
Last Updated May 27, 2026
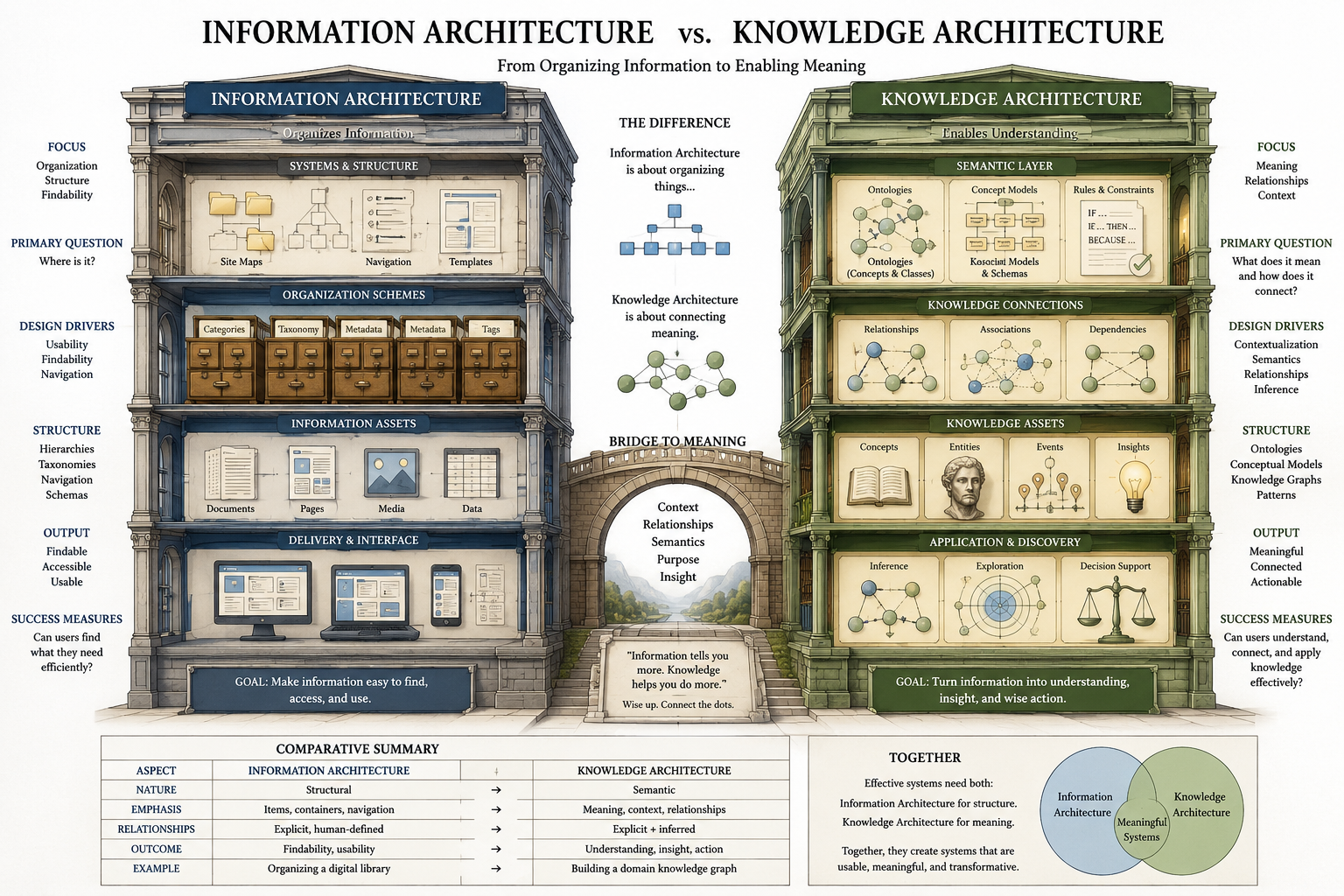
Information architecture and knowledge architecture are closely related, but they solve different problems. Information architecture organizes information so people can find, navigate, and use it. Knowledge architecture organizes meaning so people and systems can understand how concepts, evidence, documents, data, methods, and relationships fit together. The distinction matters because a platform can be easy to browse and still be intellectually shallow, just as a research system can contain sophisticated knowledge and still be difficult to navigate.
Information architecture asks how users move through information environments: menus, labels, search, navigation, page structure, categories, content types, and user pathways. Knowledge architecture asks how knowledge itself is structured: concepts, frameworks, taxonomies, ontologies, semantic relationships, metadata, knowledge graphs, evidence pathways, repositories, and governance practices. One emphasizes findability and usability. The other emphasizes meaning, interpretation, relationship, and long-term coherence.
Within knowledge architecture, information architecture remains essential. A knowledge system still needs clear navigation, labels, pathways, and user experience. But knowledge architecture extends beyond interface organization into intellectual infrastructure. It asks not only whether users can find a page, but whether the page belongs to a coherent conceptual system; not only whether content is labeled, but whether concepts are defined; not only whether topics are grouped, but whether their relationships are traceable, governed, and reusable.

What Is Information Architecture?
Information architecture is the practice of organizing information environments so that users can find, understand, and use information effectively. It focuses on structure, labeling, navigation, search, categorization, content grouping, page relationships, and user pathways. Its central concern is not simply where information exists, but how people encounter it.
In a website, information architecture may determine the navigation menu, category structure, page hierarchy, search filters, breadcrumb trails, content types, landing pages, internal links, and labels. In a digital library, it may organize browsing pathways, subject headings, metadata fields, collection structures, and search interfaces. In a knowledge base, it may determine how help articles are grouped, labeled, surfaced, and maintained.
Information architecture is often user-centered. It asks how people think about the information environment, which labels make sense to them, which pathways help them complete tasks, and where confusion occurs. It may draw on card sorting, tree testing, usability testing, content audits, search-log analysis, and user research.
IA = f(N, L, S, C, U)
\]
Interpretation: Information architecture \(IA\) can be understood as a function of navigation \(N\), labeling \(L\), search \(S\), categorization \(C\), and user pathways \(U\). The formula is conceptual, but it clarifies the primary design concerns.
The strength of information architecture is that it makes information environments usable. It helps people orient themselves, move through pages, locate relevant materials, and understand what choices are available. Without information architecture, even valuable information can become inaccessible.
What Is Knowledge Architecture?
Knowledge architecture is the design of intellectual infrastructure. It organizes concepts, categories, frameworks, ontologies, metadata, semantic relationships, evidence pathways, knowledge graphs, article maps, repositories, and governance systems so that knowledge can remain meaningful as it grows.
Where information architecture focuses on findability and navigation, knowledge architecture focuses on meaning and coherence. It asks how concepts are defined, how fields are structured, how evidence is connected, how research pathways are maintained, how metadata preserves context, how ontologies formalize relationships, and how knowledge systems can support interpretation across scale.
Knowledge architecture treats a page, file, article, dataset, or repository folder not merely as an information object but as a knowledge object. A knowledge object belongs to a conceptual field. It may discuss certain concepts, cite certain sources, depend on prior frameworks, use certain methods, support certain models, and connect to related knowledge objects. Knowledge architecture attempts to preserve those relationships.
KA = f(C, R, M, O, G)
\]
Interpretation: Knowledge architecture \(KA\) can be understood as a function of concepts \(C\), relationships \(R\), metadata \(M\), ontology or semantic structure \(O\), and governance \(G\).
The strength of knowledge architecture is that it preserves meaning across complexity. It helps a knowledge system become more than a collection of pages. It creates pathways, relationships, and structures that allow people and systems to understand how knowledge accumulates, changes, and connects.
Why the Distinction Matters
The distinction between information architecture and knowledge architecture matters because many digital systems confuse usability with coherence. A site can be clean, searchable, and easy to browse while still lacking intellectual structure. A research platform can have menus and categories while failing to show how its concepts, evidence, methods, and articles relate. A knowledge base can have hundreds of well-labeled pages while still duplicating topics, losing context, or failing to preserve institutional memory.
Information architecture solves the problem of access. Knowledge architecture solves the problem of meaning. Both are necessary, but they are not the same. Access without meaning can produce shallow navigation. Meaning without access can produce inaccessible expertise. A strong knowledge system needs both.
The distinction also matters for scale. A small website may survive with ordinary navigation and categories. A large research platform needs deeper structures: article maps, conceptual frameworks, metadata schemas, evidence links, controlled vocabularies, repositories, semantic relationships, and governance. As the system grows, navigation alone cannot preserve coherence.
The distinction matters for AI-assisted systems as well. Search and retrieval systems can locate information, but they need structured context to interpret what they retrieve. Knowledge architecture provides that context through metadata, ontologies, taxonomies, knowledge graphs, and relationship types. Information architecture helps users reach the right place. Knowledge architecture helps the system understand what that place means.
| Question | Information Architecture | Knowledge Architecture |
|---|---|---|
| Primary concern | Can users find and use information? | Can users and systems understand meaning and relationships? |
| Main unit | Page, section, content type, menu item, label. | Concept, relationship, evidence object, model, source, knowledge object. |
| Main structure | Navigation, labels, categories, search, user pathways. | Frameworks, taxonomies, ontologies, metadata, knowledge graphs, repositories. |
| Failure mode | Users cannot find what they need. | Knowledge loses coherence, context, or relationship structure. |
| Success condition | Findable, usable, navigable information. | Meaningful, connected, traceable, governed knowledge. |
The distinction is not a hierarchy of importance. Information architecture is not inferior to knowledge architecture. They address different layers of the same larger problem: how to make complex information environments usable and meaningful at the same time.
Information Architecture as Navigation and Usability
Information architecture is most visible in navigation. Users encounter it through menus, labels, filters, breadcrumbs, landing pages, search interfaces, related links, and page structures. These visible pathways determine whether users feel oriented or lost.
A strong information architecture answers practical questions. Where am I? What can I do here? What else is available? How do I move to related material? What label should I click? How do I narrow results? How do I return to the broader section? How do I know whether this page is relevant?
These questions are user-centered. Information architecture is successful when users can move through an information environment with minimal friction. It reduces cognitive load. It makes categories understandable. It helps people complete tasks. It supports clarity, consistency, and orientation.
In a publication platform, information architecture may structure the main library, article maps, category pages, tags, search filters, sidebars, table of contents blocks, and related-article sections. In a research repository, it may organize folders, documentation, datasets, notebooks, and outputs. In a digital library, it may organize collections, subjects, formats, and search facets.
Information architecture is therefore indispensable. Without it, knowledge architecture remains difficult to access. A brilliant ontology or deep article map will not help users if the platform’s labels, menus, and pathways are confusing. Usability is not superficial; it is the condition that allows people to encounter knowledge at all.
Knowledge Architecture as Meaning and Relationship
Knowledge architecture begins where ordinary navigation becomes insufficient. It asks whether the knowledge system preserves the relationships that make information meaningful. A menu can help users find an article, but knowledge architecture explains why that article belongs to a field, which concepts it develops, what evidence it uses, what methods support it, which articles precede it, and how future work can extend it.
Meaning depends on relationship. A concept means one thing in isolation and another thing inside a framework. A source becomes evidence only in relation to a claim. A dataset becomes useful only in relation to a method, model, or question. A repository becomes meaningful when it supports an article, reproduces an output, or documents a workflow. Knowledge architecture preserves these relationships.
This is why knowledge architecture uses structures that go beyond menus and categories: conceptual frameworks, controlled vocabularies, metadata schemas, ontologies, semantic networks, knowledge graphs, evidence maps, and repository documentation. These structures help knowledge systems carry context across time and scale.
Knowledge architecture also gives a system memory. It can document why a category exists, why an article belongs to a series, why a method was chosen, why a relationship is defined, and when a concept was revised. This matters for research platforms, public knowledge libraries, organizational knowledge systems, and AI-assisted retrieval environments.
Meaning = f(Context, Relationship, Evidence, Interpretation)
\]
Interpretation: In knowledge architecture, meaning depends on context, relationship, evidence, and interpretation. Information architecture can expose the object; knowledge architecture preserves the structure that helps the object make sense.
A knowledge architecture is strongest when users can move from article to concept, from concept to framework, from framework to evidence, from evidence to repository, and from repository to reproducible output. This is the movement from finding information to understanding knowledge.
Content Objects vs. Knowledge Objects
One of the clearest differences between information architecture and knowledge architecture is the difference between content objects and knowledge objects. A content object is something that exists in a system: a page, article, image, dataset, PDF, video, table, code file, or menu item. Information architecture organizes these objects so users can find and use them.
A knowledge object is a content object understood through its conceptual role. It belongs to a domain. It develops concepts. It cites sources. It may be part of a sequence. It may use a method. It may support a model. It may depend on prior knowledge. It may contain evidence or produce outputs. Knowledge architecture organizes these deeper relationships.
For example, an article is a content object in a website. It has a title, slug, category, excerpt, featured image, and link. But as a knowledge object, the same article has conceptual roles: it belongs to a knowledge series, develops a particular topic, relates to other articles, cites sources, links to a repository folder, includes code examples, and contributes to an article map.
| Object Type | Information Architecture View | Knowledge Architecture View |
|---|---|---|
| Article | A page with title, category, navigation, and URL. | A knowledge object that develops concepts, cites sources, links to related articles, and belongs to a research pathway. |
| Dataset | A downloadable file or data table. | An evidence or modeling object with provenance, method context, limitations, and use relationships. |
| Repository folder | A folder containing files. | A reproducible artifact supporting an article, method, dataset, and output chain. |
| Category | A browsing label or navigation grouping. | A controlled concept with scope, hierarchy, related terms, and governance. |
| Reference | A citation or link. | An evidence source with a role, claim relationship, authority context, and provenance function. |
This distinction changes how systems are designed. Information architecture may ask where the article should appear in navigation. Knowledge architecture asks what the article means within the system and how that meaning should be preserved.
Taxonomy, Metadata, and Semantic Structure
Information architecture and knowledge architecture both use taxonomy and metadata, but often in different ways. In information architecture, taxonomy helps users browse and filter content. Metadata helps describe pages and support search. In knowledge architecture, taxonomy and metadata become deeper semantic infrastructure.
A taxonomy in information architecture may organize pages into categories. A taxonomy in knowledge architecture may define controlled concepts, scope notes, preferred labels, broader-narrower relationships, related terms, and governance rules. The same structure moves from navigation support to intellectual classification.
Metadata in information architecture may include title, description, author, date, category, and tags. Metadata in knowledge architecture may also include concept roles, evidence status, article type, source provenance, repository path, method, version, relationship type, and review status. It carries interpretive context, not just administrative description.
Semantic structure extends these systems further by defining entities, classes, properties, and relationships. It allows a knowledge system to distinguish an article from a concept, a source from evidence, a dataset from a method, and a related concept from an equivalent concept. This is where knowledge architecture becomes machine-readable and governance-ready.
| Layer | Information Architecture Use | Knowledge Architecture Use |
|---|---|---|
| Taxonomy | Groups pages for navigation and browsing. | Defines conceptual domains, scope, hierarchy, controlled terms, and relationships. |
| Metadata | Describes content for search, filtering, and display. | Preserves provenance, concept roles, evidence status, methods, versions, and semantic relationships. |
| Ontology | Usually outside ordinary IA scope. | Defines entity classes, properties, constraints, and relationship types. |
| Knowledge graph | May appear as related-link or recommendation support. | Represents articles, concepts, sources, data, methods, and repositories as connected knowledge objects. |
| Governance | Maintains navigation, labels, and content organization. | Maintains conceptual integrity, evidence traceability, semantic relationships, and long-term coherence. |
The same system may need all of these layers. Information architecture makes them usable. Knowledge architecture makes them meaningful.
How Information Architecture Supports Knowledge Architecture
Information architecture supports knowledge architecture by making intellectual structure accessible. A knowledge system may have a strong conceptual framework, but users still need visible pathways. They need article maps, landing pages, headings, navigation buttons, related links, breadcrumbs, search filters, and clear labels. Without these, knowledge architecture remains hidden.
The five-button gateway pattern, table of contents, series context block, related articles section, and repository link block are examples of information architecture supporting knowledge architecture. They make the system’s structure visible to readers. They show where the article belongs, how to return to the article map, what related topics exist, and where reproducible assets live.
Information architecture also translates deep structure into usable interface signals. A taxonomy may contain complex relationships, but users need readable labels. A knowledge graph may contain many nodes and edges, but users need clear pathways. Metadata may store detailed context, but users need concise summaries, tags, excerpts, and navigation cues.
In this sense, information architecture is the public face of knowledge architecture. It helps users encounter the deeper structure without requiring them to understand the entire semantic model. It turns architecture into experience.
Good information architecture also provides feedback to knowledge architecture. Search behavior, navigation patterns, user confusion, duplicate pages, and abandoned pathways can reveal architectural problems. If users repeatedly fail to find a concept, the taxonomy may be unclear. If related articles are not used, relationship design may be weak. If menus become overloaded, the article map may need revision.
Where Information Architecture Is Not Enough
Information architecture is necessary, but it is not enough for complex knowledge systems. Navigation can make content easier to find, but it cannot by itself preserve conceptual relationships, evidence pathways, ontology definitions, methodological context, repository traceability, or research coherence.
A site may have excellent menus and still fail to distinguish foundational articles from applied articles. It may have tags but no controlled vocabulary. It may have related links but no relationship types. It may have a search box but no semantic structure. It may have categories but no scope notes. It may have a repository link but no explanation of how the code supports the article.
These are knowledge architecture problems. They require deeper structures than ordinary information architecture usually provides. A knowledge system needs to define concepts, connect evidence, structure repositories, maintain article maps, govern taxonomy changes, and preserve relationships across time.
Information architecture also does not automatically solve interdisciplinary complexity. A menu can list topics, but it cannot explain how a concept changes meaning across ecology, psychology, law, economics, AI, and governance. A knowledge architecture must preserve those meanings through scope notes, metadata, semantic relationships, and interpretive context.
Similarly, information architecture cannot fully support AI-assisted retrieval on its own. AI systems need more than page paths and labels. They need structured context: article type, concept relationships, source provenance, status, evidence roles, dataset type, and repository relationships. Knowledge architecture supplies these deeper signals.
Research Platforms and Digital Libraries
Research platforms and digital libraries illustrate the difference between information architecture and knowledge architecture clearly. A digital library needs browsing, search, subject labels, metadata, collections, and access pathways. These are information architecture concerns. But it also needs subject authority, controlled vocabularies, provenance, classification logic, citation relationships, source context, and long-term stewardship. These are knowledge architecture concerns.
A research platform needs more than publication pages. It needs article maps, repositories, data documentation, code examples, references, methods, models, visualizations, and evidence pathways. Information architecture helps users move through these objects. Knowledge architecture explains how they relate.
For example, a research article may have an accompanying GitHub folder. Information architecture can provide a visible repository link. Knowledge architecture clarifies the relationship: the repository supports the article, contains code and data, generates outputs, documents methods, and preserves reproducibility context.
Digital libraries also show why metadata matters. A document may be findable through search, but users still need to know its subject, creator, date, format, source, collection, authority, version, and relationship to other documents. Knowledge architecture extends metadata into a broader system of meaning and governance.
Research platforms become strongest when information architecture and knowledge architecture are aligned. The public interface, article map, metadata schema, repository structure, and semantic model should all tell the same story about how knowledge is organized.
AI-Assisted Systems and Semantic Retrieval
AI-assisted systems make the distinction between information architecture and knowledge architecture more important. Search, recommendation, summarization, and retrieval-augmented generation systems all depend on the structure of the knowledge environment. If that structure is shallow, inconsistent, or poorly governed, AI systems can retrieve or summarize information without preserving meaning.
Information architecture helps AI by providing page structure, headings, navigation labels, categories, and content organization. These signals matter. Clear headings, consistent article templates, strong titles, and meaningful sections improve retrieval and summarization.
Knowledge architecture adds deeper semantic signals. It can define article type, concept roles, related concepts, source provenance, metadata status, ontology classes, knowledge graph relationships, evidence links, and repository paths. These signals help AI systems distinguish conceptual overview from technical method, source from claim, synthetic data from empirical evidence, and related concept from equivalent concept.
For example, if an AI retrieval system knows that “Ontologies and Semantic Networks” is part of the Knowledge Architecture series, discusses RDF, OWL, SKOS, semantic relationships, and AI-assisted retrieval, cites W3C standards, and links to a repository folder, it can retrieve that article with richer context than a keyword search alone would provide.
AI can also assist knowledge architecture by suggesting relationships, detecting duplicate terms, identifying orphaned articles, clustering concepts, and checking metadata completeness. But these suggestions require human governance. Automated similarity is not the same as semantic equivalence. AI can help maintain the map, but it should not become the unreviewed author of the map.
RetrievalQuality = f(Text, Metadata, Taxonomy, Ontology, Graph, Governance)
\]
Interpretation: Retrieval quality improves when text is supported by metadata, taxonomy, ontology, graph relationships, and governance. Information architecture supports text and navigation; knowledge architecture strengthens semantic grounding.
Governance and Maintenance
Both information architecture and knowledge architecture require governance. Information architecture governance maintains navigation, labels, redirects, search filters, content types, and user pathways. Knowledge architecture governance maintains concepts, taxonomy rules, metadata schemas, ontology classes, relationship types, evidence links, repository structures, and revision histories.
Without governance, information architecture drifts. Menus become overloaded. Labels become inconsistent. Old pages remain in navigation. Duplicate categories appear. Search filters become unreliable. Users lose trust.
Without governance, knowledge architecture drifts even more deeply. Concepts change without documentation. Relationship types become vague. Metadata becomes incomplete. Sources detach from claims. Repository folders stop matching articles. Article maps no longer reflect the body of work. AI retrieval begins to operate on outdated or inconsistent structure.
| Governance Area | Information Architecture Focus | Knowledge Architecture Focus |
|---|---|---|
| Labels | Maintain clear navigation names. | Maintain preferred terms, alternate labels, and scope notes. |
| Categories | Keep browsing structure usable. | Maintain conceptual taxonomy and abstraction levels. |
| Metadata | Support search, display, and filtering. | Preserve provenance, evidence status, methods, versions, and semantic relationships. |
| Links | Maintain internal navigation and redirects. | Maintain typed relationships among articles, concepts, sources, data, and repositories. |
| Review cycles | Audit usability and content pathways. | Audit conceptual coherence, source traceability, and semantic integrity. |
| Versioning | Track navigation and content changes. | Track framework, taxonomy, ontology, repository, and relationship changes. |
Governance should not be treated as cleanup after growth. It is part of design. A serious knowledge system should assume that navigation, taxonomy, metadata, and relationships will change. The question is whether change will be documented, coherent, and accountable.
Mathematical and Computational Modeling
The difference between information architecture and knowledge architecture can be modeled computationally. Information architecture can be represented through navigation graphs, page hierarchies, search pathways, and user flows. Knowledge architecture can be represented through concept graphs, ontology schemas, metadata tables, evidence maps, repository manifests, and semantic networks.
These structures overlap, but they measure different things. A navigation graph may show whether users can move from a landing page to an article. A concept graph may show whether the article connects to a framework, source, repository, and related concepts. A complete system needs both.
IA_G = (P, N)
\]
Interpretation: An information-architecture graph \(IA_G\) can be represented as pages \(P\) and navigational links \(N\). It shows how users move through the information environment.
KA_G = (K, S)
\]
Interpretation: A knowledge-architecture graph \(KA_G\) can be represented as knowledge objects \(K\) and semantic relationships \(S\). It shows how meaning, evidence, and concepts connect.
Integration = \frac{|N \cap S|}{|S|}
\]
Interpretation: IA-KA integration can be approximated as the share of semantic relationships \(S\) that are visible or supported through navigational pathways \(N\). The measure is simplified, but it highlights the importance of making deep structure accessible.
ContextCoverage = \frac{|K_M|}{|K|}
\]
Interpretation: Context coverage measures the share of knowledge objects \(K\) with sufficient metadata \(K_M\). It helps evaluate whether a system preserves meaning beyond page-level navigation.
Computational diagnostics can help identify gaps between the two architectures. A page may be easy to reach but semantically isolated. A concept may be important but invisible in navigation. A repository may support an article but lack a visible link. An article may cite sources but lack evidence metadata. These gaps are where information architecture and knowledge architecture need better alignment.
Python Section: Comparing IA and KA Structures
The following Python example compares a simple information-architecture graph with a knowledge-architecture graph. It identifies pages that are navigationally connected but semantically underdeveloped, and knowledge objects that have semantic relationships but weak navigation support.
# ia_vs_ka_structure_audit.py
# Lightweight comparison of information architecture and knowledge architecture.
from pathlib import Path
import csv
from collections import defaultdict
ROOT = Path(".")
OUTPUTS = ROOT / "outputs"
OUTPUTS.mkdir(exist_ok=True)
pages = [
{"id": "publications", "label": "Publications", "type": "landing_page"},
{"id": "knowledge_architecture", "label": "Knowledge Architecture", "type": "article_map"},
{"id": "ia_vs_ka", "label": "Information Architecture vs. Knowledge Architecture", "type": "article"},
{"id": "taxonomy_design", "label": "Taxonomy Design for Knowledge Systems", "type": "article"},
{"id": "knowledge_graphs", "label": "Knowledge Graphs and Semantic Relationships", "type": "article"},
{"id": "repo_folder", "label": "Article Repository Folder", "type": "repository"},
]
navigation_links = [
("publications", "knowledge_architecture"),
("knowledge_architecture", "ia_vs_ka"),
("knowledge_architecture", "taxonomy_design"),
("knowledge_architecture", "knowledge_graphs"),
("ia_vs_ka", "repo_folder"),
]
semantic_relationships = [
("ia_vs_ka", "knowledge_architecture", "belongsToSeries"),
("ia_vs_ka", "taxonomy_design", "discussesRelatedArticle"),
("ia_vs_ka", "knowledge_graphs", "discussesRelatedArticle"),
("ia_vs_ka", "repo_folder", "supportedByRepository"),
("taxonomy_design", "knowledge_architecture", "belongsToSeries"),
("knowledge_graphs", "knowledge_architecture", "belongsToSeries"),
]
nav_degree = defaultdict(int)
semantic_degree = defaultdict(int)
for source, target in navigation_links:
nav_degree[source] += 1
nav_degree[target] += 1
for source, target, relationship in semantic_relationships:
semantic_degree[source] += 1
semantic_degree[target] += 1
with (OUTPUTS / "ia_ka_alignment_audit.csv").open("w", newline="", encoding="utf-8") as f:
writer = csv.writer(f)
writer.writerow([
"id",
"label",
"type",
"navigation_degree",
"semantic_degree",
"possible_alignment_issue"
])
for page in pages:
page_id = page["id"]
issue = ""
if nav_degree[page_id] > 0 and semantic_degree[page_id] == 0:
issue = "Navigable but semantically underdeveloped"
elif semantic_degree[page_id] > 0 and nav_degree[page_id] == 0:
issue = "Semantically connected but weakly visible in navigation"
elif nav_degree[page_id] == 0 and semantic_degree[page_id] == 0:
issue = "Isolated"
writer.writerow([
page_id,
page["label"],
page["type"],
nav_degree[page_id],
semantic_degree[page_id],
issue
])
with (OUTPUTS / "ia_navigation_links.csv").open("w", newline="", encoding="utf-8") as f:
writer = csv.writer(f)
writer.writerow(["source", "target"])
writer.writerows(navigation_links)
with (OUTPUTS / "ka_semantic_relationships.csv").open("w", newline="", encoding="utf-8") as f:
writer = csv.writer(f)
writer.writerow(["source", "target", "relationship"])
writer.writerows(semantic_relationships)
print("Wrote IA/KA alignment audit to outputs/")This example is intentionally simple. A full workflow could import article metadata, WordPress exports, repository manifests, internal-link tables, taxonomy records, and knowledge-graph relationships. The goal is to identify where visible navigation and deeper semantic structure are aligned or disconnected.
R Section: Auditing Navigational and Semantic Coverage
The following R example summarizes navigational coverage and semantic coverage for a small set of knowledge objects. It helps distinguish pages that are visible from pages that are meaningfully connected.
# ia_ka_coverage_audit.R
# Lightweight audit of navigational and semantic coverage.
objects <- data.frame(
id = c(
"publications",
"knowledge_architecture",
"ia_vs_ka",
"taxonomy_design",
"knowledge_graphs",
"repo_folder"
),
label = c(
"Publications",
"Knowledge Architecture",
"Information Architecture vs. Knowledge Architecture",
"Taxonomy Design for Knowledge Systems",
"Knowledge Graphs and Semantic Relationships",
"Article Repository Folder"
),
type = c(
"landing_page",
"article_map",
"article",
"article",
"article",
"repository"
),
has_navigation_path = c(TRUE, TRUE, TRUE, TRUE, TRUE, TRUE),
has_semantic_relationships = c(FALSE, TRUE, TRUE, TRUE, TRUE, TRUE),
has_metadata_context = c(TRUE, TRUE, TRUE, TRUE, TRUE, FALSE)
)
dir.create("outputs", showWarnings = FALSE)
type_summary <- as.data.frame(table(objects$type))
names(type_summary) <- c("object_type", "count")
coverage_summary <- data.frame(
object_count = nrow(objects),
navigation_coverage = mean(objects$has_navigation_path),
semantic_coverage = mean(objects$has_semantic_relationships),
metadata_context_coverage = mean(objects$has_metadata_context)
)
alignment_table <- within(objects, {
alignment_issue <- ifelse(
has_navigation_path & !has_semantic_relationships,
"Navigable but semantically underdeveloped",
ifelse(
has_semantic_relationships & !has_navigation_path,
"Semantic but weakly visible",
ifelse(
!has_metadata_context,
"Missing metadata context",
""
)
)
)
})
write.csv(type_summary, "outputs/object_type_summary.csv", row.names = FALSE)
write.csv(coverage_summary, "outputs/ia_ka_coverage_summary.csv", row.names = FALSE)
write.csv(alignment_table, "outputs/ia_ka_alignment_table.csv", row.names = FALSE)
print(type_summary)
print(coverage_summary)
print(alignment_table)R is useful for auditing information architecture and knowledge architecture together because it can summarize coverage, object types, metadata completeness, navigation visibility, and semantic relationship presence. These diagnostics can support editorial review and platform governance.
SQL Section: IA and KA Metadata Schema
SQL can support the distinction between information architecture and knowledge architecture by separating navigational structures from semantic structures. Pages, navigation links, and menus can be stored separately from concepts, relationship types, evidence sources, and repository relationships.
-- information_architecture_vs_knowledge_architecture_schema.sql
-- Minimal schema for comparing navigational IA structures with semantic KA structures.
CREATE TABLE IF NOT EXISTS information_objects (
object_id TEXT PRIMARY KEY,
title TEXT NOT NULL,
slug TEXT,
object_type TEXT NOT NULL,
status TEXT DEFAULT 'active'
);
CREATE TABLE IF NOT EXISTS navigation_links (
link_id INTEGER PRIMARY KEY,
source_object_id TEXT NOT NULL,
target_object_id TEXT NOT NULL,
navigation_type TEXT,
label TEXT,
sort_order INTEGER,
FOREIGN KEY (source_object_id) REFERENCES information_objects(object_id),
FOREIGN KEY (target_object_id) REFERENCES information_objects(object_id)
);
CREATE TABLE IF NOT EXISTS knowledge_concepts (
concept_id TEXT PRIMARY KEY,
preferred_label TEXT NOT NULL,
definition TEXT,
scope_note TEXT,
status TEXT DEFAULT 'active'
);
CREATE TABLE IF NOT EXISTS relationship_types (
relationship_type_id TEXT PRIMARY KEY,
label TEXT NOT NULL,
definition TEXT,
domain_type TEXT,
range_type TEXT,
status TEXT DEFAULT 'active'
);
CREATE TABLE IF NOT EXISTS semantic_relationships (
relationship_id INTEGER PRIMARY KEY,
source_object_id TEXT NOT NULL,
relationship_type_id TEXT NOT NULL,
target_object_id TEXT NOT NULL,
evidence_note TEXT,
status TEXT DEFAULT 'active',
FOREIGN KEY (source_object_id) REFERENCES information_objects(object_id),
FOREIGN KEY (relationship_type_id) REFERENCES relationship_types(relationship_type_id),
FOREIGN KEY (target_object_id) REFERENCES information_objects(object_id)
);
CREATE TABLE IF NOT EXISTS object_concepts (
object_id TEXT NOT NULL,
concept_id TEXT NOT NULL,
concept_role TEXT,
PRIMARY KEY (object_id, concept_id),
FOREIGN KEY (object_id) REFERENCES information_objects(object_id),
FOREIGN KEY (concept_id) REFERENCES knowledge_concepts(concept_id)
);
CREATE TABLE IF NOT EXISTS architecture_revisions (
revision_id INTEGER PRIMARY KEY,
architecture_layer TEXT NOT NULL,
object_id TEXT,
change_type TEXT NOT NULL,
change_note TEXT,
changed_at DATE
);This schema makes the distinction explicit. Information objects and navigation links support information architecture. Concepts, relationship types, semantic relationships, and concept roles support knowledge architecture. Revision records support governance across both layers.
A schema like this can help a research platform audit whether its visible navigation reflects its deeper knowledge structure. It can identify pages with navigation but no semantic metadata, concepts with no visible pathways, repository folders without article links, or related articles without typed relationships.
GitHub Repository
This article is supported by a companion repository folder with reproducible examples, small synthetic datasets, documentation, and language-specific modeling scaffolds for comparing information architecture and knowledge architecture.
Complete Code Repository
This folder contains companion research and code assets for the Information Architecture vs. Knowledge Architecture article, including Python, R, Julia, SQL, Rust, Go, C++, Fortran, C, documentation, data, and generated outputs.
The repository structure mirrors the article’s comparison between navigational and semantic design. Python supports IA/KA alignment audits. R supports coverage summaries and metadata diagnostics. SQL supports navigation objects, semantic relationships, concept assignments, and revision tracking. Systems-language folders provide space for validation utilities, graph-processing experiments, and reproducible tooling. Documentation, data, and outputs preserve the connection between interface structure, knowledge structure, and governance.
Quality Criteria for Integrated Design
A strong knowledge system should integrate information architecture and knowledge architecture. It should be easy to navigate and conceptually coherent. It should provide visible pathways and preserve deep relationships. It should help users find information and understand its place in a larger system.
Integrated design requires clarity, coherence, context, traceability, usability, and governance. Clarity means labels and concepts are understandable. Coherence means navigation and knowledge structure reinforce each other. Context means users can see where an object belongs. Traceability means sources, methods, repositories, and evidence relationships are preserved. Usability means people can move through the system. Governance means the structure can be maintained.
| Quality Criterion | Evaluation Question | Warning Sign |
|---|---|---|
| Navigational clarity | Can users find the material? | Menus, labels, or pathways are confusing. |
| Conceptual coherence | Does the structure reflect the knowledge domain? | Categories are usable but intellectually arbitrary. |
| Semantic depth | Are relationships typed and meaningful? | Everything is linked only as “related.” |
| Metadata context | Does each object carry enough interpretive context? | Articles, datasets, and repositories lack status, source, or relationship metadata. |
| Repository alignment | Do code and data structures support the article structure? | Repository folders exist but are not linked or documented. |
| Governance | Can both navigation and semantic structure be maintained? | No review process exists for labels, categories, metadata, or relationships. |
The best systems do not force users to choose between usability and depth. They use information architecture to make knowledge architecture approachable, and knowledge architecture to make information architecture meaningful.
Interpretive Cautions and Ethical Limits
Information architecture and knowledge architecture both shape what users see. Menus, labels, categories, article maps, taxonomies, metadata fields, ontologies, and knowledge graphs are not neutral in a simplistic sense. They influence what appears central, what appears peripheral, what is easy to find, what is difficult to find, and what relationships seem natural.
Information architecture can hide knowledge through poor labels, buried navigation, or shallow categories. Knowledge architecture can hide knowledge through narrow taxonomies, rigid ontologies, missing metadata, or biased relationship structures. Both can reproduce institutional assumptions if they are not reviewed critically.
This matters especially for marginalized knowledge, interdisciplinary concepts, historical injustice, cultural traditions, and contested categories. A navigation system may make dominant topics easy to find while pushing alternative perspectives into vague categories. A knowledge graph may overrepresent well-documented sources while making archival silences look like absence. An ontology may formalize disputed categories as if they were settled.
Responsible architecture should therefore include scope notes, provenance, alternative terms, revision history, contested-category documentation, and periodic review. It should make its categories and relationships inspectable. It should preserve complexity without surrendering to disorder.
The goal is not to avoid structure. Without structure, knowledge becomes inaccessible. The goal is to design structures that remain transparent, revisable, and accountable.
Why the Two Architectures Belong Together
Information architecture and knowledge architecture belong together because people need both access and meaning. A system that is easy to navigate but conceptually weak will eventually become shallow. A system that is conceptually rich but difficult to use will remain inaccessible. Serious knowledge systems need visible pathways and deep structure.
Information architecture helps users move. Knowledge architecture helps users understand. Information architecture organizes the interface. Knowledge architecture organizes the intellectual system beneath it. Information architecture improves findability. Knowledge architecture preserves relationships, evidence, provenance, and coherence.
For research platforms, digital libraries, educational systems, AI-assisted retrieval environments, and public knowledge projects, this integration is essential. Article maps need clear navigation. Taxonomies need scope and governance. Metadata needs display and retrieval pathways. Repositories need visible links and semantic context. Knowledge graphs need human-readable interfaces.
At their best, information architecture and knowledge architecture form a single layered practice. The visible system helps users navigate. The deeper system preserves meaning. Together, they turn content into a durable knowledge environment: findable, interpretable, traceable, revisable, and capable of growth.
Related Articles
- Foundations of Knowledge Architecture
- What Is Knowledge Architecture?
- Taxonomy Design for Knowledge Systems
- Hierarchical Knowledge Structures
- Ontologies and Semantic Networks
- Knowledge Graphs and Semantic Relationships
- Knowledge Mapping and Conceptual Models
Further Reading
- Allemang, D. and Hendler, J. (2011) Semantic Web for the Working Ontologist: Effective Modeling in RDFS and OWL. 2nd edn. Amsterdam: Morgan Kaufmann.
- Aitchison, J., Gilchrist, A. and Bawden, D. (2000) Thesaurus Construction and Use: A Practical Manual. 4th edn. London: Aslib.
- Hedden, H. (2016) The Accidental Taxonomist. 2nd edn. Medford, NJ: Information Today.
- Hinton, A. (2014) Understanding Context: Environment, Language, and Information Architecture. Sebastopol, CA: O’Reilly.
- Lambe, P. (2007) Organising Knowledge: Taxonomies, Knowledge and Organisational Effectiveness. Oxford: Chandos Publishing.
- Morville, P. and Rosenfeld, L. (2006) Information Architecture for the World Wide Web. 3rd edn. Sebastopol, CA: O’Reilly.
- Sowa, J.F. (2000) Knowledge Representation: Logical, Philosophical, and Computational Foundations. Pacific Grove, CA: Brooks/Cole.
References
- Allemang, D. and Hendler, J. (2011) Semantic Web for the Working Ontologist: Effective Modeling in RDFS and OWL. 2nd edn. Amsterdam: Morgan Kaufmann.
- Aitchison, J., Gilchrist, A. and Bawden, D. (2000) Thesaurus Construction and Use: A Practical Manual. 4th edn. London: Aslib.
- Hodge, G. (2000) Systems of Knowledge Organization for Digital Libraries: Beyond Traditional Authority Files. Washington, DC: Council on Library and Information Resources. Available at: https://www.clir.org/pubs/reports/pub91/
- International Organization for Standardization (2011) ISO 25964-1: Information and Documentation — Thesauri and Interoperability with Other Vocabularies — Part 1: Thesauri for Information Retrieval. Available at: https://www.iso.org/standard/53657.html
- International Organization for Standardization (2013) ISO 25964-2: Information and Documentation — Thesauri and Interoperability with Other Vocabularies — Part 2: Interoperability with Other Vocabularies. Available at: https://www.iso.org/standard/53658.html
- Morville, P. and Rosenfeld, L. (2006) Information Architecture for the World Wide Web. 3rd edn. Sebastopol, CA: O’Reilly.
- National Information Standards Organization (2010) Guidelines for the Construction, Format, and Management of Monolingual Controlled Vocabularies. Available at: https://www.niso.org/publications/ansiniso-z3919-2005-r2010
- RDF Working Group (2014) RDF 1.1 Concepts and Abstract Syntax. W3C Recommendation. Available at: https://www.w3.org/TR/rdf11-concepts/
- SKOS Working Group (2009) SKOS Simple Knowledge Organization System Reference. W3C Recommendation. Available at: https://www.w3.org/TR/skos-reference/
- Sowa, J.F. (2000) Knowledge Representation: Logical, Philosophical, and Computational Foundations. Pacific Grove, CA: Brooks/Cole.