
Last Updated June 18, 2026
Consensus, coordination, and fault tolerance explain how distributed systems continue to make decisions when machines fail, messages are delayed, replicas disagree, networks partition, leaders crash, and no participant can see the whole system at once. These ideas sit at the heart of reliable networked computation because distributed systems cannot depend on a single perfect authority, a single synchronized clock, or a single always-available machine.
Consensus asks how multiple nodes can agree on a value, order, leader, log entry, configuration, or state transition. Coordination asks how nodes organize work, assign responsibility, sequence updates, avoid conflict, and recover from uncertainty. Fault tolerance asks how the system preserves useful behavior when some components fail.
Together, these ideas shape replicated databases, distributed logs, cloud services, search systems, AI retrieval infrastructure, workflow orchestration, distributed storage, sensor networks, blockchains, peer-to-peer systems, and high-availability platforms. They show that reliability is not merely about preventing failure. It is about designing systems that know what failure means, what agreement requires, what progress depends on, and what guarantees can honestly be promised.
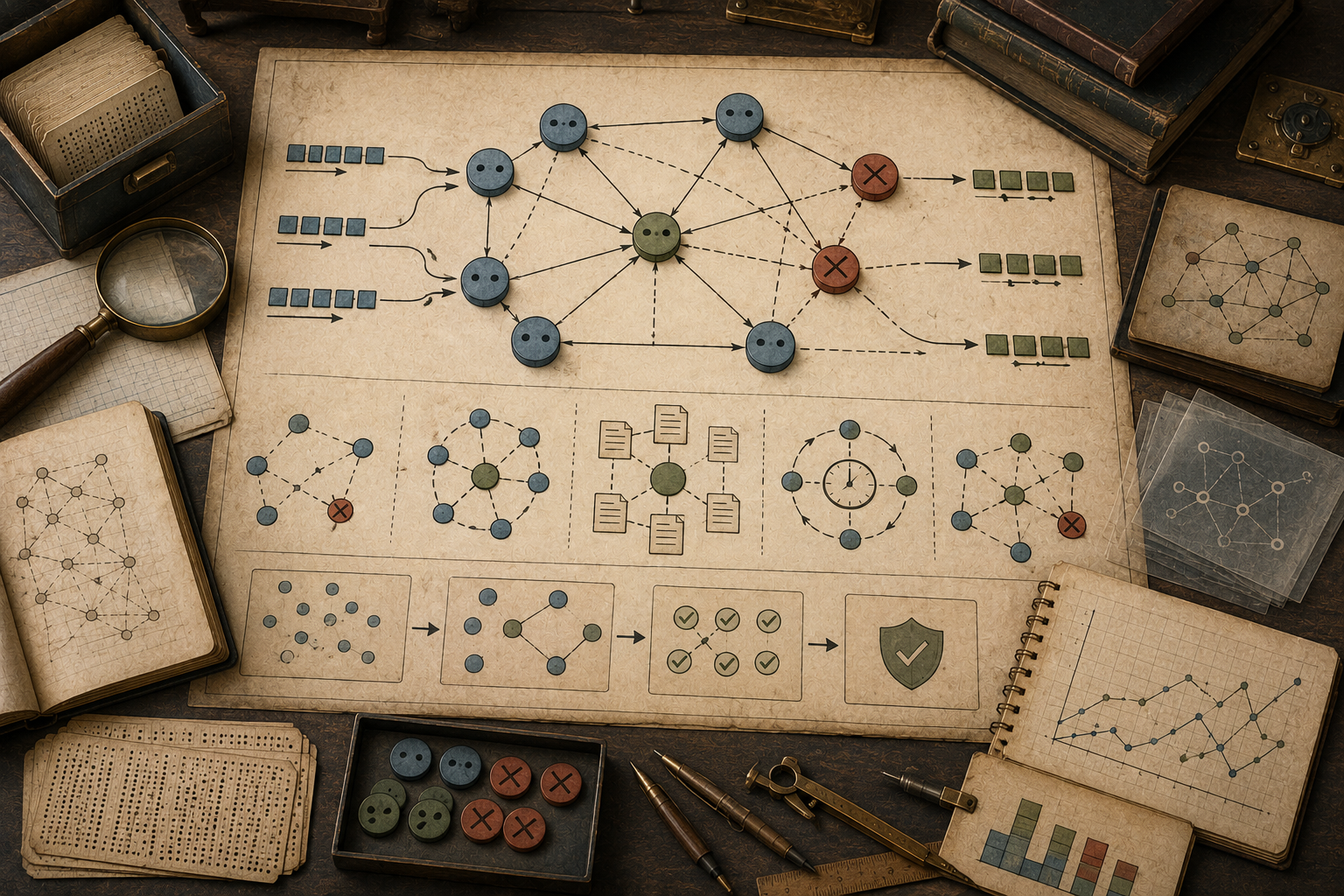
This article explains consensus, coordination, fault tolerance, quorum systems, leader election, replicated logs, state-machine replication, crash failures, Byzantine failures, network partitions, partial synchrony, safety, liveness, availability, consistency, failover, recovery, idempotent retries, fencing, split-brain prevention, distributed locks, observability, provenance, and governance. It emphasizes a central point: fault-tolerant computation is not the absence of failure. It is disciplined behavior in the presence of failure.
Why Consensus, Coordination, and Fault Tolerance Matter
Consensus, coordination, and fault tolerance matter because distributed systems cannot assume perfect communication or perfect control. A single-machine algorithm can often treat memory, time, and execution order as local concerns. A distributed system must reason about many local states connected by unreliable communication.
A replicated database must decide whether a write is committed. A distributed queue must decide whether a message has been processed. A search system must decide whether partial shard failure should be shown to users. An AI retrieval system must decide whether evidence, embeddings, source metadata, and generated output came from compatible versions. A cloud platform must decide which node is leader. A monitoring system must decide whether silence means failure or delay.
| System problem | Consensus or coordination question | Why it matters |
|---|---|---|
| Replicated write | Have enough replicas accepted the update? | Prevents disagreement about committed state. |
| Leader failure | Who is allowed to coordinate next? | Prevents no leader or multiple leaders. |
| Partial network outage | Should isolated nodes continue accepting writes? | Prevents split-brain conflicts. |
| Distributed queue | Was the task completed or should it retry? | Prevents lost or duplicated work. |
| Search shard failure | Is the result complete enough to publish? | Prevents hidden partial outputs. |
| AI retrieval pipeline | Are source, index, model, and log versions aligned? | Prevents unsupported or inconsistent responses. |
| Incident recovery | What happened, in what order, and who owned the failed state? | Supports accountability and repair. |
These are not merely engineering details. They are algorithmic and institutional decisions about what counts as agreement, progress, reliability, and evidence.
What Consensus Means
Consensus is the problem of getting distributed nodes to agree on something despite uncertainty. The agreed object may be a value, a command, a leader, a configuration, a log entry, or the order of operations.
Consensus matters because distributed systems often need one coherent decision even when participants only have local information. The system must prevent conflicting decisions while still making progress when possible.
| Consensus property | Meaning | Example |
|---|---|---|
| Agreement | Correct nodes decide the same value. | Replicas commit the same operation. |
| Validity | The chosen value was legitimately proposed. | Committed command came from an authorized request. |
| Integrity | A node decides at most once. | Replica does not commit two different values for same log index. |
| Termination | Correct nodes eventually decide under suitable assumptions. | Cluster elects leader after failure. |
| Ordering | Nodes apply decisions in compatible sequence. | Replicated log entries share same order. |
| Durability | Decision survives failures after commitment. | Write remains after leader crash. |
Consensus is difficult because nodes cannot always distinguish between a failed node, a slow node, a delayed message, and a network partition.
What Coordination Means
Coordination is broader than consensus. Coordination includes all the ways distributed components organize shared work: assigning tasks, routing messages, selecting leaders, acquiring locks, sequencing updates, joining results, rebalancing load, managing membership, recovering from failure, and publishing outputs.
Some coordination requires consensus. Some coordination can use weaker mechanisms such as leases, queues, gossip, partitioned ownership, idempotent retries, or eventual reconciliation.
| Coordination task | Question | Possible mechanism |
|---|---|---|
| Task assignment | Which worker owns which job? | Queue, lease, scheduler, partition map. |
| Leadership | Who coordinates a shard or cluster? | Leader election. |
| Exclusive access | Who may update shared resource? | Lock, transaction, lease, single-writer rule. |
| Ordering | What sequence should operations follow? | Replicated log or logical clock. |
| Membership | Which nodes are active? | Heartbeat, gossip, registry, consensus group. |
| Failover | Who takes over after failure? | Quorum election or standby replica. |
| Publication | When is output safe to expose? | Atomic snapshot and validation gate. |
Coordination should be minimized when possible, because coordination is expensive. But coordination should not be avoided when correctness depends on it.
What Fault Tolerance Means
Fault tolerance is the ability of a system to continue providing useful behavior when some components fail. It does not mean the system never fails. It means failures are anticipated, bounded, detected, isolated, recovered from, and communicated honestly.
Fault tolerance depends on failure assumptions. A system designed for crash failures may not tolerate malicious nodes. A system designed for local disk failure may not tolerate regional network partitions. A system designed for retryable tasks may not tolerate non-idempotent side effects.
| Fault-tolerance concern | Question | Design artifact |
|---|---|---|
| Failure detection | How does the system suspect failure? | Heartbeats, timeouts, health checks. |
| Failure containment | Can one failure corrupt other components? | Isolation, transactions, staging. |
| Redundancy | Are there backup nodes or replicas? | Replication, standby workers, queues. |
| Recovery | How does failed work resume? | Checkpoint, retry, replay, failover. |
| Consistency preservation | Can replicas diverge dangerously? | Quorum, consensus, reconciliation. |
| Degraded mode | Can the system provide limited service? | Read-only mode, partial result disclosure. |
| Auditability | Can failure and recovery be reconstructed? | Logs, traces, versioned state. |
A fault-tolerant system is not just redundant. It has a disciplined theory of what failures are possible and how the system should behave when they occur.
Failure Models
A failure model states what kinds of failures the algorithm assumes. This is one of the most important parts of distributed-system design. If the failure model is wrong, the reliability claim is wrong.
Crash failures are different from network partitions. Omission failures are different from Byzantine failures. Slow responses are different from missing responses. A retryable internal service is different from an untrusted external node.
| Failure model | Meaning | Example |
|---|---|---|
| Crash failure | Node stops operating. | Server process exits. |
| Omission failure | Message is not sent or received. | Packet dropped or event lost. |
| Timing failure | Node or message is too slow. | Response exceeds timeout. |
| Partition failure | Groups of nodes cannot communicate. | Regional network split. |
| Restart failure | Node returns with stale or partial state. | Worker restarts after incomplete write. |
| Byzantine failure | Node behaves arbitrarily or maliciously. | Compromised node sends conflicting messages. |
| Operator failure | Configuration or deployment causes inconsistency. | Mixed-version cluster after rollout. |
| Dependency failure | External service becomes unreliable. | Model endpoint or API intermittently fails. |
A system should not claim to tolerate failures it has not modeled.
Safety, Liveness, and Availability
Distributed algorithms are often evaluated through safety and liveness. Safety means “nothing bad happens.” Liveness means “something good eventually happens.” Availability means the system can continue responding to requests.
These goals can conflict. A system may preserve safety by refusing to proceed during uncertainty. A system may improve availability by accepting operations that later require reconciliation.
| Property | Meaning | Example |
|---|---|---|
| Safety | Bad states are avoided. | No two leaders commit conflicting writes. |
| Liveness | Progress eventually occurs. | A new leader is eventually elected. |
| Availability | Requests receive responses. | Database continues serving reads. |
| Durability | Committed decisions survive failure. | Write persists after crash. |
| Consistency | Replicas obey stated agreement rules. | Reads reflect chosen consistency model. |
| Recoverability | System can return to valid operation. | Failed node replays log and rejoins. |
Reliable design requires clarity about which properties are guaranteed, under which assumptions, and during which failures.
Quorums and Majority Agreement
A quorum is a subset of nodes large enough to make or confirm a decision. Majority quorums are common because two majorities overlap. That overlap helps preserve consistency: a later majority can encounter evidence of an earlier majority decision.
Quorums allow systems to tolerate some failures without waiting for every node. If a cluster has five nodes, a majority quorum is three. The system can often tolerate two crash failures while still preserving majority-based decision-making.
| Cluster size | Majority quorum | Crash failures tolerated under majority |
|---|---|---|
| 3 | 2 | 1 |
| 5 | 3 | 2 |
| 7 | 4 | 3 |
| 9 | 5 | 4 |
Quorums do not make failure disappear. They define how much agreement is enough to proceed safely under a stated failure model.
Leader Election and Terms
Many consensus systems use a leader to coordinate decisions. The leader proposes log entries, accepts client requests, sends heartbeats, and helps maintain a coherent order. If the leader fails, the system must elect a new one.
Leader election is difficult because nodes may disagree about whether the leader has failed. A slow network can make a live leader look dead. A partition can isolate nodes and cause competing leadership claims. Terms, epochs, leases, fencing tokens, and quorum rules help prevent stale leaders from continuing to act.
| Leadership issue | Risk | Control |
|---|---|---|
| Leader crash | No node coordinates writes. | Timeout and election. |
| False suspicion | Healthy leader appears failed. | Conservative timeout and quorum confirmation. |
| Split brain | Two leaders accept conflicting writes. | Majority quorum, terms, fencing. |
| Stale leader | Old leader acts after replacement. | Term checks and write rejection. |
| Election storm | Repeated elections prevent progress. | Randomized election timeouts. |
| Leader bottleneck | Coordinator limits throughput. | Sharding, partitioned leadership, batching. |
A leader is useful only if the system can prove who the leader is allowed to be.
Replicated Logs and State Machines
State-machine replication is a foundational pattern in fault-tolerant distributed systems. The idea is simple: if multiple replicas start from the same state and apply the same operations in the same order, they reach the same state.
A replicated log records the ordered sequence of operations. Consensus protocols often focus on ensuring that replicas agree on this log, even when leaders fail or messages delay.
| Replicated-log concept | Meaning | Why it matters |
|---|---|---|
| Log entry | Operation proposed for ordered execution. | Defines what replicas should apply. |
| Log index | Position in operation sequence. | Prevents conflicting operations at same position. |
| Term or epoch | Leadership generation marker. | Rejects stale leadership. |
| Commit point | Entry accepted enough to apply. | Separates tentative from durable decision. |
| State machine | Deterministic application of operations. | Replicas converge when logs match. |
| Snapshot | Compact representation of current state. | Reduces replay cost. |
| Replay | Rebuild state from log. | Supports recovery after crash. |
Replicated logs convert distributed uncertainty into an ordered record that can be inspected, replayed, and governed.
Network Partitions and Split Brain
A network partition occurs when some nodes cannot communicate with others. Partitions are dangerous because each side may continue operating with partial knowledge. If both sides accept conflicting writes, the system may enter split brain.
Split brain is not merely a technical inconvenience. It can create two versions of institutional reality: two leaders, two states, two histories, two answers, or two sets of decisions.
| Partition scenario | Risk | Safer response |
|---|---|---|
| Minority partition isolated | Minority accepts writes it cannot commit safely. | Minority refuses writes or enters read-only mode. |
| Two leaders appear | Conflicting writes are accepted. | Require majority quorum for leadership. |
| Stale cache survives partition | Users see old data as current. | Expose freshness and invalidation status. |
| Search shards unavailable | Results appear complete but omit data. | Show partial-result status. |
| AI retrieval store partitioned | Generated answer uses incomplete evidence. | Fail closed or disclose retrieval incompleteness. |
| Monitoring partitioned | Incidents hidden by missing telemetry. | Track telemetry gaps as incidents. |
A partition-tolerant design must define what the system does when it cannot know enough.
Timeouts, Heartbeats, and Failure Detection
Distributed systems often use heartbeats and timeouts to suspect failure. A heartbeat is a periodic signal that a node is alive. A timeout is a threshold after which another node suspects that communication has failed.
Failure detection is imperfect. A timeout does not prove failure. It proves only that a response did not arrive within the expected time. The system must treat suspicion carefully.
| Failure-detection artifact | Purpose | Risk |
|---|---|---|
| Heartbeat | Signal liveness. | Delayed heartbeat may falsely suggest failure. |
| Timeout | Bound waiting time. | Too short causes false elections; too long slows recovery. |
| Health check | Assess node readiness. | Can miss logical corruption. |
| Lease | Grant temporary authority. | Clock assumptions can be dangerous. |
| Failure detector | Abstract suspicion mechanism. | May be unreliable under asynchrony. |
| Backoff | Reduce repeated retry pressure. | Can delay recovery if too conservative. |
Failure detection is not certainty. It is managed uncertainty.
Retries, Idempotence, and Exactly-Once Illusions
Retries are necessary because distributed operations fail often. A message may be lost. A service may time out. A worker may crash after completing work but before acknowledging completion. Retrying can restore progress, but retries can also duplicate effects.
Idempotence means an operation can be safely repeated without changing the result beyond the first successful application. Idempotent design is often more reliable than trying to guarantee that an operation happens exactly once.
| Retry problem | Example | Control |
|---|---|---|
| Duplicate write | Retry creates two records. | Idempotency key. |
| Lost acknowledgment | Task completed but appears failed. | Durable completion log. |
| Partial side effect | External action succeeded before crash. | Transactional outbox or compensation. |
| Retry storm | Many clients retry at once. | Exponential backoff and jitter. |
| Out-of-order retry | Old request arrives after newer one. | Sequence numbers or version checks. |
| Hidden duplication | Output appears successful but includes duplicates. | Deduplication and audit checks. |
In distributed systems, “exactly once” is often a misleading phrase unless the system clearly defines the boundaries, logs, state transitions, and external side effects involved.
Byzantine Fault Tolerance and Adversarial Coordination
Byzantine failures occur when nodes behave arbitrarily, inconsistently, or maliciously. A Byzantine node may send different messages to different participants, lie about state, replay old messages, withhold information, or collude with other faulty nodes.
Byzantine fault tolerance is important in adversarial or low-trust environments. It is more expensive than crash fault tolerance because the system must defend against conflicting and deceptive behavior, not merely silence or delay.
| Failure type | Node behavior | Design implication |
|---|---|---|
| Crash failure | Node stops. | Replicas and majority quorums may be sufficient. |
| Omission failure | Node misses or drops messages. | Acknowledgments and retransmission help. |
| Timing failure | Node responds too slowly. | Timeouts and partial synchrony assumptions matter. |
| Byzantine failure | Node may lie or behave inconsistently. | Requires stronger protocols and more replicas. |
| Adversarial coordination | Multiple faulty nodes collude. | Requires trust, cryptography, and fault thresholds. |
Byzantine tolerance forces a harder question: what if the system’s participants are not merely unreliable, but untrustworthy?
Consistency, Availability, and the CAP Tradeoff
The CAP theorem is often summarized as a tradeoff between consistency, availability, and partition tolerance. The careful interpretation is that when a network partition occurs, a distributed data system must choose between preserving certain consistency guarantees and remaining available for all operations.
This does not mean systems simply choose two letters forever. It means partition behavior must be specified. During partitions, some systems refuse writes to preserve consistency. Others accept writes and reconcile later. Some expose stale reads. Some degrade service.
| Choice during partition | Benefit | Risk |
|---|---|---|
| Prefer consistency | Avoids conflicting committed state. | Some requests may fail or block. |
| Prefer availability | System keeps accepting requests. | Replicas may diverge and need reconciliation. |
| Read-only mode | Allows limited service safely. | Users cannot update state. |
| Degraded mode | Preserves some user value. | Requires clear disclosure of limits. |
| Fail closed | Prevents unsafe action. | May reduce usability or throughput. |
| Fail open | Maintains activity. | May cause unsupported decisions. |
The practical governance question is: what does the system promise when the network is unreliable?
Coordination in Data, AI, and Search Systems
Consensus and fault tolerance are not limited to database internals. They matter throughout modern data, AI, and search systems.
A search index may need snapshot publication so users do not see mixed versions. An AI retrieval system may need coordination between document store, vector index, prompt construction, model version, and citation logs. A data pipeline may require coordination between partition validation and publication. A knowledge graph may require consistency between entities, edges, source claims, and provenance records.
| System | Coordination issue | Fault-tolerance concern |
|---|---|---|
| Search index | Shard versions must align. | Partial shard failure changes results. |
| AI retrieval | Document, embedding, model, and citation versions must match. | Unavailable evidence store may produce unsupported answer. |
| Data pipeline | All required partitions must pass validation before publication. | Failed worker may leave partial output. |
| Knowledge graph | Entity and edge updates must preserve provenance. | Replica lag may change graph traversal. |
| Feature store | Training and serving features must align. | Stale online features distort predictions. |
| Distributed dashboard | Metrics arrive from many services. | Missing telemetry may look like normal operation. |
| Workflow orchestrator | Task status must be reliable across retries. | Duplicate execution can corrupt outputs. |
Coordination failures often look like reasoning failures because the final output hides the distributed path that produced it.
Observability, Debugging, and Incident Reconstruction
Consensus and fault tolerance require observability. A distributed incident cannot be understood from one local log. It requires traces, message IDs, request IDs, term numbers, leader history, quorum participation, replica versions, retry logs, timeout records, partition evidence, and publication metadata.
Debugging consensus failures is difficult because the root cause may involve timing: a delayed heartbeat, a stale leader, a lost acknowledgment, a partition, a disk stall, or a rolling deployment.
| Observability artifact | Question answered | Example |
|---|---|---|
| Trace ID | Which services handled the request? | End-to-end request path. |
| Term or epoch | Which leadership generation was active? | Reject stale leader writes. |
| Quorum record | Which nodes accepted the decision? | Write committed by replicas A, C, D. |
| Replica version | Which state did a node use? | Index snapshot v42. |
| Retry log | Was work repeated? | Message processed after timeout retry. |
| Partition evidence | Which links failed? | Nodes in region A could not reach region B. |
| Recovery log | How did the system return to service? | Replay, failover, leader election, reconciliation. |
| Governance note | Who reviewed the incident? | Post-incident root-cause analysis. |
A fault-tolerant system should not merely survive failure. It should leave enough evidence to understand the failure.
Governance and Accountability
Consensus and coordination create governance questions because they define who or what is authorized to decide. A leader can accept writes. A quorum can commit state. A lock can grant exclusive access. A failover process can redirect traffic. A recovery workflow can replay operations. A degraded-mode policy can decide what users see.
These decisions must be owned, documented, and reviewed.
| Governance concern | Question | Artifact |
|---|---|---|
| Decision authority | Who or what is allowed to commit state? | Consensus and leadership policy. |
| Failure assumptions | What failures are tolerated? | Failure model document. |
| Partition behavior | What happens when nodes cannot communicate? | Partition-mode policy. |
| Recovery ownership | Who approves replay, failover, or reconciliation? | Runbook and escalation path. |
| User disclosure | Are partial results or degraded guarantees visible? | Status and completeness indicators. |
| Security boundary | Can untrusted nodes affect consensus? | Authentication, authorization, signing. |
| Auditability | Can committed decisions be reconstructed? | Logs, traces, quorum records, versions. |
Distributed governance is the institutional layer of fault tolerance.
Representation Risk
Representation risk appears when a consensus or fault-tolerance mechanism is treated as proof of truth rather than proof of agreement under assumptions. Consensus can show that nodes agreed on a log entry. It does not prove that the input data was valid, the user request was ethical, the model output was correct, or the governance policy was sufficient.
Coordination mechanisms can also hide partial failure. A system may report success because a quorum accepted a write, while minority replicas lag. A dashboard may look current while a telemetry partition hides missing events. An AI system may present a confident answer while retrieval degraded silently.
| Representation risk | How it appears | Review response |
|---|---|---|
| Agreement mistaken for truth | Consensus treated as factual correctness. | Separate agreement from source validity. |
| Quorum hides minority failure | Committed state masks unavailable replicas. | Expose replica health and lag. |
| Leader authority overtrusted | Leader decision treated as legitimate without authorization review. | Audit leadership and access controls. |
| Partial result appears complete | System returns output despite failed components. | Show completeness and degraded-mode status. |
| Retry success hides duplication | Operation eventually succeeds but duplicates side effects. | Use idempotency keys and deduplication logs. |
| Fault tolerance hides fragility | System survives small failure but not modeled failure. | Declare failure model explicitly. |
| Recovery rewrites history | Reconciliation changes state without visible explanation. | Preserve recovery logs and versioned artifacts. |
Reliable representation requires stating not only what the system decided, but under what assumptions, with which nodes, by which protocol, and with what evidence.
Examples Across Distributed Systems
The examples below show how consensus, coordination, and fault tolerance appear across databases, queues, search, AI, cloud systems, and distributed knowledge infrastructure.
Replicated database commit
A write is committed only after a quorum of replicas records it, protecting durability under crash failure.
Leader election
Nodes elect a leader after heartbeat timeout, using terms and quorum rules to prevent stale leadership.
Distributed queue retry
A worker crashes after partial work, so the message is retried with an idempotency key and completion log.
Search index publication
A new index snapshot becomes visible only when required shards pass validation and publish atomically.
AI retrieval failover
A vector index is unavailable, so the system fails closed or discloses incomplete retrieval rather than fabricating evidence.
Workflow orchestration
A pipeline coordinator tracks task status, retries failed partitions, and prevents duplicate publication.
Split-brain prevention
A minority partition refuses writes because it cannot reach a majority quorum.
Incident reconstruction
Trace IDs, term numbers, quorum records, and replica versions reveal why a distributed decision failed.
Across these examples, consensus is not simply a protocol. It is a way of preserving coherent decision-making under uncertainty.
Mathematics, Computation, and Modeling
A distributed consensus group can be represented as a set of nodes:
N = \{n_1, n_2, \ldots, n_k\}
\]
Interpretation: The system contains \(k\) nodes that may communicate, fail, vote, replicate state, or participate in agreement.
A majority quorum can be represented as:
q = \left\lfloor \frac{k}{2} \right\rfloor + 1
\]
Interpretation: Majority decision requires more than half of the nodes.
Crash fault tolerance under majority agreement can be approximated as:
f = \left\lfloor \frac{k-1}{2} \right\rfloor
\]
Interpretation: A majority-based cluster with \(k\) nodes can tolerate up to \(f\) crash failures while maintaining quorum availability.
A quorum intersection condition can be represented as:
Q_i \cap Q_j \neq \varnothing
\]
Interpretation: Quorum overlap helps carry information from one decision to another.
A replicated state-machine transition can be represented as:
s_{t+1} = apply(s_t, op_t)
\]
Interpretation: If replicas begin with the same state and apply the same ordered operations, they reach the same state.
A safety property can be stated abstractly as:
\forall i,j,\ decided_i(v) \land decided_j(w) \Rightarrow v = w
\]
Interpretation: If two correct nodes decide values, those values must agree.
A liveness property can be stated abstractly as:
\Diamond decided(v)
\]
Interpretation: Eventually, under appropriate assumptions, a decision should be reached.
A Byzantine fault-tolerant threshold is often expressed as:
k \geq 3f + 1
\]
Interpretation: Many Byzantine fault-tolerant protocols require at least \(3f+1\) replicas to tolerate \(f\) Byzantine faults.
These mathematical forms simplify real protocols, but they capture the fundamental logic: agreement depends on nodes, quorums, intersections, state transitions, safety, liveness, and failure thresholds.
Python Workflow: Consensus and Fault-Tolerance Audit
The Python workflow below creates a dependency-light audit for consensus, coordination, and fault tolerance. It scores agreement clarity, quorum design, failure model, leader election, log replication, partition behavior, retry discipline, observability, recovery, security, governance, and communication clarity.
# consensus_fault_tolerance_audit.py
# Dependency-light workflow for auditing consensus, coordination, and fault tolerance.
from __future__ import annotations
from dataclasses import asdict, dataclass
from pathlib import Path
import csv
import json
from statistics import mean
ARTICLE_ROOT = Path(__file__).resolve().parents[1]
TABLES = ARTICLE_ROOT / "outputs" / "tables"
JSON_DIR = ARTICLE_ROOT / "outputs" / "json"
@dataclass(frozen=True)
class ConsensusCase:
case_name: str
system_context: str
coordination_goal: str
agreement_clarity: float
quorum_design: float
failure_model: float
leader_election: float
log_replication: float
partition_behavior: float
retry_idempotence: float
observability: float
recovery_design: float
security_trust: float
governance_review: float
communication_clarity: float
def clamp(value: float, low: float = 0.0, high: float = 100.0) -> float:
return max(low, min(high, value))
def consensus_reliability_score(case: ConsensusCase) -> float:
return clamp(
100.0 * (
0.10 * case.agreement_clarity
+ 0.10 * case.quorum_design
+ 0.11 * case.failure_model
+ 0.09 * case.leader_election
+ 0.09 * case.log_replication
+ 0.10 * case.partition_behavior
+ 0.09 * case.retry_idempotence
+ 0.10 * case.observability
+ 0.08 * case.recovery_design
+ 0.06 * case.security_trust
+ 0.05 * case.governance_review
+ 0.03 * case.communication_clarity
)
)
def consensus_risk(case: ConsensusCase) -> float:
weak_points = [
1.0 - case.agreement_clarity,
1.0 - case.quorum_design,
1.0 - case.failure_model,
1.0 - case.leader_election,
1.0 - case.partition_behavior,
1.0 - case.retry_idempotence,
1.0 - case.observability,
1.0 - case.recovery_design,
1.0 - case.governance_review,
]
return clamp(100.0 * mean(weak_points))
def diagnose(score: float, risk: float) -> str:
if score >= 84 and risk <= 20:
return "strong consensus, coordination, and fault-tolerance discipline"
if score >= 70 and risk <= 35:
return "usable coordination design with review needs"
if risk >= 55:
return "high risk; weak agreement, partition behavior, retries, recovery, or observability may create unreliable distributed decisions"
return "partial discipline; strengthen quorum design, failure modeling, partition behavior, idempotence, observability, recovery, and governance"
def build_cases() -> list[ConsensusCase]:
return [
ConsensusCase(
case_name="Replicated database commit",
system_context="A write is committed only after a quorum of replicas records it.",
coordination_goal="preserve durable committed state under crash failure",
agreement_clarity=0.88,
quorum_design=0.90,
failure_model=0.86,
leader_election=0.84,
log_replication=0.88,
partition_behavior=0.84,
retry_idempotence=0.82,
observability=0.82,
recovery_design=0.84,
security_trust=0.78,
governance_review=0.76,
communication_clarity=0.78,
),
ConsensusCase(
case_name="Search index snapshot publication",
system_context="A new index snapshot becomes visible only when required shards pass validation and publish atomically.",
coordination_goal="prevent users from seeing mixed or partial index versions",
agreement_clarity=0.82,
quorum_design=0.74,
failure_model=0.78,
leader_election=0.68,
log_replication=0.70,
partition_behavior=0.78,
retry_idempotence=0.84,
observability=0.80,
recovery_design=0.78,
security_trust=0.74,
governance_review=0.78,
communication_clarity=0.76,
),
ConsensusCase(
case_name="AI retrieval fail-closed policy",
system_context="A retrieval store becomes unavailable and the system blocks or discloses incomplete retrieval rather than producing unsupported output.",
coordination_goal="preserve evidence integrity during retrieval failure",
agreement_clarity=0.78,
quorum_design=0.62,
failure_model=0.76,
leader_election=0.58,
log_replication=0.64,
partition_behavior=0.80,
retry_idempotence=0.74,
observability=0.82,
recovery_design=0.72,
security_trust=0.78,
governance_review=0.82,
communication_clarity=0.78,
),
ConsensusCase(
case_name="Unsafe split-brain service",
system_context="Two partitions accept writes because leadership and quorum rules are unclear.",
coordination_goal="keep service writable during partition",
agreement_clarity=0.28,
quorum_design=0.18,
failure_model=0.30,
leader_election=0.22,
log_replication=0.24,
partition_behavior=0.12,
retry_idempotence=0.30,
observability=0.26,
recovery_design=0.22,
security_trust=0.44,
governance_review=0.20,
communication_clarity=0.30,
),
]
def majority_quorum(node_count: int) -> int:
return (node_count // 2) + 1
def crash_fault_tolerance(node_count: int) -> int:
return (node_count - 1) // 2
def byzantine_replica_requirement(faults: int) -> int:
return (3 * faults) + 1
def quorum_intersection_holds(node_count: int, quorum_size: int) -> bool:
return (2 * quorum_size) > node_count
def availability_with_majority(node_count: int, node_availability: float) -> float:
# Probability that at least a majority of nodes are available, assuming independent availability.
from math import comb
q = majority_quorum(node_count)
probability = 0.0
for available in range(q, node_count + 1):
probability += comb(node_count, available) * (node_availability ** available) * ((1.0 - node_availability) ** (node_count - available))
return round(probability, 8)
def calculator_examples() -> list[dict[str, object]]:
rows: list[dict[str, object]] = []
for n in [3, 5, 7, 9]:
q = majority_quorum(n)
rows.append({
"node_count": n,
"majority_quorum": q,
"crash_fault_tolerance": crash_fault_tolerance(n),
"quorum_intersection_holds": quorum_intersection_holds(n, q),
"majority_availability_at_99_percent_node_availability": availability_with_majority(n, 0.99),
})
for f in [1, 2, 3]:
rows.append({
"byzantine_faults": f,
"minimum_replicas_3f_plus_1": byzantine_replica_requirement(f),
})
return rows
def run_audit() -> list[dict[str, object]]:
rows: list[dict[str, object]] = []
for case in build_cases():
score = consensus_reliability_score(case)
risk = consensus_risk(case)
rows.append({
**asdict(case),
"consensus_reliability_score": round(score, 3),
"consensus_risk": round(risk, 3),
"diagnostic": diagnose(score, risk),
})
return rows
def write_csv(path: Path, rows: list[dict[str, object]]) -> None:
path.parent.mkdir(parents=True, exist_ok=True)
with path.open("w", newline="", encoding="utf-8") as handle:
writer = csv.DictWriter(handle, fieldnames=list(rows[0].keys()))
writer.writeheader()
writer.writerows(rows)
def write_json(path: Path, payload: object) -> None:
path.parent.mkdir(parents=True, exist_ok=True)
path.write_text(json.dumps(payload, indent=2, sort_keys=True), encoding="utf-8")
def summarize(rows: list[dict[str, object]]) -> dict[str, object]:
return {
"case_count": len(rows),
"average_consensus_reliability_score": round(mean(float(row["consensus_reliability_score"]) for row in rows), 3),
"average_consensus_risk": round(mean(float(row["consensus_risk"]) for row in rows), 3),
"highest_score_case": max(rows, key=lambda row: float(row["consensus_reliability_score"]))["case_name"],
"highest_risk_case": max(rows, key=lambda row: float(row["consensus_risk"]))["case_name"],
"interpretation": "Consensus reliability depends on agreement clarity, quorum design, failure model, leader election, log replication, partition behavior, retry idempotence, observability, recovery, security, governance, and communication."
}
def main() -> None:
audit_rows = run_audit()
summary = summarize(audit_rows)
calculator_rows = calculator_examples()
write_csv(TABLES / "consensus_fault_tolerance_audit.csv", audit_rows)
write_csv(TABLES / "consensus_fault_tolerance_audit_summary.csv", [summary])
write_csv(TABLES / "consensus_fault_tolerance_calculator_examples.csv", calculator_rows)
write_json(JSON_DIR / "consensus_fault_tolerance_audit.json", audit_rows)
write_json(JSON_DIR / "consensus_fault_tolerance_audit_summary.json", summary)
write_json(JSON_DIR / "consensus_fault_tolerance_calculator_examples.json", calculator_rows)
print("Consensus, coordination, and fault-tolerance audit complete.")
print(TABLES / "consensus_fault_tolerance_audit.csv")
if __name__ == "__main__":
main()
This workflow treats consensus as an auditable design pattern: not a black-box protocol, but a set of explicit commitments about agreement, failure, recovery, and evidence.
R Workflow: Consensus Reliability Summary
The R workflow reads the Python-generated audit table and creates summary outputs and visualizations using base R. It compares consensus reliability and consensus risk across synthetic systems.
# consensus_reliability_summary.R
# Base R workflow for summarizing consensus, coordination, and fault-tolerance audits.
args <- commandArgs(trailingOnly = FALSE)
file_arg <- grep("^--file=", args, value = TRUE)
if (length(file_arg) > 0) {
script_path <- normalizePath(sub("^--file=", "", file_arg[1]), mustWork = TRUE)
article_root <- normalizePath(file.path(dirname(script_path), ".."), mustWork = TRUE)
} else {
article_root <- getwd()
}
setwd(article_root)
tables_dir <- file.path(article_root, "outputs", "tables")
figures_dir <- file.path(article_root, "outputs", "figures")
if (!dir.exists(tables_dir)) {
dir.create(tables_dir, recursive = TRUE)
}
if (!dir.exists(figures_dir)) {
dir.create(figures_dir, recursive = TRUE)
}
audit_path <- file.path(tables_dir, "consensus_fault_tolerance_audit.csv")
if (!file.exists(audit_path)) {
stop(paste("Missing", audit_path, "Run the Python workflow first."))
}
data <- read.csv(audit_path, stringsAsFactors = FALSE)
summary_table <- data.frame(
case_count = nrow(data),
average_consensus_reliability_score = mean(data$consensus_reliability_score),
average_consensus_risk = mean(data$consensus_risk),
highest_score_case = data$case_name[which.max(data$consensus_reliability_score)],
highest_risk_case = data$case_name[which.max(data$consensus_risk)]
)
write.csv(
summary_table,
file.path(tables_dir, "r_consensus_reliability_summary.csv"),
row.names = FALSE
)
comparison_matrix <- rbind(
data$consensus_reliability_score,
data$consensus_risk
)
colnames(comparison_matrix) <- data$case_name
rownames(comparison_matrix) <- c(
"Consensus reliability",
"Consensus risk"
)
png(
file.path(figures_dir, "consensus_reliability_vs_risk.png"),
width = 1500,
height = 850
)
barplot(
comparison_matrix,
beside = TRUE,
las = 2,
ylim = c(0, 100),
ylab = "Score",
main = "Consensus Reliability vs. Consensus Risk"
)
legend(
"topleft",
legend = rownames(comparison_matrix),
pch = 15,
bty = "n"
)
grid()
dev.off()
calculator_path <- file.path(tables_dir, "consensus_fault_tolerance_calculator_examples.csv")
if (file.exists(calculator_path)) {
calculators <- read.csv(calculator_path, stringsAsFactors = FALSE)
write.csv(
calculators,
file.path(tables_dir, "r_consensus_fault_tolerance_calculator_examples.csv"),
row.names = FALSE
)
}
print(summary_table)
This workflow makes the difference between consensus reliability and consensus risk visible across system designs.
GitHub Repository
The companion repository for this article will provide reproducible code, synthetic datasets, workflow documentation, generated outputs, quorum calculators, fault-tolerance examples, consensus-readiness audits, leader-election examples, recovery notes, observability artifacts, and governance materials that extend the article into executable examples.
Complete Code Repository
Companion article folder with Python, R, Julia, SQL, Haskell, C, C++, Fortran, Rust, Go, Java, TypeScript, Prolog, Racket, notebooks, documentation, synthetic teaching data, generated outputs, schemas, and Canvas-ready workflow artifacts for consensus, coordination, fault tolerance, quorum design, leader election, replicated logs, state-machine replication, failure models, partition behavior, retries, idempotence, split-brain prevention, observability, recovery, security, and distributed governance.
articles/consensus-coordination-and-fault-tolerance/
├── python/
│ ├── consensus_fault_tolerance_audit.py
│ ├── quorum_examples.py
│ ├── leader_election_examples.py
│ ├── replicated_log_examples.py
│ ├── retry_idempotence_examples.py
│ ├── partition_behavior_examples.py
│ ├── calculators/
│ │ ├── majority_quorum_calculator.py
│ │ └── byzantine_fault_threshold_calculator.py
│ └── tests/
├── r/
│ ├── consensus_reliability_summary.R
│ ├── quorum_fault_tolerance_report.R
│ └── consensus_risk_visualization.R
├── julia/
│ ├── quorum_examples.jl
│ └── fault_tolerance_thresholds.jl
├── sql/
│ ├── schema_consensus_cases.sql
│ ├── schema_quorum_records.sql
│ └── consensus_quality_queries.sql
├── haskell/
│ ├── ConsensusModels.hs
│ ├── FaultTolerance.hs
│ └── Main.hs
├── rust/
│ └── src/
├── go/
│ └── main.go
├── c/
│ └── consensus_metrics.c
├── cpp/
│ └── consensus_metrics.cpp
├── fortran/
│ └── consensus_model.f90
├── java/
│ └── src/main/java/org/contentcatalyst/algorithms/
├── typescript/
│ └── src/
├── prolog/
│ └── consensus_rules.pl
├── racket/
│ └── consensus_checker.rkt
├── docs/
│ ├── methodology.md
│ ├── article-notes.md
│ ├── consensus-coordination-and-fault-tolerance.md
│ ├── governance-notes.md
│ └── responsible-use.md
├── data/
│ └── synthetic_consensus_cases.csv
├── outputs/
│ ├── tables/
│ ├── figures/
│ ├── json/
│ ├── logs/
│ └── reports/
├── notebooks/
│ └── consensus_coordination_and_fault_tolerance_walkthrough.ipynb
├── canvas/
│ ├── canvas_manifest.json
│ ├── canvas_cards.json
│ └── canvas_index.md
└── shared/
├── schemas/
├── templates/
├── taxonomies/
├── benchmarks/
└── governance/A Practical Method for Designing Fault-Tolerant Coordination
A practical method for designing fault-tolerant coordination begins with a simple question: what decision must remain coherent when parts of the system fail?
| Step | Question | Output |
|---|---|---|
| 1. Define the decision. | What must nodes agree on? | Consensus object: value, leader, log entry, lock, configuration, or state. |
| 2. Define participants. | Which nodes can vote, propose, replicate, or lead? | Membership and node map. |
| 3. State the failure model. | Crash, delay, partition, restart, Byzantine, or operator error? | Failure assumptions. |
| 4. Choose quorum rules. | How much agreement is enough? | Quorum size and intersection rule. |
| 5. Define leadership. | Is there a leader, and how is it elected? | Election, term, lease, or leaderless protocol. |
| 6. Define commitment. | When is a decision durable and visible? | Commit rule and publication gate. |
| 7. Define partition behavior. | What happens when communication breaks? | Consistency, availability, read-only, degraded, or fail-closed mode. |
| 8. Design recovery. | How do nodes rejoin and reconcile? | Replay, snapshot, repair, and reconciliation plan. |
| 9. Make retries safe. | Can repeated work duplicate effects? | Idempotency keys and deduplication logs. |
| 10. Preserve evidence. | Can decisions be reconstructed? | Trace IDs, quorum records, logs, terms, versions, governance notes. |
Fault-tolerant coordination is strongest when agreement, failure, recovery, and evidence are specified together.
Common Pitfalls
A common pitfall is treating consensus as a magic reliability layer. Consensus solves a specific agreement problem under specific assumptions. It does not automatically solve authorization, data quality, source validity, user disclosure, organizational accountability, observability, or ethical decision-making.
Common pitfalls include:
- unclear failure model: the system claims fault tolerance without saying which faults are tolerated;
- leader ambiguity: stale or competing leaders can accept conflicting decisions;
- weak quorum design: decisions do not have reliable intersection guarantees;
- split-brain behavior: partitions continue writing independently without reconciliation discipline;
- unsafe retries: repeated requests duplicate external effects;
- hidden partial failure: users see clean outputs while components are unavailable;
- agreement mistaken for correctness: nodes agree on a bad or unauthorized value;
- poor observability: quorum decisions and recovery events cannot be reconstructed;
- operator-driven inconsistency: deployments, configuration, or manual recovery violate protocol assumptions;
- governance gaps: no one owns partition behavior, failover, recovery, or degraded-mode disclosure.
The remedy is explicitness: define what must be agreed on, who can participate, what failures are expected, how progress is made, how safety is preserved, and how decisions are audited.
Why Consensus Shapes Computational Judgment
Consensus, coordination, and fault tolerance shape computational judgment because they determine how systems decide when knowledge is incomplete and failure is possible. They force designers to distinguish agreement from truth, progress from safety, availability from consistency, retries from duplication, leadership from authority, and fault tolerance from invisibility.
A reliable distributed system does not pretend that networks are perfect. It does not hide uncertainty behind a clean output. It defines what can fail, what must agree, what can proceed, what must stop, what can be retried, what must be logged, and what users or operators need to know.
Consensus makes agreement possible. Coordination makes shared work possible. Fault tolerance makes useful behavior possible under failure. Governance makes these mechanisms accountable.
The strongest systems are not those that never fail. They are systems whose failures are anticipated, bounded, observable, recoverable, and honestly represented.
The next article turns to online algorithms and decisions under arrival, where computation must make decisions as information arrives over time rather than after the entire input is known.
Related Articles
- Distributed Algorithms and Networked Computation
- Concurrency and Parallel Computation
- Parallelism, Distribution, and Computational Scale
- Runtime Systems, Environments, and Computational Context
- Testing, Verification, and Computational Reliability
- Data Pipelines and Algorithmic Workflow Design
- Workflow Orchestration and Reproducible Computation
- Online Algorithms and Decisions Under Arrival
Further Reading
- Attiya, H. and Welch, J. (2004) Distributed Computing: Fundamentals, Simulations, and Advanced Topics. 2nd edn. Hoboken, NJ: Wiley.
- Birman, K.P. (2012) Guide to Reliable Distributed Systems: Building High-Assurance Applications and Cloud-Hosted Services. London: Springer.
- Chandra, T.D. and Toueg, S. (1996) ‘Unreliable failure detectors for reliable distributed systems’, Journal of the ACM, 43(2), pp. 225–267.
- Fischer, M.J., Lynch, N.A. and Paterson, M.S. (1985) ‘Impossibility of distributed consensus with one faulty process’, Journal of the ACM, 32(2), pp. 374–382.
- Lamport, L. (1978) ‘Time, clocks, and the ordering of events in a distributed system’, Communications of the ACM, 21(7), pp. 558–565.
- Lamport, L. (1998) ‘The part-time parliament’, ACM Transactions on Computer Systems, 16(2), pp. 133–169.
- Lamport, L., Shostak, R. and Pease, M. (1982) ‘The Byzantine generals problem’, ACM Transactions on Programming Languages and Systems, 4(3), pp. 382–401.
- Lynch, N.A. (1996) Distributed Algorithms. San Francisco, CA: Morgan Kaufmann.
- Ongaro, D. and Ousterhout, J. (2014) ‘In search of an understandable consensus algorithm’, USENIX Annual Technical Conference, pp. 305–319.
- Schneider, F.B. (1990) ‘Implementing fault-tolerant services using the state machine approach: A tutorial’, ACM Computing Surveys, 22(4), pp. 299–319.
- Tanenbaum, A.S. and Van Steen, M. (2017) Distributed Systems. 3rd edn. Maarten van Steen.
References
- Attiya, H. and Welch, J. (2004) Distributed Computing: Fundamentals, Simulations, and Advanced Topics. 2nd edn. Hoboken, NJ: Wiley.
- Birman, K.P. (2012) Guide to Reliable Distributed Systems: Building High-Assurance Applications and Cloud-Hosted Services. London: Springer.
- Chandra, T.D. and Toueg, S. (1996) ‘Unreliable failure detectors for reliable distributed systems’, Journal of the ACM, 43(2), pp. 225–267.
- Fischer, M.J., Lynch, N.A. and Paterson, M.S. (1985) ‘Impossibility of distributed consensus with one faulty process’, Journal of the ACM, 32(2), pp. 374–382.
- Gilbert, S. and Lynch, N. (2002) ‘Brewer’s conjecture and the feasibility of consistent, available, partition-tolerant web services’, ACM SIGACT News, 33(2), pp. 51–59.
- Lamport, L. (1978) ‘Time, clocks, and the ordering of events in a distributed system’, Communications of the ACM, 21(7), pp. 558–565.
- Lamport, L. (1998) ‘The part-time parliament’, ACM Transactions on Computer Systems, 16(2), pp. 133–169.
- Lamport, L., Shostak, R. and Pease, M. (1982) ‘The Byzantine generals problem’, ACM Transactions on Programming Languages and Systems, 4(3), pp. 382–401.
- Lynch, N.A. (1996) Distributed Algorithms. San Francisco, CA: Morgan Kaufmann.
- Ongaro, D. and Ousterhout, J. (2014) ‘In search of an understandable consensus algorithm’, USENIX Annual Technical Conference, pp. 305–319.
- Schneider, F.B. (1990) ‘Implementing fault-tolerant services using the state machine approach: A tutorial’, ACM Computing Surveys, 22(4), pp. 299–319.
- Tanenbaum, A.S. and Van Steen, M. (2017) Distributed Systems. 3rd edn. Maarten van Steen.