
Last Updated June 17, 2026
Iteration, recursion, and control flow explain how algorithms move through time. An algorithm is not only a set of operations. It is an ordered process: it repeats, branches, calls subproblems, updates state, checks conditions, stops, and sometimes delegates work to other procedures.
Control flow is the structure that determines what happens next. Iteration repeats a block of computation while a condition, collection, counter, queue, or stream remains active. Recursion solves a problem by reducing it to smaller instances of the same problem. Together, these ideas form the procedural grammar of computation.
Good algorithmic reasoning requires knowing when to loop, when to recurse, when to branch, when to stop, and how to prove that the procedure is correct.
This article explains iteration, recursion, and control flow as foundational design concepts in computational reasoning, software systems, data workflows, mathematical models, and responsible automation.
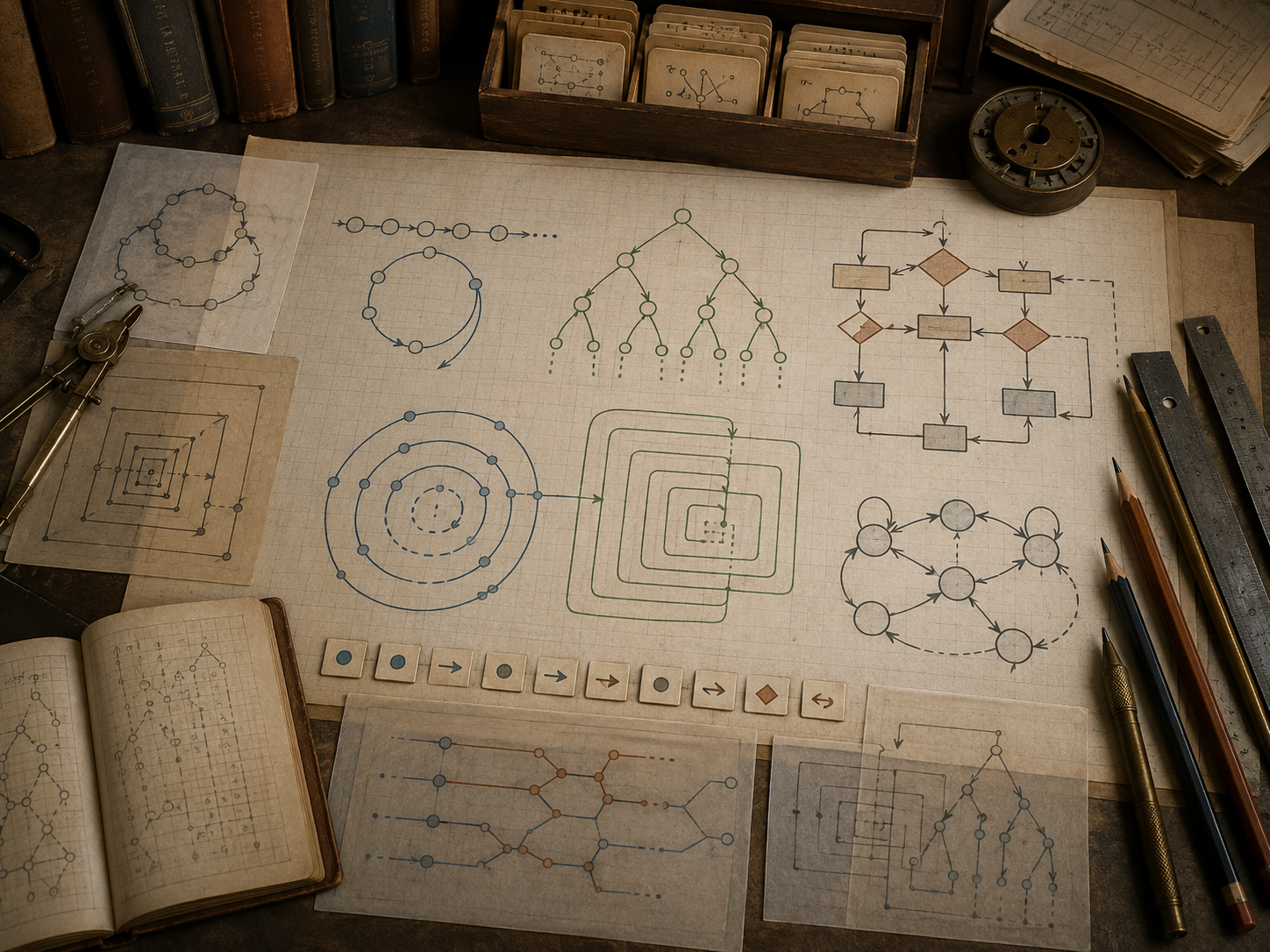
This article explains control flow as the architecture of procedural movement. It introduces sequencing, conditionals, loops, counters, accumulators, recursion, base cases, recursive decomposition, call stacks, termination, invariants, state updates, branching, exceptions, event-driven control, asynchronous workflows, data pipelines, and responsible stopping conditions. It emphasizes that control flow is not only a programming construct. It is a reasoning structure: a way of deciding what happens next, why it happens, and when it should end.
Why Iteration, Recursion, and Control Flow Matter
Iteration, recursion, and control flow matter because algorithms are not static descriptions. They unfold. They move from one step to the next, repeat when needed, branch when conditions differ, call smaller problems, and stop when their work is complete.
A procedure with unclear control flow is difficult to reason about. It may repeat forever, skip necessary cases, update state incorrectly, recurse without a base case, hide failure paths, or behave differently under unusual conditions.
| Control-flow concern | Why it matters | Computational reasoning question |
|---|---|---|
| Sequence | Steps happen in a defined order. | What must happen before what? |
| Selection | Branches choose among alternatives. | Which condition determines the path? |
| Iteration | Loops repeat computation. | What changes each time, and when does it stop? |
| Recursion | A procedure solves smaller versions of itself. | What is the base case, and what gets smaller? |
| State update | Variables, records, queues, or models change over time. | What is remembered after each step? |
| Termination | Execution must end under defined conditions. | What guarantees completion? |
| Error path | Unexpected conditions must be handled. | What happens when assumptions fail? |
| Traceability | The path should be reconstructable when needed. | Can we explain how this result was reached? |
Control flow is the logic of computational movement. It defines not only what the algorithm does, but how it gets there.
What Control Flow Is
Control flow is the order in which instructions, expressions, functions, procedures, or workflow steps are executed. It determines whether computation proceeds straight ahead, branches, repeats, calls another procedure, waits for an event, handles an error, or stops.
In programming languages, control flow appears through constructs such as `if`, `else`, `for`, `while`, `break`, `continue`, `return`, function calls, recursion, exceptions, callbacks, promises, coroutines, event handlers, and schedulers. In broader computational systems, control flow appears through workflow engines, queues, state machines, data pipelines, model pipelines, human approval steps, and automated decision paths.
| Control-flow form | What it does | Example |
|---|---|---|
| Sequential flow | Executes steps in order. | Read data, validate, transform, report. |
| Conditional flow | Chooses path based on condition. | If record is invalid, return error. |
| Iterative flow | Repeats until collection or condition is exhausted. | For each record, compute score. |
| Recursive flow | Calls the same procedure on smaller subproblems. | Traverse a tree by visiting each subtree. |
| Exceptional flow | Handles errors or unusual conditions. | Catch missing file and write diagnostic. |
| Event-driven flow | Runs when an event occurs. | When upload finishes, trigger validation. |
| Asynchronous flow | Allows work to proceed while waiting. | Queue task and check result later. |
| Human-in-the-loop flow | Pauses for review, approval, or intervention. | High-risk score requires human review. |
Control flow provides the structure that turns operations into a procedure.
Sequence, Selection, and Repetition
Many introductory accounts of control flow begin with three forms: sequence, selection, and repetition. Sequence executes steps in order. Selection chooses between paths. Repetition executes steps multiple times.
These forms are simple, but they are enough to express a remarkable range of computation when combined with memory, functions, data structures, and stopping conditions.
| Form | Question answered | Example |
|---|---|---|
| Sequence | What comes next? | Load data → validate → analyze → export. |
| Selection | Which path applies? | If score exceeds threshold, flag for review. |
| Repetition | Should this happen again? | Repeat until no unprocessed records remain. |
| Composition | How do these forms combine? | For each record, if valid, score; otherwise log error. |
A complex algorithm is often a disciplined composition of sequence, selection, and repetition.
Iteration and Looping
Iteration repeats a block of computation. A loop may iterate over a list, range, stream, queue, file, graph, state space, or condition. Iteration is useful when the same operation must be applied to many items or when a process should continue until a stopping condition is reached.
Loops require careful reasoning because they combine repetition, state change, and termination.
| Loop type | Use case | Design question |
|---|---|---|
| Counted loop | Repeat a known number of times. | Are the bounds correct? |
| Collection loop | Process every item in a collection. | What happens for empty collections? |
| Condition loop | Repeat while a condition remains true. | What changes to make the condition false? |
| Queue loop | Process work until queue is empty. | Can new work be added during processing? |
| Search loop | Continue until target is found or space is exhausted. | What guarantees completeness or stopping? |
| Simulation loop | Update system state over time. | What timestep, boundary, or stopping rule applies? |
| Training loop | Update model parameters. | What objective, convergence rule, and validation check apply? |
Iteration is not merely repetition. It is controlled repetition with a purpose, a state, and a stopping rule.
Counters, Accumulators, and State Updates
Loops often depend on variables that change over time. Counters track how many steps have occurred. Accumulators collect results. State variables record the current condition of a process. Queues and stacks manage pending work.
State updates are powerful, but they also create risk. If an update happens in the wrong order, under the wrong condition, or with the wrong initial value, the algorithm may silently drift from its intended behavior.
| State pattern | Purpose | Common risk |
|---|---|---|
| Counter | Track iteration count. | Off-by-one error. |
| Accumulator | Build sum, list, report, or result. | Incorrect initialization or duplicate update. |
| Flag | Record whether condition has occurred. | Flag is never reset or is updated too late. |
| Visited set | Avoid processing same item repeatedly. | Cycles cause infinite traversal if missing. |
| Queue | Manage first-in-first-out pending work. | Queue grows without bound. |
| Stack | Manage nested or last-in-first-out work. | Deep nesting exhausts memory. |
A loop is often best understood by asking: what state changes, what state must remain true, and what state determines stopping?
Loop Invariants and Termination
A loop invariant is a property that remains true before and after each iteration. It helps prove correctness by showing that repeated steps preserve a meaningful condition. Termination requires a progress measure: something that moves toward completion.
For example, a sorting loop may maintain the invariant that part of the array is already sorted. A graph traversal loop may maintain the invariant that every item in the visited set has already been processed. A search loop may maintain the invariant that the target, if present, remains within the current search interval.
| Reasoning element | Question | Example |
|---|---|---|
| Initialization | Is the invariant true before the loop starts? | Empty processed set is valid. |
| Maintenance | Does each iteration preserve the invariant? | New item is processed before being marked complete. |
| Progress | Does each iteration move toward stopping? | Remaining items decrease. |
| Termination | Does the loop eventually stop? | Queue becomes empty or index reaches end. |
| Usefulness | Does the invariant imply correctness at the end? | When all items processed, result is complete. |
Loop reasoning is one of the most important bridges between programming practice and mathematical proof.
Recursion and Self-Similar Structure
Recursion occurs when a procedure calls itself, directly or indirectly, to solve a smaller or simpler instance of the same problem. Recursion is powerful when a problem has self-similar structure: trees, nested expressions, divide-and-conquer algorithms, mathematical definitions, grammars, file systems, graphs, and hierarchical data.
Recursion is not magic. It is structured reduction.
| Recursive structure | Why recursion fits | Example |
|---|---|---|
| Tree | Each node has subtrees with same structure. | Traverse document outline or file directory. |
| Nested expression | Subexpressions are expressions. | Parse arithmetic expression. |
| Divide-and-conquer problem | Problem splits into smaller similar problems. | Merge sort. |
| Mathematical definition | Value defined in terms of smaller value. | Factorial or Fibonacci. |
| Grammar | Rules expand recursively. | Programming-language parser. |
| Graph search | Neighbors lead to further neighbors. | Depth-first search with visited set. |
| Institutional hierarchy | Units contain subunits. | Recursive reporting structure. |
Recursion is best when the problem’s structure is naturally recursive. It is risky when it hides excessive work, unclear base cases, or unbounded depth.
Base Cases, Recursive Cases, and Progress
Every recursive algorithm needs at least one base case and at least one recursive case. The base case stops recursion. The recursive case reduces the problem and calls the procedure again.
A recursive design is sound only if each recursive call makes progress toward a base case.
| Recursive element | Purpose | Failure if missing |
|---|---|---|
| Base case | Stops recursion at simplest case. | Infinite recursion or stack overflow. |
| Recursive case | Reduces problem to smaller instance. | No meaningful decomposition. |
| Progress measure | Shows movement toward base case. | Call may repeat same problem forever. |
| Combination step | Builds final result from recursive results. | Subproblem answers do not solve full problem. |
| State isolation | Prevents unintended shared mutation. | Recursive calls interfere with one another. |
| Depth control | Limits memory and failure risk. | Deep recursion exhausts stack. |
The central recursive question is: what gets smaller, and why is the smallest case already solved?
Call Stacks and Recursive Memory
When a recursive function calls itself, each call has its own execution context. The call stack records pending calls, local variables, return addresses, and intermediate results. This makes recursion expressive, but it also creates memory costs.
Some recursive procedures are elegant but inefficient. A naive recursive Fibonacci function repeats the same work many times. Recursive tree traversal is natural and efficient for tree-shaped data. Tail recursion can sometimes be optimized, depending on language and runtime. Deep recursion may fail if the call stack is limited.
| Recursive memory concern | Meaning | Design response |
|---|---|---|
| Call stack depth | Number of active recursive calls. | Analyze maximum depth or use iteration. |
| Repeated subproblems | Same result is recomputed. | Use memoization or dynamic programming. |
| Local state | Each call has its own variables. | Preserve isolation and avoid unintended sharing. |
| Shared mutable state | Recursive calls modify common structure. | Use careful update discipline or immutable structures. |
| Tail recursion | Recursive call is final action. | May be optimized in some languages. |
| Stack overflow | Depth exceeds runtime limit. | Convert to iterative loop or explicit stack. |
Recursion should be evaluated both conceptually and operationally: it may match the problem beautifully while still requiring attention to memory and runtime context.
Iteration vs. Recursion
Iteration and recursion can often express the same computation. The choice depends on problem structure, language support, memory cost, readability, performance, and maintainability.
Iteration is often clearer for linear repetition over collections. Recursion is often clearer for tree-shaped, nested, or divide-and-conquer problems. Some recursive algorithms can be transformed into iterative algorithms using an explicit stack or queue.
| Design consideration | Iteration may fit when | Recursion may fit when |
|---|---|---|
| Problem structure | Data are linear or sequential. | Data are hierarchical or self-similar. |
| State management | State is updated step by step. | State naturally belongs to subproblem calls. |
| Memory | Stack depth should be avoided. | Depth is bounded or manageable. |
| Readability | Loop expresses the idea directly. | Recursive definition mirrors the problem. |
| Performance | Runtime does not optimize recursion. | Recursive decomposition improves clarity or efficiency. |
| Failure risk | Deep recursion would be unsafe. | Base cases and progress are simple and clear. |
The question is not which form is superior. The question is which form makes the procedure easier to reason about under the constraints of the system.
Branching, Decision Paths, and Guards
Branching allows algorithms to behave differently under different conditions. A branch may check a value, type, threshold, permission, state, error condition, model confidence, or review requirement. Guard clauses can simplify control flow by handling invalid or special cases early.
Branching should be explicit and ordered carefully. A missing condition, overlapping condition, or wrongly ordered condition can produce subtle errors.
| Branching pattern | Purpose | Example |
|---|---|---|
| Guard clause | Exit early for invalid or special case. | If input is missing, return validation error. |
| Threshold branch | Choose path by numeric boundary. | If risk score exceeds threshold, escalate. |
| Type branch | Choose behavior by data type or variant. | If node is leaf, return value; else traverse children. |
| Permission branch | Control access based on role or scope. | If user lacks approval role, deny action. |
| State branch | Choose path based on workflow state. | Draft, review, approved, rejected, archived. |
| Error branch | Handle known failure condition. | If dependency times out, retry or fallback. |
| Confidence branch | Change behavior based on uncertainty. | If confidence is low, request human review. |
Branching is where computational logic often meets institutional judgment. A threshold is rarely just a number; it is a decision boundary.
Exceptions, Errors, and Interruptions
Control flow includes what happens when ordinary execution cannot continue. Exceptions, errors, interrupts, cancellations, timeouts, and fallback paths are part of the algorithm’s real behavior. They should not be treated as afterthoughts.
Failure paths are especially important in systems that process data, serve users, coordinate workflows, or make decisions.
| Failure-control pattern | Purpose | Risk if absent |
|---|---|---|
| Validation failure | Reject invalid input before deeper computation. | Invalid data propagates through system. |
| Exception handling | Respond to unexpected runtime condition. | System crashes or hides error. |
| Timeout | Bound waiting time. | Procedure hangs indefinitely. |
| Retry | Recover from temporary failure. | Transient error causes unnecessary failure. |
| Fallback | Provide degraded but safe behavior. | Total failure when dependency fails. |
| Cancellation | Stop unneeded or unsafe work. | Resources are wasted or stale work continues. |
| Audit logging | Preserve evidence of failure path. | Failure cannot be explained later. |
A responsible algorithm defines not only its success path, but also its failure paths.
Event-Driven and Asynchronous Control Flow
Modern computational systems often do not follow a single straight execution path. They may respond to events, queue tasks, process streams, wait for network responses, trigger callbacks, run scheduled jobs, or coordinate distributed services. Event-driven and asynchronous control flow introduce new reasoning challenges.
The central question becomes not only “What happens next?” but also “What happens when work completes later, out of order, more than once, or not at all?”
| Asynchronous concern | Why it matters | Design response |
|---|---|---|
| Ordering | Events may arrive out of sequence. | Use timestamps, versions, ordering keys, or reconciliation. |
| Duplication | Messages may be processed more than once. | Use idempotency keys. |
| Delay | Work may complete later than expected. | Use timeout, status tracking, and retry policy. |
| Failure | Tasks may fail after being accepted. | Use dead-letter queues and failure records. |
| Backpressure | Work may arrive faster than it can be processed. | Use queues, rate limits, load shedding, or scaling. |
| Traceability | Work spans many components. | Use correlation IDs and distributed traces. |
| Human review | Control flow may pause for judgment. | Represent review state explicitly. |
Asynchronous control flow turns procedural reasoning into systems reasoning.
Control Flow in Data, AI, and Modeling Systems
Control flow appears throughout data pipelines, AI workflows, simulations, and mathematical models. A data pipeline branches when validation fails. A training loop repeats until stopping criteria are met. A simulation updates state across time. A model-serving system routes low-confidence outputs to human review.
These systems are not only mathematical. They are procedural.
| System type | Control-flow pattern | Review concern |
|---|---|---|
| Data validation pipeline | Branch valid records and invalid records. | Are invalid records logged and reviewable? |
| Feature engineering pipeline | Iterate over columns, records, windows, or events. | Are transformations ordered and reproducible? |
| Machine-learning training | Repeat parameter updates until stopping rule. | Is convergence or early stopping justified? |
| Model serving | Branch by confidence, policy, or risk threshold. | When is human review required? |
| Simulation model | Iterate state transitions over time. | Are timestep and boundary conditions valid? |
| Search system | Explore candidates until target or limit is reached. | Is search complete, biased, or prematurely stopped? |
| Generative AI workflow | Route through retrieval, generation, validation, and fallback. | What happens when evidence is missing? |
Control flow determines how evidence, uncertainty, validation, and review move through computational systems.
Control Flow Governance
Control flow becomes a governance issue when branches, loops, thresholds, retries, and stopping rules affect people, resources, public claims, or institutional decisions. Governance asks who defines the path, who can change it, how exceptions are handled, and whether the path can be audited.
A control-flow diagram is not enough. Consequential systems need evidence of how control actually moved through the system.
| Governance concern | Review question | Evidence |
|---|---|---|
| Branch criteria | Who defines decision thresholds and conditions? | Policy record, design rationale, version history. |
| Stopping rule | When does the procedure stop or escalate? | Termination condition and monitoring evidence. |
| Exception handling | What happens when assumptions fail? | Error logs, fallback plan, incident review. |
| Human review | Which cases require human judgment? | Review queue, audit trail, approval record. |
| Retry policy | How are temporary failures handled? | Retry count, timeout, dead-letter record. |
| Path traceability | Can the exact path be reconstructed? | Execution trace, correlation ID, run manifest. |
| Change control | How are control-flow changes reviewed? | Pull request, decision record, test evidence. |
Governed control flow makes computational pathways visible, contestable, and accountable.
Representation Risk
Iteration, recursion, and control flow carry representation risk because the visible structure of a procedure can hide important assumptions. A loop may appear simple while depending on data order. A recursion may appear elegant while failing for deep inputs. A branch may appear neutral while encoding a contested threshold. A stopping rule may appear technical while reflecting an institutional judgment.
Control flow can make decisions look automatic when they are actually designed choices.
| Risk | How it appears | Review response |
|---|---|---|
| Infinite loop risk | Condition never becomes false. | Define progress measure and maximum guard. |
| Unbounded recursion | Recursive calls do not reach base case. | Prove reduction and test depth limits. |
| Hidden state dependence | Result depends on prior updates or iteration order. | Document state and test alternative orders. |
| Threshold opacity | Branch condition is treated as neutral. | Explain threshold rationale and consequences. |
| Silent exception path | Error branch hides or drops cases. | Log, report, and review exceptions. |
| Premature stopping | Algorithm stops before sufficient search or validation. | Review stopping rule and error bounds. |
| Trace gap | Final result lacks path evidence. | Preserve run logs, decision traces, and state records. |
Control flow is never merely mechanical. It embodies choices about order, attention, stopping, exception, and responsibility.
Examples Across Computational Systems
The examples below show how iteration, recursion, and control flow appear across software, data systems, modeling, AI workflows, public platforms, and institutional automation.
Processing a dataset
A loop validates each record, branches invalid records into an error table, and accumulates summary statistics.
Traversing a tree
A recursive function visits a document outline, file directory, taxonomy, or organizational hierarchy.
Searching a graph
A traversal loop uses a queue or stack, a visited set, and a stopping condition to avoid cycles.
Training a model
A training loop updates parameters until convergence, validation deterioration, iteration limit, or early stopping rule.
Running a simulation
A time loop updates state variables according to rules, boundary conditions, and scenario parameters.
Routing a workflow
A case-management system branches by status, role, evidence, threshold, and human-review requirement.
Handling failure
An API retries temporary failures, times out slow dependencies, and sends unprocessable messages to a review queue.
Auditing an AI response
A generation workflow branches through retrieval, evidence checks, abstention paths, fallback logic, and review triggers.
Across these cases, control flow determines how computation proceeds, pauses, escalates, and ends.
Mathematics, Computation, and Modeling
Iteration can be represented as repeated application of a state-update function:
s_{t+1} = F(s_t)
\]
Interpretation: The next state \(s_{t+1}\) is produced by applying update rule \(F\) to current state \(s_t\).
A loop can be modeled as repetition until a stopping condition holds:
\text{repeat } F \text{ while } C(s_t) = \text{true}
\]
Interpretation: The loop continues while condition \(C\) remains true.
Recursion can be represented as a function defined in terms of smaller inputs:
R(n) =
\begin{cases}
b, & n = 0 \\
G(n, R(n-1)), & n > 0
\end{cases}
\]
Interpretation: The base case returns \(b\). The recursive case reduces the problem from \(n\) to \(n-1\).
Termination requires progress toward a well-founded stopping condition:
m(s_{t+1}) < m(s_t)
\]
Interpretation: A measure \(m\) decreases with each step, showing progress toward termination.
Control-flow quality can be summarized as:
Q_C = f(\text{clarity}, \text{invariants}, \text{termination}, \text{state discipline}, \text{error handling}, \text{traceability})
\]
Interpretation: Good control flow depends on clear paths, preserved properties, stopping rules, disciplined state updates, responsible failure behavior, and reconstructable evidence.
These models show why control flow belongs to computational reasoning. It is the structure of procedural time.
Python Workflow: Control Flow Audit
The Python workflow below creates a dependency-light audit for iteration, recursion, and control flow. It scores path clarity, loop structure, recursion structure, state-update discipline, termination evidence, invariant evidence, edge-case coverage, error handling, traceability, and governance readiness.
# control_flow_audit.py
# Dependency-light workflow for auditing iteration, recursion, and control flow.
from __future__ import annotations
from dataclasses import asdict, dataclass
from pathlib import Path
import csv
import json
from statistics import mean
ARTICLE_ROOT = Path(__file__).resolve().parents[1]
TABLES = ARTICLE_ROOT / "outputs" / "tables"
JSON_DIR = ARTICLE_ROOT / "outputs" / "json"
@dataclass(frozen=True)
class ControlFlowCase:
case_name: str
problem_context: str
control_flow_choice: str
path_clarity: float
loop_structure: float
recursion_structure: float
state_update_discipline: float
termination_evidence: float
invariant_evidence: float
edge_case_coverage: float
error_handling: float
traceability: float
governance_readiness: float
def clamp(value: float, low: float = 0.0, high: float = 100.0) -> float:
return max(low, min(high, value))
def control_flow_quality(case: ControlFlowCase) -> float:
return clamp(
100.0 * (
0.12 * case.path_clarity
+ 0.10 * case.loop_structure
+ 0.10 * case.recursion_structure
+ 0.10 * case.state_update_discipline
+ 0.12 * case.termination_evidence
+ 0.12 * case.invariant_evidence
+ 0.10 * case.edge_case_coverage
+ 0.08 * case.error_handling
+ 0.08 * case.traceability
+ 0.08 * case.governance_readiness
)
)
def control_flow_risk(case: ControlFlowCase) -> float:
weak_points = [
1.0 - case.path_clarity,
1.0 - case.loop_structure,
1.0 - case.state_update_discipline,
1.0 - case.termination_evidence,
1.0 - case.invariant_evidence,
1.0 - case.edge_case_coverage,
1.0 - case.error_handling,
1.0 - case.traceability,
1.0 - case.governance_readiness,
]
return clamp(100.0 * mean(weak_points))
def diagnose(quality: float, risk: float) -> str:
if quality >= 84 and risk <= 20:
return "strong control-flow discipline"
if quality >= 70 and risk <= 35:
return "usable control-flow discipline with review needs"
if risk >= 55:
return "high control-flow risk; path, state, termination, invariant, or traceability gaps may be present"
return "partial control-flow discipline; strengthen stopping rules, invariants, state updates, and evidence"
def build_cases() -> list[ControlFlowCase]:
return [
ControlFlowCase(
case_name="Dataset validation loop",
problem_context="A workflow validates many records and separates valid records from errors.",
control_flow_choice="Collection loop with guard clauses, accumulators, error table, and audit trail.",
path_clarity=0.90,
loop_structure=0.90,
recursion_structure=0.70,
state_update_discipline=0.88,
termination_evidence=0.90,
invariant_evidence=0.86,
edge_case_coverage=0.90,
error_handling=0.90,
traceability=0.88,
governance_readiness=0.88,
),
ControlFlowCase(
case_name="Recursive tree traversal",
problem_context="A knowledge taxonomy must be traversed from root to nested leaves.",
control_flow_choice="Recursive traversal with base case for leaves, depth checks, and visited-path evidence.",
path_clarity=0.88,
loop_structure=0.76,
recursion_structure=0.92,
state_update_discipline=0.84,
termination_evidence=0.90,
invariant_evidence=0.88,
edge_case_coverage=0.84,
error_handling=0.78,
traceability=0.86,
governance_readiness=0.82,
),
ControlFlowCase(
case_name="Asynchronous review workflow",
problem_context="High-risk model outputs should route through automated checks and human review.",
control_flow_choice="Event-driven control with status states, timeout handling, review queue, and correlation IDs.",
path_clarity=0.84,
loop_structure=0.78,
recursion_structure=0.64,
state_update_discipline=0.86,
termination_evidence=0.82,
invariant_evidence=0.82,
edge_case_coverage=0.84,
error_handling=0.88,
traceability=0.90,
governance_readiness=0.92,
),
ControlFlowCase(
case_name="Unbounded retry loop",
problem_context="A script retries failed external calls without a timeout, maximum count, or audit record.",
control_flow_choice="Condition loop with unclear failure behavior.",
path_clarity=0.46,
loop_structure=0.42,
recursion_structure=0.50,
state_update_discipline=0.44,
termination_evidence=0.22,
invariant_evidence=0.34,
edge_case_coverage=0.36,
error_handling=0.28,
traceability=0.30,
governance_readiness=0.28,
),
]
def iterative_sum(values: list[float]) -> dict[str, object]:
total = 0.0
trace = []
for index, value in enumerate(values):
total += value
trace.append({"index": index, "value": value, "running_total": total})
return {"total": total, "trace": trace, "invariant": "running_total equals sum of processed prefix"}
def recursive_countdown(n: int) -> list[int]:
if n <= 0:
return [0]
return [n] + recursive_countdown(n - 1)
def branch_review(score: float, threshold: float = 80.0) -> dict[str, object]:
if score < 0 or score > 100:
return {"path": "validation_error", "reason": "score outside 0..100"}
if score >= threshold:
return {"path": "human_review", "reason": "score exceeds review threshold"}
return {"path": "ordinary_processing", "reason": "score below review threshold"}
def run_control_flow_demos() -> dict[str, object]:
return {
"iterative_sum": iterative_sum([2, 4, 6]),
"recursive_countdown": recursive_countdown(4),
"branch_low_score": branch_review(62),
"branch_high_score": branch_review(91),
"branch_invalid_score": branch_review(120),
}
def run_audit() -> list[dict[str, object]]:
rows: list[dict[str, object]] = []
for case in build_cases():
quality = control_flow_quality(case)
risk = control_flow_risk(case)
rows.append({
**asdict(case),
"control_flow_quality": round(quality, 3),
"control_flow_risk": round(risk, 3),
"diagnostic": diagnose(quality, risk),
})
return rows
def write_csv(path: Path, rows: list[dict[str, object]]) -> None:
path.parent.mkdir(parents=True, exist_ok=True)
with path.open("w", newline="", encoding="utf-8") as handle:
writer = csv.DictWriter(handle, fieldnames=list(rows[0].keys()))
writer.writeheader()
writer.writerows(rows)
def write_json(path: Path, payload: object) -> None:
path.parent.mkdir(parents=True, exist_ok=True)
path.write_text(json.dumps(payload, indent=2, sort_keys=True), encoding="utf-8")
def summarize(rows: list[dict[str, object]]) -> dict[str, object]:
return {
"case_count": len(rows),
"average_control_flow_quality": round(mean(float(row["control_flow_quality"]) for row in rows), 3),
"average_control_flow_risk": round(mean(float(row["control_flow_risk"]) for row in rows), 3),
"highest_quality_case": max(rows, key=lambda row: float(row["control_flow_quality"]))["case_name"],
"highest_risk_case": max(rows, key=lambda row: float(row["control_flow_risk"]))["case_name"],
"interpretation": "Control-flow quality depends on path clarity, loop discipline, recursion structure, state updates, termination evidence, invariants, edge cases, error handling, traceability, and governance."
}
def main() -> None:
rows = run_audit()
summary = summarize(rows)
demos = run_control_flow_demos()
write_csv(TABLES / "control_flow_audit.csv", rows)
write_csv(TABLES / "control_flow_audit_summary.csv", [summary])
write_json(JSON_DIR / "control_flow_audit.json", rows)
write_json(JSON_DIR / "control_flow_audit_summary.json", summary)
write_json(JSON_DIR / "control_flow_demos.json", demos)
print("Control flow audit complete.")
print(TABLES / "control_flow_audit.csv")
if __name__ == "__main__":
main()
This workflow treats control flow as an auditable system of paths, state updates, stopping rules, and evidence.
R Workflow: Iteration and Recursion Summary
The R workflow reads the Python-generated audit table and creates summary outputs and visualizations using base R. It compares control-flow quality and control-flow risk across synthetic cases.
# control_flow_summary.R
# Base R workflow for summarizing iteration, recursion, and control-flow evidence.
args <- commandArgs(trailingOnly = FALSE)
file_arg <- grep("^--file=", args, value = TRUE)
if (length(file_arg) > 0) {
script_path <- normalizePath(sub("^--file=", "", file_arg[1]), mustWork = TRUE)
article_root <- normalizePath(file.path(dirname(script_path), ".."), mustWork = TRUE)
} else {
article_root <- getwd()
}
setwd(article_root)
tables_dir <- file.path(article_root, "outputs", "tables")
figures_dir <- file.path(article_root, "outputs", "figures")
if (!dir.exists(tables_dir)) {
dir.create(tables_dir, recursive = TRUE)
}
if (!dir.exists(figures_dir)) {
dir.create(figures_dir, recursive = TRUE)
}
input_path <- file.path(tables_dir, "control_flow_audit.csv")
if (!file.exists(input_path)) {
stop(paste("Missing", input_path, "Run the Python workflow first."))
}
data <- read.csv(input_path, stringsAsFactors = FALSE)
summary_table <- data.frame(
case_count = nrow(data),
average_control_flow_quality = mean(data$control_flow_quality),
average_control_flow_risk = mean(data$control_flow_risk),
highest_quality_case = data$case_name[which.max(data$control_flow_quality)],
highest_risk_case = data$case_name[which.max(data$control_flow_risk)]
)
write.csv(
summary_table,
file.path(tables_dir, "r_control_flow_summary.csv"),
row.names = FALSE
)
comparison_matrix <- rbind(
data$control_flow_quality,
data$control_flow_risk
)
colnames(comparison_matrix) <- data$case_name
rownames(comparison_matrix) <- c("Control-flow quality", "Control-flow risk")
png(
file.path(figures_dir, "control_flow_quality_vs_risk.png"),
width = 1400,
height = 800
)
barplot(
comparison_matrix,
beside = TRUE,
las = 2,
ylim = c(0, 100),
ylab = "Score",
main = "Control-Flow Quality vs. Control-Flow Risk"
)
legend(
"topleft",
legend = rownames(comparison_matrix),
pch = 15,
bty = "n"
)
grid()
dev.off()
png(
file.path(figures_dir, "control_flow_dimensions.png"),
width = 1400,
height = 800
)
dimension_means <- colMeans(data[, c(
"path_clarity",
"loop_structure",
"recursion_structure",
"state_update_discipline",
"termination_evidence",
"invariant_evidence",
"edge_case_coverage",
"error_handling",
"traceability",
"governance_readiness"
)]) * 100
barplot(
dimension_means,
las = 2,
ylim = c(0, 100),
ylab = "Average score",
main = "Average Control-Flow Evidence by Dimension"
)
grid()
dev.off()
print(summary_table)
This workflow helps compare dataset validation loops, recursive tree traversal, asynchronous review workflows, and unbounded retry loops by path clarity, loop structure, recursion structure, state discipline, termination, invariants, errors, and traceability.
GitHub Repository
The companion repository for this article will provide reproducible code, synthetic datasets, workflow documentation, generated outputs, control-flow audits, iteration and recursion examples, calculator scripts, test examples, and governance artifacts that extend the article into executable examples.
Complete Code Repository
Companion article folder with Python, R, Julia, SQL, Haskell, C, C++, Fortran, Rust, Go, Java, TypeScript, Prolog, Racket, notebooks, documentation, synthetic teaching data, generated outputs, schemas, and Canvas-ready workflow artifacts for iteration, recursion, control flow, sequence, selection, loops, counters, accumulators, state updates, loop invariants, base cases, recursive decomposition, call stacks, branching, exceptions, asynchronous workflows, traceability, stopping rules, and responsible computational governance.
articles/iteration-recursion-and-control-flow/
├── python/
│ ├── control_flow_audit.py
│ ├── iteration_examples.py
│ ├── recursion_examples.py
│ ├── branching_examples.py
│ ├── invariant_examples.py
│ ├── async_control_flow_examples.py
│ ├── calculators/
│ │ ├── control_flow_quality_calculator.py
│ │ └── recursion_depth_risk_calculator.py
│ └── tests/
├── r/
│ ├── control_flow_summary.R
│ ├── iteration_recursion_visualization.R
│ └── control_flow_governance_report.R
├── julia/
│ ├── iteration_recursion_examples.jl
│ └── state_update_examples.jl
├── sql/
│ ├── schema_control_flow_cases.sql
│ ├── schema_control_flow_taxonomy.sql
│ └── control_flow_queries.sql
├── haskell/
│ ├── ControlFlow.hs
│ ├── RecursionExamples.hs
│ └── Main.hs
├── rust/
│ └── src/
├── go/
│ └── main.go
├── c/
│ └── control_flow_audit.c
├── cpp/
│ └── control_flow_audit.cpp
├── fortran/
│ └── control_flow_quality_model.f90
├── java/
│ └── src/main/java/org/contentcatalyst/algorithms/
├── typescript/
│ └── src/
├── prolog/
│ └── control_flow_rules.pl
├── racket/
│ └── control_flow_checker.rkt
├── docs/
│ ├── methodology.md
│ ├── article-notes.md
│ ├── iteration-recursion-and-control-flow.md
│ ├── governance-notes.md
│ └── responsible-use.md
├── data/
│ └── synthetic_control_flow_cases.csv
├── outputs/
│ ├── tables/
│ ├── figures/
│ ├── json/
│ ├── logs/
│ └── reports/
├── notebooks/
│ └── iteration_recursion_and_control_flow_walkthrough.ipynb
├── canvas/
│ ├── canvas_manifest.json
│ ├── canvas_cards.json
│ └── canvas_index.md
└── shared/
├── schemas/
├── templates/
├── taxonomies/
├── benchmarks/
└── governance/A Practical Method for Reviewing Control Flow
A practical control-flow review begins with the question: can we explain every path the procedure can take, why each path is taken, how state changes, and when the procedure stops?
| Step | Question | Output |
|---|---|---|
| 1. Map the path. | What steps can occur, and in what order? | Control-flow map. |
| 2. Identify branches. | What conditions select each path? | Branch table. |
| 3. Review loops. | What repeats, what changes, and what stops repetition? | Loop invariant and stopping condition. |
| 4. Review recursion. | What is the base case, and what gets smaller? | Recursive proof sketch. |
| 5. Track state. | Which variables, records, queues, or stores change? | State-update map. |
| 6. Check edge cases. | What happens with empty, extreme, invalid, or cyclic inputs? | Edge-case test set. |
| 7. Define error paths. | What happens when assumptions fail? | Error-handling plan. |
| 8. Bound resource use. | Can loops, recursion, or queues grow without limit? | Depth, count, timeout, and capacity limits. |
| 9. Preserve traces. | Can the path be reconstructed after execution? | Logs, correlation IDs, audit records. |
| 10. Govern changes. | Who can change control paths and thresholds? | Review and version-control record. |
Control-flow review makes procedural movement visible before failures make it urgent.
Common Pitfalls
A common pitfall is treating control flow as obvious because the code runs. Running once does not prove that a loop stops for all valid inputs, that recursion reaches its base case, that branches cover all conditions, or that exceptions leave an audit trail.
Common pitfalls include:
- off-by-one errors: loop bounds exclude or include the wrong item;
- missing base case: recursion never reaches a stopping condition;
- unclear progress: loop or recursion does not move toward termination;
- hidden state mutation: state changes in places readers do not expect;
- branch overlap: multiple conditions apply, but order is not justified;
- branch gap: possible condition is not handled;
- silent exception path: failure is swallowed without evidence;
- unbounded retry: procedure repeats without timeout or maximum count;
- recursive overuse: recursion is elegant but unsafe for deep inputs;
- missing traceability: final output does not show which path produced it.
The remedy is to treat control flow as a design object: map it, test it, prove its stopping behavior, and preserve evidence.
Why Control Flow Shapes Computational Judgment
Iteration, recursion, and control flow matter because they determine how computation unfolds. They govern repetition, branching, state change, recursive decomposition, error handling, asynchronous coordination, and stopping. Without control-flow discipline, an algorithm may appear sensible in outline but fail in execution.
Control flow is where procedural logic becomes temporal behavior. A loop expresses a commitment to repeat until some condition changes. A recursive call expresses a commitment to reduce the problem toward a base case. A branch expresses a commitment to treat cases differently. A stopping rule expresses a judgment that enough work has been done.
These commitments should be explicit. They should be tested, reasoned about, documented, and governed when consequences matter.
To reason responsibly about algorithms, we must ask: what path can this procedure take, what state changes along the way, what remains true, what can fail, when does it stop, and how can we know what happened?
Related Articles
- Algorithm Design Principles
- Search and Sorting as Foundational Algorithms
- Decomposition and Stepwise Reasoning
- Termination, Invariants, and Edge Cases
- Trees, Hierarchies, and Recursive Structure
- Graphs, Networks, and Computational Relationships
- Memory, State, and Mutation in Computation
- Testing, Verification, and Computational Reliability
Further Reading
- Abelson, H. and Sussman, G.J. with Sussman, J. (1996) Structure and Interpretation of Computer Programs. 2nd edn. Cambridge, MA: MIT Press.
- Aho, A.V., Hopcroft, J.E. and Ullman, J.D. (1974) The Design and Analysis of Computer Algorithms. Reading, MA: Addison-Wesley.
- Bird, R. (2014) Thinking Functionally with Haskell. Cambridge: Cambridge University Press.
- Cormen, T.H., Leiserson, C.E., Rivest, R.L. and Stein, C. (2022) Introduction to Algorithms. 4th edn. Cambridge, MA: MIT Press.
- Dijkstra, E.W. (1976) A Discipline of Programming. Englewood Cliffs, NJ: Prentice Hall.
- Felleisen, M., Findler, R.B., Flatt, M. and Krishnamurthi, S. (2018) How to Design Programs. 2nd edn. Cambridge, MA: MIT Press.
- Hoare, C.A.R. (1969) ‘An axiomatic basis for computer programming’, Communications of the ACM, 12(10), pp. 576–580.
- Kernighan, B.W. and Ritchie, D.M. (1988) The C Programming Language. 2nd edn. Englewood Cliffs, NJ: Prentice Hall.
- Knuth, D.E. (1997) The Art of Computer Programming, Volume 1: Fundamental Algorithms. 3rd edn. Boston, MA: Addison-Wesley.
- Sedgewick, R. and Wayne, K. (2011) Algorithms. 4th edn. Boston, MA: Addison-Wesley.
References
- Abelson, H. and Sussman, G.J. with Sussman, J. (1996) Structure and Interpretation of Computer Programs. 2nd edn. Cambridge, MA: MIT Press.
- Aho, A.V., Hopcroft, J.E. and Ullman, J.D. (1974) The Design and Analysis of Computer Algorithms. Reading, MA: Addison-Wesley.
- Bird, R. (2014) Thinking Functionally with Haskell. Cambridge: Cambridge University Press.
- Cormen, T.H., Leiserson, C.E., Rivest, R.L. and Stein, C. (2022) Introduction to Algorithms. 4th edn. Cambridge, MA: MIT Press.
- Dijkstra, E.W. (1976) A Discipline of Programming. Englewood Cliffs, NJ: Prentice Hall.
- Felleisen, M., Findler, R.B., Flatt, M. and Krishnamurthi, S. (2018) How to Design Programs. 2nd edn. Cambridge, MA: MIT Press.
- Hoare, C.A.R. (1969) ‘An axiomatic basis for computer programming’, Communications of the ACM, 12(10), pp. 576–580.
- Kernighan, B.W. and Ritchie, D.M. (1988) The C Programming Language. 2nd edn. Englewood Cliffs, NJ: Prentice Hall.
- Knuth, D.E. (1997) The Art of Computer Programming, Volume 1: Fundamental Algorithms. 3rd edn. Boston, MA: Addison-Wesley.
- Sedgewick, R. and Wayne, K. (2011) Algorithms. 4th edn. Boston, MA: Addison-Wesley.