rows <- lapply(names(split_data), function(value) {
subset <- split_data[[value]]
tp_g <- sum(subset$alert == TRUE & subset$outcome == 1)
fp_g <- sum(subset$alert == TRUE & subset$outcome == 0)
tn_g <- sum(subset$alert == FALSE & subset$outcome == 0)
fn_g <- sum(subset$alert == FALSE & subset$outcome == 1)
data.frame(
subgroup_type = group_name,
subgroup_value = value,
cases = nrow(subset),
sensitivity = tp_g / max(tp_g + fn_g, 1),
specificity = tn_g / max(tn_g + fp_g, 1),
alert_rate = mean(subset$alert),
false_negatives = fn_g,
brier_score = mean((subset$predicted_probability - subset$outcome)^2)
)
})
do.call(rbind, rows)
}
subgroup_summary <- rbind(
summarize_group(records, "site"),
summarize_group(records, "unit"),
summarize_group(records, "age_band"),
summarize_group(records, "language_group")
)
subgroup_summary$sensitivity_gap_from_overall <-
subgroup_summary$sensitivity - overall_metrics$sensitivity
subgroup_summary$alert_rate_gap_from_overall <-
subgroup_summary$alert_rate - overall_metrics$alert_rate
subgroup_summary$review_required <-
abs(subgroup_summary$sensitivity_gap_from_overall) > 0.12 |
abs(subgroup_summary$alert_rate_gap_from_overall) > 0.12 |
subgroup_summary$false_negatives > 20 |
subgroup_summary$brier_score > 0.22
records$clinical_ai_governance_risk <- pmin(
1,
0.25 * records$missingness_score +
0.25 * as.numeric(records$uncertainty_zone) +
0.20 * as.numeric(records$unit == "icu") +
0.15 * as.numeric(records$age_band == "85_plus") +
0.15 * as.numeric(records$language_group == "non_english")
)
records$human_review_recommended <- records$clinical_ai_governance_risk > 0.40 |
records$missingness_score > 0.35 |
(records$uncertainty_zone & records$unit %in% c("icu", "ed"))
governance_summary <- data.frame(
cases_reviewed = nrow(records),
threshold = threshold,
expected_calibration_error = expected_calibration_error,
subgroups_requiring_review = sum(subgroup_summary$review_required),
human_review_recommended_cases = sum(records$human_review_recommended),
mean_governance_risk = mean(records$clinical_ai_governance_risk),
max_governance_risk = max(records$clinical_ai_governance_risk)
)
dir.create("outputs", recursive = TRUE, showWarnings = FALSE)
write.csv(records, "outputs/r_clinical_ai_prediction_logs.csv", row.names = FALSE)
write.csv(overall_metrics, "outputs/r_clinical_ai_overall_metrics.csv", row.names = FALSE)
write.csv(calibration_bins, "outputs/r_clinical_ai_calibration_bins.csv", row.names = FALSE)
write.csv(subgroup_summary, "outputs/r_clinical_ai_subgroup_review.csv", row.names = FALSE)
write.csv(governance_summary, "outputs/r_clinical_ai_governance_summary.csv", row.names = FALSE)
print("Overall metrics")
print(overall_metrics)
print("Calibration bins")
print(calibration_bins)
print("Subgroup summary")
print(subgroup_summary)
print("Governance summary")
print(governance_summary)
This R workflow mirrors the clinical evaluation structure in a lightweight form. It emphasizes that governance review should examine performance, alert burden, subgroup gaps, calibration proxies, and human-review routing together. Clinical AI evaluation should not treat model performance as separate from workflow, thresholds, safety, or equity.
GitHub Repository
The article body includes selected computational examples so the conceptual and mathematical argument remains readable. The full repository can hold expanded workflows for clinical AI validation, calibration review, decision-curve analysis, subgroup fairness review, monitoring, alert burden, privacy controls, regulatory status tracking, clinical workflow documentation, post-deployment surveillance, incident response, and governance templates.
The full code distribution for this article includes Python, R, SQL, Rust, Go, Julia, TypeScript, C++, documentation templates, and advanced notebooks for studying clinical AI validation, calibration, subgroup review, alert burden, privacy, regulation, monitoring, post-deployment surveillance, and accountable clinical governance.
From Model Performance to Clinical Responsibility
AI in health, medicine, and clinical decision support shows why responsible AI cannot be reduced to model performance. A high-performing model can still fail if it is poorly calibrated, deployed in the wrong workflow, insufficiently monitored, inequitable across patient groups, unclear in clinical authority, or disconnected from meaningful interventions. In medicine, the question is not simply whether AI predicts. The question is whether AI improves care.
The central lesson is that clinical AI must be governed as part of a care system. It must connect data, models, thresholds, workflow, clinician judgment, patient context, privacy, regulation, safety, equity, monitoring, and accountability. A prediction that cannot be acted on safely may not be useful. An alert that overwhelms clinicians may become harmful. A generated note that sounds fluent but contains error may damage the medical record. A model that performs well on average but fails for a subgroup may deepen inequity.
This article also shows why clinical AI requires humility. Medicine is uncertain. Data are incomplete. Patients are not interchangeable. Clinical workflows are complex. Institutions are constrained. AI can support clinicians, but it cannot eliminate the need for professional judgment, patient-centered care, and institutional responsibility. The strongest clinical AI systems will not replace the clinical system; they will strengthen its ability to see, decide, monitor, learn, and correct.
Within the Artificial Intelligence Systems knowledge series, this article belongs near Calibration, Uncertainty, and Probability in AI Systems, Model Monitoring, Drift, and AI Observability, Model Validation, Benchmarking, and Generalization Theory, AI, Expertise, and Human Judgment, Human Oversight, Contestability, and AI Accountability, Large Language Models and Foundation Model Systems, and AI Governance and Regulatory Systems. It provides the clinical layer for understanding how AI systems should support health, medicine, patient safety, and accountable care.
Related Articles
- Artificial Intelligence Systems
- Calibration, Uncertainty, and Probability in AI Systems
- Model Monitoring, Drift, and AI Observability
- Model Validation, Benchmarking, and Generalization Theory
- Robustness and Adversarial Resilience in Machine Learning
- Data Governance, Provenance, and Lineage in AI Systems
- Large Language Models and Foundation Model Systems
- Retrieval-Augmented Generation and AI Knowledge Systems
- Multimodal AI: Language, Vision, Audio, and Action
- AI Governance and Regulatory Systems
Further Reading
- U.S. Food and Drug Administration (2026) Artificial Intelligence-Enabled Medical Devices. Available at: https://www.fda.gov/medical-devices/software-medical-device-samd/artificial-intelligence-enabled-medical-devices
- U.S. Food and Drug Administration (2026) Clinical Decision Support Software: Guidance for Industry and Food and Drug Administration Staff. Available at: https://www.fda.gov/regulatory-information/search-fda-guidance-documents/clinical-decision-support-software
- U.S. Food and Drug Administration (2025) Marketing Submission Recommendations for a Predetermined Change Control Plan for Artificial Intelligence-Enabled Device Software Functions. Available at: https://www.fda.gov/regulatory-information/search-fda-guidance-documents/marketing-submission-recommendations-predetermined-change-control-plan-artificial-intelligence
- Office of the National Coordinator for Health Information Technology (2024) HTI-1 Final Rule. Available at: https://healthit.gov/regulations/hti-rules/hti-1-final-rule/
- World Health Organization (2024) Ethics and Governance of Artificial Intelligence for Health: Guidance on Large Multi-Modal Models. Available at: https://www.who.int/publications/i/item/9789240084759
- NIST (2023) Artificial Intelligence Risk Management Framework (AI RMF 1.0). Available at: https://www.nist.gov/itl/ai-risk-management-framework
References
- Office of the National Coordinator for Health Information Technology (2024) Health Data, Technology, and Interoperability: Certification Program Updates, Algorithm Transparency, and Information Sharing — HTI-1 Final Rule. Available at: https://healthit.gov/regulations/hti-rules/hti-1-final-rule/
- NIST (2023) Artificial Intelligence Risk Management Framework (AI RMF 1.0). Available at: https://www.nist.gov/publications/artificial-intelligence-risk-management-framework-ai-rmf-10
- U.S. Food and Drug Administration (2025) Artificial Intelligence in Software as a Medical Device. Available at: https://www.fda.gov/medical-devices/software-medical-device-samd/artificial-intelligence-software-medical-device
- U.S. Food and Drug Administration (2026) Artificial Intelligence-Enabled Medical Devices. Available at: https://www.fda.gov/medical-devices/software-medical-device-samd/artificial-intelligence-enabled-medical-devices
- U.S. Food and Drug Administration (2026) Clinical Decision Support Software: Guidance for Industry and Food and Drug Administration Staff. Available at: https://www.fda.gov/regulatory-information/search-fda-guidance-documents/clinical-decision-support-software
- U.S. Food and Drug Administration (2025) Marketing Submission Recommendations for a Predetermined Change Control Plan for Artificial Intelligence-Enabled Device Software Functions. Available at: https://www.fda.gov/regulatory-information/search-fda-guidance-documents/marketing-submission-recommendations-predetermined-change-control-plan-artificial-intelligence
- World Health Organization (2024) Ethics and Governance of Artificial Intelligence for Health: Guidance on Large Multi-Modal Models. Available at: https://www.who.int/publications/i/item/9789240084759