
Last Updated May 10, 2026
AI safety and system reliability concern the design, deployment, monitoring, and governance of artificial intelligence systems so they operate predictably, robustly, and responsibly under real-world conditions. Safety is not merely the absence of visible errors, and reliability is not simply high benchmark performance. In deployed AI systems, safety is a lifecycle property produced by the interaction of models, data pipelines, infrastructure, human oversight, organizational incentives, security controls, feedback loops, and governance mechanisms.
The central argument of this article is that AI safety should be understood as a theory of governed reliability. A safe AI system is not simply a trained model with acceptable accuracy. It is a monitored, tested, documented, constrained, recoverable, auditable, and accountable system whose behavior can be evaluated across normal use, foreseeable misuse, distributional shift, adversarial pressure, institutional over-trust, and failure scenarios.
Main Library
Publications
Article Map
Artificial Intelligence Systems
Related Topic
Data Systems & Analytics
Related Topic
Embedded & Edge Systems
Related Topic
Intelligent Infrastructure Systems
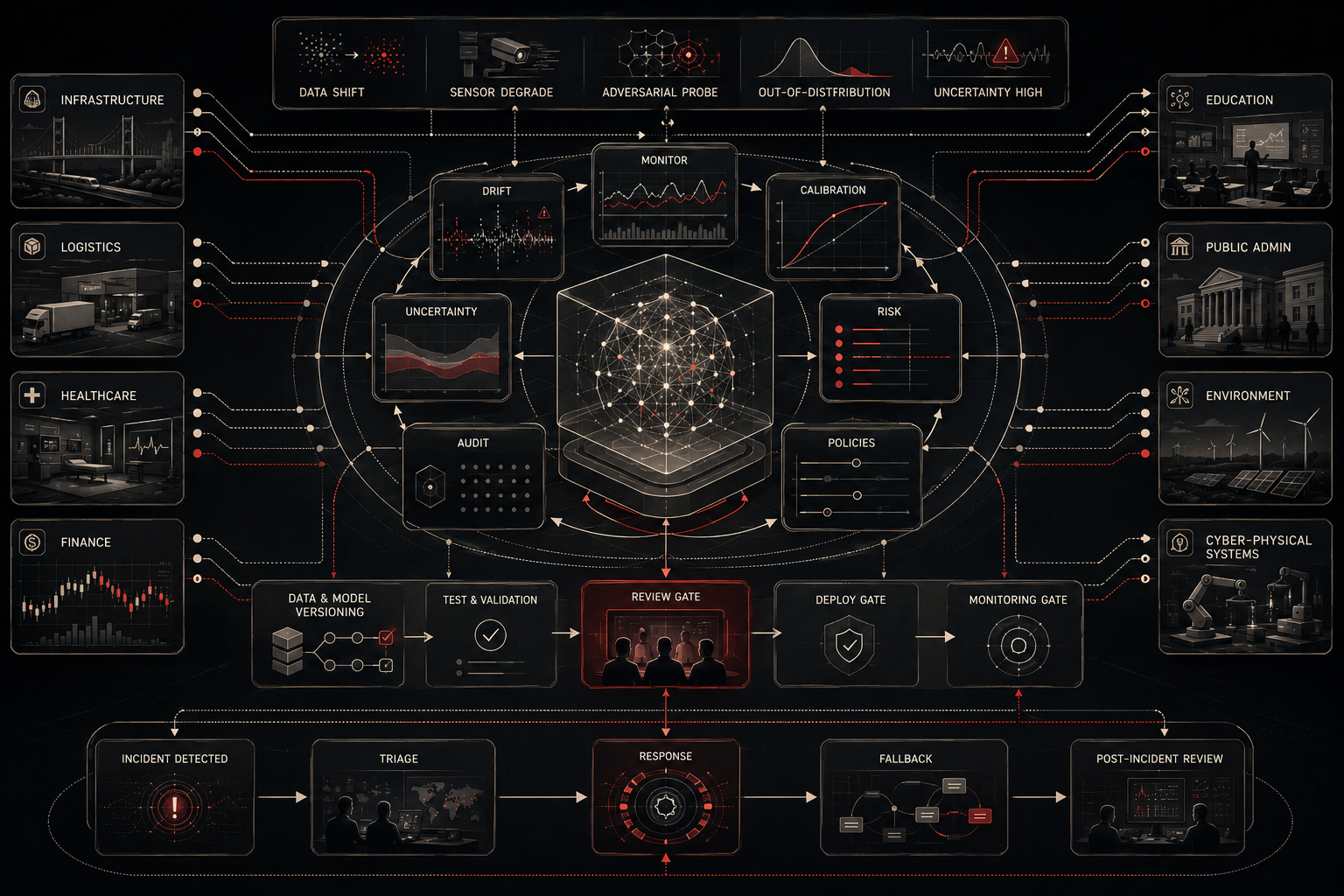
As artificial intelligence becomes embedded in decision support, infrastructure management, scientific workflows, financial systems, medical triage, education, logistics, public administration, and cyber-physical environments, the core question changes. The problem is no longer only whether a model performs well on historical data. The deeper question is whether the system remains safe when conditions shift, users behave unexpectedly, adversaries probe weaknesses, data pipelines degrade, institutions over-trust automated outputs, and optimization metrics diverge from human and social objectives.
This article develops AI Safety and System Reliability as an advanced article within the Artificial Intelligence Systems knowledge series. It explains safety as a systems-level property, reliability engineering, failure modes, deployment risk, distributional shift, monitoring, calibration, uncertainty routing, adversarial risk, human oversight, verification, validation, assurance cases, governance standards, incident response, and lifecycle accountability. Selected Python and R examples appear here, while the full GitHub repository contains expanded computational scaffolding for reliability monitoring, drift analysis, calibration review, safety-threshold diagnostics, incident-review tables, SQL metadata, governance documentation, and advanced reproducible workflows.
Why AI Safety and Reliability Matter
AI safety matters because artificial intelligence systems increasingly act inside real institutions rather than isolated research benchmarks. They recommend treatments, prioritize infrastructure maintenance, screen financial risk, support logistics, classify content, allocate attention, summarize evidence, assist public administration, and shape human decisions. In these settings, failure is not only a technical event. It can become an operational, institutional, social, legal, or ethical event.
The safety problem is especially difficult because AI systems fail differently from many conventional software systems. A traditional software service may fail by crashing, timing out, or returning an error. An AI system may fail silently while still producing plausible outputs. It may remain available while becoming miscalibrated. It may continue operating while its input distribution shifts. It may appear accurate in aggregate while failing for a subgroup, location, language, or edge case. It may optimize a measurable proxy while undermining the real-world purpose it was meant to serve.
This makes AI safety inseparable from reliability. A model that performs well in validation but degrades after deployment is not safe. A model that produces confident outputs without uncertainty review is not safe. A system that lacks incident logs, rollback procedures, monitoring thresholds, and governance ownership is not safe. Safety is not an attribute that can be certified once and forgotten. It is an ongoing practice of testing, monitoring, constraining, reviewing, correcting, and learning.
Benchmark\ Performance \neq Deployment\ Safety
\]
Interpretation: A model can perform well on a benchmark while still failing under distributional shift, misuse, adversarial pressure, fragile workflows, weak oversight, or changing real-world conditions.
| System Context | Why Accuracy Is Not Enough | Safety Question | Governance Concern |
|---|---|---|---|
| Healthcare | Clinical decisions involve uncertainty, context, and unequal risk. | Does the system support safe judgment without replacing professional responsibility? | Automation bias, missed critical cases, and accountability. |
| Infrastructure | Failures can cascade across water, energy, transport, and communications. | Does the system remain reliable under stress, disruption, and data degradation? | Resilience, incident response, and public safety. |
| Finance | Models can amplify systemic risk or unequal access. | Does the system remain fair, calibrated, and stable under market change? | Discrimination, opacity, and feedback loops. |
| Education | Automated outputs can shape opportunity, attention, and assessment. | Does the system support learners without narrowing human development? | Bias, over-reliance, and institutional responsibility. |
| Public administration | Model outputs may affect benefits, services, risk scores, or enforcement. | Can affected people understand, challenge, and correct system decisions? | Due process, transparency, and contestability. |
Note: AI safety becomes most important when model outputs affect people, infrastructure, institutions, rights, resources, or public trust.
Foundations of AI Safety and System Reliability
AI safety is the discipline of ensuring that artificial intelligence systems do not cause unacceptable harm when they are designed, trained, deployed, monitored, updated, or retired. Reliability is the ability of a system to perform its intended function consistently under specified conditions over time. These two ideas overlap, but they are not identical. A system can be reliable in the narrow sense of producing consistent outputs while still being unsafe if the intended function is poorly specified, the deployment context is misunderstood, or the system amplifies harm through feedback loops.
In classical engineering, reliability often concerns component failure, redundancy, uptime, fault tolerance, and maintenance. In AI systems, reliability also includes model validity, calibration, data quality, robustness, uncertainty estimation, monitoring, explainability, secure deployment, and governance. A deployed model may fail because a server goes down, but it may also fail because the distribution of incoming data shifts, a proxy metric becomes misaligned with real-world goals, a user misunderstands a confidence score, or a downstream decision process treats model output as more authoritative than it should.
System reliability requires asking several questions together:
- Technical reliability: Does the model perform consistently under expected conditions?
- Statistical reliability: Are predictions calibrated, robust, and valid under distributional change?
- Operational reliability: Are pipelines, logs, alerts, fallbacks, and rollback procedures in place?
- Human reliability: Do users understand the system’s limitations, uncertainty, and appropriate use?
- Institutional reliability: Are there governance structures for accountability, audit, review, and correction?
Safety emerges from the relationship among these layers. A high-performing model placed in a fragile deployment environment is not safe. A technically robust model embedded in an institution with weak oversight is not safe. A well-documented system without monitoring is not safe. A safe AI system must be engineered, tested, observed, constrained, governed, and continuously improved.
Safety = Model\ Validity + Operational\ Control + Human\ Oversight + Governance
\]
Interpretation: AI safety is not produced by model accuracy alone. It emerges from the full socio-technical system surrounding the model.
| Reliability Layer | Meaning | System Implication | Risk if Mishandled |
|---|---|---|---|
| Model reliability | The model performs consistently under specified conditions. | Validation must include calibration, robustness, and subgroup review. | Silent degradation or misleading confidence. |
| Data reliability | Inputs remain valid, documented, and fit for purpose. | Data contracts, lineage, schema checks, and provenance matter. | Pipeline drift, corrupted inputs, or semantic mismatch. |
| Operational reliability | The system remains available, monitored, and recoverable. | Logging, alerting, fallbacks, and rollback plans are required. | Failures become difficult to detect or contain. |
| Human reliability | People understand system limits and can intervene meaningfully. | Interfaces must support review, escalation, and override. | Automation bias or symbolic oversight. |
| Institutional reliability | Accountability structures convert evidence into action. | Risk registers, review boards, audit trails, and incident procedures matter. | Known harms persist without correction. |
Note: AI reliability must be evaluated across technical, statistical, operational, human, and institutional layers.
Safety as a Systems-Level Property
Modern AI systems are socio-technical systems. They include algorithms, infrastructure, people, organizations, incentives, policies, interfaces, and environments. This matters because many serious failures do not arise from a single broken component. They arise from interactions among components that individually appear to be functioning as designed.
For example, a model may be trained on historically accurate data, deployed into a decision workflow, used by operators under time pressure, connected to automated downstream actions, and monitored through aggregate performance dashboards. Each piece may appear defensible. Yet the complete system may still become unsafe if the historical data encodes structural bias, the dashboard hides subgroup failures, the workflow encourages automation bias, and the downstream actions create self-reinforcing feedback loops.
Safety engineering therefore requires more than debugging. It requires system mapping. A serious AI safety review should examine:
- the intended purpose and prohibited uses of the system;
- the training, validation, and deployment data sources;
- the model architecture, assumptions, and known limitations;
- the decision workflow in which outputs are used;
- the human roles responsible for review, override, escalation, and accountability;
- the monitoring system used to detect drift, degradation, misuse, and incidents;
- the security controls protecting data, models, APIs, and logs;
- the rollback, shutdown, and remediation procedures available when risk exceeds tolerance.
This systems view is especially important for high-stakes AI. In medical, environmental, financial, legal, educational, infrastructure, and public-sector contexts, the system’s behavior cannot be reduced to accuracy alone. The same model output may be harmless in an exploratory analytics dashboard and dangerous when used to trigger automated denial, intervention, prioritization, surveillance, or resource allocation.
Model\ Output + Workflow + Authority = System\ Behavior
\]
Interpretation: The effect of an AI system depends not only on the model output, but on how that output is used, trusted, challenged, automated, escalated, or ignored inside a real workflow.
Failure Modes in AI Systems
AI safety work begins with failure-mode analysis. A failure mode is a recognizable way a system can behave incorrectly, unreliably, or harmfully. Some failure modes are technical. Others are organizational, institutional, or social. In deployed AI systems, they often interact.
| Failure Mode | Description | Safety Concern | Possible Control |
|---|---|---|---|
| Distributional shift | Deployment data differs from training data. | Model performance degrades silently. | Drift monitoring, stress testing, retraining review. |
| Miscalibration | Predicted probabilities do not match observed frequencies. | Users may over-trust uncertain predictions. | Calibration curves, reliability diagrams, threshold review. |
| Proxy failure | The optimized metric diverges from the real objective. | System performs well statistically while harming real goals. | Objective review, stakeholder validation, multi-metric governance. |
| Automation bias | Human users defer too strongly to model outputs. | Human oversight becomes symbolic rather than meaningful. | Interface design, uncertainty display, override protocols. |
| Feedback-loop amplification | Model outputs affect future data collection. | Errors become self-reinforcing over time. | Feedback-loop audits, counterfactual review, randomized checks. |
| Adversarial manipulation | Inputs are crafted to induce unsafe behavior. | System can be exploited by malicious actors. | Threat modeling, adversarial testing, secure deployment. |
| Pipeline degradation | Data schemas, sensors, APIs, or preprocessing steps change. | Model receives corrupted or semantically changed inputs. | Data contracts, schema checks, lineage tracking. |
| Governance failure | No clear owner exists for incidents or remediation. | Known risks persist without accountability. | Risk register, escalation paths, audit trails. |
Note: Failure-mode analysis should occur before deployment and continue throughout the system lifecycle.
Failure-mode analysis should connect technical evidence to governance action. Pre-deployment testing identifies plausible hazards. Post-deployment monitoring detects realized hazards. Governance determines whether identified hazards lead to intervention, retraining, rollback, redesign, communication, or retirement.
Failure\ Mode \rightarrow Detection \rightarrow Escalation \rightarrow Correction
\]
Interpretation: A safety program is incomplete unless known failure modes are connected to detection systems, escalation paths, and corrective authority.
Reliability Architecture for AI Systems
A reliable AI system requires architecture around the model. The model is only one component in a chain that includes data ingestion, validation, feature transformation, inference, logging, monitoring, alerting, user interface design, access control, incident response, and governance review.
A basic AI reliability architecture should include:
- Data contracts: explicit expectations for schemas, units, allowed ranges, missingness, and update frequency;
- Input validation: checks for malformed, missing, shifted, or suspicious inputs;
- Model registry: versioned records of model artifacts, training data, validation results, intended uses, and known limitations;
- Evaluation gates: pre-deployment checks for performance, calibration, robustness, fairness, security, and documentation;
- Runtime monitoring: dashboards and alerts for drift, error rates, uncertainty, latency, availability, and abnormal behavior;
- Human escalation: routing mechanisms for uncertain, high-stakes, novel, or out-of-policy cases;
- Fallback modes: safe alternatives when model outputs cannot be trusted;
- Incident response: procedures for triage, containment, rollback, root-cause analysis, and remediation;
- Audit trails: records of inputs, outputs, model versions, human decisions, overrides, and system changes;
- Governance review: periodic institutional review of risk, performance, social impact, and continued appropriateness.
Reliability architecture should be designed before deployment, not added only after incidents occur. When AI systems are treated as ordinary software endpoints without lifecycle controls, their statistical and socio-technical failure modes remain hidden until harm has already occurred.
| Architecture Layer | Function | Evidence Produced | Governance Use |
|---|---|---|---|
| Data validation | Detects invalid, missing, shifted, or suspicious inputs. | Schema reports, missingness checks, drift summaries. | Determines whether inference should proceed, pause, or escalate. |
| Model evaluation | Tests performance, calibration, robustness, and subgroup behavior. | Validation reports, stress tests, benchmark comparisons. | Supports approval, limitation, or rejection of deployment. |
| Runtime monitoring | Tracks behavior after deployment. | Dashboards, alerts, incident logs, calibration trends. | Triggers review, retraining, rollback, or suspension. |
| Human escalation | Routes uncertain or high-risk cases to review. | Review queues, override logs, reviewer notes. | Tests whether oversight is meaningful and resourced. |
| Incident response | Contains and investigates failures. | Root-cause analysis, remediation records, lessons learned. | Converts failure into institutional learning. |
Note: Reliability architecture turns model performance into an operational and governable system.
Monitoring, Observability, and Drift Detection
Monitoring is the operational backbone of AI safety. A model that is not monitored after deployment is effectively ungoverned. Observability allows system owners to understand what the system is doing, whether its inputs have changed, whether its outputs remain calibrated, whether users are overriding recommendations, and whether errors are concentrated in particular subgroups or environments.
Useful monitoring dimensions include:
- Data drift: changes in the distribution of input features;
- Concept drift: changes in the relationship between inputs and outcomes;
- Prediction drift: changes in output score distributions;
- Calibration drift: changes in the match between predicted probability and observed frequency;
- Uncertainty drift: increases in model uncertainty or abstention rates;
- Operational drift: changes in latency, availability, error logs, or infrastructure behavior;
- Human workflow drift: changes in override rates, review behavior, or user dependence on the system.
Monitoring should include both technical alerts and governance triggers. A dashboard may detect drift, but an institution must decide what level of drift requires review, retraining, rollback, or suspension. Without governance thresholds, monitoring becomes passive observation rather than risk control.
P_{train}(x,y) \neq P_{deploy}(x,y)
\]
Interpretation: Distributional shift occurs when the data-generating process in deployment differs from the one represented during training, validation, or benchmarking.
Drift\ Alert \neq Governance\ Action
\]
Interpretation: Detecting drift is only useful when alerts are connected to thresholds, ownership, review authority, and corrective procedures.
Robustness, Distributional Shift, and Stress Testing
Robustness is the ability of a system to maintain acceptable behavior under variation. In AI systems, robustness is often tested against perturbations, missing data, noise, domain transfer, rare events, subgroup variation, and adversarial inputs. A model that performs well only under narrow benchmark conditions is not reliable enough for dynamic environments.
Stress testing should include:
- out-of-distribution inputs;
- missing or delayed data;
- schema changes and unit errors;
- extreme but plausible environmental conditions;
- rare but high-impact cases;
- subgroup performance analysis;
- adversarial and misuse scenarios;
- operator behavior under time pressure;
- system behavior during partial infrastructure failure.
For high-stakes systems, stress testing should be documented as part of the assurance case. It should not be treated as a one-time experiment. As systems change, data changes, and organizational use changes, old stress tests may no longer represent current risk.
| Stress Condition | What It Tests | Failure Signal | Governance Response |
|---|---|---|---|
| Data shift | Whether inputs differ from training conditions. | Feature distributions move beyond expected ranges. | Trigger drift review or restrict use. |
| Rare events | Whether the system handles low-frequency, high-impact cases. | Critical failures are missed or misclassified. | Raise thresholds, require human review, or redesign evaluation. |
| Subgroup variation | Whether performance differs across affected groups or contexts. | Aggregate metrics hide localized harm. | Require subgroup analysis and corrective mitigation. |
| Operational degradation | Whether the system functions under latency, outages, or missing inputs. | Fallback behavior is unreliable or undocumented. | Activate resilience and continuity planning. |
| Adversarial pressure | Whether malicious inputs or misuse change behavior. | Unsafe outputs occur under crafted or hostile conditions. | Escalate to security review and red-team testing. |
Note: Robustness testing should connect technical variation to operational consequence and institutional response.
Adversarial Risk, Security, and Misuse
AI safety and cybersecurity increasingly overlap. AI systems can be attacked through poisoned training data, manipulated inputs, prompt injection, model extraction, data exfiltration, supply-chain compromise, insecure APIs, unauthorized model updates, and misuse of generated outputs. A system that is statistically reliable but insecure is not safe.
Adversarial examples illustrate one part of this problem. An input may be changed in a small or strategically designed way that causes the model to produce an incorrect output. In deployed systems, adversarial risk extends beyond image classifiers or benchmark tasks. It includes manipulation of recommendation systems, fraud detection, identity verification, autonomous agents, retrieval-augmented generation, decision support tools, and monitoring systems.
f_{\theta}(x + \delta) \neq f_{\theta}(x)
\quad \text{while} \quad
d(x + \delta, x) \leq \eta
\]
Interpretation: An adversarial perturbation \(\delta\) changes the model output even though the modified input remains close to the original input under a distance measure \(d\). The threshold \(\eta\) defines how small or constrained the perturbation is.
Security controls for AI systems should include access control, dependency review, artifact signing, model versioning, logging, red-team testing, prompt-injection testing where relevant, data validation, secure deployment practices, and incident response procedures. AI safety should not be separated from secure software development.
Human Oversight and Human-AI Reliability
Human oversight is often proposed as a safety mechanism, but oversight is only meaningful if humans have the authority, time, information, training, and institutional support to intervene. A human reviewer who must approve hundreds of model recommendations per hour may become part of an automation pipeline rather than an independent safety control.
Reliable human-AI systems require careful interface and workflow design. Users should understand:
- what the model is designed to do;
- what the model is not designed to do;
- how uncertain the model is in a given case;
- what information influenced the output;
- when escalation is required;
- how to override the system;
- how overrides are reviewed and learned from.
Oversight systems should also be audited. If human reviewers almost never override the model, that may indicate high trustworthiness, but it may also indicate automation bias, poor interface design, organizational pressure, or lack of review capacity. Human oversight must be evaluated as part of the system, not assumed to solve safety by its mere presence.
Human\ in\ the\ Loop \neq Meaningful\ Oversight
\]
Interpretation: Oversight is meaningful only when people have authority, time, information, training, and institutional support to challenge or override the system.
Verification, Validation, and Assurance Cases
Verification and validation are central to system reliability. Verification asks whether the system was built according to specification. Validation asks whether the specified system is appropriate for the real-world problem. In AI, both questions are difficult because model behavior is learned from data rather than entirely programmed through explicit rules.
A safety-oriented AI assurance case should include:
- the system purpose and deployment context;
- the intended users and affected stakeholders;
- the model architecture and training process;
- the data sources, lineage, and known limitations;
- the evaluation results and stress tests;
- calibration and uncertainty analysis;
- subgroup and edge-case analysis;
- security and misuse testing;
- monitoring and incident response plans;
- human oversight procedures;
- rollback and decommissioning criteria;
- governance ownership and review schedule.
The purpose of an assurance case is not to claim perfect safety. Perfect safety is not available in complex systems. The purpose is to make the safety argument explicit, evidence-based, reviewable, and contestable.
| Practice | Core Question | Evidence | Safety Function |
|---|---|---|---|
| Verification | Was the system built according to specification? | Tests, code review, configuration checks, deployment records. | Reduces implementation and integration failures. |
| Validation | Is the system appropriate for the real-world task? | Evaluation studies, user testing, domain review, stress tests. | Reduces problem-framing and context failures. |
| Assurance case | Is the safety argument explicit and evidence-based? | Structured claims, evidence, assumptions, limitations, and review records. | Makes safety contestable and auditable. |
| Post-deployment review | Does the system remain safe over time? | Monitoring logs, incident records, drift metrics, override analysis. | Supports lifecycle governance and correction. |
Note: Verification asks whether the system was built correctly; validation asks whether the correct system was built.
Governance, Standards, and Institutional Accountability
AI safety governance connects technical controls to institutional responsibility. Frameworks such as the NIST AI Risk Management Framework, ISO/IEC 42001, ISO/IEC 23894, the OECD AI Principles, and the EU AI Act reflect a broader movement toward lifecycle risk management, documentation, transparency, accountability, and continuous review.
Governance should define who is responsible for risk acceptance, deployment approval, monitoring, incident response, user communication, model updates, third-party dependencies, and retirement. In mature systems, these responsibilities should not be informal. They should be documented through risk registers, model cards, audit logs, approval workflows, post-incident reviews, and periodic governance review.
A practical governance structure should include:
- Risk classification: identify whether the AI system is low, medium, high, or unacceptable risk in context;
- Lifecycle documentation: maintain records from design through retirement;
- Pre-deployment review: require evidence of validity, robustness, security, fairness, and operational readiness;
- Deployment controls: limit use to approved contexts and users;
- Monitoring obligations: define metrics, thresholds, alerts, and review cadence;
- Incident governance: define escalation, containment, reporting, remediation, and learning procedures;
- Change management: require review for model updates, data changes, interface changes, and use-case expansion;
- Decommissioning criteria: define when the system should be paused, rolled back, or retired.
Governance is not a substitute for technical rigor. It is the institutional structure that makes technical rigor durable, reviewable, and accountable.
Limits and Open Problems
AI safety and reliability remain open, difficult, and contested fields. Several problems remain especially important.
First, deployment environments are not stationary. Models are often evaluated using historical data, but real systems operate in changing environments. Social behavior, economic conditions, infrastructure stress, climate conditions, institutional policies, user practices, and adversarial strategies can all change the meaning of model inputs and outputs.
Second, safety metrics are incomplete. Accuracy, calibration, robustness, fairness, uptime, latency, and incident rates are all useful, but none provides a complete measure of safety. Some forms of harm are delayed, diffuse, cumulative, or institutionally mediated.
Third, alignment is difficult to specify. Systems optimize formal objectives, but real-world goals are plural, contested, and context-dependent. A proxy metric may be measurable and still misrepresent the underlying goal.
Fourth, human oversight can fail. Humans may over-trust models, misunderstand outputs, lack authority to intervene, or face organizational incentives that discourage escalation. Oversight must therefore be designed and monitored as part of the system.
Fifth, governance can become procedural rather than substantive. Documentation, checklists, and standards are necessary, but they are not sufficient. The deeper question is whether institutions actually use evidence to change deployment decisions, pause unsafe systems, remediate harms, and learn from incidents.
The future of AI safety will depend on tighter integration among machine learning research, reliability engineering, cybersecurity, human factors, institutional design, law, ethics, and democratic accountability. Safe AI is not achieved by one metric, one model card, one audit, or one governance framework. It is an ongoing practice of building systems that can be tested, questioned, constrained, corrected, and held accountable.
Mathematical Lens: Risk, Reliability, and Safety Constraints
A mathematical lens cannot capture every ethical, social, or institutional dimension of AI safety. It can, however, clarify how system designers reason about expected loss, failure probability, uncertainty, reliability, and safety constraints.
\mathcal{R}_{deploy}(\theta) = E_{(x,y) \sim P_{deploy}} \left[ L(f_{\theta}(x), y) \right]
\]
Interpretation: Deployment risk is the expected loss of a model \(f_{\theta}\) under the real deployment distribution \(P_{deploy}\), not merely the training or benchmark distribution. A system can look safe in validation and become unsafe when the deployment environment changes.
This equation highlights a central problem: the true deployment distribution is often only partially known. Historical validation data may not represent future users, rare events, adversarial behavior, policy changes, sensor failures, new economic conditions, or climate-related disruptions. Safety therefore depends on uncertainty-aware evaluation, not just average-case optimization.
\min_{\theta} \mathcal{R}_{deploy}(\theta)
\quad \text{subject to} \quad
P(H(f_{\theta}(x), x) = 1) \leq \epsilon
\]
Interpretation: The model is optimized while constraining the probability of a harmful event \(H\). The tolerance level \(\epsilon\) should be set according to the stakes of the deployment context, not merely according to technical convenience.
Reliability can also be represented as the probability that a system continues to perform its intended function over time.
R(t) = P(T > t)
\]
Interpretation: Reliability \(R(t)\) is the probability that the time to failure \(T\) exceeds time \(t\). In AI systems, failure may mean service outage, prediction degradation, calibration failure, unsafe output, or violation of an operational threshold.
When uncertainty estimates are available, a system can route high-uncertainty cases to human review instead of treating all predictions equally.
a(x) =
\begin{cases}
\text{automate}, & u(x) \leq \tau \\
\text{review}, & u(x) > \tau
\end{cases}
\]
Interpretation: A routing policy sends low-uncertainty cases to automation and high-uncertainty cases to human review. The threshold \(\tau\) should reflect domain risk, staffing capacity, legal requirements, and the cost of false confidence.
Calibration can be expressed as the relationship between predicted probability and observed frequency.
P(Y=1 \mid \hat{p}(X)=p)=p
\]
Interpretation: A calibrated model’s predicted probability should match the observed frequency of outcomes among similar predictions. Miscalibration can cause users to over-trust or under-trust model outputs.
Variables and System Interpretation
| Symbol or Term | Meaning | System Interpretation | Safety Relevance |
|---|---|---|---|
| \(x\) | Input features | Observed data entering the model | May be incomplete, shifted, manipulated, or corrupted. |
| \(y\) | Target outcome | Reference label or real-world outcome | May reflect historical bias, measurement error, or delayed observation. |
| \(f_{\theta}\) | Model with parameters \(\theta\) | Predictive or generative system component | Must be evaluated within the full workflow, not in isolation. |
| \(P_{train}\) | Training distribution | Data-generating process represented in training data | May not match future deployment conditions. |
| \(P_{deploy}\) | Deployment distribution | Data-generating process encountered in operation | Primary object of safety concern. |
| \(L\) | Loss function | Penalty for prediction error or undesirable behavior | May fail to represent real harm if poorly specified. |
| \(\mathcal{R}_{deploy}\) | Deployment risk | Expected loss under operational conditions | Should be monitored after deployment. |
| \(H\) | Harm indicator | Whether a harmful event occurs | Requires domain-specific definition and review. |
| \(\epsilon\) | Risk tolerance | Maximum acceptable probability of harm | Should be set by governance, not only engineering teams. |
| \(R(t)\) | Reliability over time | Probability the system avoids failure through time \(t\) | Supports uptime, degradation, and incident analysis. |
| \(u(x)\) | Uncertainty score | Estimated uncertainty for a specific input | Can trigger human review or abstention. |
| \(\tau\) | Review threshold | Boundary between automation and escalation | Controls automation risk and review workload. |
Note: These variables should be interpreted as components of a governed system, not only as mathematical abstractions.
Worked Example: A Safety-Critical Decision Support Model
Consider an AI decision support system used to prioritize infrastructure maintenance requests. The model estimates the probability that an asset will fail within a specified time window. The system is not fully autonomous: it recommends priorities to human operators, who approve maintenance decisions. Even so, the system can create harm if it consistently underestimates risk for certain regions, fails under extreme weather conditions, or causes operators to defer necessary inspections.
A narrow performance evaluation might ask whether the model has high area under the receiver operating characteristic curve, low average error, and acceptable precision. A safety-oriented evaluation asks a broader set of questions:
- Does performance remain stable during storms, heat waves, flooding, or unusual demand?
- Are uncertainty estimates calibrated for rare but severe events?
- Does the model under-prioritize assets in historically under-served communities?
- Can operators see why the model assigned a high or low risk score?
- Are high-uncertainty cases routed to human review?
- Is there a rollback plan if the model begins producing abnormal recommendations?
- Are decisions logged for audit, incident review, and long-term learning?
The safety requirement might be written as follows:
P(\text{missed critical failure}) \leq 0.01
\]
Interpretation: The system must keep the probability of missing a critical failure below an agreed threshold. The acceptable threshold depends on the severity of consequences, available alternatives, legal duties, and institutional risk tolerance.
A practical safety policy might combine prediction thresholds, uncertainty thresholds, and escalation rules:
- automatically flag assets with predicted failure probability above 0.70;
- route cases to human review when uncertainty is above 0.25;
- require manual inspection for critical assets when sensor data is incomplete;
- trigger incident review when missed failures exceed the tolerance threshold;
- pause automated prioritization when drift metrics exceed pre-defined limits.
The key lesson is that safety is not a single model metric. It is an operating discipline connecting prediction, uncertainty, review, monitoring, fallback, and governance.
Computational Modeling
Computational modeling for AI safety should produce artifacts that help people evaluate, govern, and audit system behavior. A monitoring workflow should not merely calculate model metrics. It should also generate reviewable evidence: drift summaries, calibration tables, safety-threshold checks, incident samples, and decision logs.
A useful safety-monitoring workflow should answer several practical questions:
- Are deployment inputs changing relative to baseline conditions?
- Are predicted probabilities still calibrated?
- Are high-risk cases being flagged?
- Are high-uncertainty cases being routed to review?
- Are missed critical failures within the institution’s risk tolerance?
- Are outputs saved in a form that supports audit, review, and remediation?
| Artifact | Purpose | Governance Value |
|---|---|---|
| Drift summary | Compares baseline and deployment feature distributions. | Identifies whether operating conditions have changed. |
| Calibration table | Compares predicted probabilities to observed outcomes. | Reveals whether confidence scores are trustworthy. |
| Safety threshold report | Checks whether failure rates exceed tolerance. | Supports pause, rollback, escalation, or remediation. |
| Incident review sample | Extracts high-risk or missed-failure cases. | Supports root-cause analysis and human review. |
| Audit log | Records model version, input state, output, decision, and reviewer action. | Preserves accountability and traceability. |
Note: Computational monitoring should produce evidence that institutions can act on, not only metrics that engineers can observe.
Python Workflow: Reliability Monitoring and Safety Thresholds
The following Python workflow demonstrates a simplified monitoring pattern for AI system reliability. It creates synthetic prediction data, estimates calibration, detects drift, calculates a safety threshold violation, and routes high-uncertainty cases to review. In production, the same logic would be connected to real model logs, feature stores, model registries, incident systems, and governance dashboards.
"""
AI Safety and System Reliability
Python workflow: monitoring drift, calibration, uncertainty, and safety thresholds.
This example uses synthetic data so the workflow can be adapted to real logs.
In production, replace synthetic data generation with model-monitoring tables,
feature-store exports, inference logs, or governed model registry outputs.
"""
from pathlib import Path
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
RANDOM_SEED = 42
rng = np.random.default_rng(RANDOM_SEED)
OUTPUT_DIR = Path("outputs")
OUTPUT_DIR.mkdir(exist_ok=True)
def make_prediction_log(n: int, shift: float = 0.0) -> pd.DataFrame:
"""
Create a synthetic AI decision-support log.
Parameters
----------
n:
Number of predictions.
shift:
Simulated shift in the feature distribution.
Returns
-------
pandas.DataFrame
Synthetic log containing features, predicted probabilities,
uncertainty estimates, and observed outcomes.
"""
feature_a = rng.normal(loc=0.0 + shift, scale=1.0, size=n)
feature_b = rng.normal(loc=0.0, scale=1.0 + abs(shift) / 3, size=n)
latent_score = 0.9 * feature_a + 0.6 * feature_b
true_probability = 1 / (1 + np.exp(-latent_score))
predicted_probability = np.clip(
true_probability + rng.normal(loc=0.02 * shift, scale=0.08, size=n),
0.01,
0.99,
)
uncertainty = np.clip(
0.12 + 0.18 * np.abs(feature_a) + rng.normal(0, 0.05, size=n),
0.01,
0.99,
)
observed_outcome = rng.binomial(1, true_probability)
return pd.DataFrame(
{
"feature_a": feature_a,
"feature_b": feature_b,
"predicted_probability": predicted_probability,
"uncertainty": uncertainty,
"observed_outcome": observed_outcome,
}
)
baseline = make_prediction_log(n=4000, shift=0.0)
deployment = make_prediction_log(n=4000, shift=0.6)
baseline["period"] = "baseline"
deployment["period"] = "deployment"
combined = pd.concat([baseline, deployment], ignore_index=True)
# ------------------------------------------------------------
# 1. Drift diagnostics.
# ------------------------------------------------------------
def summarize_drift(reference: pd.DataFrame, current: pd.DataFrame, columns: list[str]) -> pd.DataFrame:
"""
Compare feature means and standard deviations between baseline and deployment.
"""
rows = []
for column in columns:
baseline_mean = reference[column].mean()
deployment_mean = current[column].mean()
baseline_sd = reference[column].std()
deployment_sd = current[column].std()
standardized_mean_shift = (deployment_mean - baseline_mean) / baseline_sd
rows.append(
{
"feature": column,
"baseline_mean": baseline_mean,
"deployment_mean": deployment_mean,
"baseline_sd": baseline_sd,
"deployment_sd": deployment_sd,
"standardized_mean_shift": standardized_mean_shift,
"drift_flag": abs(standardized_mean_shift) > 0.25,
}
)
return pd.DataFrame(rows)
drift_summary = summarize_drift(
baseline,
deployment,
columns=["feature_a", "feature_b", "predicted_probability", "uncertainty"],
)
print("Drift summary")
print(drift_summary)
# ------------------------------------------------------------
# 2. Calibration diagnostics.
# ------------------------------------------------------------
deployment["risk_band"] = pd.cut(
deployment["predicted_probability"],
bins=np.linspace(0, 1, 11),
include_lowest=True,
)
calibration_table = (
deployment.groupby("risk_band", observed=False)
.agg(
predicted_probability=("predicted_probability", "mean"),
observed_outcome=("observed_outcome", "mean"),
count=("observed_outcome", "size"),
)
.reset_index()
)
calibration_table["calibration_gap"] = (
calibration_table["predicted_probability"] - calibration_table["observed_outcome"]
)
print("Calibration table")
print(calibration_table)
# ------------------------------------------------------------
# 3. Safety threshold and review routing.
# ------------------------------------------------------------
decision_threshold = 0.70
uncertainty_threshold = 0.30
missed_failure_tolerance = 0.01
deployment["recommended_action"] = np.where(
deployment["predicted_probability"] >= decision_threshold,
"flag",
"do_not_flag",
)
deployment["review_required"] = deployment["uncertainty"] > uncertainty_threshold
deployment["missed_failure"] = (
(deployment["recommended_action"] == "do_not_flag")
& (deployment["observed_outcome"] == 1)
)
missed_failure_rate = deployment["missed_failure"].mean()
review_rate = deployment["review_required"].mean()
safety_summary = pd.DataFrame(
{
"missed_failure_rate": [missed_failure_rate],
"review_rate": [review_rate],
"safety_threshold_violated": [
missed_failure_rate > missed_failure_tolerance
],
}
)
print("Safety summary")
print(safety_summary)
# ------------------------------------------------------------
# 4. Incident review sample.
# ------------------------------------------------------------
incident_review = (
deployment.loc[deployment["missed_failure"]]
.sort_values("uncertainty", ascending=False)
.head(25)
)
print("Highest-uncertainty missed failures")
print(incident_review.head(10))
# ------------------------------------------------------------
# 5. Save governance artifacts.
# ------------------------------------------------------------
combined.to_csv(OUTPUT_DIR / "ai_safety_prediction_log.csv", index=False)
drift_summary.to_csv(OUTPUT_DIR / "python_drift_summary.csv", index=False)
calibration_table.to_csv(OUTPUT_DIR / "python_calibration_table.csv", index=False)
safety_summary.to_csv(OUTPUT_DIR / "python_safety_summary.csv", index=False)
incident_review.to_csv(OUTPUT_DIR / "python_incident_review.csv", index=False)
# ------------------------------------------------------------
# 6. Create a simple calibration plot.
# ------------------------------------------------------------
plt.figure(figsize=(7, 5))
plt.plot(
calibration_table["predicted_probability"],
calibration_table["observed_outcome"],
marker="o",
)
plt.plot([0, 1], [0, 1], linestyle="--")
plt.xlabel("Mean predicted probability")
plt.ylabel("Observed outcome frequency")
plt.title("Calibration review for deployment predictions")
plt.tight_layout()
plt.savefig(OUTPUT_DIR / "python_calibration_plot.png", dpi=150)
plt.close()
# ------------------------------------------------------------
# 7. Create a governance memo.
# ------------------------------------------------------------
memo = f"""# AI Safety Monitoring Memo
## Summary
Deployment records evaluated: {len(deployment)}
Missed failure rate: {missed_failure_rate:.4f}
Review rate: {review_rate:.4f}
Safety threshold violated: {missed_failure_rate > missed_failure_tolerance}
## Interpretation
- Drift summaries indicate whether deployment data has moved away from baseline.
- Calibration tables show whether predicted probabilities remain trustworthy.
- The safety threshold report identifies whether missed failures exceed tolerance.
- High-uncertainty missed failures should be reviewed for root-cause analysis.
- If safety thresholds are violated, governance review should consider rollback,
threshold adjustment, retraining, workflow redesign, or temporary suspension.
"""
(OUTPUT_DIR / "python_ai_safety_monitoring_memo.md").write_text(memo)
print(memo)
This workflow treats AI safety as an evaluable system rather than only a model-performance problem. Drift, calibration, uncertainty, missed failures, and incident review all matter when AI systems operate under changing real-world conditions.
R Workflow: Drift, Calibration, and Incident Review
The following R workflow mirrors the Python example in a governance-friendly form. It creates synthetic deployment data, summarizes drift, builds calibration bands, evaluates a safety threshold, and saves outputs that can be reviewed by technical, operational, and governance teams.
# AI Safety and System Reliability
# R workflow: drift, calibration, uncertainty, and incident review.
set.seed(42)
if (!dir.exists("outputs")) {
dir.create("outputs")
}
make_prediction_log <- function(n, shift = 0) {
feature_a <- rnorm(n, mean = shift, sd = 1)
feature_b <- rnorm(n, mean = 0, sd = 1 + abs(shift) / 3)
latent_score <- 0.9 * feature_a + 0.6 * feature_b
true_probability <- 1 / (1 + exp(-latent_score))
predicted_probability <- pmin(
pmax(true_probability + rnorm(n, mean = 0.02 * shift, sd = 0.08), 0.01),
0.99
)
uncertainty <- pmin(
pmax(0.12 + 0.18 * abs(feature_a) + rnorm(n, mean = 0, sd = 0.05), 0.01),
0.99
)
observed_outcome <- rbinom(n, size = 1, prob = true_probability)
data.frame(
feature_a = feature_a,
feature_b = feature_b,
predicted_probability = predicted_probability,
uncertainty = uncertainty,
observed_outcome = observed_outcome
)
}
baseline <- make_prediction_log(4000, shift = 0)
deployment <- make_prediction_log(4000, shift = 0.6)
baseline$period <- "baseline"
deployment$period <- "deployment"
combined <- rbind(baseline, deployment)
# ------------------------------------------------------------
# 1. Drift diagnostics.
# ------------------------------------------------------------
drift_columns <- c(
"feature_a",
"feature_b",
"predicted_probability",
"uncertainty"
)
drift_summary <- data.frame()
for (column in drift_columns) {
baseline_mean <- mean(baseline[[column]])
deployment_mean <- mean(deployment[[column]])
baseline_sd <- sd(baseline[[column]])
deployment_sd <- sd(deployment[[column]])
standardized_mean_shift <- (deployment_mean - baseline_mean) / baseline_sd
drift_summary <- rbind(
drift_summary,
data.frame(
feature = column,
baseline_mean = baseline_mean,
deployment_mean = deployment_mean,
baseline_sd = baseline_sd,
deployment_sd = deployment_sd,
standardized_mean_shift = standardized_mean_shift,
drift_flag = abs(standardized_mean_shift) > 0.25
)
)
}
print("Drift summary")
print(drift_summary)
# ------------------------------------------------------------
# 2. Calibration diagnostics.
# ------------------------------------------------------------
deployment$risk_band <- cut(
deployment$predicted_probability,
breaks = seq(0, 1, by = 0.1),
include.lowest = TRUE
)
calibration_table <- aggregate(
cbind(predicted_probability, observed_outcome) ~ risk_band,
data = deployment,
FUN = mean
)
counts <- aggregate(
observed_outcome ~ risk_band,
data = deployment,
FUN = length
)
calibration_table$count <- counts$observed_outcome
calibration_table$calibration_gap <-
calibration_table$predicted_probability - calibration_table$observed_outcome
print("Calibration table")
print(calibration_table)
# ------------------------------------------------------------
# 3. Safety threshold and incident review.
# ------------------------------------------------------------
decision_threshold <- 0.70
uncertainty_threshold <- 0.30
missed_failure_tolerance <- 0.01
deployment$recommended_action <- ifelse(
deployment$predicted_probability >= decision_threshold,
"flag",
"do_not_flag"
)
deployment$review_required <- deployment$uncertainty > uncertainty_threshold
deployment$missed_failure <- deployment$recommended_action == "do_not_flag" &
deployment$observed_outcome == 1
missed_failure_rate <- mean(deployment$missed_failure)
review_rate <- mean(deployment$review_required)
safety_summary <- data.frame(
missed_failure_rate = missed_failure_rate,
review_rate = review_rate,
safety_threshold_violated = missed_failure_rate > missed_failure_tolerance
)
print("Safety summary")
print(safety_summary)
incident_review <- deployment[deployment$missed_failure == TRUE, ]
incident_review <- incident_review[order(-incident_review$uncertainty), ]
print("Highest-uncertainty missed failures")
print(head(incident_review, 10))
# ------------------------------------------------------------
# 4. Save governance artifacts.
# ------------------------------------------------------------
write.csv(combined, "outputs/r_ai_safety_prediction_log.csv", row.names = FALSE)
write.csv(drift_summary, "outputs/r_drift_summary.csv", row.names = FALSE)
write.csv(calibration_table, "outputs/r_calibration_table.csv", row.names = FALSE)
write.csv(safety_summary, "outputs/r_safety_summary.csv", row.names = FALSE)
write.csv(head(incident_review, 100), "outputs/r_incident_review.csv", row.names = FALSE)
memo <- paste0(
"# AI Safety Monitoring Memo\n\n",
"Deployment records evaluated: ", nrow(deployment), "\n",
"Missed failure rate: ", round(missed_failure_rate, 4), "\n",
"Review rate: ", round(review_rate, 4), "\n",
"Safety threshold violated: ",
missed_failure_rate > missed_failure_tolerance,
"\n\n",
"Interpretation:\n",
"- Drift summaries identify whether deployment data has changed.\n",
"- Calibration tables show whether predicted probabilities remain trustworthy.\n",
"- Missed failures should be reviewed against the risk tolerance threshold.\n",
"- High-uncertainty missed failures should support root-cause analysis.\n",
"- If thresholds are violated, governance review should consider rollback, ",
"threshold adjustment, retraining, workflow redesign, or temporary suspension.\n"
)
writeLines(memo, "outputs/r_ai_safety_monitoring_memo.md")
cat(memo)
The R workflow is useful for governance review because it turns monitoring into interpretable tables: drift summaries, calibration bands, safety-threshold status, and incident-review samples. These are the kinds of artifacts that can support periodic model review, audit meetings, and post-incident analysis.
GitHub Repository
The article body includes selected computational examples so the conceptual and mathematical argument remains readable. The full repository contains expanded computational infrastructure: advanced Jupyter notebooks, Python and R monitoring workflows, SQL metadata schemas, drift diagnostics, calibration review, uncertainty routing, safety-threshold checks, incident-review samples, governance documentation, and reproducible outputs.
Complete Code Repository
The full code distribution for this article includes Python, R, SQL, Julia, governance documentation, AI reliability diagnostics, drift-monitoring workflows, calibration review, uncertainty thresholds, incident-response artifacts, reproducible outputs, and audit scaffolding for studying AI safety and system reliability.
From Benchmark Performance to Governed Reliability
AI safety and system reliability show that intelligence is not only prediction, generation, or optimization. It is behavior inside real systems. A model becomes socially and operationally consequential when its outputs enter workflows, shape decisions, allocate attention, influence institutions, or trigger automated actions. The safety question is therefore not only whether the model works. It is whether the whole system remains reliable under changing conditions.
The central lesson is that benchmark performance must be governed. A system that performs well in validation may fail under distributional shift, adversarial manipulation, miscalibration, pipeline degradation, proxy failure, human over-trust, or institutional neglect. Real-world AI safety therefore requires more than an algorithm. It requires lifecycle documentation, monitoring, reliability architecture, incident response, fallback systems, uncertainty review, human authority, and institutional accountability.
The future of AI safety will likely depend on hybrid systems that combine machine learning, reliability engineering, cybersecurity, human factors, formal evaluation, model monitoring, governance frameworks, and democratic accountability. The strongest AI systems will not simply score well. They will remain testable, constrained, auditable, contestable, recoverable, and correctable when conditions change.
Within the Artificial Intelligence Systems knowledge series, this article belongs near Robustness and Adversarial Resilience in Machine Learning, Systemic Risk, Feedback Loops, and Cascading Failures in AI Systems, Model Validation, Benchmarking, and Generalization Theory, Data Governance, Provenance, and Lineage in AI Systems, Trust, Interpretability, and User-Centered AI Systems, and Real-Time AI Systems and Autonomous Decision-Making. It provides the reliability and governance layer for understanding how AI systems should be built, evaluated, monitored, and held accountable.
The final point is institutional. AI safety forces governance to move beyond model approval and toward lifecycle oversight. A deployed AI system is not merely a prediction artifact. It is a socio-technical system that can fail, adapt, drift, mislead, recover, and reshape the environment that later evaluates it. AI becomes trustworthy only when technical capability is paired with constraints, monitoring, auditability, correction, and human authority.
Related Articles
- Robustness and Adversarial Resilience in Machine Learning
- Systemic Risk, Feedback Loops, and Cascading Failures in AI Systems
- Model Validation, Benchmarking, and Generalization Theory
- Data Governance, Provenance, and Lineage in AI Systems
- Trust, Interpretability, and User-Centered AI Systems
- Real-Time AI Systems and Autonomous Decision-Making
- AI Infrastructure: Data Pipelines, Compute, and Deployment Systems
Further Reading
- Leveson, N.G. (2012) Engineering a Safer World: Systems Thinking Applied to Safety. Cambridge, MA: MIT Press. Available at: https://direct.mit.edu/books/oa-monograph/2908/Engineering-a-Safer-WorldSystems-Thinking-Applied
- Russell, S. (2019) Human Compatible: Artificial Intelligence and the Problem of Control. New York: Viking. Available at: https://www.penguinrandomhouse.com/books/566677/human-compatible-by-stuart-russell/
- Amodei, D. et al. (2016) ‘Concrete Problems in AI Safety’. Available at: https://arxiv.org/abs/1606.06565
- Mitchell, M. et al. (2019) ‘Model Cards for Model Reporting’. Available at: https://arxiv.org/abs/1810.03993
- Raji, I.D. et al. (2020) ‘Closing the AI Accountability Gap: Defining an End-to-End Framework for Internal Algorithmic Auditing’. Available at: https://dl.acm.org/doi/10.1145/3351095.3372873
- Hendrycks, D. et al. (2021) ‘Unsolved Problems in ML Safety’. Available at: https://arxiv.org/abs/2109.13916
- Sculley, D. et al. (2015) ‘Hidden Technical Debt in Machine Learning Systems’. Available at: https://papers.nips.cc/paper_files/paper/2015/hash/86df7dcfd896fcaf2674f757a2463eba-Abstract.html
References
- Amodei, D., Olah, C., Steinhardt, J., Christiano, P., Schulman, J. and Mané, D. (2016) ‘Concrete Problems in AI Safety’. Available at: https://arxiv.org/abs/1606.06565
- European Parliament and Council of the European Union (2024) Regulation laying down harmonised rules on artificial intelligence. Available at: https://artificialintelligenceact.eu/
- Hendrycks, D., Carlini, N., Schulman, J. and Steinhardt, J. (2021) ‘Unsolved Problems in ML Safety’. Available at: https://arxiv.org/abs/2109.13916
- International Organization for Standardization (2023) ISO/IEC 42001: Artificial intelligence management system. Available at: https://www.iso.org/standard/81230.html
- International Organization for Standardization (2023) ISO/IEC 23894: Artificial intelligence — Guidance on risk management. Available at: https://www.iso.org/standard/77304.html
- Leveson, N.G. (2012) Engineering a Safer World: Systems Thinking Applied to Safety. Cambridge, MA: MIT Press. Available at: https://direct.mit.edu/books/oa-monograph/2908/Engineering-a-Safer-WorldSystems-Thinking-Applied
- Mitchell, M., Wu, S., Zaldivar, A., Barnes, P., Vasserman, L., Hutchinson, B., Spitzer, E., Raji, I.D. and Gebru, T. (2019) ‘Model Cards for Model Reporting’. Available at: https://arxiv.org/abs/1810.03993
- National Institute of Standards and Technology (2023) Artificial Intelligence Risk Management Framework 1.0. Available at: https://www.nist.gov/itl/ai-risk-management-framework
- OECD (2019) OECD Principles on Artificial Intelligence. Available at: https://oecd.ai/en/ai-principles
- Raji, I.D., Smart, A., White, R.N., Mitchell, M., Gebru, T., Hutchinson, B., Smith-Loud, J., Theron, D. and Barnes, P. (2020) ‘Closing the AI Accountability Gap: Defining an End-to-End Framework for Internal Algorithmic Auditing’. Available at: https://dl.acm.org/doi/10.1145/3351095.3372873
- Russell, S. (2019) Human Compatible: Artificial Intelligence and the Problem of Control. New York: Viking. Available at: https://www.penguinrandomhouse.com/books/566677/human-compatible-by-stuart-russell/
- Sculley, D., Holt, G., Golovin, D., Davydov, E., Phillips, T., Ebner, D., Chaudhary, V., Young, M. and Dennison, D. (2015) ‘Hidden Technical Debt in Machine Learning Systems’. Available at: https://papers.nips.cc/paper_files/paper/2015/hash/86df7dcfd896fcaf2674f757a2463eba-Abstract.html