
Last Updated May 20, 2026
Heuristics are mental shortcuts that allow the mind to make judgments quickly under uncertainty, limited information, time pressure, and constrained cognitive capacity. In cognitive psychology, heuristics are not treated simply as careless mistakes or signs of defective reasoning. They are understood as efficient strategies that reduce complexity, conserve effort, and allow action when exhaustive analysis is impossible. These shortcuts often produce useful and adaptive judgments, but they can also generate systematic distortions known as cognitive biases.
Human cognition operates in environments where information is rarely complete and where decisions often must be made before full analysis is possible. Under those conditions, the mind frequently relies on approximate strategies rather than comprehensive calculation. Heuristics are part of that adaptive economy. They allow individuals to reach workable answers without comparing every option, estimating every probability, or evaluating every consequence in detail.
For that reason, heuristics are best understood as a trade-off between efficiency, accuracy, effort, time, and environmental fit. They reduce cognitive demand and support rapid judgment, but they may also produce recurring errors when the shortcut used does not match the structure of the problem. Understanding heuristics is therefore essential for explaining how people make decisions in everyday life, medicine, economics, law, public policy, technology, risk communication, and artificial intelligence. These processes are closely connected to attention, memory, working memory, cognitive load, and decision making.
Main Library
Publications
Article Map
Cognitive Psychology
Related Topic
Behavioral Economics
Related Topic
Artificial Intelligence Systems
Related Topic
Data Systems & Analytics
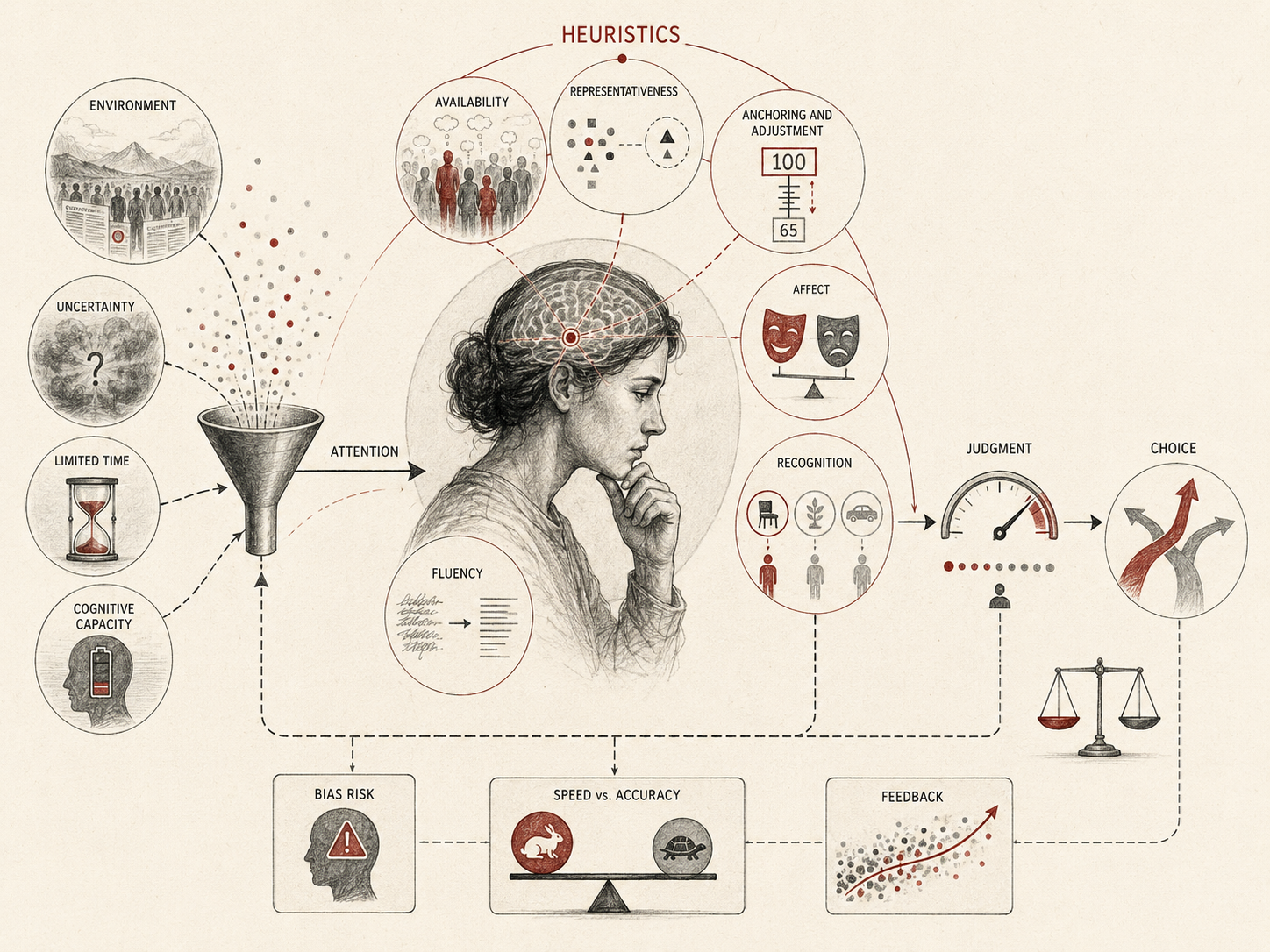
Heuristics matter because most real judgment occurs under conditions of constraint. People often lack complete information, reliable feedback, unlimited time, stable incentives, or enough cognitive capacity to evaluate every possible alternative. In those conditions, simplified strategies are not exceptions to cognition. They are part of ordinary cognition.
What are heuristics?
Heuristics are simplified strategies that allow individuals to make judgments quickly without performing full analytic calculation. Rather than evaluating every possible option or computing exact probabilities, heuristic reasoning uses rules of thumb that approximate a solution.
These shortcuts are especially useful when people face:
- limited time;
- incomplete information;
- complex problems with many variables;
- uncertain outcomes;
- high demands on attention and working memory;
- high information costs;
- rapidly changing environments;
- decisions where “good enough” action is more useful than slow optimization.
Although heuristics can sometimes lead to inaccurate conclusions, they are often effective enough for real-world purposes. Their importance lies not only in the mistakes they can generate, but in the fact that much everyday reasoning would be computationally unmanageable without them.
A heuristic is therefore not simply a cognitive defect. It is a strategy for navigating constraint. The same shortcut may be adaptive in one environment and misleading in another. A vivid memory may help someone avoid a genuine danger, or it may cause them to overestimate a rare event. Recognition may be informative when familiarity tracks real-world exposure, or misleading when visibility is shaped by advertising, media attention, or institutional power. Anchoring may provide a useful starting point when the anchor is informative, or distort judgment when the anchor is arbitrary.
This is why heuristic research must ask two questions at once: What shortcut is the mind using, and does that shortcut fit the structure of the environment?
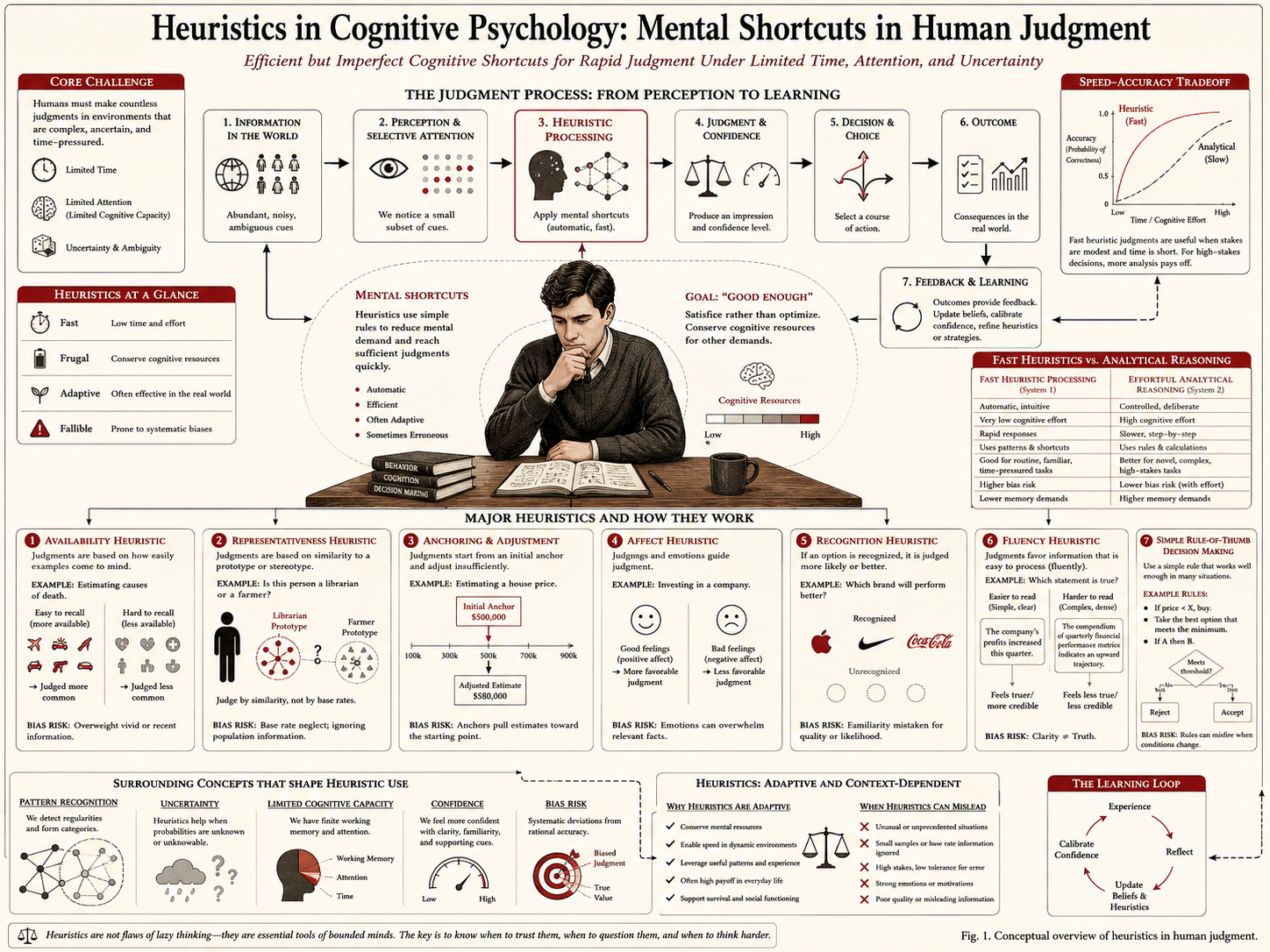
Origins of heuristic research
The scientific study of heuristics was strongly shaped by Amos Tversky and Daniel Kahneman in the 1970s. Their work showed that people often rely on intuitive shortcuts when making judgments about probability, frequency, risk, and uncertainty. This research program came to be known as the heuristics and biases framework. It challenged the classical assumption that people generally behave as fully rational decision makers who calculate according to formal probability and expected utility.
Tversky and Kahneman’s 1974 article identified several major heuristics, including representativeness, availability, and anchoring. Their central contribution was not simply that people make mistakes. It was that many judgment errors are structured, predictable, and tied to recurring cognitive strategies. That insight helped reshape psychology, economics, decision theory, medicine, legal reasoning, and behavioral economics.
The heuristics-and-biases tradition was especially powerful because it demonstrated systematic departures from formal models of rational judgment. People often neglect base rates when a case seems representative. They estimate frequency partly from ease of recall. They remain influenced by initial anchors even after adjustment. These effects are not random lapses. They reveal regular features of judgment under uncertainty.
At the same time, later traditions, especially those associated with Gerd Gigerenzer and the fast-and-frugal heuristics program, argued that heuristics should not be viewed only as sources of error. In some environments, simple heuristics can be surprisingly effective, sometimes outperforming more information-hungry procedures. This approach emphasizes ecological rationality: whether a heuristic fits the environment in which it is used.
The contemporary field therefore contains a productive tension. One tradition asks how heuristics produce bias relative to formal norms. Another asks how heuristics support adaptive judgment under real-world constraints. Both perspectives are necessary. Heuristics can mislead, and heuristics can help.
Major types of heuristics
Several heuristic strategies have been especially influential in cognitive psychology.
- Availability heuristic — judging probability or frequency by how easily examples come to mind.
- Representativeness heuristic — judging likelihood by similarity to a known pattern, category, stereotype, or prototype.
- Anchoring and adjustment — relying heavily on an initial value or reference point when making estimates.
- Recognition heuristic — inferring that a recognized option has a higher criterion value than an unrecognized option when recognition is correlated with the criterion.
- Fluency heuristic — treating information that is easier to process as more familiar, credible, likely, or preferable.
- Affect heuristic — using positive or negative feeling as a cue for risk, benefit, preference, or value.
- Take-the-best — searching cues in order of validity and stopping at the first cue that discriminates.
- Tallying — counting favorable cues without weighting them differentially.
- Satisficing — selecting an option that meets an acceptable threshold rather than optimizing over all alternatives.
Each of these heuristics simplifies a difficult reasoning task. When estimating the chance of an event, people may use recall ease rather than statistical frequency. When classifying a case, they may rely on resemblance rather than base rates. When estimating a numerical quantity, they may begin from an initial anchor and adjust insufficiently away from it. When choosing among uncertain options, they may inspect only one highly valid cue rather than weigh every possible cue.
These strategies reduce computational effort, which is part of why they are so common. But they can also produce recurring distortions when the shortcut used does not match the structure of the problem.
The key issue is not whether a heuristic is good or bad in the abstract. The key issue is whether the cue being used is valid, whether the environment is predictable, whether feedback is available, whether the stakes justify more analysis, and whether the shortcut is being used transparently or manipulated by others.
Formalizing heuristics: effort, accuracy, and approximation
Heuristics can be expressed formally as simplified decision procedures that trade information use for lower computational cost. Suppose a fully analytic judgment would require weighting all available cues \(x_1, x_2, \dots, x_n\) according to some function:
J^{*}=f(x_1,x_2,\dots,x_n)
\]
Interpretation: A fully analytic judgment \(J^{*}\) uses all relevant cues and combines them through a more complete decision function.
A heuristic instead uses a reduced subset of cues or a simpler transformation:
J_h=g(x_1,x_2,\dots,x_k),\qquad k<n
\]
Interpretation: A heuristic judgment \(J_h\) uses fewer cues than the full analytic procedure, reducing cognitive effort and information cost.
The choice between analytic and heuristic processing can be expressed as a trade-off between accuracy and effort:
U=A-\lambda E
\]
Interpretation: Overall utility \(U\) depends on expected accuracy \(A\), cognitive effort \(E\), and the weight \(\lambda\) placed on effort cost.
A heuristic becomes attractive whenever the marginal gain in accuracy from full analysis is smaller than the additional effort, time, or information cost required. This is central to Shah and Oppenheimer’s effort-reduction view of heuristics: shortcuts reduce cognitive work in several ways, including examining fewer cues, simplifying cue weighting, integrating less information, retrieving less knowledge, or stopping search earlier.
Availability can be represented by letting judged frequency depend on retrieval ease \(R\):
\hat{p}(\text{event})\propto R(\text{event})
\]
Interpretation: Events that are easier to recall may feel more probable, even when recall ease is driven by salience, recency, media exposure, or emotional vividness rather than true frequency.
Anchoring can be represented as:
\hat{x}=a+\delta
\]
Interpretation: The final estimate \(\hat{x}\) begins from an anchor \(a\) and adjusts by \(\delta\). Bias occurs when adjustment is insufficient.
Representativeness and base-rate use can be expressed as a weighted combination of similarity and prior probability:
\hat{p}(C\mid X)=\alpha S(X,C)+(1-\alpha)B(C)
\]
Interpretation: The judged probability that case \(X\) belongs to category \(C\) depends on similarity \(S(X,C)\), base rate \(B(C)\), and the weight \(\alpha\) placed on representativeness.
Fast-and-frugal heuristics can also be formalized as stopping rules. In take-the-best, cues are searched in order of validity, and the decision stops once a cue discriminates:
\text{choose } A \text{ if } c_j(A)>c_j(B) \text{ for the first discriminating cue } c_j
\]
Interpretation: The heuristic does not weigh all cues. It searches in a validity order and stops as soon as one cue distinguishes the alternatives.
These formalizations show why heuristics are researchable. They can be modeled as rules of cue selection, weighting, stopping, retrieval, adjustment, or affective substitution.
Why heuristics exist
Heuristics arise because cognition is limited. Full analysis of every decision would require far more time, information, attention, memory, and computation than real organisms usually possess. In many cases, the problem is not merely that people fail to reason optimally. The problem is that fully optimal reasoning is too expensive, too slow, or too demanding for the situation at hand.
From an adaptive perspective, heuristics make sense because they allow the mind to function under pressure. In environments where speed matters, where information is partial, or where decisions must be made repeatedly, a good-enough rule can be more useful than a theoretically ideal but practically unworkable solution.
Heuristics may reduce effort by:
- searching fewer cues;
- stopping once enough information has been gathered;
- using one strong cue instead of many weak cues;
- relying on memory retrieval rather than formal calculation;
- using affective response as a rapid value signal;
- ignoring unreliable or costly information;
- reducing the need for working-memory integration;
- substituting a simpler question for a harder question.
This is one reason heuristics should not be understood only as flaws. They are also strategies for managing complexity. A clinician under time pressure, a driver responding to traffic, a parent making a safety judgment, a worker navigating a confusing interface, or a voter trying to evaluate competing claims may all rely on heuristics because exhaustive analysis is unavailable.
The adaptive value of a heuristic depends on its environment. A recognition heuristic may work when recognition correlates with the criterion. Availability may be informative when memory reflects real exposure. Affect may be useful when emotional response carries learned information about danger. But those same heuristics can fail when the environment is distorted by advertising, sensational media, biased institutions, manipulation, unequal exposure, or misleading design.
Heuristics exist because the mind is finite. Whether they help or harm depends on how the shortcut fits the world.
Heuristics and cognitive bias
While heuristics often make efficient judgment possible, they can also produce systematic cognitive biases. These biases emerge when a shortcut that is usually useful is applied in a context where it leads the mind away from a more accurate conclusion.
For example, the availability heuristic can cause individuals to overestimate the likelihood of dramatic events that receive extensive media attention. Anchoring can distort numerical estimates even when the starting value is arbitrary. Representativeness can lead people to neglect base rates when a case strongly resembles a familiar stereotype. Fluency can make familiar or easy-to-process information feel more credible than it deserves to be.
These effects matter because they show that cognitive error is often structured rather than accidental. The study of bias therefore does not merely catalogue mistakes. It reveals the regular ways in which simplified reasoning interacts with complex environments.
Common bias patterns linked to heuristics include:
- Base-rate neglect — underweighting prior probabilities when a description seems representative.
- Availability bias — overestimating events that are vivid, recent, emotionally salient, or easy to recall.
- Anchoring bias — remaining too close to an initial value when making estimates.
- Framing effects — responding differently to equivalent information depending on presentation.
- Affect-driven risk distortion — judging risk and benefit through immediate emotional response.
- Fluency bias — treating easy-to-process information as more truthful, familiar, or valuable.
- Recognition bias — assuming that familiar options are better when recognition is not a valid cue.
Bias does not mean that the heuristic is always irrational. It means the shortcut has been used in an environment where it does not preserve the structure required for accurate judgment. The same process that helps in one setting may mislead in another.
A mature account of heuristic bias therefore requires both cognitive analysis and environmental analysis. The question is not only “What did the person do wrong?” It is also “What cues were available, how were they shaped, and why did this shortcut seem reasonable?”
Heuristics and bounded rationality
Heuristics are closely linked to the broader idea of bounded rationality. If perfect rationality assumes complete information, unlimited computation, and stable optimization, bounded rationality begins from the fact that real agents lack those conditions. Human decision makers operate under constraints of information, time, attention, memory, uncertainty, institutional pressure, and computational capacity.
Herbert Simon’s work challenged idealized models of rational economic man by emphasizing satisficing and decision making under real constraints. Rather than optimizing over every possible alternative, people often search until they find an option that is acceptable enough relative to their goals, thresholds, and available information. This is not a failure of cognition. It is a realistic response to constraint.
Heuristics can therefore be understood as tools of bounded rationality. They are not deviations from reasoning so much as one of the ways reasoning becomes possible under finite conditions.
This perspective helps explain why heuristics should be evaluated relative to environments. A shortcut that performs poorly in one domain may perform well in another. A simple rule may outperform a complex model when data are noisy, samples are small, cues are highly redundant, or rapid action is required.
Bounded rationality also shifts attention from the individual mind to the structure of the task. People do not bring unlimited resources to a problem. Systems, forms, interfaces, institutions, and policies must therefore be designed with actual human limits in view.
Ecological rationality and fast-and-frugal heuristics
The ecological rationality approach asks whether a heuristic is well matched to the structure of the environment. Rather than judging every shortcut against an idealized model of full information and optimization, this perspective studies how simple strategies perform under realistic constraints.
Fast-and-frugal heuristics are simple decision rules that use limited information, stop search early, and make decisions quickly. They are “fast” because they reduce time and computation. They are “frugal” because they use fewer cues. They can be surprisingly accurate when the environment contains cue structures that support them.
Examples include:
- Take-the-best — search cues by validity and stop at the first discriminating cue.
- Recognition heuristic — choose the recognized alternative when recognition validity is high.
- Tallying — count favorable cues without estimating weights.
- Fast-and-frugal trees — make sequential decisions using a small number of cues with early exits.
- Satisficing — choose the first option that crosses an acceptable threshold.
The point is not that these heuristics are always better than complex models. The point is that complexity is not automatically superior. When information is noisy, limited, costly, or overfit, simpler rules may generalize better.
Ecological rationality is therefore a corrective to a simplistic bias-only view. It asks how cognition, environment, and task structure fit together. A heuristic is rational when it works well for the environment and goals at hand, not merely when it resembles formal optimization.
Heuristics in risk perception and uncertainty
Heuristics are central to risk perception because risk judgments often require people to evaluate uncertain, emotionally charged, and incomplete information. In many real-world cases, people cannot directly observe probabilities, compare full datasets, or calculate expected values. They rely instead on available examples, emotional response, trust, familiarity, and perceived control.
The availability heuristic is especially important in risk perception. Events that are vivid, recent, memorable, or heavily covered by media may feel more likely than they are statistically. Conversely, common but less dramatic risks may be underestimated because they do not come easily to mind.
The affect heuristic also plays a major role. When people feel negatively about a hazard, they may judge its risk as high and its benefits as low. When they feel positively about an activity, they may judge its benefits as high and risks as low. This helps explain why risk and benefit judgments often move inversely, even when technical assessment is more complex.
But risk heuristics should not be dismissed as mere irrationality. People may rely on availability because memory reflects real exposure. A community repeatedly harmed by flooding, contamination, medical neglect, policing, or infrastructure failure may perceive risk vividly because the risk is real in their lived environment. Emotional response may encode histories of harm and institutional failure.
A serious account of risk heuristics therefore distinguishes between distorted probability judgment and situated knowledge. The question is not only whether a risk feels available. It is why it became available, whose experience is being counted, and whether formal models have ignored relevant exposure.
Heuristics and decision architecture
Heuristics matter for decision architecture because environments can either support good shortcuts or exploit bad ones. The way options are arranged, labeled, ordered, defaulted, framed, priced, timed, and visually emphasized can shape which heuristic people use.
Decision environments can influence judgment through:
- default options;
- anchoring values;
- choice order;
- salient examples;
- framing as gains or losses;
- social proof;
- scarcity cues;
- fluency and visual polish;
- risk comparisons;
- complexity and friction;
- interface timing and interruption.
In supportive design, these features help people make decisions that align with their goals. In manipulative design, they exploit predictable shortcuts for institutional benefit. This distinction is crucial in digital platforms, financial products, public-benefit systems, healthcare portals, legal forms, advertising, political communication, and AI interfaces.
Good decision architecture should reduce unnecessary cognitive load, make relevant information visible, preserve user agency, avoid deceptive anchoring, clarify uncertainty, and help users understand consequences. Bad decision architecture uses heuristics to obscure costs, hide alternatives, exaggerate urgency, or increase dependence.
Heuristic research therefore has ethical significance. It shows not only how minds simplify, but also how systems can shape simplification for good or for harm.
Neuroscience and dual-process accounts
Neuroscientific work suggests that heuristic reasoning involves interactions among several brain systems rather than a single “heuristic center.” Fast intuitive judgments are often associated with systems involved in salience, valuation, emotion, memory retrieval, and learned pattern recognition, while more effortful reasoning engages networks associated with cognitive control, working memory, conflict monitoring, and deliberate evaluation.
Dual-process accounts often distinguish between faster, more automatic, intuitive processes and slower, more effortful, reflective processes. This distinction can be useful, but it should not be made too rigid. Heuristic judgment is not simply emotional, irrational, or unintelligent. Many intuitive judgments reflect learned expertise, efficient pattern recognition, and adaptive experience.
Likewise, analytic reasoning is not automatically correct. Slow reasoning can still be biased if it begins from poor assumptions, unreliable data, motivated interpretation, or institutional blind spots. The real issue is coordination: when should a person rely on a shortcut, and when should the situation trigger more careful analysis?
Neuroscience and dual-process research therefore support a more nuanced view. Human judgment depends on multiple interacting systems. Heuristics are part of that architecture, not a separate defect outside it.
Heuristics, institutions, and power
Heuristics are often discussed as individual cognitive shortcuts, but institutions also rely on simplified rules. Schools, hospitals, courts, firms, platforms, agencies, financial systems, and governments all use categories, thresholds, proxies, risk scores, eligibility rules, checklists, defaults, and classification systems. These institutional heuristics can make large-scale coordination possible, but they can also create harm when simplified rules misrepresent complex human realities.
Institutional heuristics may appear through:
- risk scores used in policing, lending, insurance, or health systems;
- eligibility thresholds for public benefits;
- standardized categories that erase lived complexity;
- default assumptions about credibility or compliance;
- triage rules under scarcity;
- automated flags and fraud-detection proxies;
- bureaucratic checklists that substitute for judgment;
- performance metrics that become targets rather than indicators.
These institutional shortcuts are not necessarily wrong. Many systems require simplified procedures. But their consequences depend on what they simplify, whose experience they ignore, and whether affected people can contest the result.
This is especially important for marginalized communities. A rule that appears neutral may embed historical inequality. A proxy may reproduce unequal exposure. A default assumption may treat vulnerability as irresponsibility. A risk score may convert structural disadvantage into individual blame.
Heuristic research therefore connects cognitive psychology to institutional justice. It asks how simplified judgment works not only inside individual minds, but inside the systems that govern access, recognition, credibility, care, and accountability.
Heuristics and artificial intelligence systems
Artificial intelligence systems interact with human heuristics in several ways. Users may rely on fluency, authority cues, interface polish, anthropomorphic language, confidence scores, or automation as shortcuts for trust. A system that produces fluent output may be judged as more reliable than it is. A system that cites sources clearly may support better judgment. A system that hides uncertainty may encourage overreliance.
AI can also automate or formalize institutional heuristics. Classification models, recommender systems, fraud detection, triage tools, risk scores, content moderation systems, and decision-support systems all simplify complex situations into outputs that guide action. These outputs may be useful, but they can also obscure uncertainty, context, and contestability.
Human-AI interaction therefore requires attention to both human heuristics and machine heuristics. Users need to know:
- what information the system used;
- what uncertainty remains;
- what evidence supports the output;
- what assumptions shaped the result;
- where the system may fail;
- whether a score or recommendation is only a proxy;
- how to contest or verify the output;
- when human judgment should override automation.
Good AI design can reduce harmful heuristic reliance by making sources, limitations, uncertainty, and alternative interpretations visible. Poor AI design can exploit heuristics by making outputs feel authoritative, inevitable, or neutral when they are not.
The goal should not be to eliminate heuristics. It should be to design systems that support calibrated shortcuts, meaningful verification, and accountable judgment.
Heuristics in contemporary cognitive science
Contemporary heuristic research is no longer limited to the original heuristics-and-biases findings. The field now includes work on adaptive decision strategies, ecological rationality, effort reduction, risk perception, decision architecture, dual-process theories, computational modeling, human factors, behavioral economics, and artificial intelligence.
Several ongoing questions remain central:
- When do heuristics outperform complex models?
- When do they produce systematic bias?
- How do people select among heuristics?
- How does cognitive load increase reliance on shortcuts?
- How does prior knowledge transform heuristic judgment into expertise?
- How do institutions shape which shortcuts are available?
- How do digital systems manipulate anchoring, fluency, salience, and defaults?
- How should AI systems disclose uncertainty to avoid overreliance?
The strongest contemporary view treats heuristics neither as irrational defects nor as universally wise shortcuts. They are cognitive tools. Like all tools, their value depends on fit, use, context, design, and consequence.
Heuristics show that human intelligence is not merely a matter of calculation. It is also a matter of selective attention, memory, pattern recognition, learned experience, environmental structure, and practical constraint.
R code for heuristic-judgment data
The following R workflow illustrates analyses relevant to heuristic reasoning, including anchoring, availability, representativeness, base-rate use, recognition, fluency, affect, effort, bias magnitude, calibration error, response time, correctness, and adaptive fit.
# Install packages if needed:
# pak::pak(c("tidyverse", "lme4", "lmerTest", "emmeans", "broom.mixed"))
library(tidyverse)
library(lme4)
library(lmerTest)
library(emmeans)
library(broom.mixed)
# Expected columns:
# participant, condition, domain, trial, scenario_id, heuristic_type,
# anchor_value, adjustment, recall_ease, representativeness,
# base_rate, base_rate_use, recognition_strength, fluency,
# affective_valence, cue_validity, cue_count, information_cost,
# time_pressure, cognitive_load, strategy_complexity,
# subjective_effort, judged_probability, true_probability,
# estimate, true_value, choice_binary, correct, rt_ms,
# confidence, calibration_error, bias_magnitude, adaptive_fit
dat <- read_csv("heuristics_trials.csv") %>%
mutate(
participant = factor(participant),
condition = factor(condition),
domain = factor(domain),
scenario_id = factor(scenario_id),
heuristic_type = factor(heuristic_type),
choice_binary = as.integer(choice_binary),
correct = as.integer(correct),
log_rt = log(rt_ms)
)
# -----------------------------
# 1. Condition and heuristic summaries
# -----------------------------
condition_summary <- dat %>%
group_by(condition) %>%
summarise(
n_trials = n(),
participants = n_distinct(participant),
mean_judged_probability = mean(judged_probability, na.rm = TRUE),
mean_true_probability = mean(true_probability, na.rm = TRUE),
mean_estimate = mean(estimate, na.rm = TRUE),
mean_true_value = mean(true_value, na.rm = TRUE),
choice_rate = mean(choice_binary, na.rm = TRUE),
correct_rate = mean(correct, na.rm = TRUE),
mean_rt_ms = mean(rt_ms, na.rm = TRUE),
mean_confidence = mean(confidence, na.rm = TRUE),
mean_calibration_error = mean(calibration_error, na.rm = TRUE),
mean_bias_magnitude = mean(bias_magnitude, na.rm = TRUE),
mean_adaptive_fit = mean(adaptive_fit, na.rm = TRUE),
mean_effort = mean(subjective_effort, na.rm = TRUE),
mean_cue_count = mean(cue_count, na.rm = TRUE),
.groups = "drop"
)
print(condition_summary)
# -----------------------------
# 2. Anchoring effect
# -----------------------------
anchor_dat <- dat %>%
filter(condition %in% c("anchoring", "control", "analytic"))
anchor_model <- lmer(
estimate ~
anchor_value * condition +
true_value +
cognitive_load +
subjective_effort +
(1 + anchor_value | participant) +
(1 | scenario_id),
data = anchor_dat,
REML = FALSE
)
summary(anchor_model)
# -----------------------------
# 3. Availability effect
# -----------------------------
availability_dat <- dat %>%
filter(condition %in% c("availability", "control", "analytic"))
availability_model <- lmer(
judged_probability ~
recall_ease * condition +
true_probability +
affective_valence +
cognitive_load +
(1 + recall_ease | participant) +
(1 | scenario_id),
data = availability_dat,
REML = FALSE
)
summary(availability_model)
# -----------------------------
# 4. Representativeness and base-rate use
# -----------------------------
represent_dat <- dat %>%
filter(condition %in% c("representativeness", "control", "analytic"))
represent_model <- lmer(
judged_probability ~
representativeness * condition +
base_rate +
base_rate_use +
true_probability +
cognitive_load +
(1 + representativeness | participant) +
(1 | scenario_id),
data = represent_dat,
REML = FALSE
)
summary(represent_model)
# -----------------------------
# 5. Correct-choice model
# -----------------------------
correct_model <- glmer(
correct ~
condition +
domain +
heuristic_type +
cue_validity +
cue_count +
information_cost +
time_pressure +
cognitive_load +
strategy_complexity +
subjective_effort +
base_rate_use +
confidence +
(1 | participant) +
(1 | scenario_id),
data = dat,
family = binomial(),
control = glmerControl(optimizer = "bobyqa")
)
summary(correct_model)
emmeans(correct_model, ~ heuristic_type, type = "response")
# -----------------------------
# 6. Bias-magnitude model
# -----------------------------
bias_model <- lmer(
bias_magnitude ~
condition +
domain +
heuristic_type +
anchor_value +
recall_ease +
representativeness +
recognition_strength +
fluency +
affective_valence +
base_rate_use +
time_pressure +
cognitive_load +
subjective_effort +
(1 | participant) +
(1 | scenario_id),
data = dat,
REML = FALSE
)
summary(bias_model)
# -----------------------------
# 7. Calibration-error model
# -----------------------------
calibration_model <- lmer(
calibration_error ~
condition +
domain +
heuristic_type +
recall_ease +
representativeness +
base_rate_use +
cue_validity +
cognitive_load +
confidence +
(1 | participant) +
(1 | scenario_id),
data = dat,
REML = FALSE
)
summary(calibration_model)
# -----------------------------
# 8. Response-time model
# -----------------------------
rt_model <- lmer(
log_rt ~
condition +
domain +
heuristic_type +
cue_count +
information_cost +
time_pressure +
cognitive_load +
strategy_complexity +
subjective_effort +
correct +
(1 | participant) +
(1 | scenario_id),
data = dat,
REML = FALSE
)
summary(rt_model)
# -----------------------------
# 9. Adaptive-fit model
# -----------------------------
adaptive_model <- lmer(
adaptive_fit ~
condition +
domain +
heuristic_type +
cue_validity +
cue_count +
information_cost +
time_pressure +
cognitive_load +
strategy_complexity +
(1 | participant) +
(1 | scenario_id),
data = dat,
REML = FALSE
)
summary(adaptive_model)
# -----------------------------
# 10. Visualization
# -----------------------------
ggplot(dat, aes(x = anchor_value, y = estimate, color = condition)) +
geom_point(alpha = 0.25) +
geom_smooth(method = "lm", se = FALSE) +
labs(
title = "Anchoring and judgment estimates",
x = "Anchor value",
y = "Estimate"
) +
theme_minimal()This workflow can be adapted for anchoring experiments, availability studies, representativeness and base-rate experiments, recognition-heuristic tasks, fluency manipulations, affect-heuristic research, fast-and-frugal strategy comparisons, risk-perception studies, HCI decision-support experiments, and human-AI reliance research. Researchers should model participant and scenario effects whenever possible because heuristic use varies across individuals, tasks, cues, domains, and environmental structures.
Python code for heuristic-judgment data
The Python examples below parallel the R workflow and are useful for anchoring experiments, availability effects, representativeness and base-rate studies, recognition and fluency research, and strategy-comparison experiments.
import numpy as np
import pandas as pd
import statsmodels.formula.api as smf
import statsmodels.api as sm
import matplotlib.pyplot as plt
# Expected columns:
# participant, condition, domain, trial, scenario_id, heuristic_type,
# anchor_value, adjustment, recall_ease, representativeness,
# base_rate, base_rate_use, recognition_strength, fluency,
# affective_valence, cue_validity, cue_count, information_cost,
# time_pressure, cognitive_load, strategy_complexity,
# subjective_effort, judged_probability, true_probability,
# estimate, true_value, choice_binary, correct, rt_ms,
# confidence, calibration_error, bias_magnitude, adaptive_fit
df = pd.read_csv("heuristics_trials.csv")
categorical_cols = ["participant", "condition", "domain", "scenario_id", "heuristic_type"]
for col in categorical_cols:
df[col] = df[col].astype("category")
df["choice_binary"] = df["choice_binary"].astype(int)
df["correct"] = df["correct"].astype(int)
df["log_rt"] = np.log(df["rt_ms"])
# -----------------------------
# 1. Condition profile
# -----------------------------
condition_summary = (
df.groupby("condition", observed=True)
.agg(
n_trials=("correct", "size"),
participants=("participant", "nunique"),
mean_judged_probability=("judged_probability", "mean"),
mean_true_probability=("true_probability", "mean"),
mean_estimate=("estimate", "mean"),
mean_true_value=("true_value", "mean"),
choice_rate=("choice_binary", "mean"),
correct_rate=("correct", "mean"),
mean_rt_ms=("rt_ms", "mean"),
mean_confidence=("confidence", "mean"),
mean_calibration_error=("calibration_error", "mean"),
mean_bias_magnitude=("bias_magnitude", "mean"),
mean_adaptive_fit=("adaptive_fit", "mean"),
mean_effort=("subjective_effort", "mean"),
mean_cue_count=("cue_count", "mean"),
)
.reset_index()
)
print(condition_summary)
# -----------------------------
# 2. Anchoring effect
# -----------------------------
anchor_df = df[df["condition"].isin(["anchoring", "control", "analytic"])].copy()
anchor_model = smf.ols(
"estimate ~ anchor_value * condition + true_value "
"+ cognitive_load + subjective_effort",
data=anchor_df,
)
anchor_result = anchor_model.fit(
cov_type="cluster",
cov_kwds={"groups": anchor_df["participant"]},
)
print(anchor_result.summary())
# -----------------------------
# 3. Availability effect
# -----------------------------
availability_df = df[df["condition"].isin(["availability", "control", "analytic"])].copy()
availability_model = smf.ols(
"judged_probability ~ recall_ease * condition "
"+ true_probability + affective_valence + cognitive_load",
data=availability_df,
)
availability_result = availability_model.fit(
cov_type="cluster",
cov_kwds={"groups": availability_df["participant"]},
)
print(availability_result.summary())
# -----------------------------
# 4. Representativeness and base-rate use
# -----------------------------
represent_df = df[df["condition"].isin(["representativeness", "control", "analytic"])].copy()
represent_model = smf.ols(
"judged_probability ~ representativeness * condition "
"+ base_rate + base_rate_use + true_probability + cognitive_load",
data=represent_df,
)
represent_result = represent_model.fit(
cov_type="cluster",
cov_kwds={"groups": represent_df["participant"]},
)
print(represent_result.summary())
# -----------------------------
# 5. Correct-choice model
# -----------------------------
correct_model = smf.glm(
"correct ~ condition + domain + heuristic_type "
"+ cue_validity + cue_count + information_cost "
"+ time_pressure + cognitive_load + strategy_complexity "
"+ subjective_effort + base_rate_use + confidence",
data=df,
family=sm.families.Binomial(),
)
correct_result = correct_model.fit(
cov_type="cluster",
cov_kwds={"groups": df["participant"]},
)
print(correct_result.summary())
# -----------------------------
# 6. Bias-magnitude model
# -----------------------------
bias_model = smf.ols(
"bias_magnitude ~ condition + domain + heuristic_type "
"+ anchor_value + recall_ease + representativeness "
"+ recognition_strength + fluency + affective_valence "
"+ base_rate_use + time_pressure + cognitive_load "
"+ subjective_effort",
data=df,
)
bias_result = bias_model.fit(
cov_type="cluster",
cov_kwds={"groups": df["participant"]},
)
print(bias_result.summary())
# -----------------------------
# 7. Calibration-error model
# -----------------------------
calibration_model = smf.ols(
"calibration_error ~ condition + domain + heuristic_type "
"+ recall_ease + representativeness + base_rate_use "
"+ cue_validity + cognitive_load + confidence",
data=df,
)
calibration_result = calibration_model.fit(
cov_type="cluster",
cov_kwds={"groups": df["participant"]},
)
print(calibration_result.summary())
# -----------------------------
# 8. Response-time model
# -----------------------------
rt_model = smf.ols(
"log_rt ~ condition + domain + heuristic_type "
"+ cue_count + information_cost + time_pressure "
"+ cognitive_load + strategy_complexity + subjective_effort "
"+ correct",
data=df,
)
rt_result = rt_model.fit(
cov_type="cluster",
cov_kwds={"groups": df["participant"]},
)
print(rt_result.summary())
# -----------------------------
# 9. Adaptive-fit model
# -----------------------------
adaptive_model = smf.ols(
"adaptive_fit ~ condition + domain + heuristic_type "
"+ cue_validity + cue_count + information_cost "
"+ time_pressure + cognitive_load + strategy_complexity",
data=df,
)
adaptive_result = adaptive_model.fit(
cov_type="cluster",
cov_kwds={"groups": df["participant"]},
)
print(adaptive_result.summary())
# -----------------------------
# 10. Visualization
# -----------------------------
fig, ax = plt.subplots(figsize=(8, 5))
for condition, group in df.groupby("condition", observed=True):
ax.scatter(
group["anchor_value"],
group["estimate"],
alpha=0.35,
label=str(condition),
)
ax.set_xlabel("Anchor value")
ax.set_ylabel("Estimate")
ax.set_title("Anchoring and judgment estimates")
ax.legend(title="Condition")
plt.tight_layout()
plt.show()
# -----------------------------
# 11. Export summaries
# -----------------------------
condition_summary.to_csv("heuristics_condition_summary.csv", index=False)The Python workflow is intentionally transparent and extensible. It can be expanded with Bayesian hierarchical models, process-tracing data, mouse-tracking, eye-tracking, cue-search logs, drift-diffusion models, strategy-classification models, fast-and-frugal tree simulations, ecological-rationality benchmarks, adaptive strategy selection, and human-AI reliance experiments.
GitHub Repository
The companion repository provides reusable code and research scaffolding for studying heuristics in cognitive psychology, including workflows for anchoring, availability, representativeness, recognition, fluency, affect, take-the-best, tallying, satisficing, effort reduction, strategy complexity, response time, bias magnitude, calibration error, adaptive fit, and ecological rationality.
Complete Code Repository
Access the full companion repository for this article, including reproducible analysis materials and multi-language code workflows for heuristic-judgment research.
Applications of heuristic research
Understanding heuristics has influenced many applied fields. In economics, it contributed to behavioral economics by demonstrating that real choice often departs from idealized rational models. In medicine, awareness of heuristic bias can help reduce diagnostic error. In public policy, it informs the design of decision environments that help individuals make better choices. In law, finance, risk communication, organizational analysis, and AI governance, it helps explain predictable distortions in judgment under uncertainty and pressure.
In healthcare, heuristics shape diagnosis, triage, risk communication, and treatment decisions. Some shortcuts help clinicians recognize patterns quickly. Others may contribute to premature closure, availability bias, or representativeness-driven misclassification.
In finance, anchoring, loss framing, availability, social proof, and fluency affect investment decisions, risk tolerance, debt behavior, and consumer choices. In legal contexts, representativeness, anchoring, credibility cues, and narrative coherence can shape judgments about responsibility, evidence, and probability.
In public policy, heuristic research helps explain why people respond differently to equivalent information depending on framing, salience, trust, and perceived control. In interface design, it shows why defaults, labels, visual hierarchy, timing, and choice order matter.
In artificial intelligence, heuristic research is increasingly important because users rely on shortcuts when interpreting machine outputs. Fluency, confidence scores, source visibility, interface polish, and automation authority all affect how people judge AI systems.
These applications matter because heuristic reasoning is not confined to laboratory tasks. It is woven into everyday choice, institutional judgment, and large-scale social systems.
Conclusion
Heuristics allow the mind to navigate complex environments by simplifying judgment under uncertainty. These mental shortcuts reduce effort and make rapid decisions possible when information is incomplete, time is limited, and full analysis is impractical.
Although heuristics can produce cognitive biases, they are not simply flaws in reasoning. They are part of the adaptive economy of thought. Understanding how they work provides insight into both the strengths and the limits of human judgment, and it helps connect cognitive psychology to economics, public policy, medicine, law, organizational behavior, human-computer interaction, and artificial intelligence.
The central lesson is that human judgment is neither pure calculation nor mere error. It is bounded, selective, adaptive, and context-sensitive. Heuristics show how minds make the world manageable — and why the design of environments matters so much for whether that simplification supports good judgment or produces systematic harm.
Related articles
- Cognitive Psychology
- Decision Making in Cognitive Psychology
- Cognitive Biases in Decision Making
- Risk Perception and Uncertainty
- Mental Models in Cognitive Psychology
- Cognitive Load and Information Processing
- Attention in Cognitive Psychology
- Memory in Cognitive Psychology
- Behavioral Economics
Further reading
- American Psychological Association (n.d.) Heuristic. APA Dictionary of Psychology. Available at: https://dictionary.apa.org/heuristic.
- Gigerenzer, G. (2007) Gut Feelings: The Intelligence of the Unconscious. New York: Viking.
- Gigerenzer, G. and Gaissmaier, W. (2011) ‘Heuristic decision making’, Annual Review of Psychology, 62, pp. 451–482. Available at: https://www.annualreviews.org/doi/10.1146/annurev-psych-120709-145346.
- Gigerenzer, G., Todd, P.M. and the ABC Research Group (1999) Simple Heuristics That Make Us Smart. Oxford: Oxford University Press. Available at: https://global.oup.com/academic/product/simple-heuristics-that-make-us-smart-9780195143812.
- Kahneman, D. (2011) Thinking, Fast and Slow. New York: Farrar, Straus and Giroux.
- Newell, B.R., Lagnado, D.A. and Shanks, D.R. (2015) Straight Choices: The Psychology of Decision Making. 2nd edn. London: Psychology Press.
- Pachur, T., Hertwig, R. and Steinmann, F. (2012) ‘How do people judge risks: Availability heuristic, affect heuristic, or both?’, Journal of Experimental Psychology: Applied, 18(3), pp. 314–330. Available at: https://psycnet.apa.org/record/2012-21656-001.
- Payne, J.W., Bettman, J.R. and Johnson, E.J. (1993) The Adaptive Decision Maker. Cambridge: Cambridge University Press. Available at: https://www.cambridge.org/core/books/adaptive-decision-maker/C2F0579B685EC397059F5D386E7B2045.
- Shah, A.K. and Oppenheimer, D.M. (2008) ‘Heuristics made easy: An effort-reduction framework’, Psychological Bulletin, 134(2), pp. 207–222. Available at: https://psycnet.apa.org/record/2008-02854-001.
- Simon, H.A. (1957) Models of Man: Social and Rational. New York: Wiley.
- Slovic, P., Finucane, M.L., Peters, E. and MacGregor, D.G. (2007) ‘The affect heuristic’, European Journal of Operational Research, 177(3), pp. 1333–1352. Available at: https://www.sciencedirect.com/science/article/abs/pii/S0377221705003577.
- Stanovich, K.E. and West, R.F. (2000) ‘Individual differences in reasoning: Implications for the rationality debate?’, Behavioral and Brain Sciences, 23(5), pp. 645–665. Available at: https://www.cambridge.org/core/journals/behavioral-and-brain-sciences/article/individual-differences-in-reasoning-implications-for-the-rationality-debate/5A390F26633336BB37F76D0B49418B37.
- Todd, P.M. and Gigerenzer, G. (2000) ‘Précis of Simple Heuristics That Make Us Smart’, Behavioral and Brain Sciences, 23(5), pp. 727–741. Available at: https://www.cambridge.org/core/journals/behavioral-and-brain-sciences/article/precis-of-simple-heuristics-that-make-us-smart/9D0AA736C5E23AE49010B5985F3287D8.
- Tversky, A. and Kahneman, D. (1974) ‘Judgment under uncertainty: Heuristics and biases’, Science, 185(4157), pp. 1124–1131. Available at: https://www.science.org/doi/10.1126/science.185.4157.1124.
- Wheeler, G. (2018) ‘Bounded rationality’, Stanford Encyclopedia of Philosophy. Available at: https://plato.stanford.edu/entries/bounded-rationality/.
References
- American Psychological Association (n.d.) Heuristic. APA Dictionary of Psychology. Available at: https://dictionary.apa.org/heuristic.
- Gigerenzer, G. (2007) Gut Feelings: The Intelligence of the Unconscious. New York: Viking.
- Gigerenzer, G. and Gaissmaier, W. (2011) ‘Heuristic decision making’, Annual Review of Psychology, 62, pp. 451–482. Available at: https://www.annualreviews.org/doi/10.1146/annurev-psych-120709-145346.
- Gigerenzer, G., Todd, P.M. and the ABC Research Group (1999) Simple Heuristics That Make Us Smart. Oxford: Oxford University Press. Available at: https://global.oup.com/academic/product/simple-heuristics-that-make-us-smart-9780195143812.
- Kahneman, D. (2011) Thinking, Fast and Slow. New York: Farrar, Straus and Giroux.
- Newell, B.R., Lagnado, D.A. and Shanks, D.R. (2015) Straight Choices: The Psychology of Decision Making. 2nd edn. London: Psychology Press.
- Pachur, T., Hertwig, R. and Steinmann, F. (2012) ‘How do people judge risks: Availability heuristic, affect heuristic, or both?’, Journal of Experimental Psychology: Applied, 18(3), pp. 314–330. Available at: https://psycnet.apa.org/record/2012-21656-001.
- Payne, J.W., Bettman, J.R. and Johnson, E.J. (1993) The Adaptive Decision Maker. Cambridge: Cambridge University Press. Available at: https://www.cambridge.org/core/books/adaptive-decision-maker/C2F0579B685EC397059F5D386E7B2045.
- Shah, A.K. and Oppenheimer, D.M. (2008) ‘Heuristics made easy: An effort-reduction framework’, Psychological Bulletin, 134(2), pp. 207–222. Available at: https://psycnet.apa.org/record/2008-02854-001.
- Simon, H.A. (1957) Models of Man: Social and Rational. New York: Wiley.
- Slovic, P., Finucane, M.L., Peters, E. and MacGregor, D.G. (2007) ‘The affect heuristic’, European Journal of Operational Research, 177(3), pp. 1333–1352. Available at: https://www.sciencedirect.com/science/article/abs/pii/S0377221705003577.
- Stanovich, K.E. and West, R.F. (2000) ‘Individual differences in reasoning: Implications for the rationality debate?’, Behavioral and Brain Sciences, 23(5), pp. 645–665. Available at: https://www.cambridge.org/core/journals/behavioral-and-brain-sciences/article/individual-differences-in-reasoning-implications-for-the-rationality-debate/5A390F26633336BB37F76D0B49418B37.
- Todd, P.M. and Gigerenzer, G. (2000) ‘Précis of Simple Heuristics That Make Us Smart’, Behavioral and Brain Sciences, 23(5), pp. 727–741. Available at: https://www.cambridge.org/core/journals/behavioral-and-brain-sciences/article/precis-of-simple-heuristics-that-make-us-smart/9D0AA736C5E23AE49010B5985F3287D8.
- Tversky, A. and Kahneman, D. (1974) ‘Judgment under uncertainty: Heuristics and biases’, Science, 185(4157), pp. 1124–1131. Available at: https://www.science.org/doi/10.1126/science.185.4157.1124.
- Wheeler, G. (2018) ‘Bounded rationality’, Stanford Encyclopedia of Philosophy. Available at: https://plato.stanford.edu/entries/bounded-rationality/.